
Course
Streamlined Data Ingestion with pandas
4 hr
62.7K
After manipulating and filtering a large dataset, you might end up with the precise DataFrame required. However, this DataFrame retains the original index, which can be non-sequential. In such cases, you need to reset the index of the DataFrame.
In this tutorial, we'll discuss the pandas reset_index() method, which is used to reset the index of a DataFrame. We will explore the different options available with this method. Additionally, we'll cover how to reset the index for simple and multi-level DataFrame.
To practice DataFrame index resetting, we'll use an airline dataset. We will use Datacamp’s Datalab, an interactive environment specifically designed for data analysis in Python, making it a perfect tool to follow along with this tutorial.
The reset_index method in Pandas resets the index of a DataFrame to the default one. After operations like filtering, concatenation, or merging, the index may no longer be sequential. This method helps re-establish a clean, sequential index. If the DataFrame has a MultiIndex, it can remove one or more levels.
Basic syntax:
df.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill="")Parameters:
Returns:
DataFrame with the new index or None if inplace=True.
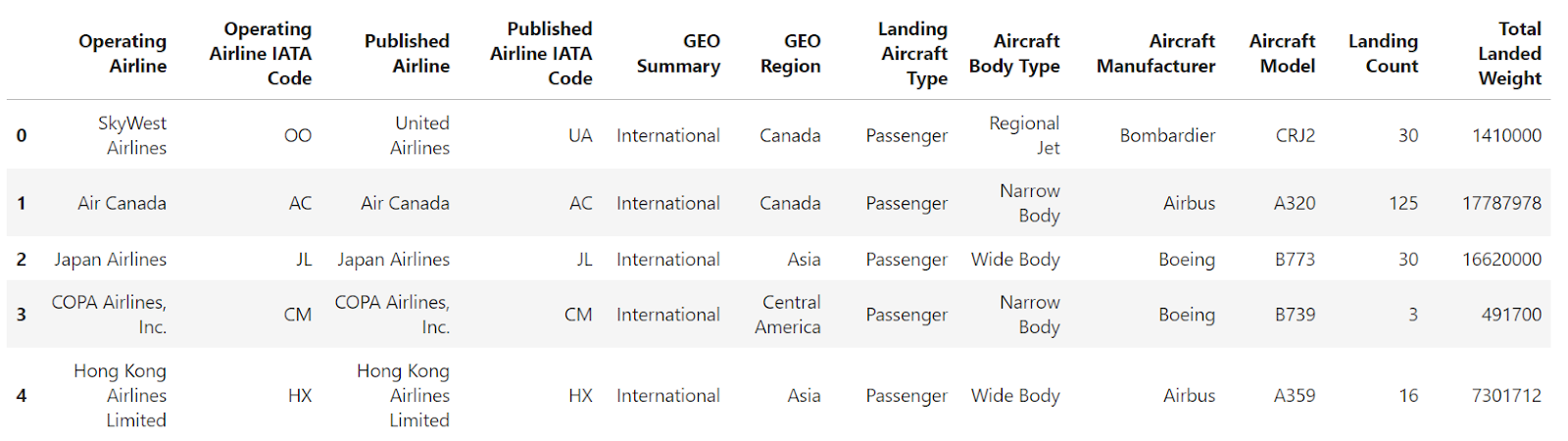
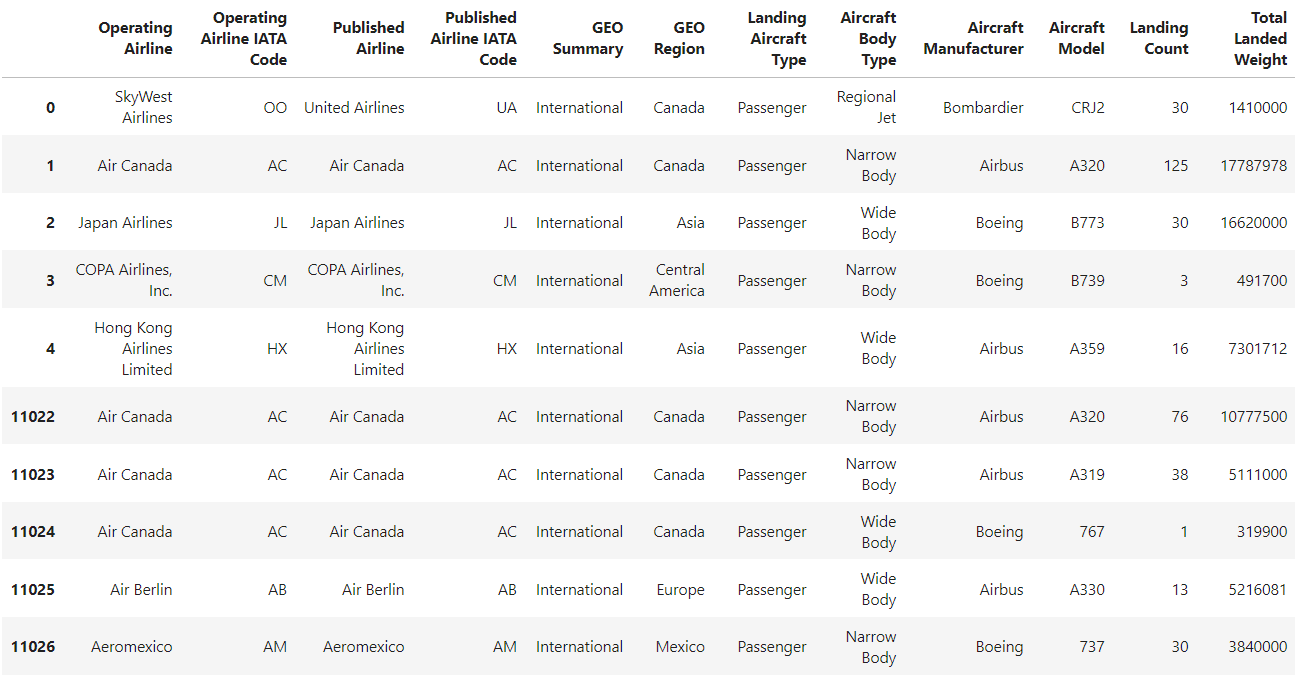
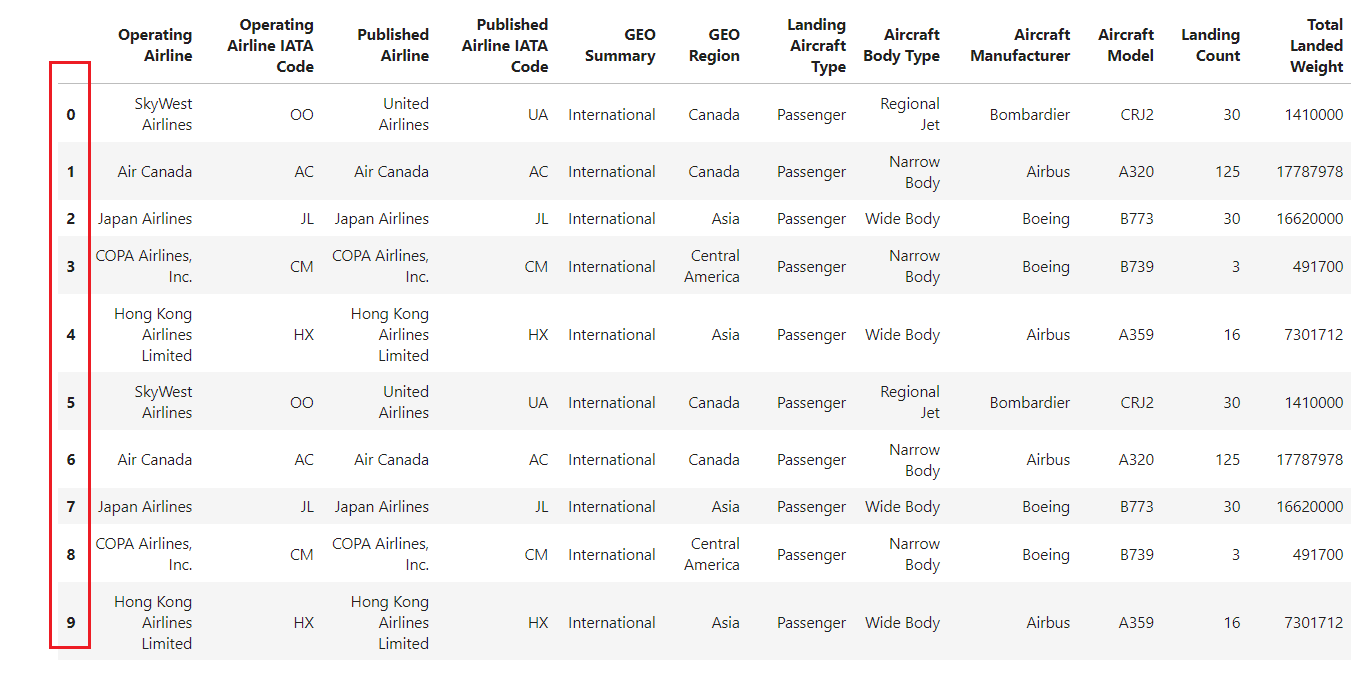
If you read a CSV file using the pandas read_csv() method without specifying an index, the resulting DataFrame will have a default integer-based index starting from 0 and increasing by 1 for each subsequent row.
import pandas as pd
df = pd.read_csv("airlines_dataset.csv").head()
df
In some cases, you might prefer more descriptive row labels. To achieve this, you can set one of the DataFrame's columns as its index (row labels). When using the read_csv() method to load data from a CSV file, specify the desired column for the index using the index_col parameter.
import pandas as pd
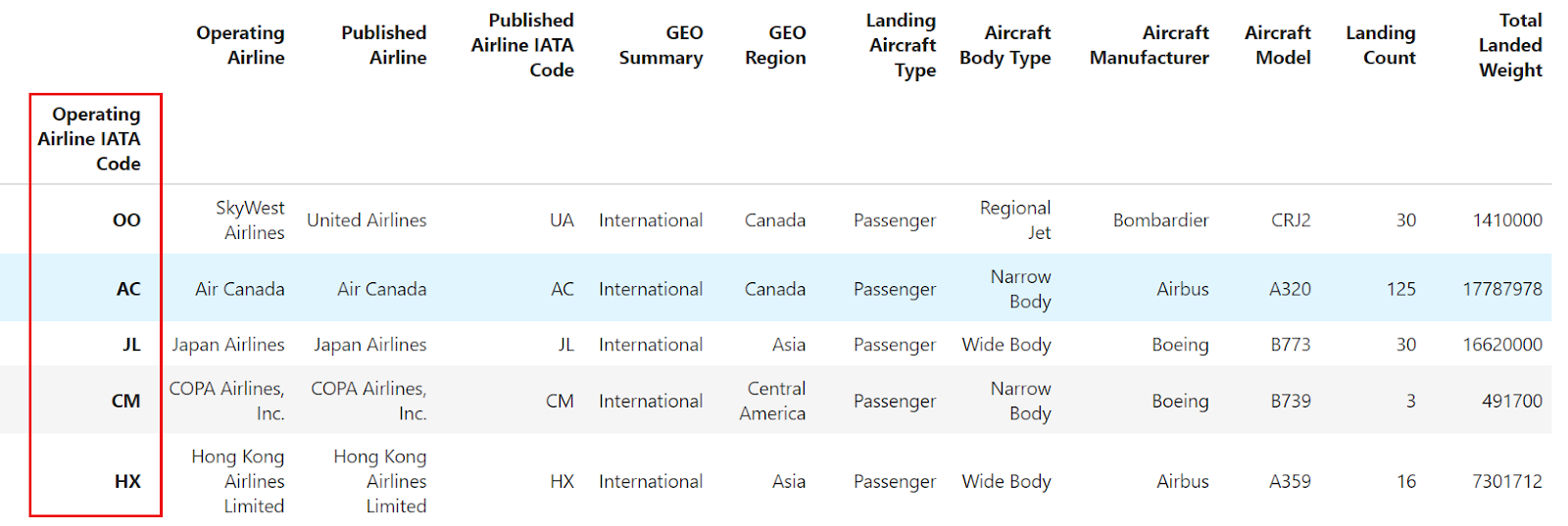
df = pd.read_csv("airlines_dataset.csv", index_col="Operating Airline IATA Code").head()
df
Alternatively, you can use the set_index() method to set any column of a DataFrame as the index:
import pandas as pd
df = pd.read_csv("airlines_dataset.csv").head()
df.set_index("Operating Airline IATA Code", inplace=True)
dfNote that the code snippet will make changes to the original DataFrame.
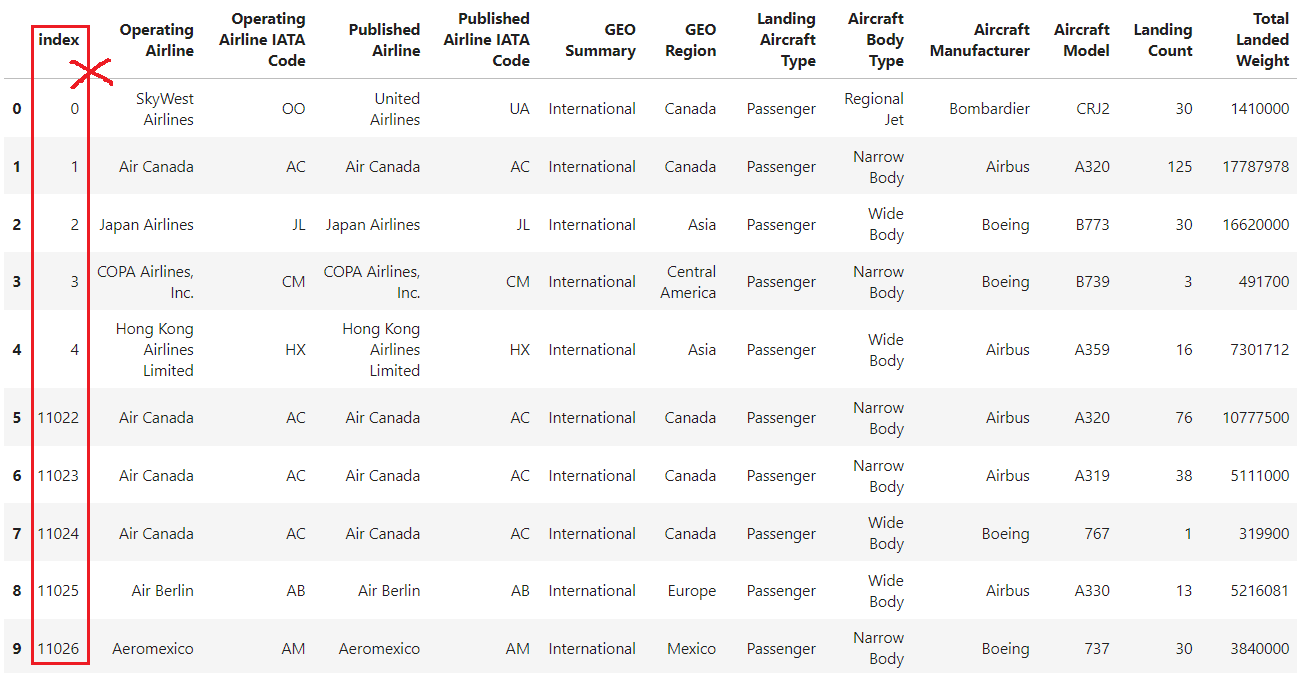
What If you need to restore the default numeric index? This is where the reset_index() Pandas method comes in.
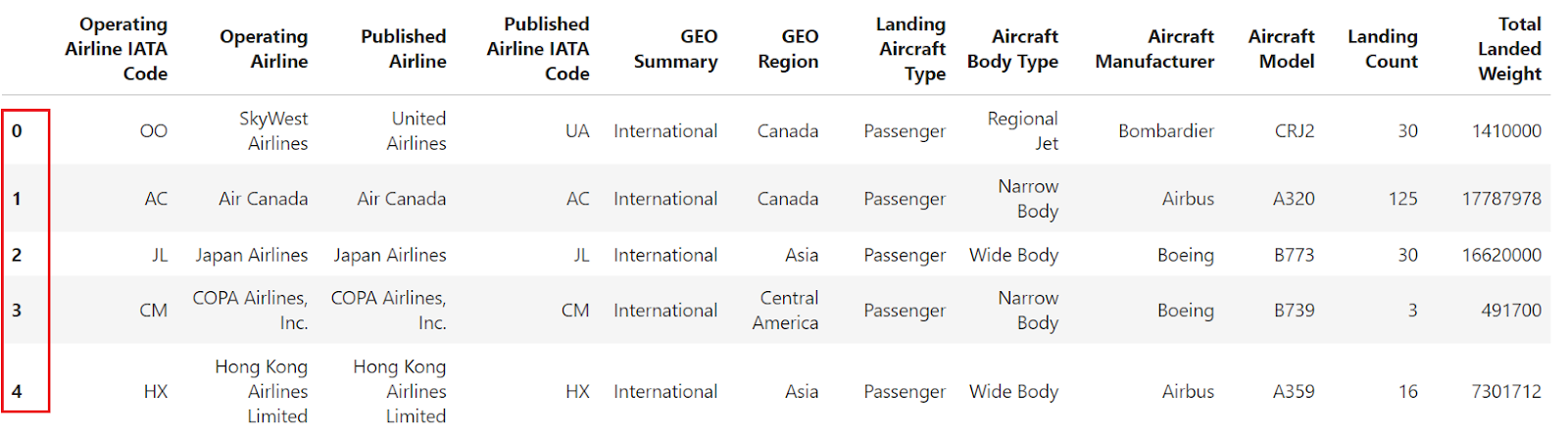
df.reset_index()
The example shows that, after setting column 'Operating Airline IATA Code' as the index, reset_index is used to revert the DataFrame to its default integer index.
The reset_index() method in Pandas is a powerful tool for reorganizing DataFrame indices when you are dealing with filtered datasets, concatenated DataFrames, or multi-level indexes.
Learn more about reshaping DataFrames from a wide to long format, how to stack and unstack rows and columns, and how to wrangle multi-index DataFrames in our online course.
When you filter a DataFrame, the original index is preserved. Using reset_index, you can reindex the filtered DataFrame.
import pandas as pd
df = pd.read_csv("airlines_dataset.csv")Let's filter the data to select only the rows where the "landing count" is greater than 1000. After filtering, the indices may not be sequential. Then, you can use the reset_index method to reset the index of the filtered DataFrame.
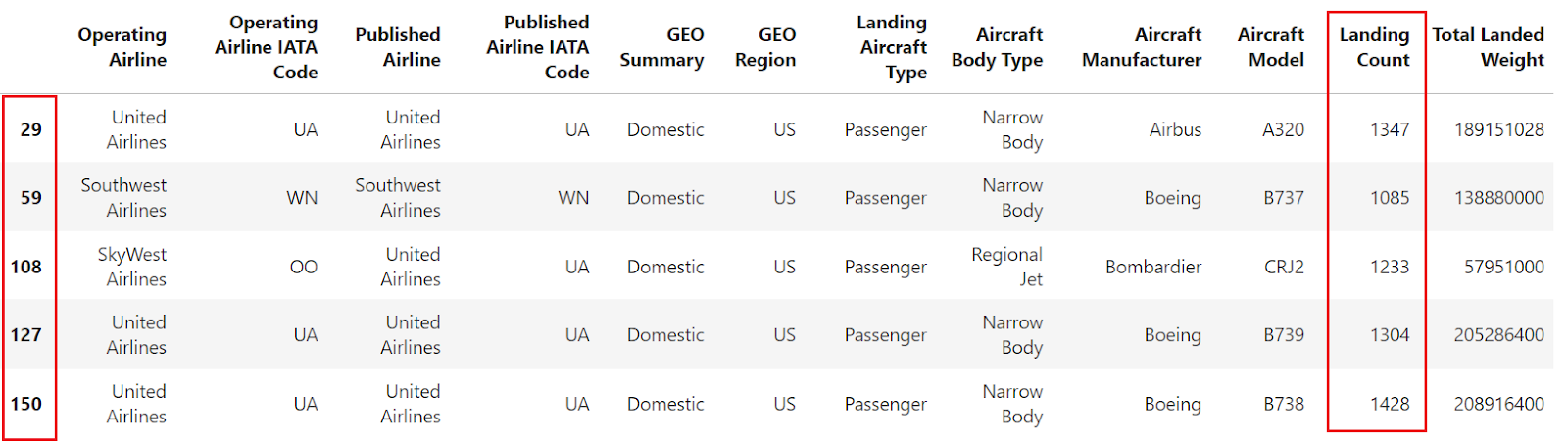
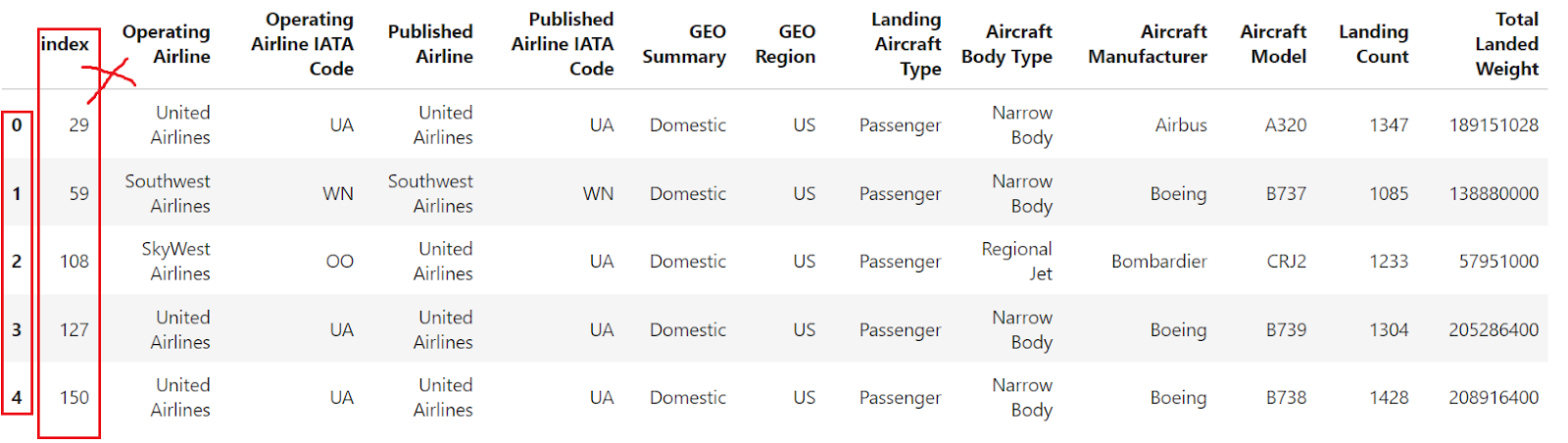
filtered_df = df[df["Landing Count"] > 1000].head()
filtered_df
The above image shows that the data frame is filtered based on the applied condition, but the index is not sequential. Now, let's use reset_index to reindex the filtered DataFrame and ensure a sequential index. Here's how you can do that:
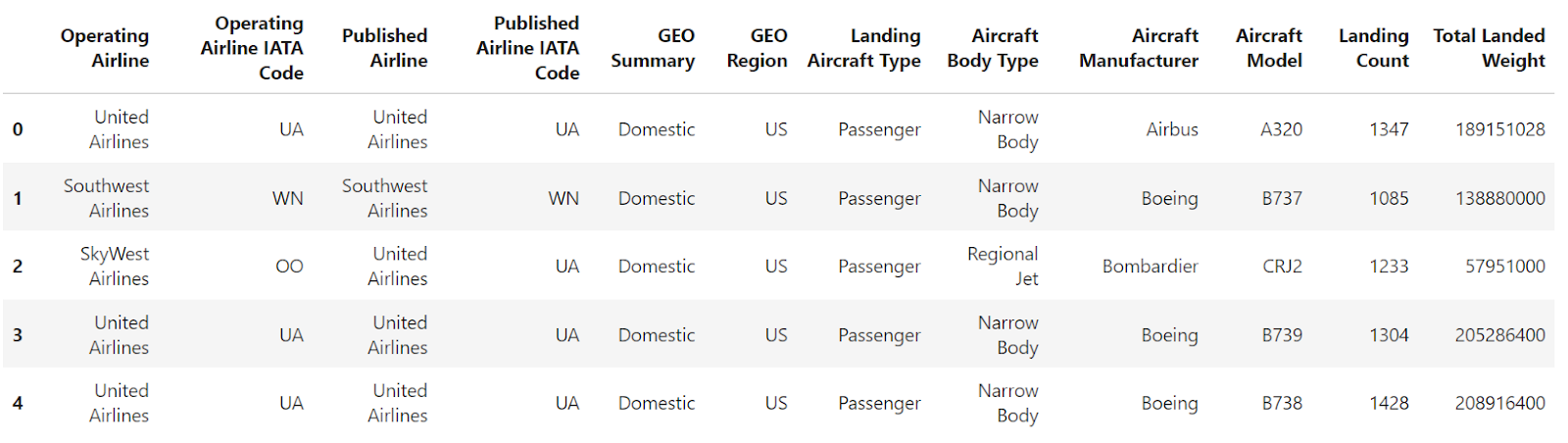
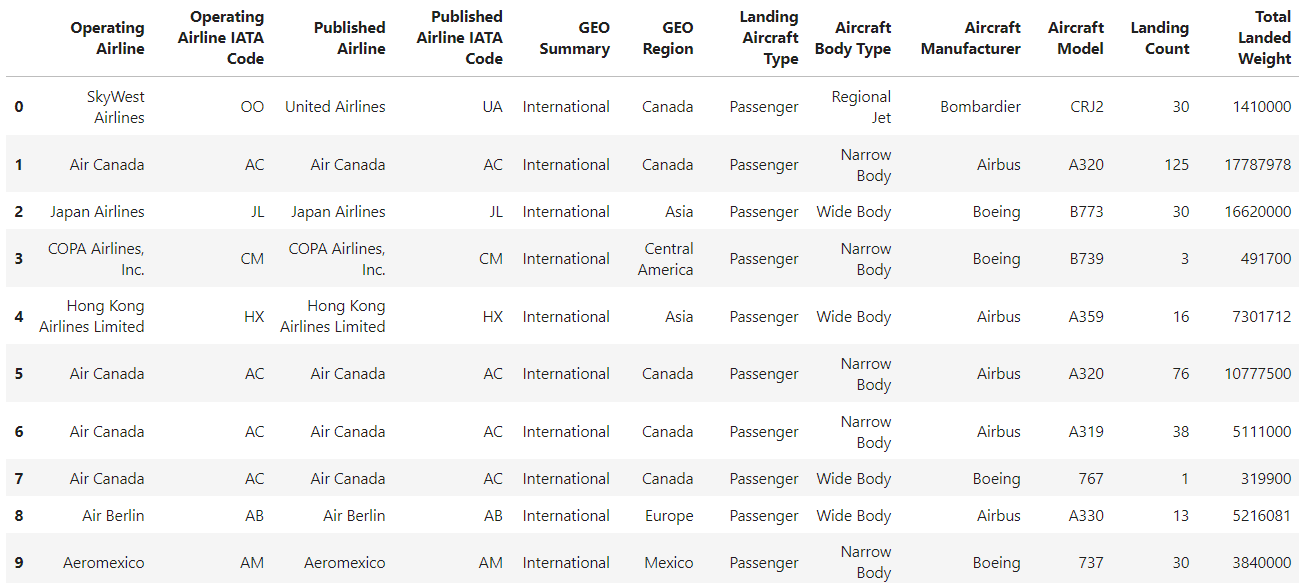
filtered_df_reset = filtered_df.reset_index()
filtered_df_reset
The default behavior of this method includes replacing the existing DataFrame index with a default integer-based one and converting the old index into a new column with the same name (or "index" if it was unnamed).
So, use the parameter drop=True, which ensures the old index is not added as a new column.
filtered_df_reset = filtered_df.reset_index(drop=True)
filtered_df_reset
Great! The indices are now reset to the default integer index (0, 1, 2, …), providing a clean and sequential index.
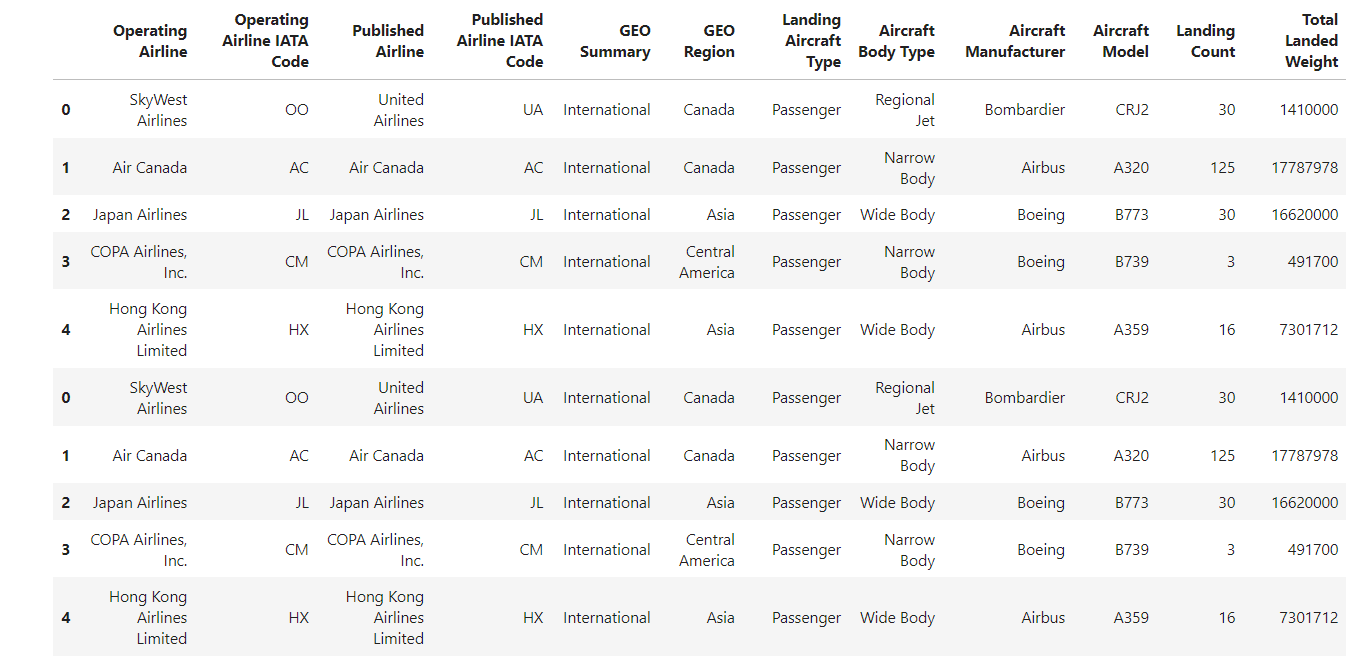
When combining DataFrames, the resulting DataFrame might contain duplicate or non-sequential indices. Resetting the index creates a clean, sequential index.
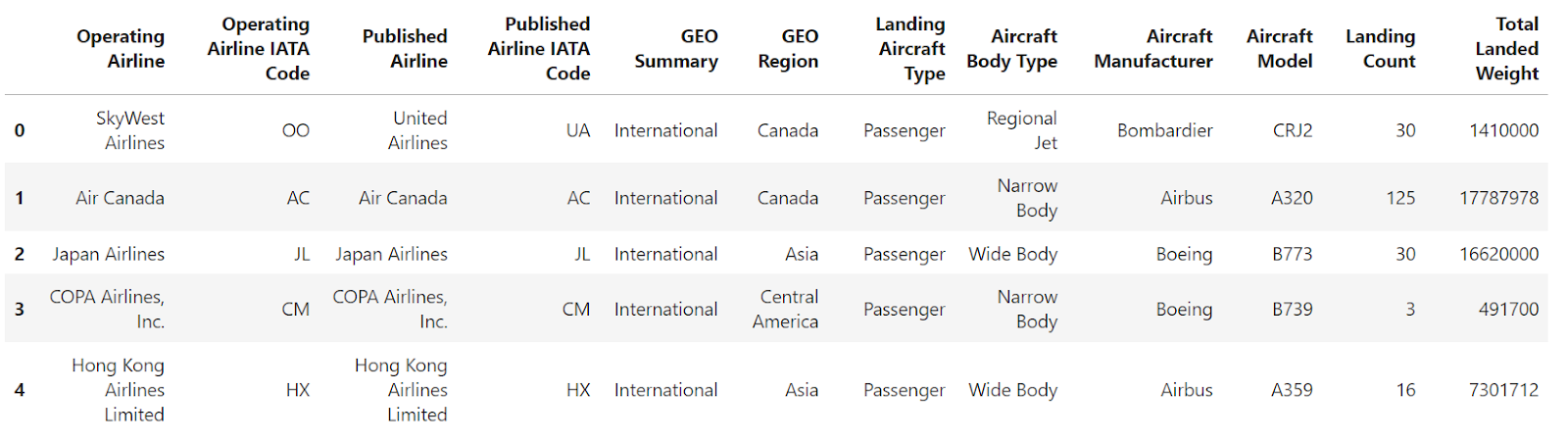
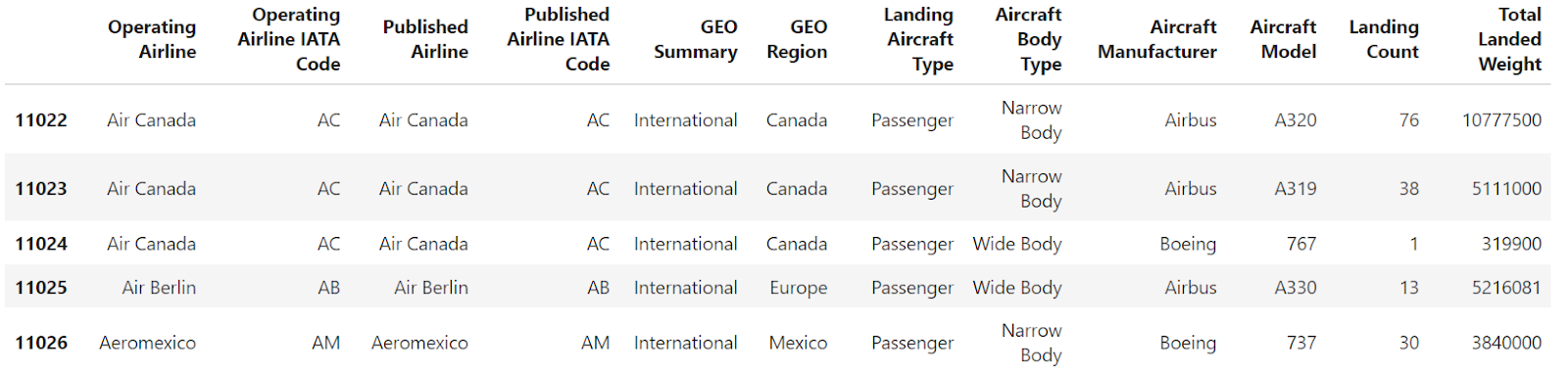
Suppose you have two DataFrames, and you want to concatenate them. I’ve created two DataFrames from the airlines' dataset for demonstration purposes.
import pandas as pd
df = pd.read_csv("airlines_dataset.csv")
split_index = int(df.shape[0] / 2)
df1 = df[:split_index].head()
df2 = df[split_index:].head()Here’s df1:
Here’s df2:
Let's concatenate the DataFrames df1 and df2.
df_concat = pd.concat([df1, df2])
The data shows non-sequential indices. We need to reset the index of the concatenated DataFrame to make it sequential.
Let's reset the index of the DataFrame using the reset_index() method in pandas.
df_concat.reset_index()
Here’s what the result looks like after resetting the index of the DataFrame. The reset_index method converts the old index into a new column. To remove this extra column, you need to use the drop=True parameter.
df_concat.reset_index(drop=True)
For DataFrames with hierarchical (multi-level) indexing, reset_index can be used to simplify the DataFrame by converting the multi-level index back into columns.
Let's look at an example of a DataFrame with a multi-level index.
import pandas as pd
df = pd.read_csv(
"airlines_dataset.csv", index_col=["Aircraft Model", "Operating Airline IATA Code"]
).head()
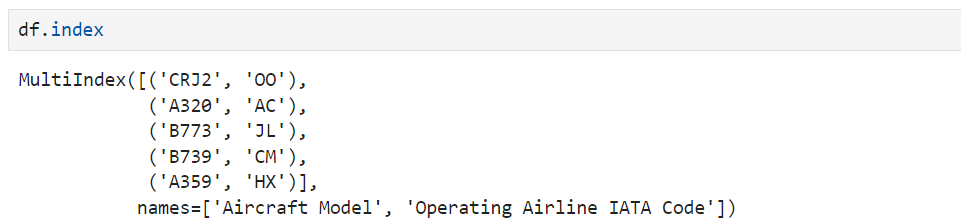
If you check its index, you'll see that it isn't a common DataFrame index but a MultiIndex object
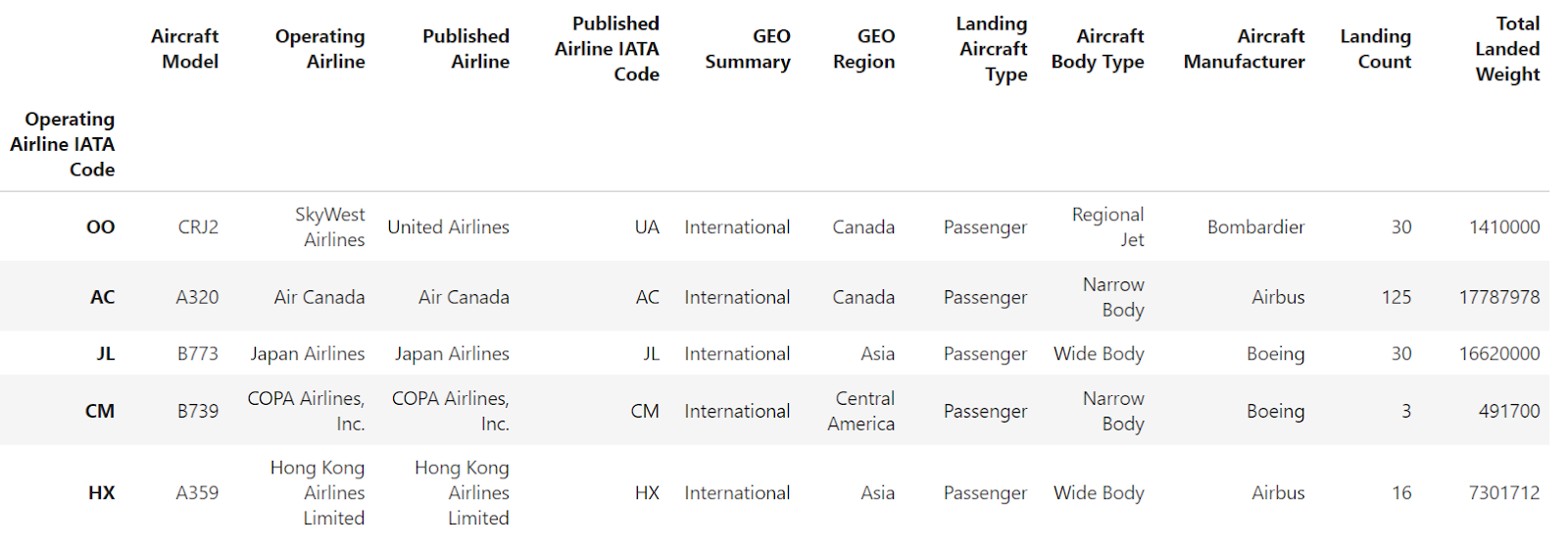
Now, let’s use the pandas reset_index() method, which removes all levels of a MultiIndex:
df.reset_index()
You can see that both levels of the MultiIndex are converted into common DataFrame columns while the index is reset to the default integer-based one.
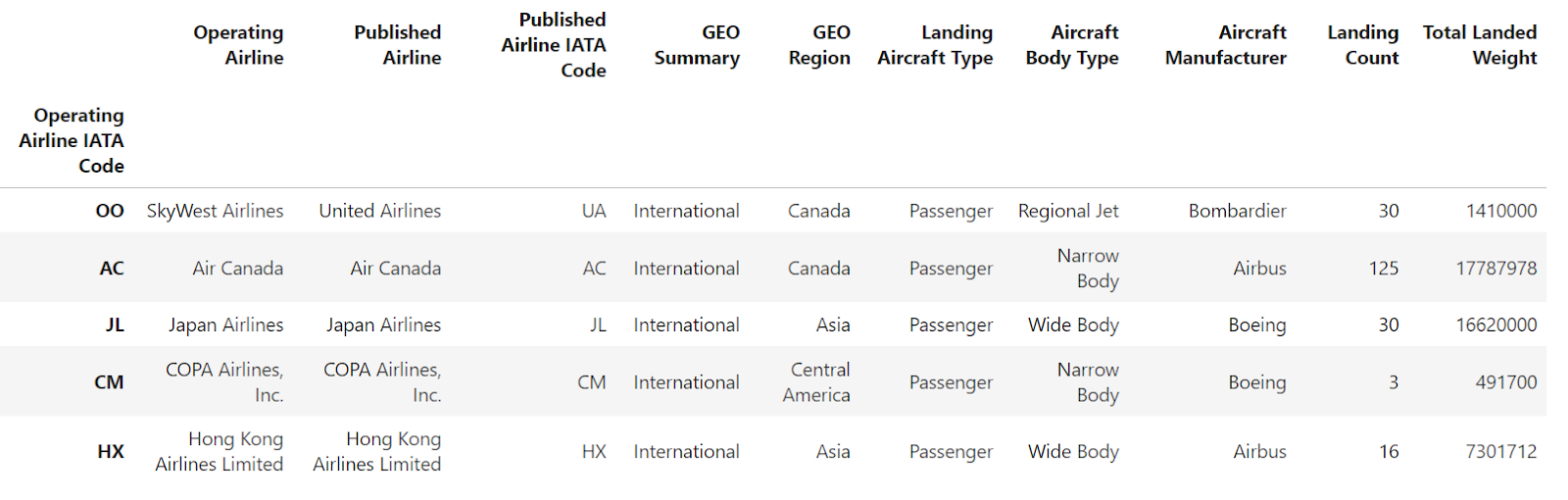
You can also use the level parameter to remove selected levels from the DataFrame index. It converts the selected levels into common DataFrame columns unless you choose to drop this information completely from the DataFrame using the drop parameter. Let's take a look at it:
df.reset_index(level=["Aircraft Model"])
The above image shows that "Aircraft Model" is now a regular column in the DataFrame. Only "Operating Airline IATA Code" remains as the index.
Now, if you don't want the index described in the list to become a regular column, you can combine the drop and level parameters to drop it from the DataFrame.
df.reset_index(level=["Aircraft Model"], drop=True)
The index 'Aircraft Model' has been removed from the index and the DataFrame. The other index, 'Operating Airline IATA Code', has been retained as the current index of the DataFrame.
Suppose you merge two DataFrames; the resulting merged DataFrame will no longer have sequential indices, as shown in the DataFrame below.
Let's reset the index of the DataFrame using the reset_index() method of pandas.
df.reset_index()
The drop determines whether to keep the old index as a column in the DataFrame after resetting the index or drop it completely. By default (drop=False), the old index is kept, as demonstrated in all the previous examples. Alternatively, setting drop=True removes the old index from the DataFrame after resetting.
df.reset_index(drop=True)
Modify the DataFrame in place using the inplace parameter to avoid creating a new DataFrame.
Suppose you have the below DataFrame:
Setting the inplace parameter to True ensures that the changes are applied directly to the original DataFrame, avoiding the creation of a separate DataFrame.
df_concat.reset_index(drop=True, inplace=True)
df_concat
Manage duplicate indices by resetting and reindexing appropriately.
Suppose you have the data with duplicate indices.
Using reset_index() with drop=True and inplace=True ensures that the resulting DataFrame will have continuous indices, starting from 0 and increasing sequentially.
df.reset_index(drop=True, inplace=True)
inplace=False parameter if you expect the original DataFrame to be modified. If inplace is set to False, a new DataFrame is returned and the original DataFrame remains unchanged.drop parameter to avoid unintentional data loss. Dropping the index will remove the current index values permanently.Let's apply what we've learned about resetting the DataFrame index and see how resetting the DataFrame index can be useful when dropping missing values.
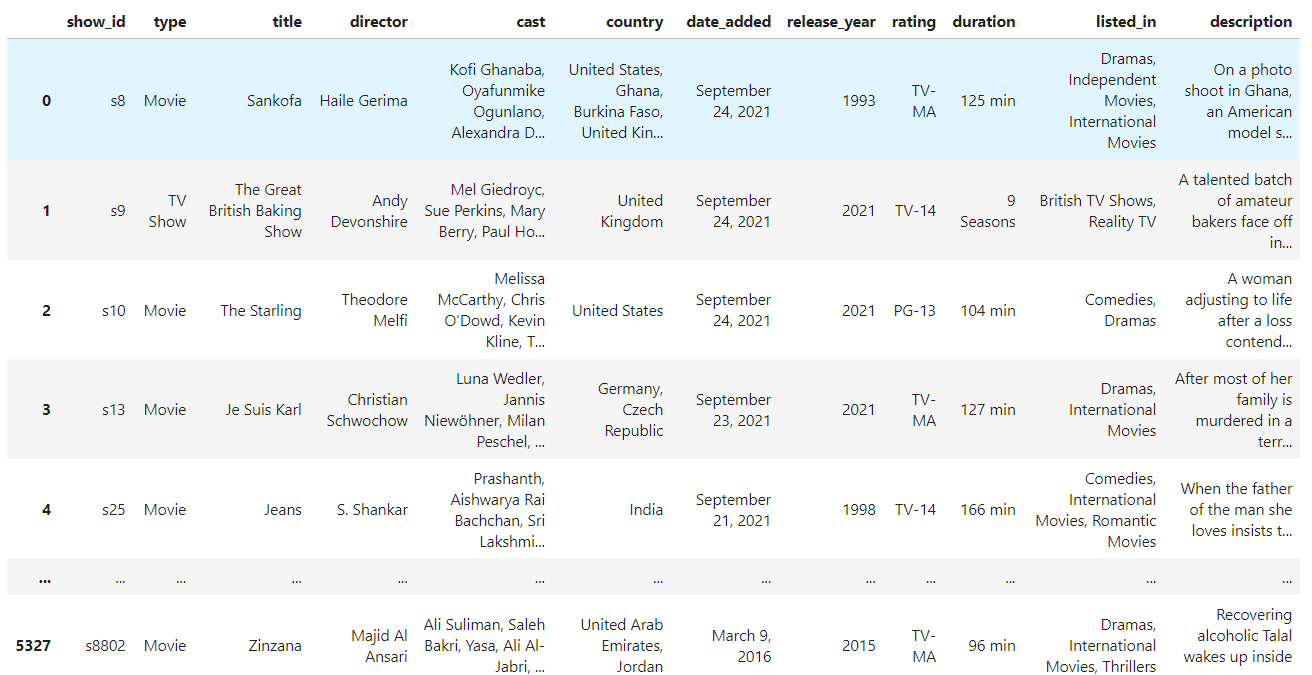
Our airline dataset has no missing values, so let's use the Netflix Movies and TV shows dataset instead. It has missing values, perfect for demonstrating reset_index().
import pandas as pd
df = pd.read_csv("netflix_shows.csv")
df.head()
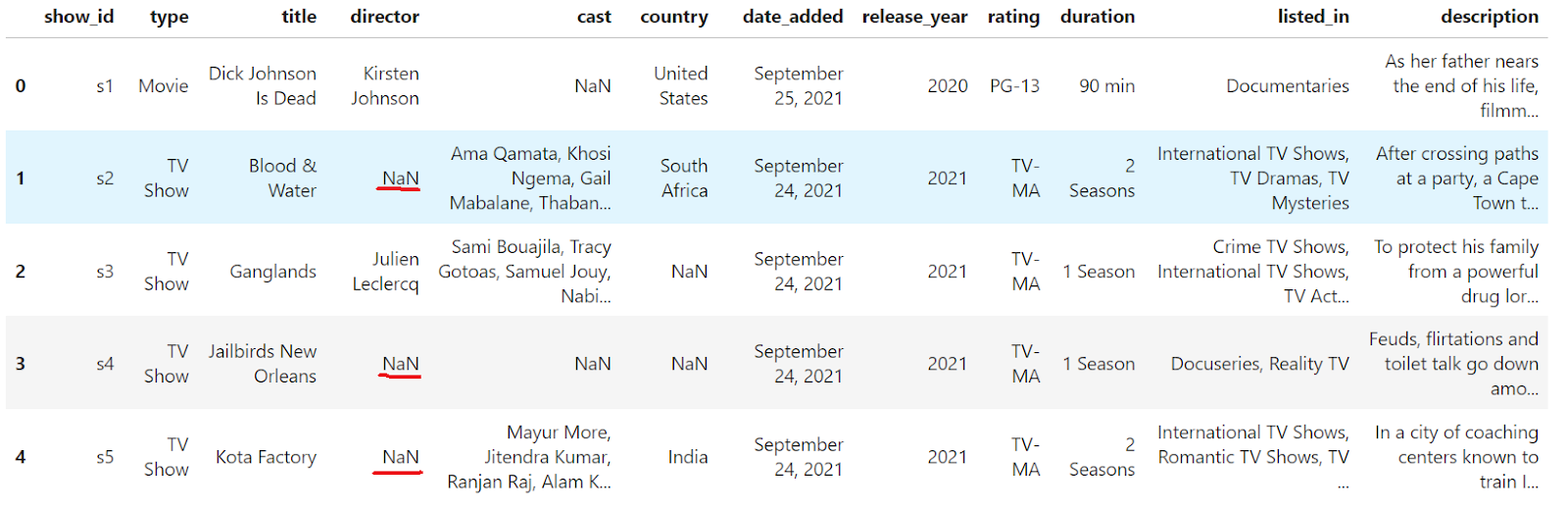
You can see that there are missing values in the DataFrame. Drop rows containing missing values using the dropna() method.
df.dropna(inplace=True)
df.head()
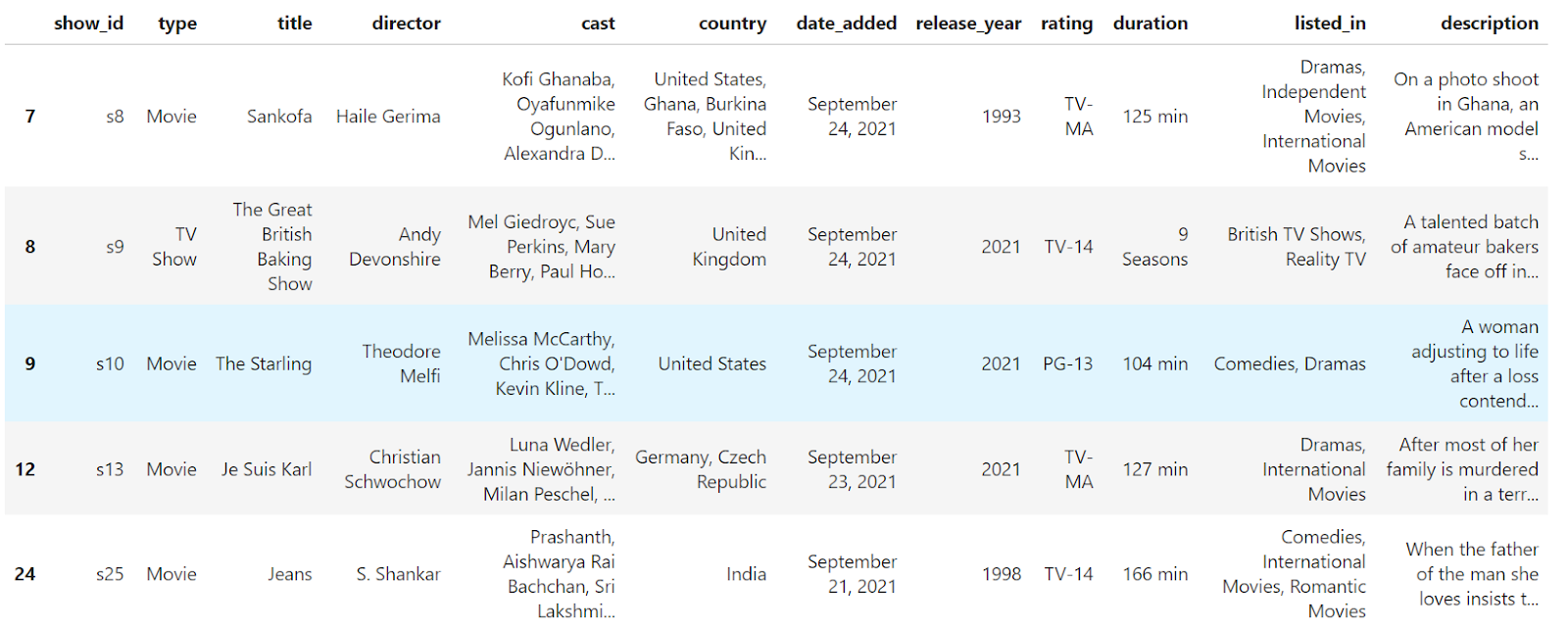
The rows containing NaN values have been removed from the DataFrame. However, the index is no longer continuous (0, 1, 2, 4). Let's reset it:
df.reset_index()
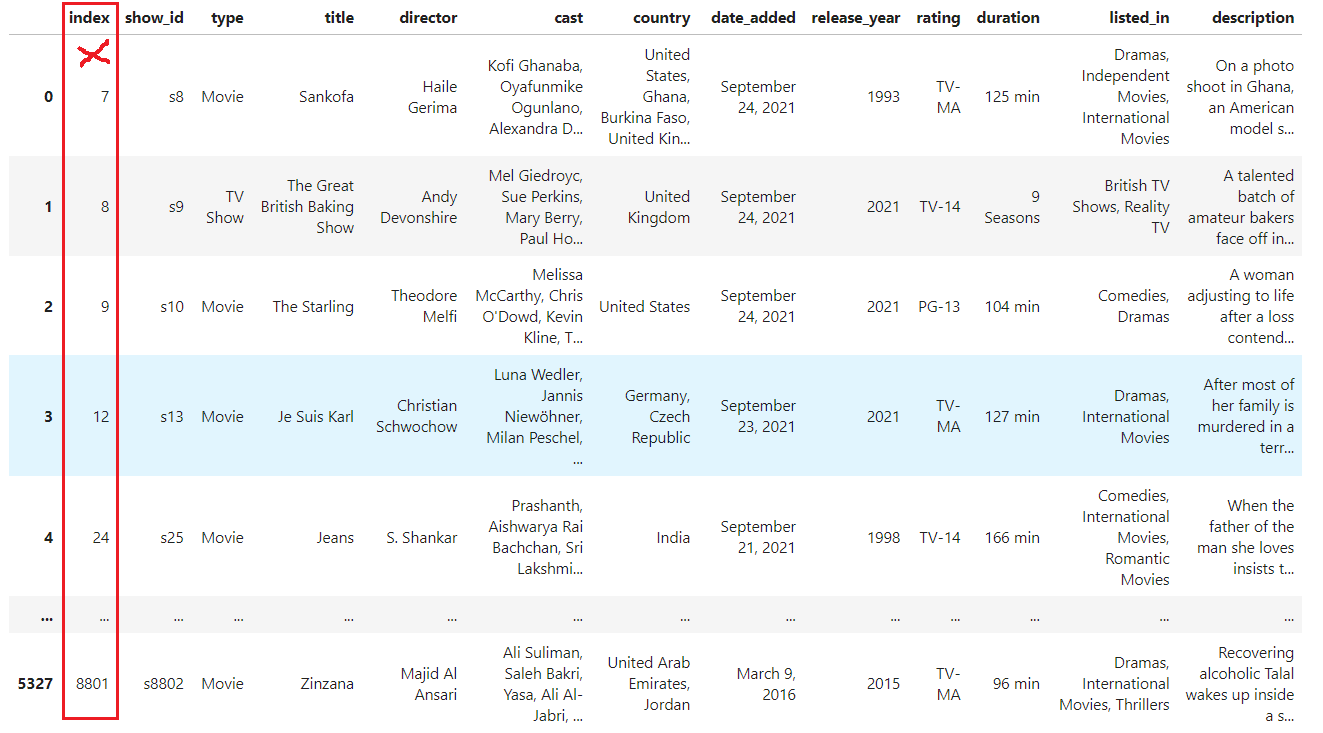
Now, the index is continuous; however, since we didn't explicitly pass the drop parameter, the old index was converted into a column with the default name index. Let's drop the old index completely from the DataFrame:
df.reset_index(drop=True)
We have completely removed the meaningless old index, and the current index is now continuous. The final step is to save these modifications to our original DataFrame using the inplace parameter:
df.reset_index(drop=True, inplace=True)You’ve learned how the reset_index function in Pandas efficiently manages DataFrame indices. Whether handling filtered data, concatenated DataFrames, or complex multi-level indexing, reset_index ensures a clean and organized DataFrame. Its parameters help manage diverse indexing scenarios in data manipulation tasks.
Keep learning to use similar functions to reset_index with DataCamp’s Data Analyst with Python career track. You can also read our Python List Index() Tutorial if you are working with lists and want to learn about the index() function as it applies to lists.
Top pandas Courses
Course
Course
Course
Tutorial
Karlijn Willems
Tutorial
Hugo Bowne-Anderson
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
DataCamp Team
