
Cours
Introduction à PySpark
4 h
157.5K
Le filtrage est une opération fondamentale de PySpark, essentielle pour affiner rapidement de grands ensembles de données afin de réduire les informations pertinentes. L'utilisation efficace des filtres dans PySpark peut améliorer l'efficacité du flux de travail pour les ingénieurs de données intermédiaires, les scientifiques des données et les développeurs qui s'attaquent au traitement des big data.
Cet article présente les techniques de filtrage fondamentales et avancées de PySpark, décrit les stratégies d'optimisation pour de meilleures performances et couvre des cas d'utilisation pratiques applicables à des scénarios du monde réel.
Ce tutoriel suppose quelques connaissances fondamentales de PySpark, mais vous pouvez découvrir ce qu'est PySpark et comment il peut être utilisé dans notre tutoriel Getting Started with PySpark.
Comme indiqué dans notre guide Apprendre PySpark à partir de zéro en 2025, PySpark est un outil largement utilisé dans le domaine de la science des données en raison de sa facilité d'utilisation et de son efficacité. Il offre des moyens simples de filtrer efficacement les ensembles de données à l'aide de fonctions intégrées telles que filter() et where(). Ces fonctions permettent aux professionnels des données d'isoler les lignes des DataFrame qui répondent à des conditions spécifiques.
Le filtrage est essentiel pour le prétraitement des données, l'analyse et l'optimisation du pipeline. Il vous permet d'exclure d'emblée les enregistrements non pertinents ou erronés, ce qui permet de gagner du temps, de réduire les coûts et d'améliorer les analyses ou les tâches de modélisation ultérieures.
Malgré sa simplicité, l'application de filtres dans des environnements distribués peut poser des problèmes tels que des goulets d'étranglement au niveau des performances, des conditions de filtrage inefficaces ou complexes et une mauvaise gestion des données manquantes ou incomplètes.
Comprendre les filtres Spark est essentiel pour réussir un entretien d'ingénierie des données.
Maîtrisez les sujets et les questions clés posées lors des entretiens sur les big data, des concepts fondamentaux comme le stockage des données et l'informatique distribuée aux domaines avancés comme l'apprentissage automatique et la sécurité, à l'aide de notre didacticiel des 30+ meilleures questions d'entretien sur les big data.
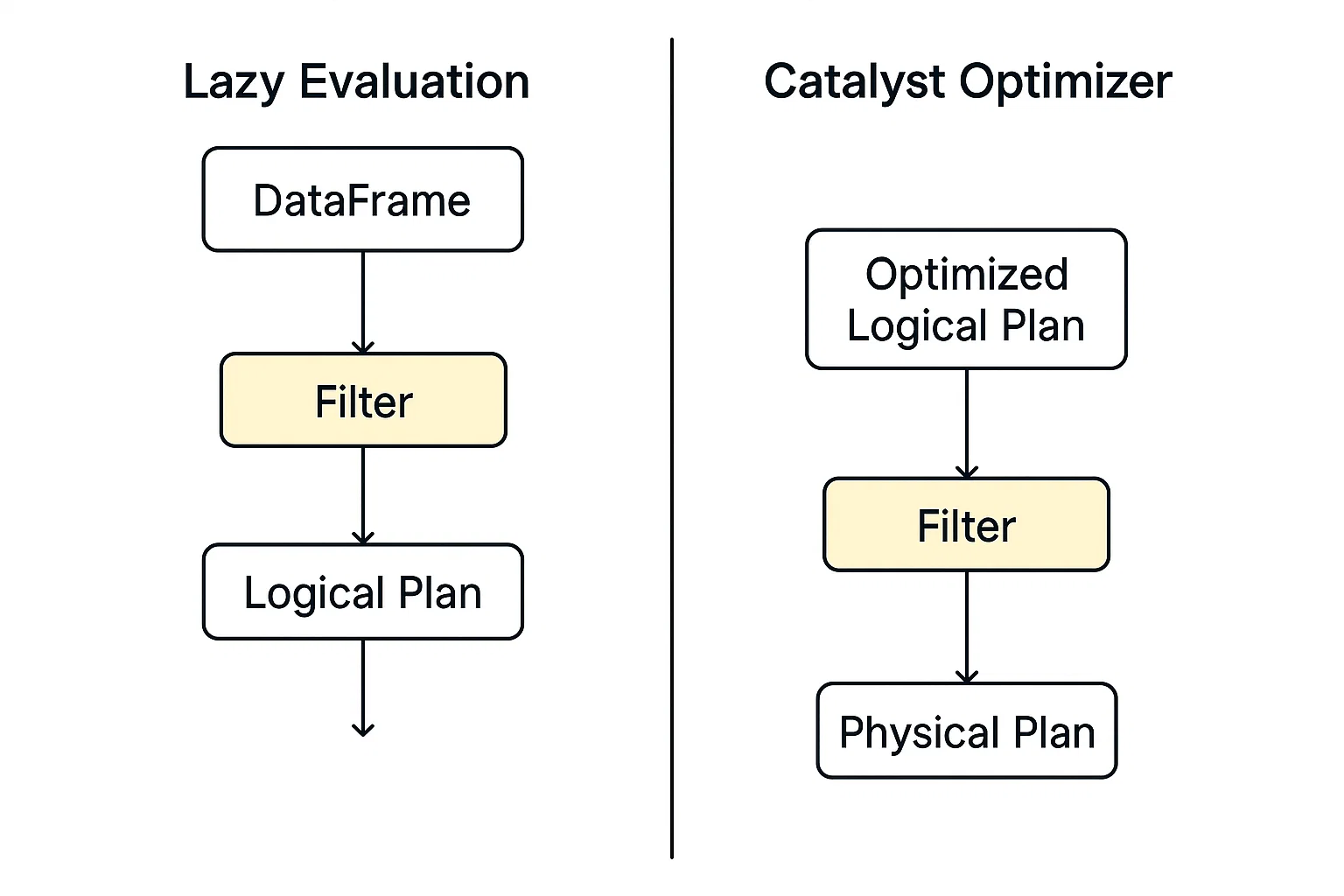
Le filtrage dans PySpark fonctionne dans le cadre de son modèle d'exécution distribué, construit au-dessus d'Apache Spark. Lorsque vous appliquez un filtre (par exemple, en utilisant .filter() ou .where())), PySpark ne scanne pas immédiatement les données. Au lieu de cela, il élabore un plan d'interrogation logique qui décrit les transformations que vous souhaitez effectuer.
Deux concepts fondamentaux influencent de manière significative l'efficacité du filtrage dans PySpark :
PySpark n'exécute pas immédiatement une commande de filtrage ; à la place, il construit un plan de requête logique et reporte l'action jusqu'à ce qu'on lui demande explicitement de l'exécuter. Ce modèle permet à PySpark de bénéficier d'une plus grande flexibilité dans l'optimisation des opérations à travers les pipelines de données.
Ce moteur d'optimisation dans Spark évalue les plans logiques, y compris le filtrage, et identifie la manière la plus rapide et la plus efficace de les exécuter automatiquement.
Lorsque l'exécution commence, les données filtrées sont traitées en parallèle sur les nœuds de travail à l'aide de RDD ou de DataFrame. Chaque partition applique le filtre de manière indépendante, ce qui permet d'adapter le système aux grands ensembles de données.
Vous pouvez obtenir plus d'informations sur les RDD sur notre site PySpark Cheat Sheet : Tutoriel Spark en Python.
Le filtrage des données en fonction des conditions est simple. Vous pouvez fournir des conditions sous forme d'expressions de colonnes ou de chaînes de type SQL.
Utilisez les objets colonnes du DataFrame et les opérateurs pour définir des conditions :
filtered_data = df.filter(df.age > 25)Écrivez la condition sous la forme d'une chaîne de style SQL :
filtered_data_2 = df.filter("age > 25")Vous pouvez également utiliser lafonction where() dela même manière :
filtered_data_3 = df.where(df.age > 25)
filtered_data_4 = df.where("age > 25")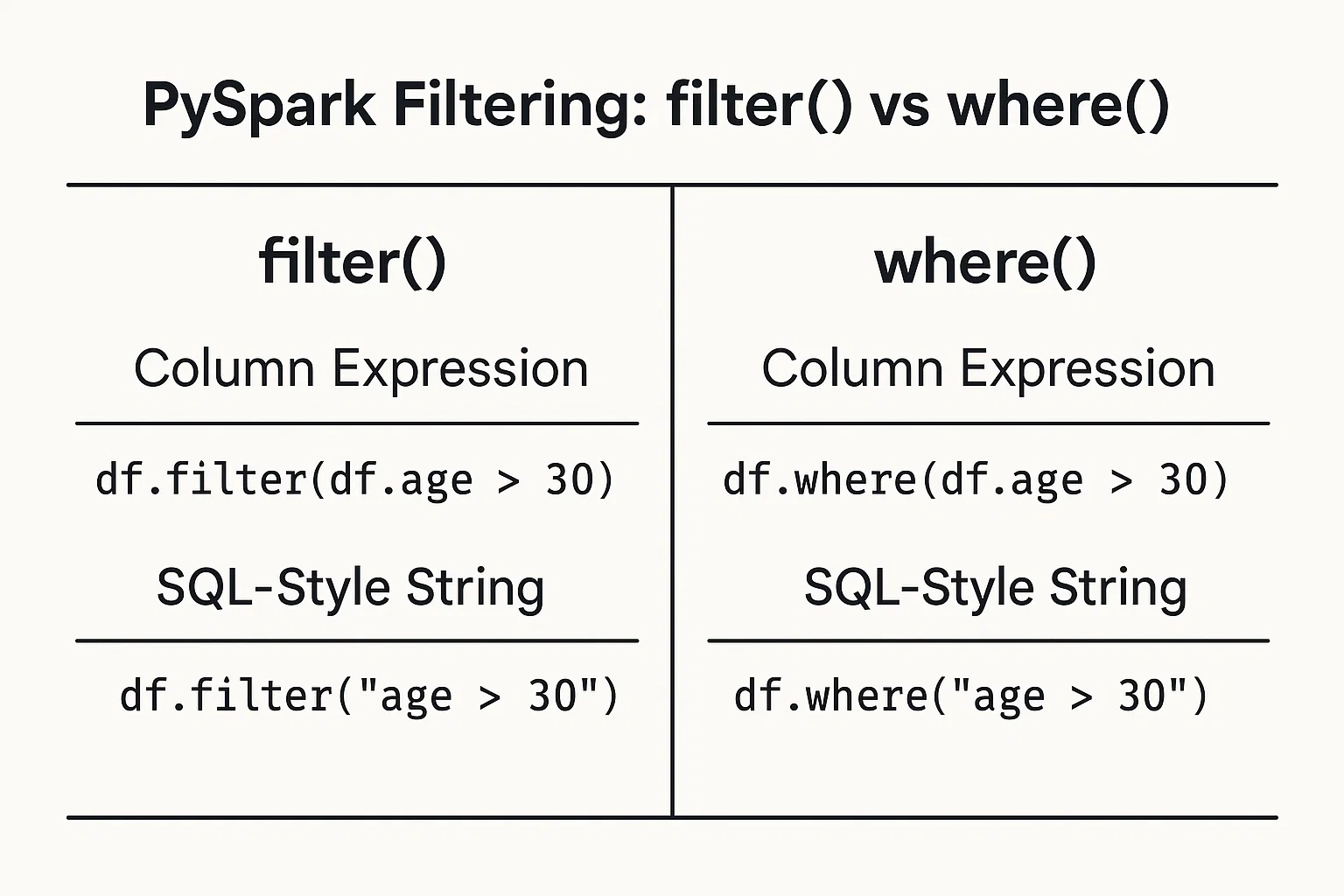
Toutes ces méthodes sont valables et produisent le même résultat. Le choix entre les deux se résume souvent à une préférence personnelle ou au style qui semble le plus lisible dans votre contexte spécifique.
Pour en savoir plus sur l'utilisation de la syntaxe SQL dans Spark, consultez notre cours Introduction à Spark SQL en Python.
Examinons maintenant les différentes méthodes de filtrage et leurs cas d'utilisation pratique.
Vous pouvez filtrer à l'aide d'opérateurs relationnels tels que plus grand que >, moins de <, égal à ==, et autres pour isoler les données en fonction de seuils numériques ou catégoriels :
greater_than_df = df.filter(df.salary > 50000)
category_match_df = df.filter(df.country == 'France')Pour combiner plusieurs conditions en un seul filtre, les opérateurs logiques tels que AND &, OR | et NOT ~ permettent de créer des expressions concises pour des exigences complexes :
combined_df = df.filter((df.age > 25) & (df.city == 'New York'))PySpark comprend des fonctions avancées pour les cas de filtrage spécialisés. Examinons-en quelques-unes.
Tests d'adhésion : Pour filtrer les valeurs d'un ensemble prédéfini à l'aide de isin:
selected_countries_df = df.filter(df.country.isin('Japan', 'Brazil', 'India'))Correspondance de motifs : Filtrage basé sur des motifs de texte en utilisant like pour les correspondances simples et rlike pour les expressions rationnelles :
name_filter_df = df.filter(df.name.like('A%'))
regex_filter_df = df.filter(df.name.rlike('^[A-Z][a-z]+Filtres de gamme : Filtrer avec des méthodes pratiques comme between:
range_df = df.filter(df.age.between(25, 35))Contrôles de nullité : Traiter les valeurs manquantes avec élégance en vérifiant explicitement les valeurs nulles :
valid_email_df = df.filter(df.email.isNotNull())Les organisations utilisent souvent des données imbriquées ou structurées. Le filtrage PySpark prend en compte les champs et les tableaux imbriqués. Pour les données structurées (structs), filtrez facilement les champs imbriqués :
city_df = df.filter(df.address.city == 'Boston')Pour les données stockées sous forme de tableaux, vous pouvez utiliser des fonctions intégrées telles que array_contains:
from pyspark.sql.functions import array_contains
skill_df = df.filter(array_contains(df.skills, 'Python'))Dans cette section, vous découvrirez les stratégies permettant d'améliorer les performances des opérations de filtrage dans PySpark.
Le "pushdown" des prédicats consiste à placer les conditions de filtrage aussi près que possible du niveau de stockage des données. Cela signifie que PySpark lit moins de données au départ, ce qui améliore les performances.
Par exemple :
# Read from a Parquet file
df = spark.read.parquet("s3://your-bucket/sales_data/")
# Apply filter on a non-partition column (e.g., product_category)
filtered_df = df.filter(df.product_category == "Electronics")
# Trigger query plan inspection
filtered_df.explain(True)Dans l'exemple ci-dessus, nous appliquons un filtre sur une colonne régulière. Normalement, Spark devrait charger l'ensemble du jeu de données, puis filtrer en mémoire, mais comme Parquet prend en charge le predicate pushdown, Spark peut envoyer la condition de filtrage directement au lecteur Parquet.
Au lieu de lire toutes les lignes puis de vérifier product_category, Spark ne lit que les lignes où product_category = 'Electronics'. Cela permet d'économiser des entrées/sorties de disque et de la mémoire, ce qui accélère le traitement.
explain imprime le plan de requête physique, montrant exactement ce que Spark prévoit de faire pendant l'exécution.
Si le prédicat pushdown est appliqué, vous verrez quelque chose comme :
PushedFilters: [EqualTo(product_category,Electronics)]Cela confirme que Spark a poussé le filtre jusqu'au niveau de l'analyse des fichiers au lieu de l'appliquer après le chargement des données.
Le pushdown de prédicats est l'une des optimisations les plus puissantes de la boîte à outils de Spark. Il :
En écrivant clairement vos filtres et en stockant les données dans des formats comme Parquet, vous permettez à Spark d'optimiser l'exécution sous le capot.

L'optimisation des performances est également cruciale lorsque vous effectuez des jointures dans PySpark. Apprenez à optimiser les jointures PySpark, à réduire les mélanges, à gérer l'asymétrie et à améliorer les performances des pipelines de big data et des flux de travail d'apprentissage automatique grâce à notre site PySpark Joins : Optimiser les performances des jointures Big Data tutoriel.
Lorsque les données sont partitionnées par champs pertinents (par exemple, la date), PySpark peut éviter de charger des partitions inutiles. Un élagage efficace des partitions permet de réduire considérablement les analyses de données et le temps d'exécution.
Supposons que nous disposions d'un ensemble de données Parquet divisé par year et month, stocké à s3://your-bucket/events_data/.
Chaque partition se présente comme suit :
events_data/year=2023/month=01/
events_data/year=2023/month=02/
...
events_data/year=2024/month=01/Un exemple d'élagage de partition dans PySpark ressemblerait à ceci :
df = spark.read.parquet("s3://your-bucket/events_data/")
filtered_df = df.filter((df.year == 2023) & (df.month == 6))
# .explain(True) to verify pruning
filtered_df.explain(True)year et month sont des colonnes de partition, permettant à l'optimiseur Catalyst de Spark d'élaguer toutes les partitions non pertinentes.
Les résultats filtrés sont souvent utilisés plusieurs fois dans le cadre d'un processus d'analyse. Le stockage temporaire en mémoire des résultats filtrés par le biais de la mise en cache permet d'éviter les calculs répétés, mais doit être utilisé avec prudence pour préserver les ressources.
recent_users_df = df.filter(df.registration_date >= '2022-01-01')
recent_users_df.cache()Explorons maintenant des scénarios complexes dans lesquels des techniques de filtrage avancées sont appliquées.
Pour traiter les données de séries temporelles, un filtrage temporel précis est souvent nécessaire. Le filtrage des données dans un laps de temps spécifique est simple :
time_df = df.filter((df.date >= '2023-08-01') & (df.date < '2023-09-01'))L'exemple ci-dessus sélectionne tous les enregistrements à partir d'août 2023. La condition fonctionne avec les colonnes DateType et TimestampType.
Pour une analyse plus approfondie des séries temporelles, telle que le calcul de métriques glissantes ou l'identification de tendances dans le temps, vous pouvez associer des filtres temporels à des fonctions de fenêtre. Par exemple, vous pouvez d'abord filtrer une plage de dates, puis appliquer une moyenne mobile ou classer les événements de chaque jour :
from pyspark.sql.window import Window
from pyspark.sql.functions import avg
window_spec = Window.partitionBy("date").orderBy("timestamp").rowsBetween(-2, 0)
df_filtered = df.filter((df.date >= '2023-08-01') & (df.date < '2023-09-01'))
df_with_avg = df_filtered.withColumn("rolling_avg", avg("value").over(window_spec))Cet exemple calcule une moyenne mobile sur 3 rangées par jour pour les valeurs classées par date d'horodatage. La combinaison de filtres temporels et de fonctions de fenêtre vous permet de contrôler finement les analyses basées sur le temps.
Le filtrage des flux de données en temps réel présente des défis uniques. Contrairement au traitement par lots, les données ne sont pas limitées et arrivent en continu. Cela nécessite l'application de filtres à la volée, avec un traitement minutieux des événements tardifs afin de garantir des résultats précis.
Structured Streaming de PySpark fournit des outils intuitifs pour filtrer les données en continu et gérer efficacement les problèmes de temps. Vous pouvez appliquer des filtres comme vous le feriez sur un DataFrame statique tout en utilisant des filigranes pour contrôler combien de temps le système doit attendre les données en retard avant de finaliser les résultats.
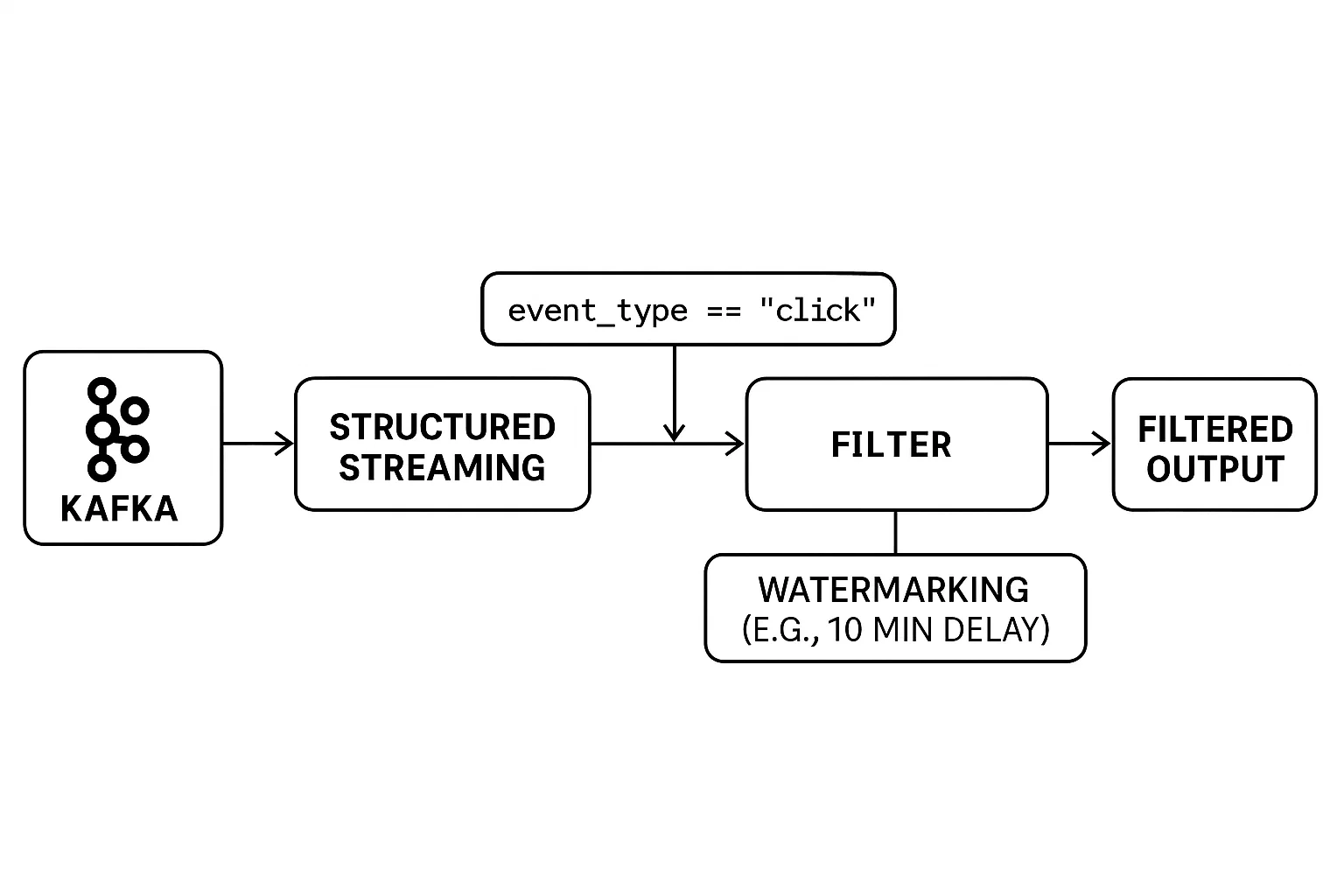
En voici un exemple :
# Example: Real-Time Filtering with Watermarking
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.types import StructType, StringType, TimestampType
# Set up Spark session
spark = SparkSession.builder.appName("RealTimeFiltering").getOrCreate()
# Define schema for streaming data
schema = StructType() \
.add("user_id", StringType()) \
.add("event_type", StringType()) \
.add("event_time", TimestampType())
# Read from a Kafka stream (or any supported source)
streaming_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "user_events") \
.load() \
.selectExpr("CAST(value AS STRING) as json") \
.selectExpr("from_json(json, 'user_id STRING, event_type STRING, event_time TIMESTAMP') as data") \
.select("data.*")
# Apply real-time filter: only 'click' events
filtered_df = streaming_df.filter(col("event_type") == "click")
# Handle late data with watermarking (e.g., 10 minutes tolerance)
filtered_with_watermark = filtered_df \
.withWatermark("event_time", "10 minutes")
# Write to console (for demo purposes)
query = filtered_with_watermark.writeStream \
.outputMode("append") \
.format("console") \
.start()
query.awaitTermination()Dans l'exemple :
.filter(col("event_type") == "click").(withWatermark(...)) permet de s'assurer que les événements tardifs sont traités dans une fenêtre de temps (10 minutes dans ce cas).La combinaison de filtres en temps réel et de filigranes vous permet de créer des applications de diffusion en continu fiables, même en cas de retard du réseau ou d'événements irréguliers.
Dans les pipelines d'apprentissage automatique, un filtrage efficace est essentiel lors du prétraitement. Il est utilisé non seulement pour éliminer le bruit, mais aussi pour sélectionner les caractéristiques les plus pertinentes pour l'apprentissage du modèle. Le filtrage permet d'éliminer les valeurs aberrantes, de supprimer les enregistrements dont les valeurs sont manquantes ou invalides et de ne conserver que les attributs qui fournissent des signaux significatifs.
Cette double approche, qui consiste à nettoyer les données et à sélectionner les caractéristiques clés, peut améliorer considérablement les performances et la fiabilité de vos modèles, comme l'explique notre cours Nettoyage de données avec PySpark. Sans cela, les modèles risquent d'être faussés par des données non pertinentes ou déformés par des données erronées.
Notre cours Big Data avec PySpark entre dans les détails de l'apprentissage automatique dans PySpark.
Dans cette section, nous allons explorer les meilleures pratiques et les défis courants rencontrés lors du filtrage de données avec PySpark.
Voici quelques recommandations pratiques pour améliorer l'efficacité du filtrage :
1. Filtrez le plus tôt possible au cours de la transformation.
2. Limitez le nombre de colonnes sélectionnées pour réduire le brassage des données.
3. Utilisez en priorité les fonctions de filtrage intégrées de PySpark plutôt que des UDF (fonctions définies par l'utilisateur) personnalisées.
Évitez les pièges les plus courants :
Des expressions de filtre trop complexes peuvent gêner l'optimiseur Catalyst de Spark. Par exemple, l'enchaînement de nombreuses conditions OR ou d'instructions logiques profondément imbriquées peut compliquer le plan logique et conduire à une exécution sous-optimale. Dans les scénarios où plusieurs contrôles d'égalité sont impliqués, envisagez d'utiliser isin() ou d'effectuer une jointure avec un DataFrame plus petit pour tirer parti des jointures de diffusion, qui sont plus efficaces pour les grands ensembles de données.
Si la mise en cache est bénéfique pour la réutilisation des DataFrame, son utilisation sans discernement peut épuiser la mémoire du cluster. La mise en cache de DataFrame nombreux ou volumineux sans évaluation de leur réutilisation peut entraîner des erreurs de sortie de mémoire. Il est essentiel de ne mettre en cache que les DataFrame qui sont réutilisés plusieurs fois et de les dépersonnaliser lorsqu'ils ne sont plus nécessaires.
L'asymétrie des données, lorsque certaines clés contiennent des quantités de données disproportionnées, peut entraîner des goulets d'étranglement au niveau des performances. Les opérations telles que les jointures ou les agrégations sur des clés asymétriques peuvent entraîner des temps d'exécution inégaux. Des techniques telles que le salage (ajout de préfixes aléatoires aux clés), le partitionnement personnalisé ou l'utilisation de l'exécution adaptative des requêtes de Spark peuvent contribuer à atténuer ces problèmes.
Un filtrage approprié joue un rôle crucial dans le traitement efficace des données avec PySpark. Il rationalise les flux de travail d'analyse, économise les ressources informatiques et clarifie les résultats analytiques ultérieurs. L'utilisation des méthodes de filtrage simples et puissantes de PySpark, ainsi que des stratégies optimisées telles que le pushdown des prédicats, l'élagage des partitions et la mise en cache sélective, améliore considérablement vos pratiques d'ingénierie des données. L'application cohérente de ces techniques garantit des pipelines de données robustes et faciles à entretenir.
Pour explorer PySpark plus en profondeur, consultez nos cours approfondis sur Spark, notamment :
Les meilleurs cours de DataCamp
Cours
Cours
Cours