
Course
Foundations of PySpark
4 hr
157.5K
Filtering is a foundational operation in PySpark, essential for quickly refining large datasets to narrow down relevant information. Effectively using filters in PySpark can enhance workflow efficiency for intermediate data engineers, data scientists, and developers tackling big data processing.
This article introduces fundamental and advanced PySpark filtering techniques, outlines optimization strategies for better performance, and covers practical use cases applicable to real-world scenarios.
This tutorial assumes some fundamental PySpark knowledge, but you can discover what PySpark is and how it can be used in our Getting Started with PySpark tutorial.
As mentioned in our Learn PySpark From Scratch in 2025 guide, PySpark is a widely used tool in data science due to its ease of use and efficiency. It provides straightforward ways to filter datasets efficiently using built-in functions like filter() and where(). These functions help data professionals isolate rows from DataFrames that satisfy specified conditions.
Filtering is critical in data preprocessing, analysis, and pipeline optimization. It allows you to exclude irrelevant or erroneous records early on, saving time, reducing costs, and improving subsequent analyses or modeling tasks.
Despite its simplicity, applying filters in distributed environments can create challenges like performance bottlenecks, inefficient or complex filter conditions, and improper handling of missing or incomplete data.
Understanding Spark Filters is vital in acing a data engineering interview.
Master the key topics and questions asked in big data interviews, from foundational concepts like data storage and distributed computing to advanced areas like machine learning and security, using our Top 30+ Big Data Interview Questions tutorial.
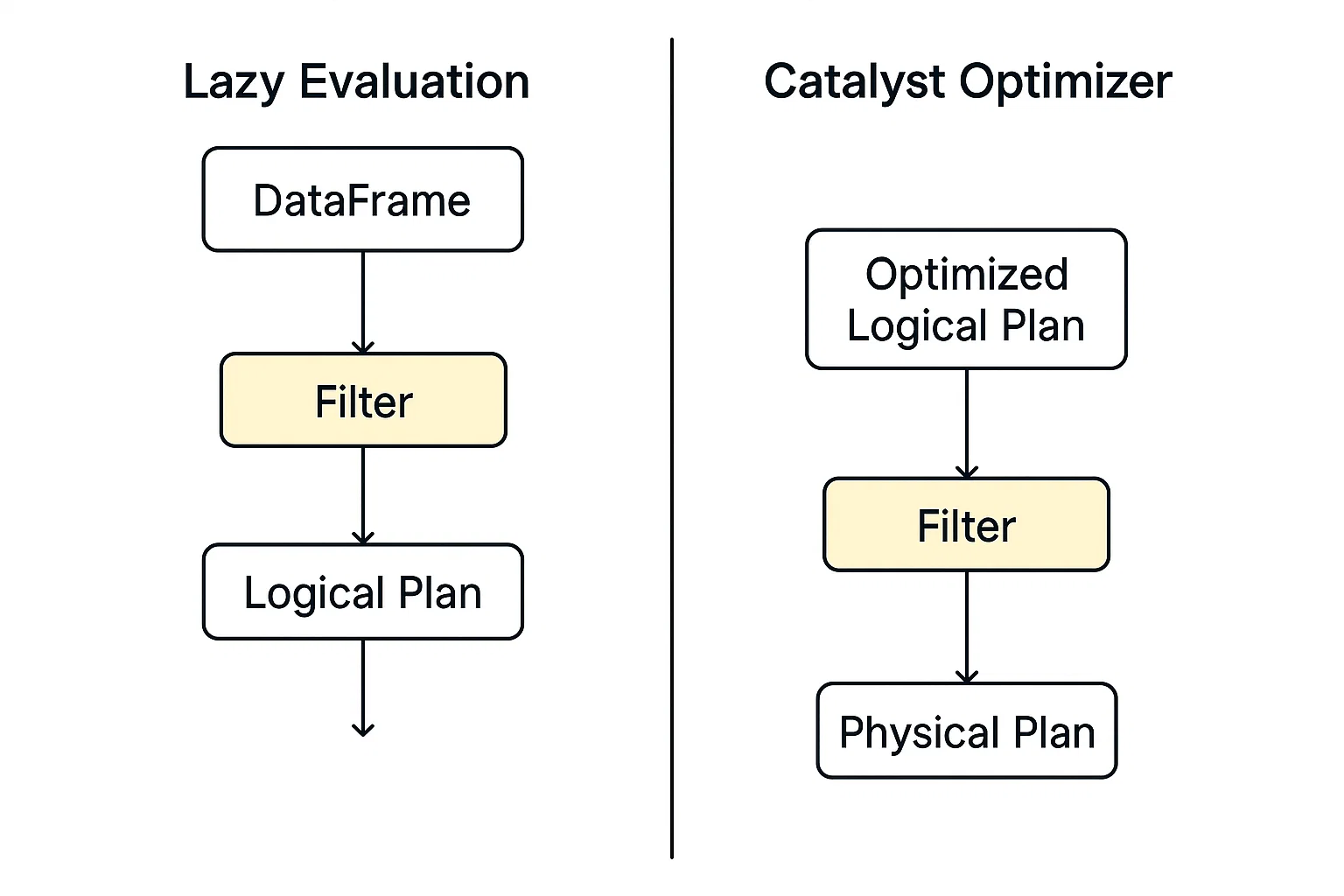
Filtering in PySpark operates within the framework of its distributed execution model, built on top of Apache Spark. When you apply a filter (e.g., using .filter() or .where()), PySpark doesn't immediately scan the data. Instead, it builds a logical query plan that outlines the transformations you want to perform.
Two core concepts significantly influence filtering efficiency in PySpark:
PySpark doesn't immediately execute a filter command; instead, it builds a logical query plan and defers action until explicitly told to execute. This model allows PySpark greater flexibility in optimizing operations across data pipelines.
This optimization engine in Spark evaluates logical plans, including filtering, and identifies the fastest, most efficient way to execute them automatically.
When execution begins, the filtered data is processed in parallel across worker nodes using RDDs or DataFrames. Each partition applies the filter independently, making it scalable for large datasets.
You can explore more information about RDDs in our PySpark Cheat Sheet: Spark in Python tutorial.
Filtering data based on conditions is straightforward. You can provide conditions as column expressions or SQL-like strings.
Use DataFrame column objects and operators to define conditions:
filtered_data = df.filter(df.age > 25)Write the condition as a SQL-style string:
filtered_data_2 = df.filter("age > 25")Alternatively, you can use the where() function the same way:
filtered_data_3 = df.where(df.age > 25)
filtered_data_4 = df.where("age > 25")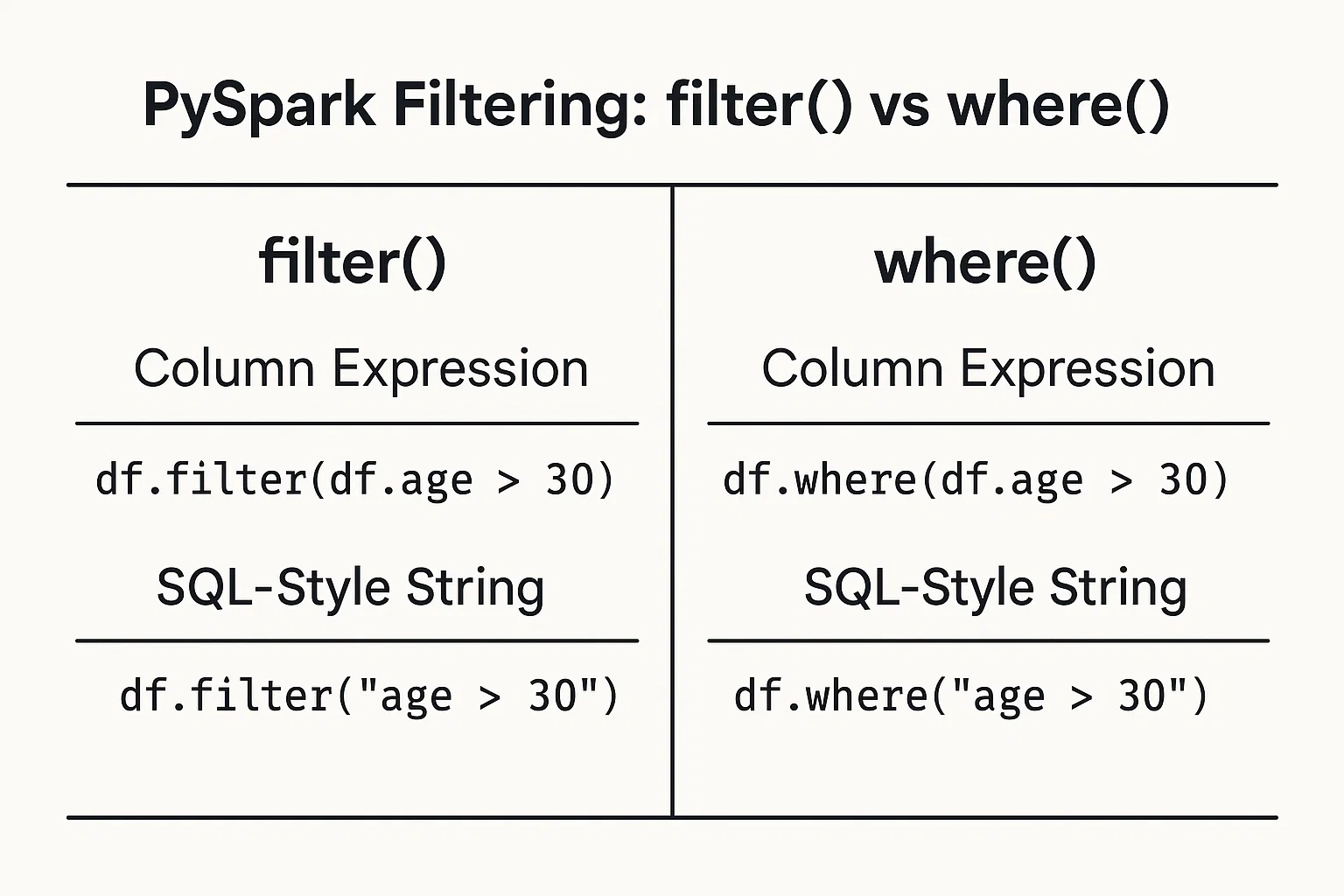
All of these are valid and produce the same result. The choice between them often comes down to personal preference or which style feels more readable in your specific context.
To learn more about using the SQL syntax in PySpark, check our Introduction to Spark SQL in Python course.
Let’s now explore various filtering methods and their practical use cases.
You can filter using relational operators such as greater than >, less than <, equals ==, and others to isolate data based on numeric or categorical thresholds:
greater_than_df = df.filter(df.salary > 50000)
category_match_df = df.filter(df.country == 'France')To combine multiple conditions into one filter, logical operators such as AND &, OR |, and NOT ~ can create concise expressions for complex requirements:
combined_df = df.filter((df.age > 25) & (df.city == 'New York'))PySpark includes advanced functions for specialized filtering cases. Let’s explore some of them.
Membership Tests: To filter values from a predefined set using isin:
selected_countries_df = df.filter(df.country.isin('Japan', 'Brazil', 'India'))Pattern Matching: Filtering based on text patterns using like for simple matches and rlike for regex:
name_filter_df = df.filter(df.name.like('A%'))
regex_filter_df = df.filter(df.name.rlike('^[A-Z][a-z]+Range Filters: Filtering with convenient methods like between:
range_df = df.filter(df.age.between(25, 35))Null Checks: Handling missing values gracefully by checking nulls explicitly:
valid_email_df = df.filter(df.email.isNotNull())Organizations often use nested or structured data. PySpark filtering accommodates nested fields and arrays. For structured data (structs), filter nested fields easily:
city_df = df.filter(df.address.city == 'Boston')For data stored as arrays, you can utilize built-in functions like array_contains:
from pyspark.sql.functions import array_contains
skill_df = df.filter(array_contains(df.skills, 'Python'))In this section, you will discover the strategies to enhance the performance of filter operations in PySpark.
Predicate pushdown involves placing filtering conditions as close to the data storage level as possible. This means PySpark reads less data initially, improving performance.
For example:
# Read from a Parquet file
df = spark.read.parquet("s3://your-bucket/sales_data/")
# Apply filter on a non-partition column (e.g., product_category)
filtered_df = df.filter(df.product_category == "Electronics")
# Trigger query plan inspection
filtered_df.explain(True)In the above example, we are applying a filter on a regular column. Normally, Spark would load the entire dataset and then filter in memory, but because Parquet supports predicate pushdown, Spark can send the filter condition directly to the Parquet reader.
Instead of reading all rows and then checking product_category, Spark only reads rows where product_category = 'Electronics'. This saves disk I/O and memory, speeding up processing.
explain prints the physical query plan, showing exactly what Spark plans to do during execution.
If predicate pushdown is applied, you’ll see something like:
PushedFilters: [EqualTo(product_category,Electronics)]This confirms that Spark pushed the filter down to the file scan level instead of applying it after loading the data.
Predicate pushdown is one of the most powerful optimizations in Spark’s toolkit. It:
By writing your filters clearly and storing data in formats like Parquet, you allow Spark to optimize execution under the hood.

Performance optimization is also crucial when doing joins in PySpark. Learn how to optimize PySpark joins, reduce shuffles, handle skew, and improve performance across big data pipelines and machine learning workflows from our PySpark Joins: Optimize Big Data Join Performance tutorial.
When data is partitioned by relevant fields (for example, date), PySpark can avoid loading unnecessary partitions. Effective partition pruning significantly reduces data scans and execution time.
Assume we have a Parquet dataset partitioned by year and month, stored at s3://your-bucket/events_data/.
Each partition looks like:
events_data/year=2023/month=01/
events_data/year=2023/month=02/
...
events_data/year=2024/month=01/An example of partition pruning in PySpark would look like this:
df = spark.read.parquet("s3://your-bucket/events_data/")
filtered_df = df.filter((df.year == 2023) & (df.month == 6))
# .explain(True) to verify pruning
filtered_df.explain(True)year and month are partition columns, allowing Spark's Catalyst optimizer to prune all irrelevant partitions.
Filtered results often get used multiple times in an analysis workflow. Storing filtered results temporarily in memory through caching helps avoid repeated computation but should be used cautiously to conserve resources.
recent_users_df = df.filter(df.registration_date >= '2022-01-01')
recent_users_df.cache()Let’s now explore complex scenarios where advanced filtering techniques are applied.
For handling time-series data, precise temporal filtering is frequently required. Filtering data within a specific time frame is straightforward:
time_df = df.filter((df.date >= '2023-08-01') & (df.date < '2023-09-01'))The above selects all records from August 2023. The condition works with both DateType and TimestampType columns.
For deeper time-series analysis, such as calculating rolling metrics or identifying trends over time, you can pair temporal filters with window functions. For example, you might first filter a date range, then apply a moving average or rank events within each day:
from pyspark.sql.window import Window
from pyspark.sql.functions import avg
window_spec = Window.partitionBy("date").orderBy("timestamp").rowsBetween(-2, 0)
df_filtered = df.filter((df.date >= '2023-08-01') & (df.date < '2023-09-01'))
df_with_avg = df_filtered.withColumn("rolling_avg", avg("value").over(window_spec))This example calculates a 3-row rolling average per day for values ordered by timestamp. Combining temporal filters with window functions gives you fine-grained control over time-based analytics.
Filtering real-time data streams presents unique challenges. Unlike batch processing, the data is unbounded and arrives continuously. This requires filters to be applied on the fly, with careful handling of late-arriving events to ensure accurate results.
PySpark’s Structured Streaming provides intuitive tools to filter streaming data and manage timing issues effectively. You can apply filters just like you would on a static DataFrame while using watermarks to control how long the system should wait for late data before finalizing results.
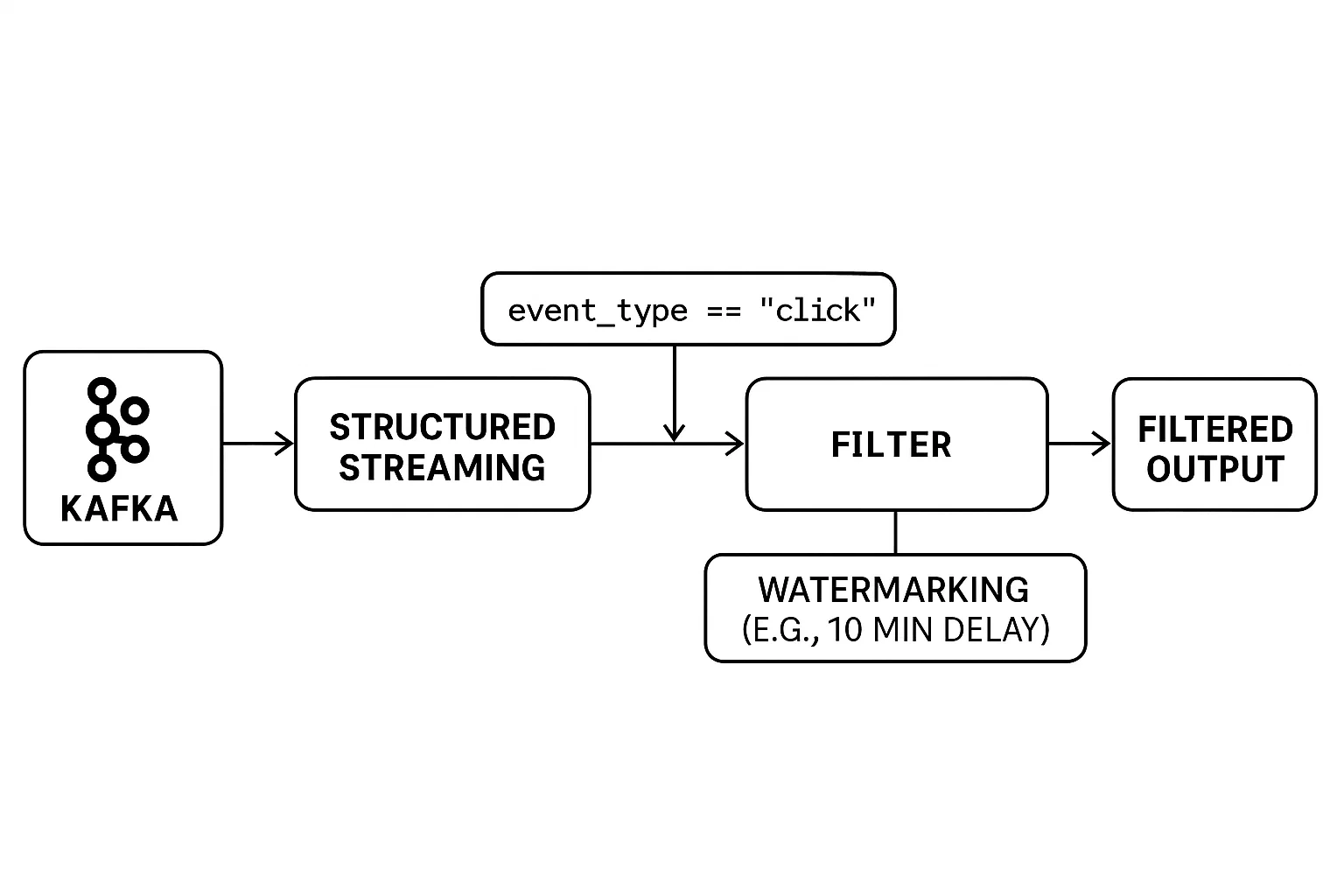
Here is an example:
# Example: Real-Time Filtering with Watermarking
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.types import StructType, StringType, TimestampType
# Set up Spark session
spark = SparkSession.builder.appName("RealTimeFiltering").getOrCreate()
# Define schema for streaming data
schema = StructType() \
.add("user_id", StringType()) \
.add("event_type", StringType()) \
.add("event_time", TimestampType())
# Read from a Kafka stream (or any supported source)
streaming_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "user_events") \
.load() \
.selectExpr("CAST(value AS STRING) as json") \
.selectExpr("from_json(json, 'user_id STRING, event_type STRING, event_time TIMESTAMP') as data") \
.select("data.*")
# Apply real-time filter: only 'click' events
filtered_df = streaming_df.filter(col("event_type") == "click")
# Handle late data with watermarking (e.g., 10 minutes tolerance)
filtered_with_watermark = filtered_df \
.withWatermark("event_time", "10 minutes")
# Write to console (for demo purposes)
query = filtered_with_watermark.writeStream \
.outputMode("append") \
.format("console") \
.start()
query.awaitTermination()In the example:
.filter(col("event_type") == "click").(withWatermark(...)) ensures late-arriving events are handled within a time window (10 minutes in this case).Combining real-time filters and watermarking enables you to build reliable streaming applications even in the case of network delays or irregular events.
In machine learning pipelines, effective filtering is critical during preprocessing. It's used not just for removing noise but also for selecting the most relevant features for model training. Filtering helps eliminate outliers, drop records with missing or invalid values, and retain only the attributes that contribute meaningful signals.
This two-fold approach, cleaning the data and selecting key features, can drastically improve both the performance and reliability of your models, as covered in our Cleaning Data with PySpark course. Without it, models risk being skewed by irrelevant inputs or distorted by bad data.
Our Big Data with PySpark course goes into more detail about machine learning in PySpark.
In this section, we will explore best practices and common challenges encountered when filtering data with PySpark.
Here are some practical recommendations for enhancing filtering efficiency:
1. Filter as early as possible during processing.
2. Limit the number of columns selected to reduce data shuffling.
3. Prioritize using PySpark's built-in filter functions instead of custom UDFs (user-defined functions).
Avoid common pitfalls:
Overly intricate filter expressions can hinder Spark's Catalyst optimizer. For instance, chaining numerous OR conditions or deeply nested logical statements can complicate the logical plan, leading to suboptimal execution. In scenarios where multiple equality checks are involved, consider using isin() or performing a join with a smaller DataFrame to leverage broadcast joins, which are more efficient for large datasets.
While caching is beneficial for reusing DataFrames, indiscriminate use can exhaust cluster memory. Caching large or numerous DataFrames without assessing their reuse can lead to out-of-memory errors. It's crucial to cache only those DataFrames that are reused multiple times and to unpersist them when they're no longer needed.
Data skew, where certain keys have disproportionately large amounts of data, can cause performance bottlenecks. Operations like joins or aggregations on skewed keys can lead to uneven task execution times. Techniques such as salting (adding random prefixes to keys), custom partitioning, or using Spark's Adaptive Query Execution can help mitigate these issues.
Proper filtering plays a crucial role in efficient data processing with PySpark. It streamlines analysis workflows, saves computational resources, and delivers clarity to subsequent analytical outcomes. Leveraging PySpark’s simple yet powerful filtering methods, along with optimized strategies like predicate pushdown, partition pruning, and selective caching, significantly enhances your data engineering practices. Consistently applying these techniques ensures robust and maintainable data pipelines.
To explore PySpark further, check out our in-depth Spark courses, including:
Top DataCamp Courses
Course
Course
Course
cheat-sheet
Karlijn Willems
cheat-sheet
Karlijn Willems
Tutorial
Derrick Mwiti
Tutorial
Natassha Selvaraj
Tutorial
Derrick Mwiti
Tutorial
Karlijn Willems

