
Curso
Modelos multimodais com Hugging Face
4 h
1.8K
Qwen-Image-2512 é um modelo poderoso de código aberto que transforma texto em imagem que é especialmente bom em visuais realistas e composições com muito texto. Neste tutorial, vamos usá-lo para criar um Poster Studio, um aplicativo Gradio onde você insere detalhes do produto, como nome, oferta, preço, CTA e benefícios, escolhe uma proporção de plataforma e gera uma imagem promocional com apenas um clique.
Como o Qwen-Image-2512 é um modelo grande, também vamos focar no lado prático de como rodá-lo sem problemas. Você vai aprender a carregá-lo de forma estável em um A100 usando as configurações de precisão certas, evitar modos de falha comuns e se adaptar a qualquer fluxo de trabalho, iterando em resoluções menores, reduzindo etapas ou explorando um modelo quantizado para hardware mais restrito.
O Qwen-Image-2512 é uma atualização do modelo básico de conversão de texto em imagem Qwen, além de ser um salto de qualidade em relação à versão anterior do Qwen-Image. Por trás dos panos, o Qwen-Image é um modelo de difusão MMDiT de 20B, que foi projetado para forte aderência imediata e renderização de texto em imagem.
Ele também é apoiado por uma avaliação em grande escala do tipo preferência, com mais de 10.000 rodadas cegas na AI Arena, onde o modelo se destacou como o modelo de código aberto mais forte, mantendo-se competitivo com sistemas fechados.
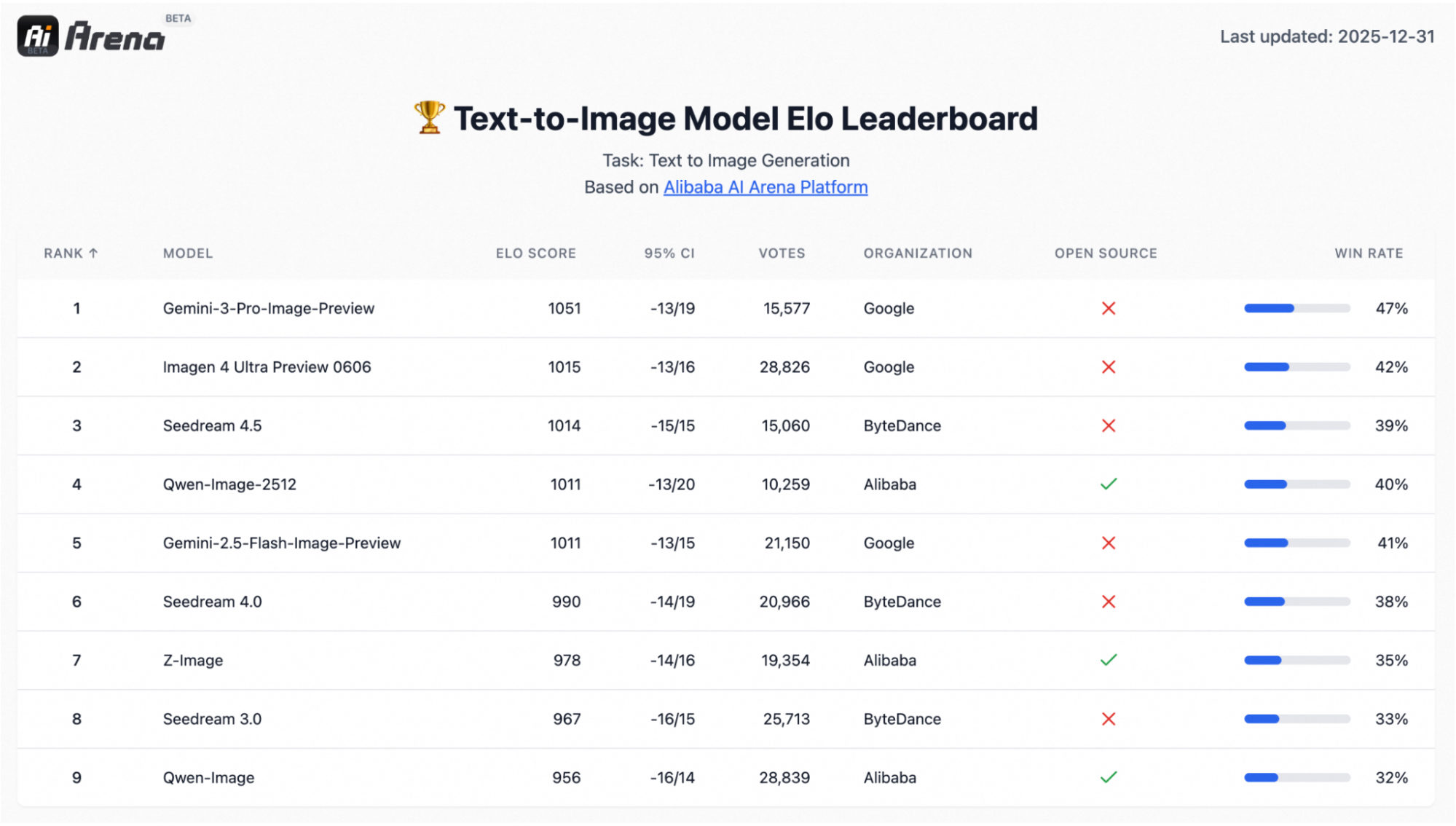
As três atualizações que costumam ser mais importantes nos fluxos de trabalho reais são:
Nesta seção, vamos criar um aplicativo Gradio simples que:
steps, true_cfg_scale, seed e um opcional negative prompt.QwenImagePipeline.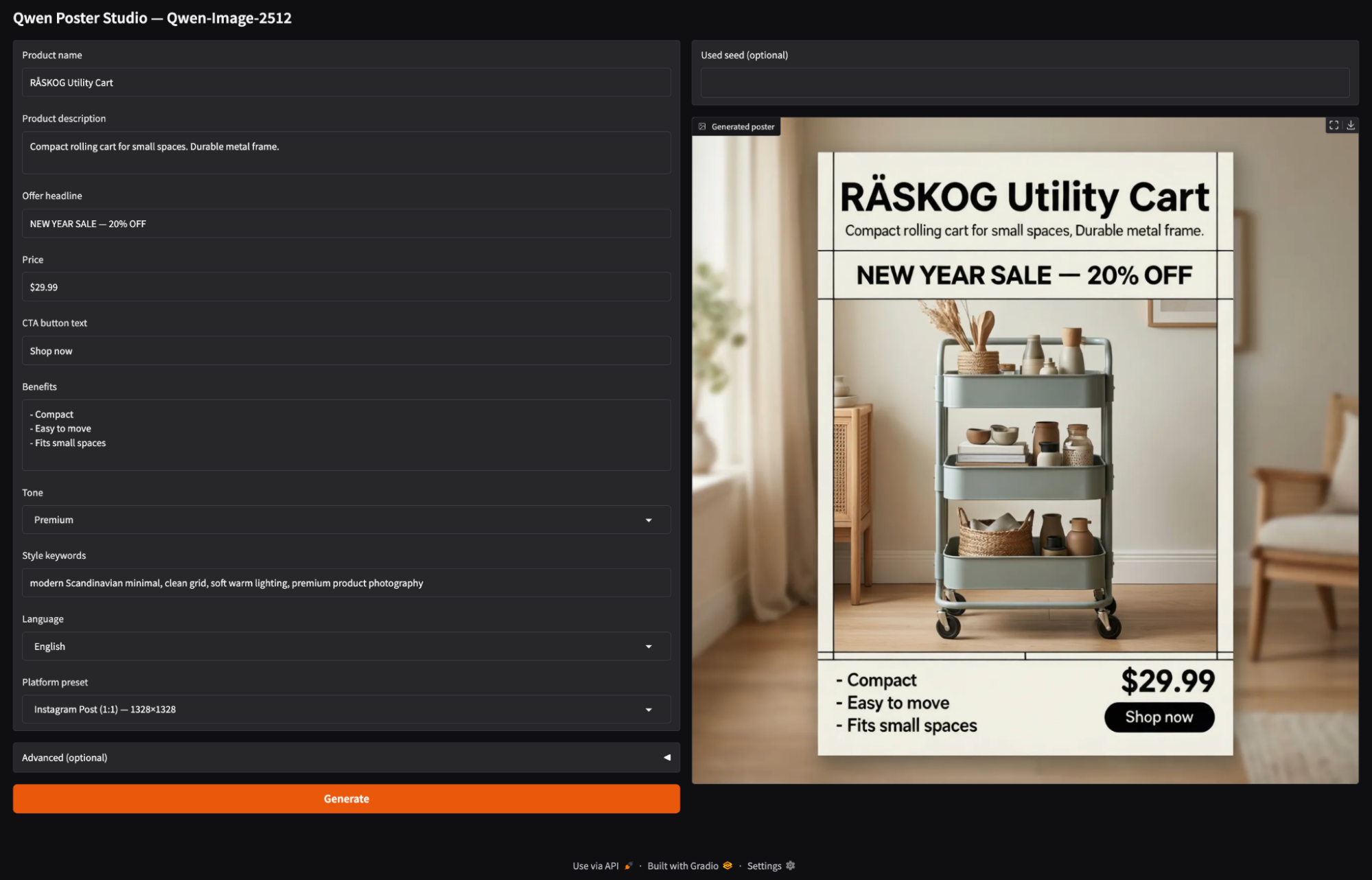
Vamos construir passo a passo.
Primeiro, instale o mais recente Diffusers do GitHub (modelo de cartão do Qwen cartão de modelo recomenda isso para suporte ao pipeline) junto com as dependências principais:
!pip -q install --upgrade pip
!pip -q install git+https://github.com/huggingface/diffusers
!pip -q install transformers accelerate safetensors gradio pillow psutilDepois, dá uma olhada rápida pra ver se o CUDA tá disponível e identifica a GPU:
import torch, diffusers
print("diffusers:", diffusers.__version__)
print("CUDA available:", torch.cuda.is_available())
!nvidia-smiSe você acessar CUDA available: True e ver sua GPU em nvidia-smi, tá tudo certo pra carregar o modelo.
Observação: QwenImagePipeline não é um único bloco no estilo UNet. No Diffusers, é uma pilha completa que inclui um codificador de texto Qwen2.5-VL-7B-Instruct, o transformador de difusão MMDiT e um Auto-Codificador Variacional(VAE) para decodificação. O codificador de texto 7B é um dos principais motivos pelos quais a RAM/VRAM pode disparar durante o carregamento e a geração do modelo, principalmente em GPUs menores.
Eu rodei esse tutorial no Google Colab com um A100, que dá conta de imagens com resolução de 1328×1328 em cerca de 50 etapas sem problemas. Em GPUs da classe T4/16 GB, você normalmente precisa reduzir a escala (para uma resolução de imagem de aproximadamente 768×768 e menos etapas) ou usar variantes quantizadas por meio de tempos de execução alternativos (como GGUF/ComfyUI).
Antes de carregarmos o modelo, vale a pena configurar um pequeno harness de tempo de execução que mantenha o Colab previsível. O Qwen-Image-2512 é pesado, e as tarefas de geração de imagens podem consumir silenciosamente tanto a memória RAM do sistema quanto a memória da GPU.
import os, gc, random, psutil, torch
from diffusers import QwenImagePipeline
import gradio as gr
os.environ["HF_HOME"] = "/content/hf"
os.makedirs("/content/hf", exist_ok=True)
def mem(tag=""):
ram = psutil.virtual_memory().used / 1e9
v_alloc = torch.cuda.memory_allocated()/1e9 if torch.cuda.is_available() else 0
v_res = torch.cuda.memory_reserved()/1e9 if torch.cuda.is_available() else 0
print(f"[{tag}] RAM={ram:.1f}GB | VRAM alloc={v_alloc:.1f}GB reserved={v_res:.1f}GB")
def cleanup(tag="cleanup"):
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
mem(tag)
assert torch.cuda.is_available(), "GPU runtime required"
print("GPU:", torch.cuda.get_device_name(0))
torch.backends.cuda.matmul.allow_tf32 = True
torch.set_float32_matmul_precision("high")
cleanup("startup")Depois que as dependências estiverem instaladas, vamos configurar as importações, o cache, o monitoramento de memória e algumas flags de desempenho da GPU. Veja como isso fica no código:
QwenImagePipeline: Essa é a principal classe de pipeline que vamos usar mais tarde para carregar e executar o Qwen-Image-2512 para geração de imagens.gradio: Essa biblioteca dá suporte à interface de usuário simples da web, pra gente poder criar pôsteres dentro do Colab.HF_HOME=/content/hf: Usamos isso pra fixar o cache do Hugging Face numa pasta conhecida, pra que os downloads e pesos do modelo sejam armazenados de forma consistente entre as execuções.mem() função: A função mem() controla a RAM do sistema e a VRAM da GPU alocadas versus reservadas. cleanup() função: É um pequeno utilitário de reinicialização para limpar referências Python e liberar memória GPU em cache, o que é útil ao iterar em resolução/etapas.Essa configuração ainda não gera imagens, mas torna as próximas etapas (carregamento e inferência) muito mais estáveis e fáceis de depurar.
Agora que o tempo de execução está configurado, é hora de carregar o modelo em um pipeline do Diffusers. Em um A100, o ideal é rodar a maioria dos pesos em BF16 para ter um bom desempenho, mas manter a decodificação VAE em FP32 para evitar NaNs que podem aparecer como imagens totalmente pretas.
DTYPE = torch.bfloat16
pipe = QwenImagePipeline.from_pretrained(
"Qwen/Qwen-Image-2512",
torch_dtype=DTYPE,
low_cpu_mem_usage=True,
use_safetensors=True,
).to("cuda")
if hasattr(pipe, "vae") and pipe.vae is not None:
pipe.vae.to(dtype=torch.float32)
cleanup("after pipe load")Aqui está o que estamos tentando fazer no código acima:
torch_dtype=DTYPE: Isso carrega a maioria dos pesos em BF16 para reduzir a VRAM e acelerar a inferência.low_cpu_mem_usage=True: Isso reduz a duplicação do lado da CPU durante o carregamento (importante para grandes pontos de verificação).use_safetensors=True: Isso garante que o carregador use o formato safetensors mais seguro/rápido quando disponível.pipe.vae.to(torch.float32) e converte as saídas do espaço latente em pixels. Se essa etapa de decodificação encontrar NaNs/Infs com precisão mais baixa, a imagem final pode ficar toda preta. Então, a gente força o VAE para FP32, seguido por uma chamada de “ cleanup() ” para confirmar o espaço ocupado pela RAM/VRAM após o carregamento.Depois, vamos definir as predefinições de proporção da plataforma e conectar o pipeline a uma interface minimalista do Gradio para criar pôsteres interativos.
Agora vamos montar o motor da demonstração, ou seja, uma pequena camada que transforma as entradas da interface do usuário em um prompt bem estruturado, escolhe uma resolução de saída com base nas predefinições da plataforma e chama o pipeline Qwen Image para gerar uma imagem.
ASPECT_PRESETS = {
"Instagram Post (1:1) — 1328×1328": (1328, 1328),
"Instagram Story (9:16) — 928×1664": (928, 1664),
"YouTube / Banner (16:9) — 1664×928": (1664, 928),
"Poster (3:4) — 1104×1472": (1104, 1472),
"Slides (4:3) — 1472×1104": (1472, 1104),
"Fast Draft (1:1) — 768×768": (768, 768),
}
DEFAULT_NEG = " "
def build_prompt(product_name, product_desc, offer, price, cta, benefits, tone, style_keywords, language):
return f"""
Create a high-converting e-commerce promotional poster in {language}. Clean grid layout, strong hierarchy.
- Product name: "{product_name}"
- Product description: "{product_desc}"
- Offer headline (exact): "{offer}"
- Price (exact): "{price}"
- CTA button text (exact): "{cta}"
- Benefits (use these exact phrases, no typos):
{benefits}
- Tone: {tone}
- Style keywords: {style_keywords}
- Text must be legible and correctly spelled.
- Do not add extra words, fake prices, or random letters.
- Align typography to a neat grid with consistent margins.
""".strip()
@torch.inference_mode()
def generate_image(product_name, product_desc, offer, price, cta, benefits, tone, style_keywords,
language, preset, negative_prompt, steps, true_cfg_scale, seed, show_seed):
w, h = ASPECT_PRESETS[preset]
prompt = build_prompt(product_name, product_desc, offer, price, cta, benefits, tone, style_keywords, language)
if seed is None or int(seed) < 0:
seed = random.randint(0, 2**31 - 1)
seed = int(seed)
gen = torch.Generator(device="cuda").manual_seed(seed)
img = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=int(w),
height=int(h),
num_inference_steps=int(steps),
true_cfg_scale=float(true_cfg_scale),
generator=gen,
).images[0].convert("RGB")
return (seed if show_seed else None), imgO mapa pré-definido e as duas funções acima são o motor principal do nosso Poster Studio.
ASPECT_PRESETS define diferentes tamanhos de tela para cada plataforma (por exemplo, 1:1 para publicações no Instagram, 9:16 para Stories, 16:9 para banners). Os usuários podem simplesmente escolher uma predefinição e nós a traduzimos para o formato correto ( width × height ) para geração.build_prompt() ” transforma informações básicas sobre o produto, como nome, oferta, preço, CTA e benefícios, em um briefing de imagem. Ele leva em conta o layout e as regras de texto, então o modelo recebe restrições consistentes todas as vezes e não acaba com uma cópia aleatória.generate_image() ` é a camada de execução. Ele lê a predefinição escolhida para obter width/height e chama o pipeline Qwen-Image com o steps, true_cfg_scale e negative_prompt selecionados. Por fim, ele mostra o pôster que foi criado (e, se quiser, a semente). Os parâmetros “ steps ” controlam por quanto tempo o processo de difusão rola (mais etapas significam resultados mais lentos, mas geralmente mais limpos), enquanto “ true_cfg_scale ” controla o quanto o modelo segue o prompt (um valor mais alto significa melhor aderência, mas um valor muito alto pode trazer artefatos).Depois, vamos colocar a função generate_image() numa interface Gradio pra que os usuários possam criar pôsteres sem precisar mexer com a engenharia de prompts brutos.
Por fim, colocamos o mecanismo de geração de pôsteres em uma interface Gradio. O aplicativo permite que o usuário digite os detalhes do produto, escolha uma proporção de plataforma e clique em Gerar.
with gr.Blocks(title="Qwen Poster Studio (Simple)") as demo:
gr.Markdown("## Qwen Poster Studio — Qwen-Image-2512")
with gr.Row():
with gr.Column(scale=1):
product_name = gr.Textbox(value="RÅSKOG Utility Cart", label="Product name")
product_desc = gr.Textbox(value="Compact rolling cart for small spaces. Durable metal frame.", lines=2, label="Product description")
offer = gr.Textbox(value="NEW YEAR SALE — 20% OFF", label="Offer headline")
price = gr.Textbox(value="$29.99", label="Price")
cta = gr.Textbox(value="Shop now", label="CTA button text")
benefits = gr.Textbox(value="- Compact\n- Easy to move\n- Fits small spaces", lines=4, label="Benefits")
tone = gr.Dropdown(["Premium", "Minimal", "Bold", "Playful", "Tech"], value="Premium", label="Tone")
style_keywords = gr.Textbox(value="modern Scandinavian minimal, clean grid, soft warm lighting, premium product photography", label="Style keywords")
language = gr.Dropdown(["English", "中文"], value="English", label="Language")
preset = gr.Dropdown(list(ASPECT_PRESETS.keys()), value="Instagram Post (1:1) — 1328×1328", label="Platform preset")
with gr.Accordion("Advanced (optional)", open=False):
negative_prompt = gr.Textbox(value=DEFAULT_NEG, label="Negative prompt", lines=2)
steps = gr.Slider(10, 80, value=50, step=1, label="Steps")
true_cfg_scale = gr.Slider(1.0, 10.0, value=4.0, step=0.1, label="true_cfg_scale")
seed = gr.Number(value=-1, precision=0, label="Seed (-1 = random)")
show_seed = gr.Checkbox(value=False, label="Show seed in output")
btn = gr.Button("Generate", variant="primary")
with gr.Column(scale=1):
used_seed_out = gr.Number(label="Used seed (optional)", precision=0)
image_out = gr.Image(label="Generated poster")
btn.click(
fn=generate_image,
inputs=[product_name, product_desc, offer, price, cta, benefits, tone, style_keywords,
language, preset, negative_prompt, steps, true_cfg_scale, seed, show_seed],
outputs=[used_seed_out, image_out]
)
demo.launch(share=True, debug=True)Veja como criamos o aplicativo Gradio:
width × height final usando ASPECT_PRESETS.steps ” e “ true_cfg_scale ”, que controlam quantas vezes o modelo faz a redução de ruído e o quanto ele segue o prompt, respectivamente. A semente controla a reprodutibilidade, e o show_seed mostra a semente final, se você quiser.btn.click() ` conecta tudo. O Gradio pega todos os widgets de entrada na ordem, passa eles para um generate_image() e encaminha os valores devolvidos para os widgets de saída. Por fim, demo.launch(share=True, debug=True) inicia o servidor Gradio, nos fornece um link público compartilhável para demonstrações e imprime logs de depuração no notebook para ajudar a diagnosticar problemas.Aqui está um vídeo mostrando nosso aplicativo Qwen Image 2512 final em ação:
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
DataCamp Team
4 min
blog
Dr Ana Rojo-Echeburúa
9 min
blog
Nisha Arya Ahmed
10 min
Tutorial
Kurtis Pykes
Tutorial
Amberle McKee
Tutorial
Abid Ali Awan



