Curso
Ingestão de dados simplificada com pandas
4 h
62.7K
Depois de manipular e filtrar um grande conjunto de dados, você pode acabar com o DataFrame exato necessário. No entanto, esse DataFrame mantém o índice original, que pode ser não sequencial. Nesses casos, você precisa redefinir o índice do DataFrame.
Neste tutorial, discutiremos o método pandas reset_index(), que é usado para redefinir o índice de um DataFrame. Vamos explorar as diferentes opções disponíveis com esse método. Além disso, abordaremos como redefinir o índice para DataFrame simples e multinível.
Para você praticar a redefinição do índice do DataFrame, usaremos um conjunto de dados de companhias aéreas. conjunto de dados de companhias aéreas. Usaremos o Datalab da Datacamp, um ambiente interativo projetado especificamente para análise de dados em Pythono que o torna uma ferramenta perfeita para você acompanhar este tutorial.
O métodoreset_index do Pandas redefine o índice de um DataFrame para o índice padrão. Após operações como filtragem, concatenação ou mesclagem, o índice pode não ser mais sequencial. Esse método ajuda a restabelecer um índice limpo e sequencial. Se o DataFrame tiver um MultiIndex, você poderá remover um ou mais níveis.
Sintaxe básica:
df.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill="")Parâmetros:
Devoluções:
DataFrame com o novo índice ou None se você não tiver nenhum. inplace=True.
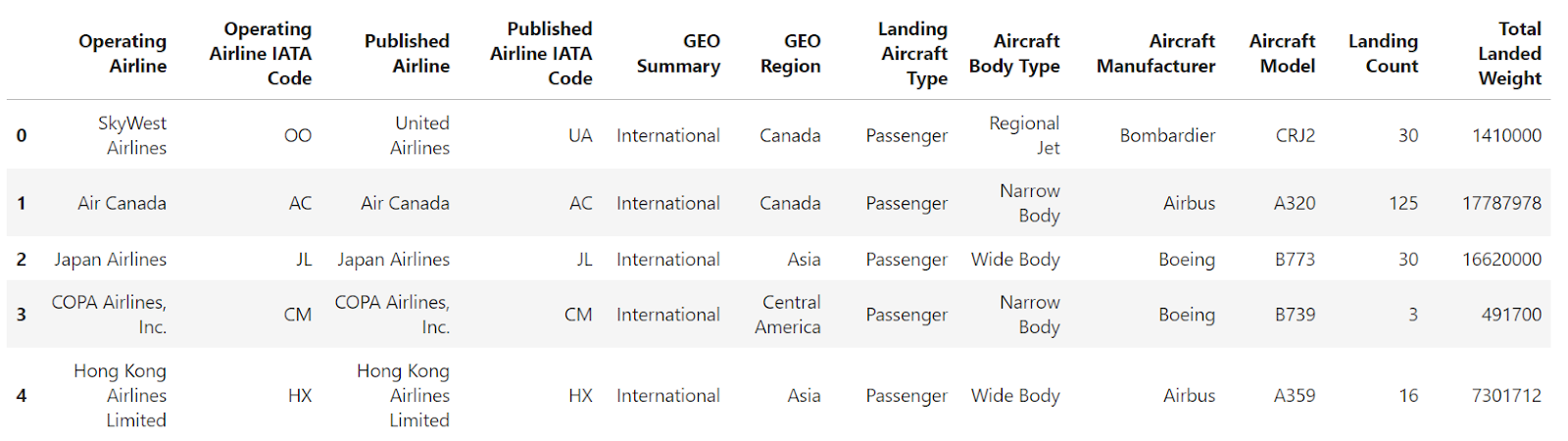
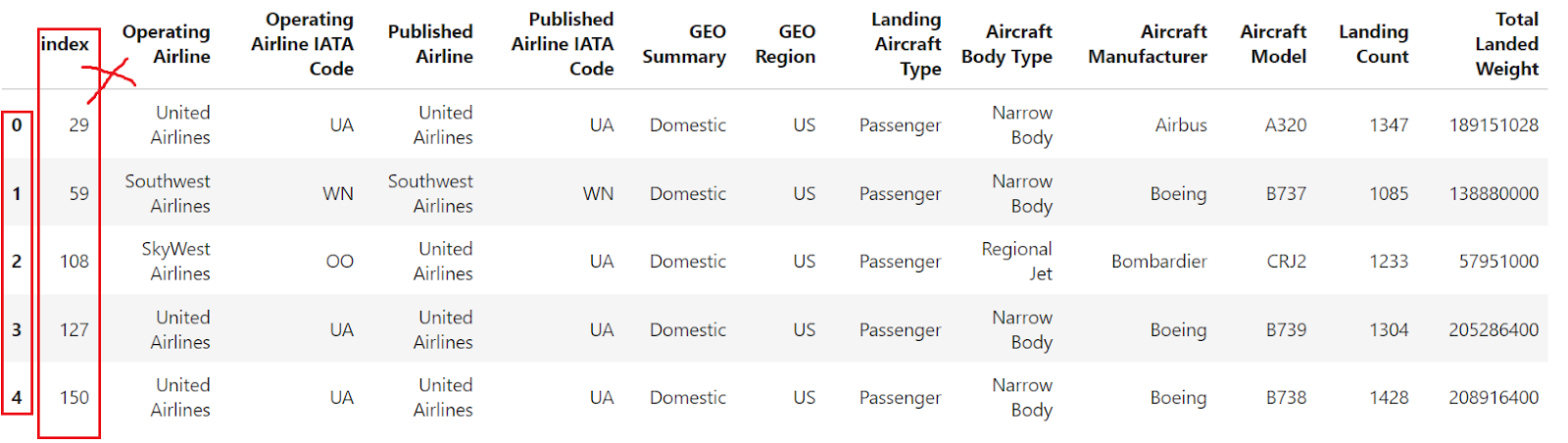
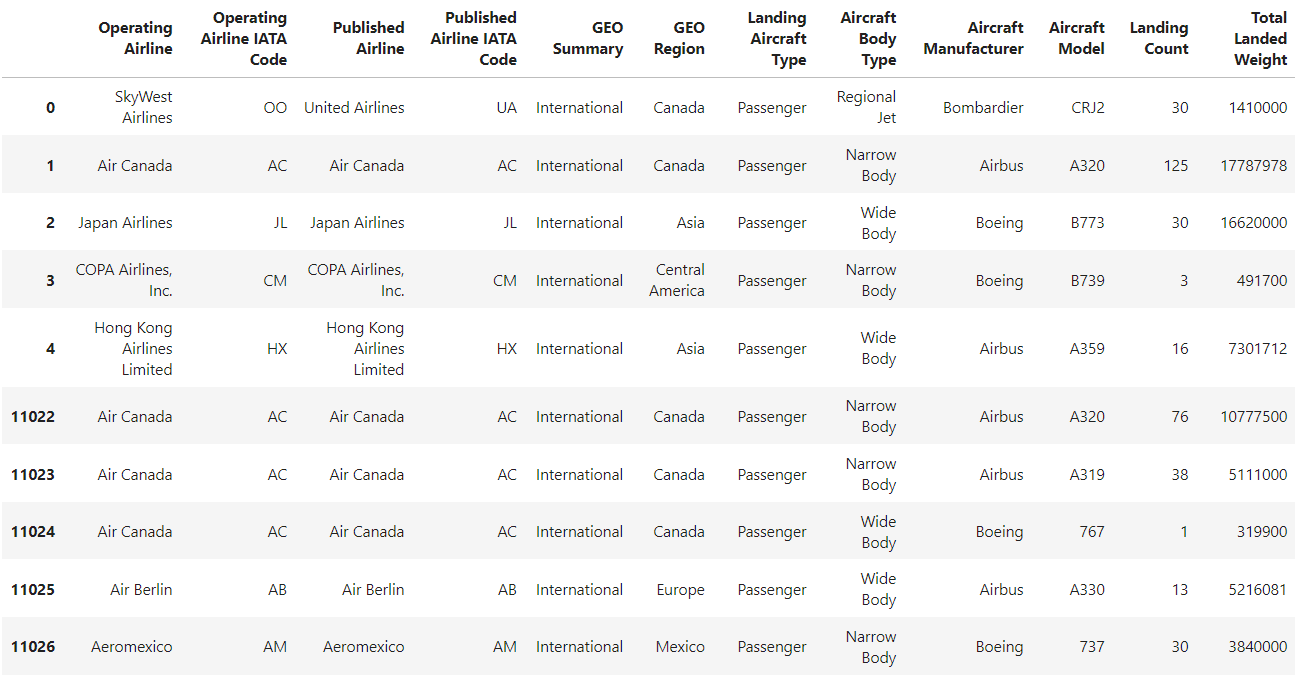
Se você ler um arquivo CSV usando o método pandas read_csv() sem especificar um índice, o DataFrame resultante terá um índice padrão baseado em números inteiros, começando em 0 e aumentando em 1 para cada linha subsequente.
import pandas as pd
df = pd.read_csv("airlines_dataset.csv").head()
df
Em alguns casos, você pode preferir rótulos de linha mais descritivos. Para isso, você pode definir uma das colunas do DataFrame como seu índice (rótulos de linha). Ao usar o método read_csv() para carregar dados de um arquivo CSV, especifique a coluna desejada para o índice usando o parâmetroindex_col.
import pandas as pd
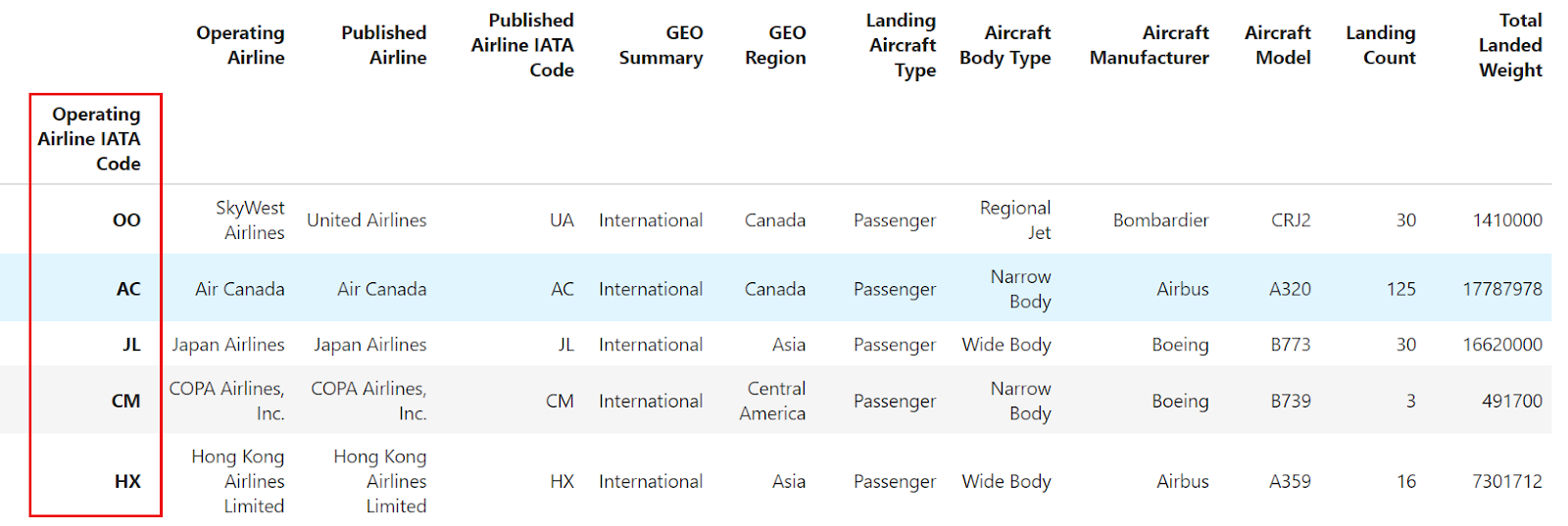
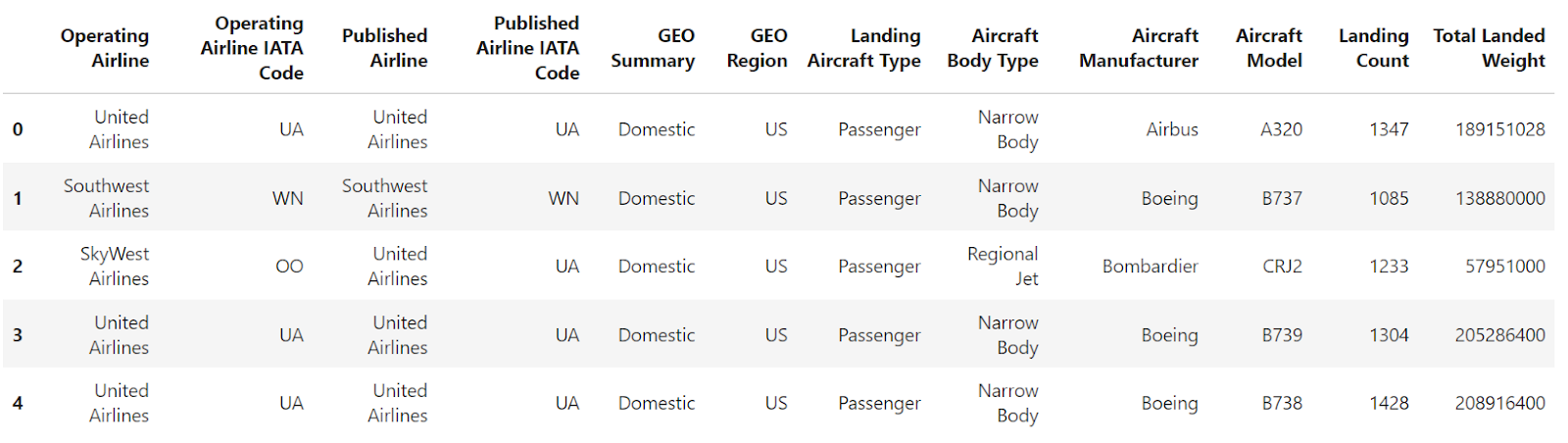
df = pd.read_csv("airlines_dataset.csv", index_col="Operating Airline IATA Code").head()
df
Como alternativa, você pode usar o método set_index() para que você defina qualquer coluna de um DataFrame como o índice:
import pandas as pd
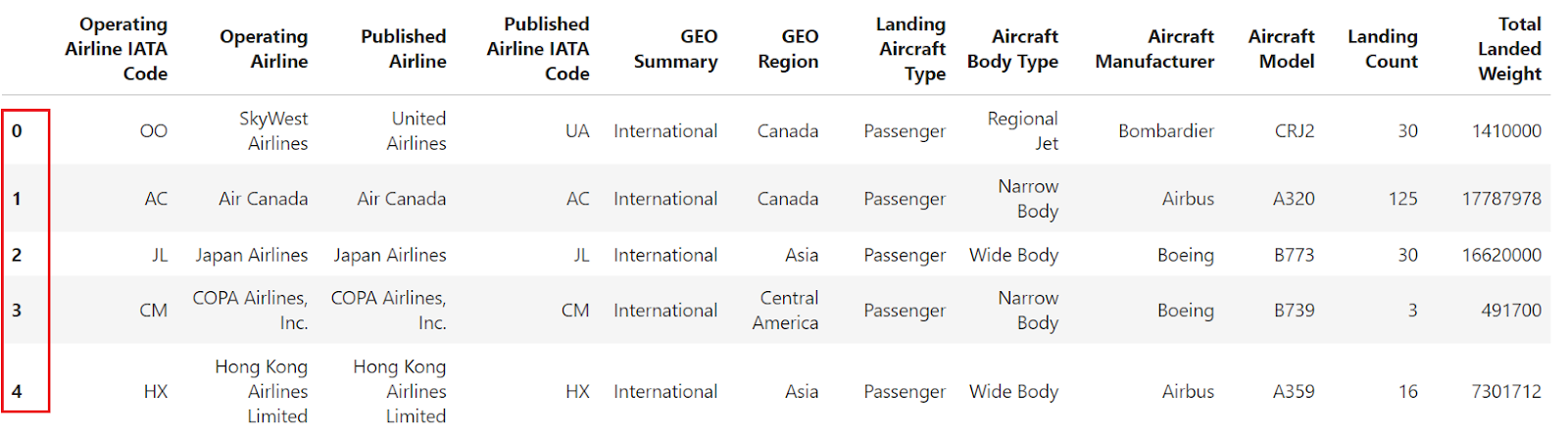
df = pd.read_csv("airlines_dataset.csv").head()
df.set_index("Operating Airline IATA Code", inplace=True)
dfObserve que o trecho de código fará alterações no DataFrame original.
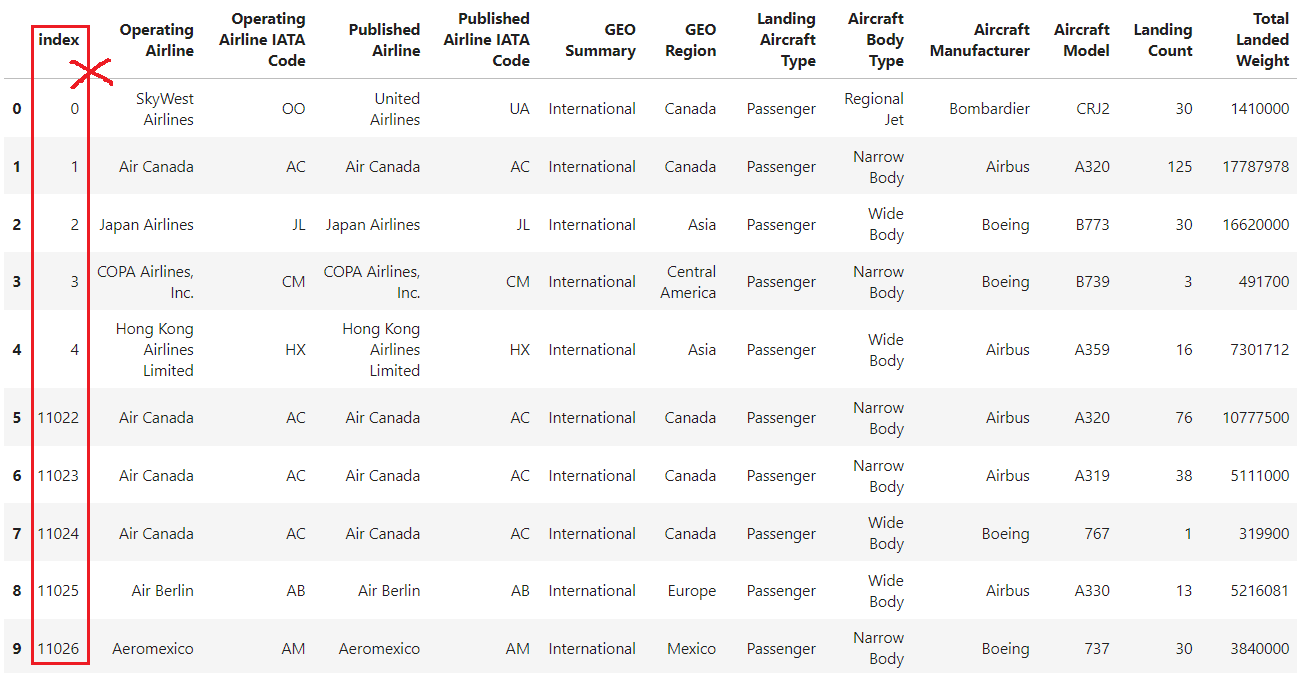
E se você precisar restaurar o índice numérico padrão? É aqui que entra o método reset_index() Pandas.
df.reset_index()
O exemplo mostra que, depois de definir a coluna "Operating Airline IATA Code" (Código IATA da companhia aérea em operação) como índice, você pode usar o DataFrame para reverter o índice inteiro padrão, reset_index é usado para reverter o DataFrame para seu índice inteiro padrão.
O método reset_index() no Pandas é uma ferramenta poderosa para reorganizar índices de DataFrame quando você está lidando com conjuntos de dados filtrados, DataFrames concatenados ou índices de vários níveis.
Saiba mais sobre como remodelar DataFrames de um formato largo para um formato longo, como empilhar e desempilhar linhas e colunas e como lidar com DataFrames com vários índices em nosso curso on-line.
Quando você filtra um DataFrame, o índice original é preservado. Usando reset_index, você pode reindexar o DataFrame filtrado.
import pandas as pd
df = pd.read_csv("airlines_dataset.csv")Vamos filtrar os dados para selecionar apenas as linhas em que a "contagem de aterrissagens" é maior que 1000. Após a filtragem, os índices podem não ser sequenciais. Em seguida, você pode usar o método reset_index para redefinir o índice do DataFrame filtrado.
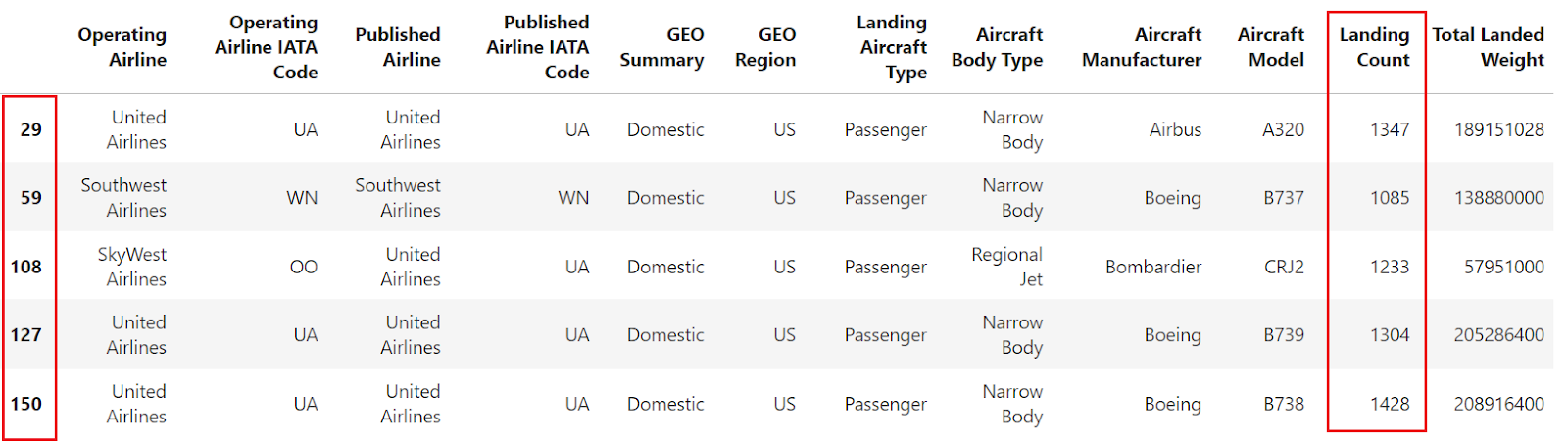
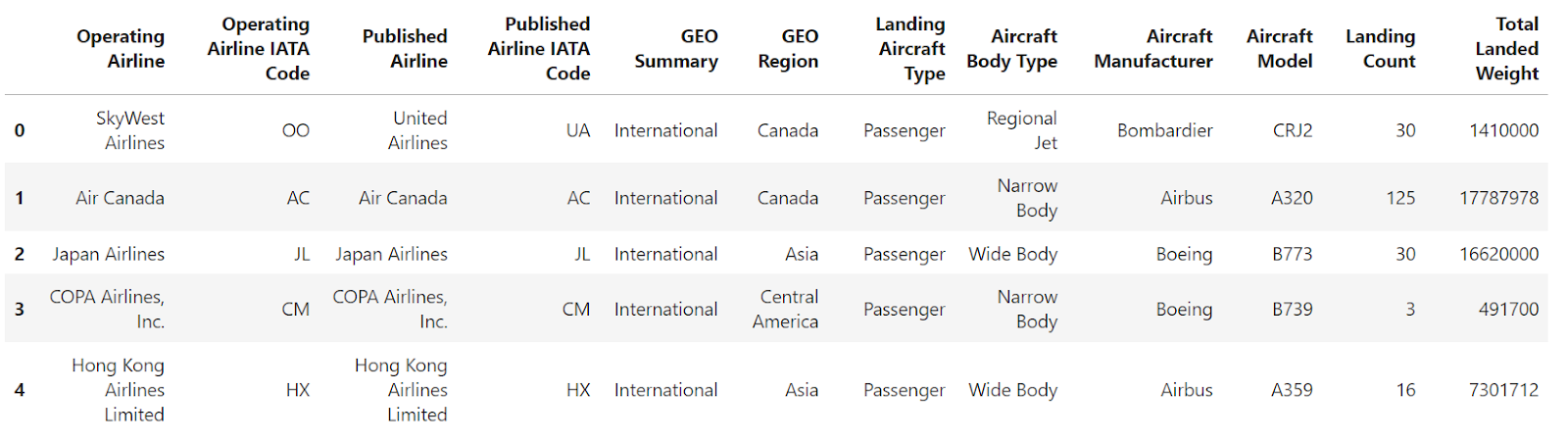
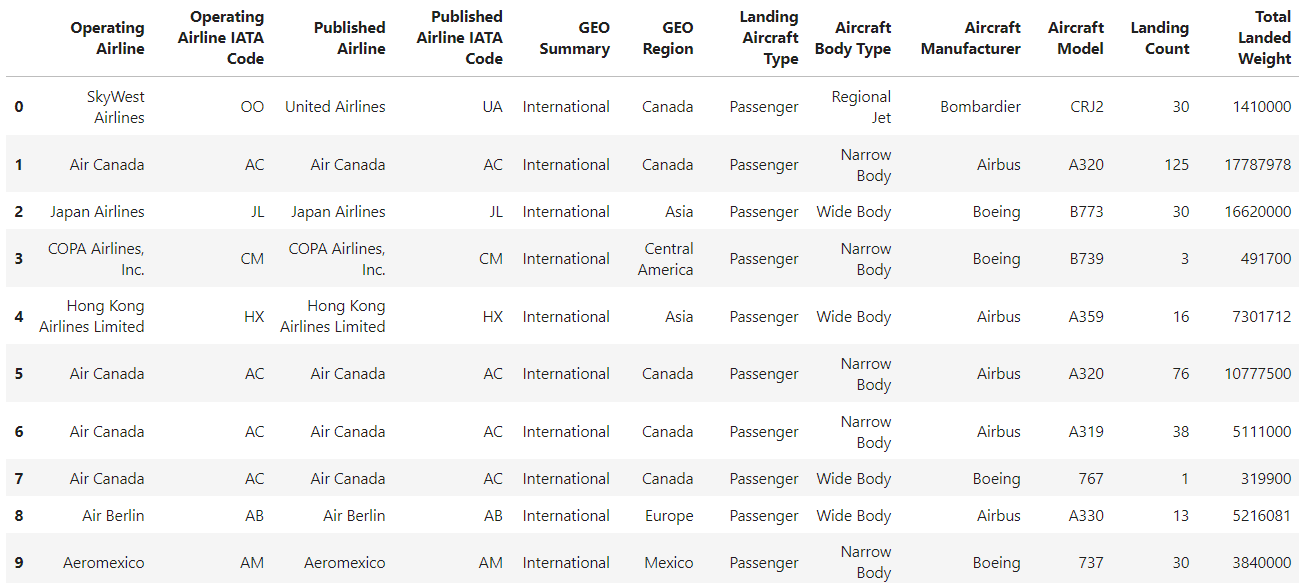
filtered_df = df[df["Landing Count"] > 1000].head()
filtered_df
A imagem acima mostra que o quadro de dados é filtrado com base na condição aplicada, mas o índice não é sequencial. Agora, vamos usar o site reset_index para reindexar o DataFrame filtrado e garantir um índice sequencial. Veja como você pode fazer isso:
filtered_df_reset = filtered_df.reset_index()
filtered_df_reset
O comportamento padrão desse método inclui a substituição do índice DataFrame existente por um índice padrão baseado em números inteiros e a conversão do índice antigo em uma nova coluna com o mesmo nome (ou "índice", se não tiver nome).
Portanto, use o parâmetro drop=Trueque garante que o índice antigo não seja adicionado como uma nova coluna.
filtered_df_reset = filtered_df.reset_index(drop=True)
filtered_df_reset
Ótimo! Os índices agora são redefinidos para o índice inteiro padrão (0, 1, 2, ...), fornecendo um índice limpo e sequencial.
Quando você combina DataFrames, o DataFrame resultante pode conter índices duplicados ou não sequenciais. A redefinição do índice cria um índice limpo e sequencial.
Suponha que você tenha dois DataFrames e queira concatená-los. Criei dois DataFrames a partir do conjunto de dados das companhias aéreas para fins de demonstração.
import pandas as pd
df = pd.read_csv("airlines_dataset.csv")
split_index = int(df.shape[0] / 2)
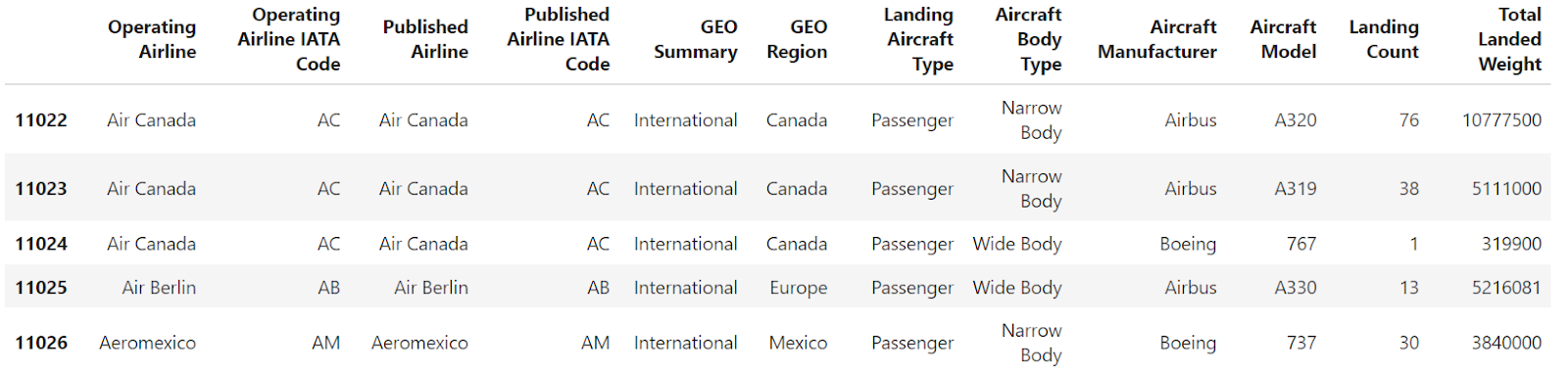
df1 = df[:split_index].head()
df2 = df[split_index:].head()Aqui está o df1:
Aqui está o df2:
Vamos concatenar os DataFrames df1 e df2.
df_concat = pd.concat([df1, df2])
Os dados mostram índices não sequenciais. Você precisa redefinir o índice do DataFrame concatenado para torná-lo sequencial.
Vamos redefinir o índice do DataFrame usando o método reset_index() em pandas.
df_concat.reset_index()
Veja como fica o resultado depois que você redefinir o índice do DataFrame. O método reset_index converte o índice antigo em uma nova coluna. Para remover essa coluna extra, você precisa usar o parâmetro drop=True.
df_concat.reset_index(drop=True)
Para DataFrames com indexação hierárquica (multinível), reset_index pode ser usado para simplificar o DataFrame, convertendo o índice multinível de volta em colunas.
Vamos dar uma olhada em um exemplo de DataFrame com um índice multinível.
import pandas as pd
df = pd.read_csv(
"airlines_dataset.csv", index_col=["Aircraft Model", "Operating Airline IATA Code"]
).head()
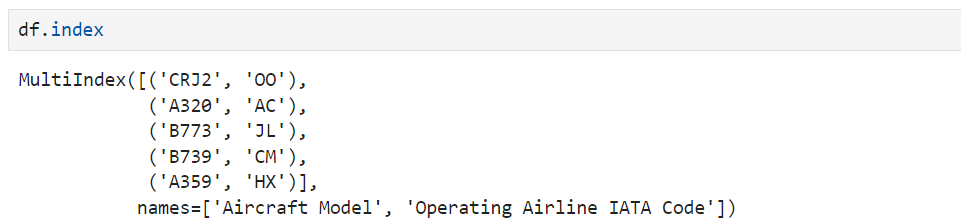
Se você verificar o índice, verá que não é um índice comum de DataFrame, mas um objeto MultiIndex
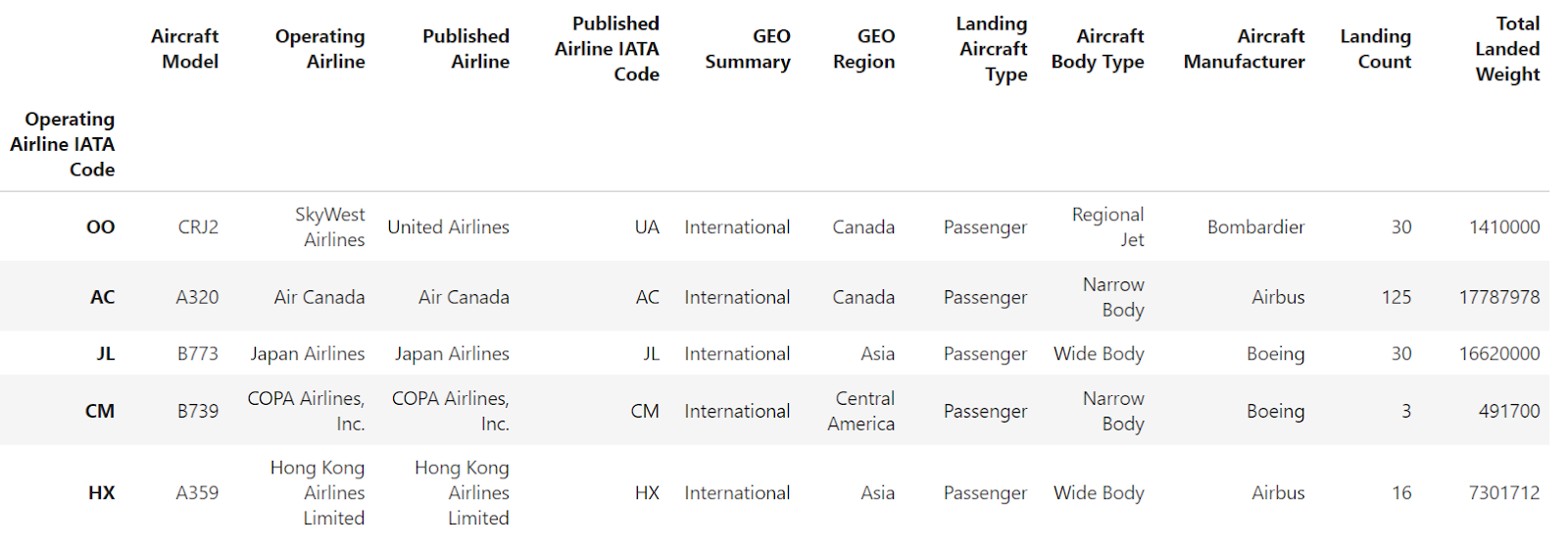
Agora, vamos usar o método pandas reset_index() que remove todos os níveis de um MultiIndex:
df.reset_index()
Você pode ver que ambos os níveis do MultiIndex são convertidos em colunas comuns do DataFrame, enquanto o índice é redefinido para o padrão baseado em números inteiros.
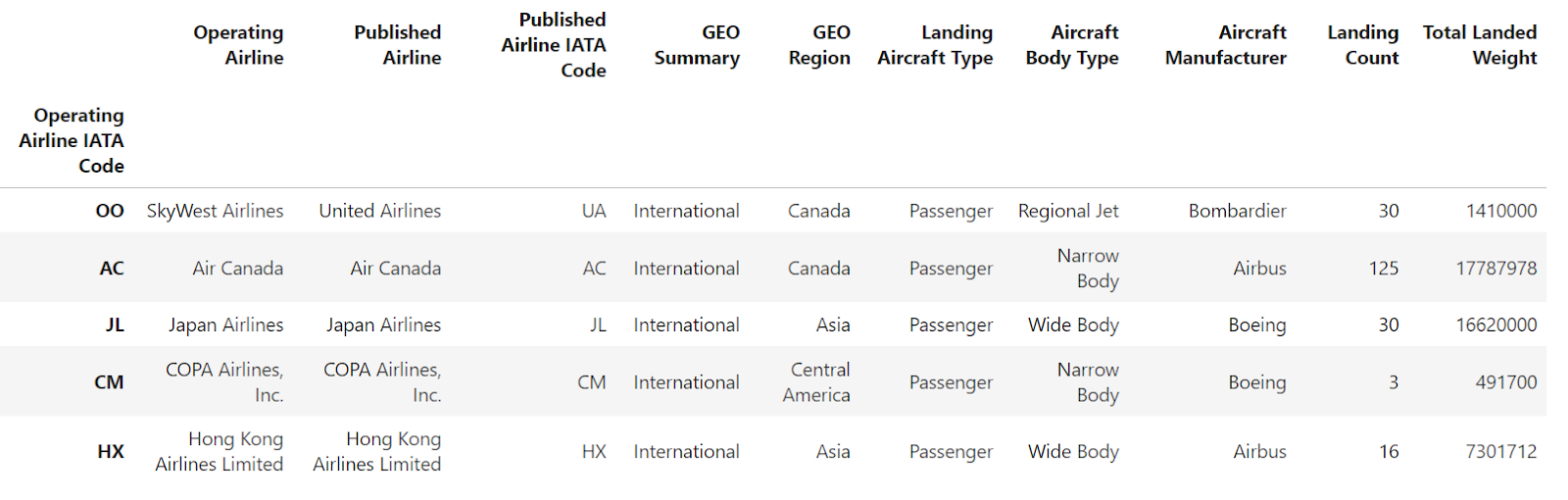
Você também pode usar o parâmetrolevel para remover os níveis selecionados do índice do DataFrame. Ele converte os níveis selecionados em colunas comuns do DataFrame, a menos que você opte por retirar completamente essas informações do DataFrame usando o parâmetro drop. Vamos dar uma olhada nisso:
df.reset_index(level=["Aircraft Model"])
A imagem acima mostra que "Aircraft Model" agora é uma coluna regular no DataFrame. Apenas o "Código IATA da companhia aérea em operação" permanece como índice.
Agora, se você não quiser que o índice descrito na lista se torne uma coluna regular, poderá combinar a opção drop e level para que você o retire do DataFrame.
df.reset_index(level=["Aircraft Model"], drop=True)
O índice 'Aircraft Model' foi removido do índice e do DataFrame. O outro índice, "Operating Airline IATA Code", foi mantido como o índice atual do DataFrame.
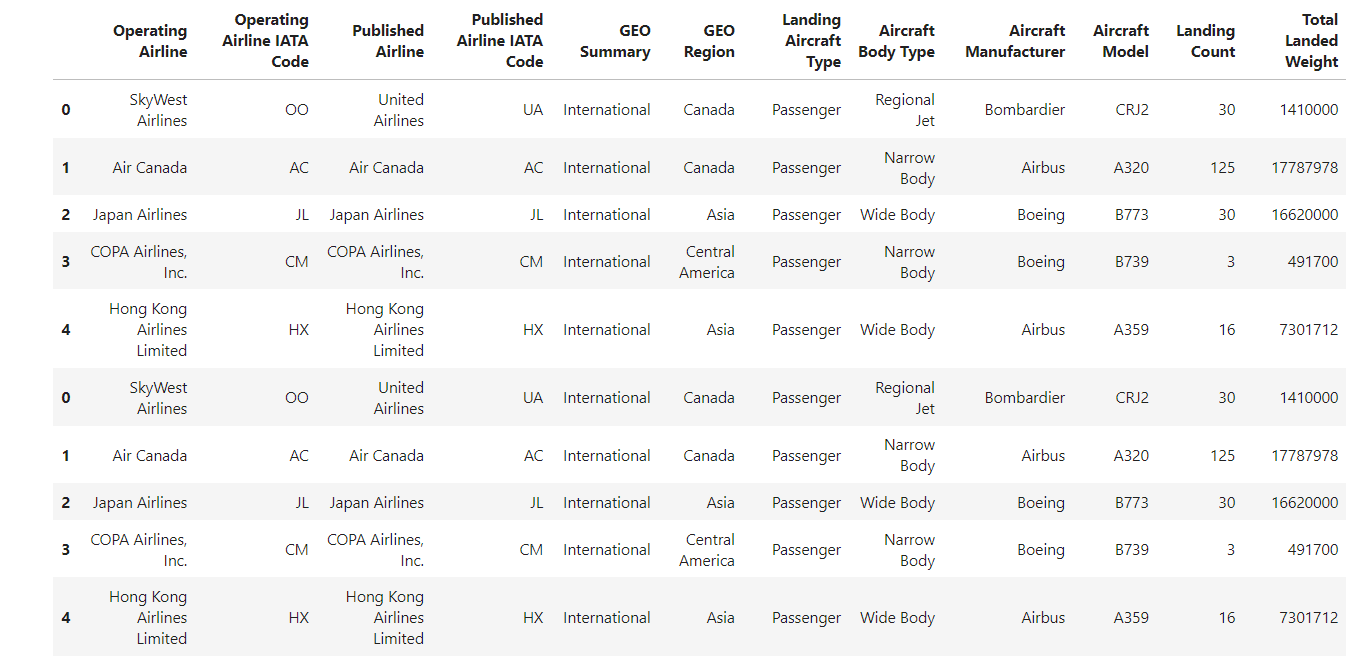
Suponha que você mescle dois DataFrames; o DataFrame mesclado resultante não terá mais índices sequenciais, como mostrado no DataFrame abaixo.
Vamos redefinir o índice do DataFrame usando o método reset_index() do pandas.
df.reset_index()
O drop determina se você manterá o índice antigo como uma coluna no DataFrame depois de redefinir o índice ou se o eliminará completamente. Por padrão (drop=False), o índice antigo é mantido, conforme demonstrado em todos os exemplos anteriores. Como alternativa, a configuração drop=True remove o índice antigo do DataFrame após a redefinição.
df.reset_index(drop=True)
Modifique o DataFrame no local usando o parâmetro inplace para evitar que você crie um novo DataFrame.
Suponha que você tenha o DataFrame abaixo:
Definindo o parâmetro inplace para True garante que as alterações sejam aplicadas diretamente ao DataFrame original, evitando a criação de um DataFrame separado.
df_concat.reset_index(drop=True, inplace=True)
df_concat
Gerencie índices duplicados, redefinindo e reindexando adequadamente.
Suponha que você tenha os dados com índices duplicados.
Usando reset_index() com drop=True e inplace=True garante que o DataFrame resultante terá índices contínuos, começando em 0 e aumentando sequencialmente.
df.reset_index(drop=True, inplace=True)
inplace=False se espera que o DataFrame original seja modificado. Se inplace for definido como False, um novo DataFrame será retornado e o DataFrame original permanecerá inalterado.drop para evitar a perda não intencional de dados. A eliminação do índice removerá permanentemente os valores atuais do índice.Vamos aplicar o que aprendemos sobre a redefinição do índice do DataFrame e ver como a redefinição do índice do DataFrame pode ser útil quando você está descartando valores ausentes.
Nosso conjunto de dados de companhias aéreas não tem valores ausentes, portanto, vamos usar o Filmes e programas de TV da Netflix da Netflix. Ele tem valores ausentes, o que é perfeito para demonstrar reset_index().
import pandas as pd
df = pd.read_csv("netflix_shows.csv")
df.head()
Você pode ver que há valores ausentes no DataFrame. Elimine as linhas que contêm valores ausentes usando o método dropna().
df.dropna(inplace=True)
df.head()
As linhas que contêm valores NaN foram removidas do DataFrame. No entanto, o índice não é mais contínuo (0, 1, 2, 4). Vamos redefinir isso:
df.reset_index()
Agora, o índice é contínuo; no entanto, como não passamos explicitamente o parâmetro drop, o índice antigo foi convertido em uma coluna com o nome padrão index. Vamos eliminar completamente o índice antigo do DataFrame:
df.reset_index(drop=True)
Removemos completamente o índice antigo sem sentido, e o índice atual agora é contínuo. A etapa final é salvar essas modificações em nosso DataFrame original usando o parâmetro inplace:
df.reset_index(drop=True, inplace=True)Você aprendeu como a função reset_index em Pandas gerencia eficientemente o DataFrame DataFrame. Se você estiver lidando com dados filtrados, DataFrames concatenados ou indexação complexa em vários níveis, o reset_index garante um DataFrame limpo e organizado. Seus parâmetros ajudam a gerenciar diversos cenários de indexação em tarefas de manipulação de dados.
Continue aprendendo a usar funções semelhantes para reset_index com o curso de carreira de Analista de dados com programa Python.
Principais cursos de pandas
Curso
Curso
Curso
Tutorial
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
DataCamp Team
