programa
Fundamentos de Datos en Python
28 h
En el mundo del análisis de datos, pandas ha sido durante mucho tiempo la opción predeterminada de los profesionales de los datos para manejar datos tabulares en Python.
Sin embargo, a medida que los conjuntos de datos aumentan en tamaño y complejidad, pandas puede encontrarse con cuellos de botella en el rendimiento, una utilización limitada de múltiples núcleos y restricciones de memoria.
Aquí es donde Polars surge como una alternativa moderna. Polars es una biblioteca DataFrame escrita en Rust que ofrece un rendimiento ultrarrápido, una gestión eficiente de la memoria y una filosofía de diseño centrada en la escalabilidad.
En este tutorial, compartiremos qué es Polars y cómo realizar algunas operaciones básicas de Polars en Python. Si buscas experiencia práctica, te recomiendo que eches un vistazo al curso Introducción a los polares.
Polars ofrece un conjunto único de características que lo diferencian de pandas:
Polars admite una amplia gama de tipos de datos más allá de los básicos:
Int32, Int64, Float32, Float64.true/false.Date, Datetime, Duration, Time.List y Struct, útiles para datos similares a JSON.Al ser la alternativa más nueva y moderna a los pandas, Polars ofrece varias ventajas:
Ahora, veamos cómo podemos empezar a utilizar Polars en Python.
Antes de utilizar Polars, debes configurar correctamente el entorno.
Polars es compatible con Windows, macOS y Linux. Se puede instalar en entornos virtuales, en el sistema Python o mediante flujos de trabajo en contenedores (Docker).
Para instalar la biblioteca polars en Python, ejecuta el siguiente comando en la terminal.
pip install polarsDeberías ver el siguiente mensaje de instalación:
Como alternativa, puedes instalar la biblioteca en el entorno conda si es con el que estás trabajando.
conda install -c conda-forge polarsPara comprobar si la instalación se ha realizado correctamente, escribe el siguiente script sencillo:
import polars as pl
print(pl.__version__)Polars te permite ajustar su funcionamiento y la forma en que se muestran sus resultados mediante la configuración de variables de entorno antes de iniciar tu sesión de Python. Por ejemplo:
POLARS_MAX_THREADS: Limita el número de subprocesos.POLARS_FMT_MAX_COLS: Controla el número de columnas impresas.POLARS_FMT_TABLE_WIDTH: Ajustar el ancho de visualización del DataFrame.A continuación se muestra un ejemplo de cómo se configurarían estas variables en un terminal antes de ejecutar Python:
export POLARS_MAX_THREADS=8
export POLARS_FMT_MAX_COLS=20Antes de profundizar en las características de Polars, es útil disponer de un conjunto de datos que podamos utilizar de forma coherente a lo largo de este tutorial. Podemos generar un archivo CSV sencillo utilizando el módulo csv integrado en Python o pandas.
A continuación se muestra un ejemplo que crea un archivo transactions.csv con datos sintéticos:
import csv
import random
from datetime import datetime, timedelta
# Define column names
columns = ["transaction_id", "customer_id", "amount", "transaction_date"]
# Generate synthetic rows
rows = []
start_date = datetime(2023, 1, 1)
for i in range(1, 101):
customer_id = random.randint(1, 10)
amount = round(random.uniform(10, 2000), 2)
date = start_date + timedelta(days=random.randint(0, 90))
rows.append([i, customer_id, amount, date.strftime("%Y-%m-%d")])
# Write to CSV
with open("transactions.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(columns)
writer.writerows(rows)Este script crea un conjunto de datos de 100 transacciones con importes, ID de clientes y fechas de transacción aleatorios. Puedes ajustar el rango y el tamaño según tus necesidades.
Guarda este script, ejecútalo una vez y tendrás un archivo CSV que podrás utilizar en los ejemplos que se incluyen a lo largo de este artículo.
Polars se basa en dos abstracciones fundamentales: la serie y el DataFrame.
Juntos, proporcionan una forma estructurada y eficiente de trabajar con datos, similar en espíritu a pandas, pero optimizada con el backend de Polars basado en Rust. Analicemos los conceptos principales.
Una serie en polares es un arreglo unidimensional, similar a una columna en una hoja de cálculo o tabla de base de datos. Cada serie tiene:
Int64, Utf8, Float64, Boolean, etc.).Debido a que el tipo de datos se aplica de forma estricta, las series en Polars suelen ser más rápidas y predecibles que las listas de Python.
Ejemplo:
import polars as pl
# Create a Series of integers
s = pl.Series("numbers", [1, 2, 3, 4, 5])
print(s)Salida:
shape: (5,)
Series: 'numbers' [i64]
[
1
2
3
4
5
]
Un DataFrame es una estructura bidimensional que organiza varias series juntas bajo un esquema. Conceptualmente, es como una tabla en SQL o Excel. Las filas representan registros y las columnas representan campos.
Ejemplo:
df = pl.DataFrame({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35]
})
print(df)Salida:
shape: (3, 3)
┌─────┬─────────┬─────┐
│ id │ name │ age │
│ --- │ --- │ --- │
│ i64 │ str │ i64 │
├─────┼─────────┼─────┤
│ 1 │ Alice │ 25 │
│ 2 │ Bob │ 30 │
│ 3 │ Charlie │ 35 │
└─────┴─────────┴─────┘Cada columna es una serie, y el DataFrame aplica su esquema.
Una de las fortalezas de Polars es la aplicación estricta de esquemas. Cada columna tiene un tipo de datos fijo, y Polars garantiza que todas las operaciones lo respeten. Esto evita errores sutiles que surgen en operaciones de tipado dinámico.
Por ejemplo, no puedes añadir accidentalmente una columna de cadena a una columna de entero sin una conversión explícita.
Ejemplo:
df = df.with_columns(
(pl.col("age") + 5).alias("age_plus_5")
)
print(df)Aquí, age es i64, y el resultado sigue siendo un número entero. Si intentabas añadir una columna de cadena, Polars generaba un error en lugar de fallar silenciosamente.
Los datos del mundo real suelen tener valores perdidos, y Polars proporciona herramientas claras para tratarlos:
fill_null(): Reemplaza los valores nulos por un valor determinado.drop_nulls(): Eliminar filas que contengan valores nulos.is_null() / is_not_null(): Comprobaciones booleanas.Polars promueve un sistema de expresión en el que las operaciones se definen como transformaciones en columnas en lugar de bucles Python fila por fila.
Estas expresiones están vectorizadas, lo que significa que operan sobre columnas completas a la vez, lo que es mucho más rápido.
En lugar de realizar bucles manualmente, Polars crea un cálculo vectorizado rápido.
Polars ofrece dos modos de ejecución:
Aquí tienes un ejemplo de ejecución anticipada:
df = pl.DataFrame({"x": [1, 2, 3]})
print(df.select(pl.col("x") * 2)) # eager: runs instantlyAquí tienes un ejemplo de ejecución diferida:
lazy_df = pl.DataFrame({"x": [1, 2, 3]}).lazy()
result = lazy_df.select(pl.col("x") * 2).collect() # execute on collect()
print(result)Aquí, no se calcula nada hasta que se llama a .collect(). En flujos de trabajo grandes, esto puede suponer una mejora espectacular del rendimiento.
A continuación, veremos cómo realizar algunas operaciones básicas utilizadas en Polars en el conjunto de datos que hemos creado.
Los polares pueden incorporar datos de múltiples formatos de archivo y objetos de memoria. Esto lo hace flexible para integrarlo en modernas canalizaciones de datos.
A continuación te explicamos cómo puedes hacerlo para diferentes fuentes:
A partir del conjunto de datos CSV que creaste anteriormente:
import polars as pl
df = pl.read_csv("transactions.csv")
print(df.head())También podemos leer el conjunto de datos desde Parquet si es necesario.
df_parquet = pl.read_parquet("transactions.parquet")Si en cambio tienes un archivo JSON, puedes leerlo utilizando este código:
df_json = pl.read_json("transactions.json")
#For JSON Lines (NDJSON), use the following instead:
df_json = pl.read_ndjson("transactions.json")A continuación se explica cómo leer conjuntos de datos de una tabla Arrow:
import pyarrow as pa
arrow_table = pa.table({
"transaction_id": [1, 2],
"customer_id": [5, 7],
"amount": [150.25, 300.75],
"transaction_date": ["2023-01-02", "2023-01-03"]
})
df_arrow = pl.from_arrow(arrow_table)Ahora seleccionemos columnas o filas específicas de nuestro conjunto de datos.
Cuando usas Polars, una operación habitual es seleccionar las columnas con las que deseas trabajar y que deseas conservar.
A continuación te explicamos cómo puedes hacerlo:
# Select only transaction_id and amount
df.select(["transaction_id", "amount"])También puedes filtrar filas según las condiciones que establezcas, de forma similar a pandas.
# Get only high-value transactions above $1,000
high_value = df.filter(pl.col("amount") > 1000)
print(high_value)La aplicación de expresiones en Polars implica el uso del objeto polars.Expr en diversos contextos para realizar transformaciones de datos.
Puedes crearlos utilizando pl.col() o pl.lit().
# Add a 10% discount column to simulate promotional pricing
df.select([
pl.col("transaction_id"),
pl.col("amount"),
(pl.col("amount") * 0.9).alias("discounted_amount")
])Podemos analizar los patrones de gasto por cliente utilizando group_by.
# Total and average spend per customer
agg_df = df.group_by("customer_id").agg([
pl.sum("amount").alias("total_spent"),
pl.mean("amount").alias("avg_transaction")
])
print(agg_df)Ejemplo de salida:
shape: (10, 3)
┌─────────────┬────────────┬───────────────┐
│ customer_id │ total_spent│ avg_transaction│
│ --- │ --- │ --- │
│ i64 │ f64 │ f64 │
├─────────────┼────────────┼───────────────┤
│ 1 │ 5230.12 │ 523.01 │
│ 2 │ 6120.45 │ 680.05 │
│ ... │ ... │ ... │
└─────────────┴────────────┴───────────────┘Nuestro conjunto de datos generado no tiene valores nulos por defecto, pero simulemos cómo los manejaríamos.
Los valores que faltan pueden causar problemas en el análisis posterior y la visualización de datos. Tendrás que completar los valores que falten para garantizar que todo funcione correctamente.
A continuación te explicamos cómo puedes rellenar los valores que faltan:
# Imagine 'amount' has missing values, then replace with 0
df_filled = df.with_columns(
pl.col("amount").fill_null(0)
)Los valores nulos pueden provocar errores si no se tratan adecuadamente. A continuación te explicamos cómo eliminarlos:
df_no_nulls = df.drop_nulls()Es posible que los tipos de datos estén formateados incorrectamente en un conjunto de datos. A continuación, te explicamos cómo puedes convertirlos utilizando el método « .cast »:
# Ensure customer_id is treated as string instead of int
df_casted = df.with_columns(
pl.col("customer_id").cast(pl.Utf8)
)Polars permite encadenar métodos para obtener flujos de trabajo más limpios. Este método de encadenamiento se utiliza habitualmente en programación SQL o R con el paquete tidyverse.
Ejemplo: Encuentra los principales clientes de marzo por gasto total.
pipeline = (
df
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d"))
#.col("date_str").str.to_date(format="%Y-%m-%d")
.filter(pl.col("transaction_date").dt.month() == 3) # transactions in March
.group_by("customer_id")
.agg(pl.sum("amount").alias("march_spent"))
.sort("march_spent", descending=True)
)
print(pipeline)Esta tubería:
Este método de encadenamiento permite realizar un análisis en cadena sin utilizar DataFrame intermedios.
Más allá de lo básico, Polars destaca cuando se trabaja con grandes conjuntos de datos gracias a su motor de evaluación diferida. Este modelo permite a Polars crear primero un plan de consulta, optimizarlo internamente y, solo entonces, ejecutar el proceso. El resultado es un enorme aumento del rendimiento y la eficiencia, especialmente con millones de filas o transformaciones complejas.
De forma predeterminada, Polars se ejecuta en modo eager. Esto significa que los cálculos se realizan inmediatamente, de forma similar a pandas. El modo perezoso, sin embargo, funciona de manera diferente:
.collect().Aquí tienes un ejemplo del modo perezoso:
import polars as pl
# Load dataset in lazy mode
lazy_df = pl.scan_csv("transactions.csv")
# Build a transformation pipeline
pipeline = (
lazy_df
.filter(pl.col("amount") > 1000) # step 1: filter expensive transactions
.group_by("customer_id") # step 2: group by customer
.agg(pl.sum("amount").alias("total_spent")) # step 3: aggregate
)
# Nothing has run yet, computation happens only on collect()
result = pipeline.collect()
print(result)Polars optimiza las consultas aplicando técnicas de pushdown:
amount > 1000, Polars aplica ese filtro mientras lee el CSV en lugar de después de cargar todas las filas.customer_id y amount, Polars omitirá por completo la lectura de transaction_date.Cuando los datos son demasiado grandes para caber en la memoria, Polars ofrece la ejecución en streaming. En lugar de cargar todo de una vez, Polars procesa los datos por lotes, lo que mantiene estable el uso de la memoria.
Esto resulta especialmente útil para archivos CSV o Parquet de varios GB.
Ejemplo (modo streaming):
# Enable streaming execution for huge datasets
stream_result = (
lazy_df
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect(streaming=True) # execute in streaming mode
)Con streaming=True, Polars evita crear enormes tablas intermedias en memoria, lo que lo hace más escalable que pandas para grandes cargas de trabajo.
.collect() y depuración de consultas diferidasEl método ` .collect() ` es el desencadenante para ejecutar una canalización diferida. Antes de eso, puedes inspeccionar y depurar el plan de consulta con:
.describe_plan(): Muestra el plan lógico..describe_optimized_plan(): Muestra el plan optimizado después de que Polars aplique empujones y simplificaciones.Los polares pueden ayudar a mejorar el rendimiento en la ejecución de tus canalizaciones de análisis.
A continuación, se indican algunas prácticas recomendadas:
El análisis del mundo real a menudo requiere combinar conjuntos de datos. Polars ofrece un conjunto completo de operaciones de unión con ejecución optimizada, lo que facilita la fusión incluso de tablas de gran tamaño.
Polars admite todos los tipos de unión principales:
Ejemplo: Unir transacciones con metadatos de clientes
# Create customer metadata DataFrame
customers = pl.DataFrame({
"customer_id": [1, 2, 3, 4, 5],
"customer_name": ["Alice", "Bob", "Charlie", "David", "Eva"]
})
# Inner join on customer_id
df_joined = df.join(customers, on="customer_id", how="inner")
print(df_joined.head())Polars es superior a Pandas en ambas áreas:
Las funciones de ventana permiten realizar cálculos dentro de grupos o sobre filas ordenadas, sin colapsar los resultados, de forma similar a las funciones de ventana SQL.
Polars te permite calcular estadísticas por cliente o por período de tiempo utilizando contextos de ventana.
A continuación, se muestran algunos ejemplos de funciones de ventana que puedes utilizar en Polars:
Ejemplo: Totales acumulados de clientes
df_window = df.with_columns( pl.col("amount") .sort_by("transaction_date") .cum_sum() .over("customer_id") .alias("running_total") )
print(df_window.head())Las funciones de rodadura operan sobre una ventana deslizante de filas o tiempo.
Ejemplo: Suma acumulada de transacciones en los últimos 7 días
df = df.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d")
rolling = (
df.group_by_rolling("transaction_date", period="7d")
.agg(pl.sum("amount").alias("rolling_7d_sum"))
)
print(rolling.head())Las ventanas expandibles (acumulativas) y las ventanas alineadas al centro también son compatibles mediante el ajuste de parámetros.
Puedes utilizar funciones de clasificación y agregaciones personalizadas dentro de las ventanas.
Ejemplo: Clasifica las transacciones por cliente según el importe.
ranked = df.with_columns(
pl.col("amount").rank("dense", descending=True).over("customer_id").alias("rank")
)
print(ranked.head())Esto genera clasificaciones (1 = más alto) para el gasto de cada cliente.
Las funciones de ventana permiten realizar cálculos contextuales:
print(
df.group_by("customer_id").agg(pl.col("amount").cum_sum().alias("cumulative_spent"))
)Para los analistas acostumbrados a SQL, Polars proporciona un contexto SQL que permite consultar DataFrame directamente con sintaxis SQL sin renunciar a la velocidad de Polars.
Para empezar, debes registrar un DataFrame antes de ejecutar SQL.
from polars import SQLContext
ctx = SQLContext()
ctx.register("transactions", df)Veamos un ejemplo de cómo ejecutar una consulta SQL en Python utilizando Polars.
Ejemplo: Consultar el gasto total por cliente en SQL
result = ctx.execute("""
SELECT customer_id, SUM(amount) AS total_spent
FROM transactions
GROUP BY customer_id
ORDER BY total_spent DESC
""").collect()
print(result)Puedes mezclar SQL y expresiones:
sql_result = ctx.execute("SELECT * FROM transactions WHERE amount > 1500")
df_sql = sql_result.collect()
# Continue with Polars expressions
df_sql = df_sql.with_columns((pl.col("amount") * 0.95).alias("discounted"))Esto resulta útil para equipos que están pasando de herramientas basadas en SQL.
Polars no está diseñado como una isla independiente, sino como una biblioteca DataFrame de alto rendimiento que funciona bien con el ecosistema de datos Python más amplio. Esta interoperabilidad garantiza que los analistas e ingenieros puedan adoptar Polars de forma gradual sin dejar de aprovechar las herramientas existentes.
A continuación se indican algunas áreas de integración:
Por último, echemos un vistazo rápido a algunos ejemplos del uso de polares:
df = df.with_columns([
pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d").alias("txn_date"),
pl.col("amount").fill_null(strategy="mean")
])result = (
pl.read_csv("transactions.csv")
.lazy()
.filter(pl.col("amount") > 1000)
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect()
)A continuación se muestra un ejemplo de medias móviles para importes de transacciones.
import polars as pl
# Load & parse dates
df = (
pl.read_csv("transactions.csv")
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d"))
)
# (A) Overall: daily totals + 7-day rolling average
daily = (
df.sort("transaction_date")
.group_by_dynamic("transaction_date", every="1d")
.agg(pl.sum("amount").alias("daily_total"))
.sort("transaction_date")
.with_columns(
pl.col("daily_total").rolling_mean(window_size=7).alias("ma7")
)
)
# (B) Per-customer: daily totals + 7-day rolling average within each customer
daily_by_cust = (
df.sort("transaction_date")
.group_by_dynamic(index_column="transaction_date", every="1d", by="customer_id")
.agg(pl.sum("amount").alias("daily_total"))
.sort(["customer_id", "transaction_date"])
.with_columns(
pl.col("daily_total")
.rolling_mean(window_size=7)
.over("customer_id")
.alias("ma7_per_customer")
)
)
print(daily.tail())
print(daily_by_cust.filter(pl.col("customer_id")==1).tail())Este es el resultado esperado:
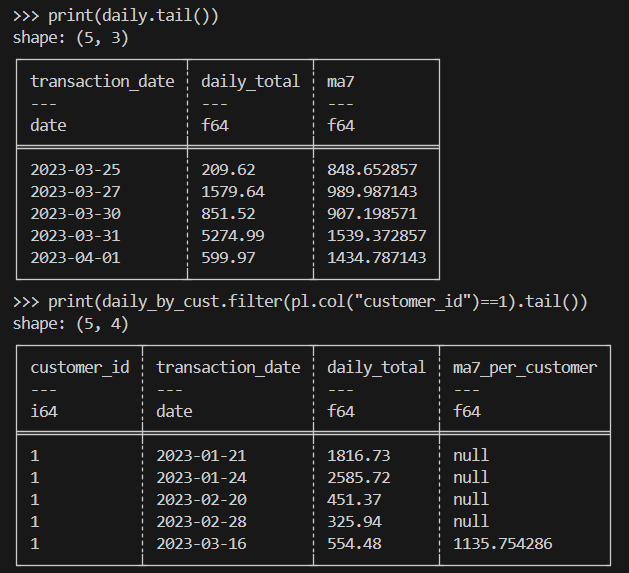
Al realizar cálculos científicos, tendrás que manejar de manera eficiente millones de filas de datos experimentales o simulados similares a transacciones.
Aquí tienes un ejemplo de implementación:
import polars as pl
# Assume a very large Parquet file with columns: id, value, ts (UTC)
# Use lazy scan_* to avoid loading into memory up-front
lazy = (
pl.scan_parquet("experiments.parquet") # or: pl.scan_csv("experiments.csv")
.filter(pl.col("value") > 0) # predicate pushdown
.select(["id", "value", "ts"]) # projection pushdown
.with_columns(
# Example transformations: standardization & bucketize timestamps by hour
((pl.col("value") - pl.col("value").mean()) / pl.col("value").std())
.alias("z_value"),
pl.col("ts").dt.truncate("1h").alias("ts_hour")
)
.group_by(["id", "ts_hour"])
.agg([
pl.len().alias("n"),
pl.mean("z_value").alias("z_mean"),
pl.std("z_value").alias("z_std")
])
.sort(["id", "ts_hour"])
)
# Execute in streaming mode to keep memory usage low
result = lazy.collect(streaming=True)
# Optionally write out partitioned Parquet for downstream analysis
result.write_parquet("experiments_hourly_stats.parquet")
print(result.head())Python Polars ofrece una biblioteca DataFrame moderna y de alto rendimiento que soluciona muchas de las limitaciones de pandas. Aunque pandas sigue siendo popular para análisis ad hoc más pequeños, Polars se está convirtiendo cada vez más en la herramienta preferida para el procesamiento de datos escalable, eficiente y fiable en Python.
¿Quieres saber más sobre Polars? Te encantará nuestro curso de Introducción a los polares o nuestro artículo Introducción a los polares. Nuestros motor Polars también te puede interesar.
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Matt Crabtree
15 min
Tutorial
Vidhi Chugh
Tutorial
Karlijn Willems
Tutorial
Oluseye Jeremiah
Tutorial
Satyabrata Pal
