Programa
Fundamentos de dados Python
28 h
No mundo da análise de dados, pandas tem sido a escolha padrão para lidar com dados tabulares em Python por profissionais de dados.
Mas, conforme os conjuntos de dados ficam maiores e mais complexos, o pandas pode ter problemas de desempenho, uso limitado de múltiplos núcleos e limitações de memória.
É aí que o Polars aparece como uma alternativa moderna. Polars é uma biblioteca DataFrame escrita em Rust que oferece um desempenho super rápido, gerenciamento de memória eficiente e uma filosofia de design focada em escalabilidade.
Neste tutorial, vamos compartilhar o que é Polars e como fazer algumas operações básicas do Polars em Python. Se você está procurando alguma experiência prática, recomendo conferir o curso Introdução aos Polares.
O Polars tem um conjunto único de recursos que o diferenciam do pandas:
O Polars dá suporte a uma ampla variedade de tipos de dados além dos básicos:
Int32, Int64, Float32, Float64.true/false.Date, Datetime, Duration, Time.List e Struct, úteis para dados do tipo JSON.Sendo a alternativa mais nova e moderna ao pandas, o Polars oferece várias vantagens:
Agora, vamos dar uma olhada em como podemos começar a usar Polars para nós mesmos em Python.
Antes de usar o Polars, você precisa configurar o ambiente corretamente.
O Polars funciona no Windows, macOS e Linux. Pode ser instalado em ambientes virtuais, no sistema Python ou por meio de fluxos de trabalho em contêineres (Docker).
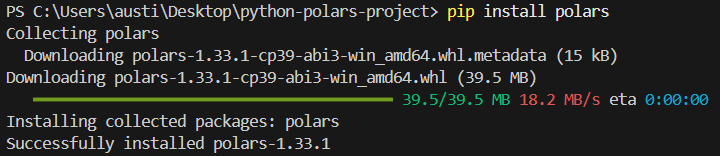
Para instalar a biblioteca polars no Python, execute o seguinte comando no terminal.
pip install polarsVocê deve ver a seguinte mensagem de instalação:
Se preferir, você pode instalar a biblioteca no ambiente conda, se for isso que você está usando.
conda install -c conda-forge polarsPara ver se a instalação deu certo, escreva este script simples:
import polars as pl
print(pl.__version__)O Polars permite que você ajuste como ele funciona e como suas saídas são mostradas, definindo variáveis de ambiente antes de começar sua sessão Python. Por exemplo:
POLARS_MAX_THREADS: Limite o número de threads.POLARS_FMT_MAX_COLS: Controle o número de colunas impressas.POLARS_FMT_TABLE_WIDTH: Ajustar a largura de exibição do DataFrame.Aqui vai um exemplo de como você definiria essas variáveis em um shell antes de rodar o Python:
export POLARS_MAX_THREADS=8
export POLARS_FMT_MAX_COLS=20Antes de mergulhar nas funcionalidades do Polars, é útil ter um conjunto de dados que possamos usar de forma consistente ao longo deste tutorial. A gente pode criar um arquivo CSV simples usando o módulo csv integrado do Python ou o pandas.
Aqui tá um exemplo que cria um arquivo transactions.csv com dados sintéticos:
import csv
import random
from datetime import datetime, timedelta
# Define column names
columns = ["transaction_id", "customer_id", "amount", "transaction_date"]
# Generate synthetic rows
rows = []
start_date = datetime(2023, 1, 1)
for i in range(1, 101):
customer_id = random.randint(1, 10)
amount = round(random.uniform(10, 2000), 2)
date = start_date + timedelta(days=random.randint(0, 90))
rows.append([i, customer_id, amount, date.strftime("%Y-%m-%d")])
# Write to CSV
with open("transactions.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(columns)
writer.writerows(rows)Esse script cria um conjunto de dados com 100 transações com valores aleatórios, IDs de clientes e datas de transação. Você pode ajustar o alcance e o tamanho de acordo com suas necessidades.
Salve esse script, execute-o uma vez e você terá um arquivo CSV para usar nos exemplos ao longo deste artigo.
O Polars é construído com base em duas abstrações principais: a Série e o DataFrame.
Juntos, eles oferecem uma maneira estruturada e eficiente de trabalhar com dados, parecida com o pandas, mas otimizada com o backend do Polars, que usa Rust. Vamos analisar os principais conceitos.
Uma série em polares é uma matriz unidimensional, parecida com uma coluna numa planilha ou tabela de banco de dados. Cada série tem:
Int64, Utf8, Float64, Boolean, etc.).Como o tipo de dados é rigorosamente aplicado, as séries no Polars tendem a ser mais rápidas e previsíveis do que as listas do Python.
Exemplo:
import polars as pl
# Create a Series of integers
s = pl.Series("numbers", [1, 2, 3, 4, 5])
print(s)Resultado:
shape: (5,)
Series: 'numbers' [i64]
[
1
2
3
4
5
]
Um DataFrame é uma estrutura bidimensional que organiza várias séries juntas em um esquema. É tipo uma tabela no SQL ou no Excel. As linhas são registros e as colunas são campos.
Exemplo:
df = pl.DataFrame({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35]
})
print(df)Resultado:
shape: (3, 3)
┌─────┬─────────┬─────┐
│ id │ name │ age │
│ --- │ --- │ --- │
│ i64 │ str │ i64 │
├─────┼─────────┼─────┤
│ 1 │ Alice │ 25 │
│ 2 │ Bob │ 30 │
│ 3 │ Charlie │ 35 │
└─────┴─────────┴─────┘Cada coluna é uma série, e o DataFrame faz valer o seu esquema.
Um dos pontos fortes do Polars é a aplicação rigorosa do esquema. Cada coluna tem um tipo de dados fixo, e o Polars garante que todas as operações respeitem isso. Isso evita bugs sutis que surgem em operações tipadas dinamicamente.
Por exemplo, você não pode adicionar sem querer uma coluna de string a uma coluna inteira sem fazer uma conversão explícita.
Exemplo:
df = df.with_columns(
(pl.col("age") + 5).alias("age_plus_5")
)
print(df)Aqui, age é i64, e o resultado continua sendo um número inteiro. Se você tentasse adicionar uma coluna de string, o Polars apresentaria um erro em vez de falhar silenciosamente.
Os dados do mundo real muitas vezes têm valores ausentes, e o Polars oferece ferramentas claras para lidar com eles:
fill_null(): Substitua os valores nulos por um valor específico.drop_nulls(): Tira as linhas que têm valores nulos.is_null() / is_not_null(): Verificações booleanas.O Polars promove um sistema de expressão, onde as operações são definidas como transformações em colunas, em vez de loops Python linha por linha.
Essas expressões são vetorizadas, ou seja, elas funcionam em colunas inteiras de uma vez, o que é bem mais rápido.
Em vez de fazer loops manualmente, o Polars cria um cálculo vetorizado rápido.
O Polars tem dois modos de execução:
Aqui vai um exemplo de execução ansiosa:
df = pl.DataFrame({"x": [1, 2, 3]})
print(df.select(pl.col("x") * 2)) # eager: runs instantlyAqui vai um exemplo de execução preguiçosa:
lazy_df = pl.DataFrame({"x": [1, 2, 3]}).lazy()
result = lazy_df.select(pl.col("x") * 2).collect() # execute on collect()
print(result)Aqui, nada é calculado até que se chame .collect(). Em fluxos de trabalho grandes, isso pode trazer melhorias incríveis no desempenho.
A seguir, vamos ver como fazer algumas operações básicas usadas no Polars no conjunto de dados que criamos.
Os Polars podem pegar dados de vários formatos de arquivo e objetos de memória. Isso torna-o flexível para integração em pipelines de dados modernos.
Veja como você pode fazer isso para diferentes fontes:
A partir do conjunto de dados CSV que criamos antes:
import polars as pl
df = pl.read_csv("transactions.csv")
print(df.head())Também podemos ler o conjunto de dados do Parquet, se for preciso.
df_parquet = pl.read_parquet("transactions.parquet")Se você tiver um arquivo JSON, pode lê-lo usando este código:
df_json = pl.read_json("transactions.json")
#For JSON Lines (NDJSON), use the following instead:
df_json = pl.read_ndjson("transactions.json")Veja como você pode ler conjuntos de dados de uma tabela Arrow:
import pyarrow as pa
arrow_table = pa.table({
"transaction_id": [1, 2],
"customer_id": [5, 7],
"amount": [150.25, 300.75],
"transaction_date": ["2023-01-02", "2023-01-03"]
})
df_arrow = pl.from_arrow(arrow_table)Agora vamos escolher colunas ou linhas específicas do nosso conjunto de dados.
Quando você usa o Polars, uma coisa comum é escolher as colunas que você quer usar e manter.
Veja como você pode fazer isso:
# Select only transaction_id and amount
df.select(["transaction_id", "amount"])Você também pode filtrar linhas com base nas condições que definir, parecido com o pandas.
# Get only high-value transactions above $1,000
high_value = df.filter(pl.col("amount") > 1000)
print(high_value)Aplicar expressões no Polars envolve usar o objeto polars.Expr em vários contextos para fazer transformações de dados.
Você pode criá-los usando pl.col() ou pl.lit().
# Add a 10% discount column to simulate promotional pricing
df.select([
pl.col("transaction_id"),
pl.col("amount"),
(pl.col("amount") * 0.9).alias("discounted_amount")
])A gente pode ver como os clientes gastam usando o group_by.
# Total and average spend per customer
agg_df = df.group_by("customer_id").agg([
pl.sum("amount").alias("total_spent"),
pl.mean("amount").alias("avg_transaction")
])
print(agg_df)Exemplo de saída:
shape: (10, 3)
┌─────────────┬────────────┬───────────────┐
│ customer_id │ total_spent│ avg_transaction│
│ --- │ --- │ --- │
│ i64 │ f64 │ f64 │
├─────────────┼────────────┼───────────────┤
│ 1 │ 5230.12 │ 523.01 │
│ 2 │ 6120.45 │ 680.05 │
│ ... │ ... │ ... │
└─────────────┴────────────┴───────────────┘Nosso conjunto de dados gerado não tem nulos por padrão, mas vamos simular como lidaríamos com eles.
Valores ausentes podem causar problemas na análise posterior e na visualização dos dados. Você vai precisar preencher os valores que faltam pra garantir que tudo corra bem.
Veja como você pode preencher os valores que estão faltando:
# Imagine 'amount' has missing values, then replace with 0
df_filled = df.with_columns(
pl.col("amount").fill_null(0)
)Os nulos podem causar erros se não forem tratados. Veja como eliminá-los:
df_no_nulls = df.drop_nulls()Os tipos de dados podem estar formatados incorretamente em um conjunto de dados. Veja como você pode convertê-los usando o método ` .cast `:
# Ensure customer_id is treated as string instead of int
df_casted = df.with_columns(
pl.col("customer_id").cast(pl.Utf8)
)O Polars permite encadear métodos para fluxos de trabalho mais organizados. Esse método de encadeamento é bem comum em SQL ou programação R usando o pacote tidyverse.
Exemplo: Descubra os principais clientes em março por gasto total
pipeline = (
df
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d"))
#.col("date_str").str.to_date(format="%Y-%m-%d")
.filter(pl.col("transaction_date").dt.month() == 3) # transactions in March
.group_by("customer_id")
.agg(pl.sum("amount").alias("march_spent"))
.sort("march_spent", descending=True)
)
print(pipeline)Este pipeline:
Esse método de encadeamento permite que uma análise de pipeline seja feita sem usar DataFrame intermediários.
Além do básico, o Polars se destaca ao trabalhar com grandes conjuntos de dados graças ao seu mecanismo de avaliação preguiçosa. Esse modelo permite que o Polars crie primeiro um plano de consulta, otimize-o internamente e só depois execute o pipeline. O resultado é um grande aumento no desempenho e na eficiência, principalmente com milhões de linhas ou transformações complexas.
Por padrão, o Polars funciona no modo eager. Isso quer dizer que os cálculos rolam na hora, tipo no pandas. O modo preguiçoso, no entanto, funciona de forma diferente:
.collect().Aqui vai um exemplo do modo preguiçoso:
import polars as pl
# Load dataset in lazy mode
lazy_df = pl.scan_csv("transactions.csv")
# Build a transformation pipeline
pipeline = (
lazy_df
.filter(pl.col("amount") > 1000) # step 1: filter expensive transactions
.group_by("customer_id") # step 2: group by customer
.agg(pl.sum("amount").alias("total_spent")) # step 3: aggregate
)
# Nothing has run yet, computation happens only on collect()
result = pipeline.collect()
print(result)O Polars otimiza as consultas usando técnicas de pushdown:
amount > 1000, o Polars aplica esse filtro enquanto lê o CSV, em vez de depois de carregar todas as linhas.customer_id e amount, o Polars vai ignorar completamente a leitura de transaction_date.Quando os dados são grandes demais para caber na memória, o Polars oferece execução em streaming. Em vez de carregar tudo de uma vez, o Polars processa os dados em lotes, mantendo o uso da memória estável.
Isso é super útil pra arquivos CSV ou Parquet com vários GB.
Exemplo (modo streaming):
# Enable streaming execution for huge datasets
stream_result = (
lazy_df
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect(streaming=True) # execute in streaming mode
)Com o streaming=True, o Polars evita criar tabelas intermediárias enormes na memória, o que o torna mais escalável do que o pandas para grandes cargas de trabalho.
.collect() e Depuração de Consultas LazyO método ` .collect() ` é o gatilho para executar um pipeline preguiçoso. Antes disso, você pode dar uma olhada e corrigir o plano de consulta com:
.describe_plan(): Mostra o plano lógico..describe_optimized_plan(): Mostra o plano otimizado depois que o Polars aplica pushdowns e simplificações.Os polares podem ajudar a melhorar o desempenho na execução de seus pipelines de análise.
Aqui estão algumas dicas:
A análise do mundo real muitas vezes precisa juntar conjuntos de dados. O Polars oferece um conjunto completo de operações de junção com execução otimizada, facilitando a fusão até mesmo de tabelas grandes.
O Polars aceita todos os principais tipos de junção:
Exemplo: Juntando transações com metadados do cliente
# Create customer metadata DataFrame
customers = pl.DataFrame({
"customer_id": [1, 2, 3, 4, 5],
"customer_name": ["Alice", "Bob", "Charlie", "David", "Eva"]
})
# Inner join on customer_id
df_joined = df.join(customers, on="customer_id", how="inner")
print(df_joined.head())O Polars é melhor que o Pandas nas duas áreas:
As funções de janela permitem cálculos dentro de grupos ou em linhas ordenadas, sem colapsar os resultados, de forma semelhante às funções de janela SQL.
O Polars permite calcular estatísticas por cliente ou por período de tempo usando contextos de janela.
Aqui estão alguns exemplos de funções de janela que você pode usar no Polars:
Exemplo: Totais acumulados do cliente
df_window = df.with_columns( pl.col("amount") .sort_by("transaction_date") .cum_sum() .over("customer_id") .alias("running_total") )
print(df_window.head())As funções rolantes funcionam em uma janela deslizante de linhas ou tempo.
Exemplo: Soma acumulada das transações dos últimos 7 dias
df = df.with_columns(pl.col("transaction_date").str.strptime(pl.Date, format="%Y-%m-%d")
rolling = (
df.group_by_rolling("transaction_date", period="7d")
.agg(pl.sum("amount").alias("rolling_7d_sum"))
)
print(rolling.head())Janelas expansíveis (cumulativas) e janelas alinhadas ao centro também são suportadas através do ajuste de parâmetros.
Você pode usar funções de classificação e agregações personalizadas dentro das janelas.
Exemplo: Classifique as transações por cliente de acordo com o valor
ranked = df.with_columns(
pl.col("amount").rank("dense", descending=True).over("customer_id").alias("rank")
)
print(ranked.head())Isso gera classificações (1 = mais alto) para os gastos de cada cliente.
As funções de janela permitem cálculos contextuais:
print(
df.group_by("customer_id").agg(pl.col("amount").cum_sum().alias("cumulative_spent"))
)Para analistas acostumados com SQL, o Polars oferece um contexto SQL para que você possa consultar DataFrame diretamente com a sintaxe SQL, sem deixar de aproveitar a velocidade do Polars.
Pra começar, você precisa registrar um DataFrame antes de rodar o SQL.
from polars import SQLContext
ctx = SQLContext()
ctx.register("transactions", df)Vamos ver um exemplo de como executar uma consulta SQL no Python usando o Polars.
Exemplo: Consultar o gasto total por cliente em SQL
result = ctx.execute("""
SELECT customer_id, SUM(amount) AS total_spent
FROM transactions
GROUP BY customer_id
ORDER BY total_spent DESC
""").collect()
print(result)Você pode misturar SQL e expressões:
sql_result = ctx.execute("SELECT * FROM transactions WHERE amount > 1500")
df_sql = sql_result.collect()
# Continue with Polars expressions
df_sql = df_sql.with_columns((pl.col("amount") * 0.95).alias("discounted"))Isso é útil para equipes que estão mudando de ferramentas baseadas em SQL.
O Polars não foi feito pra ser uma ilha isolada, mas sim uma biblioteca DataFrame de alto desempenho que funciona bem com o ecossistema de dados Python mais amplo. Essa interoperabilidade garante que analistas e engenheiros possam adotar o Polars aos poucos, sem deixar de usar as ferramentas que já têm.
Aqui estão algumas áreas de integração:
Por fim, vamos dar uma olhada rápida em alguns exemplos de uso do Polars:
df = df.with_columns([
pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d").alias("txn_date"),
pl.col("amount").fill_null(strategy="mean")
])result = (
pl.read_csv("transactions.csv")
.lazy()
.filter(pl.col("amount") > 1000)
.group_by("customer_id")
.agg(pl.sum("amount").alias("total_spent"))
.collect()
)Aqui está um exemplo de médias móveis para valores de transações.
import polars as pl
# Load & parse dates
df = (
pl.read_csv("transactions.csv")
.with_columns(pl.col("transaction_date").str.strptime(pl.Date, "%Y-%m-%d"))
)
# (A) Overall: daily totals + 7-day rolling average
daily = (
df.sort("transaction_date")
.group_by_dynamic("transaction_date", every="1d")
.agg(pl.sum("amount").alias("daily_total"))
.sort("transaction_date")
.with_columns(
pl.col("daily_total").rolling_mean(window_size=7).alias("ma7")
)
)
# (B) Per-customer: daily totals + 7-day rolling average within each customer
daily_by_cust = (
df.sort("transaction_date")
.group_by_dynamic(index_column="transaction_date", every="1d", by="customer_id")
.agg(pl.sum("amount").alias("daily_total"))
.sort(["customer_id", "transaction_date"])
.with_columns(
pl.col("daily_total")
.rolling_mean(window_size=7)
.over("customer_id")
.alias("ma7_per_customer")
)
)
print(daily.tail())
print(daily_by_cust.filter(pl.col("customer_id")==1).tail())Aqui está o resultado esperado:
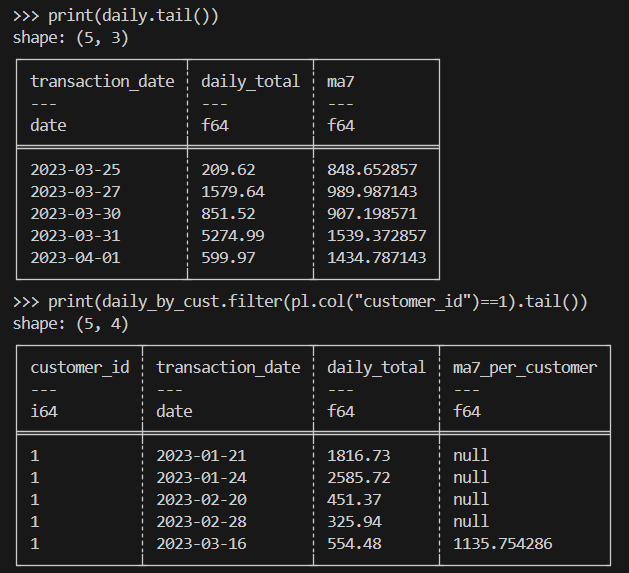
Ao fazer cálculos científicos, você vai precisar lidar com milhões de linhas de dados experimentais ou simulados, tipo transações, de forma eficiente.
Aqui está um exemplo de implementação:
import polars as pl
# Assume a very large Parquet file with columns: id, value, ts (UTC)
# Use lazy scan_* to avoid loading into memory up-front
lazy = (
pl.scan_parquet("experiments.parquet") # or: pl.scan_csv("experiments.csv")
.filter(pl.col("value") > 0) # predicate pushdown
.select(["id", "value", "ts"]) # projection pushdown
.with_columns(
# Example transformations: standardization & bucketize timestamps by hour
((pl.col("value") - pl.col("value").mean()) / pl.col("value").std())
.alias("z_value"),
pl.col("ts").dt.truncate("1h").alias("ts_hour")
)
.group_by(["id", "ts_hour"])
.agg([
pl.len().alias("n"),
pl.mean("z_value").alias("z_mean"),
pl.std("z_value").alias("z_std")
])
.sort(["id", "ts_hour"])
)
# Execute in streaming mode to keep memory usage low
result = lazy.collect(streaming=True)
# Optionally write out partitioned Parquet for downstream analysis
result.write_parquet("experiments_hourly_stats.parquet")
print(result.head())O Python Polars oferece uma biblioteca DataFrame moderna e de alto desempenho que resolve muitas das limitações do pandas. Embora o pandas continue sendo popular para análises menores e ad hoc, o Polars está cada vez mais se tornando a ferramenta preferida para o processamento de dados escalável, eficiente e confiável em Python.
Quer saber mais sobre os Polars? Você vai curtir nosso curso de curso Introdução às Polares ou nosso Introdução aos Polares. Nossos Polars Engine também pode te interessar.
Cursos mais populares do DataCamp
Programa
Curso
Curso
blog
Moez Ali
9 min
blog
Matt Crabtree
15 min
Tutorial
Vidhi Chugh
Tutorial
Oluseye Jeremiah
Tutorial
Natassha Selvaraj
Tutorial
Satyabrata Pal
