
Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
99.8K
Los transformadores se desarrollaron por primera vez para resolver el problema de la transducción de secuencias, o traducción automática neuronal, lo que significa que están pensados para resolver cualquier tarea que transforme una secuencia de entrada en una secuencia de salida. Por eso se llaman "Transformadores".
Pero empecemos por el principio.
Un modelo transformador es una red neuronal que aprende el contexto de los datos secuenciales y genera nuevos datos a partir de él.
En pocas palabras:
Un transformador es un tipo de modelo de inteligencia artificial que aprende a comprender y generar texto similar al humano analizando patrones en grandes cantidades de datos de texto.
Los transformadores son un modelo actual de PNL de última generación y se consideran la evolución de la arquitectura codificador-decodificador. Sin embargo, mientras que la arquitectura codificador-decodificador se basa principalmente en Redes Neuronales Recurrentes (RNN) para extraer información secuencial, los Transformadores carecen por completo de esta recurrencia.
Entonces, ¿cómo lo hacen?
Están diseñados específicamente para comprender el contexto y el significado analizando la relación entre distintos elementos, y para ello se basan casi por completo en una técnica matemática llamada atención.

Imagen del autor.
Originados a partir de un trabajo de investigación de Google de 2017, los modelos transformadores son uno de los desarrollos más recientes e influyentes en el campo del Aprendizaje Automático. El primer modelo Transformer se explicó en el influyente artículo "Attention is All You Need.
Este concepto pionero no fue sólo un avance teórico, sino que también encontró aplicación práctica, sobre todo en el paquete Tensor2Tensor de TensorFlow. Además, el grupo de PNL de Harvard contribuyó a este campo floreciente ofreciendo una guía comentada del artículo, complementada con una implementación de PyTorch. Puedes obtener más información sobre cómo implementar un Transformador desde cero en nuestro tutorial independiente.
Su introducción ha espoleado un auge significativo en este campo, a menudo denominado IA Transformadora. Este revolucionario modelo sentó las bases para posteriores avances en el ámbito de los grandes modelos lingüísticos, incluido el BERT. En 2018, estos avances ya eran aclamados como un momento decisivo en la PNL.
En 2020, los investigadores de OpenAI anunciaron la GPT-3. En pocas semanas, la versatilidad de GPT-3 quedó rápidamente demostrada cuando la gente lo utilizó para crear poemas, programas, canciones, sitios web y mucho más, cautivando la imaginación de usuarios de todo el mundo.
En un documento de 2021, los académicos de Stanford denominaron acertadamente a estas innovaciones modelos fundacionales, subrayando su papel fundacional en la remodelación de la IA. Su trabajo pone de relieve cómo los modelos transformadores no sólo han revolucionado el campo, sino que también han ampliado las fronteras de lo que se puede conseguir en inteligencia artificial, anunciando una nueva era de posibilidades.
"Estamos en una época en la que métodos sencillos como las redes neuronales nos están proporcionando una explosión de nuevas capacidades",Ashish Vaswani, empresario y antiguo científico investigador senior de Google.
En el momento de la introducción del modelo Transformer, las RNN eran el enfoque preferido para tratar datos secuenciales, que se caracterizan por un orden específico en su entrada.
Las RNN funcionan de forma similar a las redes neuronales feed-forward, pero procesan la entrada secuencialmente, elemento a elemento.
Los transformadores se inspiran en la arquitectura codificador-decodificador de las RNN. Sin embargo, en lugar de utilizar la recurrencia, el modelo Transformador se basa completamente en el mecanismo de Atención.
Además de mejorar el rendimiento de las RNN, los Transformadores han proporcionado una nueva arquitectura para resolver muchas otras tareas, como el resumen de textos, el subtitulado de imágenes y el reconocimiento del habla.
Entonces, ¿cuáles son los principales problemas de las RNN? Son bastante ineficaces para las tareas de PNL por dos razones principales:
El cambio de las Redes Neuronales Recurrentes (RNN) como la LSTM a los Transformadores en la PNL está impulsado por estos dos problemas principales y la capacidad de los Transformadores para evaluar ambos aprovechando las mejoras del mecanismo de Atención:
Así, los Transformadores se convirtieron en una mejora natural de las RNN.
A continuación, veamos cómo funcionan los transformadores.
Ideados originalmente para la transducción de secuencias o la traducción automática neuronal, los transformadores destacan en la conversión de secuencias de entrada en secuencias de salida. Es el primer modelo de transducción que se basa totalmente en la autoatención para calcular las representaciones de su entrada y salida, sin utilizar RNN alineadas en secuencia ni convolución. La principal característica esencial de la arquitectura de los Transformadores es que mantienen el modelo codificador-decodificador.
Si empezamos a considerar un Transformador para la traducción de idiomas como una simple caja negra, tomaría una frase en un idioma, el inglés por ejemplo, como entrada y emitiría su traducción al inglés.

Imagen del autor.
Si buceamos un poco, observamos que esta caja negra se compone de dos partes principales:
Imagen del autor. Estructura global del codificador-decodificador.
Sin embargo, tanto el codificador como el descodificador son en realidad una pila con varias capas (el mismo número para cada una). Todos los codificadores presentan la misma estructura, y la entrada entra en cada uno de ellos y pasa al siguiente. Todos los descodificadores presentan también la misma estructura y reciben la entrada del último codificador y del descodificador anterior.
La arquitectura original constaba de 6 codificadores y 6 descodificadores, pero podemos reproducir tantas capas como queramos. Así que supongamos N capas de cada.
Imagen del autor. Estructura global del codificador-decodificador. Múltiples capas.
Así que ahora que tenemos una idea genérica de la arquitectura general de los Transformadores, vamos a centrarnos en los Codificadores y Decodificadores para comprender mejor su flujo de trabajo:
El codificador es un componente fundamental de la arquitectura Transformer. La función principal del codificador es transformar los tokens de entrada en representaciones contextualizadas. A diferencia de los modelos anteriores, que procesaban los tokens de forma independiente, el codificador Transformer capta el contexto de cada token con respecto a toda la secuencia.
La composición de su estructura es la siguiente
Imagen del autor. Estructura global de los codificadores.
Así que dividamos su flujo de trabajo en sus pasos más básicos:
La incrustación sólo se produce en el codificador situado más abajo. El codificador empieza convirtiendo los tokens de entrada -palabras o subpalabras- en vectores mediante capas de incrustación. Estas incrustaciones captan el significado semántico de los tokens y los convierten en vectores numéricos.
Todos los codificadores reciben una lista de vectores, cada uno de tamaño 512 (tamaño fijo). En el codificador inferior, serían las incrustaciones de palabras, pero en otros codificadores, sería la salida del codificador que está justo debajo.
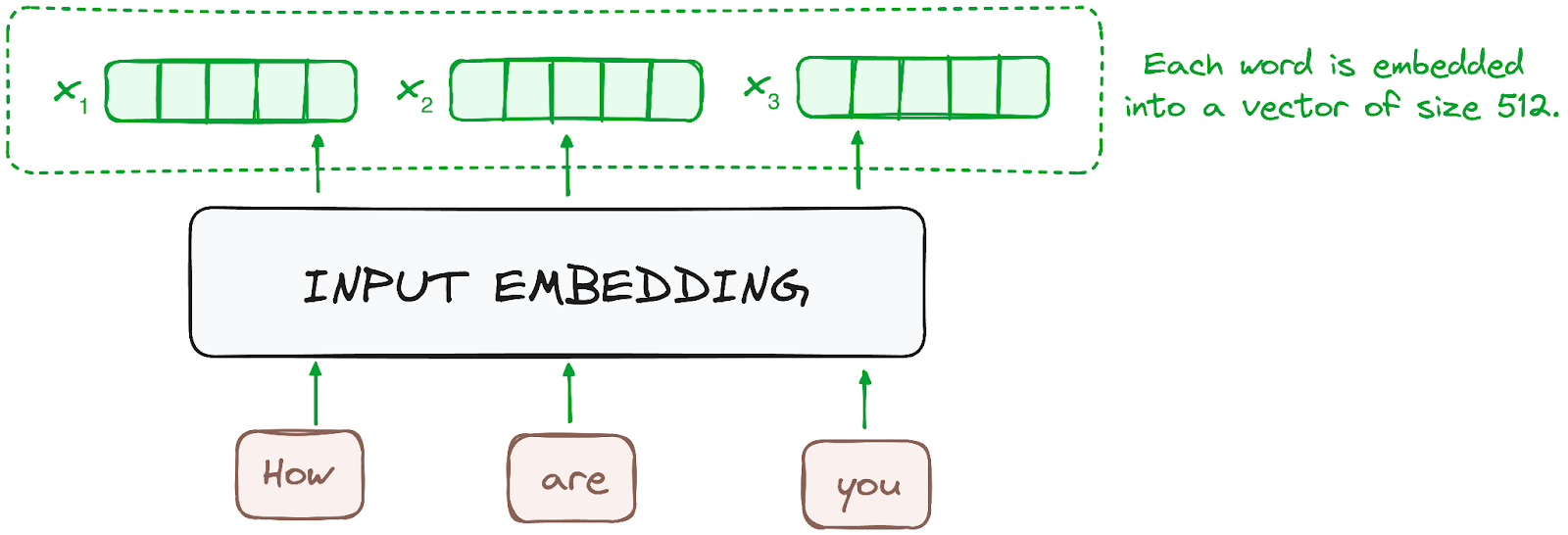
Imagen del autor. Flujo de trabajo del codificador. Incrustación de entrada.
Como los Transformadores no tienen un mecanismo de recurrencia como las RNN, utilizan codificaciones posicionales añadidas a las incrustaciones de entrada para proporcionar información sobre la posición de cada token en la secuencia. Esto les permite comprender la posición de cada palabra dentro de la frase.
Para ello, los investigadores propusieron emplear una combinación de varias funciones seno y coseno para crear vectores posicionales, lo que permitiría utilizar este codificador posicional para frases de cualquier longitud.
En este enfoque, cada dimensión está representada por frecuencias y desplazamientos únicos de la onda, con valores que van de -1 a 1, representando efectivamente cada posición.
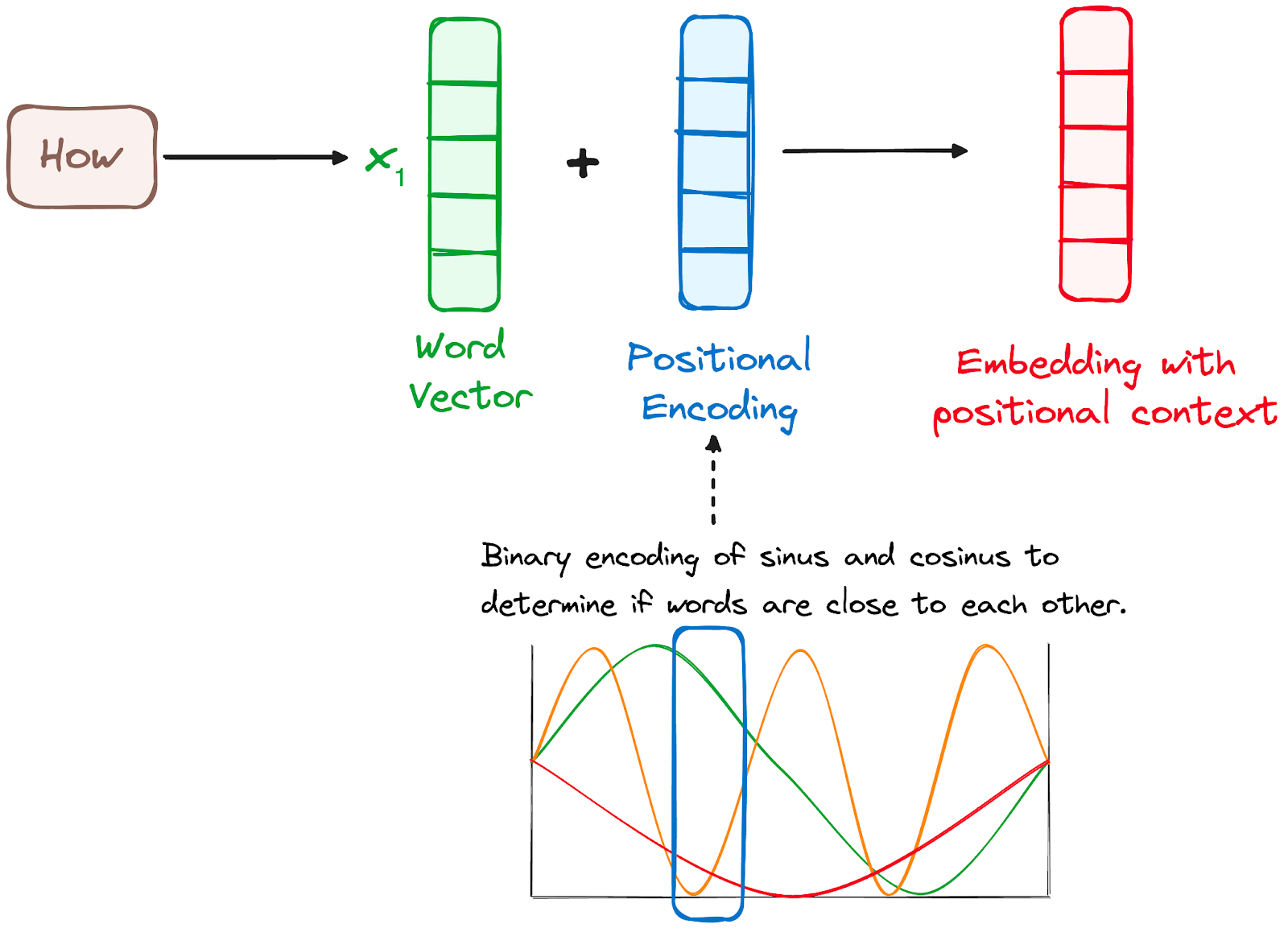
Imagen del autor. Flujo de trabajo del codificador. Codificación posicional.
El codificador Transformer está formado por una pila de capas idénticas (6 en el modelo Transformer original).
La capa codificadora sirve para transformar todas las secuencias de entrada en una representación continua y abstracta que encapsula la información aprendida de toda la secuencia. Esta capa consta de dos submódulos:
Además, incorpora conexiones residuales alrededor de cada subcapa, a las que sigue una normalización de capas.
Imagen del autor. Flujo de trabajo del codificador. Pila de capas codificadoras
En el codificador, la atención múltiple utiliza un mecanismo de atención especializado conocido como autoatención. Este enfoque permite a los modelos relacionar cada palabra de la entrada con otras palabras. Por ejemplo, en un ejemplo dado, el modelo podría aprender a relacionar la palabra "eres" con "tú".
Este mecanismo permite al codificador centrarse en diferentes partes de la secuencia de entrada a medida que procesa cada token. Calcula las puntuaciones de atención en función de:
Este primer módulo de Autoatención permite al modelo captar información contextual de toda la secuencia. En lugar de realizar una única función de atención, las consultas, claves y valores se proyectan linealmente h veces. En cada una de estas versiones proyectadas de consultas, claves y valores, el mecanismo de atención se realiza en paralelo, produciendo valores de salida h-dimensionales.
La arquitectura detallada es la siguiente
Una vez que los vectores de consulta, clave y valor pasan por una capa lineal, se realiza una multiplicación matricial de producto punto entre las consultas y las claves, lo que da lugar a la creación de una matriz de puntuación.
La matriz de puntuación establece el grado de énfasis que cada palabra debe dar a las demás. Por tanto, a cada palabra se le asigna una puntuación en relación con otras palabras dentro del mismo paso temporal. Una puntuación más alta indica una mayor concentración.
Este proceso asigna efectivamente las consultas a sus claves correspondientes.
Imagen del autor. Flujo de trabajo del codificador. Mecanismo de atención - Multiplicación de matrices.
A continuación, las puntuaciones se reducen dividiéndolas por la raíz cuadrada de la dimensión de los vectores de consulta y clave. Este paso se realiza para garantizar gradientes más estables, ya que la multiplicación de valores puede dar lugar a efectos excesivamente grandes.
Imagen del autor. Flujo de trabajo del codificador. Reducir las puntuaciones de atención.
Posteriormente, se aplica una función softmax a las puntuaciones ajustadas para obtener los pesos de atención. Esto da lugar a valores de probabilidad que van de 0 a 1. La función softmax enfatiza las puntuaciones más altas al tiempo que disminuye las puntuaciones más bajas, mejorando así la capacidad del modelo para determinar eficazmente qué palabras deben recibir más atención.
Imagen del autor. Flujo de trabajo del codificador. Puntuaciones ajustadas Softmax.
El siguiente paso del mecanismo de atención consiste en que los pesos derivados de la función softmax se multiplican por el vector de valores, lo que da como resultado un vector de salida.
En este proceso, sólo se conservan las palabras que presentan puntuaciones softmax elevadas. Por último, este vector de salida se introduce en una capa lineal para seguir procesándolo.
Imagen del autor. Flujo de trabajo del codificador. Combinar los resultados Softmax con el vector de valores.
¡Y por fin obtenemos la salida del mecanismo de Atención!
Entonces, te preguntarás ¿por qué se llama Atención Multicabeza?
Recuerda que antes de iniciar todo el proceso, rompemos nuestras consultas, claves y valores h veces. Este proceso, conocido como autoatención, ocurre por separado en cada una de estas etapas o "cabezas" más pequeñas. Cada cabezal hace su magia de forma independiente, conjurando un vector de salida.
Este conjunto pasa por una última capa lineal, como un filtro que afina su actuación colectiva. La belleza aquí reside en la diversidad del aprendizaje a través de cada cabeza, enriqueciendo el modelo codificador con una comprensión robusta y polifacética.
Cada subcapa de una capa codificadora va seguida de un paso de normalización. Además, la salida de cada subcapa se añade a su entrada (conexión residual) para ayudar a mitigar el problema del gradiente evanescente, lo que permite modelos más profundos. Este proceso se repetirá también después de la Red Neuronal Feed-Forward.
Imagen del autor. Flujo de trabajo del codificador. Normalización y conexión residual tras la Atención Multicabeza.
El viaje de la salida residual normalizada continúa mientras navega por una red de avance puntual, una fase crucial para el refinamiento adicional.
Imagina esta red como un dúo de capas lineales, con una activación ReLU encajada entre ellas, actuando de puente. Una vez procesada, la salida emprende un camino familiar: hace un bucle de retorno y se fusiona con la entrada de la red punto a punto feed-forward.
A esta reunión le sigue otra ronda de normalización, para garantizar que todo está bien ajustado y sincronizado para los siguientes pasos.
Imagen del autor. Flujo de trabajo del codificador. Subcapa de la red neuronal Feed-Forward.
La salida de la capa codificadora final es un conjunto de vectores, cada uno de los cuales representa la secuencia de entrada con una rica comprensión contextual. Esta salida se utiliza luego como entrada para el descodificador en un modelo de Transformador.
Esta codificación cuidadosa allana el camino al descodificador, guiándole para que preste atención a las palabras correctas de la entrada cuando llegue el momento de descodificar.
Piensa que es como construir una torre, en la que puedes apilar N capas de codificador. Cada capa de esta pila tiene la oportunidad de explorar y aprender diferentes facetas de la atención, de forma parecida a las capas del conocimiento. Esto no sólo diversifica la comprensión, sino que podría ampliar significativamente la capacidad de predicción de la red de transformadores.
El papel del descodificador se centra en elaborar secuencias de texto. Al igual que el codificador, el descodificador está equipado con un conjunto similar de subcapas. Presenta dos capas de atención multicapas, una capa de avance puntual, e incorpora conexiones residuales y normalización de capas después de cada subcapa.
Imagen del autor. Estructura global de los codificadores.
Estos componentes funcionan de forma parecida a las capas del codificador, pero con un giro: cada capa de atención múltiple del descodificador tiene su misión única.
El final del proceso del descodificador implica una capa lineal, que sirve de clasificador, rematada con una función softmax para calcular las probabilidades de las distintas palabras.
El descodificador Transformer tiene una estructura diseñada específicamente para generar esta salida descodificando paso a paso la información codificada.
Es importante observar que el descodificador funciona de forma autorregresiva, iniciando su proceso con una señal de arranque. Utiliza ingeniosamente como entradas una lista de salidas generadas previamente, junto con las salidas del codificador que son ricas en información de atención de la entrada inicial.
Esta danza secuencial de descodificación continúa hasta que el descodificador llega a un momento crucial: la generación de una ficha que señala el final de su creación de salida.
En la línea de salida del descodificador, el proceso es idéntico al del codificador. Aquí, la entrada pasa primero por una capa de incrustación
Tras la incrustación, al igual que el descodificador, la entrada pasa por la capa de codificación posicional. Esta secuencia está diseñada para producir incrustaciones posicionales.
A continuación, estas incrustaciones posicionales se canalizan hacia la primera capa de atención multicabezal del descodificador, donde se calculan meticulosamente las puntuaciones de atención específicas de la entrada del descodificador.
El descodificador está formado por una pila de capas idénticas (6 en el modelo original de Transformer). Cada capa tiene tres subcomponentes principales:
Esto es similar al mecanismo de autoatención del codificador, pero con una diferencia crucial: impide que las posiciones atiendan a las posiciones posteriores, lo que significa que cada palabra de la secuencia no se ve influida por las fichas futuras.
Por ejemplo, cuando se calculan las puntuaciones de atención de la palabra "eres", es importante que "eres" no se asome a "tú", que es una palabra posterior en la secuencia.
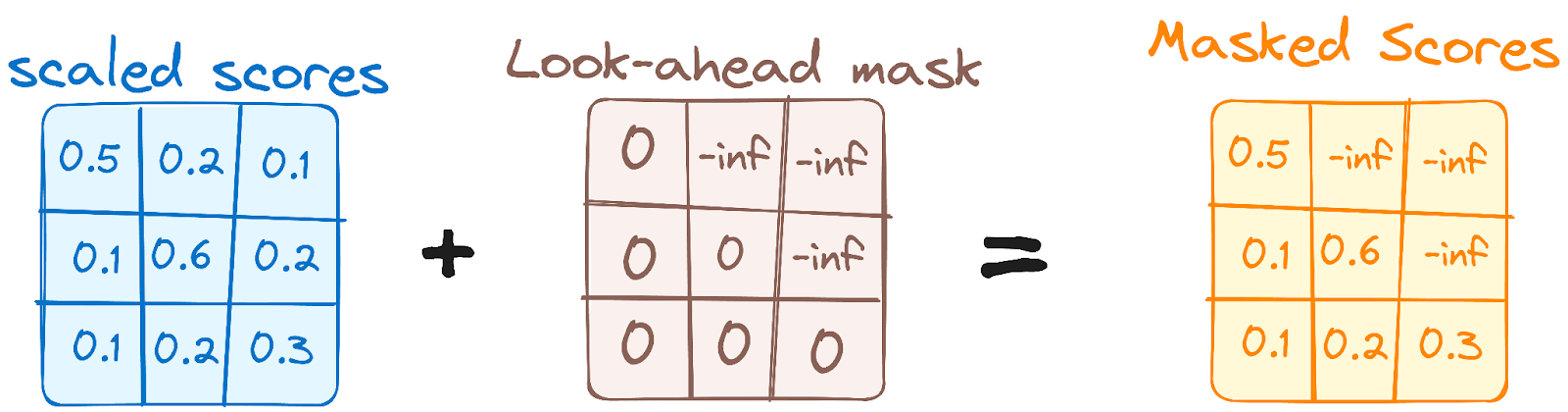
Imagen del autor. Flujo de trabajo del descodificador. Primera Máscara de Atención Multicabeza.
Este enmascaramiento garantiza que las predicciones para una posición concreta sólo puedan depender de los resultados conocidos en posiciones anteriores a ella.
En la segunda capa de atención múltiple del descodificador, vemos una interacción única entre los componentes del codificador y del descodificador. Aquí, las salidas del codificador asumen los papeles tanto de consultas como de claves, mientras que las salidas de la primera capa de atención múltiple del descodificador sirven como valores.
Esta configuración alinea eficazmente la entrada del codificador con la del descodificador, capacitando a éste para identificar y enfatizar las partes más relevantes de la entrada del codificador.
A continuación, la salida de esta segunda capa de atención múltiple se refina mediante una capa de alimentación puntual, mejorando aún más el procesamiento.
Imagen del autor. Flujo de trabajo del descodificador. Atención codificador-decodificador.
En esta subcapa, las consultas proceden de la capa decodificadora anterior, y las claves y valores proceden de la salida del codificador. Esto permite que cada posición del descodificador atienda a todas las posiciones de la secuencia de entrada, integrando eficazmente la información del codificador con la del descodificador.
De forma similar al codificador, cada capa del descodificador incluye una red de avance totalmente conectada, aplicada a cada posición por separado y de forma idéntica.
El viaje de los datos a través del modelo transformador culmina con su paso por una última capa lineal, que funciona como clasificador.
El tamaño de este clasificador corresponde al número total de clases implicadas (número de palabras contenidas en el vocabulario). Por ejemplo, en un escenario con 1000 clases distintas que representan 1000 palabras diferentes, la salida del clasificador será una matriz con 1000 elementos.
A continuación, esta salida se introduce en una capa softmax, que la transforma en una serie de puntuaciones de probabilidad, cada una de ellas comprendida entre 0 y 1. La mayor de estas puntuaciones de probabilidad es la clave, su índice correspondiente señala directamente la palabra que el modelo predice como la siguiente de la secuencia.
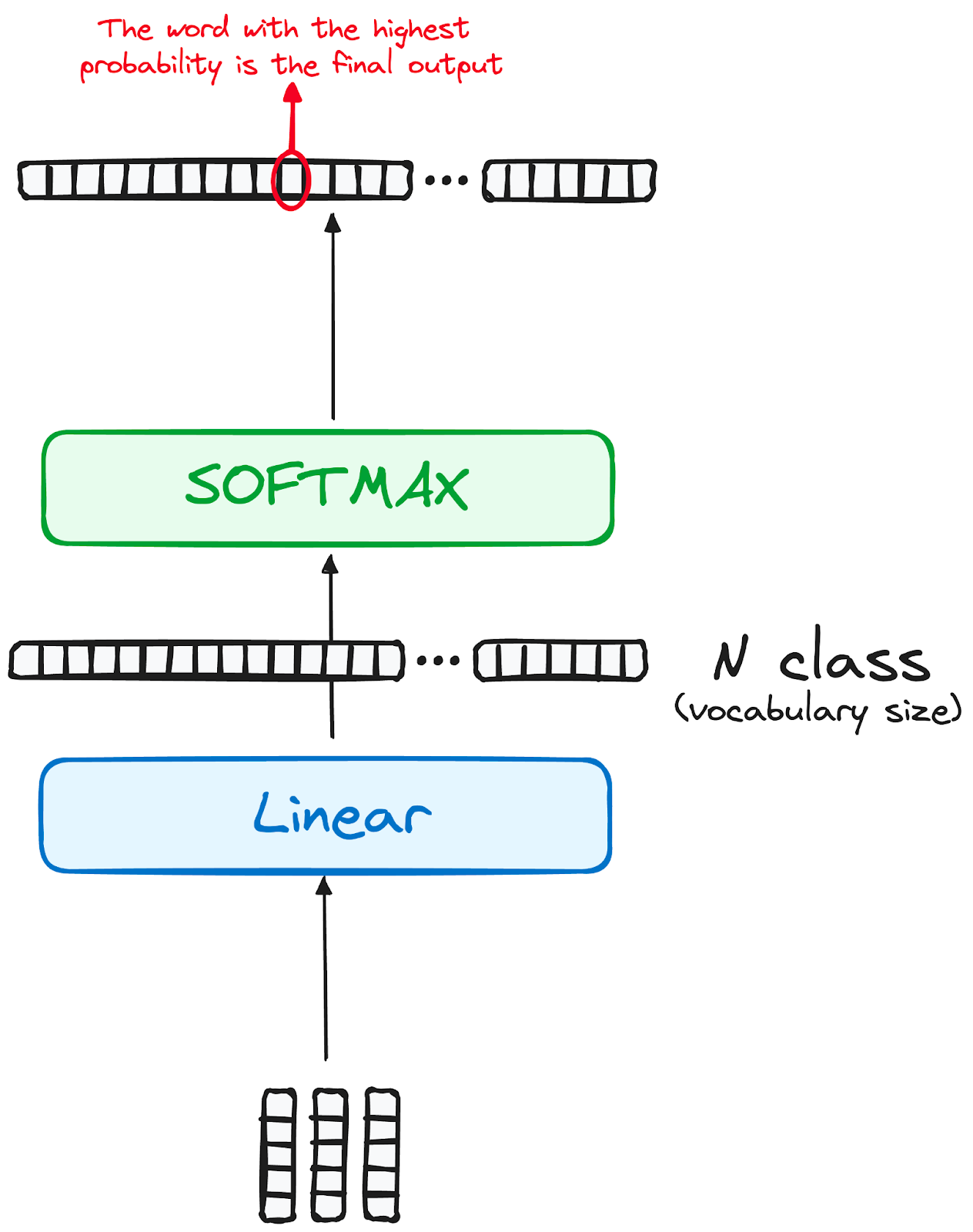
Imagen del autor. Flujo de trabajo del descodificador. Salida final del transformador.
Cada subcapa (autoatención enmascarada, atención codificador-decodificador, red feed-forward) va seguida de un paso de normalización, y cada una incluye también una conexión residual a su alrededor.
La salida de la última capa se transforma en una secuencia predicha, normalmente mediante una capa lineal seguida de una softmax para generar probabilidades sobre el vocabulario.
El descodificador, en su flujo operativo, incorpora la salida recién generada a su lista creciente de entradas, y luego prosigue con el proceso de descodificación. Este ciclo se repite hasta que el modelo predice un token específico, señalando la finalización.
El token predicho con mayor probabilidad se asigna como clase final, a menudo representada por el token final.
Recuerda de nuevo que el descodificador no está limitado a una sola capa. Puede estructurarse con N capas, cada una de las cuales se basa en la entrada recibida del codificador y sus capas precedentes. Esta arquitectura en capas permite al modelo diversificar su enfoque y extraer distintos patrones de atención a través de sus cabezas de atención.
Este enfoque multicapa puede mejorar significativamente la capacidad de predicción del modelo, ya que desarrolla una comprensión más matizada de las distintas combinaciones de atención.
Y la arquitectura final es algo parecido a esto (del documento original)
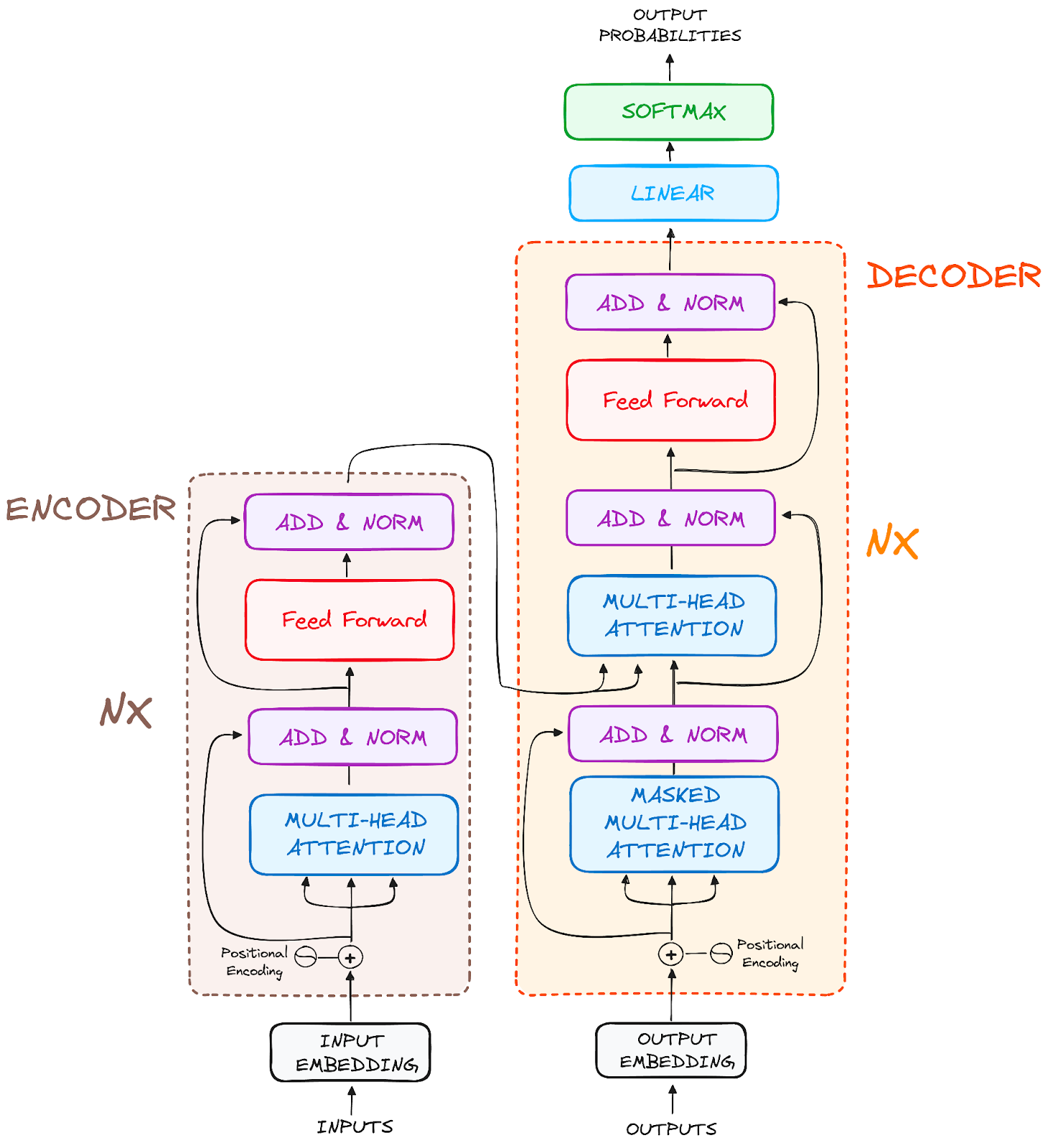
Imagen del autor. Estructura original de Transformers.
Para entender mejor esta arquitectura, te recomiendo que intentes aplicar un Transformador desde cero siguiendo este tutorial para construir un transformador con PyTorch.
El lanzamiento en 2018 de BERT de Google, un marco de procesamiento del lenguaje natural de código abierto, revolucionó la PNL con su exclusivo entrenamiento bidireccional, que permite al modelo hacer predicciones más informadas por el contexto sobre cuál debería ser la siguiente palabra.
Al comprender el contexto de todos los lados de una palabra, BERT superó a los modelos anteriores en tareas como responder preguntas y comprender el lenguaje ambiguo. Su núcleo utiliza Transformadores, que conectan dinámicamente cada elemento de salida y entrada.
BERT, preentrenado en Wikipedia, destacó en varias tareas de PNL, lo que llevó a Google a integrarlo en su motor de búsqueda para realizar consultas más naturales. Esta innovación desencadenó una carrera para desarrollar modelos lingüísticos avanzados e hizo progresar significativamente la capacidad del campo para manejar la comprensión lingüística compleja.
Para saber más sobre BERT, puedes consultar nuestro artículo independiente que presenta el modelo BERT.
LaMDA (Modelo Lingüístico para Aplicaciones de Diálogo) es un modelo basado en Transformer desarrollado por Google, diseñado específicamente para tareas conversacionales, y presentado durante la keynote de Google I/O de 2021. Están diseñados para generar respuestas más naturales y contextualmente relevantes, mejorando las interacciones de los usuarios en diversas aplicaciones.
El diseño de LaMDA le permite comprender y responder a una amplia gama de temas e intenciones del usuario, lo que la hace ideal para aplicaciones en chatbots, asistentes virtuales y otros sistemas interactivos de IA en los que una conversación dinámica es clave.
Este enfoque en la comprensión y respuesta conversacional marca a LaMDA como un avance significativo en el campo del procesamiento del lenguaje natural y la comunicación impulsada por la IA.
Si te interesa comprender mejor los modelos LaMDA, puedes hacerlo con el artículo sobre LaMDA.
GPT y ChatGPT, desarrollados por OpenAI, son modelos generativos avanzados conocidos por su capacidad de producir texto coherente y contextualmente relevante. GPT-1 fue su primer modelo lanzado en junio de 2018 y GPT-3, uno de los modelos de mayor impacto, se lanzó dos años después, en 2020.
Estos modelos son expertos en una amplia gama de tareas, como la creación de contenidos, la conversación, la traducción de idiomas, etc. La arquitectura de GPT le permite generar texto que se asemeja mucho a la escritura humana, lo que lo hace útil en aplicaciones como la escritura creativa, la atención al cliente e incluso la ayuda a la codificación. ChatGPT, una variante optimizada para contextos conversacionales, destaca en la generación de diálogos similares a los humanos, lo que potencia su aplicación en chatbots y asistentes virtuales.
El panorama de los modelos de cimentación, en particular los modelos de transformadores, se está ampliando rápidamente. Un estudio identificó más de 50 modelos de transformadores significativos, mientras que el grupo de Stanford evaluó 30 de ellos, reconociendo el rápido crecimiento del campo. NLP Cloud, una innovadora startup que forma parte del programa Inception de NVIDIA, utiliza comercialmente unos 25 grandes modelos lingüísticos para diversos sectores, como aerolíneas y farmacias.
Hay una tendencia creciente a hacer que estos modelos sean de código abierto, con plataformas como el centro de modelos de Hugging Face a la cabeza. Además, se han desarrollado numerosos modelos basados en Transformer, cada uno especializado para diferentes tareas de PNL, lo que demuestra la versatilidad y eficacia del modelo en diversas aplicaciones.
Puedes saber más de todos los Modelos de Fundación existentes en otro artículo que habla de qué son y cuáles son los más utilizados.
Comparar y evaluar el rendimiento de los modelos Transformer en la PNL implica un enfoque sistemático para valorar su eficacia y eficiencia.
Dependiendo de la naturaleza de la tarea, hay diferentes formas y recursos para hacerlo:
Cuando te enfrentes a tareas de traducción automática, puedes aprovechar conjuntos de datos estándar como el WMT (Taller de Traducción Automática), en el que los sistemas de traducción automática se encuentran con un tapiz de pares de idiomas, cada uno de los cuales ofrece sus propios retos.
Métricas como BLEU, METEOR, TER y chrF sirven como herramientas de navegación, guiándonos hacia la precisión y la fluidez.
Además, las pruebas en diversos ámbitos, como noticias, literatura y textos técnicos, garantizan la adaptabilidad y versatilidad de un sistema de TA, convirtiéndolo en un auténtico políglota en el mundo digital.
Para evaluar los modelos de GC, utilizamos colecciones especiales de preguntas y respuestas, como SQuAD (Stanford Question Answering Dataset), Natural Questions o TriviaQA.
Cada uno es como un juego diferente con sus propias reglas. Por ejemplo, SQuAD trata de encontrar respuestas en un texto dado, mientras que otros son más como un juego de preguntas con preguntas de cualquier parte.
Para ver lo bien que lo hacen estos programas, utilizamos puntuaciones como Precisión, Recall, F1 y, a veces, incluso puntuaciones de coincidencia exacta.
Cuando tratamos la Inferencia del Lenguaje Natural (NLI), utilizamos conjuntos de datos especiales como SNLI (Stanford Natural Language Inference), MultiNLI y ANLI.
Son como grandes bibliotecas de variaciones lingüísticas y casos complicados, que nos ayudan a ver lo bien que entienden nuestros ordenadores distintos tipos de frases. Principalmente comprobamos la precisión de los ordenadores para comprender si las afirmaciones coinciden, se contradicen o no están relacionadas.
También es importante estudiar cómo el ordenador averigua cosas complicadas del lenguaje, como cuándo una palabra se refiere a algo mencionado anteriormente, o cómo entiende "no", "todo" y "algo".
En el mundo de las Redes Neuronales, dos estructuras destacadas suelen compararse con los Transformadores. Cada uno de ellos ofrece ventajas y retos distintos, adaptados a tipos específicos de tratamiento de datos. RNNs, que ya ha aparecido en múltiples ocasiones a lo largo del artículo, y Capas Convolucionales.
Las Capas Recurrentes, piedra angular de las Redes Neuronales Recurrentes (RNN), destacan en el manejo de datos secuenciales. La fuerza de esta arquitectura reside en su capacidad para realizar operaciones secuenciales, cruciales para tareas como el procesamiento del lenguaje o el análisis de series temporales. En una capa recurrente, la salida de un paso anterior se devuelve a la red como entrada para el paso siguiente. Este mecanismo de bucle permite a la red recordar la información anterior, lo que es vital para comprender el contexto en una secuencia.
Sin embargo, como ya hemos comentado, este procesamiento secuencial tiene dos implicaciones principales:
Los modelos transformadores difieren significativamente de las arquitecturas que utilizan capas recurrentes, ya que carecen de recurrencia. Como hemos visto antes, la capa de Atención del Transformador evalúa ambos problemas, lo que la convierte en la evolución natural de las RNN para aplicaciones de PNL.
Por otra parte, las Capas Convolucionales, los componentes básicos de las Redes Neuronales Convolucionales (CNN), son famosas por su eficacia en el procesamiento de datos espaciales como las imágenes.
Estas capas utilizan núcleos (filtros) que escanean los datos de entrada para extraer características. La anchura de estos núcleos puede ajustarse, lo que permite a la red centrarse en rasgos pequeños o grandes, según la tarea que tenga entre manos.
Aunque las Capas Convolucionales son excepcionalmente buenas para captar jerarquías espaciales y patrones en los datos, se enfrentan a retos con las dependencias a largo plazo. No tienen en cuenta intrínsecamente la información secuencial, por lo que son menos adecuados para tareas que requieren comprender el orden o el contexto de una secuencia.
Por eso las CNN y los Transformadores se adaptan a distintos tipos de datos y tareas. Las CNN dominan en el campo de la visión por ordenador debido a su eficacia en el procesamiento de la información espacial, mientras que los Transformadores son la mejor elección para tareas secuenciales complejas, especialmente en PNL, debido a su capacidad para comprender las dependencias de largo alcance.
En conclusión, los Transformers han supuesto un avance monumental en el campo de la inteligencia artificial, la PNL.
Al gestionar eficazmente los datos secuenciales mediante su mecanismo único de autoatención, estos modelos han superado a las RNN tradicionales. Su capacidad para manejar secuencias largas de forma más eficiente y paralelizar el procesamiento de datos acelera significativamente el entrenamiento.
Modelos pioneros como el BERT de Google y la serie GPT de OpenAI ejemplifican el impacto transformador de los Transformadores en la mejora de los motores de búsqueda y la generación de textos similares a los humanos.
Como resultado, se han hecho indispensables en el aprendizaje automático moderno, impulsando los límites de la IA y abriendo nuevas vías en los avances tecnológicos.
Si quieres adentrarte en los Transformers y su uso, nuestro artículo sobre Transformers y Cara de Abrazo es un comienzo perfecto. También puedes aprender a construir un Transformer con PyTorch con nuestra guía en profundidad.
Más información sobre los transformadores y los LLM
Curso
Curso
Curso
Tutorial
Arjun Sarkar
Tutorial
Zoumana Keita
Tutorial
Joanne Xiong
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Kurtis Pykes




