
Kurs
Agentische Systeme mit LangChain entwerfen
3 Std.
12.1K
Qwen3-Coder-Next ist ein offenes Codierungsmodell vom Qwen-Team, das für agentenbasierte Programmierung und lokale Entwickler-Workflows entwickelt wurde. Es nutzt eine spärliche Mix-of-Experts-Design Design, um effizient zu bleiben und trotzdem bei modernen Codierungs- und Tool-Nutzungs-Benchmarks gut abzuschneiden, mit Unterstützung für lange Kontexte und komplexe mehrstufige Aufgaben.
Was Qwen3-Coder-Next so spannend macht, ist, wie gut es im Vergleich zu den besten Closed-Modellen abschneidet. Erste Tests zeigen, dass es fast so gut wie Systeme wie Claude Sonnet 4.5, während es trotzdem lokal mit voller Kontrolle über die Konfiguration, Privatsphäre und Geschwindigkeit betrieben werden kann, ohne dass man auf teure gehostete APIs angewiesen ist.
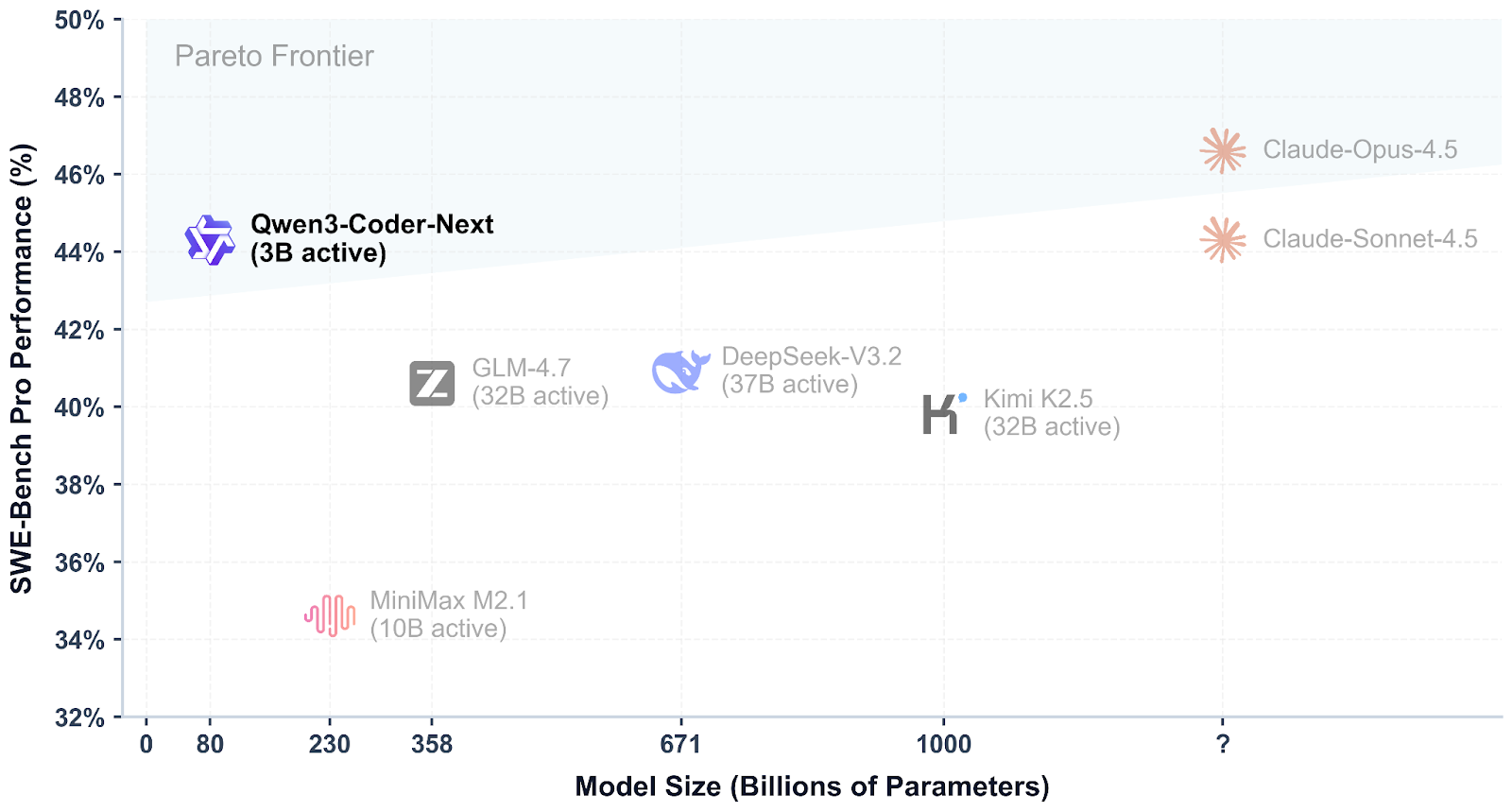
Quelle: Qwen/Qwen3-Coder-Next
In diesem Tutorial erstellen wir llama.cpp aus dem Quellcode erstellen, Qwen3-Coder-Next lokal mit dem Inferenzserver llama.cpp ausführen und dann mit Qwen Code CLI verbinden. Zum Schluss programmieren wir ein einfaches Dashboard für die Datenanalyse.
Bevor du Qwen3-Coder-Next lokal zu erstellen und auszuführen, brauchst du eine funktionierende Linux-Entwicklungsumgebung mit den Standard-Build-Tools, die zum Kompilieren von llama.cpp und zum Ausführen von GGUF-Modellen.
Stell sicher, dass du neben den Systempaketen auch Folgendes hast:
Fang damit an, dein System zu aktualisieren und die wichtigsten Abhängigkeiten zu installieren:
sudo apt-get update
sudo apt-get install -y build-essential cmake curl git libcurl4-openssl-devWenn du vorhast, CUDA-Beschleunigungzu nutzen, check mal, ob deine NVIDIA-GPU richtig erkannt wird:
nvidia-smiBei uns haben wir eine NVIDIA RTX 3090 mit 24 GB VRAM. Da Qwen3-Coder-Next für größere Quantisierungen mehr Speicher braucht, werden die restlichen Modellgewichte automatisch inden RAM-Speicher des Systems „ “ ausgelagert, sodass das Modell weiterhin lokal mit guter Leistung laufen kann.
Damit Qwen3-Coder-Next gut läuft, sollte deine Hardware ungefähr diese Speicheranforderungen erfüllen:
Wenn du keine 46 GB Speicherplatz hast, kannst du trotzdem kleinere quantisierte Versionen ausführen (z. B. 3-Bit).
Eine einfache Faustregel lautet:
Festplatte + RAM + VRAM ≥ Quantengröße
Wenn das ganze Quant in den Speicher passt, kannst du mit einer schnellen lokalen Leistung rechnen. Wenn nicht, läuft das Modell trotzdem weiter, aber die Schlussfolgerung dauert länger.
Bevor wir Qwen3-Coder-Next lokal ausführen können, brauchen wir eine schnelle Inferenz-Engine. Die beliebteste Option ist derzeit llama.cpp, das eine leichtgewichtige GGUF-Inferenz und einen einfach zu bedienenden lokalen Server bietet.
Wenn du die schnellste Einrichtung willst, bietet llama.cpp vorgefertigte Binärdateien für macOS, Linux und Windows (einschließlich CUDA-fähiger Builds). Du kannst sie direkt von der offiziellen GitHub-Release-Seite runterladen: Release b7936 · ggml-org/llama.cpp.
Mit einer vorgefertigten Installation kannst du die CLI-Tools von llama.cpp sofort ausführen oder den Inferenzserver starten, ohne selbst was kompilieren zu müssen.

In diesem Tutorial werden wir llama.cpp manuell erstellen, anstatt auf vorgefertigte Binärdateien zurückzugreifen, und zwar aus ein paar wichtigen Gründen:
Lass uns damit anfangen, den offiziellen Quellcode llama.cpp direkt von GitHub runterzuladen. So stellen wir sicher, dass wir mit der aktuellsten Version arbeiten, einschließlich der neuesten CUDA-Verbesserungen und Fehlerbehebungen:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cppJetzt solltest du dich im Verzeichnis „ llama.cpp “ befinden, das alles enthält, was du brauchst, um das Projekt von Grund auf neu zu erstellen.
Als Nächstes müssen wir das Build-System mit CMakekonfigurieren: . Dieser Schritt macht die benötigten Build-Dateien und aktiviert die GPU-Beschleunigung über CUDA:
cmake /workspace/llama.cpp -B /workspace/llama.cpp/build -DGGML_CUDA=ON -DBUILD_SHARED_LIBS=OFF
Jetzt kompilieren wir die eigentliche Binärdatei des Inferenzservers. Das ist die Komponente, die Qwen3-Coder-Next lokal hosten und einen API-Endpunkt für Codierungstools und CLI-Integrationen bereitstellen wird:
cmake --build /workspace/llama.cpp/build -j --clean-first --target llama-server
Sobald der Build fertig ist, werden die kompilierten ausführbaren Dateien im Verzeichnis „ build/bin/ “ gespeichert. Damit du sie einfacher direkt aus dem Hauptprojektordner starten kannst, kannst du sie so kopieren:
cp /workspace/llama.cpp/build/bin/llama-server /workspace/llama.cpp/llama-serverNachdem du jetzt llama.cpp installiert hast, musst du als Nächstes den Qwen3-Coder-Next GGUF von Hugging Face runterzuladen.
Bevor du loslegst, stell sicher, dass du eine aktuelle Python-Installation (>= 3.11), weil die Hugging Face-Tools und Transfer-Utilities davon abhängen.
Um große GGUF-Dateien effizient runterzuladen, nutzen wir den Hugging Face Hub-Client zusammen mit den schnellen Backends Xet und Transfer:
pip install -U "huggingface_hub[hf_xet]" hf-xet hf_transferAls Nächstes schaltest du das optimierte Transfer-Backend von Hugging Face ein:
export HF_HUB_ENABLE_HF_TRANSFER=1Jetzt können wir die dynamische GGUF- -Version von Qwen3-Coder-Nextvon Unslothrunterladen . In diesem Tutorial holen wir uns die Quantisierung„ “ UD-Q4_K_XL.
Das ist eine super Standardwahl, weil es einen tollen Kompromiss bietet zwischen:
Das Q4 bedeutet, dass das Modell auf 4-Bit-Genauigkeit, wodurch es viel leichter als vollständige FP16-Gewichte ist, aber trotzdem eine beeindruckende Ausgabequalität beibehält.
hf download unsloth/Qwen3-Coder-Next-GGUF \
--local-dir /workspace/models/qwen3-coder-next \
--include "*UD-Q4_K_XL*"Sobald der Befehl ausgeführt wird, fangen die Modelldateien an, in dein lokales Verzeichnis runtergeladen zu werden.

In einem schnellen Netzwerk dauert das normalerweise nur ein paar Minuten. Sobald der Download fertig ist, kannst du das GGUF-Modell inden llama-Server von laden, um lokale Inferenz durchzuführen.
Sobald das GGUF-Modell runtergeladen ist, können wir Qwen3-Coder-Next lokal starten , indem wir das Inferenz-Backend „ llama-server “ nutzen. Damit startest du einen OpenAI-kompatiblen API-Server, mit dem sich Codierungswerkzeuge und CLIs verbinden können.
Mach mal den folgenden Befehl:
./llama-server \
--model "/workspace/models/qwen3-coder-next/Qwen3-Coder-Next-UD-Q4_K_XL.gguf" \
--alias "Qwen3-Coder-Next" \
--host 0.0.0.0 \
--port 8080 \
--threads 32 \
--threads-batch 32 \
--ctx-size 20000\
--batch-size 1024\
--ubatch-size 256 \
--jinja \
--flash-attn on \
--temp 0.7 \
--top-p 0.9 \
--min-p 0.05 \
--fit on \
--swa off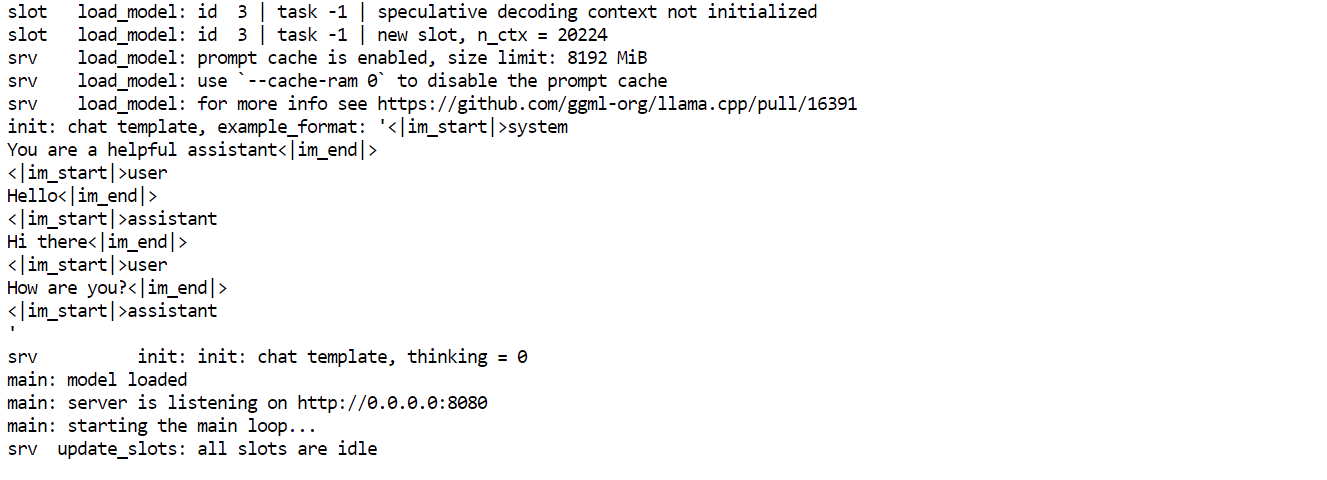
Die wichtigsten Argumente erklärt:
--model: Pfad zum heruntergeladenen Qwen3-Coder-Next GGUF -Checkpoint--alias: Freundlicher Modellname, der in API-Clients angezeigt wird--host 0.0.0.0: Macht den Server auf allen Netzwerkschnittstellen sichtbar (praktisch für den Fernzugriff)--port 8080: Startet die Inferenz-API auf Port 8080--threads 32: Nutzt 32 CPU-Threads für maximalen Durchsatz--threads-batch 32: Parallelisiert die Stapelverarbeitung für eine schnellere Token-Generierung--ctx-size 20000: Stellt ein großes Kontextfenster (~20.000 Token) für lange Programmiersitzungen ein.--batch-size 1024: Verbessert die GPU-Auslastung während der Inferenz--ubatch-size 256: Regelt die Mikro-Batch-Verarbeitung für eine flüssigere Leistung--jinja: Aktiviert die Formatierung von Chat-Vorlagen, die für Modelle im Anleitungsstil gebraucht werden.--flash-attn on: Aktiviert Flash Attention für schnellere Schlussfolgerungen in einem längeren Kontext.--temp 0.7: Hält die Ergebnisse fokussiert, aber trotzdem kreativ für die Vibe-Codierung.--top-p 0.9: Kernprobenahme für ausgewogene Vielfalt--min-p 0.05: Filtert Tokens mit extrem geringer Wahrscheinlichkeit heraus, um sauberere Vervollständigungen zu bekommen.--fit on: Passt die Ebenen automatisch in den VRAM und verschiebt den Rest in den RAM.--swa off: Deaktiviert die Aufmerksamkeit für Schiebefenster (besser für Aufgaben, die den ganzen Kontext brauchen)Sobald der Server läuft, lass ihn einfach in dem Terminalfenster offen. Öffne dann in einem neuen Terminal-Tab oder einer neuen Sitzung, um die API zu testen, ohne den Server anzuhalten.
Vom neuen Terminal aus kannst du überprüfen, ob alles funktioniert, indem du die verfügbaren Modelle abfragst:
curl http://127.0.0.1:8080/v1/modelsWenn der Server richtig läuft, solltest du sehen Qwen3-Coder-Next in der Antwort sehen, was bedeutet, dass dein lokaler Inferenz-Endpunkt einsatzbereit ist.
Sobald der Inferenzserver läuft, kannst du auch direkt über die integrierte Web-Benutzeroberfläche mit Qwen3-Coder-Next interagieren. llama.cpp-Web-UIinteragieren.
Öffne deinen Browser und geh auf: http://127.0.0.1:8080.
Damit startest du eine einfache chatGPT-ähnliche Oberfläche, wo du schnell Eingabeaufforderungen testen und überprüfen kannst, ob das Modell richtig reagiert.
Frag das Modell zum Beispiel zuerst, ob es was Praktisches machen kann, wie einen einfachen Python-Trading-Bot.
 Innerhalb von Sekunden kriegst du eine vollständige Antwort mit funktionierendem Code und klaren Implementierungsschritten.
Innerhalb von Sekunden kriegst du eine vollständige Antwort mit funktionierendem Code und klaren Implementierungsschritten.
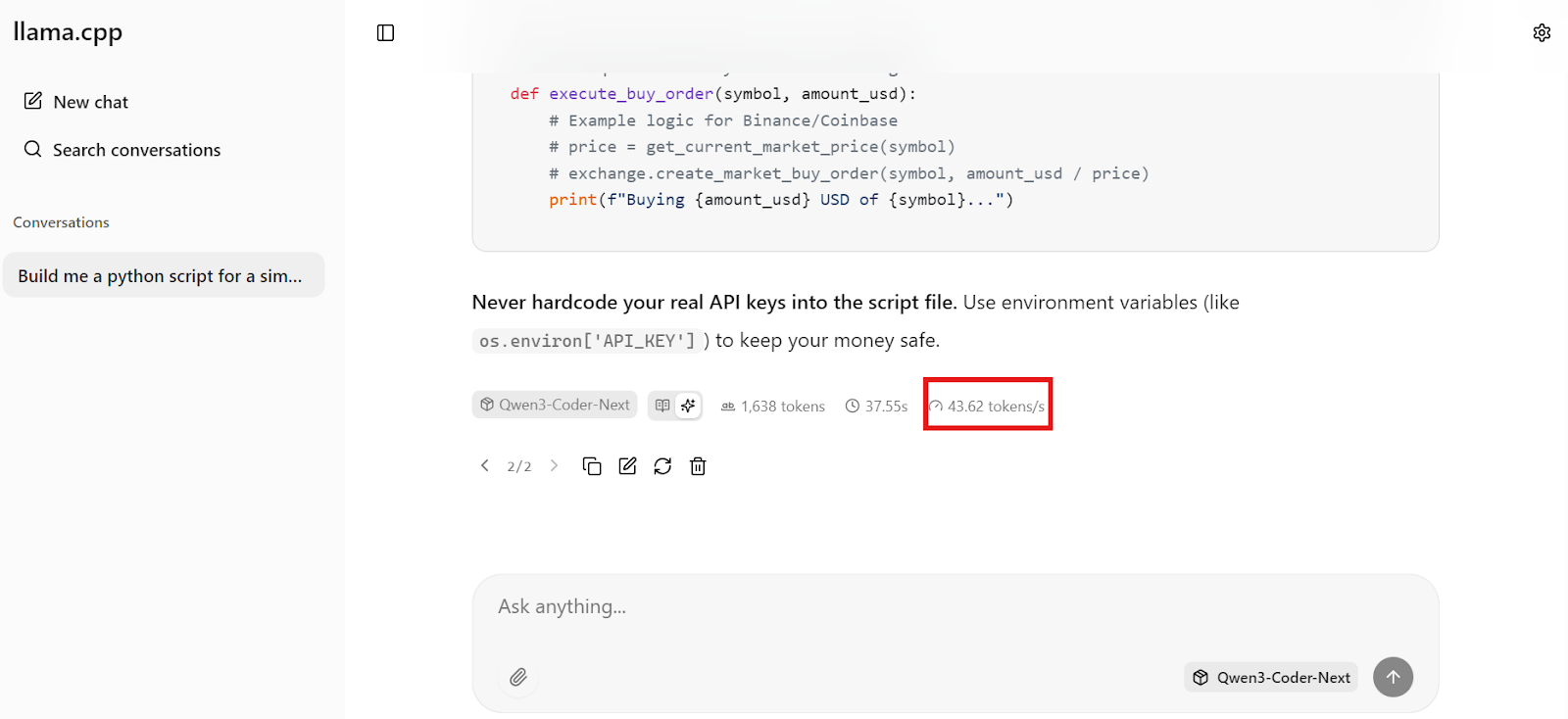
Besonders beeindruckend ist die Geschwindigkeit. Bei unserer Konfiguration schafft Qwen3-Coder-Next ungefähr 44 Token pro Sekunde, was das lokale Codieren super reaktionsschnell macht – schnell genug für Echtzeit-Vibe-Codierungs-Workflows.
Jetzt, wo der lokale Inferenzserver auf http://127.0.0.1:8080/v1läuft, können wir ihn mit Qwen Code CLIverbinden. Damit hast du einen schlanken, terminalbasierten Programmierassistenten, der über die OpenAI-kompatible API mit deinem lokalen Qwen3-Coder-Next-Modell kommuniziert.
Qwen Code CLI ist ein Node-basiertes Tool, also brauchst du:
Installiere Node.js von NodeSource (empfohlen, um die richtige Version zu kriegen):
sudo apt update
sudo apt install -y curl ca-certificates
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash -
sudo apt install -y nodejsJetzt installierst du die Qwen Code CLI global:
npm install -g @qwen-code/qwen-code@latestÜberprüfe, ob es richtig installiert ist:
qwen --version 0.9.0Qwen CLI braucht Umgebungsvariablen im OpenAI-Stil. Wir machen eine einfache Konfigurationsdatei, die ihm sagt:
--aliasMach das Verzeichnis „config“ und die Datei „ .env “:
mkdir -p ~/.qwen
cat > ~/.qwen/.env <<'EOF'
OPENAI_API_KEY="dummy"
OPENAI_BASE_URL="http://127.0.0.1:8080/v1"
OPENAI_MODEL="Qwen3-Coder-Next"
EOFJetzt Qwen Code starten:
qwen  Jetzt ist deine CLI mit deinem lokalen Qwen3-Coder-Next-Server, sodass jede Eingabeaufforderung lokal läuft, anstatt eine gehostete API zu nutzen.
Jetzt ist deine CLI mit deinem lokalen Qwen3-Coder-Next-Server, sodass jede Eingabeaufforderung lokal läuft, anstatt eine gehostete API zu nutzen.
Jetzt, wo alles lokal läuft, können wir mit dem vibe coding ein einfaches Analyse-Dashboard mit der Qwen Code CLI.
Mach erst mal einen neuen Projektordner und geh da rein:
mkdir dashboardcd dashboardStarte dann die Qwen-CLI in diesem Verzeichnis:
qwenGib dem Modell jetzt eine klare, einfache Anweisung, zum Beispiel:
Erstell ein HTML-Analytics-Dashboard mit Dummy-Daten (Verkäufe, Nutzer, Einnahmen, Abwanderung), zeig KPI-Karten, eine interaktive Tabelle und mindestens ein Diagramm an, füge Filter für Datumsbereiche und Kategorien hinzu.
Innerhalb von Sekunden versteht Qwen3-Coder-Next die Anforderungen und macht einen strukturierten Plan, bevor er den Code schreibt.
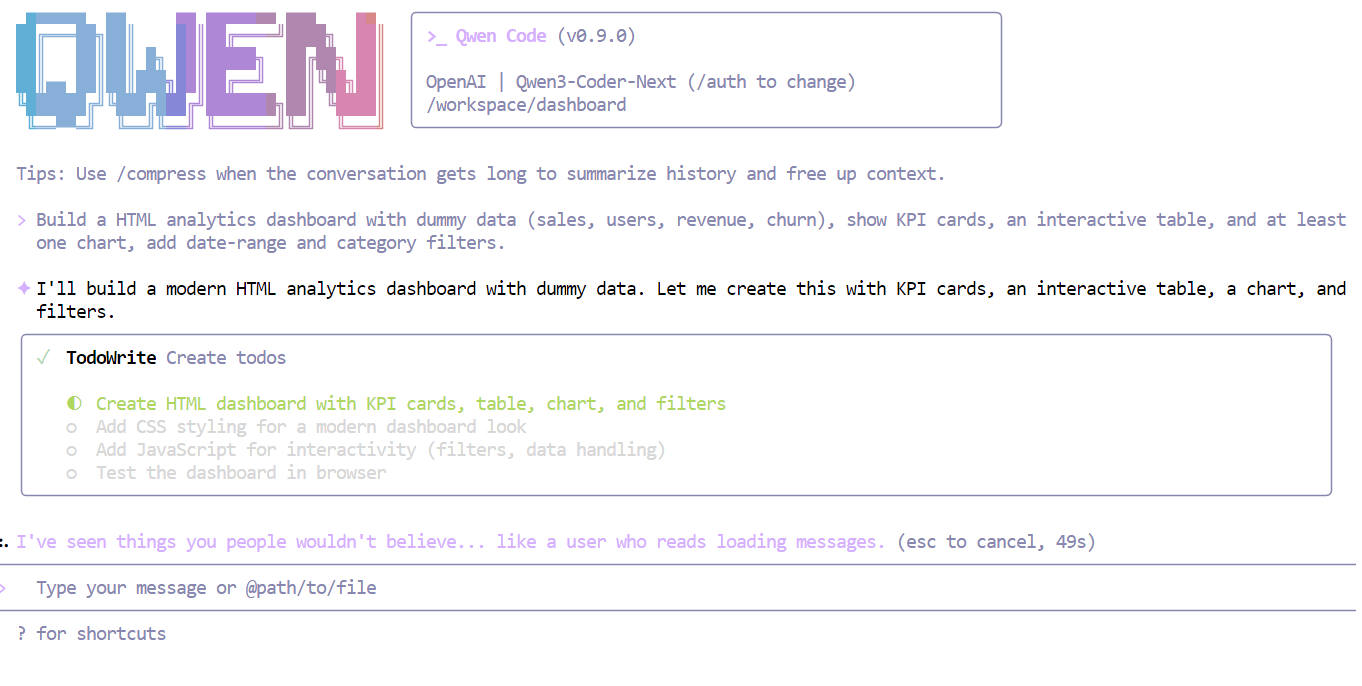
Nachdem die Checkliste abgearbeitet war, hat das Modell auf einen Schlag ein voll funktionsfähiges Dashboard erstellt, mit:
index.htmlstyle.cssscript.js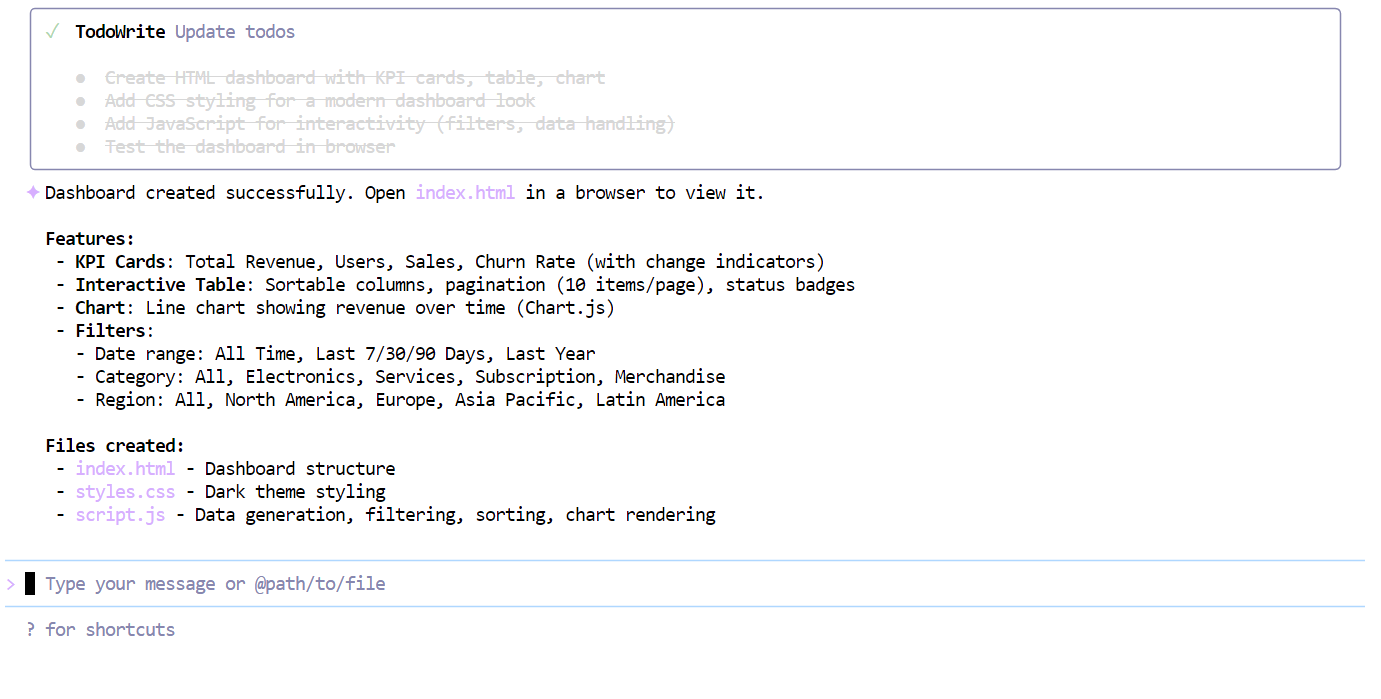
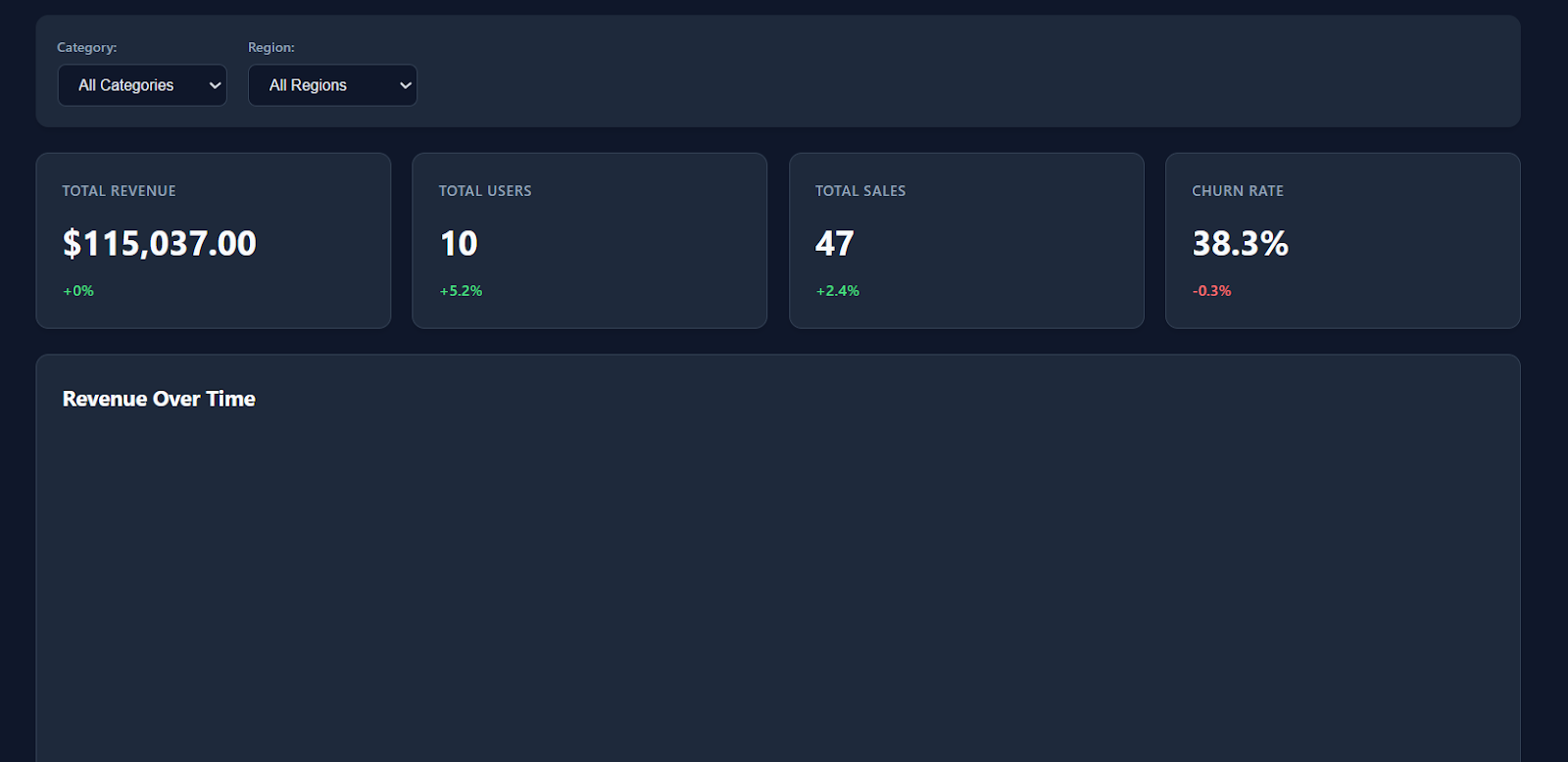
Wenn du die Datei „ index.html “ in deinem Browser öffnest, siehst du sofort ein modernes, übersichtliches Dashboard mit klarem Design, KPI-Karten und realistischen Platzhalterkennzahlen.
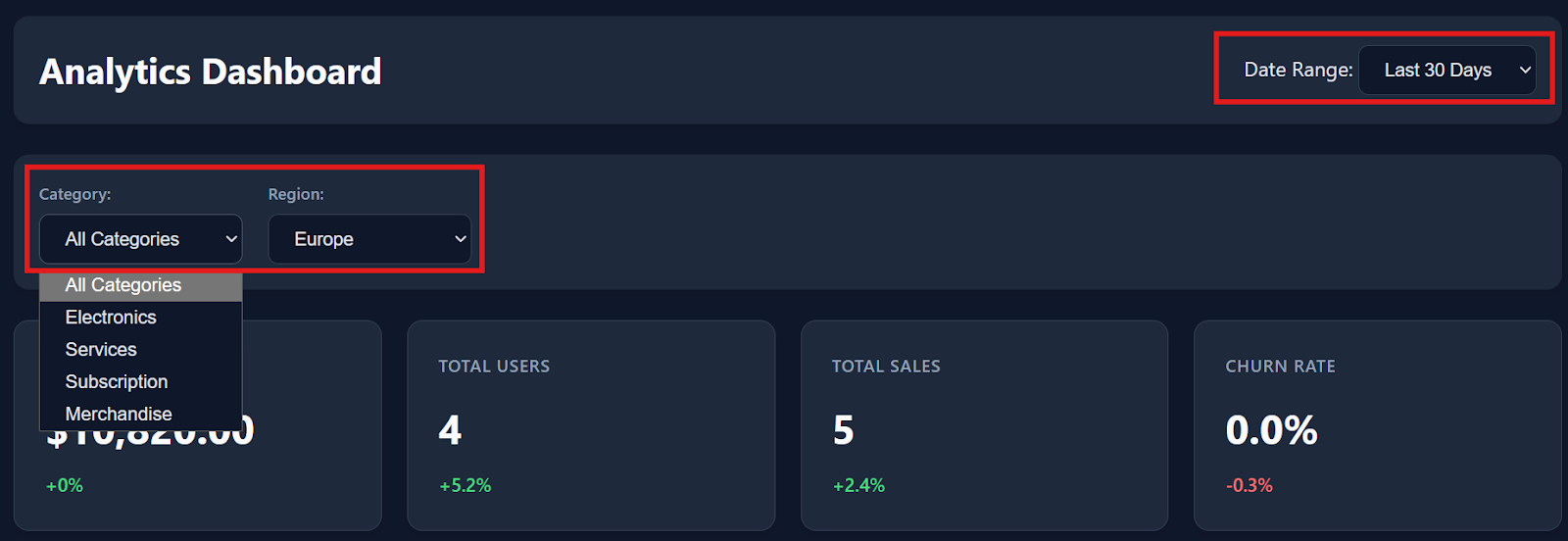
Die Filter, die Interaktionen mit Tabellen und die Download-Optionen funktionieren alle sofort reibungslos.
Wenn du runter scrollst, findest du im Dashboard auch detaillierte Transaktionsdaten mit ungefähr 150 Dummy-Datensätzen, sodass es sich wie ein echtes Analyseprodukt anfühlt.
Auch wenn es nicht jede mögliche Visualisierung erzeugt (zum Beispiel wäre ein Liniendiagramm zur Umsatzentwicklung im Zeitverlauf eine coole Ergänzung), ist es trotzdem echt beeindruckend, dass ein lokal laufendes quantisiertes Modell im Grunde mit einem Schlag ein funktionales Dashboard erstellen kann.
Insgesamt hat der ganze Build-Vorgang von der Eingabe bis zum funktionierenden Ergebnis nur ein paar Minuten gedauert.
Ich bin ehrlich: Meine Erfahrung mit Qwen3-Coder-Next waren ein bisschen gemischt.
Auf dem Papier deuten die Bewertungen darauf hin, dass es fast so gut sein sollte wie Modelle auf dem neuesten Stand der Technik wie Claude Sonnet 4.5ähneln sollte, und die Idee, ein 80-Bit-MoE-Codierungsmodell lokal auszuführen, ist wirklich spannend.
In diesem Tutorial haben wir llama.cpp mit CUDA-Unterstützungerfolgreich gebaut , den Unsloth GGUF-Quant runtergeladen, einen lokalen Inferenzserver gestartet und sogar in wenigen Minuten ein funktionierendes Analyse-Dashboard programmiert. Die lokale Geschwindigkeit und Reaktionsfähigkeit waren echt beeindruckend, vor allem für ein offenes Gewicht-Setup.
Aber ehrlich gesagt habe ich nicht immer die Zuverlässigkeit auf „Sonnet-Niveau“ gesehen, die manche Benchmarks andeuten. Ich habe ein paar Stunden damit verbracht, das Modell in komplexeren Agentenumgebungen wie opencode zu testen, und bin dabei immer wieder auf Probleme wie Tool-Fehler, instabile Generierungen und gelegentliche Schleifenausgaben gestoßen.
Interessanterweise fühlte sich das Modell viel zuverlässiger an, nachdem ich zu einem einfacheren Workflow mit Qwen Code CLIgewechselt hatte . In dieser Umgebung hat es bei direkten Programmieraufgaben, beim schnellen Prototyping und bei Vibe-Coding-Sessions echt gut funktioniert. Es lief flüssig, schnell und hat echt Spaß gemacht, es lokal zu benutzen.
Meine Erkenntnis: Qwen3-Coder-Next ist echt einen Versuch wert, vor allem, wenn du einen starken lokalen Programmierassistenten ohne Cloud-APIs suchst. Aber ich würde es noch nicht als kompletten Ersatz für produktionsreife Codierungsagenten empfehlen, es sei denn, du bist bereit, Zeit mit Debugging, der Anpassung der llama.cpp-Einstellungen und der Optimierung der Leistung für deine Hardware zu verbringen.
Wenn du mehr darüber erfahren möchtest, wie du KI in deinen Arbeitsabläufen einsetzen kannst, empfehle ich dir den Kurs „KI-gestütztes Programmieren für Entwickler ”.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
Tutorial
Matt Crabtree