
Cours
Modèles multimodaux avec Hugging Face
4 h
1.8K
Qwen-Image-2512 est un modèle open source puissant de conversion de texte en image. modèle open source puissant de conversion de texte en image particulièrement performant pour les visuels réalistes et les compositions riches en texte. Dans ce tutoriel, nous l'utiliserons pour créer un Poster Studio, un application Gradio, une application dans laquelle vous pouvez saisir les détails d'un produit tels que son nom, son offre, son prix, son CTA et ses avantages, choisir le format de la plateforme et générer une image promotionnelle en un seul clic.
Étant donné que Qwen-Image-2512 est un modèle volumineux, nous nous concentrerons également sur les aspects pratiques de son bon fonctionnement. Vous apprendrez à le charger de manière stable sur un A100 en utilisant les bons paramètres de précision, à éviter les modes de défaillance courants et à vous adapter à n'importe quel flux de travail en itérant à des résolutions plus faibles, en réduisant les étapes ou en explorant un modèle quantifié pour un matériel plus performant.
Qwen-Image-2512 est une mise à jour du modèle de base Qwen de conversion de texte en image, qui présente une amélioration significative de la qualité par rapport à la version précédente de Qwen-Image. Sous le capot, Qwen-Image est un modèle de diffusion MMDiT de 20 milliards, conçu pour une forte adhésion immédiate et un rendu texte-image.
Il s'appuie également sur une évaluation à grande échelle de type préférentiel avec plus de 10 000 tours à l'aveugle sur AI Arena, où le modèle s'est distingué comme le modèle open source le plus performant tout en restant compétitif par rapport aux systèmes fermés.
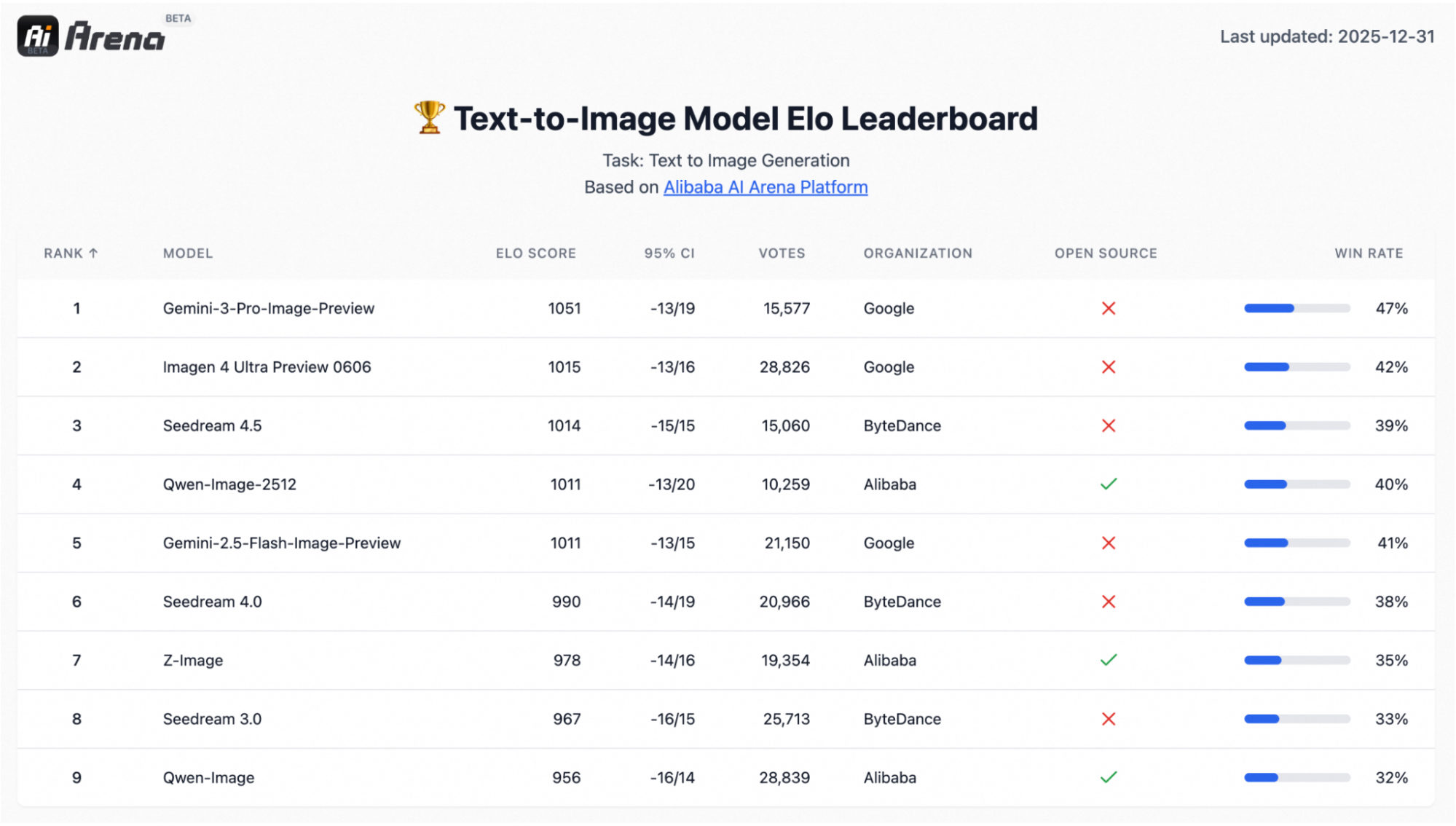
Les trois améliorations qui ont tendance à être les plus importantes dans les flux de travail réels sont les suivantes :
Dans cette section, nous allons créer une application Gradio simple qui :
steps, true_cfg_scale, seed et un panneau optionnel. negative prompt.QwenImagePipeline.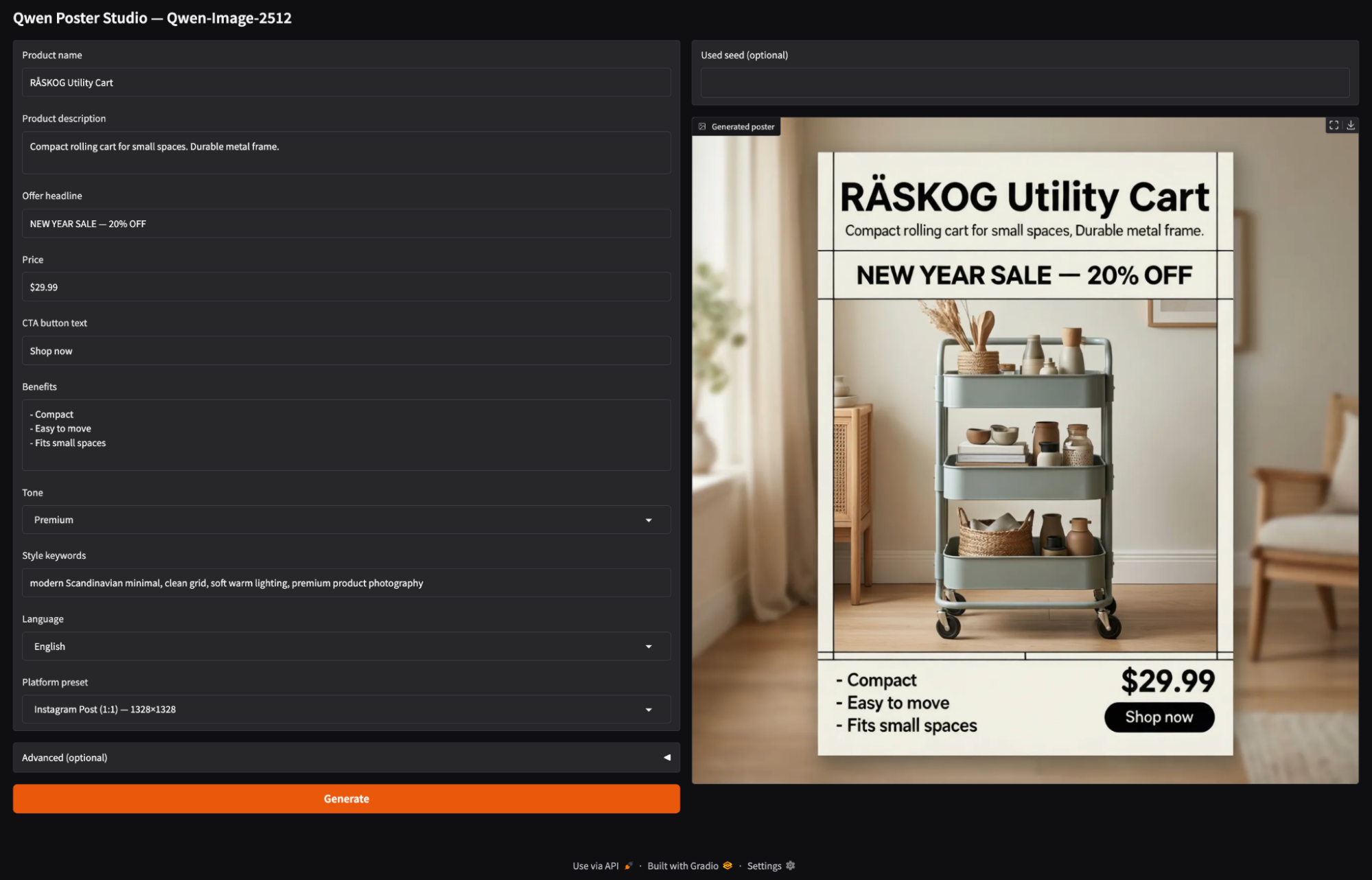
Construisons-le étape par étape.
Tout d'abord, veuillez installer la dernière version des Diffusers sur GitHub (carte de modèle de Qwen carte modèle le recommande pour la prise en charge du pipeline) ainsi que les dépendances principales :
!pip -q install --upgrade pip
!pip -q install git+https://github.com/huggingface/diffusers
!pip -q install transformers accelerate safetensors gradio pillow psutilEnsuite, veuillez effectuer une vérification rapide pour confirmer que CUDA est disponible et identifier le GPU :
import torch, diffusers
print("diffusers:", diffusers.__version__)
print("CUDA available:", torch.cuda.is_available())
!nvidia-smiSi CUDA available: True et que vous voyez votre GPU dans nvidia-smi, vous êtes prêt à charger le modèle.
Remarque : QwenImagePipeline n'est pas un bloc unique de type UNet. Dans Diffusers, il s'agit d'une pile complète comprenant un encodeur de texte Qwen2.5-VL-7B-Instruct, le transformateur de diffusion MMDiT et un auto-encodeur variationnel(VAE) pour le décodage. Le codeur de texte 7B est l'une des principales raisons pour lesquelles la RAM/VRAM peut connaître des pics pendant le chargement et la génération du modèle, en particulier sur les GPU plus petits.
J'ai exécuté ce tutoriel sur Google Colab avec un A100, qui gère facilement une résolution d'image de 1328 × 1328 à environ 50 étapes. Sur les GPU de classe T4/16 Go, il est généralement nécessaire de réduire la résolution (à environ 768 × 768 pixels et moins d'étapes) ou d'utiliser des variantes quantifiées via d'autres environnements d'exécution (tels que GGUF/ComfyUI).
Avant de charger le modèle, il est recommandé de configurer un petit harnais d'exécution qui garantit la prévisibilité de Colab. Qwen-Image-2512 est un programme exigeant, et les tâches de génération d'images peuvent rapidement utiliser à la fois la mémoire RAM du système et la mémoire GPU.
import os, gc, random, psutil, torch
from diffusers import QwenImagePipeline
import gradio as gr
os.environ["HF_HOME"] = "/content/hf"
os.makedirs("/content/hf", exist_ok=True)
def mem(tag=""):
ram = psutil.virtual_memory().used / 1e9
v_alloc = torch.cuda.memory_allocated()/1e9 if torch.cuda.is_available() else 0
v_res = torch.cuda.memory_reserved()/1e9 if torch.cuda.is_available() else 0
print(f"[{tag}] RAM={ram:.1f}GB | VRAM alloc={v_alloc:.1f}GB reserved={v_res:.1f}GB")
def cleanup(tag="cleanup"):
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
mem(tag)
assert torch.cuda.is_available(), "GPU runtime required"
print("GPU:", torch.cuda.get_device_name(0))
torch.backends.cuda.matmul.allow_tf32 = True
torch.set_float32_matmul_precision("high")
cleanup("startup")Une fois les dépendances installées, nous configurons les importations, la mise en cache, la surveillance de la mémoire et quelques indicateurs de performances GPU. Voici à quoi cela ressemble dans le code :
QwenImagePipeline: Il s'agit de la classe principale que nous utiliserons ultérieurement pour charger et exécuter Qwen-Image-2512 afin de générer des images.gradio: Cette bibliothèque alimente l'interface utilisateur web simple afin que nous puissions générer des affiches dans Colab.HF_HOME=/content/hf: Nous utilisons cette option pour épingler le cache Hugging Face à un dossier connu, afin que les téléchargements de modèles et les poids soient stockés de manière cohérente d'une exécution à l'autre.mem() fonction : La fonction mem() permet de suivre la mémoire RAM système et la mémoire VRAM GPU allouées par rapport à celles réservées. cleanup() fonction : Il s'agit d'un petit utilitaire de réinitialisation permettant d'effacer les références Python et de libérer la mémoire GPU mise en cache, ce qui est utile lors de l'itération sur la résolution/les étapes.Cette configuration ne génère pas encore d'images, mais elle rend les étapes suivantes (chargement et inférence) beaucoup plus stables et faciles à déboguer.
Maintenant que le runtime est configuré, il est temps de charger le modèle dans un pipeline Diffusers. Sur une A100, il est recommandé d'utiliser BF16 pour la plupart des poids afin d'optimiser les performances, tout en conservant le décodage VAE en FP32 afin d'éviter les NaN qui peuvent apparaître sous forme d'images entièrement noires.
DTYPE = torch.bfloat16
pipe = QwenImagePipeline.from_pretrained(
"Qwen/Qwen-Image-2512",
torch_dtype=DTYPE,
low_cpu_mem_usage=True,
use_safetensors=True,
).to("cuda")
if hasattr(pipe, "vae") and pipe.vae is not None:
pipe.vae.to(dtype=torch.float32)
cleanup("after pipe load")Voici ce que nous cherchons à accomplir dans le code ci-dessus :
torch_dtype=DTYPE: Cela charge la plupart des poids dans BF16 afin de réduire la VRAM et d'accélérer l'inférence.low_cpu_mem_usage=True: Cela réduit la duplication côté CPU pendant le chargement (ce qui est important pour les points de contrôle volumineux).use_safetensors=True: Cela garantit que le chargeur utilise le format safetensors, plus sûr et plus rapide, lorsqu'il est disponible.pipe.vae.to(torch.float32) e convertit les sorties de l'espace latent en pixels. Si cette étape de décodage rencontre des valeurs NaN/Inf dans une précision inférieure, l'image finale peut devenir entièrement noire. Nous imposons donc au VAE le format FP32, suivi d'un appel à la fonction « cleanup() » afin de vérifier l'empreinte mémoire RAM/VRAM après le chargement.Ensuite, nous définirons les préréglages du format d'image de la plateforme et connecterons le pipeline à une interface utilisateur Gradio minimale pour la génération interactive d'affiches.
Nous allons maintenant développer le moteur de la démo, c'est-à-dire une petite couche qui transforme les entrées de l'interface utilisateur en une invite bien structurée, choisit une résolution de sortie en fonction des préréglages de la plateforme et appelle le pipeline Qwen Image pour générer une image.
ASPECT_PRESETS = {
"Instagram Post (1:1) — 1328×1328": (1328, 1328),
"Instagram Story (9:16) — 928×1664": (928, 1664),
"YouTube / Banner (16:9) — 1664×928": (1664, 928),
"Poster (3:4) — 1104×1472": (1104, 1472),
"Slides (4:3) — 1472×1104": (1472, 1104),
"Fast Draft (1:1) — 768×768": (768, 768),
}
DEFAULT_NEG = " "
def build_prompt(product_name, product_desc, offer, price, cta, benefits, tone, style_keywords, language):
return f"""
Create a high-converting e-commerce promotional poster in {language}. Clean grid layout, strong hierarchy.
- Product name: "{product_name}"
- Product description: "{product_desc}"
- Offer headline (exact): "{offer}"
- Price (exact): "{price}"
- CTA button text (exact): "{cta}"
- Benefits (use these exact phrases, no typos):
{benefits}
- Tone: {tone}
- Style keywords: {style_keywords}
- Text must be legible and correctly spelled.
- Do not add extra words, fake prices, or random letters.
- Align typography to a neat grid with consistent margins.
""".strip()
@torch.inference_mode()
def generate_image(product_name, product_desc, offer, price, cta, benefits, tone, style_keywords,
language, preset, negative_prompt, steps, true_cfg_scale, seed, show_seed):
w, h = ASPECT_PRESETS[preset]
prompt = build_prompt(product_name, product_desc, offer, price, cta, benefits, tone, style_keywords, language)
if seed is None or int(seed) < 0:
seed = random.randint(0, 2**31 - 1)
seed = int(seed)
gen = torch.Generator(device="cuda").manual_seed(seed)
img = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=int(w),
height=int(h),
num_inference_steps=int(steps),
true_cfg_scale=float(true_cfg_scale),
generator=gen,
).images[0].convert("RGB")
return (seed if show_seed else None), imgLa carte prédéfinie et les deux fonctions ci-dessus constituent le moteur central de notre Poster Studio.
ASPECT_PRESETS définit différentes tailles de toile pour différentes plateformes (par exemple, 1:1 pour les publications Instagram, 9:16 pour les stories, 16:9 pour les bannières). Les utilisateurs peuvent simplement sélectionner un préréglage, et nous le convertissons en l'width × height e appropriée pour la génération.build_prompt() » transforme les informations basiques sur les produits, telles que le nom, l'offre, le prix, le CTA et les avantages, en un brief visuel. Il tient compte de la mise en page et des règles de texte, de sorte que le modèle obtient à chaque fois des contraintes cohérentes et ne dérive pas vers une copie aléatoire.generate_image(), constitue la couche d'exécution. Il lit le préréglage sélectionné pour obtenir l'width/height, puis appelle le pipeline Qwen-Image avec l'steps, l'true_cfg_scale et l'negative_prompt sélectionnés. Enfin, il renvoie l'affiche générée (et éventuellement la graine). L'steps, contrôle la durée du processus de diffusion (plus il y a d'étapes, plus le résultat est lent mais généralement plus propre), tandis que l'true_cfg_scale, contrôle la force avec laquelle le modèle suit la consigne (une valeur plus élevée signifie une meilleure adhésion, mais une valeur trop élevée peut introduire des artefacts).Ensuite, nous intégrerons la fonction generate_image() dans une interface Gradio afin que les utilisateurs puissent générer des affiches sans jamais avoir à se préoccuper de l'ingénierie brute des invites.
Enfin, nous intégrons le moteur de génération d'affiches dans une interface Gradio. L'application permet à l'utilisateur de saisir les détails du produit, de sélectionner un format d'image et de cliquer sur « Générer ».
with gr.Blocks(title="Qwen Poster Studio (Simple)") as demo:
gr.Markdown("## Qwen Poster Studio — Qwen-Image-2512")
with gr.Row():
with gr.Column(scale=1):
product_name = gr.Textbox(value="RÅSKOG Utility Cart", label="Product name")
product_desc = gr.Textbox(value="Compact rolling cart for small spaces. Durable metal frame.", lines=2, label="Product description")
offer = gr.Textbox(value="NEW YEAR SALE — 20% OFF", label="Offer headline")
price = gr.Textbox(value="$29.99", label="Price")
cta = gr.Textbox(value="Shop now", label="CTA button text")
benefits = gr.Textbox(value="- Compact\n- Easy to move\n- Fits small spaces", lines=4, label="Benefits")
tone = gr.Dropdown(["Premium", "Minimal", "Bold", "Playful", "Tech"], value="Premium", label="Tone")
style_keywords = gr.Textbox(value="modern Scandinavian minimal, clean grid, soft warm lighting, premium product photography", label="Style keywords")
language = gr.Dropdown(["English", "中文"], value="English", label="Language")
preset = gr.Dropdown(list(ASPECT_PRESETS.keys()), value="Instagram Post (1:1) — 1328×1328", label="Platform preset")
with gr.Accordion("Advanced (optional)", open=False):
negative_prompt = gr.Textbox(value=DEFAULT_NEG, label="Negative prompt", lines=2)
steps = gr.Slider(10, 80, value=50, step=1, label="Steps")
true_cfg_scale = gr.Slider(1.0, 10.0, value=4.0, step=0.1, label="true_cfg_scale")
seed = gr.Number(value=-1, precision=0, label="Seed (-1 = random)")
show_seed = gr.Checkbox(value=False, label="Show seed in output")
btn = gr.Button("Generate", variant="primary")
with gr.Column(scale=1):
used_seed_out = gr.Number(label="Used seed (optional)", precision=0)
image_out = gr.Image(label="Generated poster")
btn.click(
fn=generate_image,
inputs=[product_name, product_desc, offer, price, cta, benefits, tone, style_keywords,
language, preset, negative_prompt, steps, true_cfg_scale, seed, show_seed],
outputs=[used_seed_out, image_out]
)
demo.launch(share=True, debug=True)Voici comment nous développons l'application Gradio :
width × height finale à l'aide de ASPECT_PRESETS.steps » (Nombre maximal d'itérations de débruitage) et « true_cfg_scale » (Niveau de suivi de la consigne), qui contrôlent respectivement le nombre d'itérations de débruitage exécutées par le modèle et la force avec laquelle le modèle suit la consigne. La graine contrôle la reproductibilité, et l'option show_seed permet d'afficher la graine finale.btn.click() e relie tous les éléments. Gradio traite tous les widgets d'entrée dans l'ordre, les transmet à generate_image() et achemine les valeurs renvoyées vers les widgets de sortie. Enfin, demo.launch(share=True, debug=True) démarre le serveur Gradio, nous fournit un lien public partageable pour les démonstrations et affiche les journaux de débogage dans le notebook afin de faciliter le diagnostic des problèmes.Voici une vidéo présentant notre application finale Qwen Image 2512 en fonctionnement :
Meilleurs cours DataCamp
Cours
Cours
Cours