
Curso
Diseño de sistemas agénticos con LangChain
3 h
12.1K
Qwen3-Coder-Next es un modelo de codificación de peso abierto del equipo Qwen, creado para la programación de agentes y los flujos de trabajo de los programadores locales. Utiliza una mezcla escasa diseño de mezcla de expertos para mantener la eficiencia y seguir ofreciendo un alto rendimiento en los benchmarks modernos de codificación y uso de herramientas, con soporte para contextos largos y tareas complejas de varios pasos.
Lo que hace que Qwen3-Coder-Next sea especialmente interesante es lo competitivo que resulta en comparación con los mejores modelos cerrados. Las primeras evaluaciones muestran que puede alcanzar niveles de rendimiento similares a los de sistemas como Claude Sonnet 4.5, al tiempo que sigue siendo algo que puedes ejecutar localmente con control total sobre tu configuración, privacidad y velocidad, sin depender de costosas API alojadas.
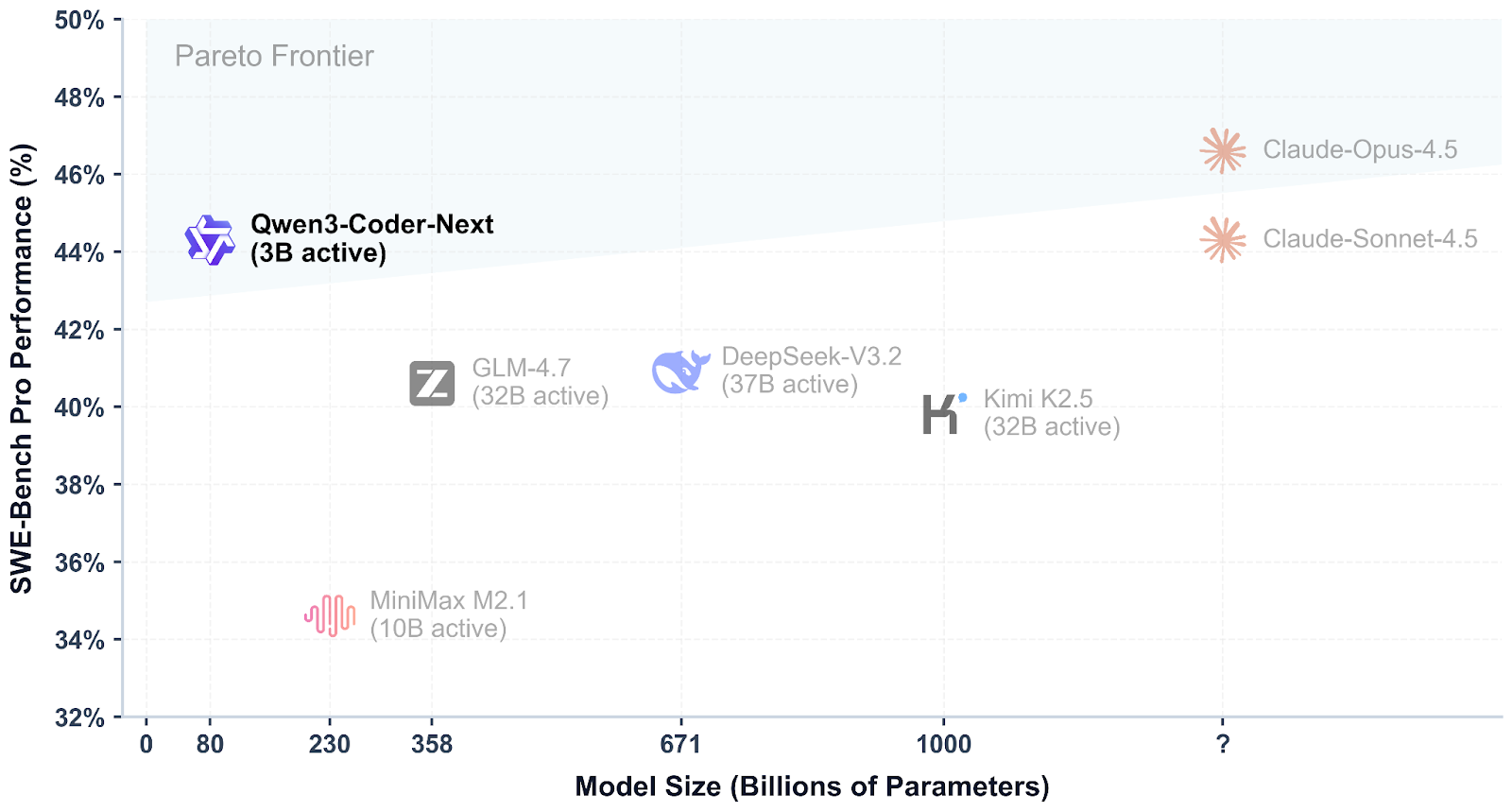
Fuente: Qwen/Qwen3-Coder-Next
En este tutorial, crearemos llama.cpp desde el código fuente, ejecutaremos Qwen3-Coder-Next localmente utilizando el servidor de inferencia llama.cpp y, a continuación, lo conectaremos a Qwen Code CLI. Por último, programaremos un sencillo panel de control para el análisis de datos.
Antes de compilar y ejecutar Qwen3-Coder-Next localmente, necesitarás una configuración de desarrollo Linux que funcione con las herramientas de compilación estándar necesarias para compilar llama.cpp y ejecutar modelos GGUF.
Además de los paquetes del sistema, asegúrate de que también dispones de:
Comienza actualizando tu sistema e instalando las dependencias principales:
sudo apt-get update
sudo apt-get install -y build-essential cmake curl git libcurl4-openssl-devSi tienes pensado utilizar la aceleración CUDA, confirma que tu GPU NVIDIA se detecta correctamente:
nvidia-smiEn nuestro caso, estamos utilizando una NVIDIA RTX 3090 con 24 GB de VRAM. Dado que Qwen3-Coder-Next requiere más memoria que la necesaria para cuantificaciones más grandes, los pesos restantes del modelo se descargarán automáticamente enuna RAM del sistem , lo que permitirá que el modelo siga funcionando localmente con un buen rendimiento.
Para ejecutar Qwen3-Coder-Next sin problemas, tu hardware debe cumplir con estos requisitos aproximados de memoria:
Si no dispones de 46 GB, puedes ejecutar versiones cuantificadas más pequeñas (como 3 bits).
Una regla general sencilla es:
Disco + RAM + VRAM ≥ tamaño cuantitativo
Si todo el cuantificado cabe en la memoria, puedes esperar un rendimiento local rápido. Si no es así, el modelo seguirá funcionando mediante la descarga, pero la inferencia será más lenta.
Antes de ejecutar Qwen3-Coder-Next localmente, necesitamos un motor de inferencia rápido. La opción más popular hoy en día es llama.cpp, que proporciona una inferencia GGUF ligera y un servidor local fácil de ejecutar.
Si deseas una configuración rápida, llama.cpp ofrece binarios precompilados para macOS, Linux y Windows (incluidas compilaciones compatibles con CUDA). Puedes descargarlos directamente desde la página oficial de GitHub: Versión b7936 · ggml-org/llama.cpp.
Con una instalación precompilada, puedes ejecutar inmediatamente las herramientas CLI de llama.cpp o iniciar el servidor de inferencia sin necesidad de compilar nada tú mismo.

En este tutorial, compilaremos llama.cpp manualmente en lugar de utilizar binarios precompilados por varias razones importantes:
Comencemos descargando el código fuente oficial llama.cpp directamente desde GitHub. Esto garantiza que trabajéis con la versión más reciente, incluidas las últimas mejoras y correcciones de errores de CUDA:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cppEn este punto, deberías estar dentro del directorio llama.cpp, que contiene todo lo necesario para compilar el proyecto desde cero.
A continuación, hay que configurar el sistema de compilación utilizando CMake. Este paso genera los archivos de compilación necesarios y habilita la aceleración de la GPU a través de CUDA:
cmake /workspace/llama.cpp -B /workspace/llama.cpp/build -DGGML_CUDA=ON -DBUILD_SHARED_LIBS=OFF
Ahora compilamos el binario del servidor de inferencia real. Este es el componente que alojará Qwen3-Coder-Next localmente y expondrá un punto final de API para herramientas de codificación e integraciones CLI:
cmake --build /workspace/llama.cpp/build -j --clean-first --target llama-server
Una vez completada la compilación, los ejecutables compilados se almacenan en el directorio build/bin/. Para que sea más fácil ejecutarlos directamente desde la carpeta principal del proyecto, puedes copiarlos así:
cp /workspace/llama.cpp/build/bin/llama-server /workspace/llama.cpp/llama-serverAhora que llama.cpp está instalado, el siguiente paso es descargar el modelo Qwen3-Coder-Next GGUF de Hugging Face.
Antes de empezar, asegúrate de que tienes una versión reciente de instalación de Python (>= 3.11), ya que las herramientas y utilidades de transferencia de Hugging Face dependen de ella.
Para descargar archivos GGUF de gran tamaño de forma eficiente, utilizaremos el cliente Hugging Face Hub junto con los backends de alta velocidad Xet y transfer:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferA continuación, habilita el backend de transferencia optimizado de Hugging Face:
export HF_HUB_ENABLE_HF_TRANSFER=1Ahora podemos descargar la versióndinámica GGUF de Qwen3-Coder-Next. En este tutorial, obtendremos específicamente la cuantificaciónUD-Q4_K_XL de .
Esta es una excelente opción predeterminada, ya que ofrece un equilibrio perfecto entre:
El formato Q4 significa que el modelo se comprime a precisión de 4 bits, lo que lo hace mucho más ligero que los pesos FP16 completos, al tiempo que mantiene una calidad de salida impresionante.
hf download unsloth/Qwen3-Coder-Next-GGUF \
--local-dir /workspace/models/qwen3-coder-next \
--include "*UD-Q4_K_XL*"Una vez ejecutado el comando, los archivos del modelo comenzarán a descargarse en tu directorio local.

En una red de alta velocidad, esto suele tardar solo unos minutos. Una vez completada la descarga, tendrás el modelo GGUF listo para cargarlo enun servidor llam e para la inferencia local.
Una vez descargado el modelo GGUF, podemos ejecutar Qwen3-Coder-Next localmente utilizando el backend de inferencia llama-server. Esto inicia un servidor API compatible con OpenAI al que pueden conectarse herramientas de codificación y CLI.
Ejecuta el siguiente comando:
./llama-server \
--model "/workspace/models/qwen3-coder-next/Qwen3-Coder-Next-UD-Q4_K_XL.gguf" \
--alias "Qwen3-Coder-Next" \
--host 0.0.0.0 \
--port 8080 \
--threads 32 \
--threads-batch 32 \
--ctx-size 20000\
--batch-size 1024\
--ubatch-size 256 \
--jinja \
--flash-attn on \
--temp 0.7 \
--top-p 0.9 \
--min-p 0.05 \
--fit on \
--swa off
Explicación de los argumentos clave:
--model: Ruta a la descarga Qwen3-Coder-Next GGUF checkpoint--alias: Nombre de modelo amigable que se muestra en los clientes API.--host 0.0.0.0: Expone el servidor en todas las interfaces de red (útil para el acceso remoto).--port 8080: Ejecuta la API de inferencia en el puerto 8080.--threads 32: Utiliza 32 subprocesos de CPU para obtener el máximo rendimiento.--threads-batch 32: Paraleliza el procesamiento por lotes para acelerar la generación de tokens.--ctx-size 20000: Establece una ventana de contexto grande (~20 000 tokens) para sesiones de programación largas.--batch-size 1024: Mejora la utilización de la GPU durante la inferencia.--ubatch-size 256: Controla los micro lotes para un rendimiento más fluido.--jinja: Permite el formato de plantillas de chat necesario para los modelos de estilo instructivo.--flash-attn on: Activa la atención instantánea para una inferencia más rápida en contextos largos.--temp 0.7: Mantiene los resultados centrados, pero sin perder la creatividad para la codificación de vibraciones.--top-p 0.9: Muestreo del núcleo para una diversidad equilibrada--min-p 0.05: Filtra los tokens con una probabilidad extremadamente baja para obtener completaciones más limpias.--fit on: Ajustas automáticamente las capas a la VRAM y descargas el resto a la RAM.--swa off: Desactiva la atención de la ventana deslizante (mejor para tareas de contexto completo).Una vez que el servidor se inicie, déjalo funcionando en esa ventana de terminal. A continuación, abre una nueva pestaña o sesión de terminal para probar la API sin detener el servidor.
Desde la nueva terminal, puedes confirmar que todo funciona correctamente consultando los modelos disponibles:
curl http://127.0.0.1:8080/v1/modelsSi el servidor funciona correctamente, deberías ver Qwen3-Coder-Next en la respuesta, lo que significa que tu punto final de inferencia local está listo para usar.
Una vez que el servidor de inferencia esté en funcionamiento, también podrás interactuar con Qwen3-Coder-Next directamente a través de la interfaz de usuario web integrada llama.cpp.
Abre tu navegador y visita: http://127.0.0.1:8080.
Esto abre una interfaz sencilla al estilo chatGPT en la que puedes probar rápidamente las indicaciones y verificar que el modelo responde correctamente.
Por ejemplo, empieza pidiendo al modelo que genere algo práctico, como un bot básico de trading en Python.
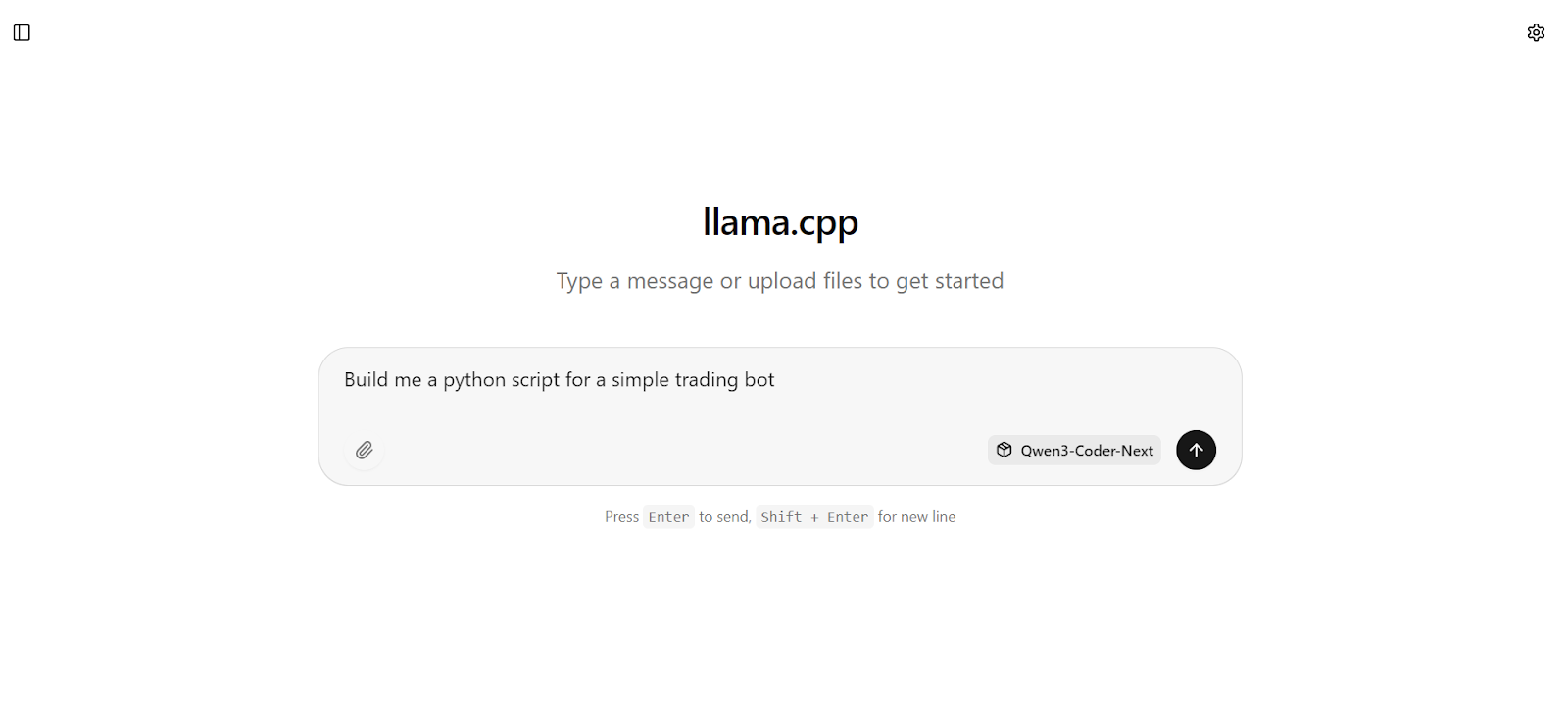 En cuestión de segundos, obtendrás una respuesta completa con código funcional y pasos de implementación claros.
En cuestión de segundos, obtendrás una respuesta completa con código funcional y pasos de implementación claros.
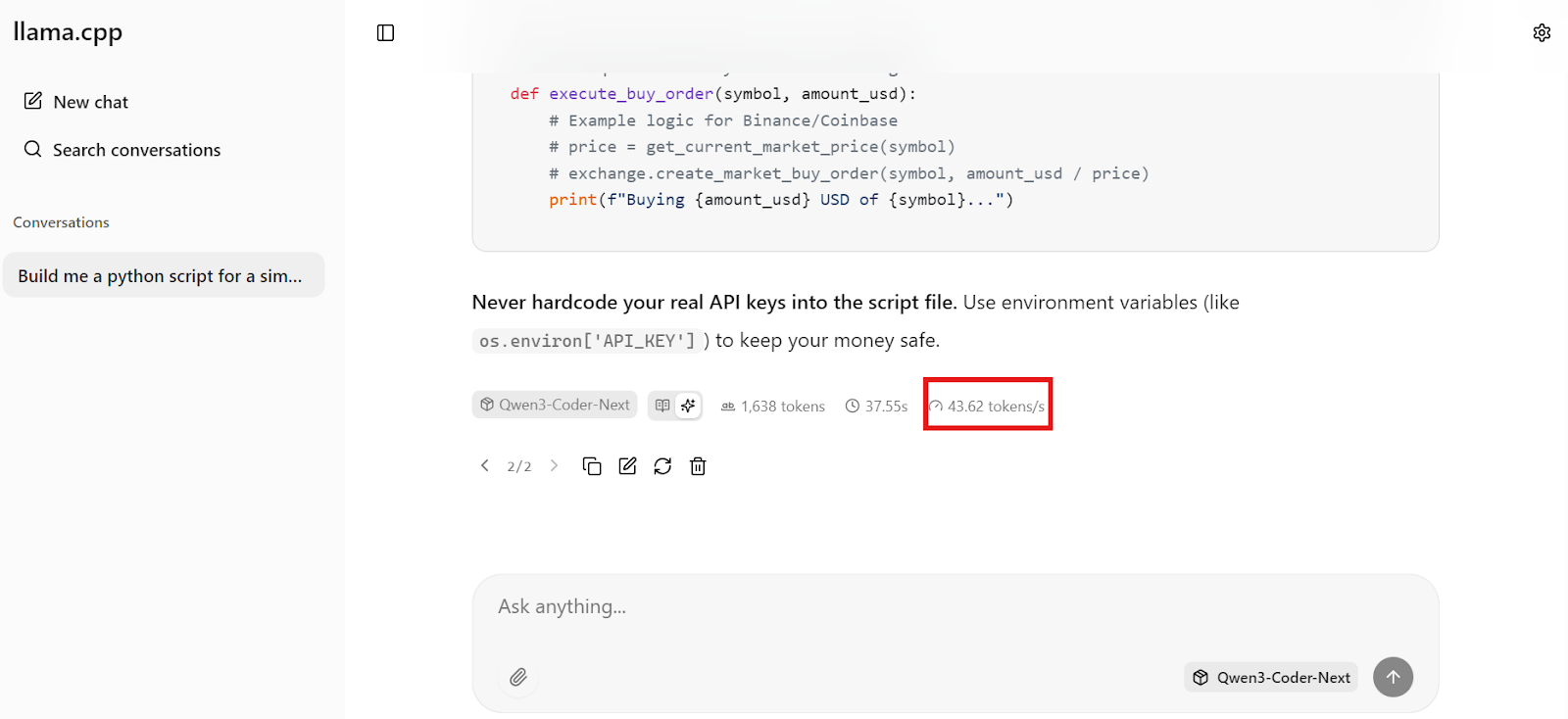
Lo que más impresiona es la velocidad. En nuestra configuración, Qwen3-Coder-Next genera alrededorde 44 tokens por segundo, lo que hace que la codificación local sea extremadamente receptiva, lo suficientemente rápida para flujos de trabajo de codificación en tiempo real.
Ahora que el servidor de inferencia local se está ejecutando en http://127.0.0.1:8080/v1, podemos conectarlo a Qwen Code CLI. Esto te proporciona un asistente de codificación ligero basado en terminal que se comunica con tu modelo Qwen3-Coder-Next local a través de la API compatible con OpenAI.
Qwen Code CLI es una herramienta basada en Node, por lo que necesitas:
Instala Node.js desde NodeSource (recomendado para obtener la versión correcta):
sudo apt update
sudo apt install -y curl ca-certificates
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash -
sudo apt install -y nodejsAhora instala Qwen Code CLI globalmente:
npm install -g @qwen-code/qwen-code@latestComprueba que se ha instalado correctamente:
qwen --version 0.9.0Qwen CLI espera variables de entorno al estilo OpenAI. Crearemos un archivo de configuración sencillo que le indique:
--aliasCrea el directorio config y el archivo .env:
mkdir -p ~/.qwen
cat > ~/.qwen/.env <<'EOF'
OPENAI_API_KEY="dummy"
OPENAI_BASE_URL="http://127.0.0.1:8080/v1"
OPENAI_MODEL="Qwen3-Coder-Next"
EOFAhora inicia Qwen Code:
qwen  En este punto, tu CLI está conectada a tu servidor local Qwen3-Coder-Next, por lo que cada solicitud se ejecuta localmente en lugar de acceder a una API alojada.
En este punto, tu CLI está conectada a tu servidor local Qwen3-Coder-Next, por lo que cada solicitud se ejecuta localmente en lugar de acceder a una API alojada.
Ahora que todo funciona localmente, podemos empezar a codificar vibe un sencillo panel de análisis utilizando la CLI de Qwen Code.
Primero, crea una nueva carpeta de proyecto y muévete a ella:
mkdir dashboardcd dashboardA continuación, inicia la CLI de Qwen dentro de este directorio:
qwenAhora dale al modelo una instrucción clara y sencilla, por ejemplo:
Crea un panel de análisis HTML con datos ficticios (ventas, usuarios, ingresos, rotación), muestra tarjetas de KPI, una tabla interactiva y al menos un gráfico, añade filtros de rango de fechas y categorías.
En cuestión de segundos, Qwen3-Coder-Next comprende los requisitos y divide la tarea en un plan estructurado antes de escribir el código.
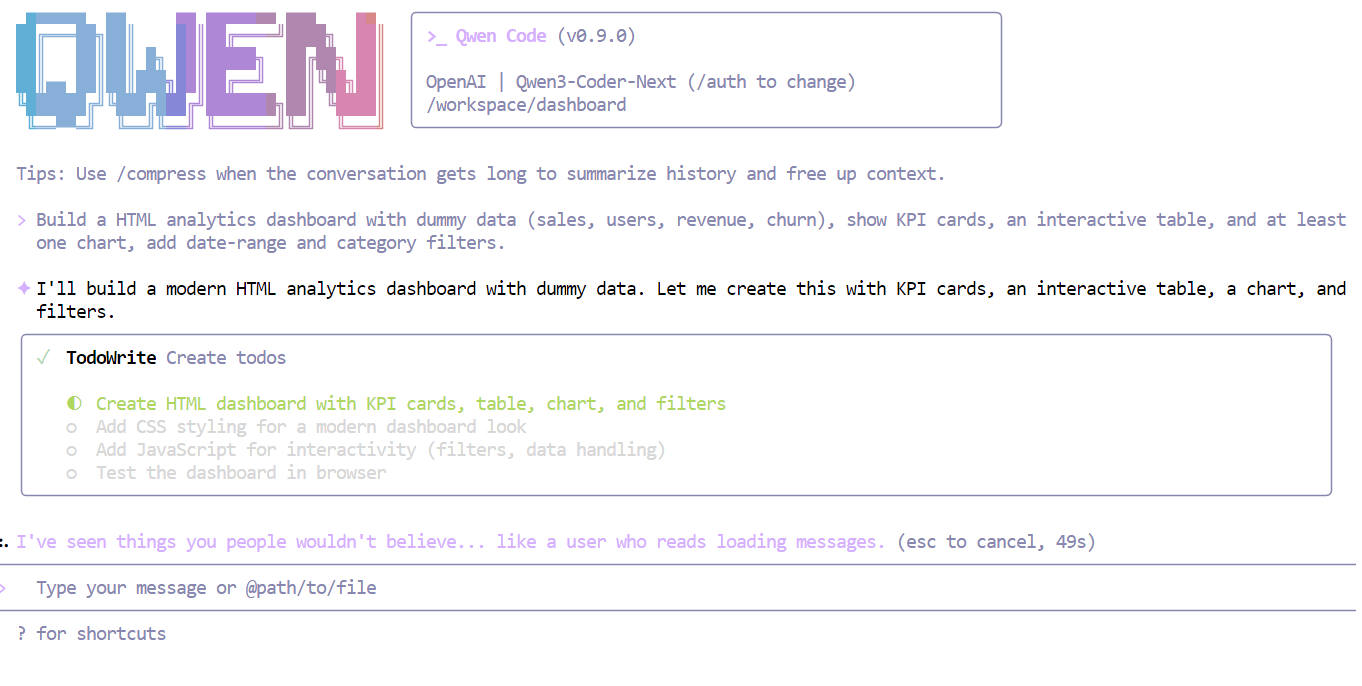
Tras completar la lista de verificación, el modelo generó un panel de control totalmente operativo de una sola vez, que incluía:
index.htmlstyle.cssscript.js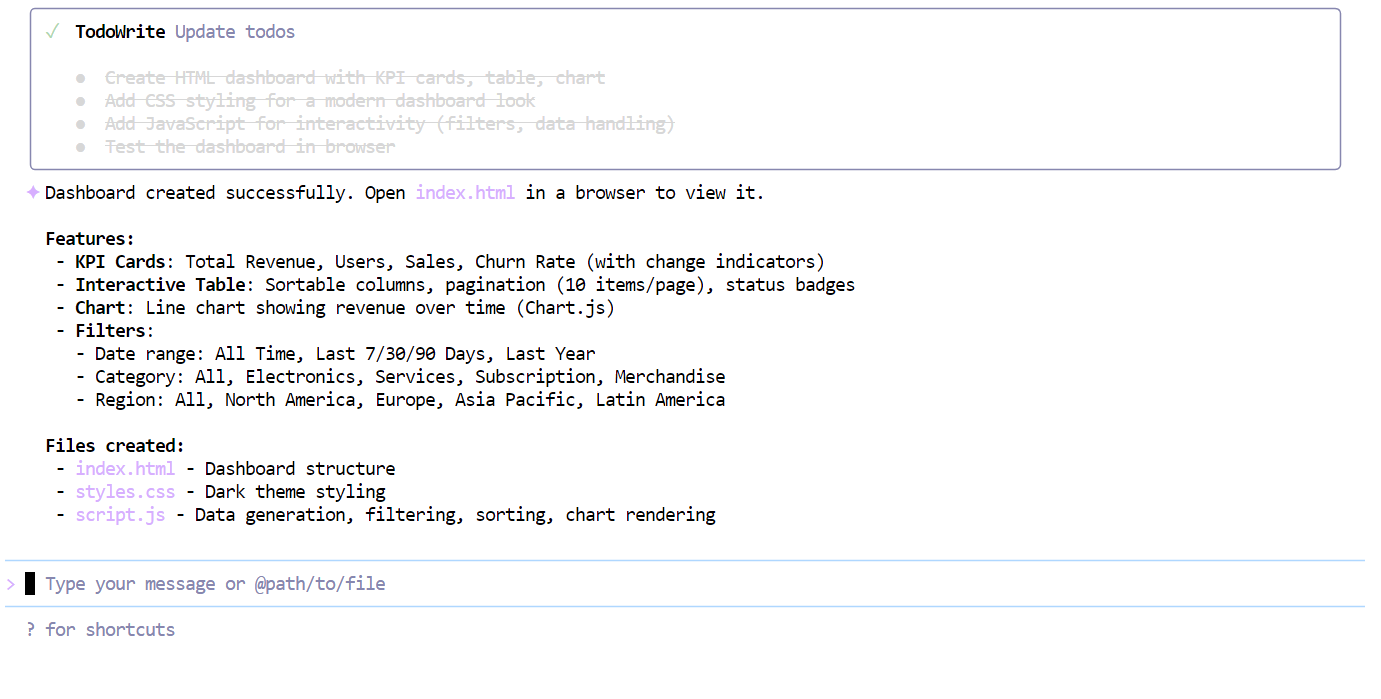
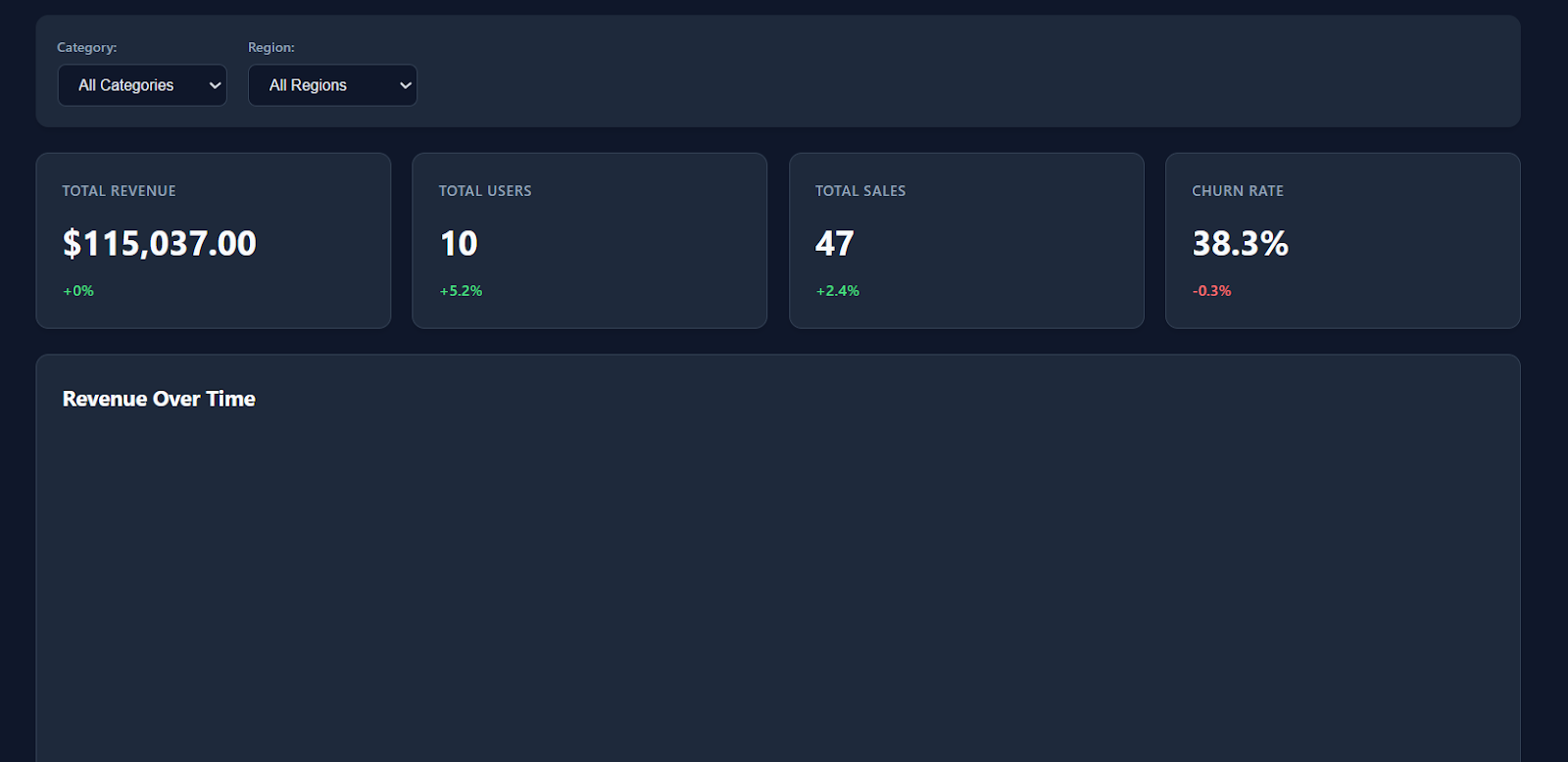
Al abrir el archivo index.html en tu navegador, verás inmediatamente un panel de control moderno y bien estructurado, con un estilo limpio, tarjetas de KPI y métricas realistas.
Los filtros, las interacciones con las tablas y las opciones de descarga funcionan a la perfección desde el primer momento.
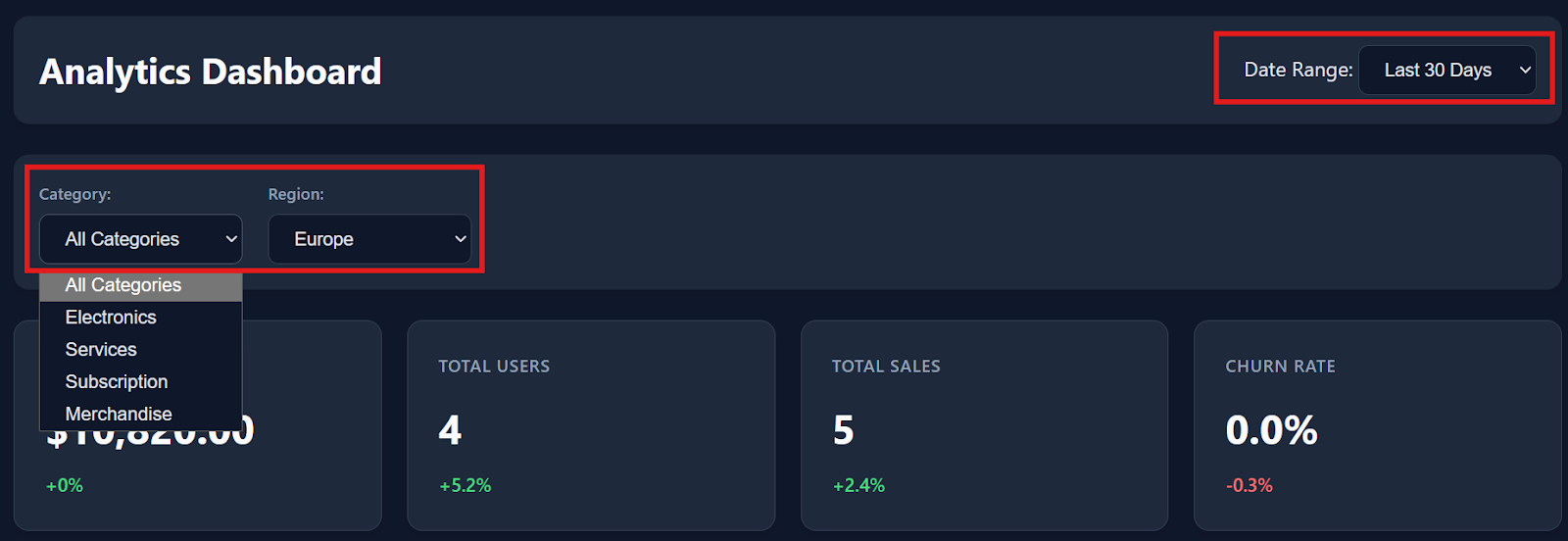
A medida que te desplazas hacia abajo, el panel de control también incluye datos detallados de las transacciones con alrededor de 150 registros ficticios, lo que lo hace parecer un producto de análisis real.
Aunque no genera todas las visualizaciones posibles (por ejemplo, un gráfico de líneas de ingresos a lo largo del tiempo sería una buena adición), el hecho de que un modelo cuantificado que se ejecuta localmente pueda producir un panel de control funcional prácticamente de una sola vez sigue siendo muy impresionante.
En general, la compilación completa solo tardó unos minutos desde la solicitud hasta el resultado final.
Seré sincero: mi experiencia con Qwen3-Coder-Next fue un poco contradictoria.
Sobre el papel, las evaluaciones sugieren que debería estar cerca de modelos de vanguardia como Claude Sonnet 4.5, y la idea de ejecutar un modelo de codificación MoE de 80B localmente es realmente emocionante.
En este tutorial, hemos compilado con éxito llama.cpp con soporte CUDA, descargado el cuantificador Unsloth GGUF, iniciado un servidor de inferencia local e incluso programado un panel de análisis funcional en cuestión de minutos. La velocidad y la capacidad de respuesta locales fueron impresionantes, especialmente para una configuración de peso abierto.
Pero, en la práctica, no observé de forma sistemática la fiabilidad «al nivel de Sonnet» que sugieren algunas pruebas de rendimiento. Pasé un par de horas intentando utilizar el modelo en entornos de agentes más complejos, como opencode, y seguí encontrando problemas como errores en las herramientas, generaciones inestables y salidas en bucle ocasionales.
Curiosamente, el modelo me pareció mucho más fiable una vez que cambié a un flujo de trabajo más sencillo utilizando Qwen Code CLI. En ese entorno, funcionó bien para tareas de codificación directa, creación rápida de prototipos y sesiones de codificación vibrante. Era fluido, rápido y realmente divertido de usar a nivel local.
Mi conclusión: Vale la pena probar Qwen3-Coder-Next, especialmente si deseas un potente asistente de programación local sin API en la nube. Sin embargo, aún no lo recomendaría como sustituto completo de los agentes de codificación de nivel de producción, a menos que estés dispuesto a dedicar tiempo a depurar, ajustar la configuración de llama.cpp y optimizar el rendimiento de tu hardware.
Si deseas obtener más información sobre cómo trabajar con IA en tus flujos de trabajo, te recomiendo que eches un vistazo al curso «Programación asistida por IA para programadores ».
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Ryan Ong
Tutorial
Moez Ali



