Curso
Ingesta de datos eficiente con pandas
4 h
62.7K
Después de manipular y filtrar un gran conjunto de datos, puede que acabes teniendo el DataFrame preciso que necesitas. Sin embargo, este DataFrame conserva el índice original, que puede ser no secuencial. En estos casos, debes restablecer el índice del Marco de datos.
En este tutorial, hablaremos del método pandas reset_index(), que se utiliza para restablecer el índice de un DataFrame. Exploraremos las distintas opciones disponibles con este método. Además, veremos cómo restablecer el índice de los DataFrame simples y multinivel.
Para practicar el restablecimiento de índices DataFrame, utilizaremos un conjunto de datos de aerolíneas. Utilizaremos Datalab de Datacamp, un entorno interactivo diseñado específicamente para análisis de datos en Pythonpor lo que es una herramienta perfecta para seguir este tutorial.
El métodoreset_index de Pandas restablece el índice de un DataFrame al predeterminado. Tras operaciones como filtrar, concatenar o fusionar, el índice puede dejar de ser secuencial. Este método ayuda a restablecer un índice limpio y secuencial. Si el Marco de Datos tiene un Multiíndice, puede eliminar uno o varios niveles.
Sintaxis básica:
df.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill="")Parámetros:
Devuelve:
DataFrame con el nuevo índice o Ninguno si inplace=True.
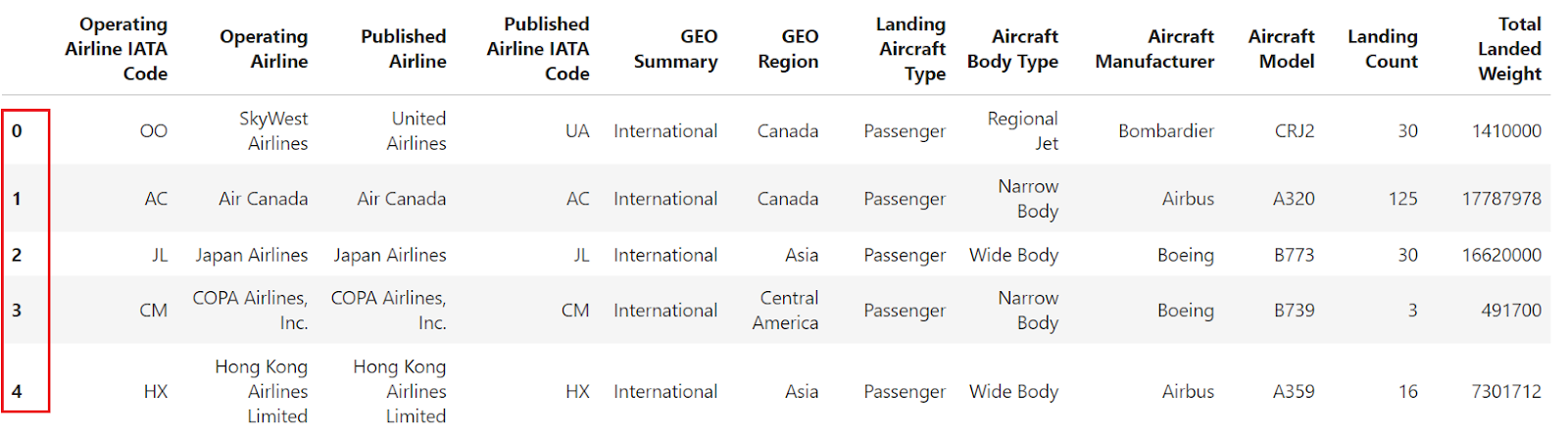
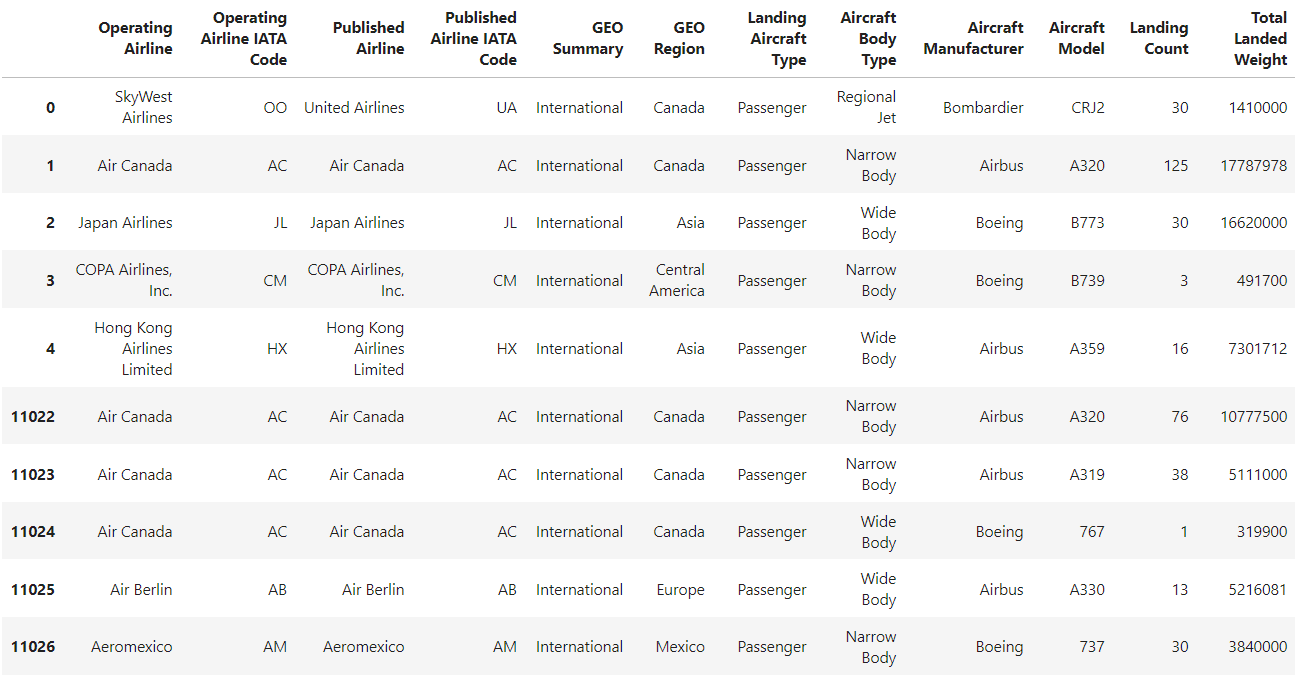
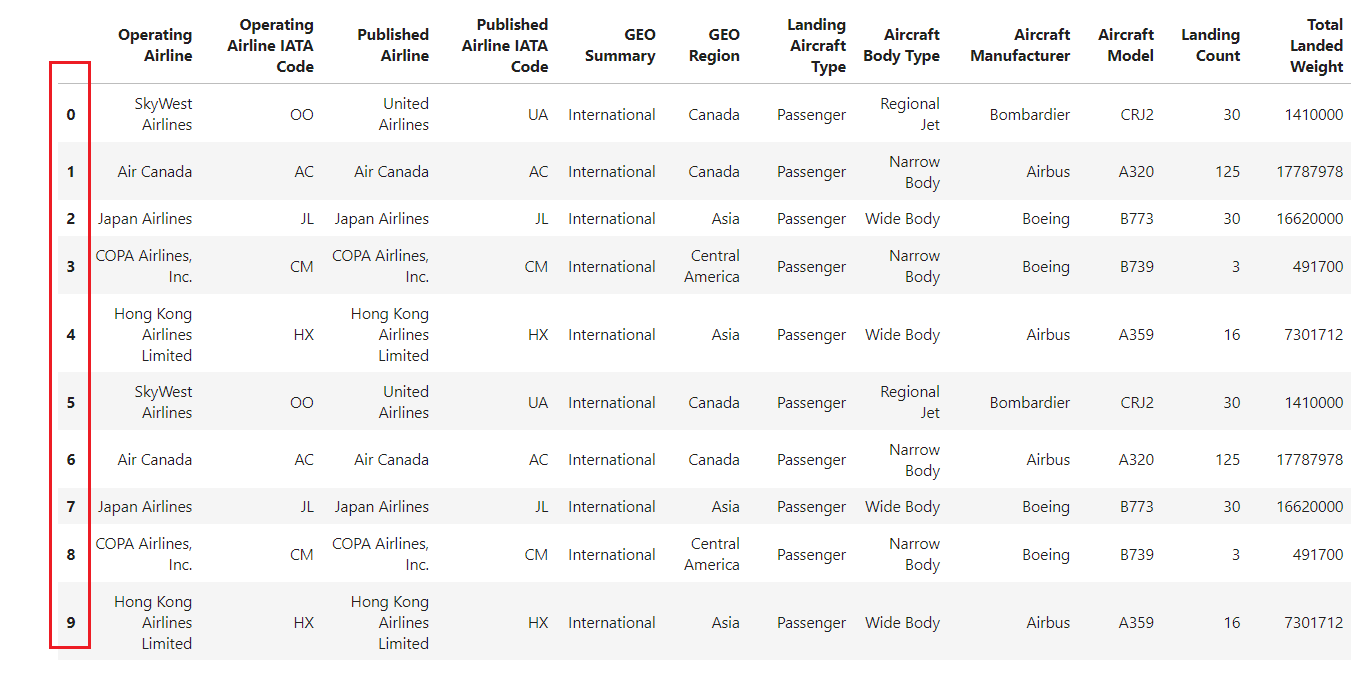
Si lees un archivo CSV utilizando el método pandas read_csv() sin especificar un índice, el DataFrame resultante tendrá un índice por defecto basado en números enteros que comenzará en 0 y aumentará en 1 para cada fila posterior.
import pandas as pd
df = pd.read_csv("airlines_dataset.csv").head()
df
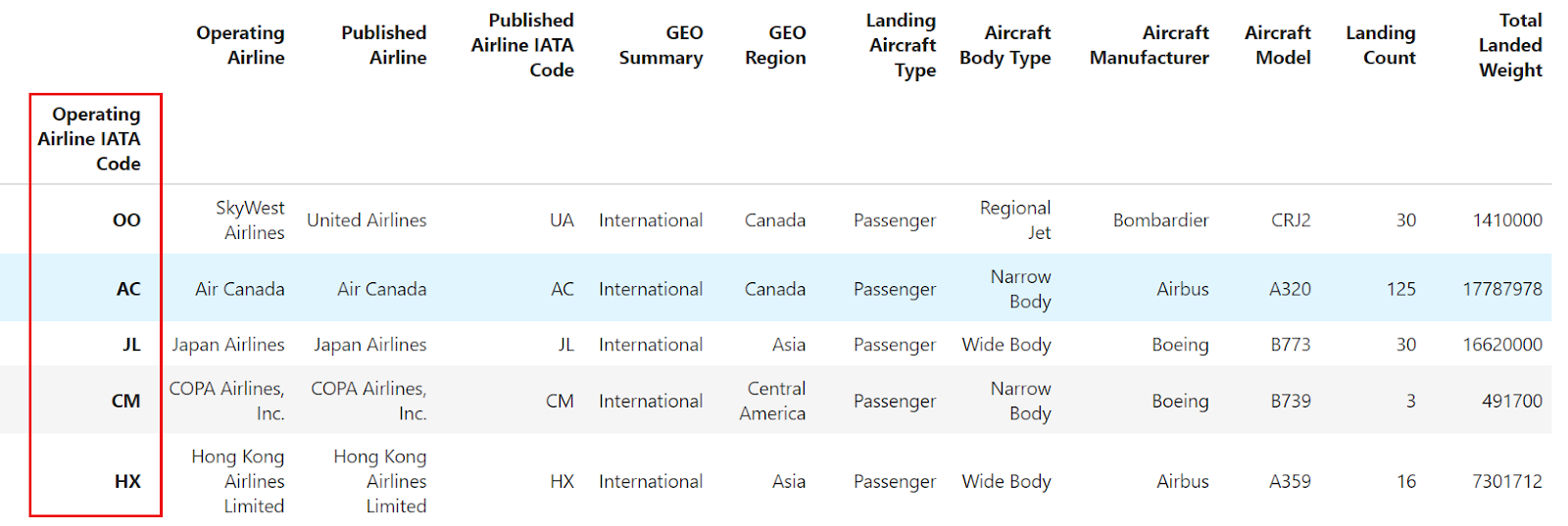
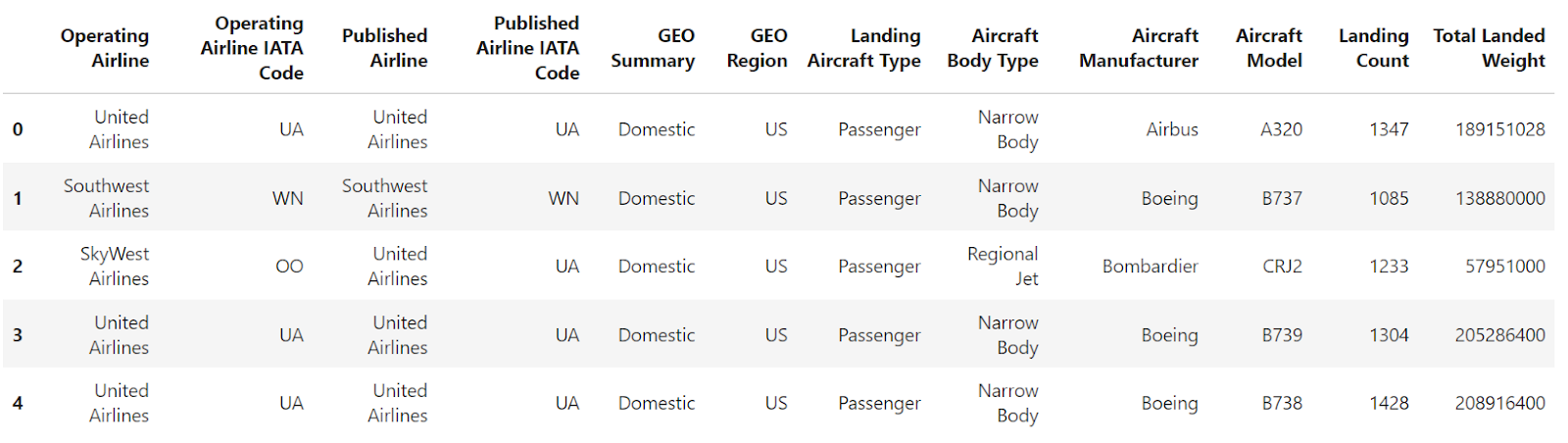
En algunos casos, puede que prefieras etiquetas de fila más descriptivas. Para conseguirlo, puedes establecer una de las columnas del Marco de datos como su índice (etiquetas de fila). Cuando utilices el método read_csv() para cargar datos de un archivo CSV, especifica la columna deseada para el índice utilizando el parámetroindex_col.
import pandas as pd
df = pd.read_csv("airlines_dataset.csv", index_col="Operating Airline IATA Code").head()
df
También puedes utilizar el método set_index() para establecer como índice cualquier columna de un Marco de datos:
import pandas as pd
df = pd.read_csv("airlines_dataset.csv").head()
df.set_index("Operating Airline IATA Code", inplace=True)
dfTen en cuenta que el fragmento de código hará cambios en el DataFrame original.
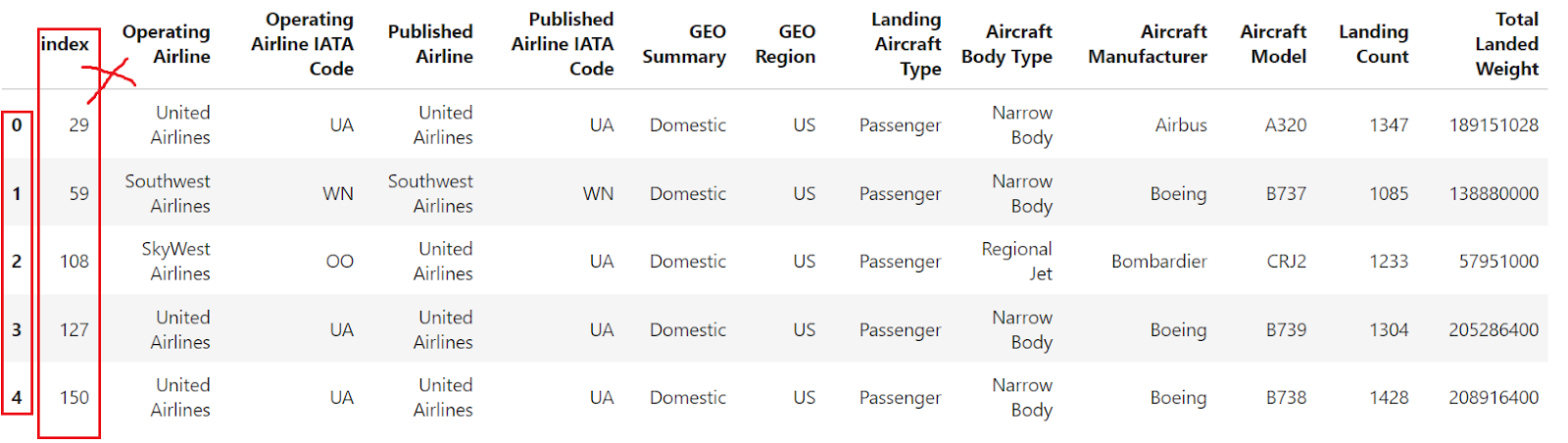
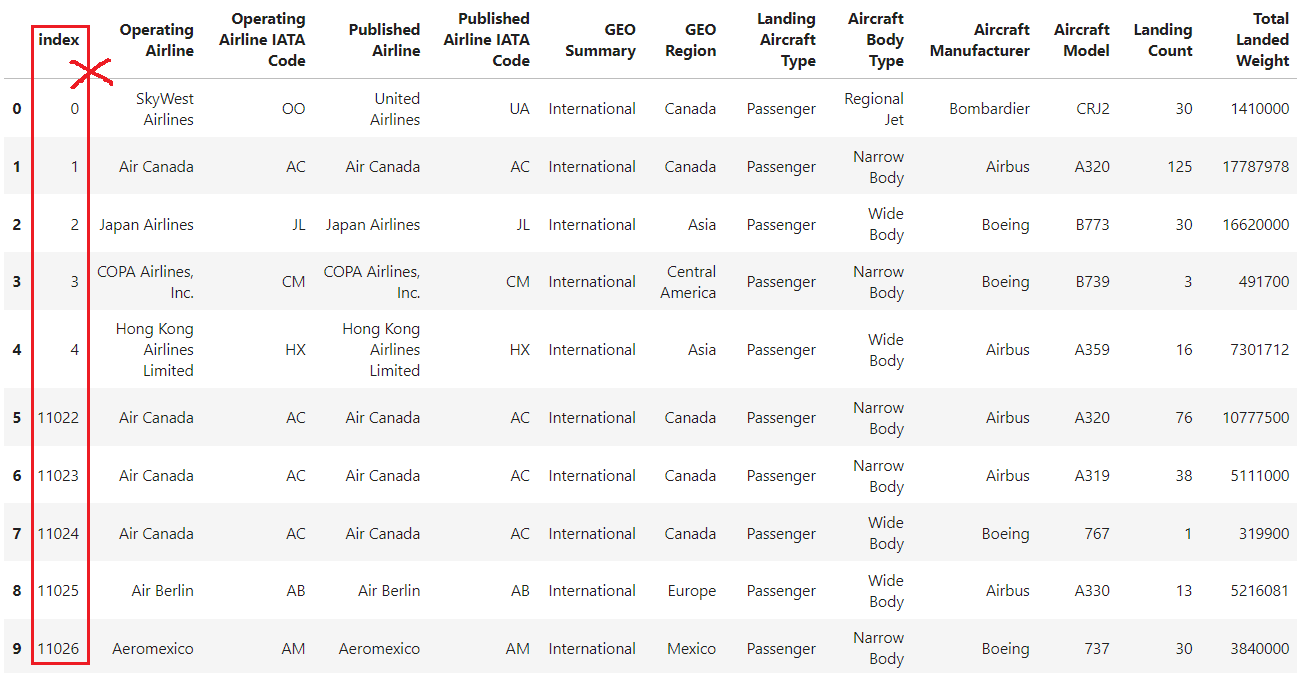
¿Y si necesitas restaurar el índice numérico por defecto? Aquí es donde entra en juego el método reset_index() Pandas.
df.reset_index()
El ejemplo muestra que, tras establecer como índice la columna "Código IATA de la compañía aérea operadora", reset_index se utiliza para revertir el Marco de Datos a su índice entero por defecto.
El método reset_index() de Pandas es una potente herramienta para reorganizar los índices de DataFrame cuando se trata de conjuntos de datos filtrados, DataFrames concatenados o índices multinivel.
Más información sobre remodelar marcos de datos de formato ancho a formato largo, cómo apilar y desapilar filas y columnas, y cómo manejar DataFrames multiíndice en nuestro curso online.
Cuando filtras un Marco de datos, se conserva el índice original. Utilizando reset_index, puedes volver a indexar el DataFrame filtrado.
import pandas as pd
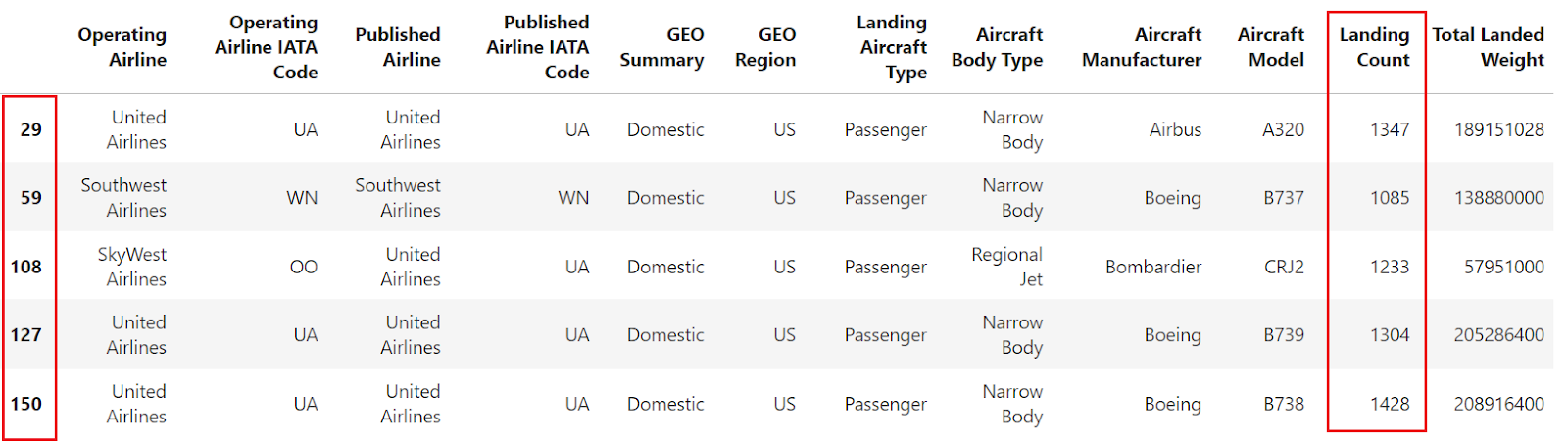
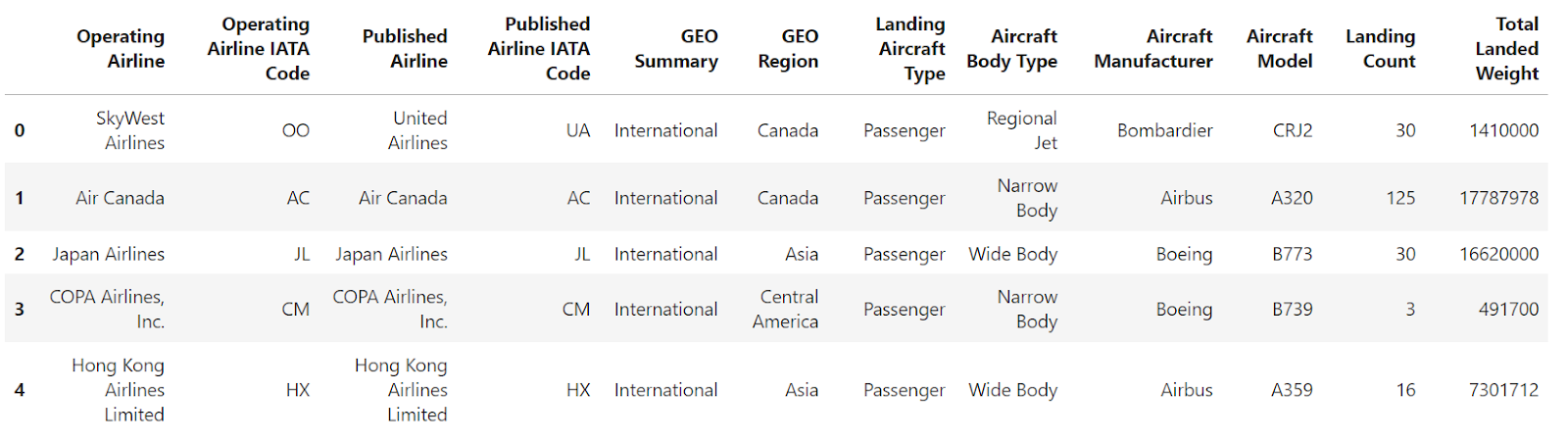
df = pd.read_csv("airlines_dataset.csv")Vamos a filtrar los datos para seleccionar sólo las filas en las que el "recuento de aterrizajes" sea superior a 1000. Tras el filtrado, los índices pueden no ser secuenciales. A continuación, puedes utilizar el método reset_index para restablecer el índice del Marco de datos filtrado.
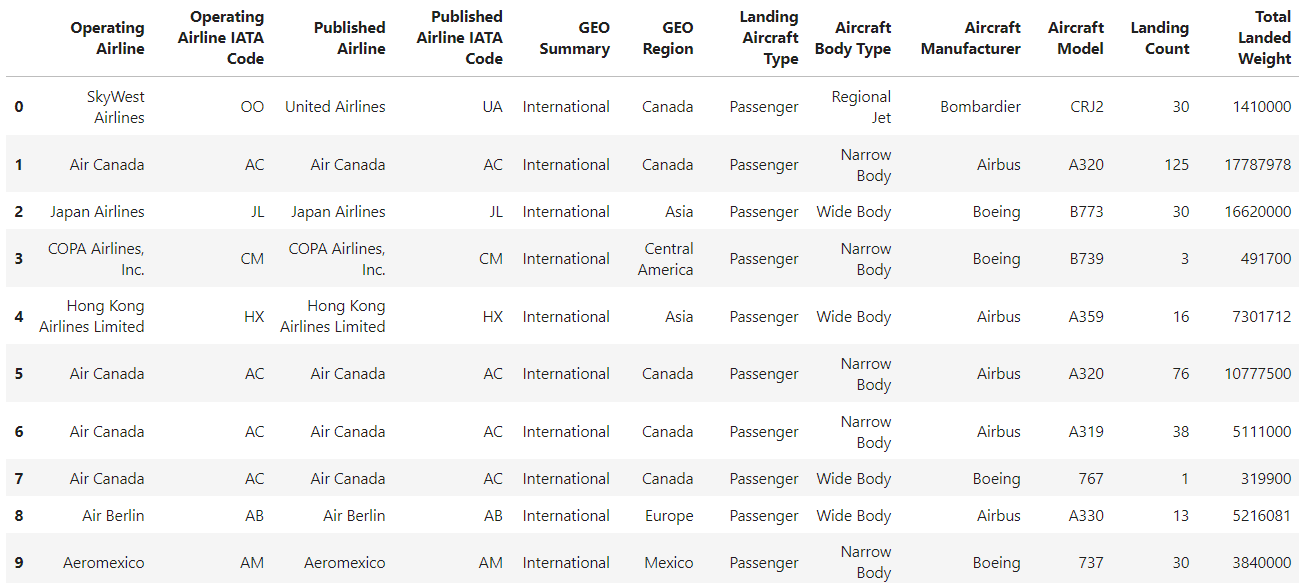
filtered_df = df[df["Landing Count"] > 1000].head()
filtered_df
La imagen anterior muestra que el marco de datos se filtra en función de la condición aplicada, pero el índice no es secuencial. Ahora, vamos a utilizar reset_index para reindexar el DataFrame filtrado y garantizar un índice secuencial. He aquí cómo puedes hacerlo:
filtered_df_reset = filtered_df.reset_index()
filtered_df_reset
El comportamiento por defecto de este método incluye sustituir el índice existente del Marco de datos por uno por defecto basado en números enteros y convertir el índice antiguo en una nueva columna con el mismo nombre (o "índice" si no tenía nombre).
Por tanto, utiliza el parámetro drop=Trueque garantiza que el índice antiguo no se añada como una columna nueva.
filtered_df_reset = filtered_df.reset_index(drop=True)
filtered_df_reset
¡Estupendo! Los índices se restablecen ahora al índice entero por defecto (0, 1, 2, ...), proporcionando un índice limpio y secuencial.
Al combinar DataFrames, el DataFrame resultante podría contener índices duplicados o no secuenciales. Restablecer el índice crea un índice limpio y secuencial.
Supón que tienes dos DataFrames y quieres concatenarlos. He creado dos DataFrames a partir del conjunto de datos de las compañías aéreas con fines de demostración.
import pandas as pd
df = pd.read_csv("airlines_dataset.csv")
split_index = int(df.shape[0] / 2)
df1 = df[:split_index].head()
df2 = df[split_index:].head()Aquí está df1:
Aquí está df2:
Vamos a concatenar los DataFrames df1 y df2.
df_concat = pd.concat([df1, df2])
Los datos muestran índices no secuenciales. Tenemos que restablecer el índice del DataFrame concatenado para que sea secuencial.
Vamos a restablecer el índice del DataFrame utilizando el método reset_index() de pandas.
df_concat.reset_index()
Éste es el resultado tras restablecer el índice del Marco de datos. El método reset_index convierte el índice antiguo en una columna nueva. Para eliminar esta columna adicional, debes utilizar el parámetro drop=True.
df_concat.reset_index(drop=True)
Para los DataFrames con indexación jerárquica (multinivel), reset_index puede utilizarse para simplificar el Marco de datos convirtiendo el índice multinivel en columnas.
Veamos un ejemplo de un Marco de datos con un índice multinivel.
import pandas as pd
df = pd.read_csv(
"airlines_dataset.csv", index_col=["Aircraft Model", "Operating Airline IATA Code"]
).head()
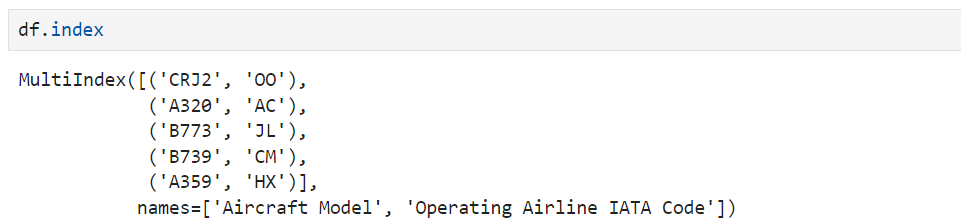
Si compruebas su índice, verás que no es un índice DataFrame común, sino un objeto MultiIndex
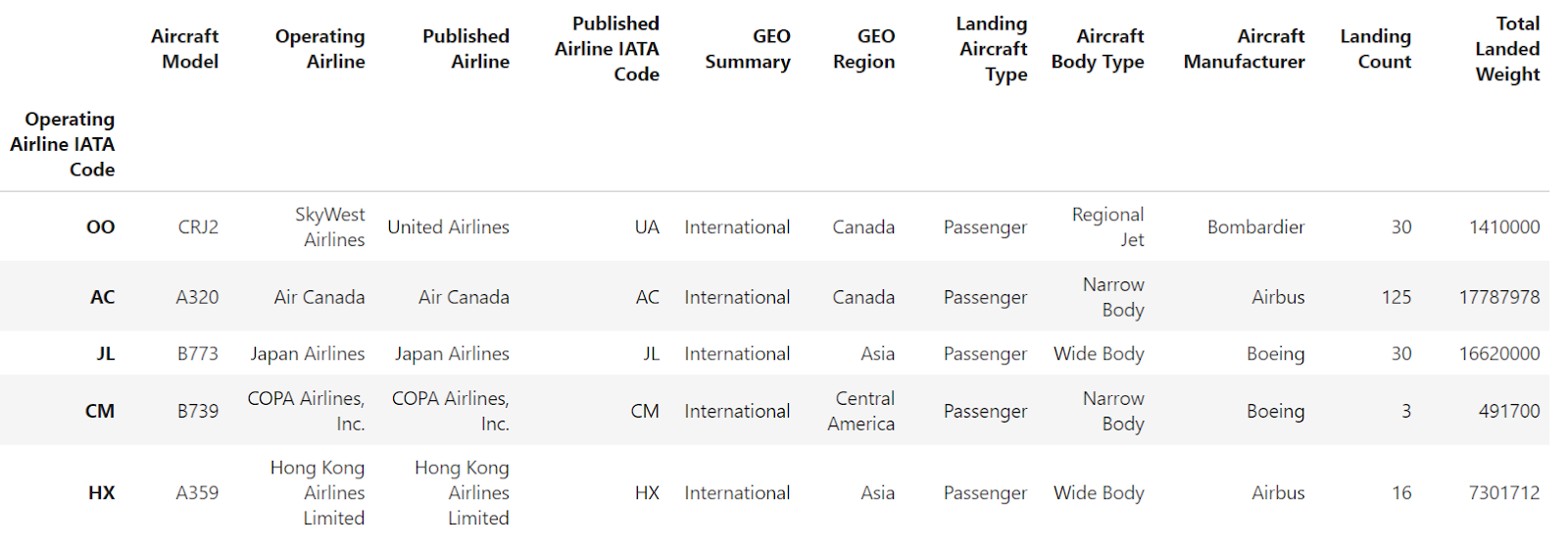
Ahora, utilicemos el método pandas reset_index() que elimina todos los niveles de un Multiíndice:
df.reset_index()
Puedes ver que ambos niveles del Multiíndice se convierten en columnas comunes del Marco de datos, mientras que el índice se restablece al predeterminado basado en enteros.
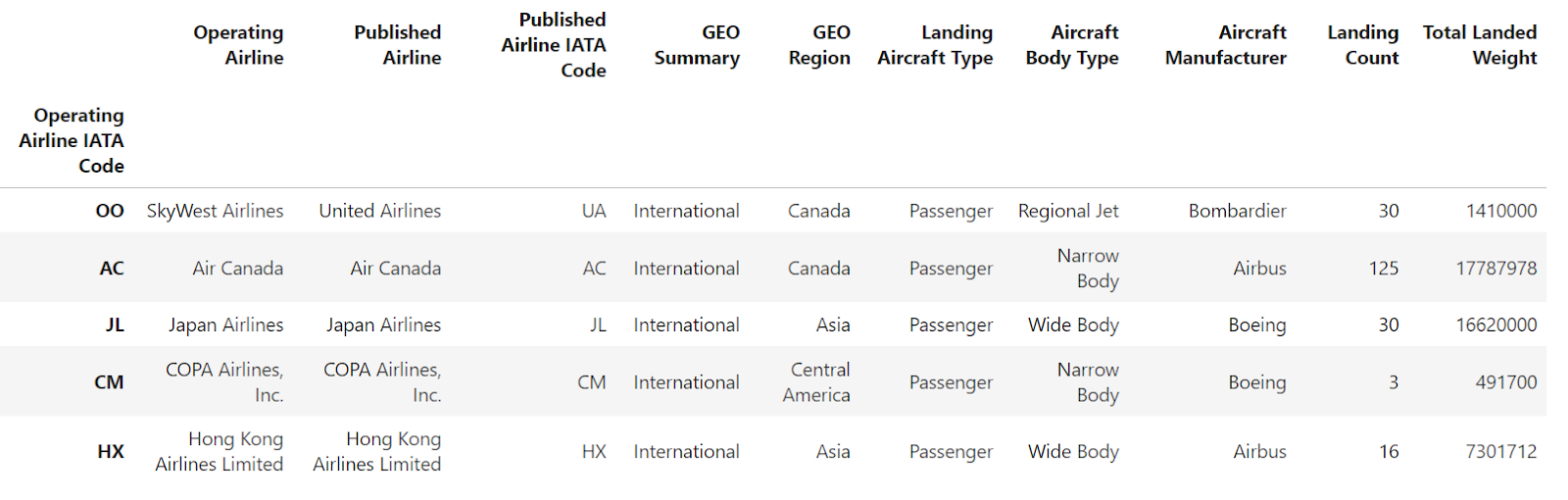
También puedes utilizar el parámetrolevel para eliminar los niveles seleccionados del índice del Marco de datos. Convierte los niveles seleccionados en columnas comunes del DataFrame, a menos que elijas eliminar completamente esta información del DataFrame mediante el parámetro drop. Echémosle un vistazo:
df.reset_index(level=["Aircraft Model"])
La imagen anterior muestra que "Modelo de avión" es ahora una columna normal en el Marco de datos. Sólo queda como índice "Código IATA de la compañía aérea operadora".
Ahora bien, si no quieres que el índice descrito en la lista se convierta en una columna normal, puedes combinar el botón soltar y nivel para eliminarlo del Marco de datos.
df.reset_index(level=["Aircraft Model"], drop=True)
El índice "Modelo de avión" se ha eliminado del índice y del Marco de datos. El otro índice, "Código IATA de la compañía aérea operadora", se ha mantenido como índice actual del Marco de datos.
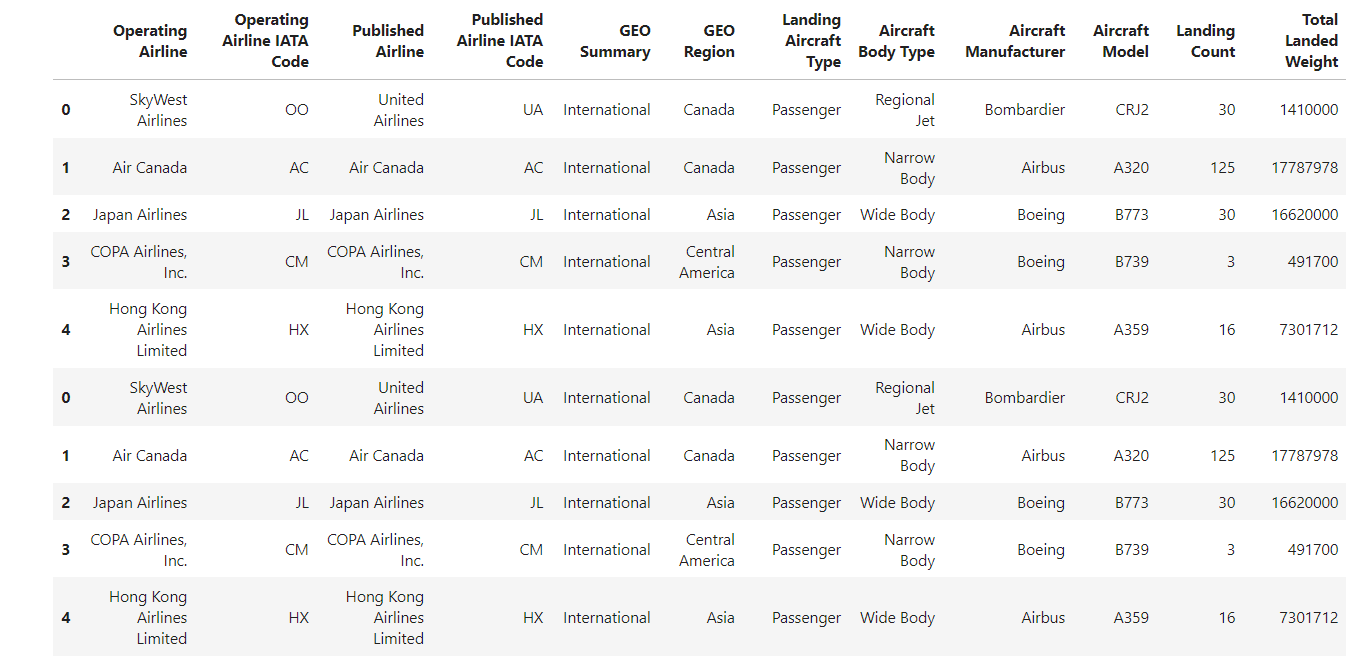
Supón que fusionas dos DataFrame; el DataFrame fusionado resultante ya no tendrá índices secuenciales, como se muestra en el DataFrame siguiente.
Vamos a restablecer el índice del DataFrame utilizando el método reset_index() de pandas.
df.reset_index()
El drop determina si se mantiene el índice antiguo como columna en el DataFrame después de restablecer el índice o si se elimina por completo. Por defecto (drop=False), se mantiene el índice antiguo, como se ha demostrado en todos los ejemplos anteriores. Alternativamente, si estableces drop=True, eliminarás el índice antiguo del DataFrame después de reiniciarlo.
df.reset_index(drop=True)
Modifica el DataFrame en su lugar utilizando el parámetro inplace para evitar crear un nuevo Marco de datos.
Supón que tienes el siguiente Marco de Datos:
Establecer el parámetro inplace a True garantiza que los cambios se apliquen directamente al Marco de Datos original, evitando la creación de un Marco de Datos distinto.
df_concat.reset_index(drop=True, inplace=True)
df_concat
Gestiona los índices duplicados restableciendo y reindexando adecuadamente.
Supón que tienes los datos con índices duplicados.
Utilizando reset_index() con drop=True y inplace=True garantiza que el DataFrame resultante tendrá índices continuos, empezando por 0 e incrementándose secuencialmente.
df.reset_index(drop=True, inplace=True)
inplace=False si esperas que se modifique el DataFrame original. Si inplace se establece en False, se devuelve un nuevo Marco de datos y el Marco de datos original permanece inalterado.drop para evitar la pérdida involuntaria de datos. Si eliminas el índice, los valores actuales del índice desaparecerán permanentemente.Apliquemos lo que hemos aprendido sobre restablecer el índice del Marco de datos y veamos cómo puede ser útil restablecer el índice del Marco de datos al eliminar valores perdidos.
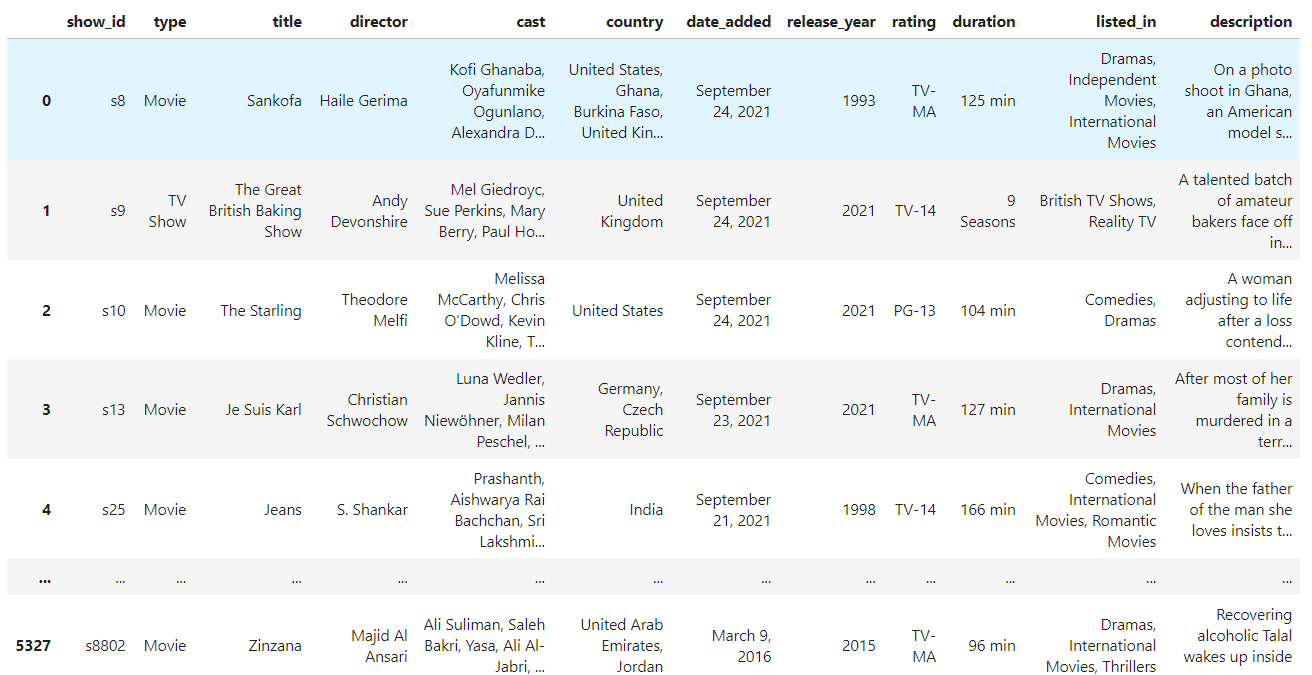
Nuestro conjunto de datos de aerolíneas no tiene valores perdidos, así que vamos a utilizar la función Películas y programas de TV de Netflix de Netflix. Tiene valores perdidos, perfectos para demostrar reset_index().
import pandas as pd
df = pd.read_csv("netflix_shows.csv")
df.head()
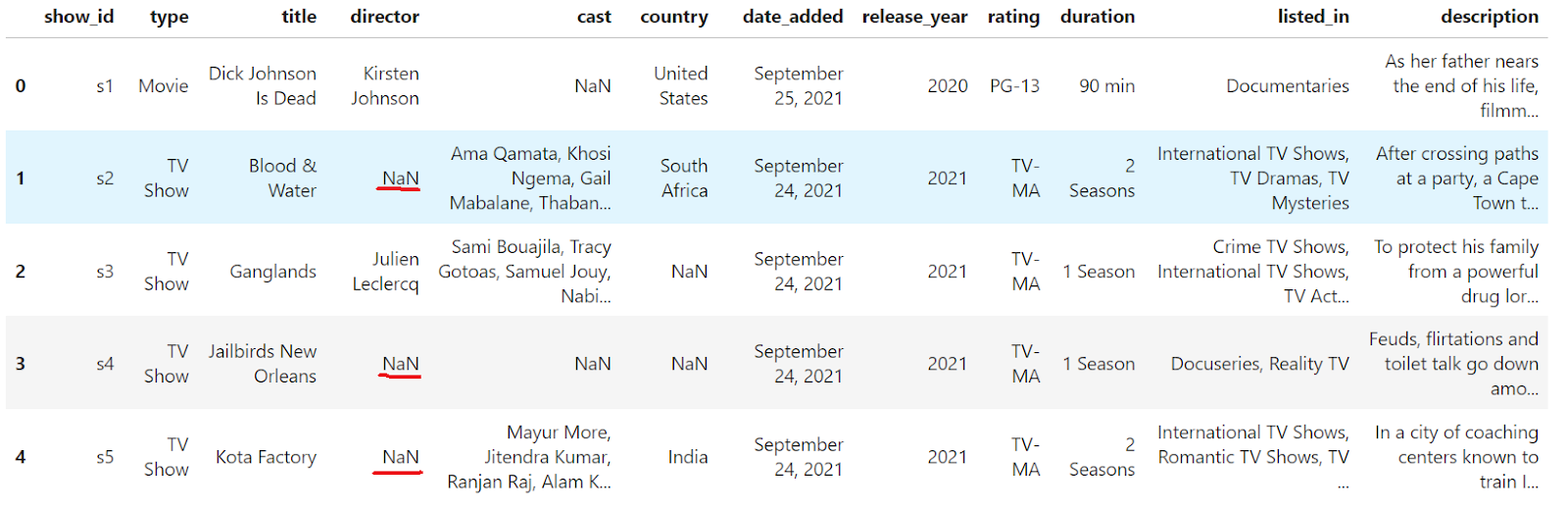
Puedes ver que faltan valores en el Marco de datos. Elimina las filas que contengan valores perdidos utilizando el método dropna().
df.dropna(inplace=True)
df.head()
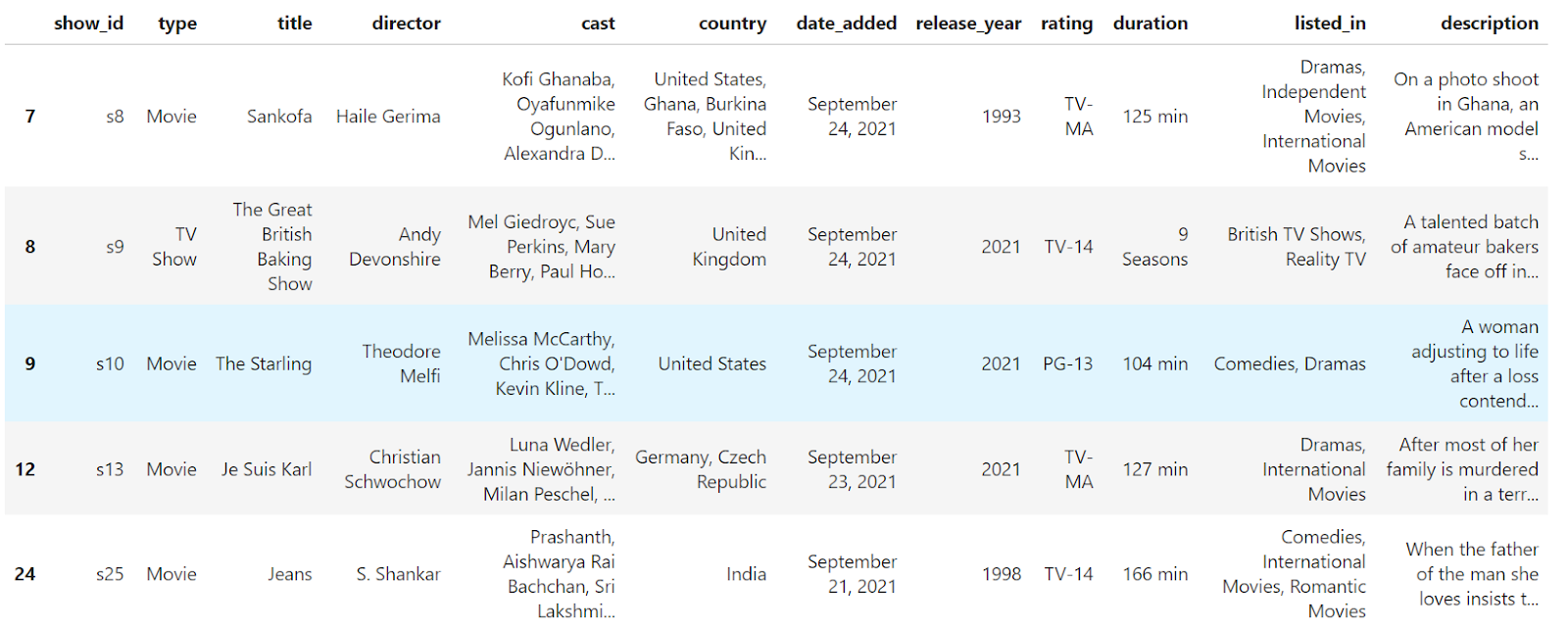
Se han eliminado del DataFrame las filas que contenían valores NaN. Sin embargo, el índice ya no es continuo (0, 1, 2, 4). Vamos a reajustarlo:
df.reset_index()
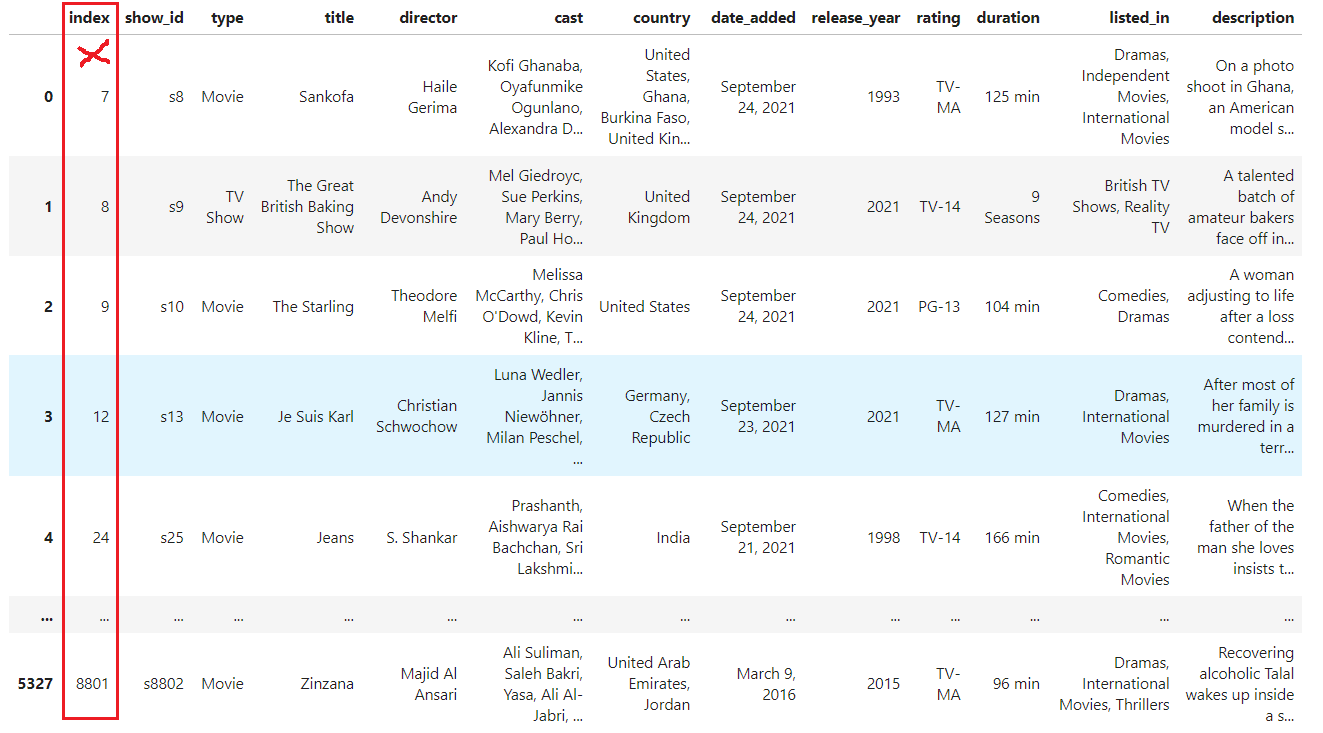
Ahora, el índice es continuo; sin embargo, como no pasamos explícitamente el parámetro drop, el índice antiguo se convirtió en una columna con el nombre por defectoindex. Vamos a eliminar completamente el índice antiguo del Marco de datos:
df.reset_index(drop=True)
Hemos eliminado por completo el antiguo índice sin sentido, y el índice actual es ahora continuo. El paso final es guardar estas modificaciones en nuestro DataFrame original utilizando el parámetro inplace:
df.reset_index(drop=True, inplace=True)Has aprendido cómo funciona la función reset_index en Pandas gestiona eficazmente DataFrame índices. Tanto si manejas datos filtrados, DataFrames concatenados o una compleja indexación multinivel, reset_index garantiza un DataFrame limpio y organizado. Sus parámetros ayudan a gestionar diversos escenarios de indexación en las tareas de manipulación de datos.
Sigue aprendiendo a utilizar funciones similares a reset_index con la carrera de Analista de Datos con Python.
Top pandas Cursos
Curso
Curso
Curso
Tutorial
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
DataCamp Team
