
Kurs
Einführung in PySpark
4 Std.
157.5K
Filtern ist ein grundlegender Vorgang in PySpark, der wichtig ist, um große Datensätze schnell zu verfeinern und die relevanten Informationen einzugrenzen. Der effektive Einsatz von Filtern in PySpark kann die Effizienz der Arbeitsabläufe von Dateningenieuren, Datenwissenschaftlern und Entwicklern bei der Verarbeitung von Big Data verbessern.
In diesem Artikel werden grundlegende und fortgeschrittene PySpark-Filtertechniken vorgestellt, Optimierungsstrategien für eine bessere Leistung skizziert und praktische Anwendungsfälle für reale Szenarien behandelt.
Dieses Tutorial setzt einige grundlegende PySpark-Kenntnisse voraus. Was PySpark ist und wie es verwendet werden kann, erfährst du in unserem Tutorial "Erste Schritte mit PySpark".
Wie in unserem Leitfaden PySpark von Grund auf lernen im Jahr 2025 erwähnt, ist PySpark aufgrund seiner Benutzerfreundlichkeit und Effizienz ein weit verbreitetes Tool in der Datenwissenschaft. Es bietet einfache Möglichkeiten, Datensätze mit Hilfe eingebauter Funktionen wie filter() und where() effizient zu filtern. Mit diesen Funktionen können Datenexperten Zeilen aus DataFrames isolieren, die bestimmte Bedingungen erfüllen.
Die Filterung ist entscheidend für die Datenvorverarbeitung, die Analyse und die Optimierung der Pipeline. So kannst du irrelevante oder fehlerhafte Datensätze frühzeitig ausschließen, was Zeit spart, die Kosten senkt und nachfolgende Analysen oder Modellierungsaufgaben verbessert.
Trotz ihrer Einfachheit kann die Anwendung von Filtern in verteilten Umgebungen Herausforderungen wie Leistungsengpässe, ineffiziente oder komplexe Filterbedingungen und den unsachgemäßen Umgang mit fehlenden oder unvollständigen Daten mit sich bringen.
Das Verständnis von Spark-Filtern ist wichtig, um ein Vorstellungsgespräch in der Datentechnik zu bestehen.
Beherrsche die wichtigsten Themen und Fragen, die in Big-Data-Interviews gestellt werden, von grundlegenden Konzepten wie Datenspeicherung und verteiltem Rechnen bis hin zu fortgeschrittenen Bereichen wie maschinelles Lernen und Sicherheit, mit unserem Top 30+ Big Data Interview Questions Tutorial.
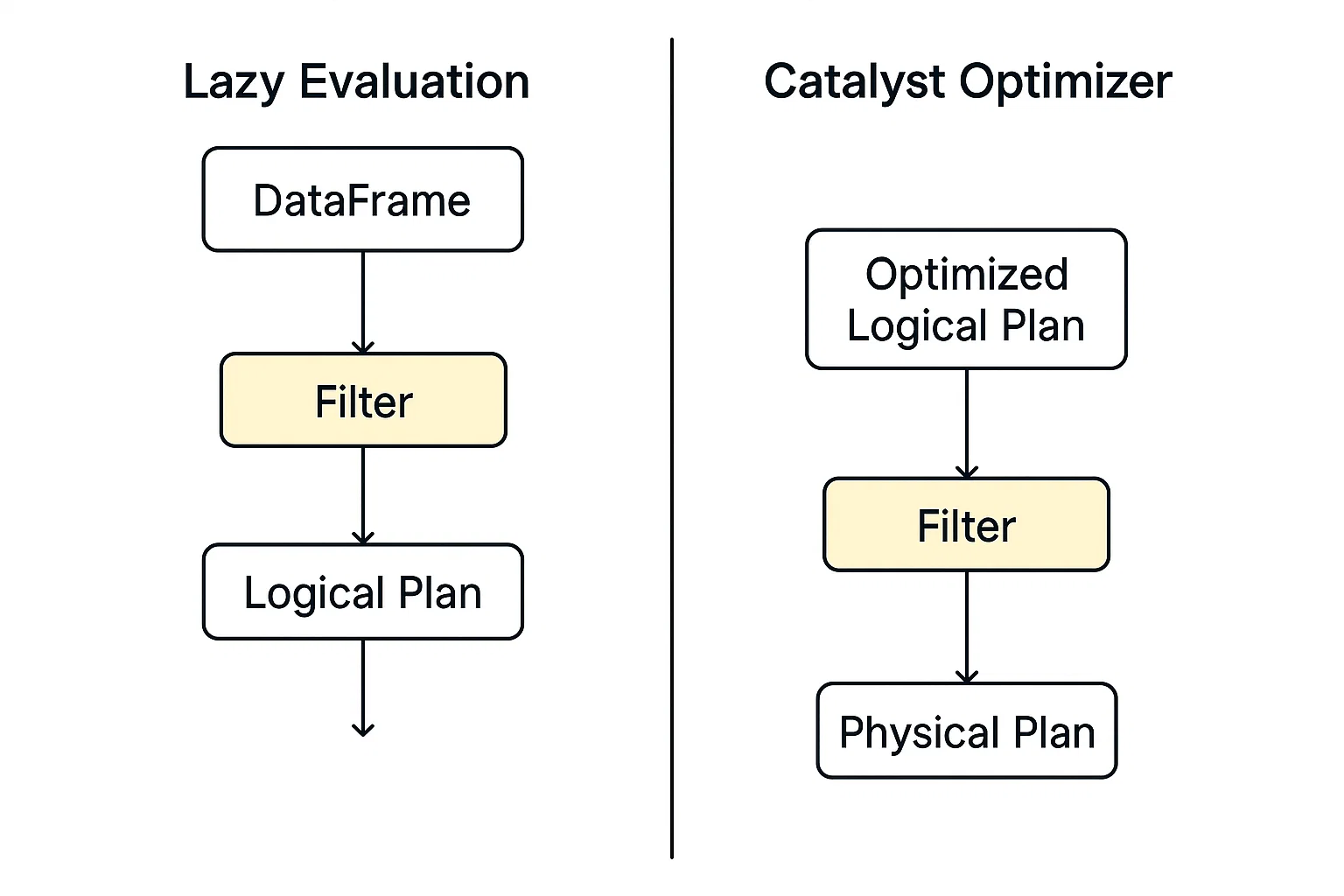
Die Filterung in PySpark erfolgt im Rahmen des verteilten Ausführungsmodells, das auf Apache Spark aufbaut. Wenn du einen Filter anwendest (z. B. mit .filter() oder .where())), durchsucht PySpark die Daten nicht sofort. Stattdessen wird ein logischer Abfrageplan erstellt, der die Transformationen beschreibt, die du durchführen möchtest.
Zwei zentrale Konzepte beeinflussen die Effizienz der Filterung in PySpark maßgeblich:
PySpark führt einen Filterbefehl nicht sofort aus; stattdessen erstellt es einen logischen Abfrageplan und schiebt die Aktion auf, bis es explizit zur Ausführung aufgefordert wird. Dieses Modell ermöglicht PySpark eine größere Flexibilität bei der Optimierung von Vorgängen in Datenpipelines.
Diese Optimierungs-Engine in Spark wertet logische Pläne aus, einschließlich der Filterung, und ermittelt automatisch den schnellsten und effizientesten Weg, um sie auszuführen.
Wenn die Ausführung beginnt, werden die gefilterten Daten mithilfe von RDDs oder DataFrames parallel auf den Worker-Knoten verarbeitet. Jede Partition wendet den Filter unabhängig an, sodass er für große Datensätze skalierbar ist.
Weitere Informationen über RDDs findest du in unserem PySpark Cheat Sheet: Spark in Python tutorial.
Das Filtern von Daten auf der Grundlage von Bedingungen ist ganz einfach. Du kannst Bedingungen als Spaltenausdrücke oder SQL-ähnliche Zeichenketten angeben.
Verwende DataFrame-Spaltenobjekte und Operatoren, um Bedingungen zu definieren:
filtered_data = df.filter(df.age > 25)Schreibe die Bedingung als String im SQL-Stil:
filtered_data_2 = df.filter("age > 25")Alternativ dazu kannst du auch dieFunktion where() verwenden:
filtered_data_3 = df.where(df.age > 25)
filtered_data_4 = df.where("age > 25")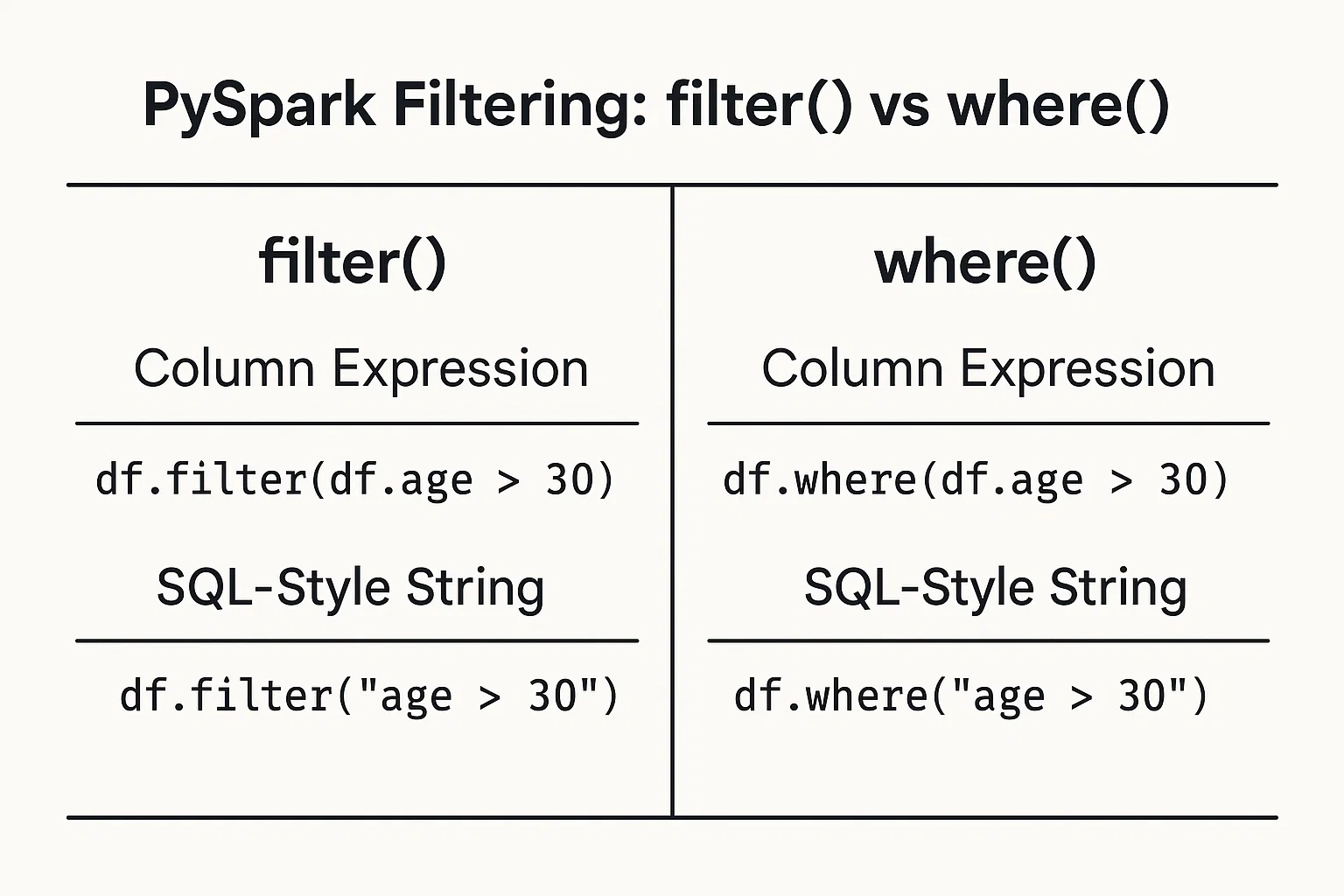
Alle diese Methoden sind gültig und führen zum gleichen Ergebnis. Die Wahl zwischen diesen beiden Stilen hängt oft von persönlichen Vorlieben ab oder davon, welcher Stil sich in deinem speziellen Kontext besser lesen lässt.
Wenn du mehr über die Verwendung der SQL-Syntax in PySpark erfahren möchtest, besuche unseren Kurs Einführung in Spark SQL in Python.
Sehen wir uns nun verschiedene Filtermethoden und ihre praktischen Anwendungsfälle an.
Du kannst mit relationalen Operatoren wie "größer als >", "kleiner als <", "gleich ==" und anderen filtern, um Daten anhand von numerischen oder kategorischen Schwellenwerten zu isolieren:
greater_than_df = df.filter(df.salary > 50000)
category_match_df = df.filter(df.country == 'France')Um mehrere Bedingungen in einem Filter zu kombinieren, können logische Operatoren wie AND &, OR | und NOT ~ prägnante Ausdrücke für komplexe Anforderungen erstellen:
combined_df = df.filter((df.age > 25) & (df.city == 'New York'))PySpark enthält erweiterte Funktionen für spezielle Filterungsfälle. Lass uns einige von ihnen erkunden.
Mitgliedschaftstests: Um Werte aus einer vordefinierten Menge mit isin zu filtern:
selected_countries_df = df.filter(df.country.isin('Japan', 'Brazil', 'India'))Mustervergleiche: Filterung nach Textmustern mit like für einfache Übereinstimmungen und rlike für Regex:
name_filter_df = df.filter(df.name.like('A%'))
regex_filter_df = df.filter(df.name.rlike('^[A-Z][a-z]+Bereichsfilter: Filtern mit praktischen Methoden wie between:
range_df = df.filter(df.age.between(25, 35))Null-Checks: Sorgfältiger Umgang mit fehlenden Werten durch explizite Überprüfung von Nullen:
valid_email_df = df.filter(df.email.isNotNull())Unternehmen verwenden oft verschachtelte oder strukturierte Daten. PySpark kann verschachtelte Felder und Arrays filtern. Bei strukturierten Daten (Structs) kannst du verschachtelte Felder einfach filtern:
city_df = df.filter(df.address.city == 'Boston')Für Daten, die als Arrays gespeichert sind, kannst du eingebaute Funktionen wie array_contains verwenden:
from pyspark.sql.functions import array_contains
skill_df = df.filter(array_contains(df.skills, 'Python'))In diesem Abschnitt erfährst du, mit welchen Strategien du die Leistung von Filteroperationen in PySpark verbessern kannst.
Beim Prädikats-Pushdown werden die Filterbedingungen so nah wie möglich an der Datenspeicherebene platziert. Das bedeutet, dass PySpark anfangs weniger Daten liest, was die Leistung verbessert.
Zum Beispiel:
# Read from a Parquet file
df = spark.read.parquet("s3://your-bucket/sales_data/")
# Apply filter on a non-partition column (e.g., product_category)
filtered_df = df.filter(df.product_category == "Electronics")
# Trigger query plan inspection
filtered_df.explain(True)Im obigen Beispiel wenden wir einen Filter auf eine reguläre Spalte an. Normalerweise würde Spark den gesamten Datensatz laden und dann im Speicher filtern. Da Parquet jedoch Prädikat-Pushdown unterstützt, kann Spark die Filterbedingung direkt an den Parquet-Leser senden.
Anstatt alle Zeilen zu lesen und dann product_category zu überprüfen, liest Spark nur die Zeilen, in denen product_category = 'Electronics'. Das spart Festplatten-E/A und Speicherplatz und beschleunigt die Verarbeitung.
explain gibt den physischen Abfrageplan aus, der genau zeigt, was Spark während der Ausführung plant.
Wenn das Prädikat "pushdown" angewendet wird, siehst du so etwas wie:
PushedFilters: [EqualTo(product_category,Electronics)]Dies bestätigt, dass Spark den Filter auf die Ebene des Dateiscans verlagert hat, anstatt ihn nach dem Laden der Daten anzuwenden.
Der Prädikats-Pushdown ist eine der leistungsstärksten Optimierungen im Spark-Toolkit. Es:
Wenn du deine Filter klar schreibst und Daten in Formaten wie Parquet speicherst, kannst du Spark die Ausführung unter der Haube optimieren.

Die Leistungsoptimierung ist auch bei der Durchführung von Joins in PySpark entscheidend. In unserem PySpark Joins erfährst du, wie du PySpark-Joins optimierst, Shuffles reduzierst, Skew handhabst und die Leistung von Big-Data-Pipelines und Machine-Learning-Workflows verbesserst: Optimize Big Data Join Performance tutorial.
Wenn die Daten nach relevanten Feldern (z. B. Datum) aufgeteilt sind, kann PySpark das Laden unnötiger Partitionen vermeiden. Ein effektives Partition Pruning reduziert das Scannen der Daten und die Ausführungszeit erheblich.
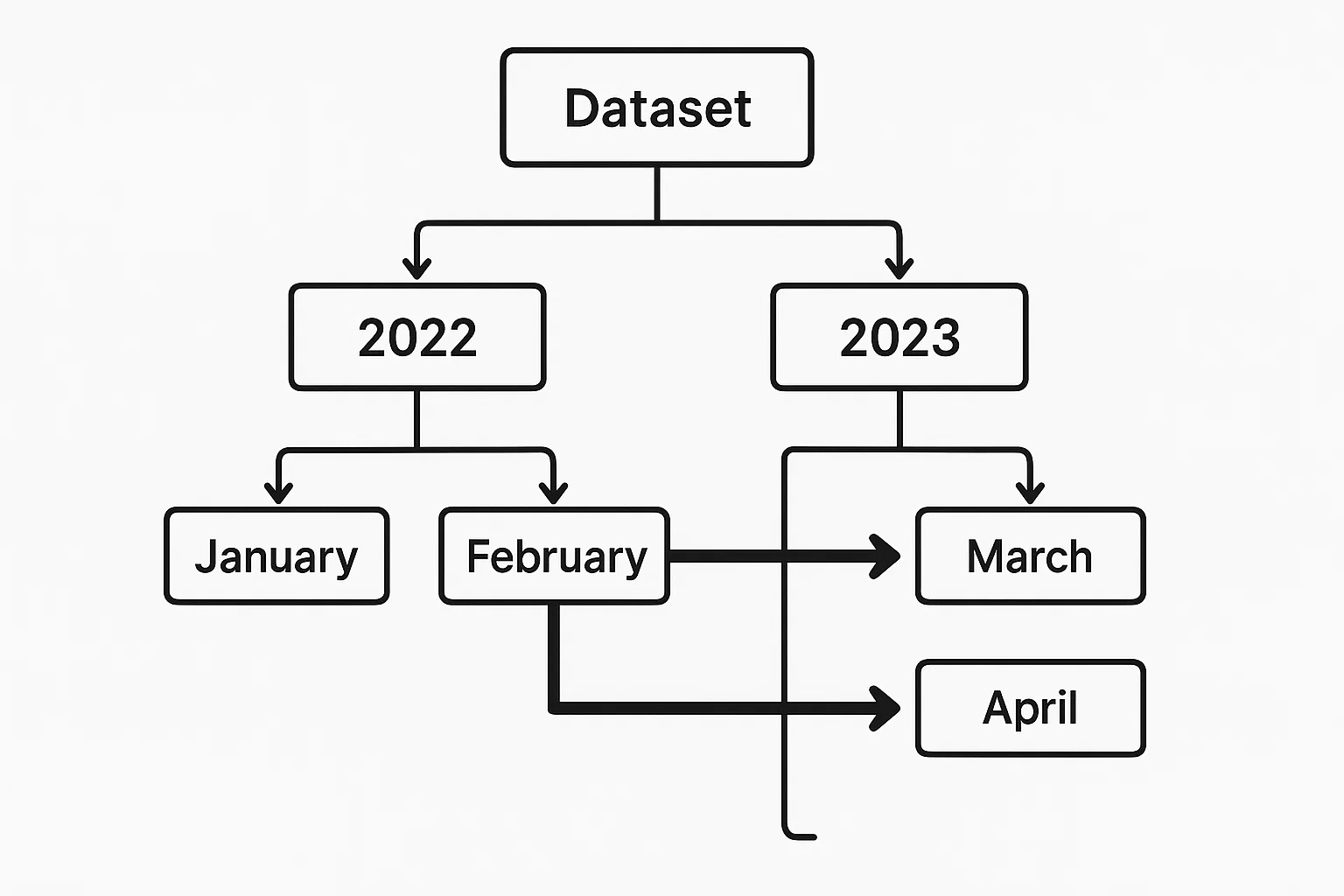
Angenommen, wir haben einen Parquet-Datensatz, der durch year und month partitioniert ist und auf s3://your-bucket/events_data/ gespeichert wird.
Jede Partition sieht wie folgt aus:
events_data/year=2023/month=01/
events_data/year=2023/month=02/
...
events_data/year=2024/month=01/Ein Beispiel für Partition Pruning in PySpark würde so aussehen:
df = spark.read.parquet("s3://your-bucket/events_data/")
filtered_df = df.filter((df.year == 2023) & (df.month == 6))
# .explain(True) to verify pruning
filtered_df.explain(True)year und month sind Partitionsspalten, die es dem Catalyst-Optimierer von Spark ermöglichen, alle irrelevanten Partitionen zu entfernen.
Gefilterte Ergebnisse werden oft mehrfach in einem Analyse-Workflow verwendet. Das Zwischenspeichern gefilterter Ergebnisse im Speicher hilft, wiederholte Berechnungen zu vermeiden, sollte aber mit Bedacht eingesetzt werden, um Ressourcen zu sparen.
recent_users_df = df.filter(df.registration_date >= '2022-01-01')
recent_users_df.cache()Lass uns nun komplexe Szenarien untersuchen, in denen fortgeschrittene Filtertechniken angewendet werden.
Für die Verarbeitung von Zeitreihendaten ist häufig eine präzise zeitliche Filterung erforderlich. Das Filtern von Daten innerhalb eines bestimmten Zeitrahmens ist ganz einfach:
time_df = df.filter((df.date >= '2023-08-01') & (df.date < '2023-09-01'))Die obige Auswahl umfasst alle Datensätze ab August 2023. Die Bedingung funktioniert sowohl mit DateType als auch mit TimestampType Spalten.
Für tiefer gehende Zeitreihenanalysen, wie z. B. die Berechnung von rollierenden Kennzahlen oder die Ermittlung von Trends im Zeitverlauf, kannst du zeitliche Filter mit Fensterfunktionen kombinieren. Du könntest zum Beispiel zuerst einen Datumsbereich filtern und dann einen gleitenden Durchschnitt anwenden oder die Ereignisse innerhalb eines Tages ordnen:
from pyspark.sql.window import Window
from pyspark.sql.functions import avg
window_spec = Window.partitionBy("date").orderBy("timestamp").rowsBetween(-2, 0)
df_filtered = df.filter((df.date >= '2023-08-01') & (df.date < '2023-09-01'))
df_with_avg = df_filtered.withColumn("rolling_avg", avg("value").over(window_spec))In diesem Beispiel wird ein 3-zeiliger gleitender Durchschnitt pro Tag für die nach Zeitstempel geordneten Werte berechnet. Durch die Kombination von zeitlichen Filtern mit Fensterfunktionen erhältst du eine feinkörnige Kontrolle über zeitbasierte Analysen.
Das Filtern von Echtzeit-Datenströmen ist eine besondere Herausforderung. Anders als bei der Stapelverarbeitung sind die Daten unbegrenzt und treffen kontinuierlich ein. Dies erfordert, dass Filter im laufenden Betrieb angewendet werden und dass spät eintreffende Ereignisse sorgfältig behandelt werden, um genaue Ergebnisse zu gewährleisten.
Das strukturierte Streaming von PySpark bietet intuitive Werkzeuge, um Streaming-Daten zu filtern und Timing-Probleme effektiv zu lösen. Du kannst Filter wie bei einem statischen DataFrame anwenden und mit Wasserzeichen steuern, wie lange das System auf verspätete Daten warten soll, bevor es die Ergebnisse abschließt.
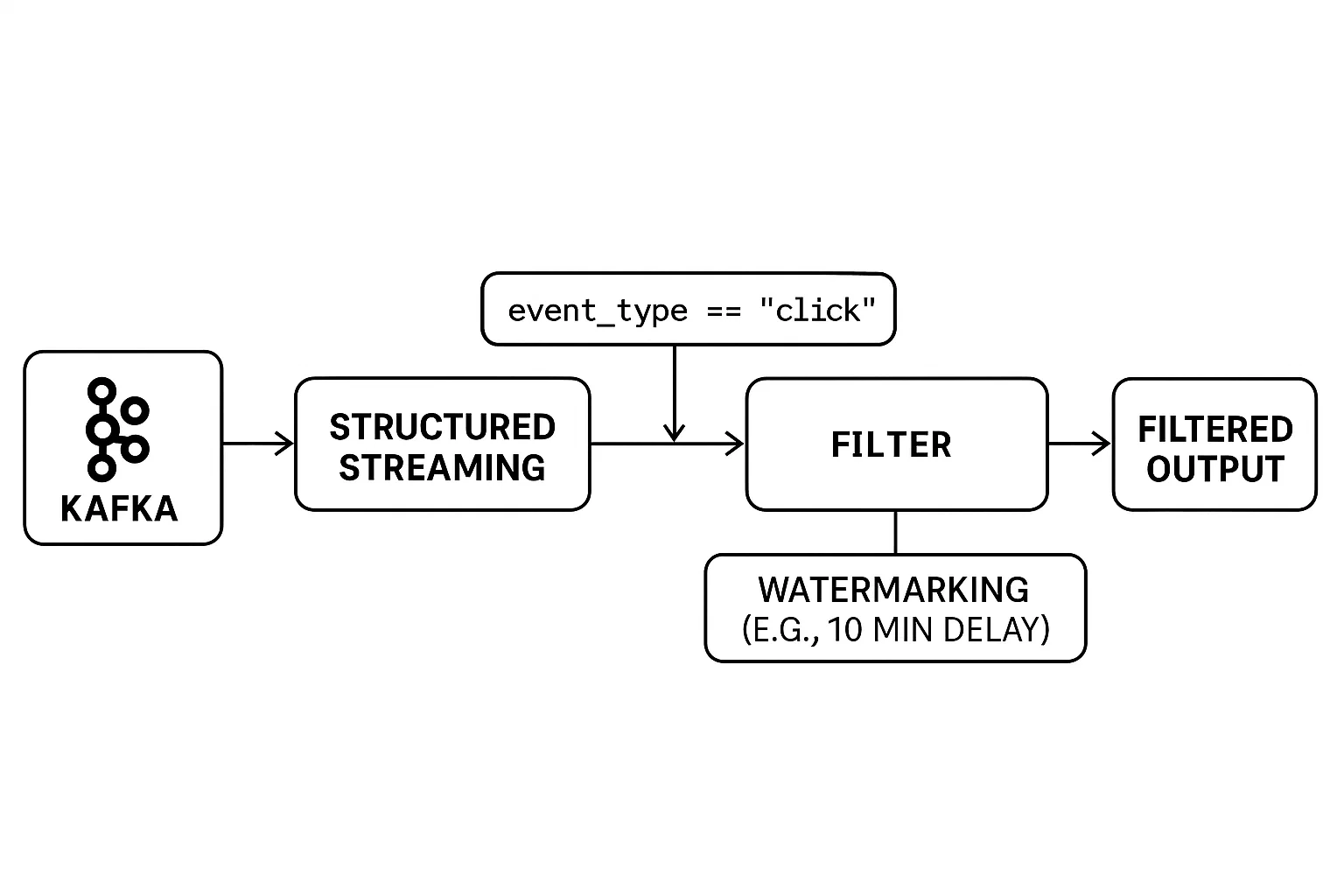
Hier ist ein Beispiel:
# Example: Real-Time Filtering with Watermarking
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.types import StructType, StringType, TimestampType
# Set up Spark session
spark = SparkSession.builder.appName("RealTimeFiltering").getOrCreate()
# Define schema for streaming data
schema = StructType() \
.add("user_id", StringType()) \
.add("event_type", StringType()) \
.add("event_time", TimestampType())
# Read from a Kafka stream (or any supported source)
streaming_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "user_events") \
.load() \
.selectExpr("CAST(value AS STRING) as json") \
.selectExpr("from_json(json, 'user_id STRING, event_type STRING, event_time TIMESTAMP') as data") \
.select("data.*")
# Apply real-time filter: only 'click' events
filtered_df = streaming_df.filter(col("event_type") == "click")
# Handle late data with watermarking (e.g., 10 minutes tolerance)
filtered_with_watermark = filtered_df \
.withWatermark("event_time", "10 minutes")
# Write to console (for demo purposes)
query = filtered_with_watermark.writeStream \
.outputMode("append") \
.format("console") \
.start()
query.awaitTermination()In diesem Beispiel:
.filter(col("event_type") == "click").(withWatermark(...)) stellt sicher, dass spät eintreffende Ereignisse innerhalb eines Zeitfensters (in diesem Fall 10 Minuten) bearbeitet werden.Die Kombination von Echtzeitfiltern und Wasserzeichen ermöglicht es dir, selbst bei Netzwerkverzögerungen oder unregelmäßigen Ereignissen zuverlässige Streaming-Anwendungen zu erstellen.
In Pipelines für maschinelles Lernen ist eine effektive Filterung während der Vorverarbeitung entscheidend. Sie wird nicht nur zum Entfernen von Rauschen verwendet, sondern auch zur Auswahl der wichtigsten Merkmale für das Modelltraining. Die Filterung hilft dabei, Ausreißer zu eliminieren, Datensätze mit fehlenden oder ungültigen Werten auszuschließen und nur die Attribute zu behalten, die aussagekräftige Signale liefern.
Dieser doppelte Ansatz, nämlich das Bereinigen der Daten und das Auswählen von Schlüsselmerkmalen, kann sowohl die Leistung als auch die Zuverlässigkeit deiner Modelle drastisch verbessern, wie in unserem Kurs "Daten bereinigen mit PySpark " beschrieben. Ohne sie besteht die Gefahr, dass Modelle durch irrelevante Eingaben verzerrt oder durch schlechte Daten verfälscht werden.
In unserem Kurs Big Data mit PySpark gehen wir näher auf das maschinelle Lernen in PySpark ein.
In diesem Abschnitt werden wir uns mit den besten Methoden und den häufigsten Herausforderungen beim Filtern von Daten mit PySpark beschäftigen.
Hier sind einige praktische Empfehlungen, wie du die Effizienz der Filterung verbessern kannst:
1. Filtere so früh wie möglich während der Verarbeitung.
2. Schränke die Anzahl der ausgewählten Spalten ein, um das Mischen der Daten zu reduzieren.
3. Verwende vorrangig die in PySpark eingebauten Filterfunktionen statt benutzerdefinierter UDFs (User-Defined Functions).
Vermeide häufige Fallstricke:
Zu komplizierte Filterausdrücke können den Catalyst-Optimierer von Spark behindern. Zum Beispiel kann die Verkettung zahlreicher OR Bedingungen oder tief verschachtelter logischer Anweisungen den logischen Plan verkomplizieren und zu einer suboptimalen Ausführung führen. In Szenarien, in denen mehrere Gleichheitsprüfungen erforderlich sind, solltest du isin() verwenden oder einen Join mit einem kleineren DataFrame durchführen, um Broadcast-Joins zu nutzen, die bei großen Datensätzen effizienter sind.
Die Zwischenspeicherung ist zwar von Vorteil für die Wiederverwendung von DataFrames, aber bei wahlloser Verwendung kann der Speicher des Clusters erschöpft werden. Das Zwischenspeichern großer oder zahlreicher DataFrames, ohne ihre Wiederverwendung zu prüfen, kann zu Out-of-Memory-Fehlern führen. Es ist wichtig, dass nur die DataFrames zwischengespeichert werden, die mehrfach verwendet werden, und dass sie wieder entfernt werden, wenn sie nicht mehr benötigt werden.
Datenschieflage, bei der bestimmte Schlüssel überproportional viele Daten enthalten, kann zu Leistungsengpässen führen. Operationen wie Joins oder Aggregationen auf schiefen Schlüsseln können zu ungleichen Ausführungszeiten von Aufgaben führen. Techniken wie Salting (das Hinzufügen von zufälligen Präfixen zu den Schlüsseln), benutzerdefinierte Partitionierung oder die Verwendung der adaptiven Abfrageausführung von Spark können dazu beitragen, diese Probleme zu entschärfen.
Richtiges Filtern spielt eine entscheidende Rolle bei der effizienten Datenverarbeitung mit PySpark. Es strafft die Analyseabläufe, spart Rechenressourcen und schafft Klarheit bei den späteren Analyseergebnissen. Die Nutzung der einfachen, aber leistungsstarken Filtermethoden von PySpark zusammen mit optimierten Strategien wie Predicate Pushdown, Partition Pruning und Selective Caching verbessert deine Data Engineering-Praktiken erheblich. Die konsequente Anwendung dieser Techniken gewährleistet robuste und wartbare Datenpipelines.
Wenn du mehr über PySpark erfahren möchtest, schau dir unsere ausführlichen Spark-Kurse an, z. B:
Top DataCamp Kurse
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
