
Cours
Concevoir des systèmes agentiques avec LangChain
3 h
12.1K
Qwen3-Coder-Next est un modèle de codage à poids ouvert développé par l'équipe Qwen, conçu pour la programmation agentique et les workflows des développeurs locaux. Il utilise un mélange restreint conception de mélange d'experts pour rester efficace tout en offrant des performances élevées sur les benchmarks modernes de codage et d'utilisation d'outils, avec une prise en charge des contextes longs et des tâches complexes en plusieurs étapes.
Ce qui rend Qwen3-Coder-Next particulièrement intéressant, c'est sa compétitivité par rapport aux meilleurs modèles fermés. Les premières évaluations indiquent qu'il peut atteindre des niveaux de performance proches de ceux de systèmes tels que Claude Sonnet 4.5, tout en restant un système que vous pouvez exécuter localement avec un contrôle total sur votre configuration, votre confidentialité et votre vitesse, sans dépendre d'API hébergées coûteuses.
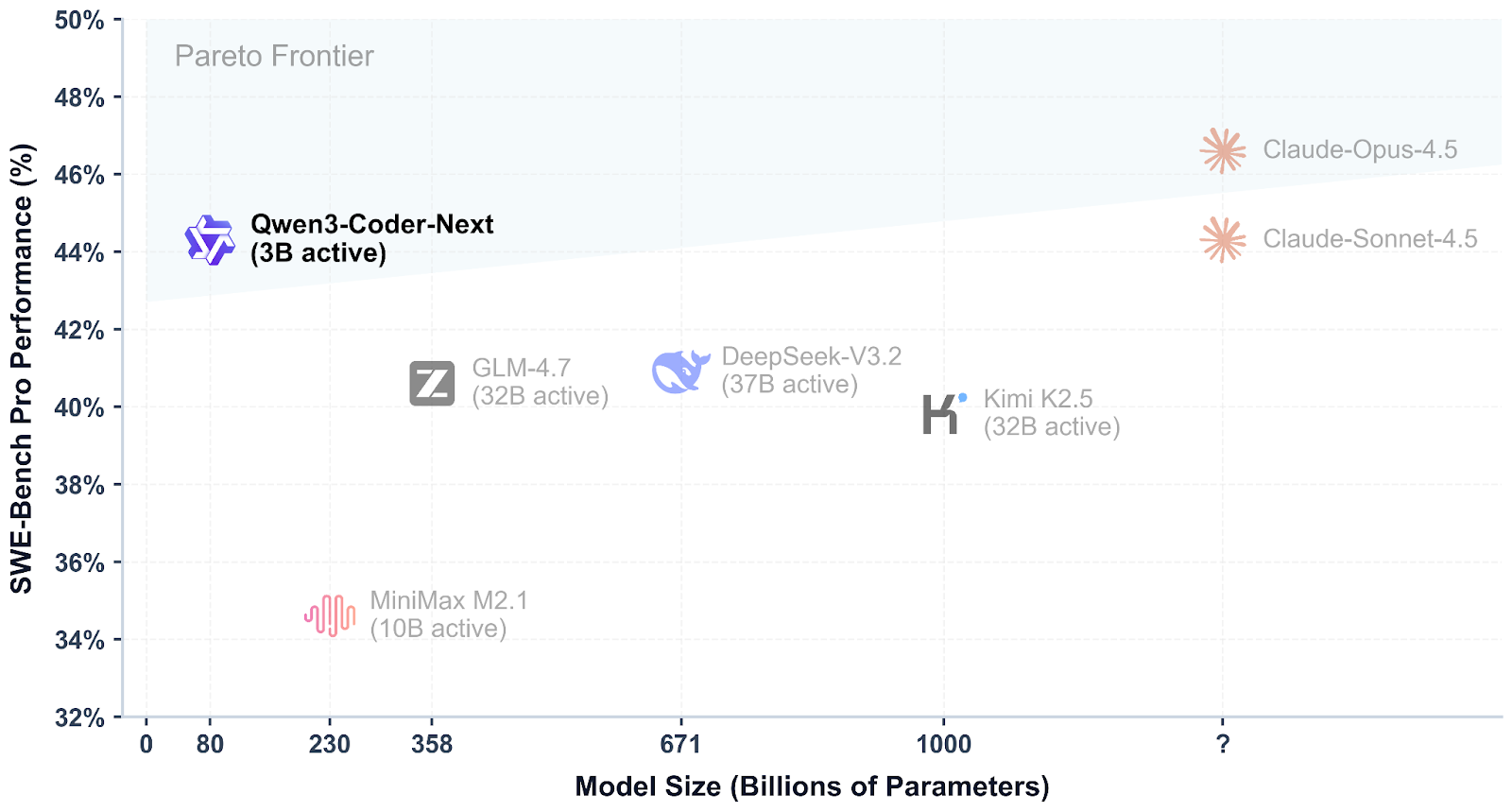
Source : Qwen/Qwen3-Codeur-Suivant
Dans ce tutoriel, nous allons créer llama.cpp à partir du code source, exécuter Qwen3-Coder-Next localement à l'aide du serveur d'inférence llama.cpp, puis le connecter à Qwen Code CLI. Enfin, nous allons coder un tableau de bord simple pour l'analyse des données.
Avant de compiler et d'exécuter Qwen3-Coder-Next localement, vous aurez besoin d'un environnement de développement Linux fonctionnel avec les outils de compilation standard requis pour compiler llama.cpp et exécuter les modèles GGUF.
En plus des paquets système, veuillez vous assurer que vous disposez également des éléments suivants :
Veuillez commencer par mettre à jour votre système et installer les dépendances principales :
sudo apt-get update
sudo apt-get install -y build-essential cmake curl git libcurl4-openssl-devSi vous envisagez d'utiliser l'accélération CUDA, veuillez noter que les cartes graphiques NVIDIA ne sont pas prises en charge. l'accélération CUDA, veuillez vérifier que votre GPU NVIDIA est correctement détecté :
nvidia-smiDans notre cas, nous utilisons une NVIDIA RTX 3090 avec 24 Go de VRAM. Étant donné que Qwen3-Coder-Next nécessite davantage de mémoire pour les quantifications plus importantes, les poids restants du modèle seront automatiquement transférés versla mémoire vive du systèm , ce qui permettra au modèle de continuer à fonctionner localement avec de bonnes performances.
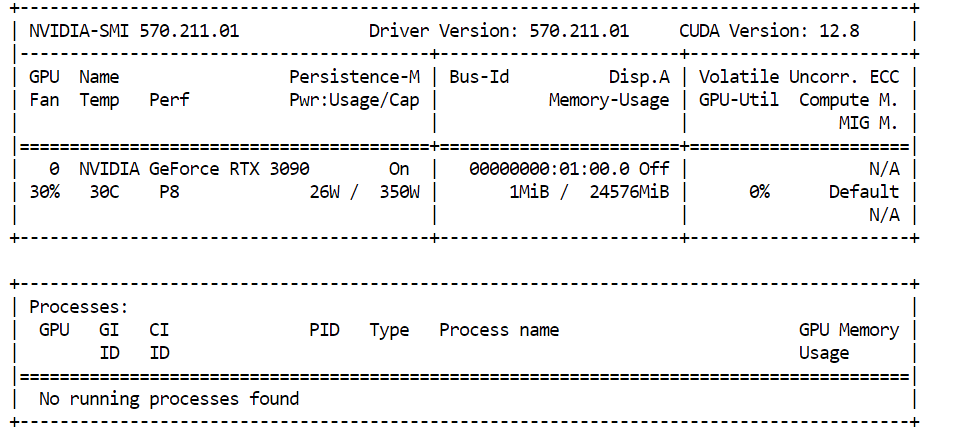
Pour assurer le bon fonctionnement de Qwen3-Coder-Next, votre matériel informatique doit respecter les exigences de mémoire suivantes :
Si vous ne disposez pas de 46 Go d'espace disponible, vous pouvez toujours exécuter des versions quantifiées plus petites (telles que 3 bits).
Une règle empirique simple est la suivante :
Disque + RAM + VRAM ≥ taille quantifiée
Si l'ensemble des quantités tient dans la mémoire, vous pouvez vous attendre à des performances locales rapides. Dans le cas contraire, le modèle continuera de fonctionner par déchargement, mais l'inférence sera plus lente.
Avant d'exécuter Qwen3-Coder-Next localement, il est nécessaire de disposer d'un moteur d'inférence rapide. L'option la plus populaire actuellement est llama.cpp, qui offre une inférence GGUF légère et un serveur local facile à exécuter.
Si vous souhaitez une configuration rapide, llama.cpp propose des binaires précompilés pour macOS, Linux et Windows (y compris des versions compatibles CUDA). Vous pouvez les télécharger directement depuis la page officielle de GitHub : Version b7936 · ggml-org/llama.cpp.
Avec une installation préconfigurée, vous pouvez immédiatement exécuter les outils CLI d' llama.cpp ou démarrer le serveur d'inférence sans avoir à compiler quoi que ce soit vous-même.

Dans ce tutoriel, nous allons compiler manuellement llama.cpp au lieu d'utiliser des binaires précompilés, et ce pour plusieurs raisons importantes :
Commençons par télécharger le code source officiel llama.cpp directement depuis GitHub. Cela garantit que nous travaillons avec la version la plus récente, incluant les dernières améliorations CUDA et corrections de bogues :
git clone https://github.com/ggml-org/llama.cpp
cd llama.cppÀ ce stade, vous devriez vous trouver dans le répertoire llama.cpp, qui contient tous les éléments nécessaires pour créer le projet à partir de zéro.
Ensuite, nous devons configurer le système de compilation à l'aide de CMake. Cette étape génère les fichiers de compilation requis et active l'accélération GPU via CUDA :
cmake /workspace/llama.cpp -B /workspace/llama.cpp/build -DGGML_CUDA=ON -DBUILD_SHARED_LIBS=OFF
Nous allons maintenant compiler le binaire du serveur d'inférence. Il s'agit du composant qui hébergera Qwen3-Coder-Next localement et exposera un point de terminaison API pour les outils de codage et les intégrations CLI :
cmake --build /workspace/llama.cpp/build -j --clean-first --target llama-server
Une fois la compilation terminée, les exécutables compilés sont stockés dans le répertoire build/bin/. Pour faciliter leur exécution directement à partir du dossier principal du projet, vous pouvez les copier de la manière suivante :
cp /workspace/llama.cpp/build/bin/llama-server /workspace/llama.cpp/llama-serverMaintenant que llama.cpp est installé, l'étape suivante consiste à télécharger le modèle Qwen3-Coder-Next GGUF sur Hugging Face.
Avant de commencer, veuillez vous assurer que vous disposez d'une version récente de installation Python récente (>= 3.11), car les outils et utilitaires de transfert Hugging Face en dépendent.
Afin de télécharger efficacement les fichiers GGUF volumineux, nous utiliserons le client Hugging Face Hub ainsi que les backends Xet et transfer à haut débit :
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferEnsuite, veuillez activer le backend de transfert optimisé de Hugging Face :
export HF_HUB_ENABLE_HF_TRANSFER=1Nous pouvons désormais télécharger la versiondynamique GGUF de Qwen3-Coder-Next. Dans ce tutoriel, nous allons spécifiquement récupérer la quantificationUD-Q4_K_XL d' .
Il s'agit d'un excellent choix par défaut, car il offre un excellent compromis entre :
Le format Q4 signifie que le modèle est compressé à une précision de 4 bits. précision de 4 bits, ce qui le rend beaucoup plus léger que les poids FP16 complets tout en conservant une qualité de sortie impressionnante.
hf download unsloth/Qwen3-Coder-Next-GGUF \
--local-dir /workspace/models/qwen3-coder-next \
--include "*UD-Q4_K_XL*"Une fois la commande exécutée, les fichiers du modèle commenceront à être téléchargés dans votre répertoire local.

Sur un réseau haut débit, cela ne prend généralement que quelques minutes. Une fois le téléchargement terminé, le modèle GGUF sera prêt à être chargé dansle serveur llama d' pour une inférence locale.
Une fois le modèle GGUF téléchargé, nous pouvons lancer Qwen3-Coder-Next localement en utilisant le backend d'inférence llama-server. Cela permet de démarrer un serveur API compatible avec OpenAI auquel les outils de codage et les interfaces CLI peuvent se connecter.
Veuillez exécuter la commande suivante :
./llama-server \
--model "/workspace/models/qwen3-coder-next/Qwen3-Coder-Next-UD-Q4_K_XL.gguf" \
--alias "Qwen3-Coder-Next" \
--host 0.0.0.0 \
--port 8080 \
--threads 32 \
--threads-batch 32 \
--ctx-size 20000\
--batch-size 1024\
--ubatch-size 256 \
--jinja \
--flash-attn on \
--temp 0.7 \
--top-p 0.9 \
--min-p 0.05 \
--fit on \
--swa off
Explication des arguments clés :
--model: Chemin d'accès au fichier téléchargé Qwen3-Coder-Next GGUF checkpoint--alias : Nom convivial du modèle affiché dans les clients API--host 0.0.0.0: Expose le serveur sur toutes les interfaces réseau (utile pour l'accès à distance)--port 8080: Exécute l'API d'inférence sur le port 8080--threads 32: Utilise 32 threads CPU pour un débit maximal--threads-batch 32: Parallélise le traitement par lots pour accélérer la génération de jetons.--ctx-size 20000: Définit une fenêtre de contexte étendue (~20 000 jetons) pour les sessions de codage prolongées.--batch-size 1024: Améliore l'utilisation du GPU pendant l'inférence--ubatch-size 256: Contrôle le micro-batching pour des performances plus fluides--jinja: Permet le formatage des modèles de chat requis pour les modèles de type instructionnel.--flash-attn on: Active l'attention flash pour une inférence plus rapide dans un contexte étendu.--temp 0.7: Permet de maintenir des résultats ciblés tout en conservant une approche créative pour le codage d'ambiance.--top-p 0.9: Échantillonnage du noyau pour une diversité équilibrée--min-p 0.05: Filtre les jetons à très faible probabilité pour des complétions plus claires.--fit on: Ajustement automatique des couches dans la mémoire VRAM et transfert du reste dans la mémoire RAM--swa off: Désactive l'attention par fenêtre glissante (plus adapté aux tâches nécessitant un contexte complet)Une fois le serveur démarré, veuillez le laisser fonctionner dans cette fenêtre de terminal. Ensuite,veuillez ouvrir un nouvel onglet ou une nouvelle session de terminal pour tester l'API sans arrêter le serveur.
Depuis le nouveau terminal, vous pouvez vérifier que tout fonctionne correctement en interrogeant les modèles disponibles :
curl http://127.0.0.1:8080/v1/modelsSi le serveur fonctionne correctement, vous devriez voir Qwen3-Coder-Next dans la réponse, ce qui signifie que votre point de terminaison d'inférence local est prêt à être utilisé.
Une fois le serveur d'inférence en cours d'exécution, vous pouvez également interagir directement avec Qwen3-Coder-Next via l'interface utilisateur Web intégrée llama.cpp.
Veuillez ouvrir votre navigateur et vous rendre sur : http://127.0.0.1:8080.
Cela ouvre une interface simple de type chatGPT où vous pouvez rapidement tester des invites et vérifier que le modèle répond correctement.
Par exemple, commencez par demander au modèle de générer quelque chose de pratique, comme un bot de trading Python basique.
 En quelques secondes, vous obtiendrez une réponse complète avec un code fonctionnel et des étapes d'implémentation claires.
En quelques secondes, vous obtiendrez une réponse complète avec un code fonctionnel et des étapes d'implémentation claires.
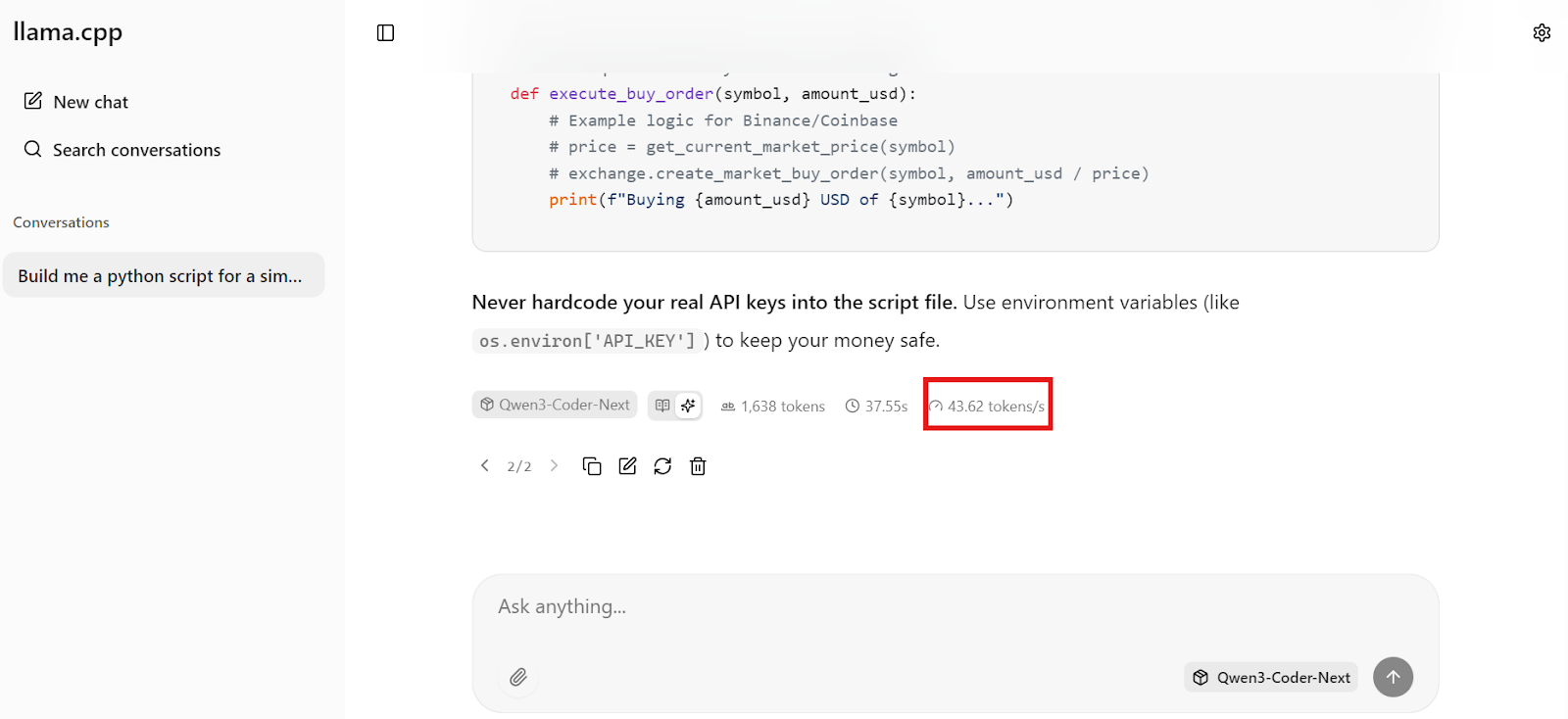
Ce qui est particulièrement remarquable, c'est la rapidité. Sur notre configuration, Qwen3-Coder-Next génère environ 44 jetons par seconde, ce qui rend le codage local extrêmement réactif, suffisamment rapide pour les flux de travail de codage en temps réel.
Maintenant que le serveur d'inférence local fonctionne sur http://127.0.0.1:8080/v1, nous pouvons le connecter à Qwen Code CLI. Vous disposez ainsi d'un assistant de codage léger basé sur un terminal qui communique avec votre modèle Qwen3-Coder-Next local via l'API compatible OpenAI.
Qwen Code CLI est un outil basé sur Node, vous aurez donc besoin de :
Veuillez installer Node.js à partir de NodeSource (recommandé pour obtenir la version appropriée) :
sudo apt update
sudo apt install -y curl ca-certificates
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash -
sudo apt install -y nodejsVeuillez maintenant installer Qwen Code CLI de manière globale :
npm install -g @qwen-code/qwen-code@latestVeuillez vérifier qu'il est correctement installé :
qwen --version 0.9.0Qwen CLI requiert des variables d'environnement de type OpenAI. Nous allons créer un fichier de configuration simple qui lui indique :
--aliasVeuillez créer le répertoire de configuration et le fichier .env:
mkdir -p ~/.qwen
cat > ~/.qwen/.env <<'EOF'
OPENAI_API_KEY="dummy"
OPENAI_BASE_URL="http://127.0.0.1:8080/v1"
OPENAI_MODEL="Qwen3-Coder-Next"
EOFVeuillez maintenant lancer Qwen Code :
qwen  À ce stade, votre CLI est connecté à votre serveur local Qwen3-Coder-Next, de sorte que chaque invite s'exécute localement au lieu de passer par une API hébergée.
À ce stade, votre CLI est connecté à votre serveur local Qwen3-Coder-Next, de sorte que chaque invite s'exécute localement au lieu de passer par une API hébergée.
Maintenant que tout fonctionne localement, nous pouvons commencer le codage de l'ambiance. vibe coding un tableau de bord analytique simple à l'aide de l'interface CLI interface CLI Qwen Code.
Tout d'abord, veuillez créer un nouveau dossier de projet et y accéder :
mkdir dashboardcd dashboardEnsuite, veuillez lancer l'interface CLI Qwen à l'intérieur de ce répertoire :
qwenVeuillez maintenant donner au modèle une instruction claire et simple, par exemple :
Veuillez créer un tableau de bord analytique HTML avec des données fictives (ventes, utilisateurs, revenus, taux de désabonnement), afficher des cartes KPI, un tableau interactif et au moins un graphique, et ajouter des filtres par période et par catégorie.
En quelques secondes, Qwen3-Coder-Next comprend les exigences et décompose la tâche en un plan structuré avant de rédiger le code.
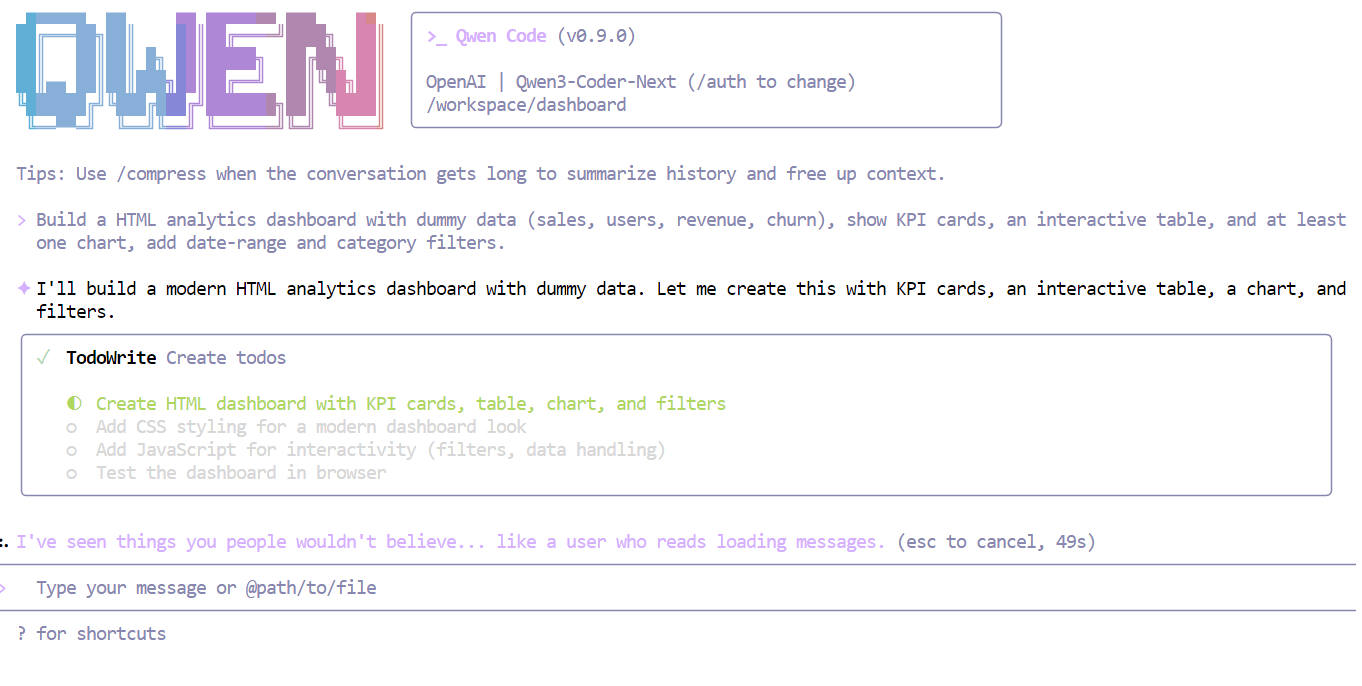
Une fois la liste de contrôle complétée, le modèle a généré en une seule fois un tableau de bord entièrement fonctionnel, comprenant :
index.htmlstyle.cssscript.js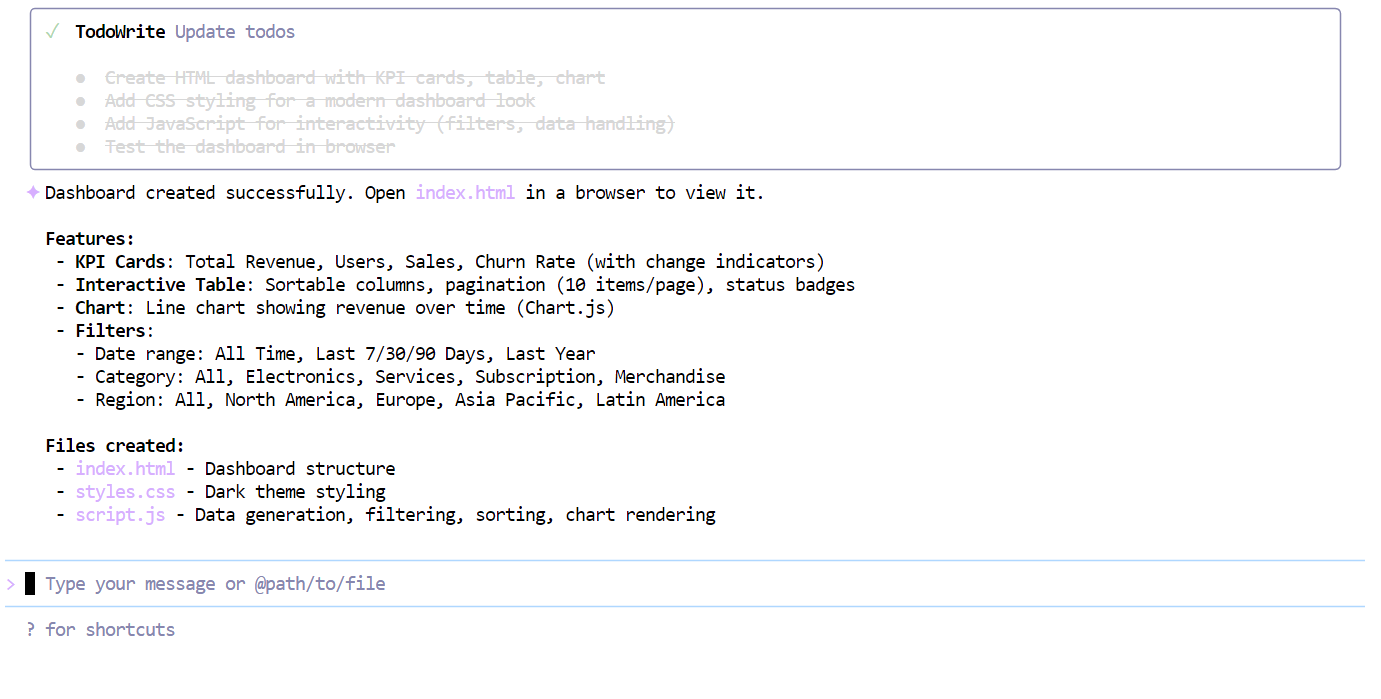
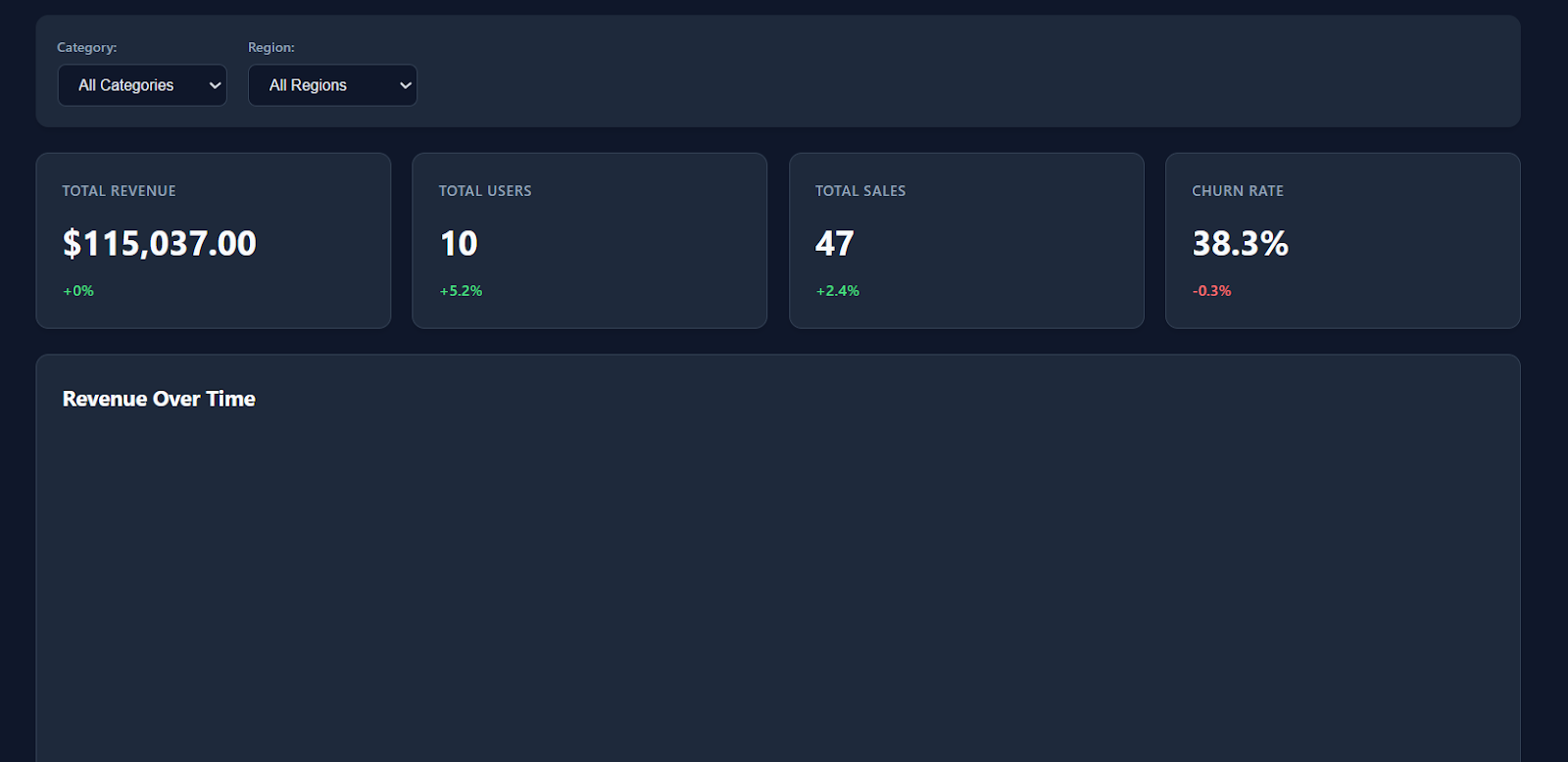
Lorsque vous ouvrez le fichier index.html dans votre navigateur, vous verrez immédiatement apparaître un tableau de bord moderne et bien structuré, avec un style épuré, des cartes KPI et des indicateurs de remplacement réalistes.
Les filtres, les interactions avec les tableaux et les options de téléchargement fonctionnent tous de manière fluide dès leur installation.
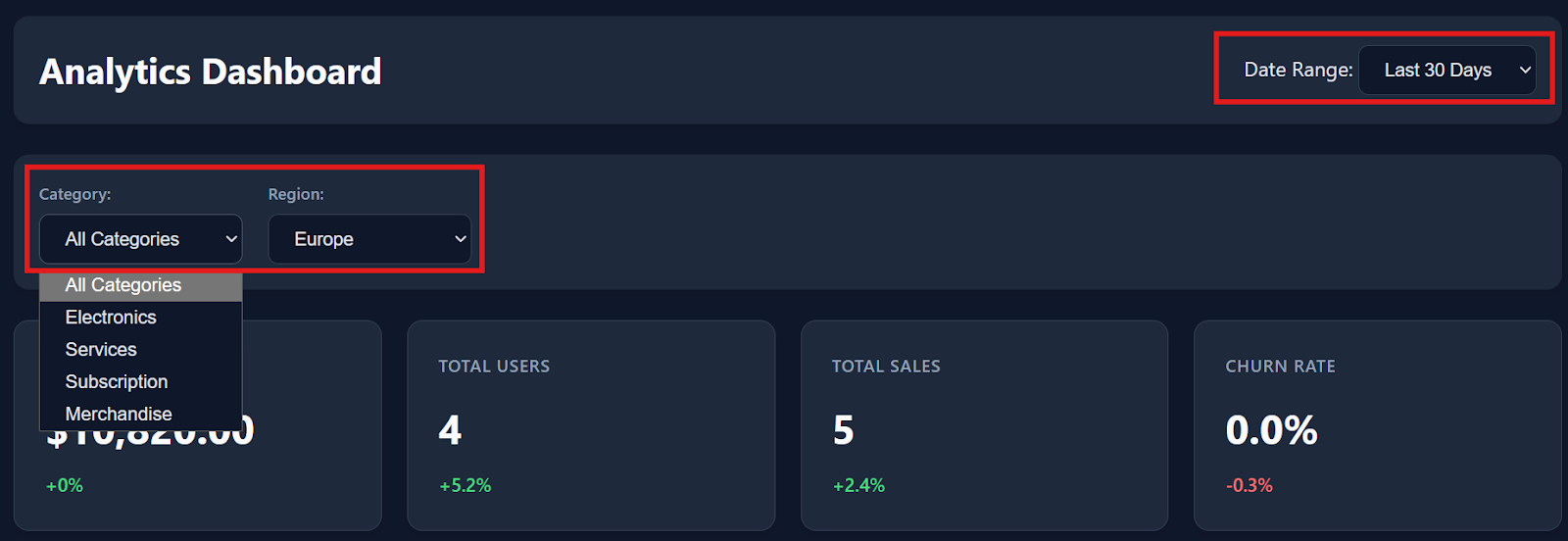
En faisant défiler la page vers le bas, le tableau de bord affiche également des données détaillées sur les transactions, avec environ 150 enregistrements fictifs, ce qui lui donne l'apparence d'un véritable produit d'analyse.
Bien qu'il ne génère pas toutes les visualisations possibles (par exemple, un graphique linéaire représentant l'évolution des revenus dans le temps serait un ajout appréciable), le fait qu'un modèle quantifié fonctionnant localement puisse produire un tableau de bord fonctionnel en une seule fois est tout de même extrêmement impressionnant.
Dans l'ensemble, la construction complète n'a pris que quelques minutes, de la demande à la sortie opérationnelle.
Je serai honnête : mon expérience avec Qwen3-Coder-Next a été quelque peu mitigée.
Sur le papier, les évaluations suggèrent qu'il devrait être proche des modèles de pointe tels que Claude Sonnet 4.5, et l'idée d'exécuter localement un modèle de codage MoE de 80 Go est vraiment passionnante.
Dans ce tutoriel, nous avons réussi à compiler llama.cpp avec le support CUDA, téléchargé le quant Unsloth GGUF, lancé un serveur d'inférence local et même codé en quelques minutes un tableau de bord analytique fonctionnel. La vitesse et la réactivité locales étaient remarquables, en particulier pour une configuration à poids libre.
Cependant, dans la pratique, je n'ai pas constamment observé la fiabilité « de niveau Sonnet » que certains benchmarks suggèrent. J'ai passé plusieurs heures à tenter d'utiliser le modèle dans des environnements d'agents plus complexes telsqu' u opencode, et j'ai rencontré des problèmes tels que des erreurs d'outils, des générations instables et des sorties en boucle occasionnelles.
Il est intéressant de noter que le modèle m'a semblé beaucoup plus fiable lorsque je suis passé à un flux de travail plus simple utilisant Qwen Code CLI. Dans ce contexte, il a démontré une performance satisfaisante pour les tâches de codage direct, le prototypage rapide et les sessions de codage collaboratif. Son utilisation locale s'est avérée fluide, rapide et véritablement agréable.
Ma conclusion : Qwen3-Coder-Next mérite vraiment d'être testé, en particulier si vous recherchez un assistant de codage local performant sans API cloud. Cependant, je ne recommanderais pas encore de le considérer comme un substitut complet aux agents de codage de qualité production, à moins que vous ne soyez prêt à consacrer du temps au débogage, au réglage des paramètres de llama.cpp et à l'optimisation des performances de votre matériel.
Si vous souhaitez en savoir plus sur l'utilisation de l'IA dans vos flux de travail, je vous recommande de suivre le cours « AI-Assisted Coding for Developers » (Codage assisté par l'IA pour les développeurs).
Meilleurs cours DataCamp
Cours
Cours
Cours