
programa
Associate AI Engineer para desarrolladores
26 h
SAM 3 es el nuevo «segment anything» de Meta que puede encontrar todas las instancias de un concepto a través de breves indicaciones de texto o ejemplos y devolver máscaras con precisión de píxeles en imágenes y vídeos. Esto lo hace perfecto para tareas prácticas relacionadas con la privacidad, como difuminar rostros, matrículas o pantallas sin necesidad de seleccionar manualmente las zonas o escribir detectores clásicos.
En este tutorial, crearemos un filtro de privacidad SAM3 en Colab utilizando una interfaz de usuario Gradio. Solo tienes que subir una imagen o un vídeo, escribir una indicación (como caras, matrículas) y SAM3 devolverá máscaras de instancia para que podamos difuminar solo esos píxeles. Vamos a ver paso a paso la configuración, la generación de máscaras, la aplicación de un desenfoque gaussiano y la conexión de la aplicación Gradio para exportar los archivos finales.
Segment Anything Model 3 (SAM 3) es el modelo unificado de Meta para la detección, segmentación y seguimiento de vocabulario abierto en imágenes y vídeos. En lugar de configurar detectores independientes para cada clase, puedes introducir frases cortas o ejemplos, y SAM 3 devuelve máscaras por instancia.
Bajo el capó, SAM 3 fusiona un codificador de texto y un codificador de imágenes con un detector de estilo DETR y un rastreador derivado de SAM-2 con un banco de memoria. En cada fotograma, detecta máscaras para tu concepto a partir de la indicación, propaga las máscaras hacia adelante a través del rastreador y fusiona las máscaras recién detectadas y rastreadas en el resultado final de ese fotograma.
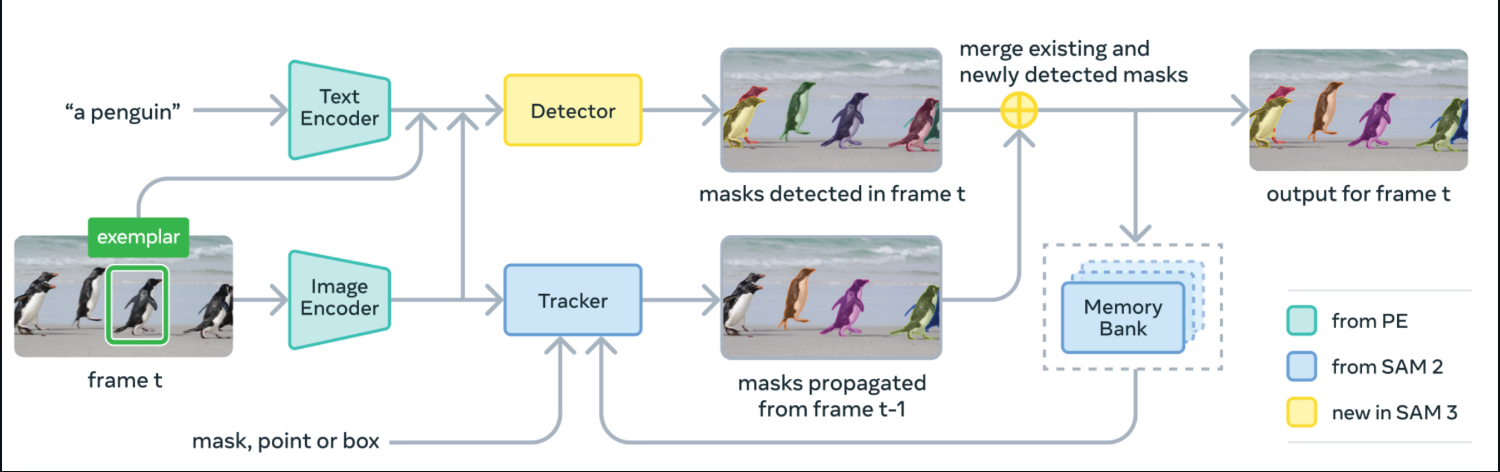
Fuente: SAM3 GitHub
SAM 3 se lanza con pesos de modelo, código de ajuste fino y datos de evaluación, incluyendo el benchmark SA-Co para la segmentación de conceptos promptable.
En los informes de Meta, se muestra ganancias de aproximadamente el doble respecto a las sólidas bases de referencia en la segmentación de vocabulario abierto en imágenes y vídeos, al tiempo que se mantienen las ventajas interactivas de SAM-2.
En este tutorial, tomaremos esas máscaras SAM 3 y las convertiremos en un compuesto con desenfoque gaussiano tanto para imágenes como para vídeos, envuelto en una interfaz de usuario Gradio.
En esta sección, crearemos un filtro de privacidad con SAM3 para imágenes y vídeos integrados en una interfaz de usuario Gradio sencilla.
Así es como funciona:
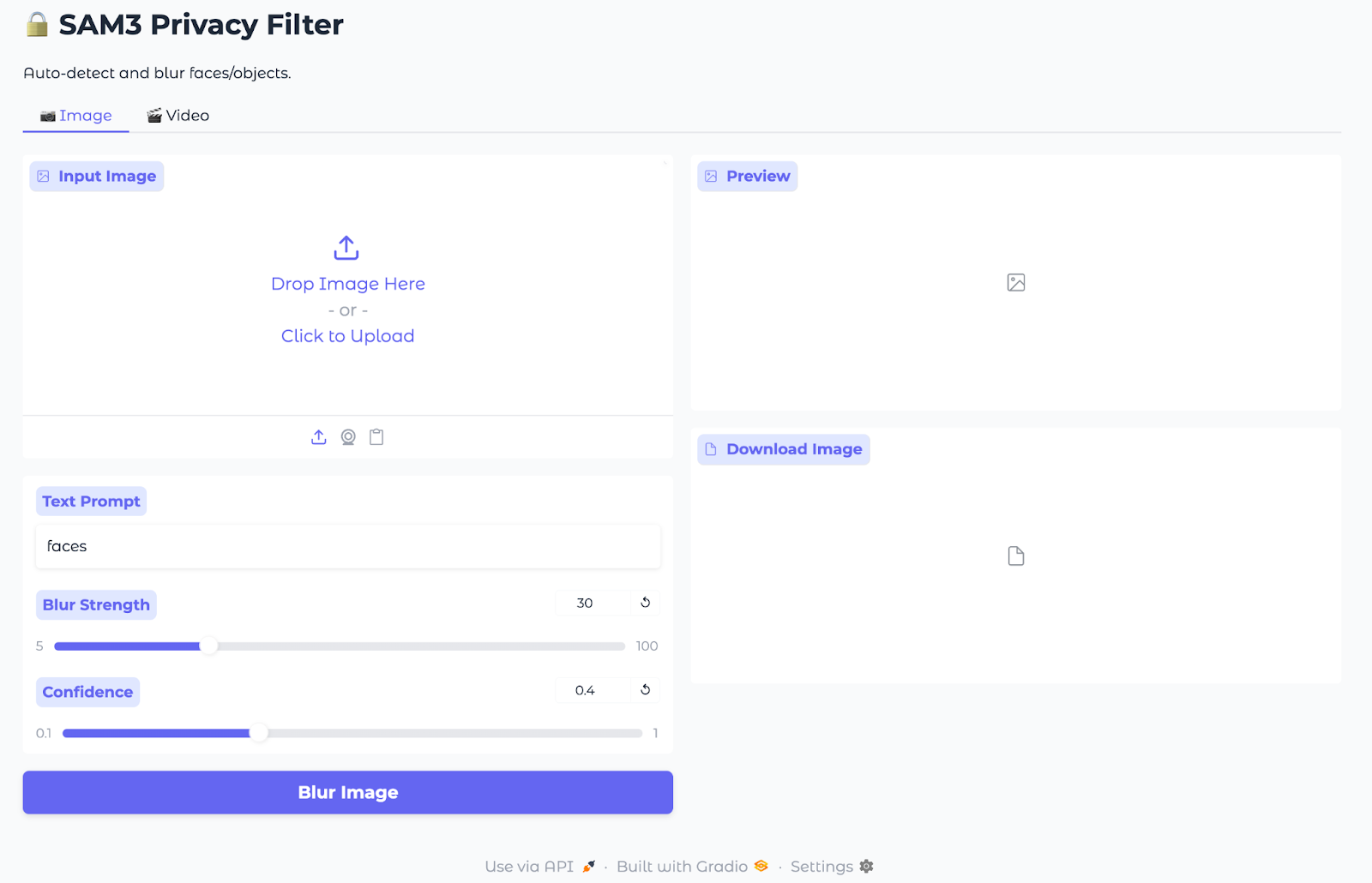
Vamos a repasar la implementación completa paso a paso.
Antes de ejecutar esta demostración, asegurémonos de que cumplís con todos los requisitos previos. Para ejecutar el filtro de privacidad SAM3 en Colab, necesitas la última versión de Transformers, junto con algunas bibliotecas de tiempo de ejecución para la interfaz de usuario, operaciones tensoriales, imágenes y E/S de vídeo. El siguiente fragmento de código instala todo de una sola vez.
import subprocess
import sys
import os
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", "-q", package])
print(" Installing latest Transformers")
install("git+https://github.com/huggingface/transformers.git")
pkgs = [
"accelerate",
"gradio",
"numpy",
"pillow",
"torch",
"torchvision",
"imageio[ffmpeg]"
]
for p in pkgs:
install(p)A continuación se explica la función de cada requisito previo:
git+https://github.com/huggingface/transformers.git: Esto extrae la última biblioteca Transformers del código fuente, por lo que las clases Sam3Processor y Sam3Model están disponibles.torch y torchvision: Estas son las utilidades de cálculo tensorial y de imágenes que ejecutan la pasada directa SAM3.accelerate: Este es el asistente de inferencia utilizado por Transformers.gradio: Una interfaz de usuario web ligera para subir archivos multimedia y previsualizar resultados borrosos.numpy, pillow: Entre ellas se incluyen arreglos de imágenes y operaciones de imagen PIL para la composición de máscaras/desenfoques.imageio[ffmpeg]: Lee/escribe vídeos y codifica MP4 (FFmpeg) para la pestaña de vídeo.Una vez configurado el entorno y cargado facebook/sam3, la demostración te permite segmentar con breves indicaciones de texto y difuminar las máscaras resultantes en imágenes o vídeos a través de una sencilla aplicación Gradio.
Nota: Si tienes pensado utilizar una GPU en Colab, configura el tiempo de ejecución en GPU (T4/A100) antes de la instalación. Utilicé una GPU A100 en Colab para obtener una experiencia más rápida.
Una vez configurado el entorno, importen las bibliotecas que alimentan la interfaz de usuario, la inferencia de modelos, el manejo de imágenes/vídeos y la sincronización. Estos son los únicos módulos que necesitas para el filtro de privacidad SAM3.
import gradio as gr
import torch
import numpy as np
import imageio
from PIL import Image, ImageFilter
from transformers import Sam3Processor, Sam3Model
import timeAhora, Gradio proporciona la interfaz web, la biblioteca transformers ejecuta SAM3 y PyTorch ejecuta la inferencia en la GPU o la CPU. Mientras que PIL carga y edita imágenes (incluido el desenfoque gaussiano), NumPy gestiona los arreglos de máscaras y imageio lee y escribe archivos de vídeo.
A continuación, cargaremos el modelo y construiremos un pequeño motor que convierta las indicaciones de texto en máscaras que puedas difuminar.
Ahora que el entorno está listo, vamos a integrar SAM3 en un pequeño motor que carga el modelo una vez, ejecuta la segmentación de instancias por texto bajo demanda y devuelve máscaras binarias que se utilizan para el desenfoque.
class Sam3PrivacyEngine:
def __init__(self):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model = None
self.processor = None
print(f"Initializing SAM3 on {self.device}")
try:
self.model = Sam3Model.from_pretrained("facebook/sam3").to(self.device)
self.processor = Sam3Processor.from_pretrained("facebook/sam3")
print("SAM3 Loaded Successfully!")
except Exception as e:
print(f"Error loading SAM3: {e}")
def predict_masks(self, image_pil, text_prompt, threshold=0.4):
if self.model is None: return []
inputs = self.processor(
images=image_pil,
text=text_prompt,
return_tensors="pt"
).to(self.device)
with torch.no_grad():
outputs = self.model(**inputs)
results = self.processor.post_process_instance_segmentation(
outputs,
threshold=threshold,
mask_threshold=0.5,
target_sizes=inputs["original_sizes"].tolist()
)[0]
masks = []
if "masks" in results:
for i, mask_tensor in enumerate(results["masks"]):
mask_np = (mask_tensor.cpu().numpy() * 255).astype(np.uint8)
mask_pil = Image.fromarray(mask_np)
masks.append(mask_pil)
return masks
engine = Sam3PrivacyEngine()Veamos cómo encaja este motor en el proceso:
Sam3PrivacyEngine.init(): Este inicializador selecciona el mejor dispositivo (CUDA si está disponible, de lo contrario CPU), carga los pesos facebook/sam3 y el emparejado Sam3Processor, y mueve el modelo al dispositivo elegido para que la inferencia se pueda ejecutar de manera eficiente.Sam3PrivacyEngine.predict_masks(): Este método crea entradas de modelo a partir de una imagen PIL y un mensaje de texto, ejecuta la inferencia hacia adelante bajo una red neuronal convolucional ( torch.no_grad() ) para evitar la sobrecarga del gradiente y posprocesa las salidas con una red neuronal convolucional ( post_process_instance_segmentation ) utilizando los umbrales de detección y máscara dados, así como los tamaños originales de los objetivos para un escalado correcto. Devuelve máscaras de segmentación por instancia convertidas de tensores a arreglos NumPy y, a continuación, a máscaras PIL «L» (imágenes en escala de grises de 8 bits (modo «L») en las que cada píxel es un valor entre 0 y 255) para su composición.engine = Sam3PrivacyEngine(): Esta línea crea una única instancia de motor reutilizable, de modo que el modelo SAM3 se carga una sola vez y se puede invocar repetidamente para imágenes o fotogramas de vídeo sin necesidad de reinicializarlo.Una vez inicializado este motor autónomo, puedes convertir cualquier imagen y texto en máscaras de instancia. A continuación, aplicaremos un desenfoque selectivo utilizando estas máscaras e integraremos todo en la interfaz de usuario de Gradio.
En esta sección, tomamos las máscaras de SAM3 y aplicamos la privacidad. Solo difumina las regiones enmascaradas, conservando todo lo demás. Empezamos con una función de desenfoque gaussiano reutilizable y, a continuación, la conectamos a dos canalizaciones, una para imágenes y otra para vídeos.
Este ayudante toma una imagen y una o más máscaras «L» de PIL, las combina en una única máscara compuesta y pega una copia borrosa de la imagen solo donde la máscara es blanca (255).
def apply_blur_pure(image_pil, masks, blur_strength):
if not masks:
return image_pil
radius = blur_strength
blurred_image = image_pil.filter(ImageFilter.GaussianBlur(radius=radius))
composite_mask = Image.new("L", image_pil.size, 0)
for mask in masks:
composite_mask.paste(255, (0, 0), mask=mask)
final_image = image_pil.copy()
final_image.paste(blurred_image, (0, 0), mask=composite_mask)
return final_imageAsí es como funciona esta función:
GaussianBlur() crea primero una versión totalmente desenfocada de la imagen. Mientras que composite_mask es una máscara «L» (escala de grises) inicializada en negro (0 = mantener el original). composite_mask, de modo que solo las regiones blancas queden desenfocadas.final_image.paste() » sustituye solo los píxeles enmascarados, dejando el resto sin modificar para obtener la máxima fidelidad visual.Con una sola llamada, puedes difuminar cualquier conjunto de regiones, como caras, pantallas o placas, manteniendo los fondos tal y como están.
Este subpaso abarca el flujo de imágenes de principio a fin, desde la normalización de la entrada hasta la obtención de máscaras de SAM3, pasando por el desenfoque de los píxeles enmascarados y, finalmente, la devolución del resultado.
def process_image(input_img, text_prompt, blur_strength, confidence):
if input_img is None: return None, None
if isinstance(input_img, np.ndarray):
image_pil = Image.fromarray(input_img).convert("RGB")
else:
image_pil = input_img.convert("RGB")
masks = engine.predict_masks(image_pil, text_prompt, confidence)
result_pil = apply_blur_pure(image_pil, masks, blur_strength)
output_path = "privacy_image.png"
result_pil.save(output_path)
return np.array(result_pil), output_pathManejamos las imágenes con el siguiente proceso paso a paso:
engine.predict_masks() para obtener las máscaras de instancia SAM3 para el text_prompt proporcionado.apply_blur_pure() ) con el tamaño de píxel seleccionado ( blur_strength ) para que solo se desenfocen las regiones enmascaradas.png » y devolvemos tanto un arreglo NumPy como un archivo descargable.Una vez completado el flujo de imágenes, podemos pasar al proceso de vídeo.
El flujo de vídeo refleja la ruta de la imagen, pero se transmite fotograma a fotograma con imageio. Para cada fotograma, segmentamos, difuminamos las regiones enmascaradas y escribimos en un archivo MP4 codificado en H.264.
def process_video(video_path, text_prompt, blur_strength, confidence, max_frames):
if not video_path: return None, None
try:
reader = imageio.get_reader(video_path)
meta = reader.get_meta_data()
fps = meta.get('fps', 24)
output_path = "privacy_video.mp4"
writer = imageio.get_writer(
output_path,
fps=fps,
codec='libx264',
pixelformat='yuv420p',
macro_block_size=1
)
print("Starting video processing...")
for i, frame in enumerate(reader):
if i >= max_frames:
break
frame_pil = Image.fromarray(frame).convert("RGB")
masks = engine.predict_masks(frame_pil, text_prompt, confidence)
processed_pil = apply_blur_pure(frame_pil, masks, blur_strength)
writer.append_data(np.array(processed_pil))
if i % 10 == 0:
print(f"Processed frame {i}...")
writer.close()
reader.close()
print("Video processing complete.")
return output_path, output_path
except Exception as e:
print(f"Error: {e}")
return None, NoneAsí es como gestionamos los vídeos con el siguiente proceso:
imageio.get_reader() », luego iteramos los fotogramas y leemos los FPS de los metadatos (por defecto, 24 si faltan).engine.predict_masks() » (Aprendizaje automático de máscaras) y difuminando las regiones enmascaradas con la función « apply_blur_pure() » (Difuminado de bordes).pixelformat='yuv420p' para una amplia compatibilidad y macro_block_size=1 para evitar artefactos de alineación.Con este flujo de vídeo, puedes difuminar las zonas sensibles de las grabaciones de reuniones, los clips de cámaras de salpicadero o las capturas de pantalla mediante un sencillo mensaje de texto.
Ahora que el enmascaramiento y el desenfoque están listos, lo envolveremos todo en una interfaz de usuario Gradio ligera para que cualquiera pueda subir una imagen o un vídeo, escribir un mensaje de texto y descargar el resultado.
with gr.Blocks(title="SAM3 Privacy Filter", theme=gr.themes.Soft()) as demo:
gr.Markdown("# SAM3 Privacy Filter")
gr.Markdown("Auto-detect and blur faces/objects.")
with gr.Tabs():
with gr.Tab("Image"):
with gr.Row():
with gr.Column():
im_input = gr.Image(label="Input Image", type="numpy")
im_prompt = gr.Textbox(label="Text Prompt", value="faces")
im_blur = gr.Slider(5, 100, value=30, label="Blur Strength")
im_conf = gr.Slider(0.1, 1.0, value=0.4, label="Confidence")
im_btn = gr.Button("Blur Image", variant="primary")
with gr.Column():
im_output = gr.Image(label="Preview")
im_dl = gr.File(label="Download Image")
im_btn.click(process_image, [im_input, im_prompt, im_blur, im_conf], [im_output, im_dl])
with gr.Tab("Video"):
with gr.Row():
with gr.Column():
vid_input = gr.Video(label="Input Video")
vid_prompt = gr.Textbox(label="Text Prompt", value="faces")
vid_blur = gr.Slider(5, 100, value=30, label="Blur Strength")
vid_conf = gr.Slider(0.1, 1.0, value=0.4, label="Confidence")
vid_limit = gr.Slider(10, 300, value=60, step=10, label="Max Frames")
vid_btn = gr.Button("Blur Video", variant="primary")
with gr.Column():
vid_output = gr.Video(label="Preview")
vid_dl = gr.File(label="Download Video")
vid_btn.click(process_video, [vid_input, vid_prompt, vid_blur, vid_conf, vid_limit], [vid_output, vid_dl])
demo.launch(share=True, debug=True)La aplicación Gradio integra el proceso de enmascaramiento y desenfoque SAM3 en una sencilla interfaz de usuario web mediante el uso de:
gr.Blocks): Este bloque crea una aplicación Gradio de una sola página con un título y dos pestañas, una para imágenes y otra para vídeos, de modo que los usuarios pueden cambiar de modo sin salir de la página.process_image » (Desenfocar imagen), que llama a SAM3 para las máscaras y aplica el desenfoque gaussiano solo a los píxeles enmascarados.process_video, iterando fotogramas para predecir máscaras, desenfocar regiones enmascaradas y codificar un vídeo H.264.demo.launch() ` inicia la aplicación, genera un enlace compartible y muestra trazas de pila detalladas cuando la depuración está habilitada.Ahora, nuestro filtro de privacidad SAM3 está listo para cargar archivos multimedia (imágenes/vídeos), configurar avisos y umbrales, y exportar los resultados difuminados.
Nota: Todas las imágenes y vídeos de esta demostración proceden de Pexels.com y son de uso gratuito.
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
blog
Abid Ali Awan
10 min
Tutorial
Aashi Dutt
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita



