
Curso
Fundamentos de PySpark
4 h
157.5K
PySpark es la combinación de dos potentes tecnologías: Python y Apache Spark.
Python es uno de los lenguajes de programación más utilizados en el desarrollo de software, especialmente para la ciencia de datos y machine learning, debido principalmente a su sintaxis sencilla y fácil de usar.
Por otro lado, Apache Spark es un marco de trabajo capaz de gestionar grandes cantidades de datos no estructurados. Spark se ha creado utilizando Scala, un lenguaje que nos permite un mayor control sobre él. Sin embargo, Scala no es un lenguaje de programación popular entre los profesionales de los datos. Por lo tanto, PySpark se creó para superar esta brecha.
PySpark ofrece una API y una interfaz fácil de usar para interactuar con Spark. Aprovecha la simplicidad y flexibilidad de Python para hacer que el procesamiento de big data sea accesible a un público más amplio.
En los últimos años, PySpark se ha convertido en una herramienta importante para los profesionales de datos que necesitan procesar grandes cantidades de datos. Podemos explicar tu popularidad por varios factores clave:
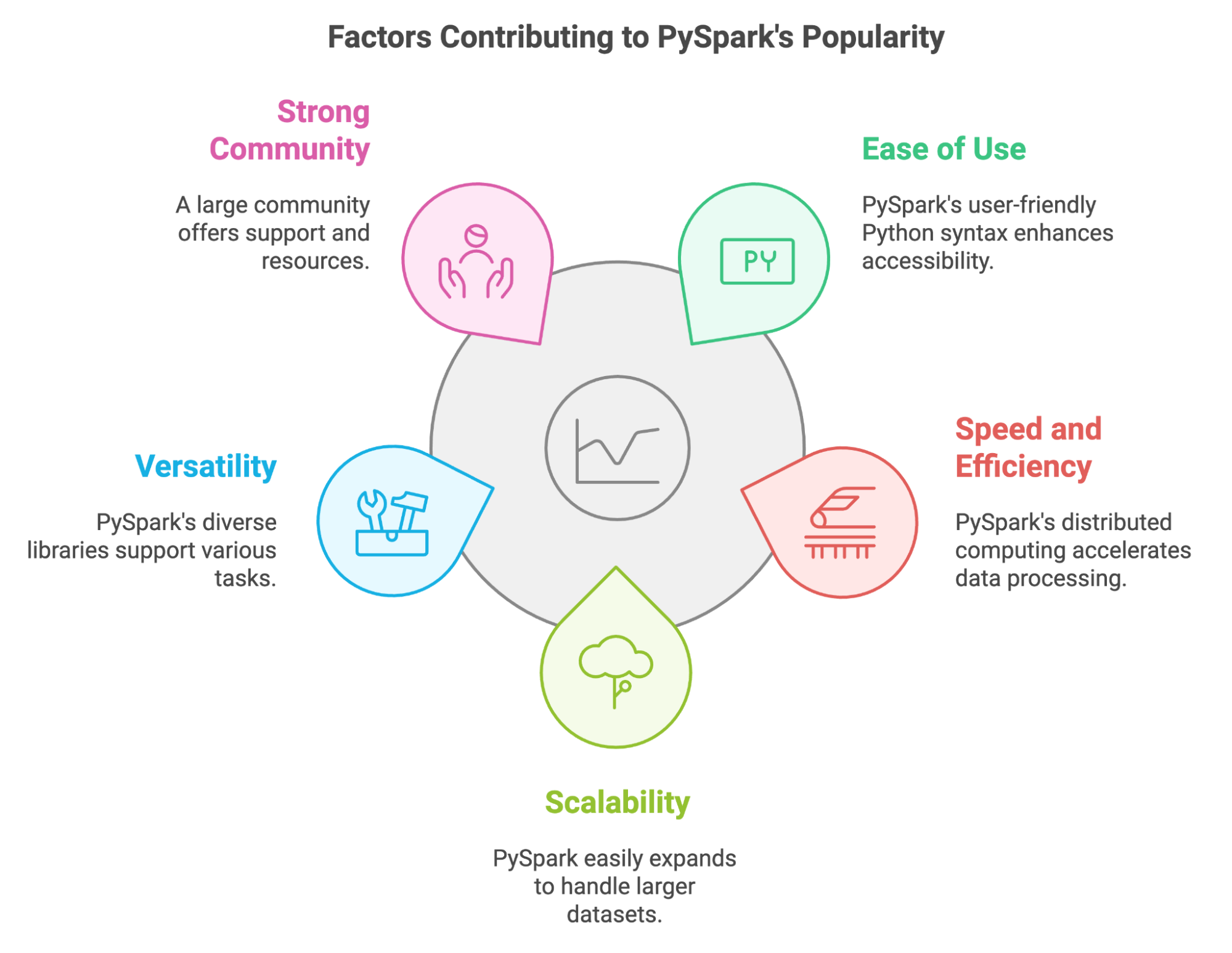
PySpark también nos permite aprovechar los conocimientos y las bibliotecas de Python existentes. Podemos integrarlo fácilmente con herramientas populares como Pandas y Scikit-learn, y nos permite utilizar diversas fuentes de datos.
PySpark se creó especialmente para big data y machine learning. Pero, ¿qué características lo convierten en una herramienta tan potente para manejar grandes cantidades de datos? Echemos un vistazo a ellos:
El volumen de datos no deja de aumentar. Hoy en día, las tareas de gestión de datos, análisis de datos y machine learning implican trabajar con grandes cantidades de datos. Necesitamos utilizar herramientas potentes que procesen esos datos de manera eficiente y rápida. PySpark es una de esas herramientas.
Ya hemos mencionado las ventajas de PySpark, pero veamos algunos ejemplos concretos en los que puedes utilizarlas:
Con el auge de la ciencia de datos y machine learning, y el aumento de los datos disponibles, existe una gran demanda de profesionales con habilidades para la manipulación de datos. Según el informe «The State of Data & AI Literacy Report 2024», el 80 % de los líderes valoran las habilidades de análisis y manipulación de datos.
Aprender PySpark puede abrirte un amplio abanico de oportunidades profesionales. Más de 800 ofertas de empleo en Indeed, desde ingenieros de datos hasta científicos de datos, ponen de relieve la demanda de conocimientos de PySpark en ofertas de trabajo relacionadas con los datos.
Si aprendes PySpark de forma metódica, tendrás más posibilidades de éxito. Centrémonos en algunos principios que puedes utilizar en tu proceso de aprendizaje.
Antes de aprender los detalles técnicos, define tu motivación para aprender PySpark. Pregúntate a ti mismo:
Una vez identificados tus objetivos, domina los conceptos básicos de PySpark y comprende cómo funcionan.
Dado que PySpark se basa en Python, debes familiarizarte con Python antes de utilizar PySpark. Debes sentirte cómodo trabajando con variables y funciones. Además, puede ser una buena idea familiarizarse con bibliotecas de manipulación de datos como Pandas. Curso de introducción a Python de DataCamp Introducción a Python y Manipulación de datos con Pandas pueden ayudarte a ponerte al día.
Debes instalar PySpark para empezar a utilizarlo. Puedes descargar PySpark utilizando pip o Conda, descargarlo manualmente desde el sitio web oficial o empezar con DataLab para empezar a utilizar PySpark en tu navegador.
Si deseas obtener una explicación detallada sobre cómo configurar PySpark, consulta esta guía sobre cómo instalar PySpark en Windows, Mac y Linux.
El primer concepto que debes aprender es cómo funcionan los DataFrame de PySpark. Son una de las razones principales por las que PySpark funciona de forma tan rápida y eficiente. Comprender cómo crearlos, transformarlos (mapearlos y filtrarlos) y manipularlos. El tutorial sobre cómo empezar a trabajar con PySpark te ayudará con estos conceptos.
Una vez que te sientas cómodo con los conceptos básicos, es hora de explorar las habilidades intermedias de PySpark.
Una de las mayores ventajas de PySpark es su capacidad para realizar consultas similares a SQL para leer y manipular DataFrame, realizar agregaciones y utilizar funciones de ventana. Entre bastidores, PySpark utiliza Spark SQL. Esta introducción a Spark SQL en Python puede ayudarte a adquirir esta habilidad.
Trabajar con datos implica dominar las tareas de limpieza, transformación y preparación de los mismos para su análisis. Esto incluye gestionar valores perdidos, administrar diferentes tipos de datos y realizar agregaciones utilizando PySpark. Toma el Curso de limpieza de datos con PySpark de DataCamp para adquirir experiencia práctica y dominar estas habilidades.
PySpark también se puede utilizar para desarrollar e implementar modelos de machine learning, gracias a tu biblioteca MLlib. Debes aprender a realizar ingeniería de características, evaluación de modelos y ajuste de hiperparámetros utilizando esta biblioteca. DataCamp's Machine learning con PySpark ofrece una introducción completa.
Realizar cursos y practicar ejercicios con PySpark es una forma excelente de familiarizarse con la tecnología. Sin embargo, para dominar PySpark, es necesario resolver problemas desafiantes y que permitan desarrollar habilidades, como los que se encuentran en proyectos del mundo real. Puedes empezar realizando tareas sencillas de análisis de datos y pasar gradualmente a retos más complejos.
Aquí tienes algunas formas de practicar tus habilidades:
A medida que avances en tu aprendizaje de PySpark, completarás diferentes proyectos. Para mostrar tus habilidades y experiencia en PySpark a posibles empleadores, debes recopilarlas en un portafolio. Este portafolio debe reflejar tus habilidades e intereses y estar adaptado a la carrera o industria que te interesa.
Intenta que tus proyectos sean originales y demuestren tu capacidad para resolver problemas. Incluye proyectos que demuestren tu dominio de diversos aspectos de PySpark, como el manejo de datos, machine learning y la visualización de datos. Documenta tus proyectos, proporcionando contexto, metodología, código y resultados. Puedes utilizar DataLab, un IDE en línea que te permite escribir código, analizar datos de forma colaborativa y compartir tus conocimientos.
Aquí tienes dos proyectos PySpark en los que puedes trabajar:
Aprender PySpark es un proceso continuo. La tecnología evoluciona constantemente y se desarrollan nuevas funciones y aplicaciones con regularidad. PySpark no es una excepción.
Una vez que domines los fundamentos, podrás buscar tareas y proyectos más desafiantes, como la optimización del rendimiento o GraphX. Céntrate en tus objetivos y especialízate en áreas que sean relevantes para tus metas profesionales y tus intereses.
Mantente al día de las últimas novedades y aprende a aplicarlas a tus proyectos actuales. Sigue practicando, busca nuevos retos y oportunidades, y acepta la idea de cometer errores como una forma de aprender.
Recapitulemos los pasos que podemos seguir para elaborar un plan de aprendizaje de PySpark satisfactorio:
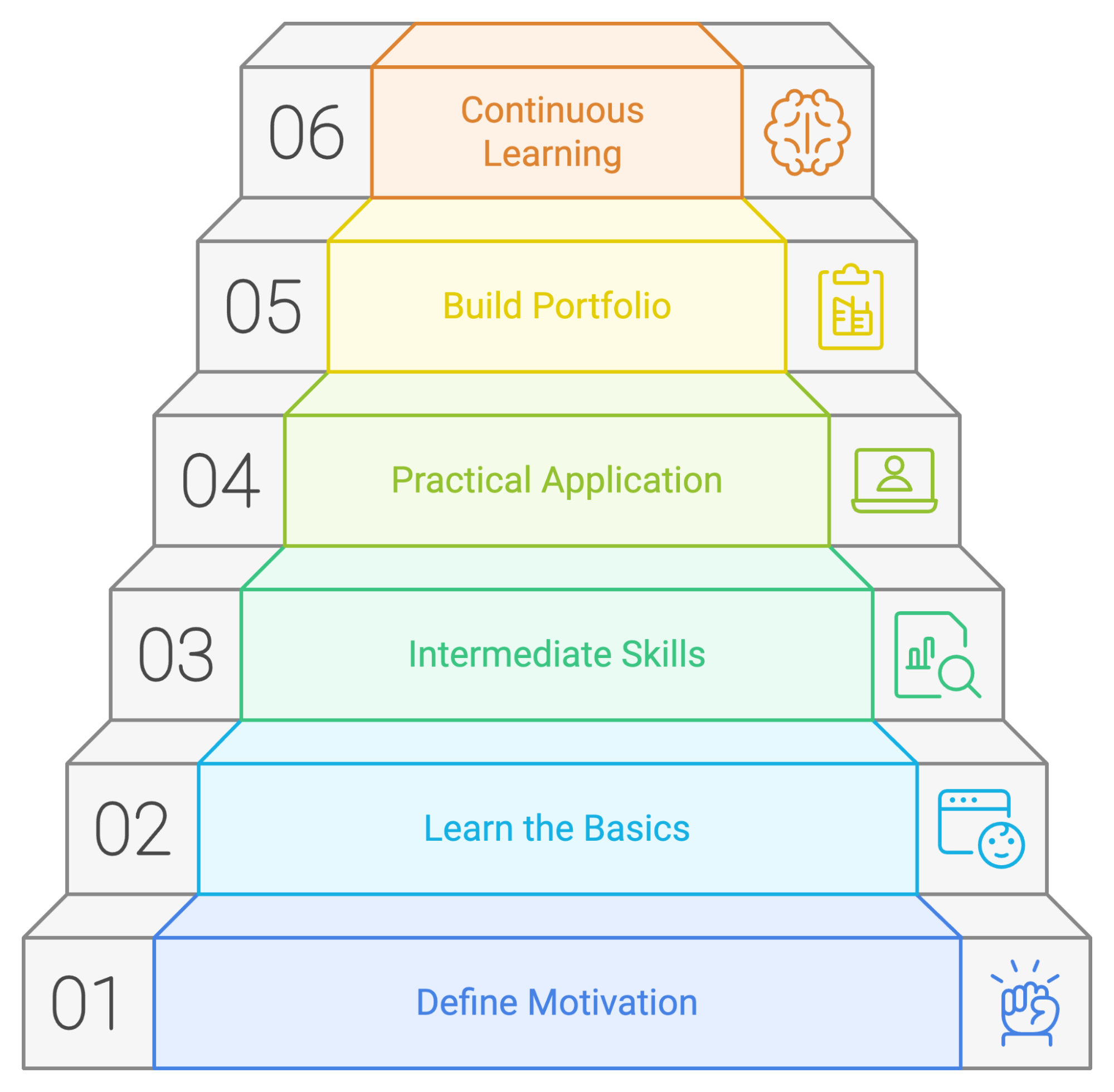
Aunque cada persona tiene su propia forma de aprender, siempre es buena idea contar con un plan o una guía que seguir para aprender a utilizar una nueva herramienta. Hemos creado un posible plan de aprendizaje en el que se describe dónde debes centrar tu tiempo y tus esfuerzos si acabas de empezar con PySpark.
Imagino que a estas alturas ya estás listo para lanzarte a aprender PySpark y poner en práctica tus nuevos conocimientos con un gran conjunto de datos. Pero antes de hacerlo, permíteme destacar estos consejos que te ayudarán a recorrer el camino hacia el dominio de PySpark.
PySpark es una herramienta que puede tener muchas aplicaciones diferentes. Para mantener la concentración y alcanzar tu objetivo, debes identificar tu área de interés. ¿Quieres centrarte en el análisis de datos, la ingeniería de datos o machine learning? Adoptar un enfoque específico puede ayudarte a adquirir los aspectos y conocimientos más relevantes de PySpark para la trayectoria que hayas elegido.
La constancia es clave para dominar cualquier habilidad nueva. Debes reservar tiempo específico para practicar con PySpark. Solo necesitas dedicarle un poco de tiempo cada día. No es necesario que abordes conceptos complejos todos los días. Puedes repasar lo que has aprendido o volver a realizar un ejercicio sencillo para refactorizarlo. La práctica regular reforzará tu comprensión de los conceptos y aumentará tu confianza a la hora de aplicarlos.
Este es uno de los consejos clave, y lo leerás varias veces en esta guía. Practicar ejercicios es ideal para ganar confianza. Sin embargo, aplicar tus habilidades en PySpark a proyectos del mundo real es lo que te hará destacar en este campo. Busca conjuntos de datos que te interesen y utiliza PySpark para analizarlos, extraer información y resolver problemas.
Empieza con proyectos y preguntas sencillos y ve pasando gradualmente a otros más complejos. Esto puede ser tan sencillo como leer y limpiar un conjunto de datos reales y escribir una consulta compleja para realizar agregaciones y predecir el precio de una casa.
El aprendizaje suele ser más eficaz cuando se realiza de forma colaborativa. Compartir tus experiencias y aprender de los demás puede acelerar tu progreso y proporcionarte información valiosa.
Para intercambiar conocimientos, ideas y preguntas, puedes unirte a algunos grupos relacionados con PySpark y asistir a reuniones y conferencias. La comunidad Databricks, la empresa fundada por los creadores de Spark, cuenta con un foro comunitario muy activo en el que puedes participar en debates y plantear preguntas sobre PySpark. Además, la Spark Summit, organizada por Databricks, es la mayor conferencia sobre Spark.
Al igual que con cualquier otra tecnología, aprender PySpark es un proceso iterativo. Y aprender de tus errores es una parte esencial del proceso de aprendizaje. No tengas miedo de experimentar, prueba diferentes enfoques y aprende de tus errores. Prueba diferentes funciones y alternativas para agregar los datos, realiza subconsultas o consultas anidadas y observa la rápida respuesta que ofrece PySpark.
Veamos algunos métodos eficaces para aprender PySpark.
Los cursos en línea ofrecen una excelente manera de aprender PySpark a tu propio ritmo. DataCamp ofrece cursos de PySpark para todos los niveles, que en conjunto conforman el Big Data con PySpark programa Los cursos abarcan conceptos introductorios sobre temas relacionados con machine learning y están diseñados con ejercicios prácticos.
Estos son algunos de los cursos relacionados con PySpark que se imparten en DataCamp:
Los tutoriales son otra forma estupenda de aprender PySpark, especialmente si eres nuevo en esta tecnología. Contienen instrucciones paso a paso sobre cómo realizar tareas específicas o comprender determinados conceptos. Para empezar, ten en cuenta estos tutoriales:
Las hojas de referencia son útiles cuando necesitas una guía rápida sobre temas relacionados con PySpark. Aquí hay dos hojas de referencia útiles:
Para aprender PySpark es necesario practicar. Enfrentar retos mientras completas proyectos que te permitirán aplicar todas las habilidades que has aprendido. A medida que empieces a asumir tareas más complejas, necesitarás encontrar soluciones e investigar nuevas alternativas para obtener los resultados que deseas, lo que te permitirá mejorar tus conocimientos sobre PySpark.
Busca proyectos PySpark en los que trabajar en DataCamp. Esto te permite aplicar tus habilidades de manipulación de datos y creación de modelos de machine learning aprovechando PySpark:
Los libros son un recurso excelente para aprender PySpark. Ofrecen conocimientos profundos y opiniones de expertos, junto con fragmentos de código y explicaciones. Estos son algunos de los libros más populares sobre PySpark:
La demanda de habilidades en PySpark ha aumentado en varios puestos relacionados con los datos, desde analistas de datos hasta ingenieros de big data. Si te estás preparando para una entrevista, ten en cuenta estas preguntas de entrevista sobre PySpark para
Como ingeniero de big data, eres el arquitecto de soluciones de big data, responsable de diseñar, construir y mantener la infraestructura que gestiona grandes conjuntos de datos. Utilizarás PySpark para crear canalizaciones de datos escalables, lo que garantizará una ingesta, un procesamiento y un almacenamiento de datos eficientes.
Se requiere un profundo conocimiento de la informática distribuida y las plataformas de nube, así como experiencia en almacenamiento de datos y procesos ETL.
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¡Aprende PySpark con estos cursos!
Curso
Curso
Curso
blog
Matt Crabtree
15 min
blog
Gus Frazer
11 min
blog
Laiba Siddiqui
13 min
blog
Adel Nehme
15 min
Tutorial
Natassha Selvaraj
Tutorial
Olivia Smith

