
Curso
Modelos multimodales con Hugging Face
4 h
1.8K
Qwen-Image-2512 es un potente modelo de código abierto de texto a imagen que destaca especialmente en la creación de imágenes realistas y composiciones con gran cantidad de texto. En este tutorial, lo utilizaremos para crear un Poster Studio, un aplicación de Gradio en la que introduces detalles del producto como el nombre, la oferta, el precio, la llamada a la acción y las ventajas, eliges la relación de aspecto de la plataforma y generas una imagen promocional con un solo clic.
Dado que Qwen-Image-2512 es un modelo grande, también nos centraremos en el aspecto práctico de su funcionamiento fluido. Aprenderás a cargarlo de forma estable en un A100 utilizando los ajustes de precisión adecuados, a evitar los modos de fallo más comunes y a adaptarte a cualquier flujo de trabajo mediante iteraciones a resoluciones más pequeñas, la reducción de pasos o la exploración de un modelo cuantificado para un hardware más ajustado.
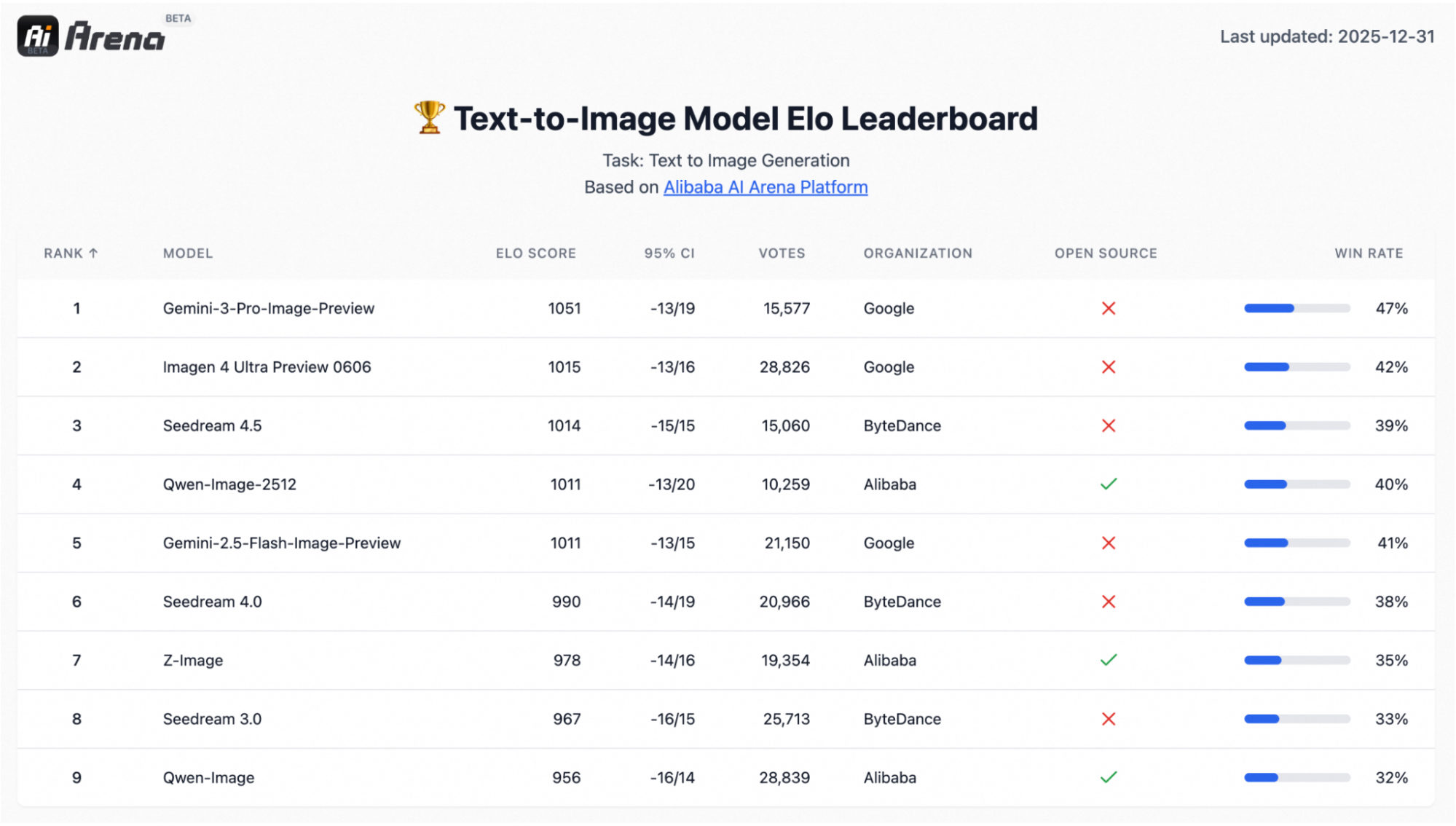
Qwen-Image-2512 es una actualización del modelo básico de conversión de texto a imagen Qwen, junto con una mejora cualitativa con respecto a la versión anterior de Qwen-Image. En realidad, Qwen-Image es un modelo de difusión MMDiT de 20B, diseñado para una fuerte adherencia a las indicaciones y la representación de texto en imágenes.
También está respaldado por una evaluación a gran escala basada en preferencias con más de 10 000 rondas a ciegas en AI Arena, donde el modelo destacó como el modelo de código abierto más potente, al tiempo que se mantuvo competitivo con los sistemas cerrados.
Las tres mejoras que suelen ser más importantes en los flujos de trabajo reales son:
En esta sección, crearemos una sencilla aplicación Gradio que:
steps, true_cfg_scale, seed y un opcional negative prompt.QwenImagePipeline.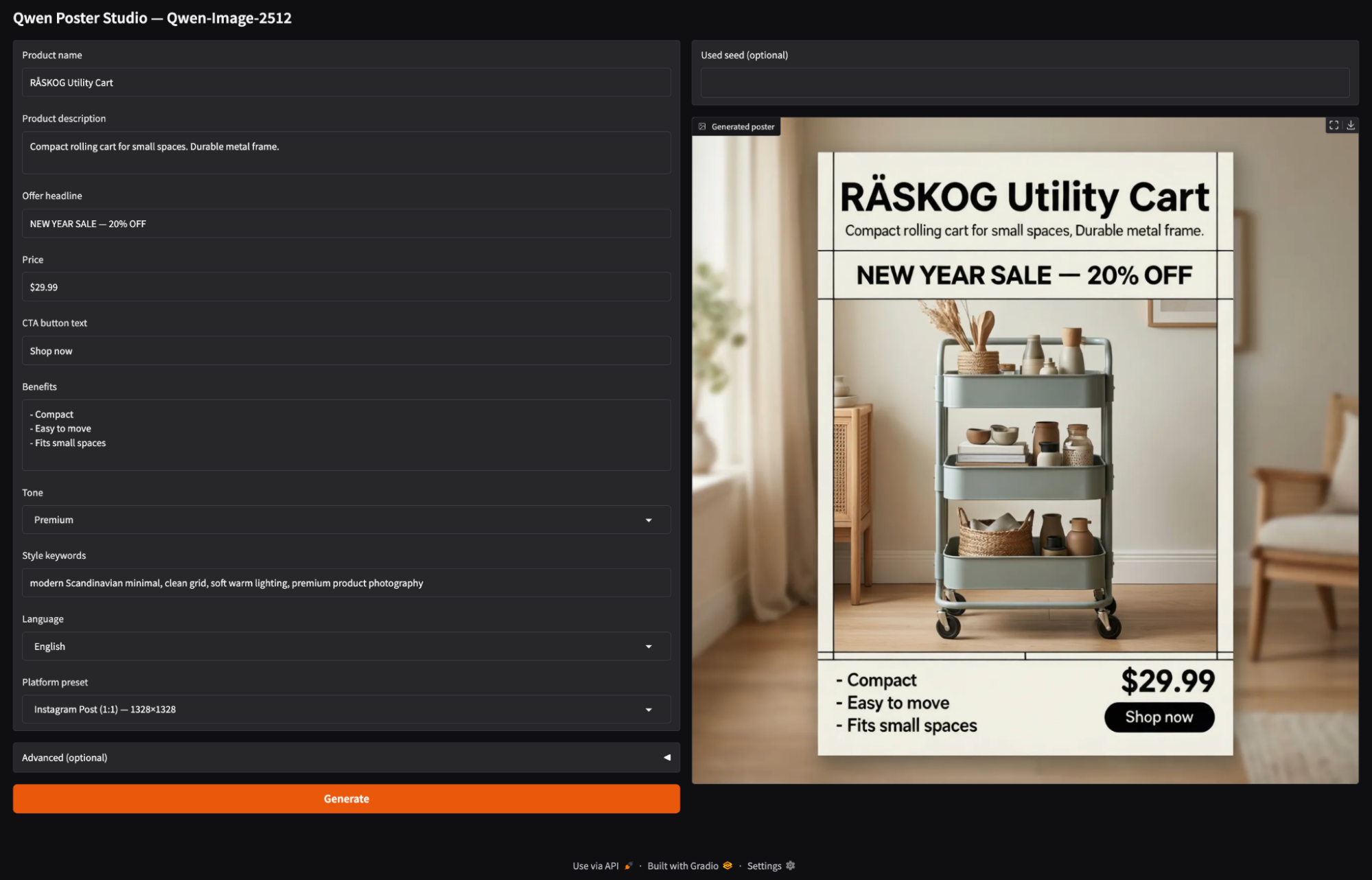
Construyámoslo paso a paso.
En primer lugar, instala la última versión de Difusores de GitHub (tarjeta de modelo de Qwen recomienda esto para la compatibilidad con el pipeline) junto con las dependencias principales: lo recomienda para la compatibilidad con el canal) junto con las dependencias principales:
!pip -q install --upgrade pip
!pip -q install git+https://github.com/huggingface/diffusers
!pip -q install transformers accelerate safetensors gradio pillow psutilA continuación, realiza una comprobación rápida para confirmar que CUDA está disponible e identificar la GPU:
import torch, diffusers
print("diffusers:", diffusers.__version__)
print("CUDA available:", torch.cuda.is_available())
!nvidia-smiSi CUDA available: True y ves tu GPU en nvidia-smi, ya estás listo para cargar el modelo.
Nota: « QwenImagePipeline » no es un bloque único al estilo UNet. En Diffusers, se trata de una pila completa que comprende un codificador de texto Qwen2.5-VL-7B-Instruct, el transformador de difusión MMDiT y un codificador automático variacional(VAE) para la decodificación. El codificador de texto 7B es una de las principales razones por las que la RAM/VRAM puede dispararse durante la carga y la generación de modelos, especialmente en GPU más pequeñas.
He ejecutado este tutorial en Google Colab con una A100, que maneja cómodamente una resolución de imagen de 1328×1328 en ~50 pasos. En las GPU de clase T4/16 GB, normalmente es necesario reducir la escala (a una resolución de imagen de aproximadamente 768 × 768 y menos pasos) o utilizar variantes cuantificadas a través de tiempos de ejecución alternativos (como GGUF/ComfyUI).
Antes de cargar el modelo, vale la pena configurar un pequeño arnés de tiempo de ejecución que mantenga Colab predecible. Qwen-Image-2512 es pesado, y las cargas de trabajo de generación de imágenes pueden consumir silenciosamente tanto la RAM del sistema como la memoria de la GPU.
import os, gc, random, psutil, torch
from diffusers import QwenImagePipeline
import gradio as gr
os.environ["HF_HOME"] = "/content/hf"
os.makedirs("/content/hf", exist_ok=True)
def mem(tag=""):
ram = psutil.virtual_memory().used / 1e9
v_alloc = torch.cuda.memory_allocated()/1e9 if torch.cuda.is_available() else 0
v_res = torch.cuda.memory_reserved()/1e9 if torch.cuda.is_available() else 0
print(f"[{tag}] RAM={ram:.1f}GB | VRAM alloc={v_alloc:.1f}GB reserved={v_res:.1f}GB")
def cleanup(tag="cleanup"):
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
mem(tag)
assert torch.cuda.is_available(), "GPU runtime required"
print("GPU:", torch.cuda.get_device_name(0))
torch.backends.cuda.matmul.allow_tf32 = True
torch.set_float32_matmul_precision("high")
cleanup("startup")Una vez instaladas las dependencias, configuramos las importaciones, el almacenamiento en caché, la supervisión de la memoria y un par de indicadores de rendimiento de la GPU. Así es como se ve en el código:
QwenImagePipeline: Esta es la clase principal del proceso que usaremos más adelante para cargar y ejecutar Qwen-Image-2512 para la generación de imágenes.gradio: Esta biblioteca impulsa la sencilla interfaz de usuario web para que podamos generar pósteres dentro de Colab.HF_HOME=/content/hf: Utilizamos esto para fijar la caché de Hugging Face en una carpeta conocida, de modo que las descargas y los pesos de los modelos se almacenen de forma coherente en todas las ejecuciones.mem() función: La función mem() realiza un seguimiento de la RAM del sistema y la VRAM de la GPU asignadas frente a las reservadas. cleanup() función: Es una pequeña utilidad de reinicio para borrar las referencias de Python y liberar la memoria caché de la GPU, lo que resulta muy útil cuando se iteran la resolución y los pasos.Esta configuración aún no genera imágenes, pero hace que los siguientes pasos (carga e inferencia) sean mucho más estables y fáciles de depurar.
Ahora que el tiempo de ejecución está configurado, es hora de cargar el modelo en un canal de Diffusers. En un A100, lo ideal es ejecutar la mayoría de los pesos en BF16 para obtener un mejor rendimiento, pero mantener la decodificación VAE en FP32 para evitar los NaN que pueden aparecer como imágenes completamente negras.
DTYPE = torch.bfloat16
pipe = QwenImagePipeline.from_pretrained(
"Qwen/Qwen-Image-2512",
torch_dtype=DTYPE,
low_cpu_mem_usage=True,
use_safetensors=True,
).to("cuda")
if hasattr(pipe, "vae") and pipe.vae is not None:
pipe.vae.to(dtype=torch.float32)
cleanup("after pipe load")Esto es lo que intentamos conseguir con el código anterior:
torch_dtype=DTYPE: Esto carga la mayoría de los pesos en BF16 para reducir la VRAM y acelerar la inferencia.low_cpu_mem_usage=True: Reduce la duplicación del lado de la CPU durante la carga (importante para puntos de control grandes).use_safetensors=True: Esto garantiza que el cargador utilice el formato safetensors, más seguro y rápido, cuando esté disponible.pipe.vae.to(torch.float32) ) convierte las salidas del espacio latente en píxeles. Si ese paso de decodificación encuentra valores NaN/Inf con menor precisión, la imagen final puede quedar completamente negra. Por lo tanto, obligamos al VAE a FP32 seguido de una llamada a « cleanup() » para confirmar la huella de RAM/VRAM tras la carga.A continuación, definiremos los ajustes preestablecidos de relación de aspecto de la plataforma y conectaremos el proceso a una interfaz de usuario Gradio mínima para la generación interactiva de pósteres.
Ahora construimos el motor de la demostración, es decir, una pequeña capa que convierte las entradas de la interfaz de usuario en una indicación bien estructurada, elige una resolución de salida basada en los ajustes preestablecidos de la plataforma y llama al canal de imágenes Qwen para generar una imagen.
ASPECT_PRESETS = {
"Instagram Post (1:1) — 1328×1328": (1328, 1328),
"Instagram Story (9:16) — 928×1664": (928, 1664),
"YouTube / Banner (16:9) — 1664×928": (1664, 928),
"Poster (3:4) — 1104×1472": (1104, 1472),
"Slides (4:3) — 1472×1104": (1472, 1104),
"Fast Draft (1:1) — 768×768": (768, 768),
}
DEFAULT_NEG = " "
def build_prompt(product_name, product_desc, offer, price, cta, benefits, tone, style_keywords, language):
return f"""
Create a high-converting e-commerce promotional poster in {language}. Clean grid layout, strong hierarchy.
- Product name: "{product_name}"
- Product description: "{product_desc}"
- Offer headline (exact): "{offer}"
- Price (exact): "{price}"
- CTA button text (exact): "{cta}"
- Benefits (use these exact phrases, no typos):
{benefits}
- Tone: {tone}
- Style keywords: {style_keywords}
- Text must be legible and correctly spelled.
- Do not add extra words, fake prices, or random letters.
- Align typography to a neat grid with consistent margins.
""".strip()
@torch.inference_mode()
def generate_image(product_name, product_desc, offer, price, cta, benefits, tone, style_keywords,
language, preset, negative_prompt, steps, true_cfg_scale, seed, show_seed):
w, h = ASPECT_PRESETS[preset]
prompt = build_prompt(product_name, product_desc, offer, price, cta, benefits, tone, style_keywords, language)
if seed is None or int(seed) < 0:
seed = random.randint(0, 2**31 - 1)
seed = int(seed)
gen = torch.Generator(device="cuda").manual_seed(seed)
img = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=int(w),
height=int(h),
num_inference_steps=int(steps),
true_cfg_scale=float(true_cfg_scale),
generator=gen,
).images[0].convert("RGB")
return (seed if show_seed else None), imgEl mapa preestablecido y las dos funciones anteriores constituyen el motor central de nuestro Poster Studio.
ASPECT_PRESETS define diferentes tamaños de lienzo para cada plataforma (por ejemplo, 1:1 para publicaciones de Instagram, 9:16 para Stories, 16:9 para banners). Los usuarios solo tienen que elegir un ajuste preestablecido y nosotros lo traducimos al lenguaje de programación correcto ( width × height ) para su generación.build_prompt() » convierte datos básicos sobre el producto, como el nombre, la oferta, el precio, la llamada a la acción y las ventajas, en un resumen visual. Tiene en cuenta las reglas de diseño y texto, por lo que el modelo obtiene restricciones coherentes en todo momento y no se desvía hacia copias aleatorias.generate_image() es la capa de ejecución. Lee el ajuste preestablecido elegido para obtener width/height y llama al canal Qwen-Image con los siguientes ajustes seleccionados: steps, true_cfg_scale y negative_prompt. Por último, devuelve el póster generado (y, opcionalmente, la semilla). steps a el tiempo que dura el proceso de difusión (cuantos más pasos, más lento pero normalmente más limpio es el resultado), mientras que true_cfg_scale a la intensidad con la que el modelo sigue la indicación (un valor más alto significa una mayor adherencia, pero si es demasiado alto puede introducir artefactos).A continuación, integraremos la función generate_image() en una interfaz Gradio para que los usuarios puedan generar pósteres sin tener que lidiar con la ingeniería de comandos sin procesar.
Por último, envolvemos el motor de generación de pósteres en una interfaz Gradio. La aplicación permite al usuario introducir los detalles del producto, seleccionar una relación de aspecto de la plataforma y pulsar Generar.
with gr.Blocks(title="Qwen Poster Studio (Simple)") as demo:
gr.Markdown("## Qwen Poster Studio — Qwen-Image-2512")
with gr.Row():
with gr.Column(scale=1):
product_name = gr.Textbox(value="RÅSKOG Utility Cart", label="Product name")
product_desc = gr.Textbox(value="Compact rolling cart for small spaces. Durable metal frame.", lines=2, label="Product description")
offer = gr.Textbox(value="NEW YEAR SALE — 20% OFF", label="Offer headline")
price = gr.Textbox(value="$29.99", label="Price")
cta = gr.Textbox(value="Shop now", label="CTA button text")
benefits = gr.Textbox(value="- Compact\n- Easy to move\n- Fits small spaces", lines=4, label="Benefits")
tone = gr.Dropdown(["Premium", "Minimal", "Bold", "Playful", "Tech"], value="Premium", label="Tone")
style_keywords = gr.Textbox(value="modern Scandinavian minimal, clean grid, soft warm lighting, premium product photography", label="Style keywords")
language = gr.Dropdown(["English", "中文"], value="English", label="Language")
preset = gr.Dropdown(list(ASPECT_PRESETS.keys()), value="Instagram Post (1:1) — 1328×1328", label="Platform preset")
with gr.Accordion("Advanced (optional)", open=False):
negative_prompt = gr.Textbox(value=DEFAULT_NEG, label="Negative prompt", lines=2)
steps = gr.Slider(10, 80, value=50, step=1, label="Steps")
true_cfg_scale = gr.Slider(1.0, 10.0, value=4.0, step=0.1, label="true_cfg_scale")
seed = gr.Number(value=-1, precision=0, label="Seed (-1 = random)")
show_seed = gr.Checkbox(value=False, label="Show seed in output")
btn = gr.Button("Generate", variant="primary")
with gr.Column(scale=1):
used_seed_out = gr.Number(label="Used seed (optional)", precision=0)
image_out = gr.Image(label="Generated poster")
btn.click(
fn=generate_image,
inputs=[product_name, product_desc, offer, price, cta, benefits, tone, style_keywords,
language, preset, negative_prompt, steps, true_cfg_scale, seed, show_seed],
outputs=[used_seed_out, image_out]
)
demo.launch(share=True, debug=True)Así es como creamos la aplicación Gradio:
width × height final utilizando ASPECT_PRESETS.steps » (Iteraciones de eliminación de ruido) y « true_cfg_scale » (Sensibilidad a la entrada), que controlan, respectivamente, el número de iteraciones de eliminación de ruido que ejecuta el modelo y la intensidad con la que el modelo sigue la indicación. La semilla controla la reproducibilidad, y show_seed muestra opcionalmente la semilla final.btn.click() conecta todo. Gradio toma todos los widgets de entrada en orden, los pasa a generate_image() y envía los valores devueltos a los widgets de salida. Por último, demo.launch(share=True, debug=True) inicia el servidor Gradio, nos proporciona un enlace público compartible para las demostraciones e imprime registros de depuración en el cuaderno para ayudar a diagnosticar problemas.Aquí tienes un vídeo que muestra nuestra aplicación Qwen Image 2512 final en acción:
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Ryan Ong
Tutorial
Kurtis Pykes
Tutorial
Josef Waples
Tutorial
DataCamp Team
Tutorial
Moez Ali


