
Curso
Fundamentos do PySpark
4 h
157.5K
A filtragem é uma operação fundamental no PySpark, essencial para refinar rapidamente grandes conjuntos de dados para restringir as informações relevantes. O uso eficaz de filtros no PySpark pode aumentar a eficiência do fluxo de trabalho para engenheiros de dados intermediários, cientistas de dados e desenvolvedores que lidam com o processamento de Big Data.
Este artigo apresenta técnicas fundamentais e avançadas de filtragem do PySpark, descreve estratégias de otimização para melhorar o desempenho e aborda casos de uso práticos aplicáveis a cenários do mundo real.
Este tutorial pressupõe algum conhecimento fundamental sobre o PySpark, mas você pode descobrir o que é o PySpark e como ele pode ser usado em nosso tutorial Getting Started with PySpark.
Conforme mencionado em nosso guia Learn PySpark From Scratch in 2025 (Aprenda PySpark do zero em 2025 ), o PySpark é uma ferramenta amplamente usada na ciência de dados devido à sua facilidade de uso e eficiência. Ele oferece maneiras diretas de filtrar conjuntos de dados com eficiência usando funções integradas como filter() e where(). Essas funções ajudam os profissionais de dados a isolar as linhas dos DataFrames que satisfazem as condições especificadas.
A filtragem é essencial para o pré-processamento, a análise e a otimização do pipeline de dados. Ele permite que você exclua registros irrelevantes ou errôneos logo no início, economizando tempo, reduzindo custos e melhorando as análises subsequentes ou as tarefas de modelagem.
Apesar de sua simplicidade, a aplicação de filtros em ambientes distribuídos pode criar desafios como gargalos de desempenho, condições de filtro ineficientes ou complexas e tratamento inadequado de dados ausentes ou incompletos.
Para que você seja bem-sucedido em uma entrevista de engenharia de dados, é fundamental entender os filtros do Spark.
Domine os principais tópicos e perguntas feitas em entrevistas sobre Big Data, desde conceitos básicos, como armazenamento de dados e computação distribuída, até áreas avançadas, como machine learning e segurança, usando nosso tutorial com as 30 principais perguntas para entrevistas sobre Big Data.
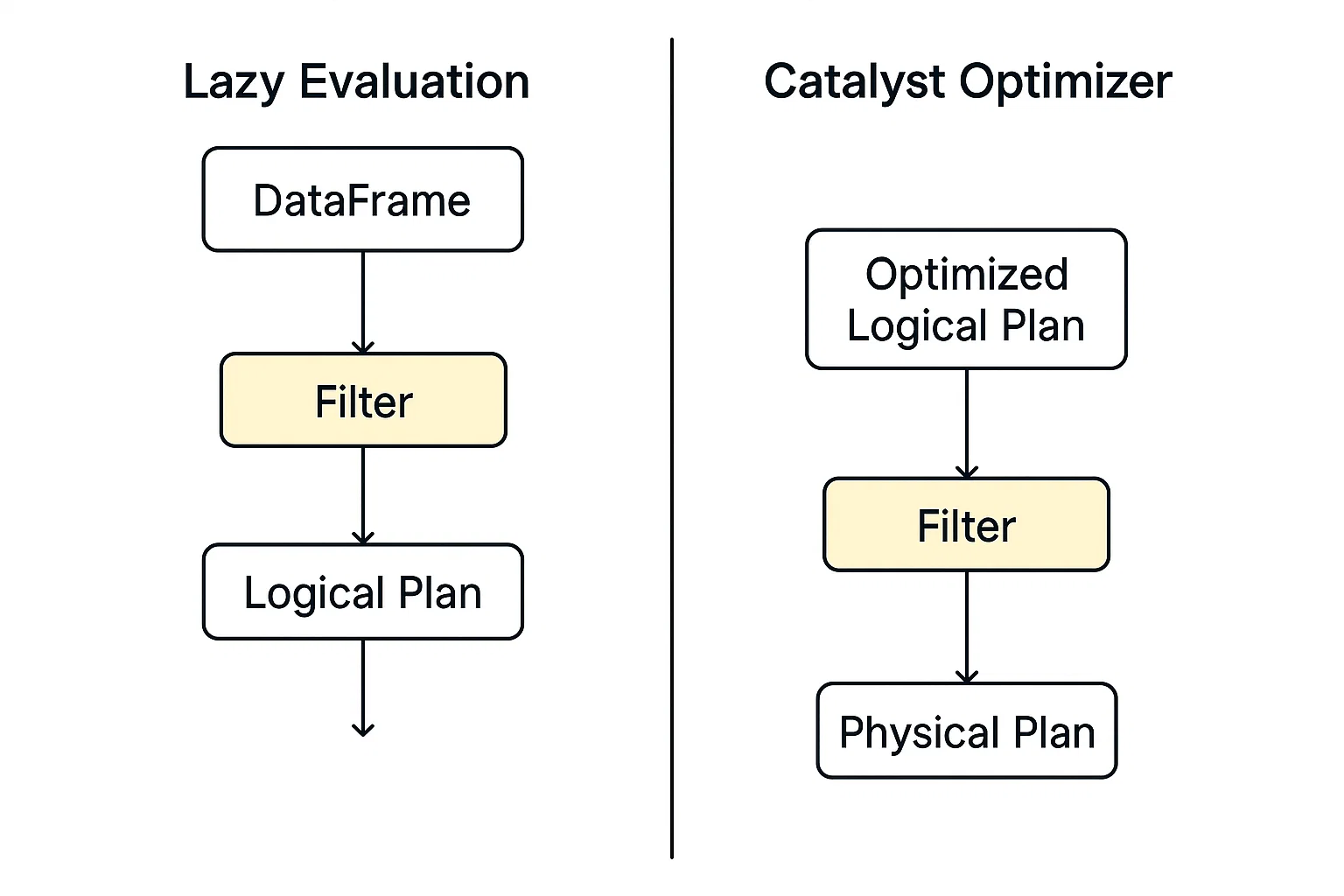
A filtragem no PySpark opera dentro da estrutura de seu modelo de execução distribuída, desenvolvido com base no Apache Spark. Quando você aplica um filtro (por exemplo, usando .filter() ou .where())), o PySpark não examina os dados imediatamente. Em vez disso, ele cria um plano de consulta lógico que descreve as transformações que você deseja executar.
Dois conceitos principais influenciam significativamente a eficiência da filtragem no PySpark:
O PySpark não executa imediatamente um comando de filtro; em vez disso, ele cria um plano de consulta lógico e adia a ação até que você seja explicitamente instruído a executar. Esse modelo permite ao PySpark maior flexibilidade na otimização de operações em pipelines de dados.
Esse mecanismo de otimização no Spark avalia os planos lógicos, incluindo a filtragem, e identifica a maneira mais rápida e eficiente de executá-los automaticamente.
Quando a execução começa, os dados filtrados são processados em paralelo nos nós de trabalho usando RDDs ou DataFrames. Cada partição aplica o filtro independentemente, tornando-o escalável para grandes conjuntos de dados.
Você pode explorar mais informações sobre RDDs em nosso PySpark Cheat Sheet: Tutorial do Spark em Python.
A filtragem de dados com base em condições é simples. Você pode fornecer condições como expressões de coluna ou cadeias de caracteres do tipo SQL.
Use os objetos e operadores de coluna do DataFrame para definir condições:
filtered_data = df.filter(df.age > 25)Escreva a condição como uma cadeia de caracteres no estilo SQL:
filtered_data_2 = df.filter("age > 25")Como alternativa, você pode usar afunção where() da mesma forma:
filtered_data_3 = df.where(df.age > 25)
filtered_data_4 = df.where("age > 25")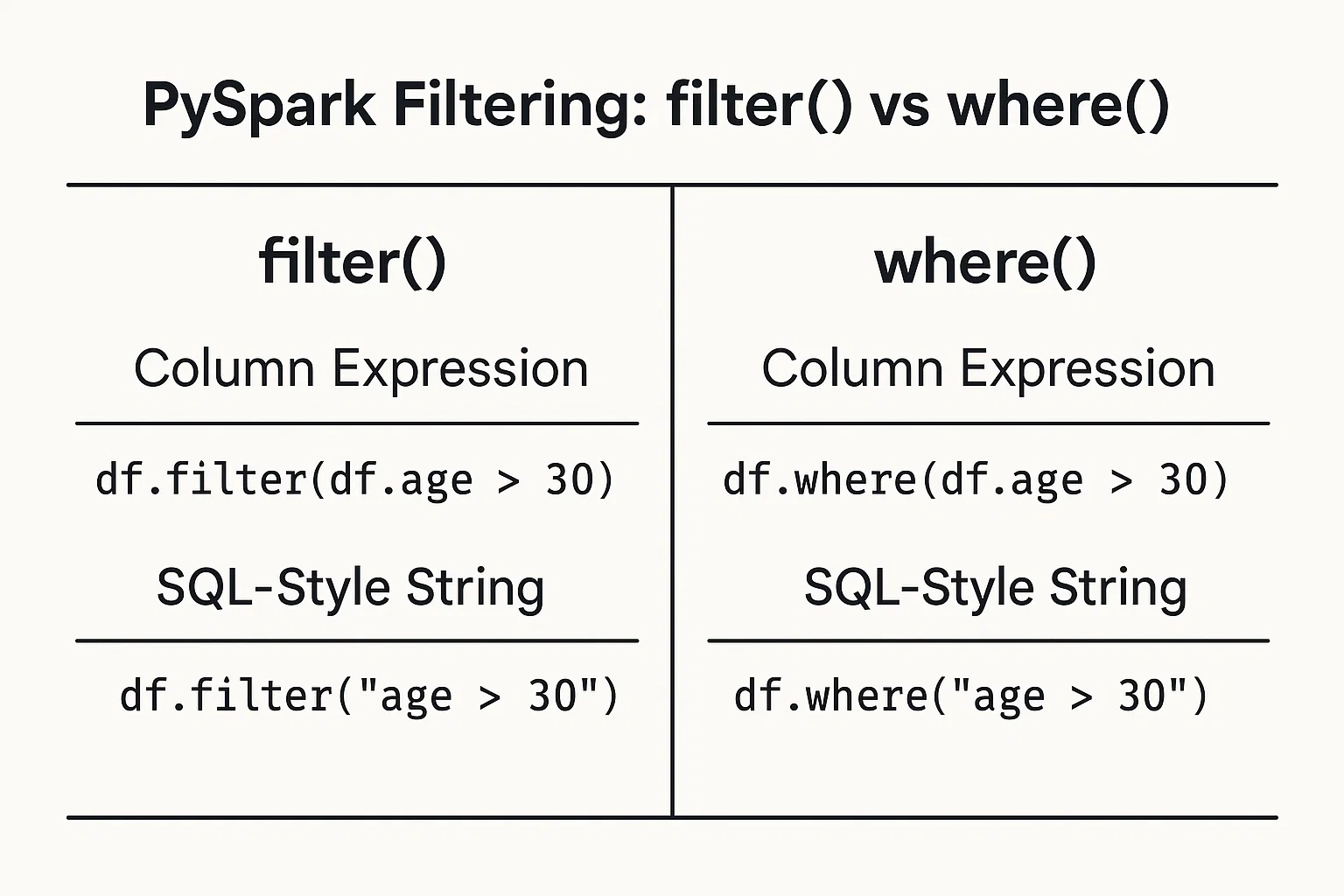
Todas elas são válidas e produzem o mesmo resultado. A escolha entre eles geralmente se resume à preferência pessoal ou a qual estilo você acha mais legível em seu contexto específico.
Para saber mais sobre como usar a sintaxe SQL no PySpark, consulte nosso curso Introdução ao Spark SQL em Python.
Vamos agora explorar vários métodos de filtragem e seus casos de uso prático.
Você pode filtrar usando operadores relacionais como maior que >, menor que <, igual a == e outros para isolar dados com base em limites numéricos ou categóricos:
greater_than_df = df.filter(df.salary > 50000)
category_match_df = df.filter(df.country == 'France')Para combinar várias condições em um filtro, operadores lógicos como AND &, OR | e NOT ~ podem criar expressões concisas para requisitos complexos:
combined_df = df.filter((df.age > 25) & (df.city == 'New York'))O PySpark inclui funções avançadas para casos de filtragem especializados. Vamos explorar alguns deles.
Testes de associação: Para filtrar valores de um conjunto predefinido usando isin:
selected_countries_df = df.filter(df.country.isin('Japan', 'Brazil', 'India'))Correspondência de padrões: Filtragem baseada em padrões de texto usando like para correspondências simples e rlike para regex:
name_filter_df = df.filter(df.name.like('A%'))
regex_filter_df = df.filter(df.name.rlike('^[A-Z][a-z]+Filtros de faixa: Filtragem com métodos convenientes, como between:
range_df = df.filter(df.age.between(25, 35))Verificações nulas: Manipulação de valores ausentes de forma elegante, verificando nulos explicitamente:
valid_email_df = df.filter(df.email.isNotNull())As organizações geralmente usam dados aninhados ou estruturados. A filtragem do PySpark acomoda campos e matrizes aninhados. Para dados estruturados (structs), filtre facilmente os campos aninhados:
city_df = df.filter(df.address.city == 'Boston')Para dados armazenados como matrizes, você pode utilizar funções internas como array_contains:
from pyspark.sql.functions import array_contains
skill_df = df.filter(array_contains(df.skills, 'Python'))Nesta seção, você descobrirá as estratégias para melhorar o desempenho das operações de filtro no PySpark.
O pushdown de predicado envolve a colocação de condições de filtragem o mais próximo possível do nível de armazenamento de dados. Isso significa que o PySpark lê menos dados inicialmente, melhorando o desempenho.
Por exemplo:
# Read from a Parquet file
df = spark.read.parquet("s3://your-bucket/sales_data/")
# Apply filter on a non-partition column (e.g., product_category)
filtered_df = df.filter(df.product_category == "Electronics")
# Trigger query plan inspection
filtered_df.explain(True)No exemplo acima, estamos aplicando um filtro em uma coluna regular. Normalmente, o Spark carregaria todo o conjunto de dados e, em seguida, filtraria na memória, mas como o Parquet é compatível com o predicado pushdown, o Spark pode enviar a condição do filtro diretamente para o leitor do Parquet.
Em vez de ler todas as linhas e depois verificar product_category, o Spark lê apenas as linhas em que product_category = 'Electronics'. Isso economiza E/S de disco e memória, acelerando o processamento.
explain imprime o plano de consulta físico, mostrando exatamente o que o Spark planeja fazer durante a execução.
Se o predicado pushdown for aplicado, você verá algo como:
PushedFilters: [EqualTo(product_category,Electronics)]Isso confirma que o Spark empurrou o filtro para o nível de varredura do arquivo em vez de aplicá-lo depois de carregar os dados.
O pushdown de predicado é uma das otimizações mais poderosas do kit de ferramentas do Spark. It:
Ao escrever seus filtros de forma clara e armazenar dados em formatos como o Parquet, você permite que o Spark otimize a execução sob o capô.

A otimização do desempenho também é crucial quando você faz junções no PySpark. Saiba como otimizar as junções do PySpark, reduzir embaralhamentos, lidar com distorções e melhorar o desempenho em pipelines de big data e fluxos de trabalho de machine learning em nosso site PySpark Joins: Tutorial para otimizar o desempenho da união de Big Data.
Quando os dados são particionados por campos relevantes (por exemplo, data), o PySpark pode evitar o carregamento de partições desnecessárias. A poda eficaz da partição reduz significativamente as varreduras de dados e o tempo de execução.
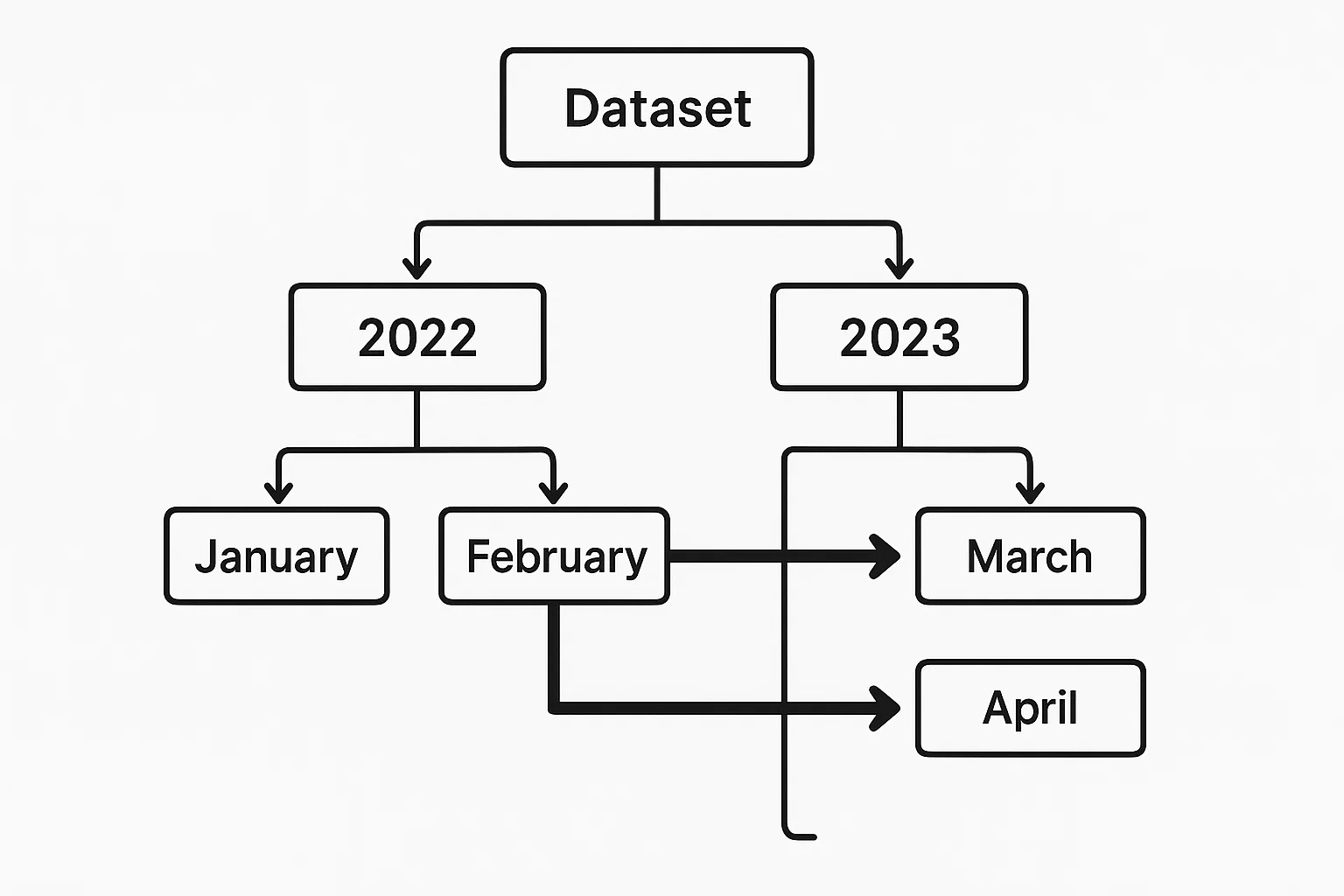
Suponha que você tenha um conjunto de dados Parquet particionado por year e month, armazenado em s3://your-bucket/events_data/.
Cada partição tem a seguinte aparência:
events_data/year=2023/month=01/
events_data/year=2023/month=02/
...
events_data/year=2024/month=01/Um exemplo de poda de partição no PySpark seria o seguinte:
df = spark.read.parquet("s3://your-bucket/events_data/")
filtered_df = df.filter((df.year == 2023) & (df.month == 6))
# .explain(True) to verify pruning
filtered_df.explain(True)year e month são colunas de partição, permitindo que o otimizador Catalyst do Spark elimine todas as partições irrelevantes.
Os resultados filtrados geralmente são usados várias vezes em um fluxo de trabalho de análise. O armazenamento temporário de resultados filtrados na memória por meio de cache ajuda a evitar cálculos repetidos, mas deve ser usado com cautela para conservar recursos.
recent_users_df = df.filter(df.registration_date >= '2022-01-01')
recent_users_df.cache()Vamos agora explorar cenários complexos em que são aplicadas técnicas avançadas de filtragem.
Para lidar com dados de séries temporais, frequentemente é necessária uma filtragem temporal precisa. A filtragem de dados em um período de tempo específico é simples:
time_df = df.filter((df.date >= '2023-08-01') & (df.date < '2023-09-01'))A opção acima seleciona todos os registros a partir de agosto de 2023. A condição funciona com as colunas DateType e TimestampType.
Para uma análise mais profunda de séries temporais, como o cálculo de métricas contínuas ou a identificação de tendências ao longo do tempo, você pode combinar filtros temporais com funções de janela. Por exemplo, você pode primeiro filtrar um intervalo de datas e, em seguida, aplicar uma média móvel ou classificar eventos dentro de cada dia:
from pyspark.sql.window import Window
from pyspark.sql.functions import avg
window_spec = Window.partitionBy("date").orderBy("timestamp").rowsBetween(-2, 0)
df_filtered = df.filter((df.date >= '2023-08-01') & (df.date < '2023-09-01'))
df_with_avg = df_filtered.withColumn("rolling_avg", avg("value").over(window_spec))Esse exemplo calcula uma média móvel de três linhas por dia para valores ordenados por carimbo de data/hora. A combinação de filtros temporais com funções de janela oferece a você um controle refinado sobre a análise baseada em tempo.
A filtragem de fluxos de dados em tempo real apresenta desafios únicos. Ao contrário do processamento em lote, os dados são ilimitados e chegam continuamente. Isso exige que os filtros sejam aplicados em tempo real, com um tratamento cuidadoso dos eventos que chegam mais tarde para garantir resultados precisos.
O Structured Streaming do PySpark fornece ferramentas intuitivas para filtrar dados de streaming e gerenciar problemas de tempo de forma eficaz. Você pode aplicar filtros da mesma forma que faria em um DataFrame estático enquanto usa marcas d'água para controlar quanto tempo o sistema deve esperar por dados atrasados antes de finalizar os resultados.
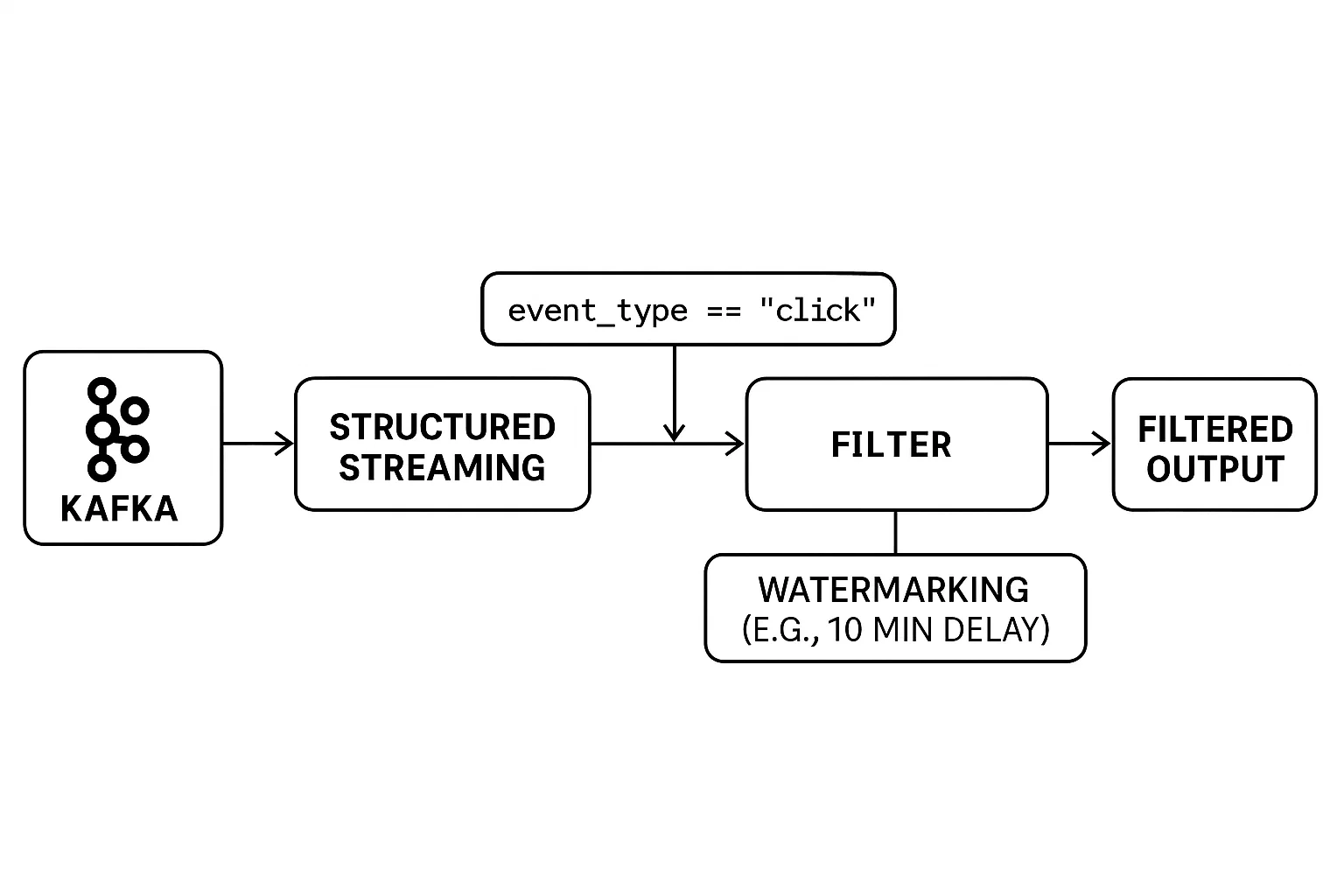
Aqui está um exemplo:
# Example: Real-Time Filtering with Watermarking
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.types import StructType, StringType, TimestampType
# Set up Spark session
spark = SparkSession.builder.appName("RealTimeFiltering").getOrCreate()
# Define schema for streaming data
schema = StructType() \
.add("user_id", StringType()) \
.add("event_type", StringType()) \
.add("event_time", TimestampType())
# Read from a Kafka stream (or any supported source)
streaming_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "user_events") \
.load() \
.selectExpr("CAST(value AS STRING) as json") \
.selectExpr("from_json(json, 'user_id STRING, event_type STRING, event_time TIMESTAMP') as data") \
.select("data.*")
# Apply real-time filter: only 'click' events
filtered_df = streaming_df.filter(col("event_type") == "click")
# Handle late data with watermarking (e.g., 10 minutes tolerance)
filtered_with_watermark = filtered_df \
.withWatermark("event_time", "10 minutes")
# Write to console (for demo purposes)
query = filtered_with_watermark.writeStream \
.outputMode("append") \
.format("console") \
.start()
query.awaitTermination()No exemplo:
.filter(col("event_type") == "click").(withWatermark(...)) garante que os eventos de chegada tardia sejam tratados dentro de uma janela de tempo (10 minutos, neste caso).A combinação de filtros em tempo real e marca d'água permite que você crie aplicativos de streaming confiáveis, mesmo em caso de atrasos na rede ou eventos irregulares.
Nos pipelines de machine learning, a filtragem eficaz é fundamental durante o pré-processamento. Ele é usado não apenas para remover ruídos, mas também para selecionar os recursos mais relevantes para o treinamento do modelo. A filtragem ajuda a eliminar exceções, eliminar registros com valores ausentes ou inválidos e reter apenas os atributos que contribuem com sinais significativos.
Essa abordagem dupla, que limpa os dados e seleciona os principais recursos, pode melhorar drasticamente o desempenho e a confiabilidade dos seus modelos, conforme abordado em nosso curso Cleaning Data with PySpark. Sem isso, os modelos correm o risco de serem distorcidos por entradas irrelevantes ou distorcidos por dados ruins.
Em nosso curso Big Data com PySpark, você encontrará mais detalhes sobre machine learning no PySpark.
Nesta seção, exploraremos as práticas recomendadas e os desafios comuns encontrados ao filtrar dados com o PySpark.
Aqui estão algumas recomendações práticas para aumentar a eficiência da filtragem:
1. Filtre o mais cedo possível durante o processamento.
2. Limite o número de colunas selecionadas para reduzir o embaralhamento de dados.
3. Priorize o uso das funções de filtro integradas do PySpark em vez de UDFs (funções definidas pelo usuário) personalizadas.
Evite armadilhas comuns:
Expressões de filtro muito complexas podem prejudicar o otimizador Catalyst do Spark. Por exemplo, encadear várias condições OR ou instruções lógicas profundamente aninhadas pode complicar o plano lógico, levando a uma execução abaixo do ideal. Em cenários em que várias verificações de igualdade estão envolvidas, considere usar isin() ou realizar uma união com um DataFrame menor para aproveitar as uniões de difusão, que são mais eficientes para grandes conjuntos de dados.
Embora o armazenamento em cache seja benéfico para a reutilização de DataFrames, o uso indiscriminado pode esgotar a memória do cluster. Se você armazenar em cache DataFrames grandes ou numerosos sem avaliar sua reutilização, poderá ocorrer erros de falta de memória. É crucial que você armazene em cache apenas os DataFrames que são reutilizados várias vezes e que os retire do cache quando não forem mais necessários.
A distorção de dados, em que determinadas chaves têm quantidades desproporcionalmente grandes de dados, pode causar gargalos de desempenho. Operações como junções ou agregações em chaves distorcidas podem levar a tempos de execução de tarefas desiguais. Técnicas como salting (adição de prefixos aleatórios às chaves), particionamento personalizado ou o uso da Adaptive Query Execution do Spark podem ajudar a mitigar esses problemas.
A filtragem adequada desempenha um papel crucial no processamento eficiente de dados com o PySpark. Ele agiliza os fluxos de trabalho de análise, economiza recursos computacionais e oferece clareza aos resultados analíticos subsequentes. O uso dos métodos de filtragem simples e avançados do PySpark, juntamente com estratégias otimizadas como predicado pushdown, poda de partição e cache seletivo, aprimora significativamente suas práticas de engenharia de dados. A aplicação consistente dessas técnicas garante pipelines de dados robustos e de fácil manutenção.
Para explorar mais o PySpark, confira nossos cursos detalhados sobre o Spark, incluindo:
Principais cursos da DataCamp
Curso
Curso
Curso
Tutorial
Natassha Selvaraj
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Joleen Bothma
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
