Cursus
Principes de base des données en Python
28 h
Dans le domaine de l'analyse de données, pandas est depuis longtemps le choix par défaut des professionnels des données pour traiter les données tabulaires en Python.
Cependant, à mesure que les ensembles de données gagnent en taille et en complexité, pandas peut rencontrer des problèmes de performances, une utilisation limitée des processeurs multicœurs et des contraintes de mémoire.
C'est là que Polars se présente comme une alternative moderne. Polars est une bibliothèque DataFrame écrite en Rust qui offre des performances exceptionnelles, une gestion efficace de la mémoire et une philosophie de conception axée sur l'évolutivité.
Dans ce tutoriel, nous vous expliquerons ce qu'est Polars et comment effectuer certaines opérations Polars de base en Python. Si vous souhaitez acquérir une expérience pratique, je vous recommande de suivre le cours Introduction aux polaires.
Polars propose un ensemble unique de fonctionnalités qui le distinguent de pandas :
Polars prend en charge un large éventail de types de données au-delà des types de base :
Int32, Int64, Float32, Float64.true/false.Date, Datetime, Duration, Time.List et Struct, utiles pour les données de type JSON.En tant qu'alternative plus récente et plus moderne à pandas, Polars offre plusieurs avantages :
Maintenant, examinons comment nous pouvons commencer à utiliser Polars pour nous-mêmes dans Python.
Avant d'utiliser Polars, il est nécessaire de configurer correctement l'environnement.
Polars est compatible avec Windows, macOS et Linux. Veuillez consulter l'. Il peut être installé dans des environnements virtuels, dans le système Python ou via des workflows conteneurisés (Docker).
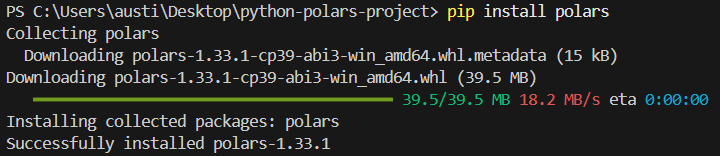
Pour installer la bibliothèque polars dans Python, veuillez exécuter la commande suivante dans le terminal.
pip install polarsLe message d'installation suivant devrait s'afficher :
Vous pouvez également installer la bibliothèque dans l'environnement conda si c'est celui que vous utilisez.
conda install -c conda-forge polarsPour vérifier si votre installation s'est déroulée correctement, veuillez rédiger le script simple suivant :
import polars as pl
print(pl.__version__)Polars vous permet de régler son fonctionnement et l'affichage de ses résultats en définissant des variables d'environnement avant de démarrer votre session Python. Par exemple :
POLARS_MAX_THREADS: Veuillez limiter le nombre de fils.POLARS_FMT_MAX_COLS: Contrôlez le nombre de colonnes imprimées.POLARS_FMT_TABLE_WIDTH: Ajuster la largeur d'affichage du DataFrame.Voici un exemple illustrant comment définir ces variables dans un shell avant d'exécuter Python :
export POLARS_MAX_THREADS=8
export POLARS_FMT_MAX_COLS=20Avant d'aborder les fonctionnalités de Polars, il est utile de disposer d'un ensemble de données que nous pourrons utiliser de manière cohérente tout au long de ce tutoriel. Nous pouvons générer un fichier CSV simple à l'aide du module csv intégré à Python ou de pandas.
Voici un exemple qui crée un fichier transactions.csv avec des données synthétiques :
import csv
import random
from datetime import datetime, timedelta
# Define column names
columns = ["transaction_id", "customer_id", "amount", "transaction_date"]
# Generate synthetic rows
rows = []
start_date = datetime(2023, 1, 1)
for i in range(1, 101):
customer_id = random.randint(1, 10)
amount = round(random.uniform(10, 2000), 2)
date = start_date + timedelta(days=random.randint(0, 90))
rows.append([i, customer_id, amount, date.strftime("%Y-%m-%d")])
# Write to CSV
with open("transactions.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(columns)
writer.writerows(rows)Ce script génère un ensemble de données comprenant 100 transactions avec des montants, des identifiants clients et des dates de transaction aléatoires. Vous pouvez ajuster la portée et la taille en fonction de vos besoins.
Veuillez enregistrer ce script, l'exécuter une fois, et vous obtiendrez un fichier CSV à utiliser dans les exemples présentés tout au long de cet article.
Polars repose sur deux abstractions fondamentales : la série et le DataFrame.
Ensemble, ils offrent une méthode structurée et efficace pour travailler avec des données, similaire dans son esprit à pandas, mais optimisée grâce au backend Rust de Polars. Analysons les concepts principaux.
Une série dans Polars est un tableau unidimensionnel, similaire à une colonne dans une feuille de calcul ou un tableau de base de données. Chaque série comprend :
Int64, Utf8, Float64, Boolean, etc.).Étant donné que le type de données est strictement appliqué, les séries dans Polars ont tendance à être plus rapides et plus prévisibles que les listes Python.
Exemple :
import polars as pl
# Create a Series of integers
s = pl.Series("numbers", [1, 2, 3, 4, 5])
print(s)Résultat:
shape: (5,)
Series: 'numbers' [i64]
[
1
2
3
4
5
]
Un DataFrame est une structure bidimensionnelle qui organise plusieurs séries ensemble sous un schéma. Conceptuellement, cela s'apparente à un tableau dans SQL ou Excel. Les lignes représentent les enregistrements et les colonnes représentent les champs.
Exemple :
df = pl.DataFrame({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35]
})
print(df)Résultat:
shape: (3, 3)
┌─────┬─────────┬─────┐
│ id │ name │ age │
│ --- │ --- │ --- │
│ i64 │ str │ i64 │
├─────┼─────────┼─────┤
│ 1 │ Alice │ 25 │
│ 2 │ Bob │ 30 │
│ 3 │ Charlie │ 35 │
└─────┴─────────┴─────┘Chaque colonne est une série, et le DataFrame applique son schéma.
L'un des points forts de Polars réside dans l'application stricte des schémas. Chaque colonne possède un type de données fixe, et Polars veille à ce que toutes les opérations le respectent. Cela permet d'éviter les erreurs subtiles qui surviennent dans les opérations de typage dynamique.
Par exemple, il n'est pas possible d'ajouter accidentellement une colonne de type chaîne à une colonne de type entier sans conversion explicite.
Exemple:
df = df.with_columns(
(pl.col("age") + 5).alias("age_plus_5")
)
print(df)Ici, age correspond à i64, et le résultat reste un nombre entier. Si vous avez tenté d'ajouter une colonne de type chaîne, Polars générerait une erreur au lieu d'échouer silencieusement.
Les données réelles comportent souvent des valeurs manquantes, et Polars fournit des outils clairs pour les traiter :
fill_null(): Remplacer les valeurs nulles par une valeur spécifiée.drop_nulls(): Veuillez supprimer les lignes contenant des valeurs nulles.is_null() / is_not_null(): Vérifications booléennes.Polars promeut un système d'expression où les opérations sont définies comme des transformations sur des colonnes plutôt que comme des boucles Python ligne par ligne.
Ces expressions sont vectorisées, ce qui signifie qu'elles opèrent sur des colonnes entières à la fois, ce qui est beaucoup plus rapide.
Au lieu d'effectuer des boucles manuellement, Polars met en place un calcul vectorisé rapide.
Polars propose deux modes d'exécution :
Voici un exemple d'exécution anticipée :
df = pl.DataFrame({"x": [1, 2, 3]})
print(df.select(pl.col("x") * 2)) # eager: runs instantlyVoici un exemple d'exécution différée :
lazy_df = pl.DataFrame({"x": [1, 2, 3]}).lazy()
result = lazy_df.select(pl.col("x") * 2).collect() # execute on collect()
print(result)Ici, aucun calcul n'est effectué tant que la fonction ` .collect() ` n'est pas appelée. Dans les flux de travail importants, cela peut entraîner des améliorations significatives des performances.
Ensuite, nous examinerons la réalisation de certaines opérations de base utilisées dans Polars sur l'ensemble de données que nous avons créé.
Les polars peuvent traiter des données provenant de plusieurs formats de fichiers et objets mémoire. Cela le rend flexible pour une intégration dans les pipelines de données modernes.
Voici comment procéder pour différentes sources :
À partir de l'ensemble de données CSV que nous avons créé précédemment :
import polars as pl
df = pl.read_csv("transactions.csv")
print(df.head())Nous pouvons également lire l'ensemble de données à partir de Parquet si nécessaire.
df_parquet = pl.read_parquet("transactions.parquet")Si vous disposez d'un fichier JSON, vous pouvez le lire à l'aide du code suivant :
df_json = pl.read_json("transactions.json")
#For JSON Lines (NDJSON), use the following instead:
df_json = pl.read_ndjson("transactions.json")Voici comment lire les ensembles de données à partir d'une table Arrow :
import pyarrow as pa
arrow_table = pa.table({
"transaction_id": [1, 2],
"customer_id": [5, 7],
"amount": [150.25, 300.75],
"transaction_date": ["2023-01-02", "2023-01-03"]
})
df_arrow = pl.from_arrow(arrow_table)Sélectionnons maintenant des colonnes ou des lignes spécifiques dans notre ensemble de données.
Lorsque vous utilisez Polars, une opération courante consiste à sélectionner les colonnes sur lesquelles vous souhaitez travailler et que vous souhaitez conserver.
Voici comment procéder :
# Select only transaction_id and amount
df.select(["transaction_id", "amount"])Vous pouvez également filtrer les lignes en fonction des conditions que vous définissez, de manière similaire à pandas.
# Get only high-value transactions above $1,000
high_value = df.filter(pl.col("amount") > 1000)
print(high_value)L'application d'expressions dans Polars implique l'utilisation de l'objet polars.Expr dans divers contextes afin d'effectuer des transformations de données.
Vous pouvez les créer à l'aide de pl.col() ou pl.lit().
# Add a 10% discount column to simulate promotional pricing
df.select([
pl.col("transaction_id"),
pl.col("amount"),
(pl.col("amount") * 0.9).alias("discounted_amount")
])Nous pouvons analyser les habitudes de dépenses par client à l'aide de group_by.
# Total and average spend per customer
agg_df = df.group_by("customer_id").agg([
pl.sum("amount").alias("total_spent"),
pl.mean("amount").alias("avg_transaction")
])
print(agg_df)Exemple de résultat :
shape: (10, 3)
┌─────────────┬────────────┬───────────────┐
│ customer_id │ total_spent│ avg_transaction│
│ --- │ --- │ --- │
│ i64 │ f64 │ f64 │
├─────────────┼────────────┼───────────────┤
│ 1 │ 5230.12 │ 523.01 │
│ 2 │ 6120.45 │ 680.05 │
│ ... │ ... │ ... │
└─────────────┴────────────┴───────────────┘Notre ensemble de données généré ne contient aucune valeur nulle par défaut, mais nous allons simuler la manière dont nous les traiterions.
Les valeurs manquantes peuvent entraîner des problèmes dans l'analyse en aval et la visualisation des données. Il est nécessaire de compléter les valeurs manquantes afin de garantir le bon déroulement des opérations.
Voici comment vous pouvez compléter les valeurs manquantes :
# Imagine 'amount' has missing values, then replace with 0
df_filled = df.with_columns(
pl.col("amount").fill_null(0)
)Les valeurs nulles peuvent entraîner des erreurs si elles ne sont pas traitées. Voici comment les supprimer :
df_no_nulls = df.drop_nulls()Les types de données peuvent être incorrectement formatés dans un ensemble de données. Voici comment vous pouvez les convertir à l'aide de la méthode .cast:
# Ensure customer_id is treated as string instead of int
df_casted = df.with_columns(
pl.col("customer_id").cast(pl.Utf8)
)Polars permet le chaînage de méthodes pour des flux de travail plus efficaces. Cette méthode de chaînage est couramment utilisée dans la programmation SQL ou R à l'aide du package tidyverse.
Exemple: Identifiez les principaux clients du mois de mars en fonction du montant total de leurs dépenses.
pipeline = (
df
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d"))
#.col("date_str").str.to_date(format="%Y-%m-%d")
.filter(pl.col("transaction_date").dt.month() == 3) # transactions in March
.group_by("customer_id")
.agg(pl.sum("amount").alias("march_spent"))
.sort("march_spent", descending=True)
)
print(pipeline)Ce pipeline :
Cette méthode de chaînage permet d'effectuer une analyse en pipeline sans utiliser de DataFrame intermédiaires.
Au-delà des fonctionnalités de base, Polars se distingue particulièrement lors du traitement de grands ensembles de données grâce à son moteur d'évaluation différée. Ce modèle permet à Polars de créer d'abord un plan de requête, de l'optimiser en arrière-plan, puis d'exécuter le pipeline. Il en résulte une augmentation considérable des performances et de l'efficacité, en particulier avec des millions de lignes ou des transformations complexes.
Par défaut, Polars fonctionne en mode « eager ». Cela signifie que les calculs s'effectuent immédiatement, comme avec pandas. Le mode paresseux, cependant, fonctionne différemment :
.collect().Voici un exemple de mode paresseux :
import polars as pl
# Load dataset in lazy mode
lazy_df = pl.scan_csv("transactions.csv")
# Build a transformation pipeline
pipeline = (
lazy_df
.filter(pl.col("amount") > 1000) # step 1: filter expensive transactions
.group_by("customer_id") # step 2: group by customer
.agg(pl.sum("amount").alias("total_spent")) # step 3: aggregate
)
# Nothing has run yet, computation happens only on collect()
result = pipeline.collect()
print(result)Polars optimise les requêtes en appliquant des techniques de pushdown :
amount > 1000, Polars applique ce filtre pendant la lecture du fichier CSV plutôt qu'après le chargement de toutes les lignes.customer_id et amount, Polars ignorera complètement la lecture de transaction_date.Lorsque les données sont trop volumineuses pour tenir dans la mémoire, Polars propose une exécution en continu. Au lieu de tout charger en une seule fois, Polars traite les données par lots, ce qui permet de maintenir une utilisation stable de la mémoire.
Ceci est particulièrement utile pour les fichiers CSV ou Parquet de plusieurs gigaoctets.
Exemple (mode streaming) :
# Enable streaming execution for huge datasets
stream_result = (
lazy_df
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect(streaming=True) # execute in streaming mode
)Grâce à l' streaming=True, Polars évite de créer d'énormes tableaux intermédiaires en mémoire, ce qui le rend plus évolutif que pandas pour les charges de travail importantes.
.collect() et débogage des requêtes paresseusesLa méthode ` .collect() ` déclenche l'exécution d'un pipeline différé. Avant cela, vous pouvez examiner et déboguer le plan de requête à l'aide de :
.describe_plan(): Affiche le plan logique..describe_optimized_plan(): Affiche le plan optimisé après que Polars a appliqué les pushdowns et les simplifications.Les polars peuvent contribuer à améliorer les performances de vos pipelines d'analyse.
Voici quelques bonnes pratiques :
L'analyse du monde réel nécessite souvent la combinaison de plusieurs ensembles de données. Polars offre une suite complète d'opérations de jointure avec une exécution optimisée, facilitant la fusion même de tableaux volumineux.
Polars prend en charge tous les principaux types de jointures :
Exemple : Association des transactions aux métadonnées client
# Create customer metadata DataFrame
customers = pl.DataFrame({
"customer_id": [1, 2, 3, 4, 5],
"customer_name": ["Alice", "Bob", "Charlie", "David", "Eva"]
})
# Inner join on customer_id
df_joined = df.join(customers, on="customer_id", how="inner")
print(df_joined.head())Polars est supérieur à Pandas dans les deux domaines :
Les fonctions de fenêtre permettent d'effectuer des calculs au sein de groupes ou sur des lignes ordonnées, sans réduire les résultats, de manière similaire aux fonctions de fenêtre SQL.
Polars vous permet de calculer des statistiques par client ou par période à l'aide de contextes de fenêtre.
Voici quelques exemples de fonctions de fenêtre que vous pouvez utiliser dans Polars :
Exemple : Totaux cumulés des clients
df_window = df.with_columns( pl.col("amount") .sort_by("transaction_date") .cum_sum() .over("customer_id") .alias("running_total") )
print(df_window.head())Les fonctions glissantes fonctionnent sur une fenêtre glissante de lignes ou de temps.
Exemple : Somme cumulée des transactions sur 7 jours
df = df.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d")
rolling = (
df.group_by_rolling("transaction_date", period="7d")
.agg(pl.sum("amount").alias("rolling_7d_sum"))
)
print(rolling.head())Les fenêtres extensibles (cumulatives) et alignées au centre sont également prises en charge en ajustant les paramètres.
Vous pouvez utiliser des fonctions de classement et des agrégations personnalisées à l'intérieur des fenêtres.
Exemple : Classez les transactions par client en fonction du montant.
ranked = df.with_columns(
pl.col("amount").rank("dense", descending=True).over("customer_id").alias("rank")
)
print(ranked.head())Cela permet d'établir un classement (1 = le plus élevé) pour les dépenses de chaque client.
Les fonctions de fenêtre permettent d'effectuer des calculs contextuels :
print(
df.group_by("customer_id").agg(pl.col("amount").cum_sum().alias("cumulative_spent"))
)Pour les analystes habitués au langage SQL, Polars fournit un contexte SQL qui vous permet d'interroger directement les DataFrame à l'aide de la syntaxe SQL tout en continuant à bénéficier de la rapidité de Polars.
Pour commencer, il est nécessaire d'enregistrer un DataFrame avant d'exécuter SQL.
from polars import SQLContext
ctx = SQLContext()
ctx.register("transactions", df)Examinons un exemple illustrant comment exécuter une requête SQL dans Python à l'aide de Polars.
Exemple : Requête sur le montant total des dépenses par client dans SQL
result = ctx.execute("""
SELECT customer_id, SUM(amount) AS total_spent
FROM transactions
GROUP BY customer_id
ORDER BY total_spent DESC
""").collect()
print(result)Il est possible de combiner SQL et expressions :
sql_result = ctx.execute("SELECT * FROM transactions WHERE amount > 1500")
df_sql = sql_result.collect()
# Continue with Polars expressions
df_sql = df_sql.with_columns((pl.col("amount") * 0.95).alias("discounted"))Ceci est particulièrement utile pour les équipes qui effectuent la transition depuis des outils basés sur SQL.
Polars n'est pas conçu comme une île isolée, mais comme une bibliothèque DataFrame haute performance qui s'intègre parfaitement à l'écosystème de données Python au sens large. Cette interopérabilité permet aux analystes et aux ingénieurs d'adopter Polars de manière progressive tout en continuant à utiliser les outils existants.
Voici quelques domaines d'intégration :
Enfin, examinons rapidement quelques exemples d'utilisation des Polars :
df = df.with_columns([
pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d").alias("txn_date"),
pl.col("amount").fill_null(strategy="mean")
])result = (
pl.read_csv("transactions.csv")
.lazy()
.filter(pl.col("amount") > 1000)
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect()
)Voici un exemple de moyennes mobiles pour les montants des transactions.
import polars as pl
# Load & parse dates
df = (
pl.read_csv("transactions.csv")
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d"))
)
# (A) Overall: daily totals + 7-day rolling average
daily = (
df.sort("transaction_date")
.group_by_dynamic("transaction_date", every="1d")
.agg(pl.sum("amount").alias("daily_total"))
.sort("transaction_date")
.with_columns(
pl.col("daily_total").rolling_mean(window_size=7).alias("ma7")
)
)
# (B) Per-customer: daily totals + 7-day rolling average within each customer
daily_by_cust = (
df.sort("transaction_date")
.group_by_dynamic(index_column="transaction_date", every="1d", by="customer_id")
.agg(pl.sum("amount").alias("daily_total"))
.sort(["customer_id", "transaction_date"])
.with_columns(
pl.col("daily_total")
.rolling_mean(window_size=7)
.over("customer_id")
.alias("ma7_per_customer")
)
)
print(daily.tail())
print(daily_by_cust.filter(pl.col("customer_id")==1).tail())Voici le résultat escompté :
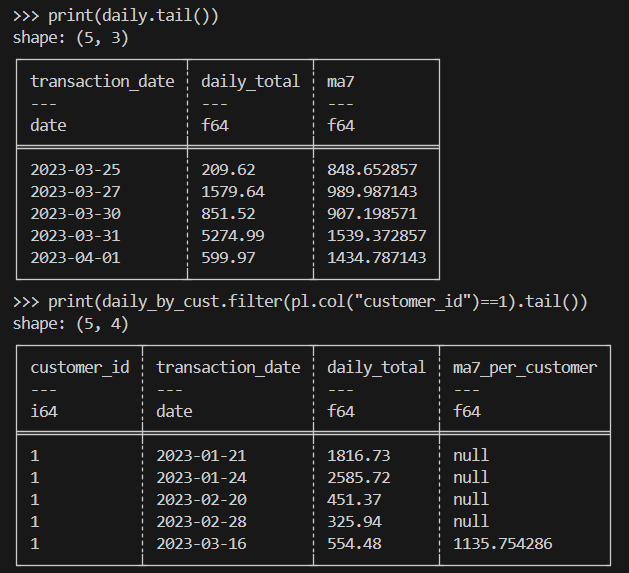
Lorsque vous effectuez des calculs scientifiques, vous devez traiter efficacement des millions de lignes de données expérimentales ou simulées de type transactionnel.
Voici un exemple d'implémentation :
import polars as pl
# Assume a very large Parquet file with columns: id, value, ts (UTC)
# Use lazy scan_* to avoid loading into memory up-front
lazy = (
pl.scan_parquet("experiments.parquet") # or: pl.scan_csv("experiments.csv")
.filter(pl.col("value") > 0) # predicate pushdown
.select(["id", "value", "ts"]) # projection pushdown
.with_columns(
# Example transformations: standardization & bucketize timestamps by hour
((pl.col("value") - pl.col("value").mean()) / pl.col("value").std())
.alias("z_value"),
pl.col("ts").dt.truncate("1h").alias("ts_hour")
)
.group_by(["id", "ts_hour"])
.agg([
pl.len().alias("n"),
pl.mean("z_value").alias("z_mean"),
pl.std("z_value").alias("z_std")
])
.sort(["id", "ts_hour"])
)
# Execute in streaming mode to keep memory usage low
result = lazy.collect(streaming=True)
# Optionally write out partitioned Parquet for downstream analysis
result.write_parquet("experiments_hourly_stats.parquet")
print(result.head())Python Polars propose une bibliothèque DataFrame moderne et performante qui pallie bon nombre des limites de pandas. Alors que pandas reste populaire pour les analyses ponctuelles de petite envergure, Polars s'impose de plus en plus comme l'outil de choix pour le traitement de données évolutif, efficace et fiable en Python.
Souhaitez-vous en savoir plus sur Polars ? Vous apprécierez notre cours d'cours d'introduction aux polaires ou notre article Introduction aux polaires. Nos moteur Polars pourrait également vous intéresser.
Meilleurs cours DataCamp
Cursus
Cours
Cours
Tutoriel
Satyabrata Pal
Tutoriel
Sejal Jaiswal
Tutoriel
Sejal Jaiswal
Tutoriel
Aditya Sharma
Tutoriel
DataCamp Team
Tutoriel
Mark Pedigo