
Curso
Introducción a la ciencia de datos con Python
4 h
498.3K
Recientemente, tuve el privilegio de obtener acceso anticipado al motor de GPU Polars, impulsado por NVIDIA RAPIDS cuDF, antes de su lanzamiento de la beta abierta. Esta función de vanguardia tiene el potencial de transformar los flujos de trabajo de datos acelerando las operaciones Polars hasta 13 veces con las GPUs NVIDIA. Si trabajas con conjuntos de datos a gran escala en Python, éste es un cambio de juego que no querrás perderte.
En esta entrada del blog, te explicaré todo lo que necesitas saber sobre el nuevo motor GPU Polars y te proporcionaré una guía paso a paso para ayudarte a empezar.

En el núcleo de la mayoría de los flujos de trabajo de la ciencia de datos está el DataFrame, una estructura de datos tabular que es a la vez flexible e intuitiva para manejar datos estructurados. En pocas palabras, todo el mundo en la ciencia de datos ha trabajado con DataFrames.
Los DataFrames permiten manipular, explorar y analizar fácilmente los datos, proporcionando una interfaz familiar y coherente para limpiar, filtrar, agrupar y transformar los datos.
Sin embargo, en el contexto de los grandes datos, las bibliotecas tradicionales de DataFrame pueden carecer de rendimiento y escalabilidad, que es donde Polars entra en escena.
Polares es una biblioteca DataFrame rápida y eficaz que se ha convertido rápidamente en la mejor opción para el procesamiento de datos de alto rendimiento. Escrito desde cero en Rust, Polars está diseñado para funcionar cerca del hardware, optimizando la velocidad y el uso de recursos sin depender de dependencias externas.
El Introducción a Polars es un excelente recurso para empezar a utilizar la biblioteca en Python.
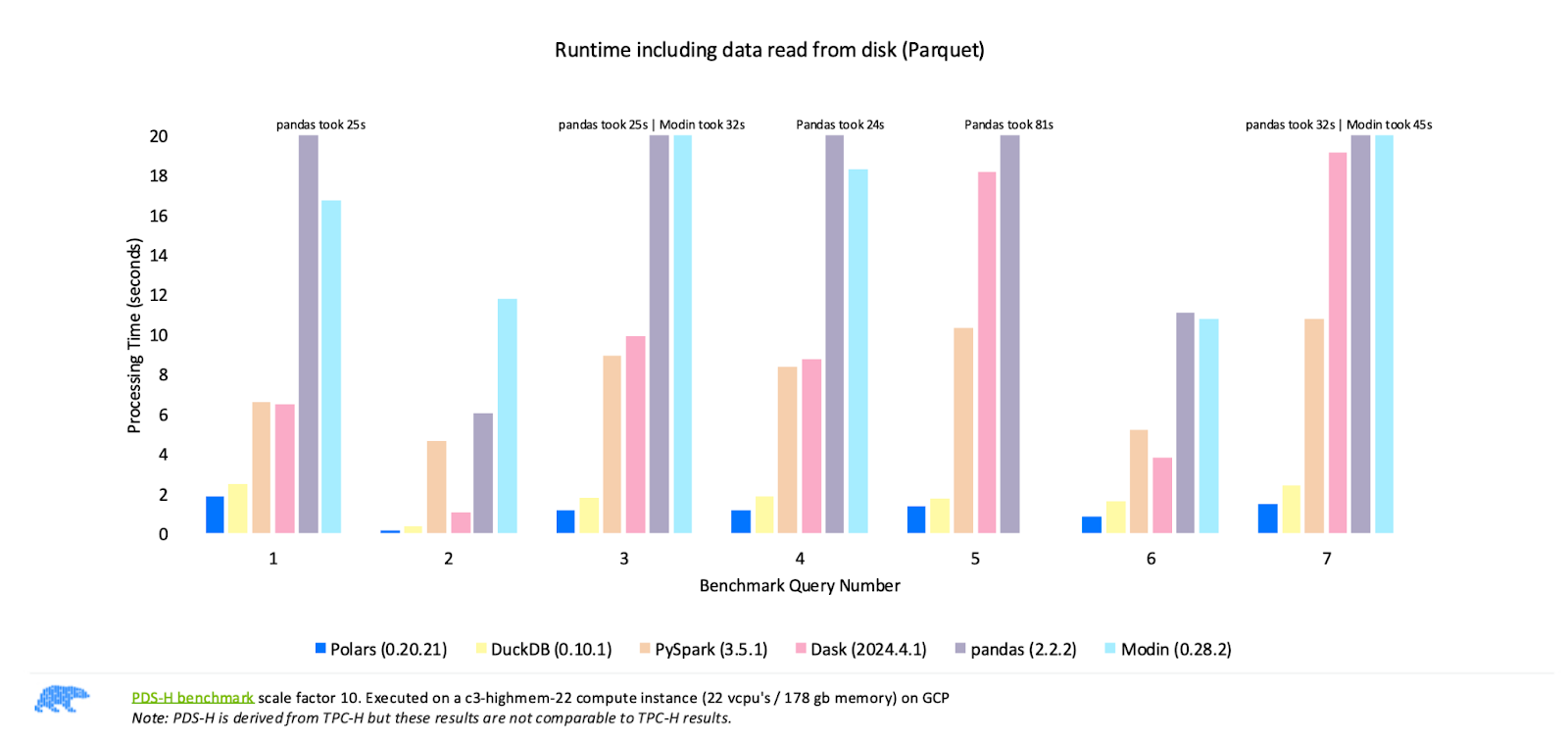
Comparar el rendimiento de las bibliotecas DataFrame más populares. Fuente de la imagen: Polares
Los resultados de las pruebas comparativas publicadas por Polars, que se muestran en la imagen de arriba, demuestran que Polars supera sistemáticamente a otras bibliotecas como Pandas, Modin, PySpark y Dask en diferentes consultas. Estos resultados ponen de relieve la fuerza de Polars como la opción más rápida para el procesamiento de datos de alto rendimiento.
Pero, ¿cómo es posible? Estas son algunas de las características que hacen que Polares sea rapidísimo:
Y con el reciente anuncio de la beta abierta del motor GPU Polars, ¡está a punto de ser aún más rápido!
La demanda de procesamiento y análisis de datos más rápidos ha crecido exponencialmente en los últimos años, a medida que los conjuntos de datos se han ampliado a cientos de millones o incluso miles de millones de filas. Para hacer frente a este reto, en el campo de la ciencia de datos se ha producido un cambio creciente del procesamiento tradicional basado en la CPU a la computación acelerada por GPU. Aquí es donde entra en juego NVIDIA RAPIDS cuDF.
NVIDIA RAPIDS es un conjunto de librerías de código abierto que permite el análisis y la ciencia de datos acelerados en la GPU. En esencia, RAPIDS está diseñado para agilizar los flujos de trabajo de datos utilizando el paralelismo masivo de las GPUs NVIDIA para acelerar tareas que normalmente se realizan en la CPU.
Dentro de RAPIDS, cuDF es la biblioteca responsable de las operaciones DataFrame. cuDF amplía la conocida abstracción DataFrame a la memoria GPU, permitiendo la integración en los flujos de trabajo de datos sin grandes cambios de código. La biblioteca admite todas las operaciones clave que los científicos de datos realizan en DataFrames: filtrado, agregación, fusión y ordenación, todas ellas potenciadas por la GPU para mayor velocidad.
NVIDIA y Polars acaban de anunciar la versión beta abierta del motor de GPU Python Polars, impulsado por RAPIDS cuDF. ¡Esta nueva función supone un importante salto adelante en el procesamiento de datos de alto rendimiento, ya que proporciona flujos de trabajo hasta 13 veces más rápidos para los usuarios de Polars con GPUs NVIDIA!
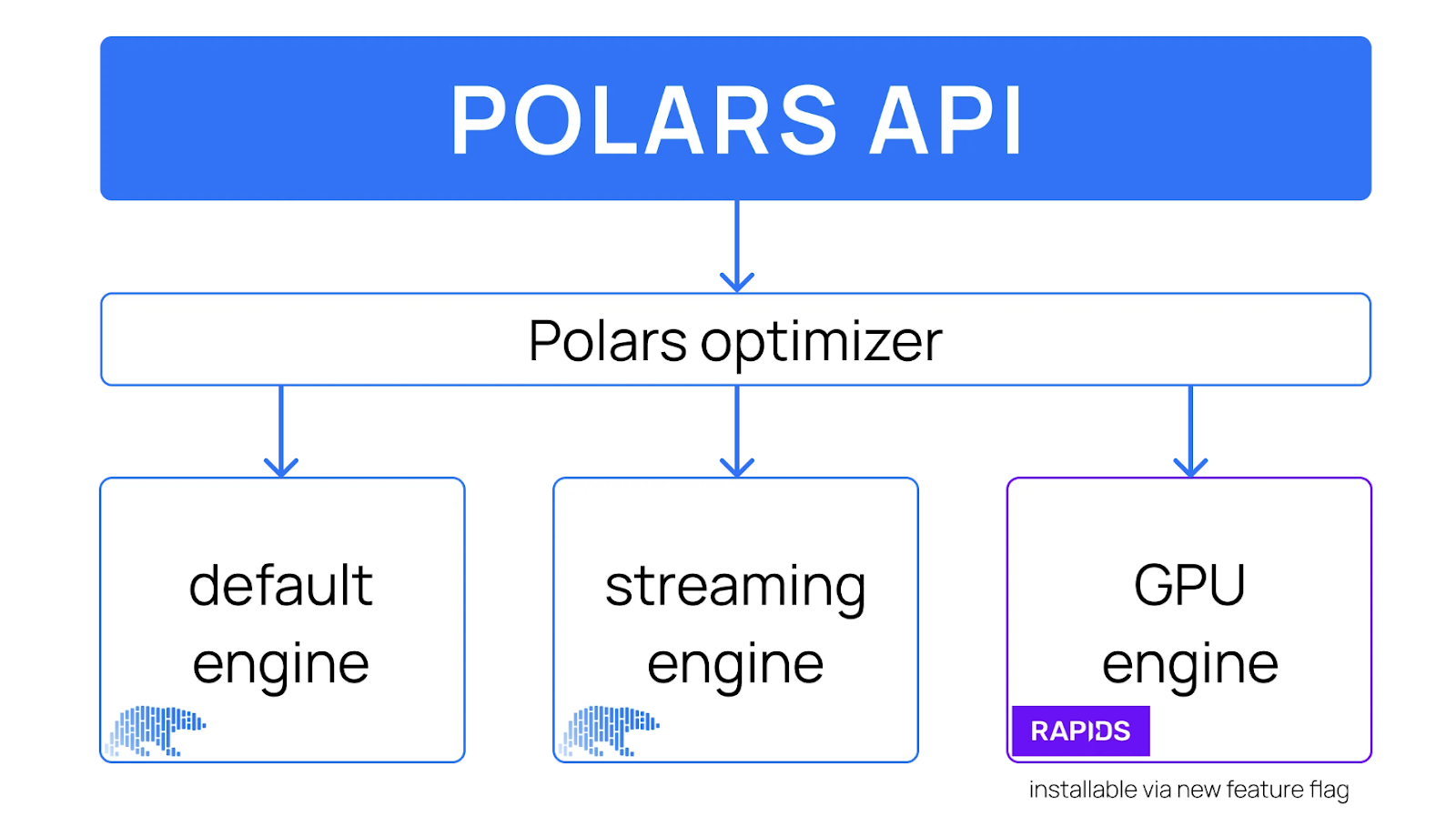
Diseño de alto nivel de la API Polars, incluido un motor GPU. Fuente de la imagen: Polares
Con la incorporación del motor GPU, los usuarios de Polars pueden decidir en qué motor ejecutar sus cargas de trabajo de datos. El optimizador Polars admite todos los motores, determinando dinámicamente qué consultas pueden ejecutarse en la GPU o en la CPU.
Así que ahora tienes algo de contexto sobre Polars y la biblioteca NVIDIA RAPIDS cuDF y cómo ambos se integran y están disponibles a través de la API Python Polars. Pero, ¿qué significa esto para los desarrolladores y los científicos de datos?
Aquí tienes un resumen de lo que permite el motor GPU Polars:
engine="gpu" a la operación collect() en la API Lazy de Polars, permitiendo el procesamiento en la GPU sin cambios significativos en el código.¿Cuáles son los resultados hasta ahora? Veamos.
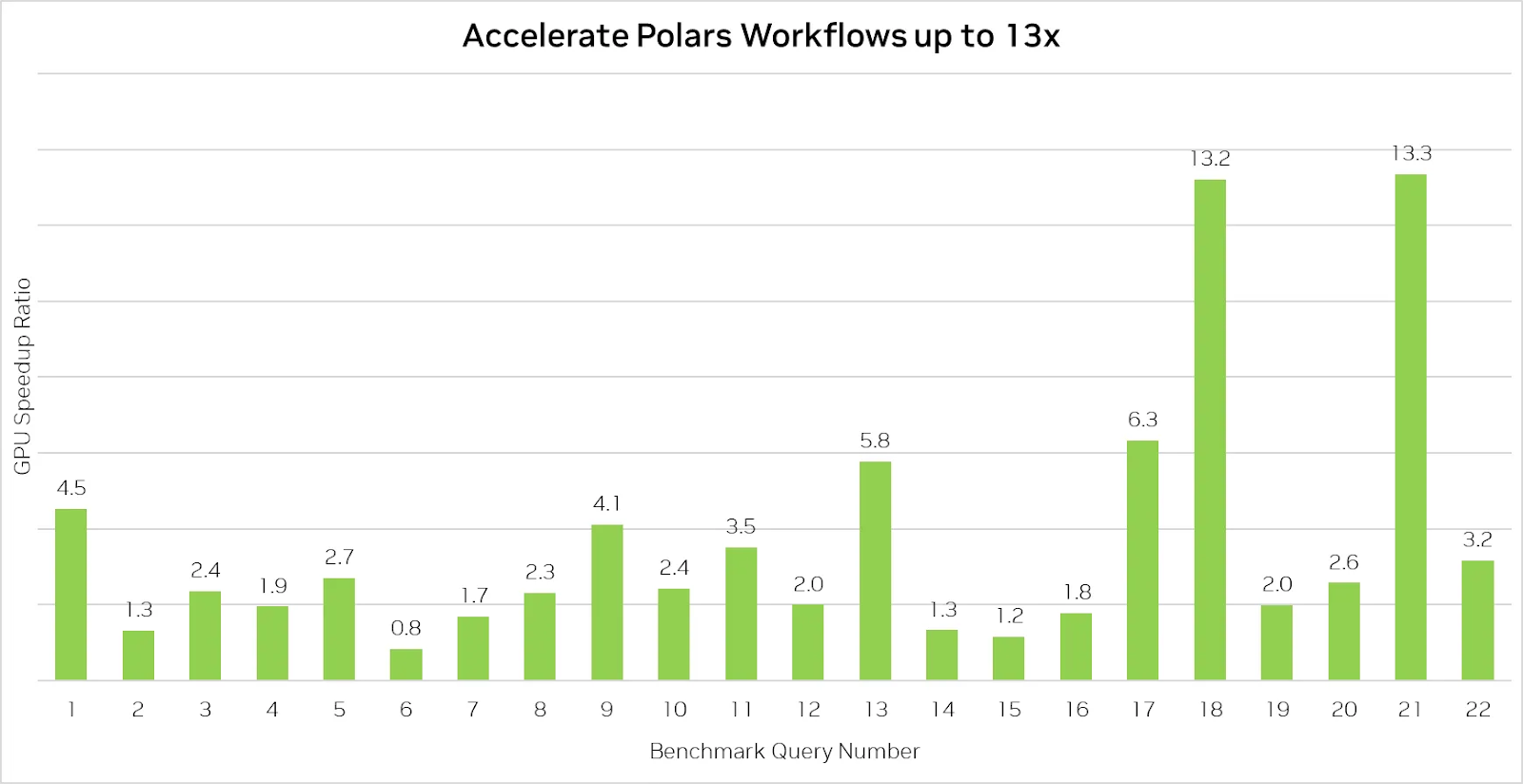
El motor GPU Polars acelera el procesamiento de datos hasta 13 veces. Fuente de la imagen: Polares
El benchmark anterior demuestra las impresionantes capacidades del motor GPU Polars al acelerar las consultas hasta 13 veces.
Sin embargo, es importante tener en cuenta que utilizar Polars en una GPU no siempre garantiza ser más rápido que en una CPU, sobre todo para consultas más sencillas que no sean intensivas desde el punto de vista computacional. En estos casos, el rendimiento suele estar limitado por la velocidad de lectura de los datos del disco, lo que significa que la aceleración de la GPU ofrece menos ventajas cuando las operaciones de entrada/salida (E/S) son la principal limitación.
Dicho esto, el motor de la GPU proporciona importantes aumentos de velocidad para operaciones de datos más complejas, lo que lo convierte en una valiosa herramienta para equipos que manejan grandes conjuntos de datos o consultas que implican uniones, agrupaciones y procesamiento de cadenas.
Una de las características más atractivas de esta nueva integración es su flexibilidad. Como ya hemos dicho, el optimizador puede alternar entre la ejecución en CPU y en GPU en función de la complejidad de tus consultas. Pero, ¿cómo funciona exactamente esta transición?
Cuando se ejecuta Polares en la CPU, el motor sigue un pipeline estructurado y altamente optimizado para ejecutar las operaciones de datos. Este proceso implica aproximadamente los siguientes pasos:
Cuando activas la aceleración de la GPU pasando engine="gpu" al método .collect(), el proceso sigue siendo esencialmente el mismo en apariencia, pero con comprobaciones y optimizaciones adicionales entre bastidores para determinar qué parte de la carga de trabajo puede descargarse en la GPU, a través de cuDF:
Este modelo de ejecución híbrido -en el que la GPU y la CPU se utilizan conjuntamente- hace que Polares sea muy flexible. Te beneficias de la aceleración de la GPU sin sacrificar la compatibilidad de las consultas no compatibles con la GPU. Los Polares publicación en el blog lo explica con más detalles técnicos.
Por último, ¡la parte más emocionante! En esta sección, recorreré los pasos necesarios para configurar tu entorno y empezar a aprovechar el procesamiento de datos acelerado por la GPU.
La forma más sencilla de ponerte en marcha es seguir este cuaderno Google Colab.
Colab ofrece un uso limitado gratuito de la GPU, especialmente útil si no tienes acceso inmediato a una GPU. Si utilizas el cuaderno proporcionado, empezaremos desde el paso 2, así que puedes saltarte los pasos anteriores.
Antes de instalar el motor GPU Polars, asegúrate de que tu sistema cumple los requisitos para NVIDIA RAPIDS cuDF. Puedes revisar las especificaciones necesarias del sistema, incluida la compatibilidad con la GPU y los requisitos de los controladores, en la página de documentación de página de documentación de RAPIDS.
Para empezar con el motor GPU Polars, la mejor práctica es crear un entorno virtual para aislar las dependencias de tu proyecto.
Yo utilizo conda para este ejemplo, pero puedes utilizar el gestor de paquetes que prefieras.
Además de Python, puedes incluir JupyterLab en el entorno para la exploración y el desarrollo interactivos de datos, lo que resulta especialmente útil para ejecutar pequeños fragmentos de código y analizar conjuntos de datos sobre la marcha.
conda create -n polars-gpu -c conda-forge python=3.11 jupyterlabDespués de crear el entorno virtual, actívalo utilizando:
conda activate polars-gpuAhora, vamos a activar la aceleración GPU instalando Polars y el motor GPU. Esto también configurará cuDF y otras dependencias necesarias para utilizar las GPUs NVIDIA:
pip install -U polars[gpu] --extra-index-url=https://pypi.nvidia.comUna vez instalado el motor Polars GPU, utilizar Polars en una GPU será similar a trabajar con la CPU, pero con resultados mucho más rápidos para flujos de trabajo complejos o con muchos datos.
Como ya hemos explicado, el motor Polars optimiza automáticamente el plan de ejecución, utilizando plenamente la GPU NVIDIA para acelerar las operaciones y minimizar el uso de memoria. Para las consultas que no admiten aceleración de GPU, el motor de GPU de Polars dispone de un sistema de recuperación de CPU, que garantiza que el flujo de trabajo continúe sin interrupciones.
¡Pongamos el motor en acción con algunos ejemplos sencillos!
Para esta demostración, utilizaremos un conjunto de datos de 22 GB de transacciones financieras simuladas de Kaggle. NVIDIA aloja el conjunto de datos en un bucket de Google Cloud Storage (GCS), lo que garantiza velocidades de descarga rápidas.
Para empezar, descarga el conjunto de datos:
!wget https://storage.googleapis.com/rapidsai/polars-demo/transactions.parquet -O transactions.parquetDado que este conjunto de datos procede de Kaggle, se rige por una licencia específica de este conjunto de datos y condiciones de uso.
Carguemos el conjunto de datos utilizando Polars e inspeccionemos el esquema:
import polars as pl
from polars.testing import assert_frame_equal
transactions = pl.scan_parquet("transactions.parquet")
transactions.collect_schema()Este es el resultado:
Schema([('CUST_ID', String),
('START_DATE', Date),
('END_DATE', Date),
('TRANS_ID', String),
('DATE', Date),
('YEAR', Int64),
('MONTH', Int64),
('DAY', Int64),
('EXP_TYPE', String),
('AMOUNT', Float64)])Ahora, calculemos el volumen total de transacciones sumando la columna AMOUNT. Primero, vamos a probarlo sin aceleración de GPU:
transactions.select(pl.col("AMOUNT").sum()).collect()Salida:
AMOUNT
f64
3.6183e9¡Eso es un alto volumen total de transacciones! Ejecutemos la misma consulta en la GPU:
transactions.select(pl.col("AMOUNT").sum()).collect(engine="gpu")Salida:
AMOUNT
f64
3.6183e9Para operaciones sencillas como ésta, la CPU y la GPU producen el mismo resultado con una velocidad similar, ya que la consulta no es lo suficientemente intensiva desde el punto de vista computacional como para beneficiarse mucho de la aceleración de la GPU. Sin embargo, la GPU brillará cuando maneje consultas más complejas.
Ahora, pasemos a una consulta más compleja. En esta consulta, agrupamos las transacciones por ID de cliente (CUST_ID), sumamos los importes totales de las transacciones y, a continuación, ordenamos los resultados por los que más han gastado.
Primero, lo ejecutaremos en la CPU:
%%time
res_cpu = (
transactions
.group_by("CUST_ID")
.agg(pl.col("AMOUNT").sum())
.sort(by="AMOUNT", descending=True)
.head()
.collect()
)
res_cpuEste es el resultado:
CPU times: user 4.63 s, sys: 3.75 s, total: 8.38 s
Wall time: 6.04 s
CUST_ID
AMOUNT
str
f64
"CA9UYOQ5DA"
2.0290e6
"CJUK2MTM5Q"
1.8115e6
"CYXX1NBIKL"
1.8082e6
"C6ILEYAYQ9"
1.7961e6
"CCNBC305GI"
1.7274e6Ahora, ejecutemos la misma consulta en la GPU:
%%time
res_gpu = (
transactions
.group_by("CUST_ID")
.agg(pl.col("AMOUNT").sum())
.sort(by="AMOUNT", descending=True)
.head()
.collect(engine=”gpu”)
)
res_gpuSalida:
CPU times: user 347 ms, sys: 0 ns, total: 347 ms
Wall time: 353 ms
shape: (5, 2)
CUST_ID
AMOUNT
str
f64
"CA9UYOQ5DA"
2.0290e6
"CJUK2MTM5Q"
1.8115e6
"CYXX1NBIKL"
1.8082e6
"C6ILEYAYQ9"
1.7961e6
"CCNBC305GI"
1.7274e6Como podemos ver, el uso de la GPU para consultas más complejas ofrece importantes mejoras de rendimiento, reduciendo el tiempo de ejecución de 6,04 segundos en la CPU a sólo 353 milisegundos ¡en la GPU!
Este ejemplo demuestra el potente aumento de rendimiento que proporciona el motor de la GPU Polars para las operaciones de datos a gran escala.
Puedes encontrar ejemplos más avanzados en el cuaderno Colab.
El motor de GPU Polars, impulsado por NVIDIA RAPIDS cuDF, aporta impresionantes mejoras de velocidad, con un procesamiento de datos hasta 13 veces más rápido para operaciones complejas. Para conjuntos de datos a gran escala, Polars ofrece una clara ventaja sobre las bibliotecas DataFrame tradicionales.
Aunque no todas las consultas se beneficiarán por igual de la aceleración en la GPU, Polars sigue siendo una potente herramienta para cualquiera que trabaje con grandes conjuntos de datos. La facilidad de integración, combinada con su modelo de ejecución híbrido CPU-GPU, hace de Polars un fuerte competidor para los flujos de trabajo de datos modernos.
Si estás interesado en desarrollar tus habilidades de manipulación de datos, especialmente con Pandas, te recomiendo encarecidamente que eches un vistazo a estos cursos:
¡Estos recursos te darán una base sólida que complementa las potentes capacidades de herramientas como Polars!
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¡Aprende más sobre ciencia de datos y Python con estos cursos!
Curso
Curso
Curso
Tutorial
Natassha Selvaraj
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Satyam Tripathi
