Lernpfad
Python Daten Grundlagen
28 Std.
In der Welt der Datenanalyse ist Pandas schon lange die erste Wahl für Datenprofis, wenn es darum geht, tabellarische Daten in Python zu bearbeiten.
Wenn die Datensätze aber größer und komplizierter werden, kann es bei Pandas zu Performance-Problemen, eingeschränkter Multi-Core-Nutzung und Speicherengpässen kommen.
Hier kommt Polars als coole Alternative ins Spiel. Polars ist eine in Rust geschriebene DataFrame-Bibliothek, die super schnelle Leistung, effizientes Speichermanagement und ein Design bietet, das auf Skalierbarkeit ausgerichtet ist.
In diesem Tutorial zeigen wir dir, was Polars ist und wie du ein paar grundlegende Polars-Operationen in Python machst. Wenn du praktische Erfahrungen sammeln möchtest, empfehle ich dir den Kurs „Einführung in Polars“.
Polars hat ein paar coole Features, die es von Pandas unterscheiden:
Polars unterstützt eine ganze Reihe von Datentypen, die über die Basistypen hinausgehen:
Int32, Int64, Float32, Float64.true “ (wahr) und „false “ (falsch).Date, Datetime, Duration, Time.List ” und „ Struct ”, die für JSON-ähnliche Daten nützlich sind.Als die neuere und modernere Alternative zu Pandas hat Polars ein paar Vorteile:
Schauen wir uns jetzt mal an, wie wir Polars in Python für uns nutzen können.
Bevor du Polars nutzen kannst, musst du die Umgebung richtig einrichten.
Polars läuft auf Windows, macOS und Linux-. Es kann in virtuellen Umgebungen, im System Python oder über containerisierte Workflows (Docker) installiert werden.
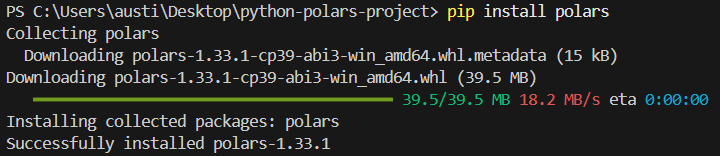
Um die Bibliothek „ polars ” in Python zu installieren, gib einfach den folgenden Befehl im Terminal ein.
pip install polarsDu solltest die folgende Installationsmeldung sehen:
Du kannst die Bibliothek auch in der conda-Umgebung installieren, wenn du damit arbeitest.
conda install -c conda-forge polarsUm zu checken, ob deine Installation erfolgreich war, schreib das folgende einfache Skript:
import polars as pl
print(pl.__version__)Mit Polars kannst du einstellen, wie es läuft und wie die Ergebnisse angezeigt werden, indem du vor dem Start deiner Python-Sitzung Umgebungsvariablen festlegst. Zum Beispiel:
POLARS_MAX_THREADS: Begrenze die Anzahl der Threads.POLARS_FMT_MAX_COLS: Steuer die Anzahl der gedruckten Spalten.POLARS_FMT_TABLE_WIDTH: Die Breite der DataFrame-Anzeige anpassen.Hier ist ein Beispiel, wie du diese Variablen in einer shell setzen würdest, bevor du Python startest:
export POLARS_MAX_THREADS=8
export POLARS_FMT_MAX_COLS=20Bevor wir uns mit den Funktionen von Polars beschäftigen, wäre es gut, einen Datensatz zu haben, den wir in diesem Tutorial immer wieder verwenden können. Wir können eine einfache CSV-Datei mit dem in Python integrierten CSV-Modul oder mit Pandas erstellen.
Hier ist ein Beispiel, das eine Datei namens „transactions.csv“ mit erfundenen Daten erstellt:
import csv
import random
from datetime import datetime, timedelta
# Define column names
columns = ["transaction_id", "customer_id", "amount", "transaction_date"]
# Generate synthetic rows
rows = []
start_date = datetime(2023, 1, 1)
for i in range(1, 101):
customer_id = random.randint(1, 10)
amount = round(random.uniform(10, 2000), 2)
date = start_date + timedelta(days=random.randint(0, 90))
rows.append([i, customer_id, amount, date.strftime("%Y-%m-%d")])
# Write to CSV
with open("transactions.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(columns)
writer.writerows(rows)Dieses Skript erstellt einen Datensatz mit 100 Transaktionen mit zufälligen Beträgen, Kunden-IDs und Transaktionsdaten. Du kannst den Bereich und die Größe nach deinen Bedürfnissen anpassen.
Speicher dieses Skript, führ es einmal aus, und schon hast du eine CSV-Datei, die du in den Beispielen in diesem Artikel verwenden kannst.
Polars basiert auf zwei Kernabstraktionen: der Serie und dem DataFrame.
Zusammen bieten sie eine strukturierte, effiziente Methode zur Arbeit mit Daten, ähnlich wie Pandas, aber optimiert mit dem Rust-basierten Backend von Polars. Schauen wir uns mal die wichtigsten Konzepte an.
Eine Reihe in Polars ist ein eindimensionales Array, ähnlich wie eine Spalte in einer Tabellenkalkulation oder einer Datenbank Tabelle. Jede Serie hat:
Int64, Utf8, Float64, Boolean usw.).Weil der Datentyp streng durchgesetzt wird, sind Reihen in Polars meistens schneller und berechenbarer als Python-Listen.
Beispiel:
import polars as pl
# Create a Series of integers
s = pl.Series("numbers", [1, 2, 3, 4, 5])
print(s)Ausgabe:
shape: (5,)
Series: 'numbers' [i64]
[
1
2
3
4
5
]
Ein DataFrame ist eine zweidimensionale Struktur, die mehrere Serien unter einem Schema zusammenfasst. Konzeptionell ist es wie eine Tabelle in SQL oder Excel. Zeilen sind Datensätze und Spalten sind Felder.
Beispiel:
df = pl.DataFrame({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35]
})
print(df)Ausgabe:
shape: (3, 3)
┌─────┬─────────┬─────┐
│ id │ name │ age │
│ --- │ --- │ --- │
│ i64 │ str │ i64 │
├─────┼─────────┼─────┤
│ 1 │ Alice │ 25 │
│ 2 │ Bob │ 30 │
│ 3 │ Charlie │ 35 │
└─────┴─────────┴─────┘Jede Spalte ist eine Serie, und der DataFrame sorgt dafür, dass das Schema eingehalten wird.
Eine der Stärken von Polars ist die strenge Durchsetzung von Schemata. Jede Spalte hat einen festen Datentyp, und Polars sorgt dafür, dass alle Operationen diesen respektieren. Das verhindert kleine Fehler, die bei dynamisch typisierten Operationen auftreten können.
Du kannst zum Beispiel nicht einfach so eine Zeichenfolgen-Spalte zu einer Ganzzahl-Spalte hinzufügen, ohne sie vorher umzuwandeln.
Beispiel:
df = df.with_columns(
(pl.col("age") + 5).alias("age_plus_5")
)
print(df)Hier ist „ age “ gleich „ i64 “, und das Ergebnis bleibt eine ganze Zahl. Wenn du versucht hast, eine Zeichenfolgen-Spalte hinzuzufügen, würde Polars einen Fehler melden, anstatt stillschweigend zu scheitern.
In echten Daten fehlen oft Werte, und Polars hat coole Tools, um damit umzugehen:
fill_null(): Ersetze Nullwerte durch einen bestimmten Wert.drop_nulls(): Entferne Zeilen, die Nullwerte enthalten.is_null() / is_not_null(): Boolesche Überprüfungen.Polars setzt auf ein Ausdruckssystem, bei dem Operationen als Transformationen auf Spalten definiert sind und nicht als Zeile für Zeile ablaufende Python-Schleifen.
Diese Ausdrücke sind vektorisiert, was bedeutet, dass sie auf ganze Spalten gleichzeitig angewendet werden, was viel schneller ist.
Anstatt manuell zu loopen, macht Polars eine schnelle vektorisierte Berechnung.
Polars hat zwei Ausführungsmodi:
Hier ist ein Beispiel für eine eifrige Ausführung:
df = pl.DataFrame({"x": [1, 2, 3]})
print(df.select(pl.col("x") * 2)) # eager: runs instantlyHier ist ein Beispiel für eine verzögerte Ausführung:
lazy_df = pl.DataFrame({"x": [1, 2, 3]}).lazy()
result = lazy_df.select(pl.col("x") * 2).collect() # execute on collect()
print(result)Hier wird erst was berechnet, wenn „ .collect() “ aufgerufen wird. Bei großen Arbeitsabläufen kann das zu einer deutlichen Leistungssteigerung führen.
Als Nächstes schauen wir uns an, wie man ein paar grundlegende Operationen, die in Polars verwendet werden, auf den von uns erstellten Datensatz anwendet.
Polars kann Daten aus verschiedenen Dateiformaten und Speicherobjekten einlesen. Das macht es flexibel für die Integration in moderne Datenpipelines.
So kannst du das für verschiedene Quellen machen:
Aus dem CSV-Datensatz, den wir vorher erstellt haben:
import polars as pl
df = pl.read_csv("transactions.csv")
print(df.head())Bei Bedarf können wir den Datensatz auch aus Parquet einlesen.
df_parquet = pl.read_parquet("transactions.parquet")Wenn du stattdessen eine JSON-Datei hast, kannst du sie mit diesem Code lesen:
df_json = pl.read_json("transactions.json")
#For JSON Lines (NDJSON), use the following instead:
df_json = pl.read_ndjson("transactions.json")So liest du Datensätze aus einer Arrow-Tabelle:
import pyarrow as pa
arrow_table = pa.table({
"transaction_id": [1, 2],
"customer_id": [5, 7],
"amount": [150.25, 300.75],
"transaction_date": ["2023-01-02", "2023-01-03"]
})
df_arrow = pl.from_arrow(arrow_table)Jetzt schauen wir uns bestimmte Spalten oder Zeilen aus unserem Datensatz an.
Bei der Verwendung von Polars ist es üblich, die Spalten auszuwählen, die du bearbeiten und behalten möchtest.
So kannst du das machen:
# Select only transaction_id and amount
df.select(["transaction_id", "amount"])Du kannst Zeilen auch nach Bedingungen filtern, die du festlegst, ähnlich wie bei Pandas.
# Get only high-value transactions above $1,000
high_value = df.filter(pl.col("amount") > 1000)
print(high_value)Um Ausdrücke in Polars anzuwenden, musst du das Objekt „ polars.Expr “ in verschiedenen Kontexten nutzen, um Daten zu transformieren.
Du kannst sie mit pl.col() oder pl.lit() erstellen.
# Add a 10% discount column to simulate promotional pricing
df.select([
pl.col("transaction_id"),
pl.col("amount"),
(pl.col("amount") * 0.9).alias("discounted_amount")
])Wir können die Ausgabengewohnheiten der Kunden mit „ group_by “ analysieren.
# Total and average spend per customer
agg_df = df.group_by("customer_id").agg([
pl.sum("amount").alias("total_spent"),
pl.mean("amount").alias("avg_transaction")
])
print(agg_df)Beispielausgabe:
shape: (10, 3)
┌─────────────┬────────────┬───────────────┐
│ customer_id │ total_spent│ avg_transaction│
│ --- │ --- │ --- │
│ i64 │ f64 │ f64 │
├─────────────┼────────────┼───────────────┤
│ 1 │ 5230.12 │ 523.01 │
│ 2 │ 6120.45 │ 680.05 │
│ ... │ ... │ ... │
└─────────────┴────────────┴───────────────┘Unser generierter Datensatz hat standardmäßig keine Nullwerte, aber lass uns mal simulieren, wie wir damit umgehen würden.
Fehlende Werte können bei der weiteren Analyse und Datenvisualisierung Probleme verursachen. Du musst alle fehlenden Werte ausfüllen, damit alles reibungslos läuft.
So kannst du fehlende Werte ergänzen:
# Imagine 'amount' has missing values, then replace with 0
df_filled = df.with_columns(
pl.col("amount").fill_null(0)
)Nullwerte können Fehler verursachen, wenn man sie nicht richtig behandelt. So kannst du sie löschen:
df_no_nulls = df.drop_nulls()Die Datentypen in einem Datensatz könnten falsch formatiert sein. So kannst du sie mit der Methode „ .cast “ umwandeln:
# Ensure customer_id is treated as string instead of int
df_casted = df.with_columns(
pl.col("customer_id").cast(pl.Utf8)
)Polars macht es möglich, Methoden zu verketten, was für übersichtlichere Arbeitsabläufe sorgt. Diese Verkettungsmethode wird oft in SQL oder bei der Programmierung mit R mit dem Tidyverse-Paket benutzt.
Beispiel: Finde die Top-Kunden im März nach Gesamtausgaben
pipeline = (
df
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d"))
#.col("date_str").str.to_date(format="%Y-%m-%d")
.filter(pl.col("transaction_date").dt.month() == 3) # transactions in March
.group_by("customer_id")
.agg(pl.sum("amount").alias("march_spent"))
.sort("march_spent", descending=True)
)
print(pipeline)Diese Pipeline:
Mit dieser Verkettungsmethode kann man eine Pipeline-Analyse machen, ohne zwischengeschaltete DataFrames zu brauchen.
Über die Grundlagen hinaus ist Polars dank seiner Lazy-Evaluation-Engine besonders gut bei der Arbeit mit großen Datensätzen. Mit diesem Modell kann Polars erst mal einen Abfrageplan erstellen, ihn im Hintergrund optimieren und dann die Pipeline ausführen. Das Ergebnis ist ein enormer Schub bei der Leistung und Effizienz, vor allem bei Millionen von Zeilen oder komplizierten Transformationen.
Standardmäßig läuft Polars im Eager-Modus. Das heißt, die Berechnungen laufen sofort ab, ähnlich wie bei Pandas. Der Lazy-Modus funktioniert aber anders:
.collect() “ aufrufst.Hier ist ein Beispiel für den Lazy-Modus:
import polars as pl
# Load dataset in lazy mode
lazy_df = pl.scan_csv("transactions.csv")
# Build a transformation pipeline
pipeline = (
lazy_df
.filter(pl.col("amount") > 1000) # step 1: filter expensive transactions
.group_by("customer_id") # step 2: group by customer
.agg(pl.sum("amount").alias("total_spent")) # step 3: aggregate
)
# Nothing has run yet, computation happens only on collect()
result = pipeline.collect()
print(result)Polars macht Abfragen schneller, indem es Pushdown-Techniken einsetzt:
amount > 1000 wendet Polars diesen Filter beim Lesen der CSV-Datei an, statt erst nach dem Laden aller Zeilen.customer_id “ und „ amount “ auswählst, überspringt Polars das Lesen von „ transaction_date “ komplett.Wenn die Daten zu groß sind, um in den Speicher zu passen, bietet Polars Streaming-Ausführung an. Anstatt alles auf einmal zu laden, verarbeitet Polars die Daten in Stapeln, sodass der Speicherverbrauch stabil bleibt.
Das ist besonders praktisch für CSV- oder Parquet-Dateien, die mehrere GB groß sind.
Beispiel (Streaming-Modus):
# Enable streaming execution for huge datasets
stream_result = (
lazy_df
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect(streaming=True) # execute in streaming mode
)Mit „ streaming=True ” vermeidet Polars das Erstellen riesiger Zwischentabellen im Arbeitsspeicher, wodurch es für große Arbeitslasten besser skalierbar ist als Pandas.
.collect() und Debugging von Lazy QueriesDie Methode „ .collect() “ ist der Auslöser für die Ausführung einer Lazy-Pipeline. Vorher kannst du den Abfrageplan mit folgendem Befehl überprüfen und debuggen:
.describe_plan(): Zeigt den logischen Plan..describe_optimized_plan(): Zeigt den optimierten Plan, nachdem Polars Pushdowns und Vereinfachungen angewendet hat.Polars kann dir dabei helfen, die Leistung deiner Analyse-Pipelines zu verbessern.
Hier sind ein paar bewährte Methoden:
In der Praxis muss man oft mehrere Datensätze zusammenführen. Polars bietet eine ganze Reihe von Verknüpfungsoperationen mit optimierter Ausführung, sodass man auch große Tabellen einfach zusammenführen kann.
Polars unterstützt alle gängigen Verknüpfungstypen:
Beispiel: Transaktionen mit Kunden-Metadaten verbinden
# Create customer metadata DataFrame
customers = pl.DataFrame({
"customer_id": [1, 2, 3, 4, 5],
"customer_name": ["Alice", "Bob", "Charlie", "David", "Eva"]
})
# Inner join on customer_id
df_joined = df.join(customers, on="customer_id", how="inner")
print(df_joined.head())Polars ist Pandas in beiden Bereichen überlegen:
Fensterfunktionen ermöglichen Berechnungen innerhalb von Gruppen oder über geordnete Zeilen, ohne die Ergebnisse zusammenzufassen, ähnlich wie SQL-Fensterfunktionen.
Mit Polars kannst du Statistiken pro Kunde oder pro Zeitraum mit Fensterkontexten berechnen.
Hier sind ein paar Beispiele für Fensterfunktionen, die du in Polars nutzen kannst:
Beispiel: Kunden-Zwischensummen
df_window = df.with_columns( pl.col("amount") .sort_by("transaction_date") .cum_sum() .over("customer_id") .alias("running_total") )
print(df_window.head())Rollierende Funktionen werden über ein gleitendes Fenster von Zeilen oder Zeit angewendet.
Beispiel: 7-Tage-Summe der Transaktionen
df = df.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d")
rolling = (
df.group_by_rolling("transaction_date", period="7d")
.agg(pl.sum("amount").alias("rolling_7d_sum"))
)
print(rolling.head())Durch Anpassen von Parametern werden auch erweiterbare Fenster (kumulativ) und zentrierte Fenster unterstützt.
Du kannst Ranking-Funktionen und benutzerdefinierte Aggregationen innerhalb von Fenstern nutzen.
Beispiel: Ordne die Transaktionen pro Kunde nach Betrag
ranked = df.with_columns(
pl.col("amount").rank("dense", descending=True).over("customer_id").alias("rank")
)
print(ranked.head())Das ergibt eine Rangliste (1 = am höchsten) für die Ausgaben jedes Kunden.
Fensterfunktionen ermöglichen kontextbezogene Berechnungen:
print(
df.group_by("customer_id").agg(pl.col("amount").cum_sum().alias("cumulative_spent"))
)Für Leute, die mit SQL arbeiten, bietet Polars einen SQL-Kontext, sodass du DataFrame direkt mit SQL-Syntax abfragen kannst, während du trotzdem die Geschwindigkeit von Polars nutzt.
Bevor du loslegst, musst du einen DataFrame registrieren, bevor du SQL ausführen kannst.
from polars import SQLContext
ctx = SQLContext()
ctx.register("transactions", df)Schauen wir uns mal ein Beispiel an, wie man mit Polars eine SQL-Abfrage in Python macht.
Beispiel: Frage: Gesamtkosten pro Kunde in SQL
result = ctx.execute("""
SELECT customer_id, SUM(amount) AS total_spent
FROM transactions
GROUP BY customer_id
ORDER BY total_spent DESC
""").collect()
print(result)Du kannst SQL und Ausdrücke mischen:
sql_result = ctx.execute("SELECT * FROM transactions WHERE amount > 1500")
df_sql = sql_result.collect()
# Continue with Polars expressions
df_sql = df_sql.with_columns((pl.col("amount") * 0.95).alias("discounted"))Das ist super für Teams, die von SQL-basierten Tools umsteigen.
Polars ist nicht als eigenständige Insel gedacht, sondern als leistungsstarke DataFrame-Bibliothek, die super mit dem breiteren Python-Daten-Ökosystem zusammenarbeitet. Dank dieser Interoperabilität können Analysten und Ingenieure Polars nach und nach einführen und trotzdem ihre vorhandenen Tools weiter nutzen.
Hier sind ein paar Bereiche, in denen Integration stattfindet:
Zum Schluss schauen wir uns noch schnell ein paar Beispiele für die Verwendung von Polars an:
df = df.with_columns([
pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d").alias("txn_date"),
pl.col("amount").fill_null(strategy="mean")
])result = (
pl.read_csv("transactions.csv")
.lazy()
.filter(pl.col("amount") > 1000)
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect()
)Hier ist ein Beispiel für gleitende Durchschnitte von Transaktionsbeträgen.
import polars as pl
# Load & parse dates
df = (
pl.read_csv("transactions.csv")
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d"))
)
# (A) Overall: daily totals + 7-day rolling average
daily = (
df.sort("transaction_date")
.group_by_dynamic("transaction_date", every="1d")
.agg(pl.sum("amount").alias("daily_total"))
.sort("transaction_date")
.with_columns(
pl.col("daily_total").rolling_mean(window_size=7).alias("ma7")
)
)
# (B) Per-customer: daily totals + 7-day rolling average within each customer
daily_by_cust = (
df.sort("transaction_date")
.group_by_dynamic(index_column="transaction_date", every="1d", by="customer_id")
.agg(pl.sum("amount").alias("daily_total"))
.sort(["customer_id", "transaction_date"])
.with_columns(
pl.col("daily_total")
.rolling_mean(window_size=7)
.over("customer_id")
.alias("ma7_per_customer")
)
)
print(daily.tail())
print(daily_by_cust.filter(pl.col("customer_id")==1).tail())Hier ist das Ergebnis, das du erwarten kannst:
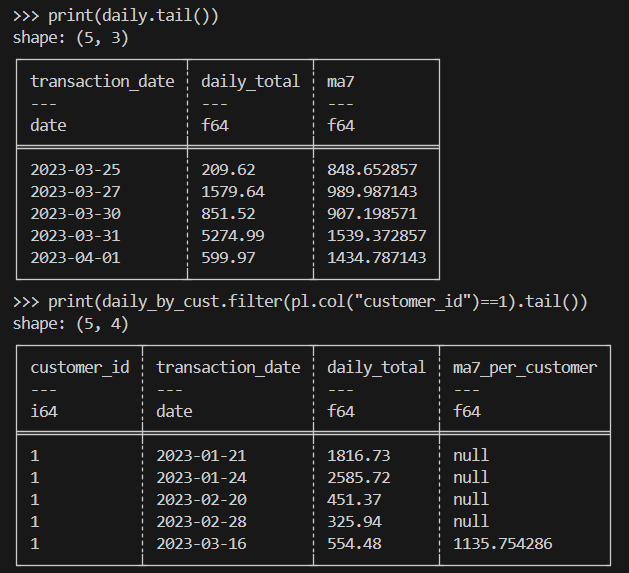
Beim wissenschaftlichen Rechnen musst du Millionen von Zeilen mit experimentellen oder simulierten transaktionsähnlichen Daten effizient verarbeiten.
Hier ist ein Beispiel für die Umsetzung:
import polars as pl
# Assume a very large Parquet file with columns: id, value, ts (UTC)
# Use lazy scan_* to avoid loading into memory up-front
lazy = (
pl.scan_parquet("experiments.parquet") # or: pl.scan_csv("experiments.csv")
.filter(pl.col("value") > 0) # predicate pushdown
.select(["id", "value", "ts"]) # projection pushdown
.with_columns(
# Example transformations: standardization & bucketize timestamps by hour
((pl.col("value") - pl.col("value").mean()) / pl.col("value").std())
.alias("z_value"),
pl.col("ts").dt.truncate("1h").alias("ts_hour")
)
.group_by(["id", "ts_hour"])
.agg([
pl.len().alias("n"),
pl.mean("z_value").alias("z_mean"),
pl.std("z_value").alias("z_std")
])
.sort(["id", "ts_hour"])
)
# Execute in streaming mode to keep memory usage low
result = lazy.collect(streaming=True)
# Optionally write out partitioned Parquet for downstream analysis
result.write_parquet("experiments_hourly_stats.parquet")
print(result.head())Python Polars hat eine moderne, leistungsstarke DataFrame-Bibliothek, die viele der Einschränkungen von pandas löst. Während Pandas für kleinere Ad-hoc-Analysen immer noch beliebt ist, wird Polars immer mehr zum Tool der Wahl für skalierbare, effiziente und zuverlässige Datenverarbeitung in Python.
Willst du mehr über Polars erfahren? Du wirst unseren Kurs „Einführung in Polarkoordinaten“ lieben Einführungskurs in Polarkoordinaten oder unseren Einführung in Polars. Unsere Polars Engine könnte dich auch interessieren.
Die besten DataCamp-Kurse
Lernpfad
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Mark Pedigo
Tutorial
DataCamp Team
Tutorial
Satyabrata Pal
Tutorial
Sejal Jaiswal