
Curso
Fundamentos de PySpark
4 h
157.5K
El filtrado es una operación fundamental en PySpark, esencial para refinar rápidamente grandes conjuntos de datos y acotar la información relevante. El uso eficaz de filtros en PySpark puede mejorar la eficiencia del flujo de trabajo para ingenieros de datos intermedios, científicos de datos y programadores que abordan el procesamiento de big data.
Este artículo presenta técnicas de filtrado fundamentales y avanzadas de PySpark, esboza estrategias de optimización para mejorar el rendimiento y cubre casos prácticos de uso aplicables a escenarios del mundo real.
Este tutorial asume algunos conocimientos fundamentales de PySpark, pero puedes descubrir qué es PySpark y cómo se puede utilizar en nuestro tutorial Introducción a PySpark.
Como mencionamos en nuestra guía Aprende PySpark desde cero en 2025, PySpark es una herramienta muy utilizada en la ciencia de datos debido a su facilidad de uso y eficacia. Proporciona formas sencillas de filtrar conjuntos de datos de forma eficaz utilizando funciones integradas como filter() y where(). Estas funciones ayudan a los profesionales de los datos a aislar las filas de los DataFrames que cumplen las condiciones especificadas.
El filtrado es fundamental en el preprocesamiento de datos, el análisis y la optimización de canalizaciones. Te permite excluir registros irrelevantes o erróneos desde el principio, ahorrando tiempo, reduciendo costes y mejorando los análisis posteriores o las tareas de modelado.
A pesar de su simplicidad, la aplicación de filtros en entornos distribuidos puede crear problemas como cuellos de botella en el rendimiento, condiciones de filtrado ineficaces o complejas, y un tratamiento inadecuado de los datos que faltan o están incompletos.
Comprender los Filtros Spark es vital para superar una entrevista de ingeniería de datos.
Domina los temas y preguntas clave que se plantean en las entrevistas sobre big data, desde conceptos básicos como el almacenamiento de datos y la informática distribuida hasta áreas avanzadas como el machine learning y la seguridad, utilizando nuestro tutorial sobre las 30+ preguntas más frecuentes en las entrevistas sobre big data.
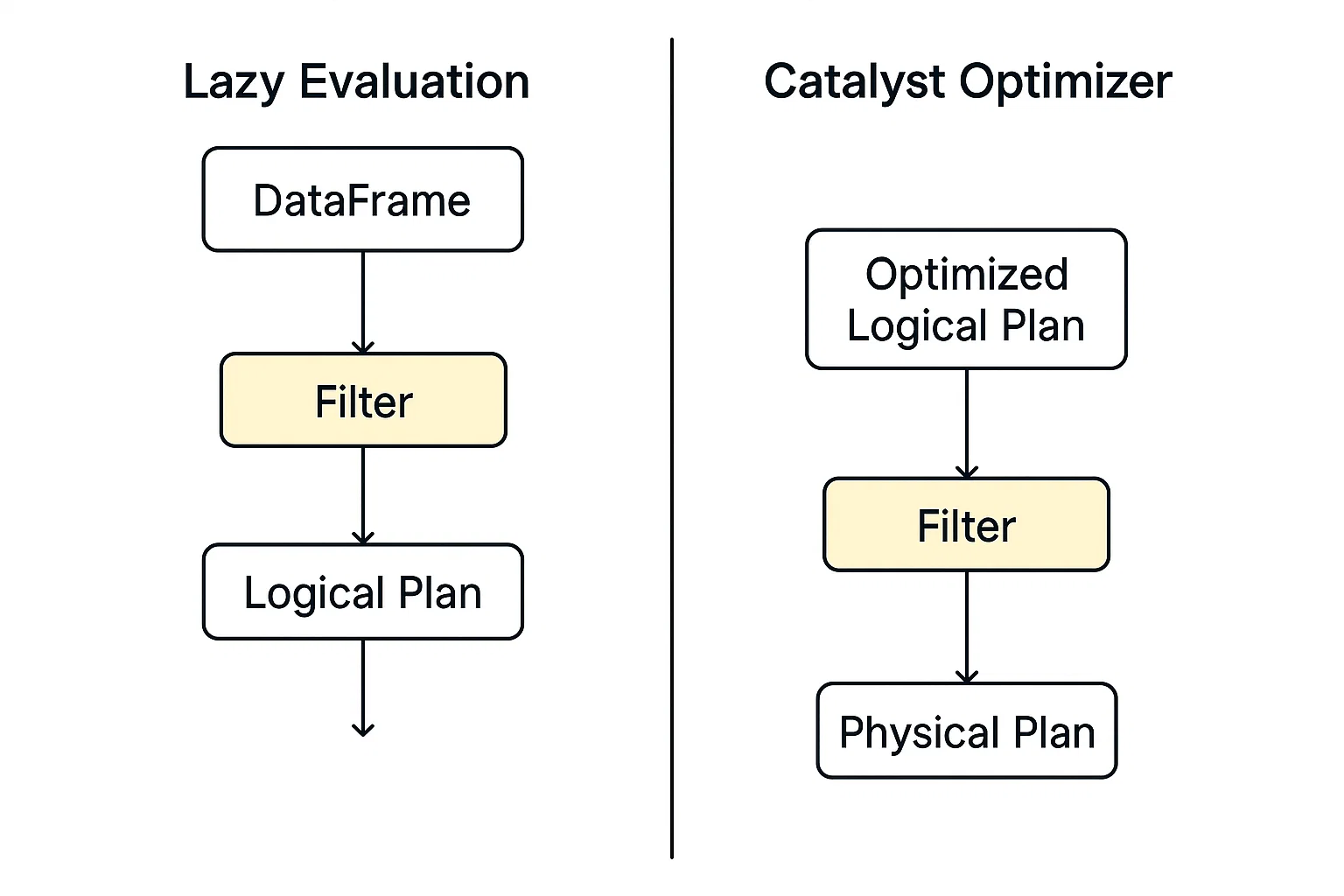
El filtrado en PySpark funciona en el marco de su modelo de ejecución distribuida, construido sobre Apache Spark. Cuando aplicas un filtro (por ejemplo, utilizando .filter() o .where()), PySpark no explora inmediatamente los datos. En lugar de eso, construye un plan de consulta lógico que describa las transformaciones que quieres realizar.
Dos conceptos básicos influyen significativamente en la eficacia del filtrado en PySpark:
PySpark no ejecuta inmediatamente un comando de filtro; en su lugar, construye un plan de consulta lógico y aplaza la acción hasta que se le indique explícitamente que lo ejecute. Este modelo permite a PySpark una mayor flexibilidad a la hora de optimizar las operaciones en los conductos de datos.
Este motor de optimización de Spark evalúa los planes lógicos, incluido el filtrado, e identifica la forma más rápida y eficiente de ejecutarlos automáticamente.
Cuando comienza la ejecución, los datos filtrados se procesan en paralelo en los nodos trabajadores utilizando RDDs o DataFrames. Cada partición aplica el filtro de forma independiente, por lo que es escalable para grandes conjuntos de datos.
Puedes explorar más información sobre los RDDs en nuestra PySpark Cheat Sheet: Tutorial de Spark en Python.
Filtrar los datos en función de las condiciones es sencillo. Puedes proporcionar las condiciones como expresiones de columna o cadenas tipo SQL.
Utiliza objetos columna y operadores de DataFrame para definir condiciones:
filtered_data = df.filter(df.age > 25)Escribe la condición como una cadena de estilo SQL:
filtered_data_2 = df.filter("age > 25")Alternativamente, puedes utilizar lafunción where() del mismo modo:
filtered_data_3 = df.where(df.age > 25)
filtered_data_4 = df.where("age > 25")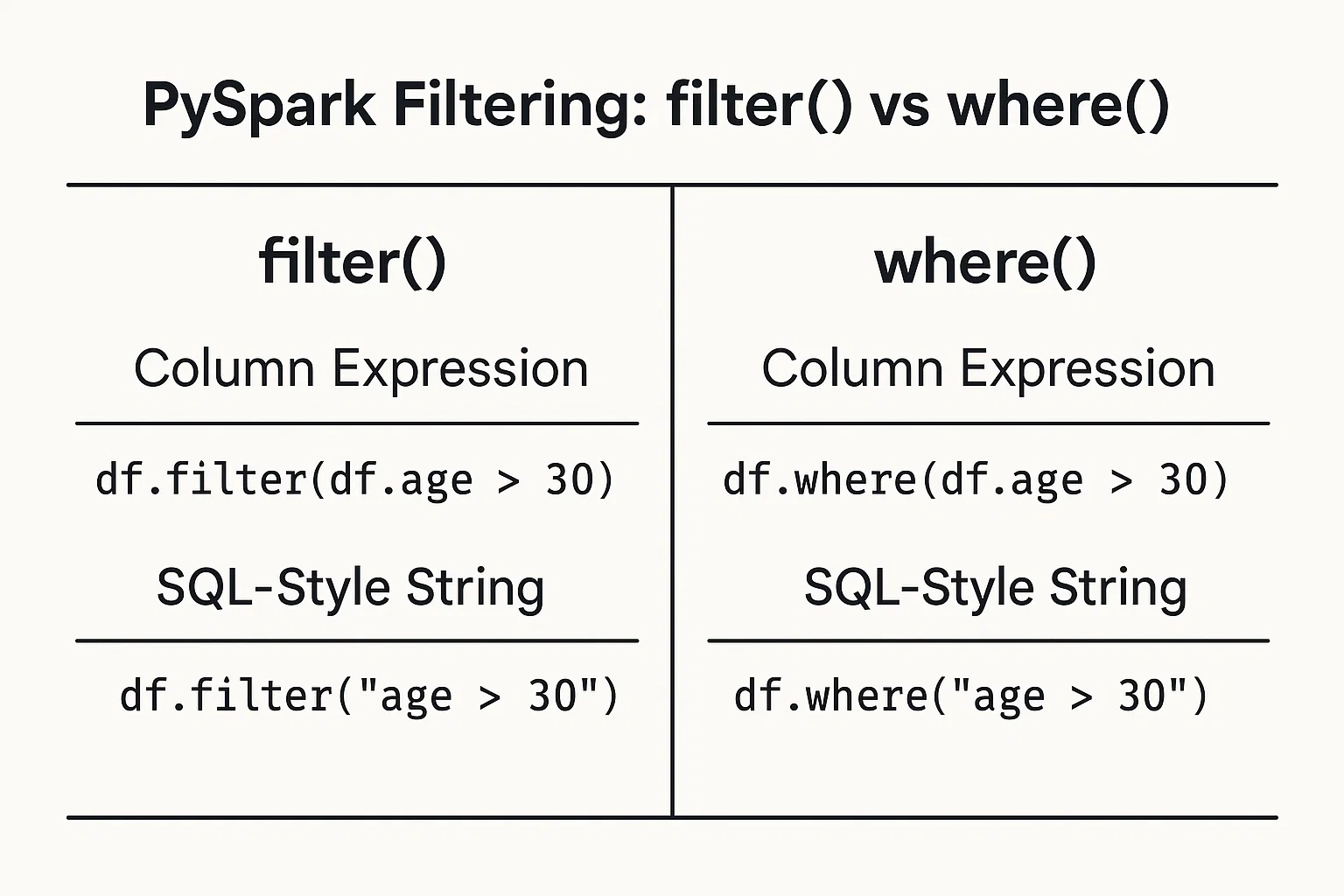
Todas ellas son válidas y producen el mismo resultado. La elección entre uno y otro a menudo se reduce a la preferencia personal o a qué estilo te parece más legible en tu contexto específico.
Para saber más sobre el uso de la sintaxis SQL en PySpark, consulta nuestro curso Introducción a Spark SQL en Python.
Exploremos ahora varios métodos de filtrado y sus casos prácticos de uso.
Puedes filtrar utilizando operadores relacionales como mayor que >, menor que <, igual a ==, y otros, para aislar los datos basándote en umbrales numéricos o categóricos:
greater_than_df = df.filter(df.salary > 50000)
category_match_df = df.filter(df.country == 'France')Para combinar varias condiciones en un filtro, los operadores lógicos como AND &, OR | y NOT ~ pueden crear expresiones concisas para requisitos complejos:
combined_df = df.filter((df.age > 25) & (df.city == 'New York'))PySpark incluye funciones avanzadas para casos de filtrado especializados. Exploremos algunas de ellas.
Pruebas de afiliación: Para filtrar valores de un conjunto predefinido utilizando isin:
selected_countries_df = df.filter(df.country.isin('Japan', 'Brazil', 'India'))Coincidencia de patrones: Filtrado basado en patrones de texto utilizando like para coincidencias simples y rlike para regex:
name_filter_df = df.filter(df.name.like('A%'))
regex_filter_df = df.filter(df.name.rlike('^[A-Z][a-z]+Filtros de alcance: Filtra con métodos prácticos como between:
range_df = df.filter(df.age.between(25, 35))Comprobaciones nulas: Maneja los valores omitidos con elegancia comprobando los nulos explícitamente:
valid_email_df = df.filter(df.email.isNotNull())Las organizaciones suelen utilizar datos anidados o estructurados. El filtrado PySpark admite campos anidados y arreglos. Para datos estructurados (structs), filtra fácilmente los campos anidados:
city_df = df.filter(df.address.city == 'Boston')Para los datos almacenados como arreglos, puedes utilizar funciones integradas como array_contains:
from pyspark.sql.functions import array_contains
skill_df = df.filter(array_contains(df.skills, 'Python'))En esta sección, descubrirás las estrategias para mejorar el rendimiento de las operaciones de filtrado en PySpark.
El pushdown de predicados consiste en colocar las condiciones de filtrado lo más cerca posible del nivel de almacenamiento de datos. Esto significa que PySpark lee menos datos inicialmente, mejorando el rendimiento.
Por ejemplo:
# Read from a Parquet file
df = spark.read.parquet("s3://your-bucket/sales_data/")
# Apply filter on a non-partition column (e.g., product_category)
filtered_df = df.filter(df.product_category == "Electronics")
# Trigger query plan inspection
filtered_df.explain(True)En el ejemplo anterior, estamos aplicando un filtro a una columna normal. Normalmente, Spark cargaría todo el conjunto de datos y luego filtraría en memoria, pero como Parquet admite el pushdown de predicados, Spark puede enviar la condición de filtrado directamente al lector de Parquet.
En lugar de leer todas las filas y luego comprobar product_category, Spark sólo lee las filas en las que product_category = 'Electronics'. Esto ahorra E/S de disco y memoria, acelerando el procesamiento.
explain imprime el plan de consulta físico, mostrando exactamente lo que Spark planea hacer durante la ejecución.
Si se aplica el predicado pushdown, verás algo como
PushedFilters: [EqualTo(product_category,Electronics)]Esto confirma que Spark empujó el filtro hasta el nivel de exploración del archivo en lugar de aplicarlo después de cargar los datos.
El pushdown de predicados es una de las optimizaciones más potentes del conjunto de herramientas de Spark. Ello:
Al escribir tus filtros con claridad y almacenar los datos en formatos como Parquet, permites que Spark optimice la ejecución bajo el capó.

La optimización del rendimiento también es crucial cuando se hacen uniones en PySpark. Aprende a optimizar las uniones de PySpark, a reducir las mezclas, a manejar la inclinación y a mejorar el rendimiento en los pipelines de big data y en los flujos de trabajo de machine learning en nuestra página PySpark Joins: Tutorial para optimizar el rendimiento de las uniones de Big Data.
Cuando los datos se particionan por campos relevantes (por ejemplo, la fecha), PySpark puede evitar cargar particiones innecesarias. La poda eficaz de particiones reduce significativamente el escaneado de datos y el tiempo de ejecución.
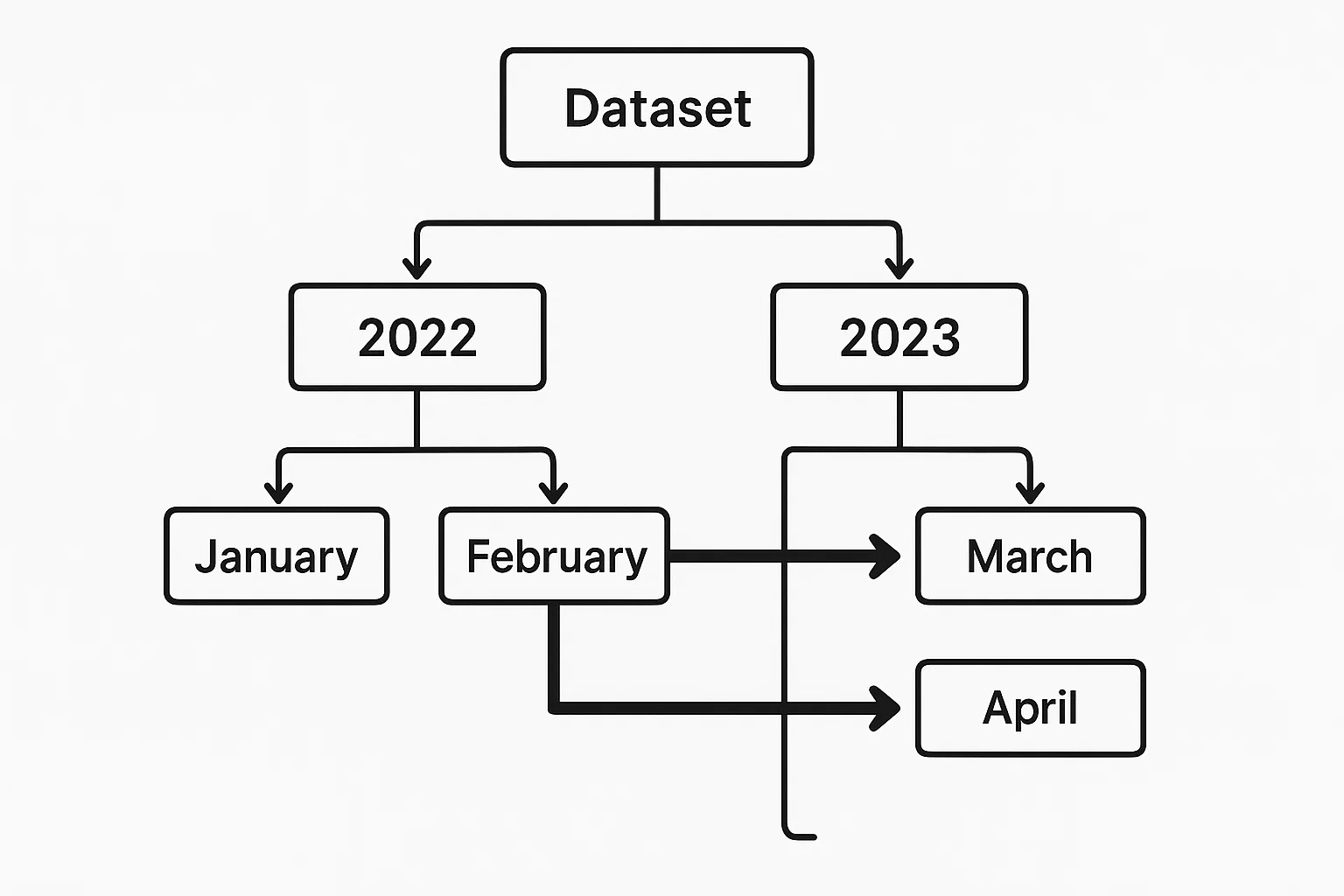
Supongamos que tenemos un conjunto de datos Parquet particionado por year y month, almacenado en s3://your-bucket/events_data/.
Cada partición tiene el siguiente aspecto:
events_data/year=2023/month=01/
events_data/year=2023/month=02/
...
events_data/year=2024/month=01/Un ejemplo de poda de particiones en PySpark tendría este aspecto:
df = spark.read.parquet("s3://your-bucket/events_data/")
filtered_df = df.filter((df.year == 2023) & (df.month == 6))
# .explain(True) to verify pruning
filtered_df.explain(True)year y month son columnas de partición, lo que permite al optimizador Catalyst de Spark eliminar todas las particiones irrelevantes.
Los resultados filtrados suelen utilizarse varias veces en un flujo de trabajo de análisis. Almacenar los resultados filtrados temporalmente en la memoria mediante el almacenamiento en caché ayuda a evitar el cálculo repetido, pero debe utilizarse con precaución para conservar los recursos.
recent_users_df = df.filter(df.registration_date >= '2022-01-01')
recent_users_df.cache()Exploremos ahora escenarios complejos en los que se aplican técnicas avanzadas de filtrado.
Para manejar datos de series temporales, suele ser necesario un filtrado temporal preciso. Filtrar datos dentro de un marco temporal concreto es sencillo:
time_df = df.filter((df.date >= '2023-08-01') & (df.date < '2023-09-01'))Lo anterior selecciona todos los registros a partir de agosto de 2023. La condición funciona con las columnas DateType y TimestampType.
Para un análisis de series temporales más profundo, como calcular métricas móviles o identificar tendencias a lo largo del tiempo, puedes emparejar los filtros temporales con funciones de ventana. Por ejemplo, podrías filtrar primero un intervalo de fechas, y luego aplicar una media móvil o clasificar los eventos dentro de cada día:
from pyspark.sql.window import Window
from pyspark.sql.functions import avg
window_spec = Window.partitionBy("date").orderBy("timestamp").rowsBetween(-2, 0)
df_filtered = df.filter((df.date >= '2023-08-01') & (df.date < '2023-09-01'))
df_with_avg = df_filtered.withColumn("rolling_avg", avg("value").over(window_spec))Este ejemplo calcula una media móvil de 3 filas por día para valores ordenados por fecha/hora. La combinación de filtros temporales con funciones de ventana te proporciona un control detallado de los análisis basados en el tiempo.
Filtrar flujos de datos en tiempo real presenta retos únicos. A diferencia del procesamiento por lotes, los datos son ilimitados y llegan continuamente. Esto requiere que los filtros se apliquen sobre la marcha, con un manejo cuidadoso de los eventos que llegan tarde para garantizar resultados precisos.
El Streaming Estructurado de PySpark proporciona herramientas intuitivas para filtrar los datos de streaming y gestionar eficazmente los problemas de sincronización. Puedes aplicar filtros como lo harías en un DataFrame estático y utilizar marcas de agua para controlar el tiempo que el sistema debe esperar a los datos atrasados antes de finalizar los resultados.
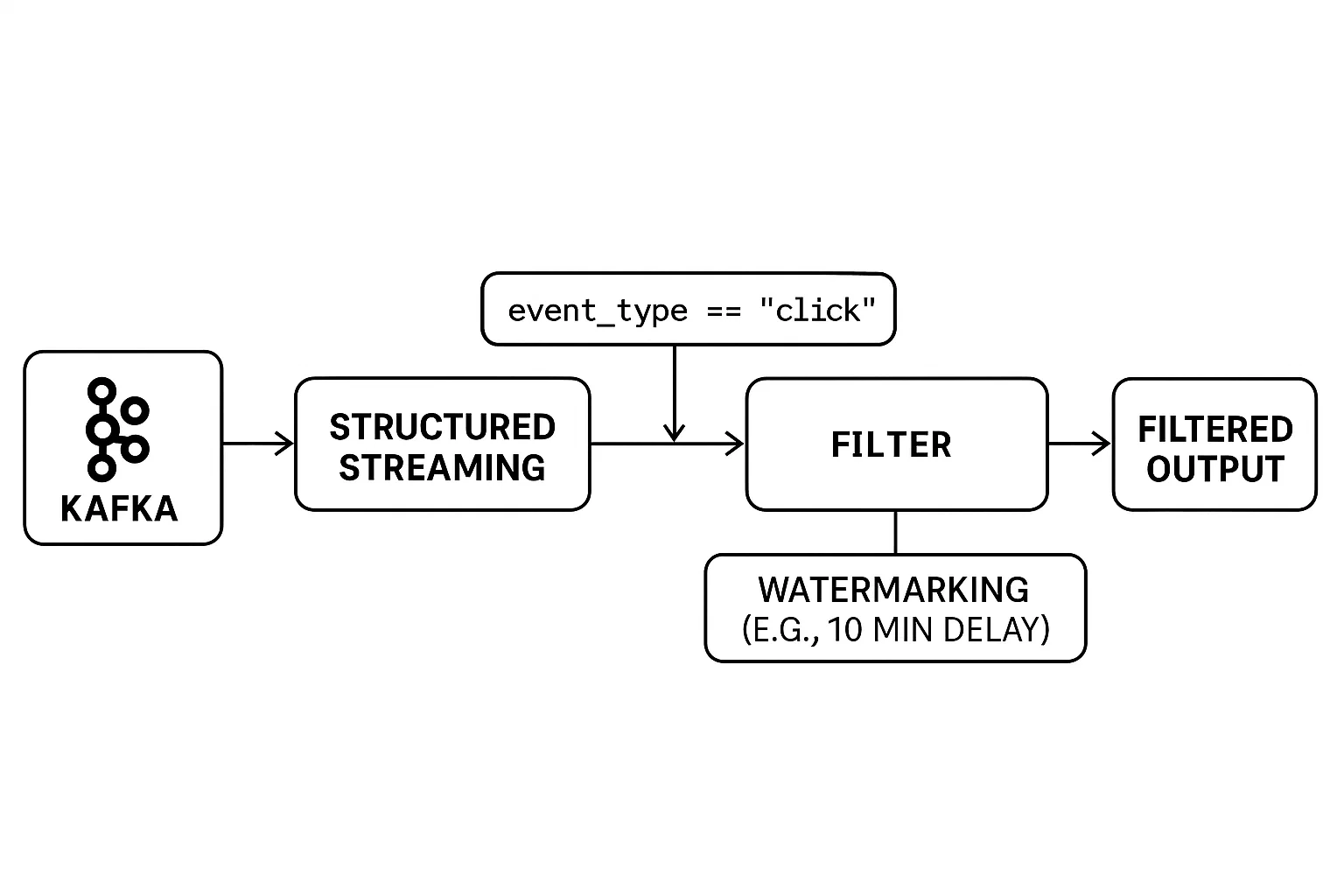
He aquí un ejemplo:
# Example: Real-Time Filtering with Watermarking
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.types import StructType, StringType, TimestampType
# Set up Spark session
spark = SparkSession.builder.appName("RealTimeFiltering").getOrCreate()
# Define schema for streaming data
schema = StructType() \
.add("user_id", StringType()) \
.add("event_type", StringType()) \
.add("event_time", TimestampType())
# Read from a Kafka stream (or any supported source)
streaming_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "user_events") \
.load() \
.selectExpr("CAST(value AS STRING) as json") \
.selectExpr("from_json(json, 'user_id STRING, event_type STRING, event_time TIMESTAMP') as data") \
.select("data.*")
# Apply real-time filter: only 'click' events
filtered_df = streaming_df.filter(col("event_type") == "click")
# Handle late data with watermarking (e.g., 10 minutes tolerance)
filtered_with_watermark = filtered_df \
.withWatermark("event_time", "10 minutes")
# Write to console (for demo purposes)
query = filtered_with_watermark.writeStream \
.outputMode("append") \
.format("console") \
.start()
query.awaitTermination()En el ejemplo:
.filter(col("event_type") == "click").(withWatermark(...)) garantiza que los eventos que lleguen tarde se gestionen dentro de una ventana de tiempo (10 minutos en este caso).La combinación de filtros en tiempo real y marcas de agua te permite crear aplicaciones de streaming fiables, incluso en caso de retrasos en la red o eventos irregulares.
En los conductos de machine learning, el filtrado eficaz es fundamental durante el preprocesamiento. Se utiliza no sólo para eliminar el ruido, sino también para seleccionar las características más relevantes para el entrenamiento del modelo. El filtrado ayuda a eliminar los valores atípicos, descartar los registros con valores que faltan o no válidos, y conservar sólo los atributos que aportan señales significativas.
Este doble enfoque, la limpieza de los datos y la selección de las características clave, puede mejorar drásticamente tanto el rendimiento como la fiabilidad de tus modelos, como se explica en nuestro curso Limpieza de datos con PySpark. Sin ella, los modelos corren el riesgo de estar sesgados por datos irrelevantes o distorsionados por datos erróneos.
Nuestro curso Big Data con PySpark profundiza en el machine learning en PySpark.
En esta sección, exploraremos las mejores prácticas y los retos habituales que se encuentran al filtrar datos con PySpark.
He aquí algunas recomendaciones prácticas para mejorar la eficacia del filtrado:
1. Filtra lo antes posible durante el procesado.
2. Limita el número de columnas seleccionadas para reducir la mezcla de datos.
3. Prioriza el uso de las funciones de filtro integradas en PySpark en lugar de las UDF (funciones definidas por el usuario) personalizadas.
Evita los errores comunes:
Las expresiones de filtro demasiado intrincadas pueden entorpecer el optimizador Catalizador de Spark. Por ejemplo, encadenar numerosas condiciones OR o sentencias lógicas profundamente anidadas puede complicar el plan lógico, provocando una ejecución subóptima. En situaciones en las que haya varias comprobaciones de igualdad, considera la posibilidad de utilizar isin() o de realizar una unión con un DataFrame más pequeño para aprovechar las uniones de difusión, que son más eficientes para grandes conjuntos de datos.
Aunque el almacenamiento en caché es beneficioso para reutilizar los DataFrames, su uso indiscriminado puede agotar la memoria del clúster. Almacenar en caché DataFrames grandes o numerosos sin evaluar su reutilización puede provocar errores de falta de memoria. Es fundamental almacenar en caché sólo los DataFrames que se reutilicen varias veces y desocuparlos cuando ya no se necesiten.
La desviación de datos, en la que ciertas claves tienen cantidades desproporcionadamente grandes de datos, puede provocar cuellos de botella en el rendimiento. Operaciones como uniones o agregaciones sobre claves sesgadas pueden provocar tiempos de ejecución de tareas desiguales. Técnicas como el salting (añadir prefijos aleatorios a las claves), la partición personalizada o el uso de la Ejecución Adaptativa de Consultas de Spark pueden ayudar a mitigar estos problemas.
Un filtrado adecuado desempeña un papel crucial en el procesamiento eficaz de datos con PySpark. Agiliza los flujos de trabajo de análisis, ahorra recursos computacionales y aporta claridad a los resultados analíticos posteriores. Aprovechar los sencillos pero potentes métodos de filtrado de PySpark, junto con estrategias optimizadas como el pushdown de predicados, la poda de particiones y el almacenamiento selectivo en caché, mejora significativamente tus prácticas de ingeniería de datos. La aplicación coherente de estas técnicas garantiza canalizaciones de datos sólidas y mantenibles.
Para explorar PySpark más a fondo, echa un vistazo a nuestros cursos Spark en profundidad, incluyendo:
Los mejores cursos de DataCamp
Curso
Curso
Curso
Tutorial
Natassha Selvaraj
Tutorial
Olivia Smith
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Joleen Bothma

