
programa
Fundamentos de la IA
10 h
After DeepSeek disrupted the AI market, another Chinese company, Qwen, released several state-of-the-art models that are outperforming even DeepSeek's advanced reasoning models. Within just a few days of the DeepSeek launch, Qwen has released top-of-the-line, task-specific models that deliver real-world value rather than functioning solely as chatbots.
You can read the I Tested QwQ 32B Preview: Alibaba’s Reasoning Model blog to learn about Qwen reasoning model similar to DeekSeek R1.
In this tutorial, we will explore Qwen2.5-VL, a vision-language model that has surpassed all proprietary models in terms of vision capabilities. We will also learn how to use it locally and experience the flagship model online.
Image by Author
If you're new to AI and large language models (LLMs), consider taking the Introduction to LLMs in Python course. This course will help you understand LLMs and the revolutionary transformer architecture they are based on.
Qwen2.5-VL is the new flagship vision-language model from Qwen and a significant leap forward from its predecessor, Qwen2-VL. This model sets a new standard in multi-modal AI by not only mastering the recognition of common objects like flowers, birds, fish, and insects but also by analyzing complex texts, charts, icons, graphics, and layouts within images.
Additionally, Qwen2.5-VL is designed to be highly agentic, and capable of dynamic reasoning and tool direction—whether used on a computer or a phone.
The model’s advanced features include the ability to comprehend videos exceeding one hour in length, pinpoint specific events within them, and accurately localize objects in images by generating bounding boxes or points. It also provides stable JSON outputs for coordinates and attributes, ensuring precision in tasks requiring structured data.
Furthermore, Qwen2.5-VL supports structured outputs for scanned documents, such as invoices, forms, and tables, making it highly beneficial for industries like finance and commerce.
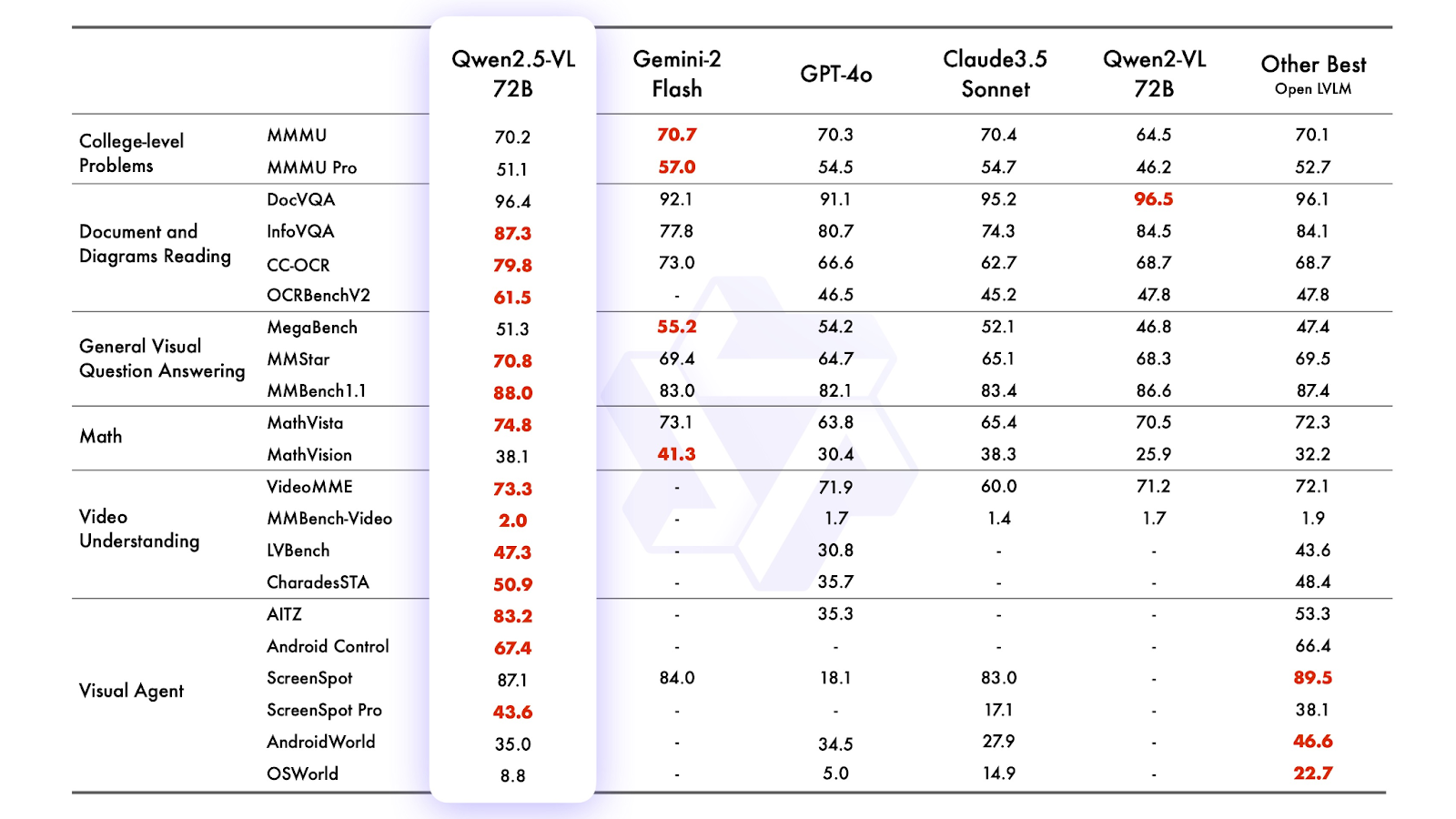
Source: Qwen2.5 VL
The flagship model Qwen2.5-VL-72B-Instruct delivers exceptional performance across a wide range of benchmarks, showcasing its versatility in handling diverse domains and tasks. It outperforms leading models such as Gemini 2 Flash, GPT-4o, and Claude 3.5 Sonnet, solidifying its position as a top-tier vision-language model.
You can also evaluate the Qwen model or any kind of LLM on your own by following the Evaluate LLMs Effectively Using DeepEval tutorial.
We will now learn a few ways to run Qwen2.5-VL locally. These solutions are already available in the QwenLM/Qwen2.5-VL GitHub repository. All we have to do is set up the environment, fix some common errors, and run the web application locally.
1. Start by cloning the Qwen2.5-VL GitHub repository and navigating to the project directory:
git clone https://github.com/QwenLM/Qwen2.5-VL
cd Qwen2.5-VL2. Install the required dependencies for the web application using the following command:
pip install -r requirements_web_demo.txt3. To ensure compatibility with your GPU, install the latest versions of PyTorch, TorchVision, and TorchAudio with CUDA support. Even if PyTorch is already installed, you may encounter issues while running the web application, so it’s best to update:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1244. Update Gradio and Gradio Client to avoid connection and UI-related errors, as older versions may cause issues:
pip install -U gradio gradio_client 5. Now, run the web demo application using the smaller 3B model checkpoint. This is recommended for laptops with limited GPU memory (e.g., 8GB VRAM). While the 7B model might work, it will likely result in slow response generation:
python web_demo_mm.py --checkpoint-path "Qwen/Qwen2.5-VL-3B-Instruct" As we can see, it downloaded the model first, then loaded the processor and model, and now the web app is running on the local URL, http://127.0.0.1:7860.
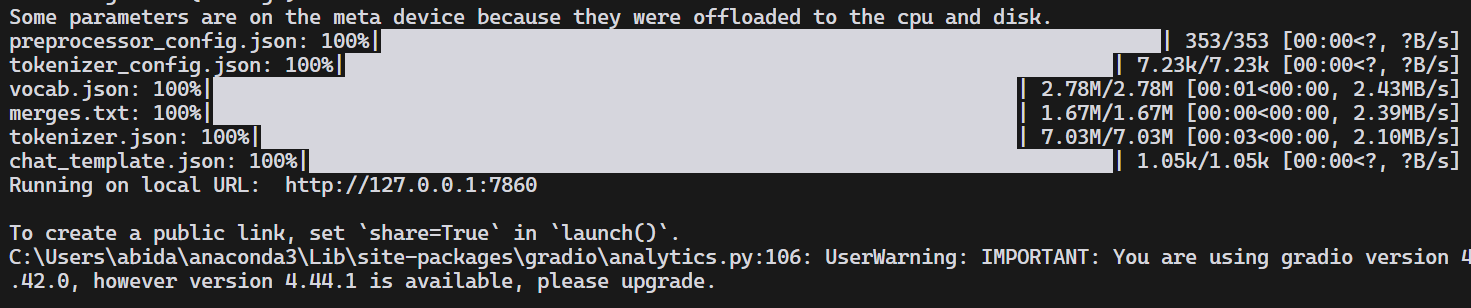
The web app is running perfectly.
6. You can upload an image with text and multiple figures and ask the model to explain it. Even the smaller 3B model demonstrates impressive performance, identifying intricate details in the image.
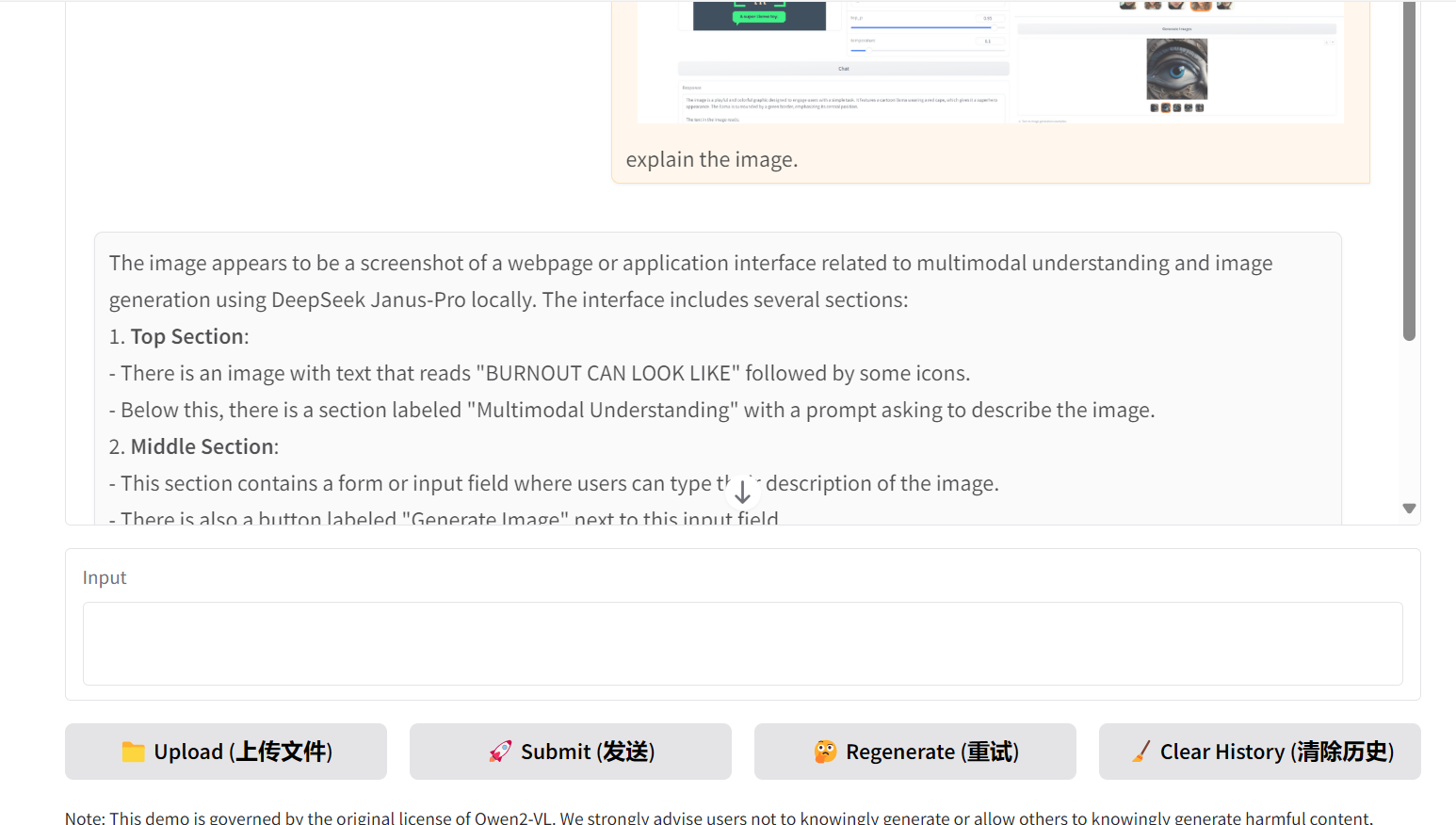
7. You can also interact with the model without providing an image. It will generate text-based responses, functioning like a standard large language model.

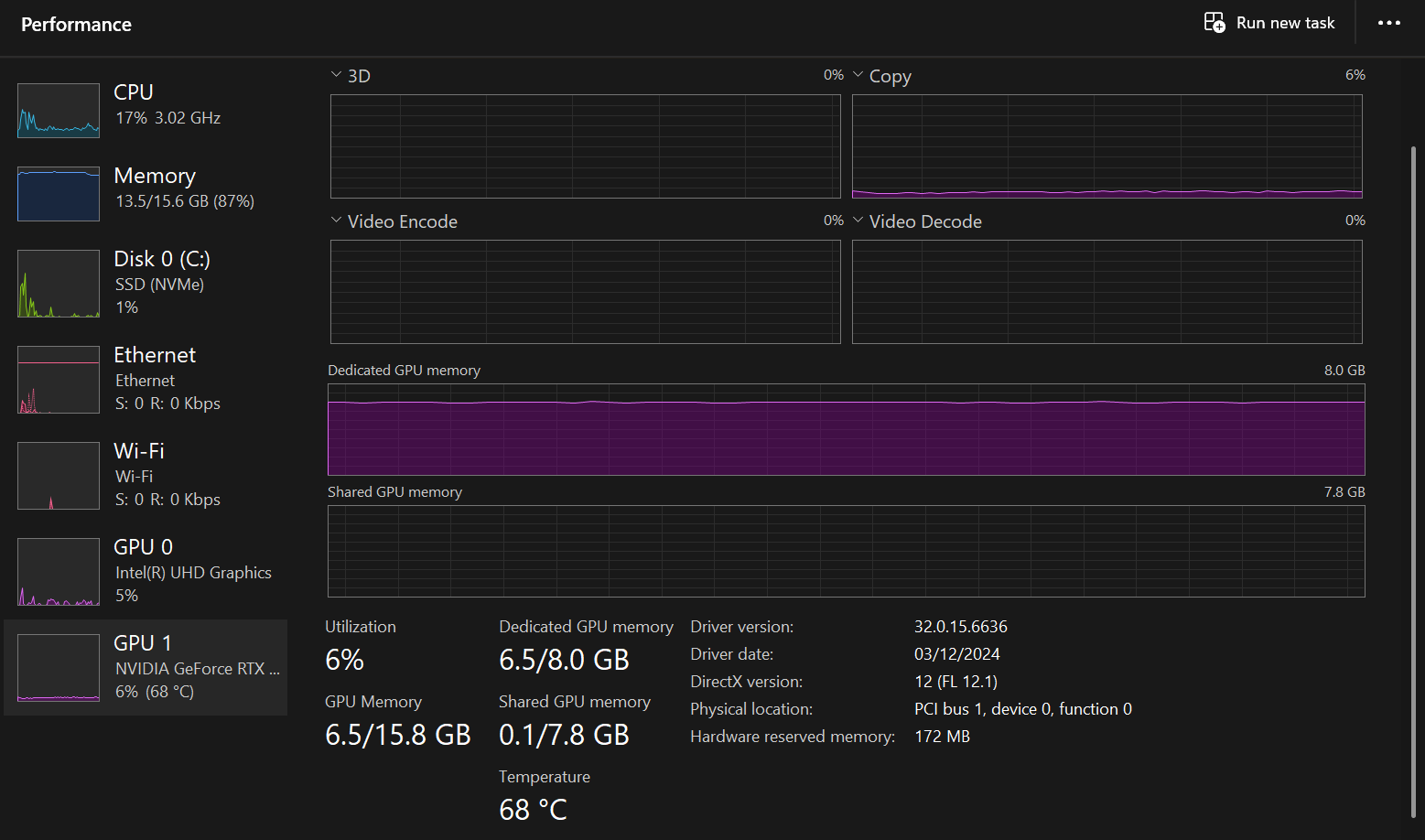
If you open your Task Manager and monitor performance, you will notice that GPU utilization is around 6%, indicating smooth operation.
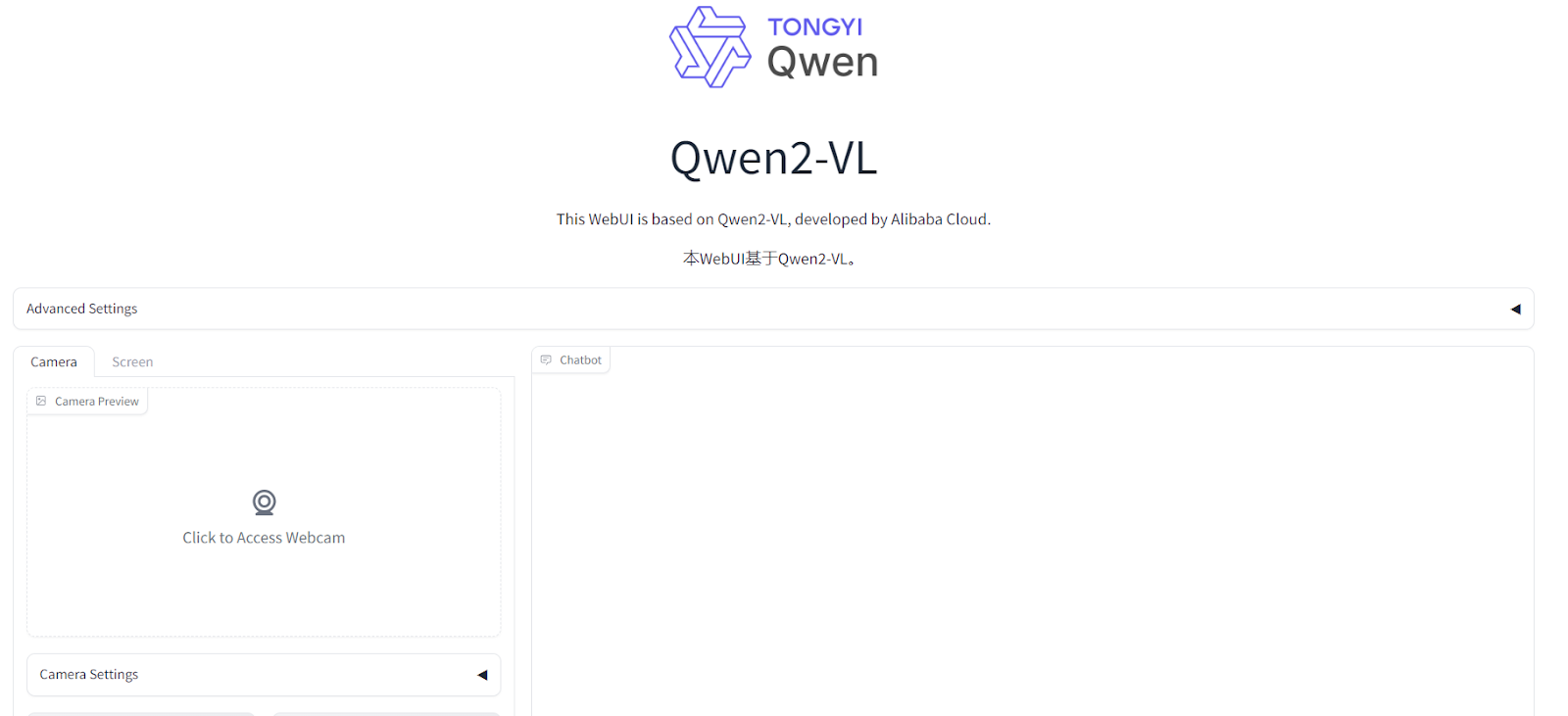
The GitHub repository also includes an experimental streaming video chat demo, located in the web_demo_streaming directory. This demo allows you to interact with the model using your webcam.
To run the streaming video chat demo, navigate to the streaming demo directory and run the application with the 3B model checkpoint.
cd web_demo_streaming/
python app.py --checkpoint-path "Qwen/Qwen2.5-VL-3B-Instruct" If you have a more powerful GPU, this web app will run smoothly. Simply grant access to your webcam and start asking questions.
Learn how to use the locally deployed model and build a proper UI application around it. You can do this by completing the Developing LLM Applications with LangChain course.
The most stable way to use Qwen2.5-VL locally is by running it through Docker. The Qwen team provides pre-built Docker images with all necessary environments configured.
1. Download and install Docker Desktop from the official website.
2. To simplify deployment, use the pre-built Docker image qwenllm/qwenvl. Install the required drivers and download the model files to launch the demo.
docker run --gpus all --ipc=host --network=host --rm --name qwen2 -it qwenllm/qwenvl:2-cu121 bashYou can learn about a code generation model called Qwen 2.5 Coder by reading our Qwen 2.5 Coder: A Guide With Examples.
If you want to experience the flagship model Qwen2.5-VL 72B Instuct, go to the Qwen Chat website, create an account, and start using the model just like ChatGPT. You may need to select the model before loading the image.
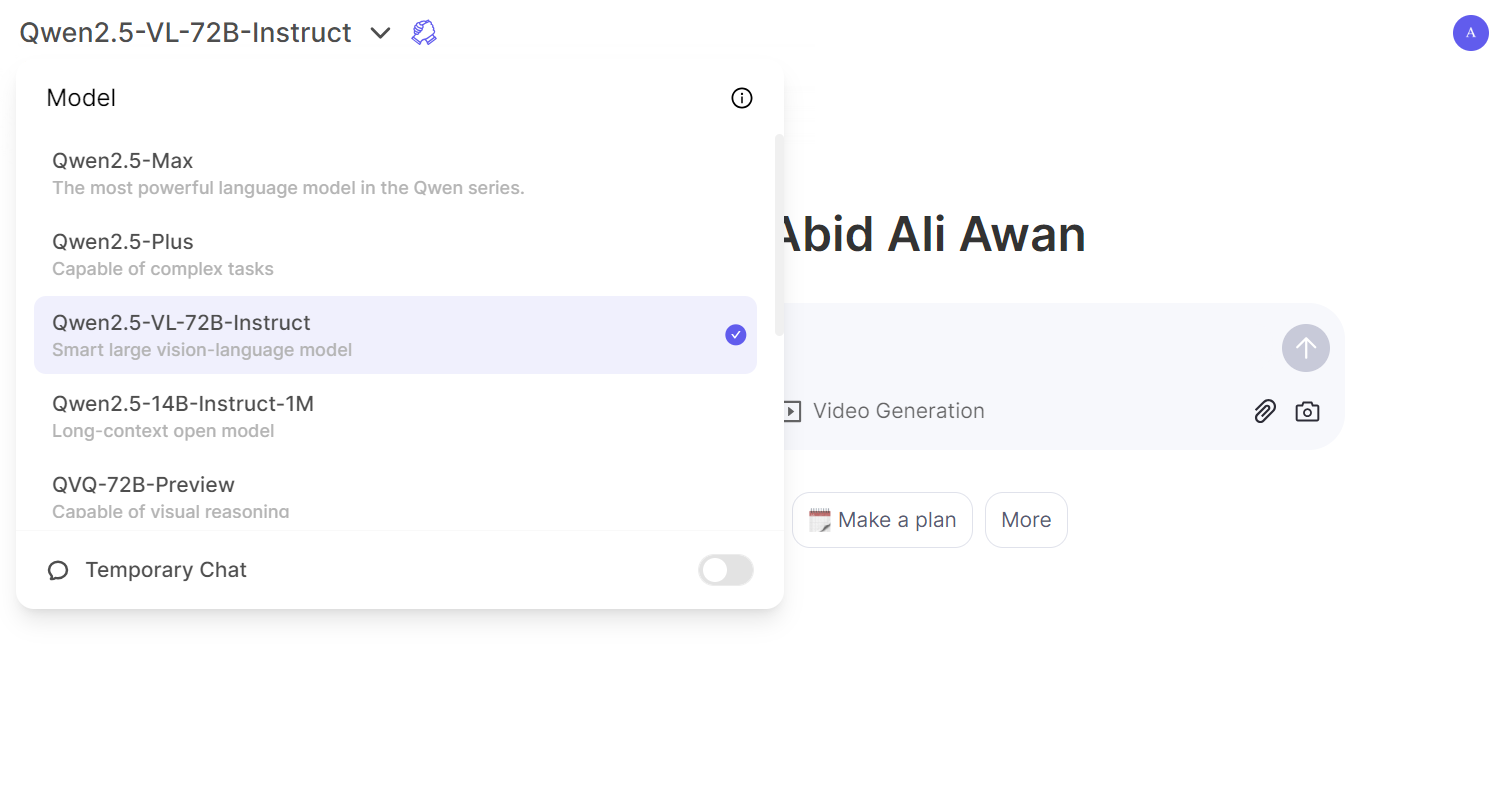
Load the image and start asking questions about it.
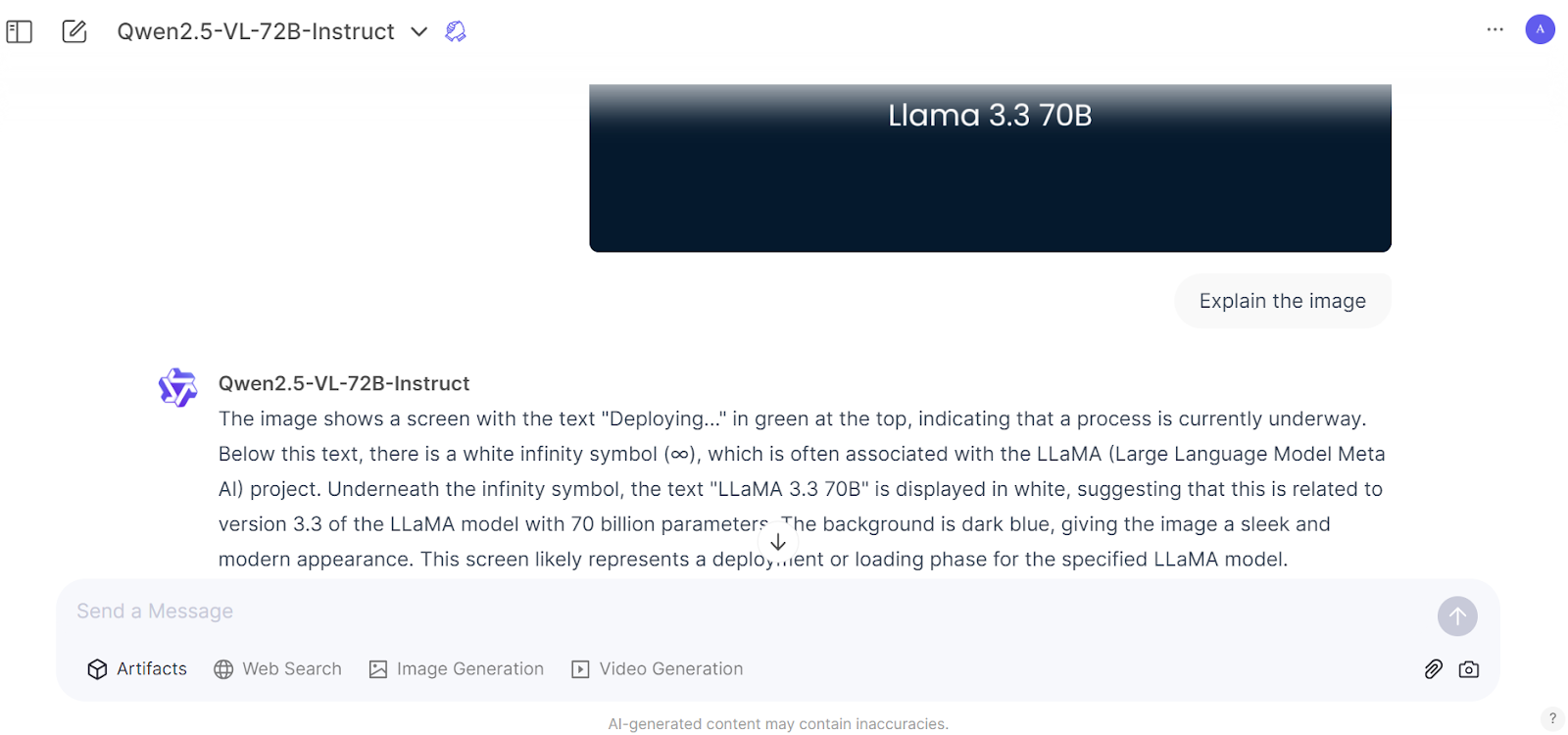
The response generation is fast and accurate, and with your effort, you can experience a top-of-the-line AI model.
Alibaba Cloud provides all the necessary tools for you to access various AI models using the API, fine-tuned similarly to the OpenAI platform. Read the Qwen (Alibaba Cloud) Tutorial: Introduction and Fine-Tuning to learn more about it.
Qwen2.5-VL is a glimpse into the future of AI, proving that innovation in advanced AI models is not exclusive to the US or the Western world. This model demonstrates exceptional accuracy and offers seamless integration into various workflows, enabling users to create custom AI tools to automate tasks.
For instance, you can use Qwen2.5-VL to set up a LinkedIn account, populate it with all necessary details, and even post articles on your behalf — all with minimal effort.
In this tutorial, we have learned about Qwen 2.5-VL, a vision model capable of handling even the smallest details in an image. We also learned how to use it locally on a laptop with a GPU. In the end, we created a Qwen account and used the flagship model online, similar to ChatGPT.
Read about Alibaba's Qwen 2.5-Max, a model that competes with GPT-4o, Claude 3.5 Sonnet, and DeepSeek V3.
Top DataCamp Courses
programa
programa
Curso
blog
Alex Olteanu
8 min
Tutorial
Aashi Dutt
Tutorial
François Aubry
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan

