
Curso
Projetando Sistemas Agentes com LangChain
3 h
12.1K
O Qwen3-Coder-Next é um modelo de codificação de peso aberto da equipe Qwen, feito pra programação de agentes e fluxos de trabalho de desenvolvedores locais. Ele usa uma mistura esparsa design de mistura de especialistas para manter a eficiência e, ao mesmo tempo, apresentar um forte desempenho em benchmarks modernos de codificação e uso de ferramentas, com suporte para contexto longo e tarefas complexas de várias etapas.
O que torna o Qwen3-Coder-Next especialmente interessante é o quão competitivo ele é em comparação com os melhores modelos fechados. As primeiras avaliações mostram que ele pode atingir níveis de desempenho próximos aos de sistemas como o Claude Sonnet 4.5, mas ainda assim é algo que você pode rodar localmente com controle total sobre sua configuração, privacidade e velocidade, sem depender de APIs hospedadas caras.
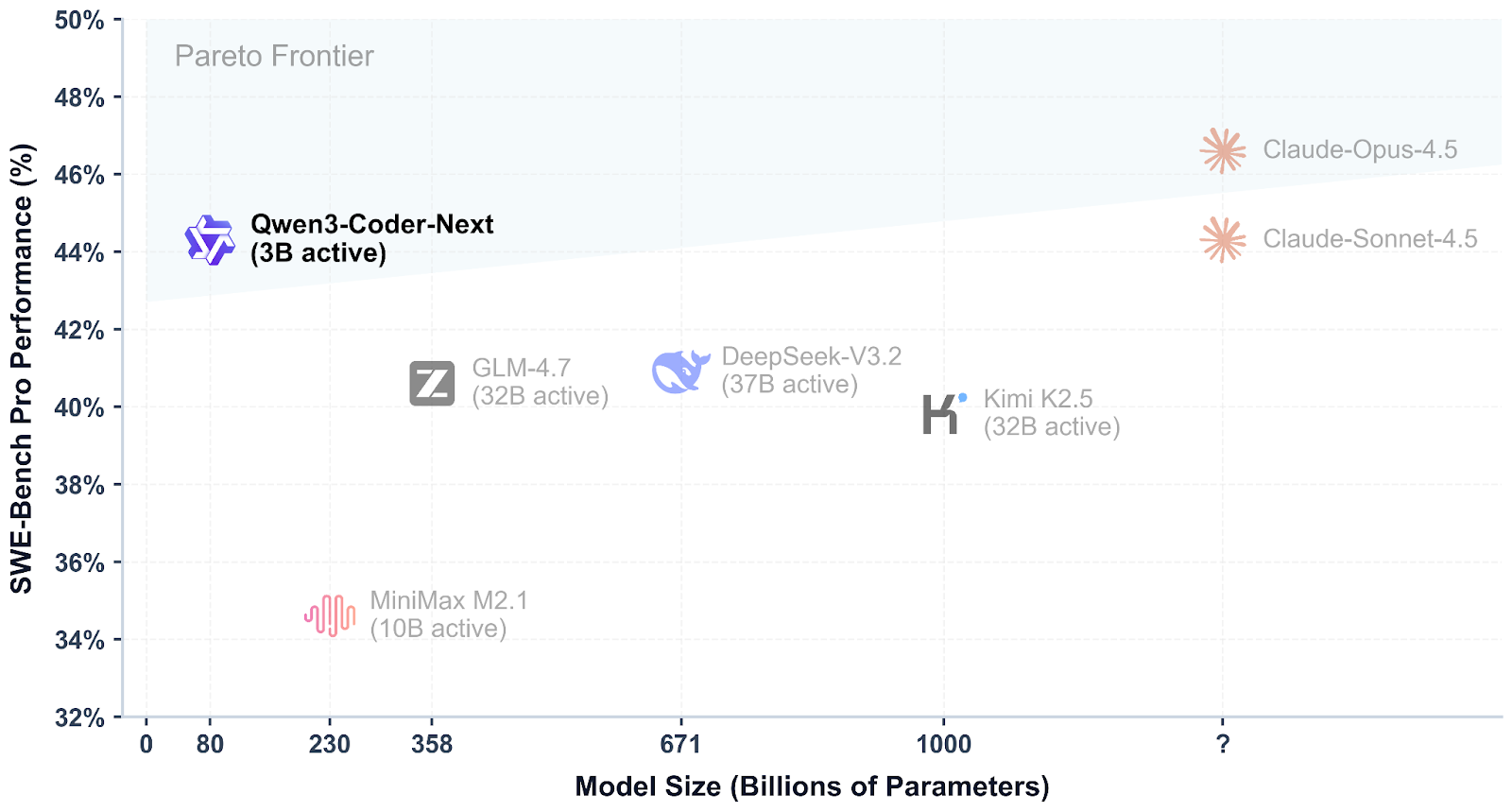
Fonte: Qwen/Qwen3-Codificador-Próximo
Neste tutorial, vamos criar llama.cpp a partir do código-fonte, vamos rodar o Qwen3-Coder-Next localmente usando o servidor de inferência llama.cpp e, em seguida, conectá-lo ao Qwen Code CLI. Por fim, vamos programar um painel simples de análise de dados.
Antes de compilar e executar o Qwen3-Coder-Next localmente, você vai precisar de uma configuração de desenvolvimento Linux funcional com as ferramentas de compilação padrão necessárias para compilar llama.cpp e executar modelos GGUF.
Além dos pacotes do sistema, certifique-se de que você também tem:
Comece atualizando seu sistema e instalando as dependências principais:
sudo apt-get update
sudo apt-get install -y build-essential cmake curl git libcurl4-openssl-devSe você planeja usar aceleração CUDA, confira se sua GPU NVIDIA foi detectada corretamente:
nvidia-smiNo nosso caso, estamos usando uma NVIDIA RTX 3090 com 24 GB de VRAM. Como o Qwen3-Coder-Next precisa de mais memória do que a necessária para quantizações maiores, os pesos restantes do modelo serão automaticamente transferidos paraa RAM do sistem , permitindo que o modelo continue a funcionar localmente com bom desempenho.
Para rodar o Qwen3-Coder-Next sem problemas, seu hardware deve ter mais ou menos essa quantidade de memória:
Se você não tiver 46 GB disponíveis, ainda pode usar versões quantizadas menores (como 3 bits).
Uma regra simples é:
Disco + RAM + VRAM ≥ tamanho do quantum
Se todo o quant couber na memória, você pode esperar um desempenho local rápido. Caso contrário, o modelo continuará funcionando por meio do offloading, mas a inferência será mais lenta.
Antes de rodar o Qwen3-Coder-Next localmente, precisamos de um mecanismo de inferência rápido. A opção mais popular hoje em dia é llama.cpp, que oferece inferência GGUF leve e um servidor local fácil de usar.
Se você quer uma configuração rápida, o llama.cpp oferece binários pré-compilados para macOS, Linux e Windows (incluindo compilações habilitadas para CUDA). Você pode baixá-los diretamente da página oficial de lançamento do GitHub: Lançamento b7936 · ggml-org/llama.cpp.
Com uma instalação pré-construída, você pode executar imediatamente as ferramentas CLI do llama.cpp ou iniciar o servidor de inferência sem precisar compilar nada.

Neste tutorial, vamos compilar o llama.cpp manualmente, em vez de usar binários pré-compilados, por alguns motivos importantes:
Vamos começar baixando o código-fonte oficial llama.cpp direto do GitHub. Isso garante que estamos trabalhando com a versão mais recente, incluindo as últimas melhorias e correções de bugs do CUDA:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cppNeste ponto, você deve estar dentro do diretório llama.cpp, que tem tudo que precisa para construir o projeto do zero.
Depois, precisamos configurar o sistema de compilação usando o CMake. Essa etapa gera os arquivos de compilação necessários e permite a aceleração da GPU por meio do CUDA:
cmake /workspace/llama.cpp -B /workspace/llama.cpp/build -DGGML_CUDA=ON -DBUILD_SHARED_LIBS=OFF
Agora vamos compilar o binário do servidor de inferência. Esse é o componente que vai hospedar o Qwen3-Coder-Next localmente e disponibilizar um endpoint de API para ferramentas de codificação e integrações CLI:
cmake --build /workspace/llama.cpp/build -j --clean-first --target llama-server
Depois que a compilação terminar, os executáveis compilados vão ficar guardados na pasta build/bin/. Para facilitar a execução diretamente da pasta principal do projeto, você pode copiá-los assim:
cp /workspace/llama.cpp/build/bin/llama-server /workspace/llama.cpp/llama-serverAgora que o llama.cpp está instalado, o próximo passo é baixar o modelo Qwen3-Coder-Next GGUF do Hugging Face.
Antes de começar, certifique-se de ter uma instalação recente do Python recente (>= 3.11), já que as ferramentas e utilitários de transferência do Hugging Face dependem dela.
Para baixar arquivos GGUF grandes de forma eficiente, vamos usar o cliente Hugging Face Hub junto com os backends de alta velocidade Xet e transfer:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferDepois, habilite o backend de transferência otimizado do Hugging Face:
export HF_HUB_ENABLE_HF_TRANSFER=1Agora podemos baixar a versãodinâmica Unsloth GGUF do Qwen3-Coder-Next. Neste tutorial, vamos buscar especificamente a quantizaçãoUD-Q4_K_XL do .
Essa é uma ótima escolha padrão, porque oferece um excelente equilíbrio entre:
O formato Q4 significa que o modelo é compactado para precisão de 4 bits, tornando-o muito mais leve do que pesos FP16 completos, mas mantendo uma qualidade de saída impressionante.
hf download unsloth/Qwen3-Coder-Next-GGUF \
--local-dir /workspace/models/qwen3-coder-next \
--include "*UD-Q4_K_XL*"Assim que o comando for executado, os arquivos do modelo começarão a ser baixados para o seu diretório local.

Em uma rede de alta velocidade, isso normalmente leva apenas alguns minutos. Depois que o download terminar, você vai ter o modelo GGUF pronto pra carregar numservidor llama d pra fazer inferência local.
Depois de baixar o modelo GGUF, dá pra abrir o Qwen3-Coder-Next localmente usando o backend de inferência llama-server. Isso inicia um servidor API compatível com OpenAI ao qual ferramentas de codificação e CLIs podem se conectar.
Execute o seguinte comando:
./llama-server \
--model "/workspace/models/qwen3-coder-next/Qwen3-Coder-Next-UD-Q4_K_XL.gguf" \
--alias "Qwen3-Coder-Next" \
--host 0.0.0.0 \
--port 8080 \
--threads 32 \
--threads-batch 32 \
--ctx-size 20000\
--batch-size 1024\
--ubatch-size 256 \
--jinja \
--flash-attn on \
--temp 0.7 \
--top-p 0.9 \
--min-p 0.05 \
--fit on \
--swa off
Explicação dos principais argumentos:
--model: Caminho para o arquivo baixado Qwen3-Coder-Next GGUF checkpoint--alias: Nome amigável do modelo mostrado nos clientes API--host 0.0.0.0: Exibe o servidor em todas as interfaces de rede (útil para acesso remoto)--port 8080: Executa a API de inferência na porta 8080--threads 32: Usa 32 threads da CPU para obter o máximo rendimento--threads-batch 32: Faz o processamento em lote em paralelo pra gerar tokens mais rápido--ctx-size 20000: Define uma janela de contexto grande (~20 mil tokens) para sessões longas de codificação--batch-size 1024: Melhora a utilização da GPU durante a inferência--ubatch-size 256: Controla o micro-batching para um desempenho mais suave--jinja: Permite a formatação de modelos de chat necessária para modelos do tipo instrucional.--flash-attn on: Ativa o Flash Attention para uma inferência mais rápida em contextos longos--temp 0.7: Mantém os resultados focados, mas ainda criativos para a codificação de vibrações--top-p 0.9: Amostragem do núcleo para diversidade equilibrada--min-p 0.05: Filtra tokens com probabilidade super baixa para conclusões mais limpas--fit on: Ajusta automaticamente as camadas na VRAM e descarrega o restante na RAM--swa off: Desativa a atenção da janela deslizante (melhor para tarefas que exigem todo o contexto)Depois que o servidor começar, deixe-o funcionando nessa janela do terminal. Então, abra uma nova aba ou sessão do terminal para testar a API sem parar o servidor.
No novo terminal, você pode conferir se tudo está funcionando bem perguntando quais modelos estão disponíveis:
curl http://127.0.0.1:8080/v1/modelsSe o servidor estiver funcionando direitinho, você deve ver Qwen3-Coder-Next na resposta, o que significa que seu endpoint de inferência local está pronto para uso.
Quando o servidor de inferência estiver funcionando, você também pode interagir com o Qwen3-Coder-Next direto pela interface da web integrada llama.cpp.
Abra o seu navegador e vá até: http://127.0.0.1:8080.
Isso abre uma interface simples, tipo o chatGPT, onde você pode testar rapidamente os prompts e ver se o modelo está respondendo direitinho.
Por exemplo, comece pedindo ao modelo para criar algo prático, como um bot básico de negociação em Python.
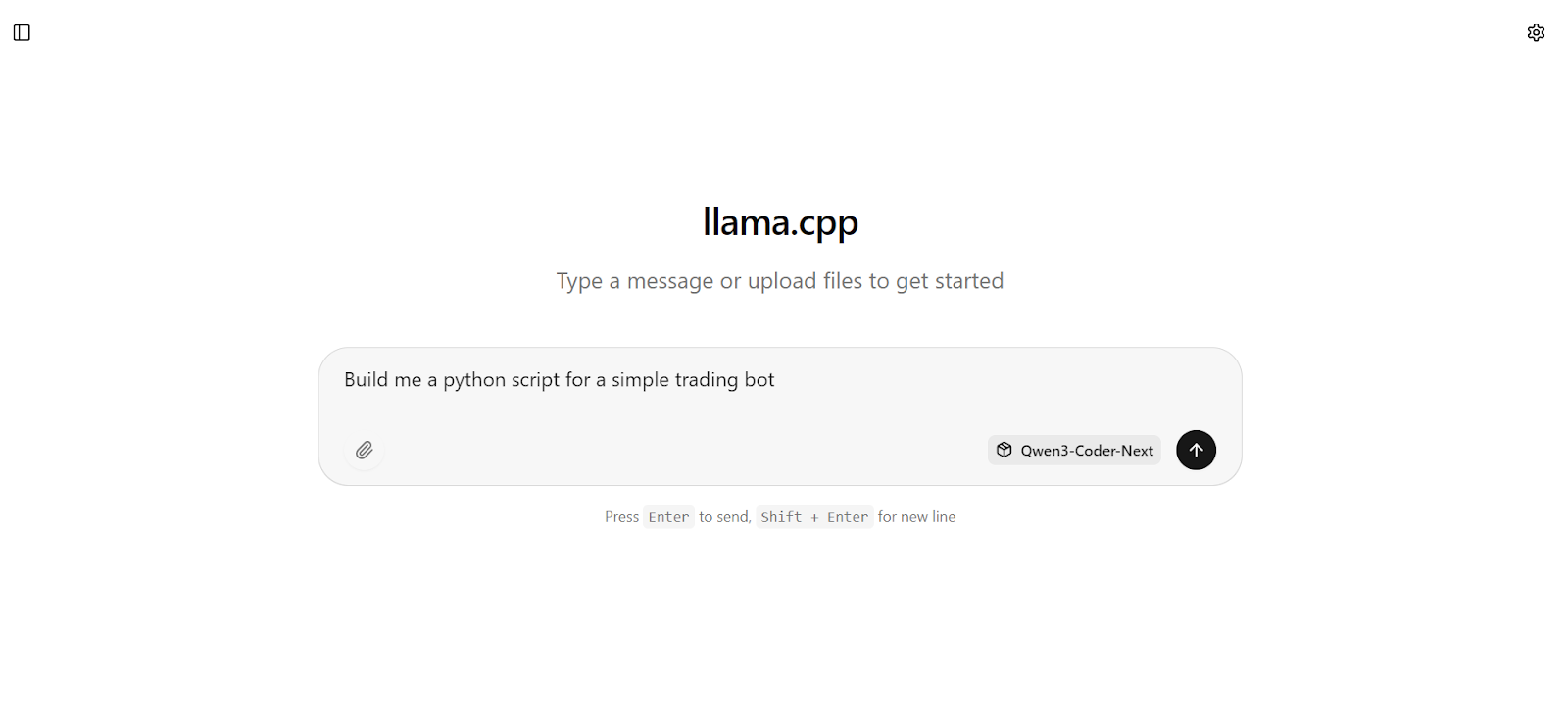 Em segundos, você vai receber uma resposta completa com código funcional e etapas de implementação claras.
Em segundos, você vai receber uma resposta completa com código funcional e etapas de implementação claras.
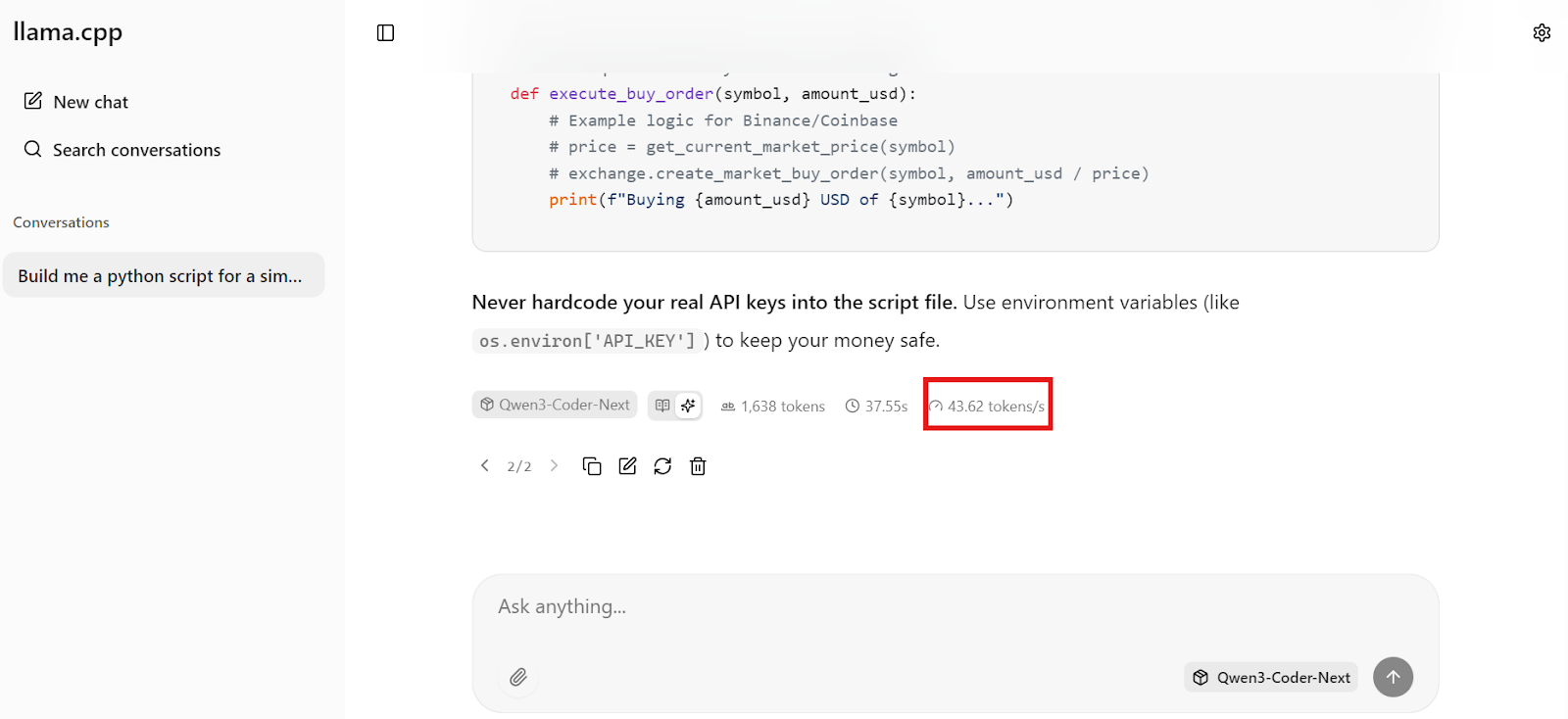
O que é mais impressionante é a velocidade. Na nossa configuração, o Qwen3-Coder-Next está gerando cerca de 44 tokens por segundo, o que torna a codificação local extremamente responsiva, rápida o suficiente para fluxos de trabalho de codificação em tempo real.
Agora que o servidor de inferência local está funcionando em http://127.0.0.1:8080/v1, podemos conectá-lo ao CLI do Qwen Code. Isso te dá um assistente de codificação leve baseado em terminal que se comunica com o seu modelo Qwen3-Coder-Next local por meio da API compatível com OpenAI.
O Qwen Code CLI é uma ferramenta baseada em Node, então você precisa de:
Instale o Node.js a partir do NodeSource (recomendado para obter a versão correta):
sudo apt update
sudo apt install -y curl ca-certificates
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash -
sudo apt install -y nodejsAgora instale o Qwen Code CLI globalmente:
npm install -g @qwen-code/qwen-code@latestConfira se instalou direitinho:
qwen --version 0.9.0O Qwen CLI espera variáveis de ambiente no estilo OpenAI. Vamos criar um arquivo de configuração simples que diga isso:
--aliasCrie o diretório config e o arquivo .env:
mkdir -p ~/.qwen
cat > ~/.qwen/.env <<'EOF'
OPENAI_API_KEY="dummy"
OPENAI_BASE_URL="http://127.0.0.1:8080/v1"
OPENAI_MODEL="Qwen3-Coder-Next"
EOFAgora, abra o Qwen Code:
qwen  Neste ponto, sua CLI está conectada ao seu servidor local Qwen3-Coder-Next, então cada prompt está sendo executado localmente, em vez de acessar uma API hospedada.
Neste ponto, sua CLI está conectada ao seu servidor local Qwen3-Coder-Next, então cada prompt está sendo executado localmente, em vez de acessar uma API hospedada.
Agora que tudo está funcionando localmente, podemos começar a codificar o vibe um painel de análise simples usando o CLI do Qwen Code.
Primeiro, crie uma nova pasta de projeto e vá até ela:
mkdir dashboardcd dashboardDepois, abra o Qwen CLI dentro desse diretório:
qwenAgora, dá ao modelo uma instrução clara e simples, por exemplo:
Crie um painel de análise HTML com dados fictícios (vendas, usuários, receita, rotatividade), mostre cartões de KPI, uma tabela interativa e pelo menos um gráfico, adicione filtros de intervalo de datas e categorias.
Em segundos, o Qwen3-Coder-Next entende os requisitos e divide a tarefa em um plano estruturado antes de escrever o código.
Depois de preencher a lista de verificação, o modelo criou um painel de controle completo de uma vez só, incluindo:
index.htmlstyle.cssscript.js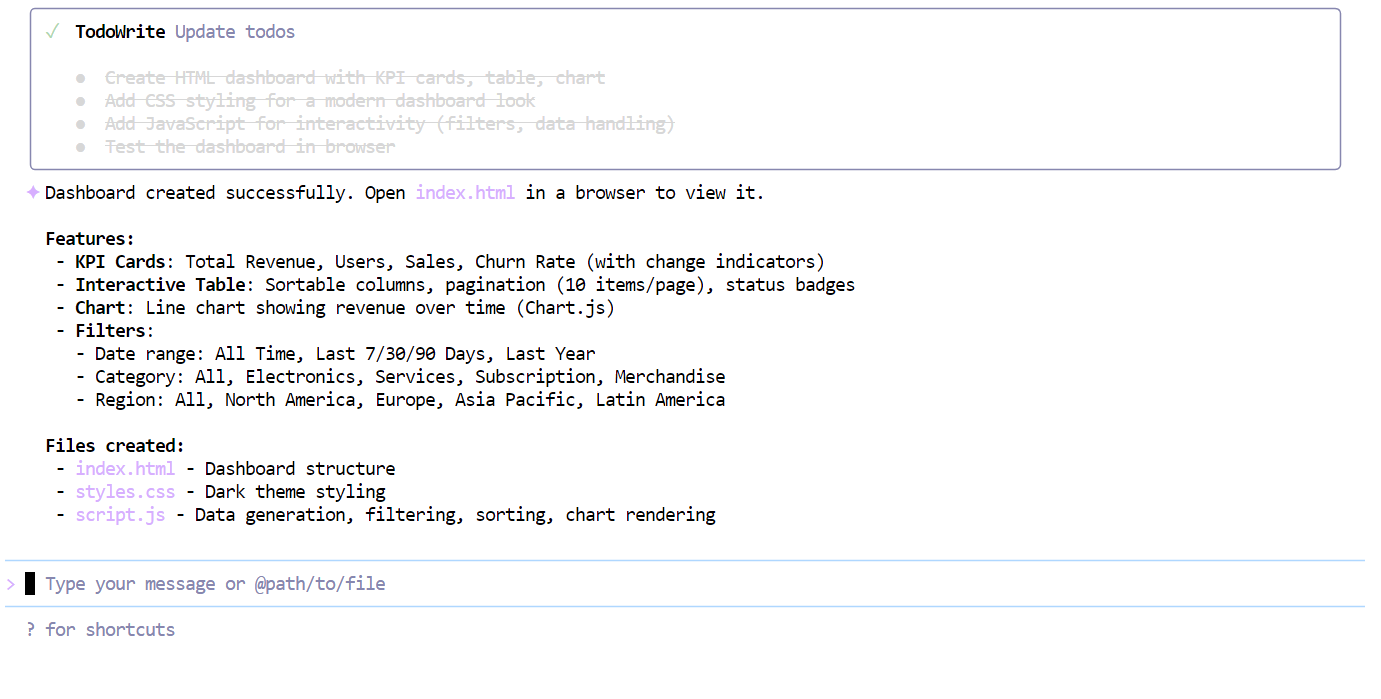
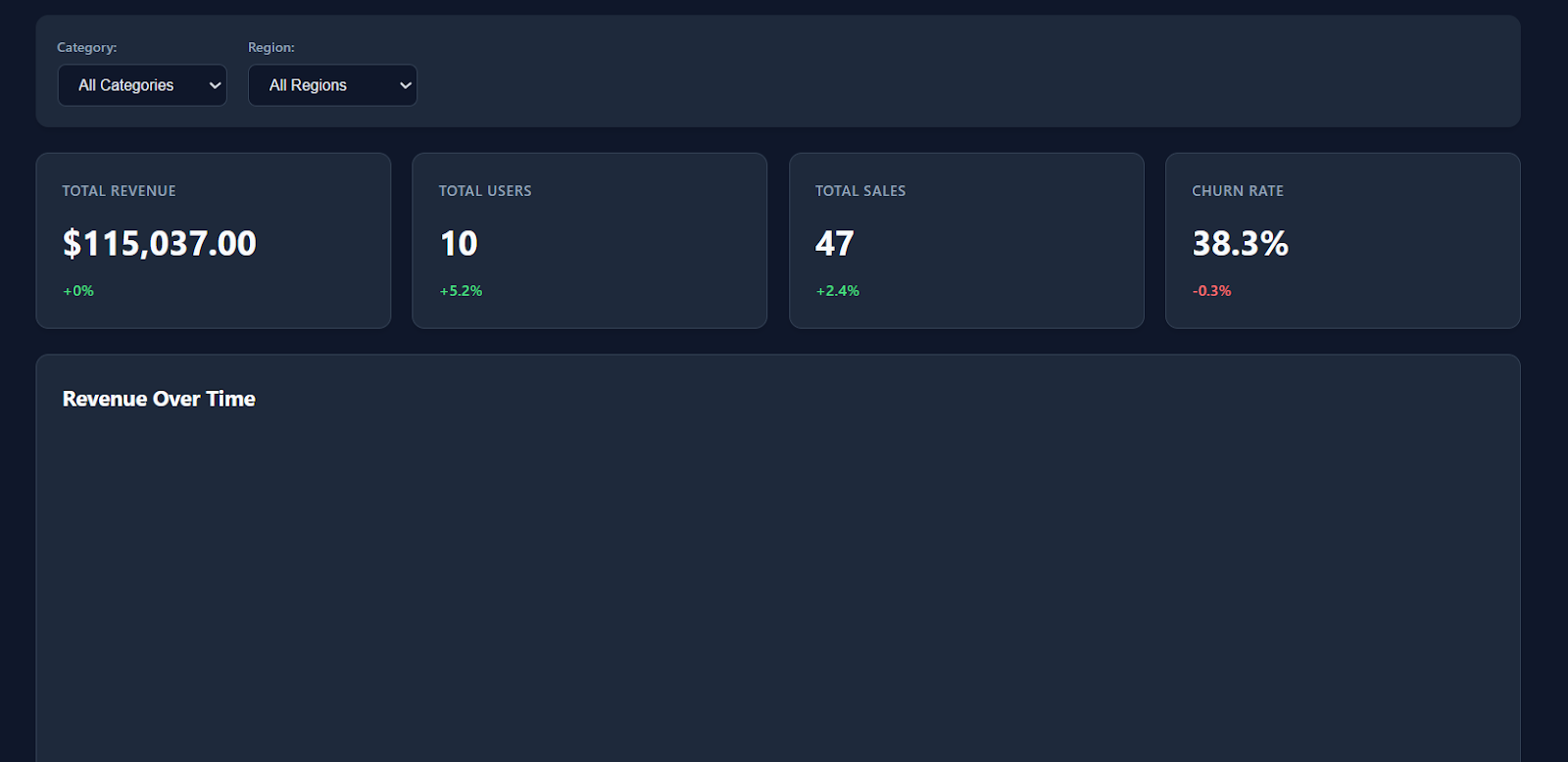
Quando você abrir o arquivo index.html no seu navegador, vai ver logo um painel moderno e bem organizado, com um estilo simples, cartões de KPI e métricas realistas.
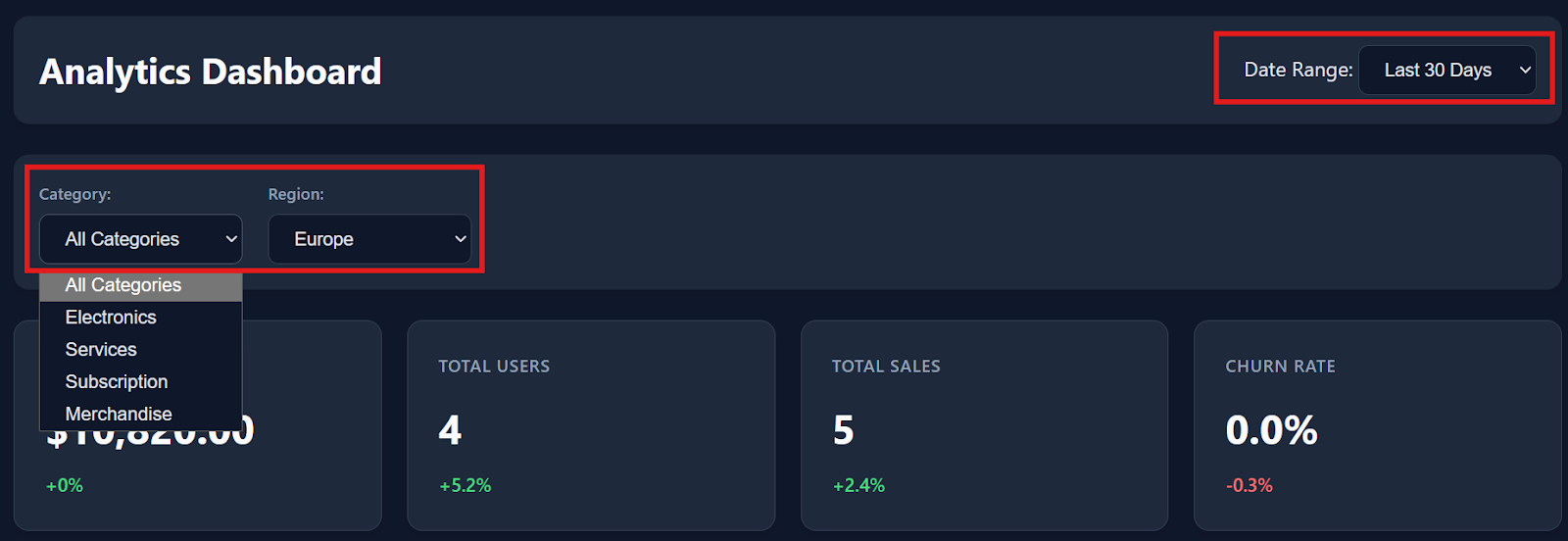
Os filtros, as interações com a tabela e as opções de download funcionam perfeitamente assim que você começa a usar.
Conforme você rola a tela para baixo, o painel também mostra dados detalhados das transações, com cerca de 150 registros fictícios, fazendo com que pareça um produto de análise real.
Embora não gere todas as visualizações possíveis (por exemplo, um gráfico de linha de receita ao longo do tempo seria uma boa adição), o fato de um modelo quantizado executado localmente poder produzir um painel funcional basicamente de uma só vez ainda é super impressionante.
No geral, a compilação toda levou só alguns minutos, desde o comando até o resultado final.
Vou ser sincero: minha experiência com o Qwen3-Coder-Next foi meio mista.
No papel, as avaliações sugerem que ele deve estar próximo de modelos de ponta, como o Claude Sonnet 4.5, e a ideia de executar um modelo de codificação MoE de 80B localmente é realmente empolgante.
Neste tutorial, a gente conseguiu compilar o llama.cpp com suporte a CUDA, baixou o quant Unsloth GGUF, iniciou um servidor de inferência local e até criou um painel de análise funcional em poucos minutos. A velocidade e a capacidade de resposta locais foram impressionantes, especialmente para uma configuração de peso aberto.
Mas, na prática, não vi sempre a confiabilidade “nível Sonnet” que alguns benchmarks sugerem. Passei algumas horas tentando usar o modelo em ambientes de agentes mais complexos, comoo código aberto , e sempre me deparei com problemas como erros de ferramentas, gerações instáveis e saídas em loop ocasionais.
Curiosamente, o modelo pareceu muito mais confiável depois que mudei para um fluxo de trabalho mais simples usando o Qwen Code CLI. Nesse cenário, ele se saiu bem em tarefas de codificação direta, prototipagem rápida e sessões de codificação vibrante. Foi tranquilo, rápido e realmente divertido de usar localmente.
Minha conclusão: Vale muito a pena experimentar o Qwen3-Coder-Next, principalmente se você quer um assistente de codificação local poderoso sem APIs na nuvem. Mas eu ainda não recomendaria isso como um substituto completo para agentes de codificação de nível de produção, a menos que você esteja pronto para gastar tempo depurando, ajustando as configurações do llama.cpp e otimizando o desempenho do seu hardware.
Se você quiser saber mais sobre como usar IA nos seus fluxos de trabalho, recomendo dar uma olhada no curso Codificação Assistida por IA para Desenvolvedores.
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan



