
Curso
Fundamentos de big data con PySpark
4 h
65.2K
PySpark es la API de Python para Apache Spark, diseñada para el procesamiento paralelo y distribuido de datos en clusters. Elegir la operación de unión correcta para tus necesidades afecta a la velocidad del trabajo, al consumo de recursos y al éxito general.
Trabajar con amplios conjuntos de datos a menudo significa integrar datos de varias fuentes. Combinar eficazmente esta información es esencial para un análisis preciso y unas perspectivas significativas. Las uniones de PySpark proporcionan potentes formas de combinar conjuntos de datos separados basándose en claves compartidas.
Sin embargo, las uniones ineficaces pueden afectar gravemente a la velocidad y fiabilidad del procesamiento de datos cuando se trata de grandes conjuntos de datos que contienen millones o incluso miles de millones de registros en clústeres distribuidos.
¿Has experimentado uniones que fallan con análisis lentos o incluso con datos a gran escala? Si es así, esta guía es para ti. Ayudará a los científicos de datos, desarrolladores e ingenieros intermedios a adquirir dominio y confianza a la hora de realizar uniones en PySpark.
Si estás buscando algunos ejercicios prácticos para familiarizarte con PySpark, consulta nuestro Curso sobre Big Data con PySpark.
Como descubrirás en nuestro Aprende PySpark desde cero una de las principales características de PySpark es la capacidad de fusionar grandes conjuntos de datos. Las operaciones de unión de PySpark son esenciales para combinar grandes conjuntos de datos basados en columnas compartidas, permitiendo una integración, comparación y análisis de datos eficientes a escala.
Desempeñan un papel fundamental en la gestión de los macrodatos, ya que ayudan a descubrir relaciones y a extraer perspectivas significativas de las fuentes de datos distribuidas.
PySpark ofrece varios tipos de uniones, como uniones internas, uniones externas, uniones a izquierda y derecha, semiuniones y antiunionescada una de las cuales sirve para distintos fines analíticos.
Sin embargo, trabajar con uniones en grandes conjuntos de datos puede plantear retos como datos sesgados, sobrecarga de barajado y limitaciones de memoria, lo que hace que sea crucial seleccionar la estrategia de unión adecuada para el rendimiento y la precisión.
Comprender las operaciones internas de PySpark es vital para unir eficientemente grandes conjuntos de datos, como mostramos en nuestro curso de Curso de Introducción a PySpark. Esta sección esboza el marco conceptual que subyace a la ejecución conjunta de PySpark y el papel de su optimizador.
PySpark realiza uniones en un entorno informático distribuido, lo que significa que divide grandes conjuntos de datos en particiones más pequeñas y las procesa en paralelo en un clúster de máquinas. Cuando se activa unaunión , PySpark distribuye el trabajo entre estos nodos, buscando un cálculo equilibrado para acelerar la ejecución y evitar cuellos de botella.
En el núcleo de este proceso se encuentra Catalyst, el potente motor de optimización de consultas de Spark. El catalizador determina cómo se ejecutan las operaciones de unión. Decide las estrategias de partición, detecta cuándo es necesario barajar los datos y aplica optimizaciones de rendimiento como el pushdown de predicados y las uniones de difusión. Esta optimización automatizada garantiza una ejecución eficaz sin necesidad de ajuste manual por parte del desarrollador.
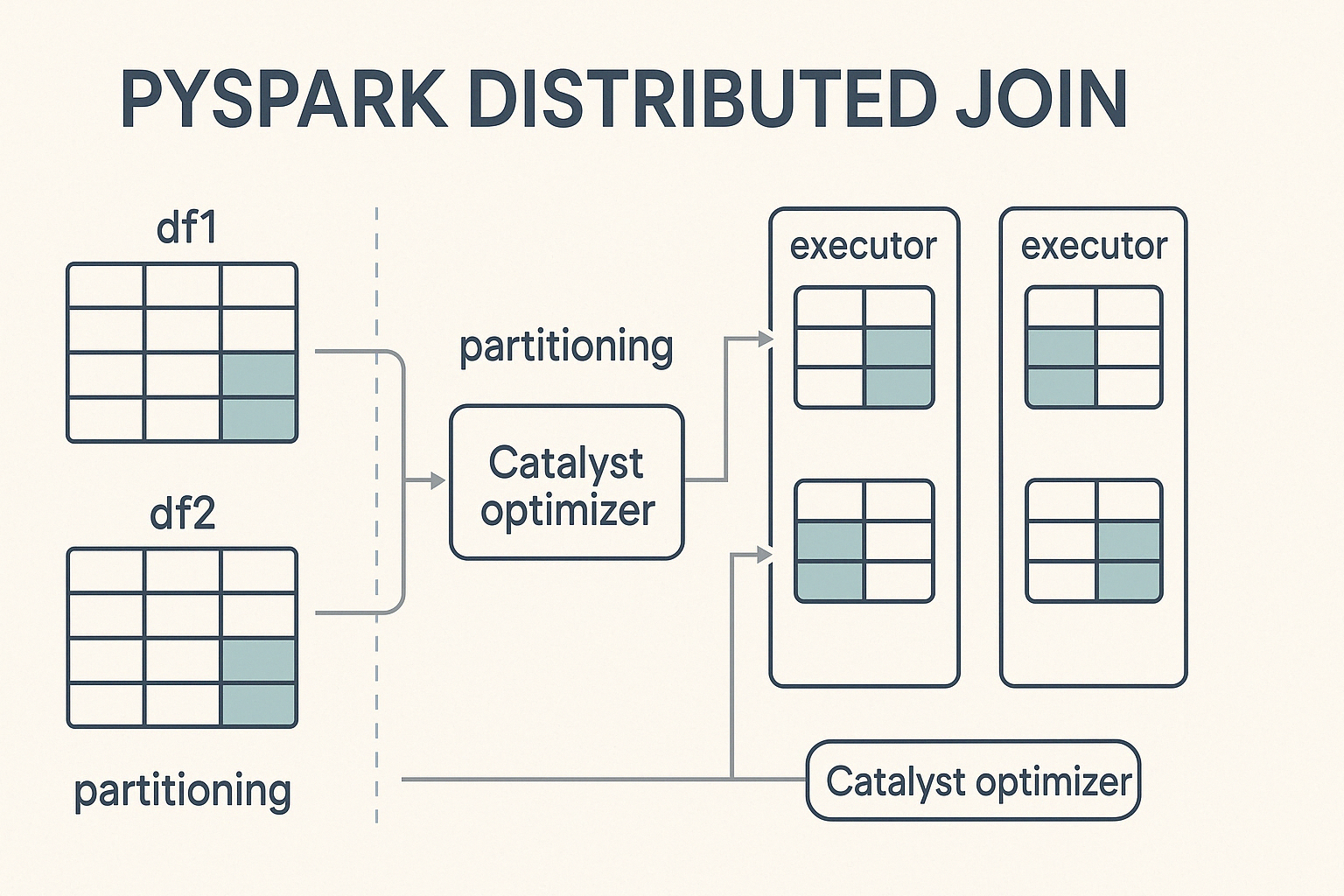
Para realizar uniones en PySpark, hay que seguir una sintaxis sencilla que implica especificar los marcos de datos, a condición de unióny el tipo de unión a ejecutar.
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName("PySpark Joins Example").getOrCreate()
# Perform a join
joined_df = df1.join(df2, on="key", how="inner")En este ejemplo:
df1 y df2 son los DataFrames que hay que unir.df1.key == df2.key es la condición de unión, que determina cómo deben emparejarse las filas de cada DataFrame.inner' specifies the join type, which could also be izquierda, derecha,, exterior, semi, or anti` según el resultado deseado.Sigue nuestro tutorial Introducción a PySpark para obtener instrucciones sobre cómo instalar PySpark y ejecutar las uniones anteriores sin errores.
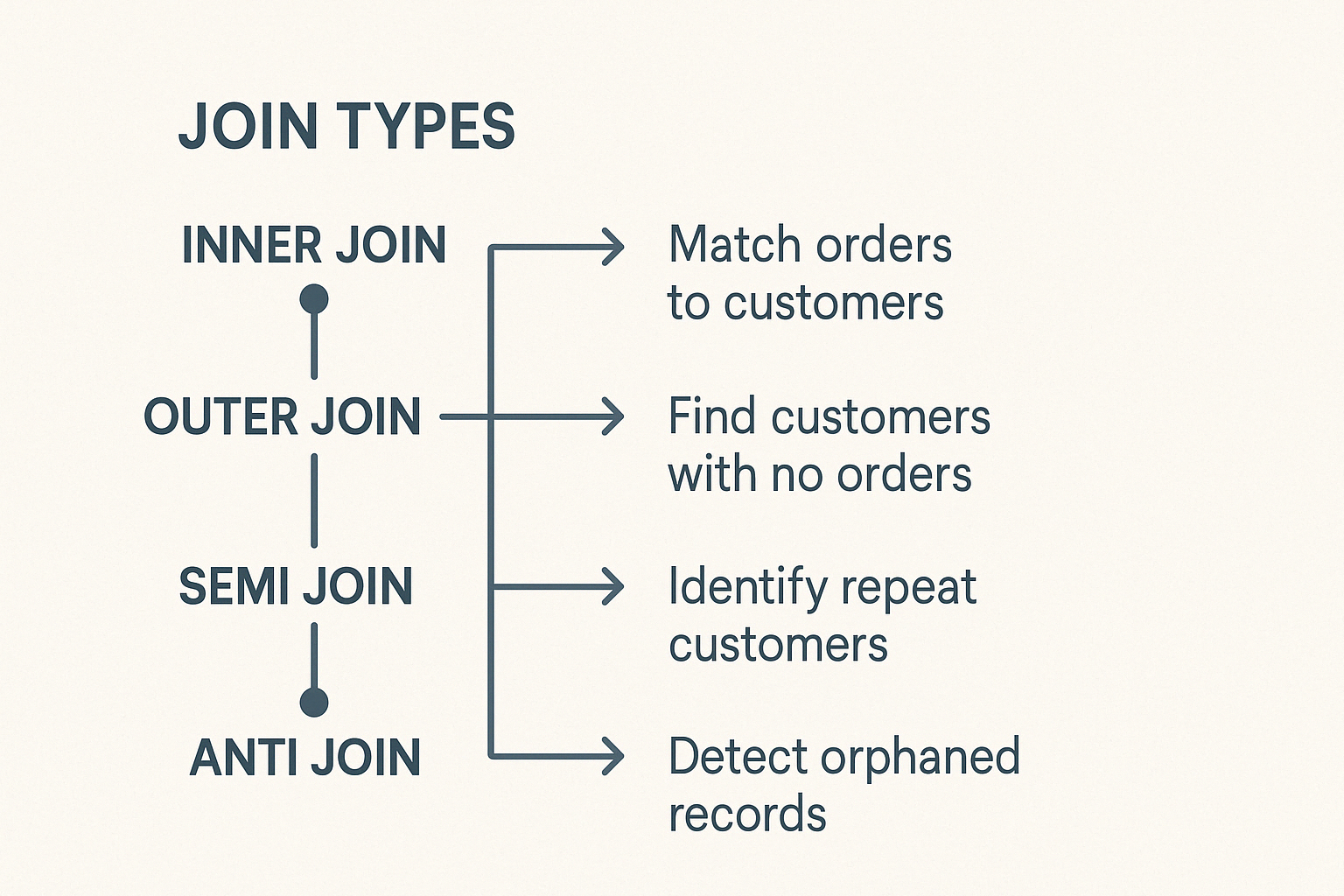
PySpark incluye diferentes tipos de uniones, cada una adecuada para tareas de datos distintas. Comprenderlos te ayudará a elegir sabiamente.
La unión interna combina filas de dos Marcos de Datos cuando existen claves coincidentes en ambos. Se excluirán las filas sin claves coincidentes. Es el tipo de unión más común y por defecto en PySpark.
Los escenarios de uso típicos incluyen:
PySpark admite uniones a la izquierda, a la derecha y externas completas.
La unión externa izquierda devuelve todas las filas del Marco de Datos izquierdo y las filas coincidentes del Marco de Datos derecho. Cuando no aparece ninguna clave coincidente en el Marco de datos derecho, los valores nulos llenan las columnas de la derecha.
Casos prácticos:
La unión externa derecha refleja la lógica de la unión izquierda. Devuelve todas las filas del Marco de datos derecho y las filas coincidentes del Marco de datos izquierdo, rellenando con nulos las coincidencias que falten en las columnas de la izquierda.
Ejemplo de situación:
La unión externa completa devuelve todas las filas disponibles de ambos marcos de datos, rellenando las entradas no coincidentes con nulos. Ayuda a detectar discrepancias o lagunas de datos entre dos conjuntos de datos.
Las semi-uniones y anti-uniones cumplen funciones especializadas:
Una semiunión devuelve filas del Marco de Datos izquierdo donde existen claves coincidentes en el Marco de Datos derecho. No añade columnas del DataFrame correcto y evita duplicados, por lo que es ideal para comprobaciones de existencia.
Ejemplo de caso práctico:
Una antiUnión devuelve filas de un Marco de Datos que no tienen una clave coincidente en el segundo Marco de Datos.
Ejemplo de caso práctico:
Las uniones cruzadas crean datos emparejando cada fila de un Marco de datos con cada fila de otro. A menos que se desee específicamente, evita las uniones cruzadas, ya que amplían drásticamente los conjuntos de datos.
Utilízalos con precaución para situaciones concretas como:
Las uniones a gran escala exigen una optimización cuidadosa. Considera las siguientes técnicas:
Las uniones por difusión mejoran el rendimiento al replicar los DataFrames más pequeños en todos los nodos, eliminando las costosas barajadas.
Ejemplo de sintaxis:
from pyspark.sql.functions import broadcast
joined_df = large_df.join(broadcast(small_df), "id", "inner")Ten en cuenta los límites de memoria de tu sistema; la difusión de DataFrames excesivamente grandes no funcionará eficazmente.
La desviación de datos significa que los datos no se distribuyen uniformemente entre las particiones, lo que crea cuellos de botella. Las técnicas para reducir la desviación incluyen
El rendimiento eficiente de las uniones en PySpark depende en gran medida de la minimización de la sobrecarga de barajado, que se produce cuando hay que mover datos entre nodos para satisfacer las condiciones de unión. Una de las formas más eficaces de reducir esta sobrecarga es alinear las particiones de los DataFrames que se van a unir.
Ten en cuenta estas buenas prácticas:
repartition() o broadcast() con prudencia: Utiliza repartition() para conjuntos de datos grandes en los que sea posible una distribución uniforme, y broadcast() para tablas significativamente más pequeñas, para evitar por completo el barajado.PySpark incluye mecanismos especializados para casos más exigentes, que permiten una eficacia aún mayor:
Las uniones por rango se utilizan cuando se emparejan filas basándose en condiciones numéricas o temporales, en lugar de en la igualdad exacta. Estas uniones son habituales en escenarios que implican series temporales de datos, como el análisis de registros, el seguimiento de eventos o los flujos de sensores IoT.
Las mejores prácticas para una unión eficaz de las gamas incluyen
rangeBetween o between.Ejemplos de casos de uso
Unir datos de flujo presenta retos únicos debido a su naturaleza continua y a menudo impredecible. Los problemas clave son los acontecimientos que llegan tarde, los datos fuera de orden y la necesidad de gestionar el estado de forma eficaz a lo largo del tiempo.
PySpark aborda estos retos utilizando marcas de agua, que definen un umbral para el tiempo que el sistema debe esperar los datos atrasados antes de descartarlos. Al establecer una marca de agua en las columnas de tiempo de eventos, PySpark puede gestionar eficazmente los datos atrasados y optimizar el uso de recursos.
Las marcas de agua son especialmente útiles cuando se unen dos fuentes de flujo o un flujo con un conjunto de datos estático, ayudando a mantener tanto el rendimiento como la coherencia en los conductos de datos en tiempo real.
Las uniones desempeñan un papel crucial en la preparación de los datos para los modelos de aprendizaje automático, por ejemplo, al modelos con Spark MLlib. Consolidar estas características en un conjunto de datos único y unificado es esencial para el entrenamiento y la evaluación precisos de los modelos.
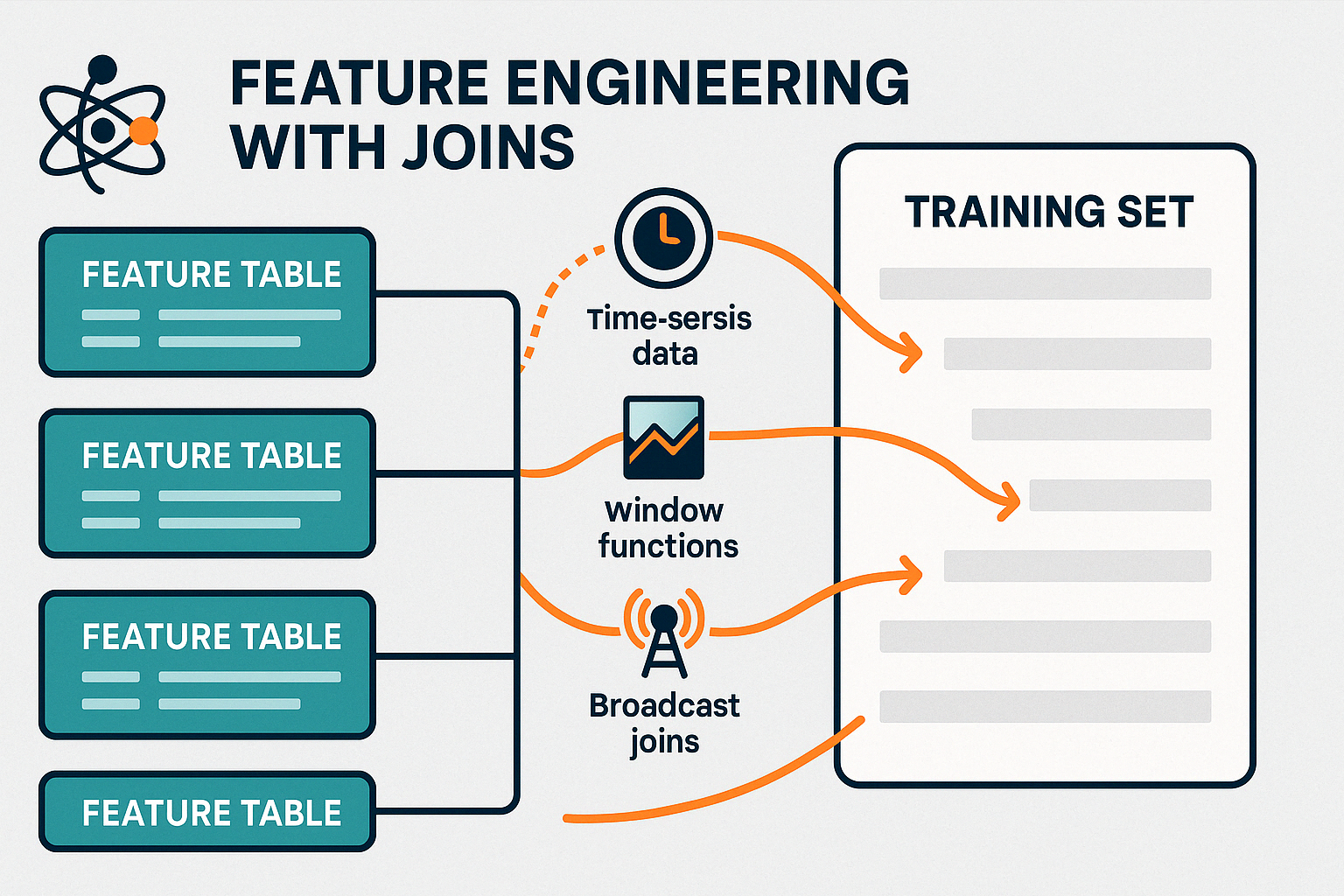
Al gestionar eficazmente estas uniones, PySpark permite la ingeniería de características en tiempo real, dando soporte tanto a los sistemas de aprendizaje en línea como a los pipelines de entrenamiento por lotes actualizados.
Puedes aprender a hacer predicciones a partir de datos con Apache Spark, utilizando árboles de decisión, regresión logística, regresión lineal, ensembles y pipelines con nuestro curso Curso de Aprendizaje Automático con PySpark.
Las operaciones de unión en la informática distribuida requieren una atención regular para evitar posibles problemas.
Unas operaciones de unión eficientes pueden mejorar drásticamente la velocidad general de la tubería y el uso de recursos. Estas son las prácticas clave que debes seguir:
repartition() o coalesce() para ajustar el tamaño de las particiones y conseguir un procesamiento paralelo más equilibrado.Incluso pequeños errores en la lógica de las uniones pueden provocar problemas importantes de rendimiento o precisión de los datos. Aquí tienes los escollos más comunes a los que debes prestar atención:
Incluso las uniones bien estructuradas pueden tener problemas de rendimiento o de ejecución.
He aquí los problemas más comunes y cómo resolverlos:
Las uniones de PySpark son la piedra angular del procesamiento de datos a gran escala, ya que permiten realizar análisis potentes y eficientes de conjuntos de datos masivos. Cuando se utilizan correctamente, revelan relaciones significativas que impulsan conocimientos más profundos y decisiones más inteligentes.
Aunque el ajuste del rendimiento puede presentar retos, como el manejo de la inclinación de los datos o la optimización de la partición, dominar estos aspectos es clave para construir canalizaciones de datos robustas.
Tanto si estás uniendo flujos en tiempo real como consolidando funciones para el aprendizaje automático, perfeccionar tus estrategias de unión puede mejorar significativamente la velocidad de ejecución, la eficiencia de los recursos y la precisión analítica.
Para profundizar, explora el procesamiento de big data con PySpark, y trabaja para convertirte en un experto en ingeniería de datos con nuestros Fundamentos de Big Data con PySpark con PySpark.
Los mejores cursos de DataCamp
Curso
Curso
Curso
Tutorial
Natassha Selvaraj
Tutorial
DataCamp Team
Tutorial
Olivia Smith
Tutorial
Joleen Bothma
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
