
Programa
Associate AI Engineer para desenvolvedores
26 h
O SAM 3 é o novo “segment anything” que consegue encontrar todas as instâncias de um conceito por meio de prompts de texto curtos ou exemplos e retornar máscaras com precisão de pixel em imagens e vídeos. Isso torna-o perfeito para tarefas práticas de privacidade, como desfocar rostos, placas de veículos ou telas, sem precisar fazer seleções manualmente ou escrever detectores clássicos.
Neste tutorial, vamos criar um filtro de privacidade SAM3 no Colab usando uma interface Gradio. É só enviar uma imagem ou vídeo, digitar uma instrução (como rostos, placas de carros) e o SAM3 vai mostrar máscaras de instância pra gente desfocar só esses pixels. Vamos ver como configurar, criar máscaras, aplicar um desfoque gaussiano e conectar o aplicativo Gradio para exportar os arquivos finais.
O Segment Anything Model 3 (SAM 3) é o modelo unificado da Meta para detecção, segmentação e rastreamento de vocabulário aberto em imagens e vídeos. Em vez de configurar detectores separados para cada classe, você pode solicitar frases curtas ou exemplos, e o SAM 3 retorna máscaras por instância.
Por baixo do capô, o SAM 3 junta um codificador de texto e um codificador de imagem com um detector tipo DETR e um rastreador derivado do SAM-2 com um banco de memória. Em cada quadro, ele detecta máscaras para o seu conceito a partir do prompt, propaga as máscaras para a frente através do rastreador e mescla as máscaras recém-detectadas e rastreadas na saída final para esse quadro.
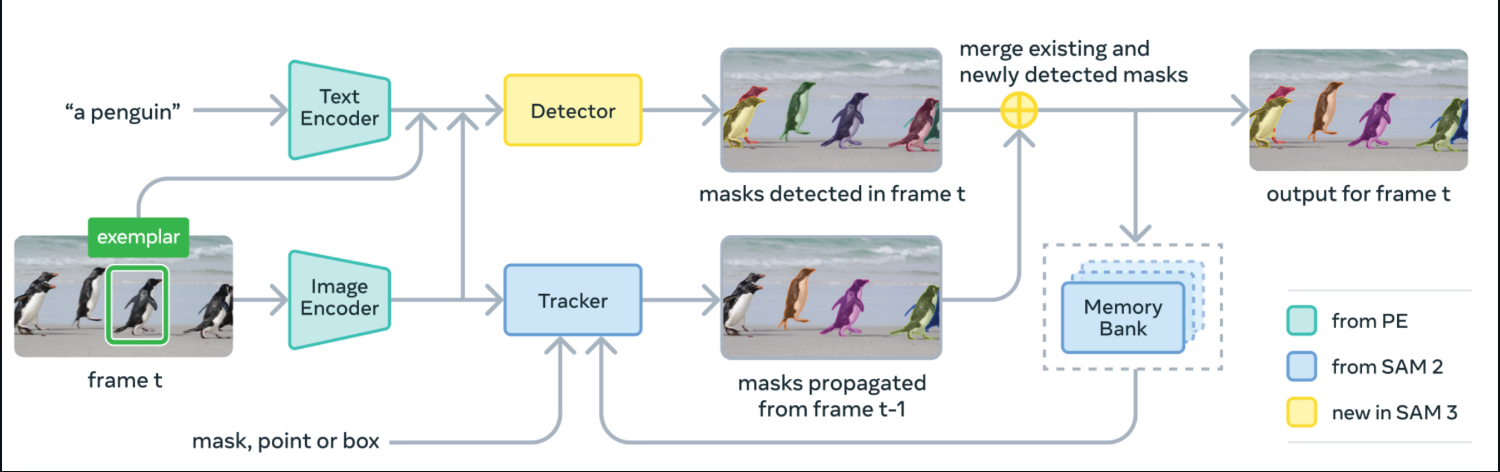
Fonte: SAM3 GitHub
O SAM 3 foi lançado com pesos de modelo, código de ajuste fino e dados de avaliação, incluindo o benchmark SA-Co para segmentação de conceitos promptáveis.
Nos relatórios da Meta, mostra ganhos de ~2x em relação a linhas de base sólidas na segmentação de vocabulário aberto em imagens e vídeos, mantendo os pontos fortes interativos do SAM-2.
Neste tutorial, vamos pegar essas máscaras SAM 3 e transformá-las em uma composição com desfoque gaussiano para imagens e vídeos, envolvida em uma interface Gradio.
Nesta seção, vamos criar um filtro de privacidade com SAM3 para imagens e vídeos incorporados em uma interface de usuário Gradio simples.
Funciona assim:
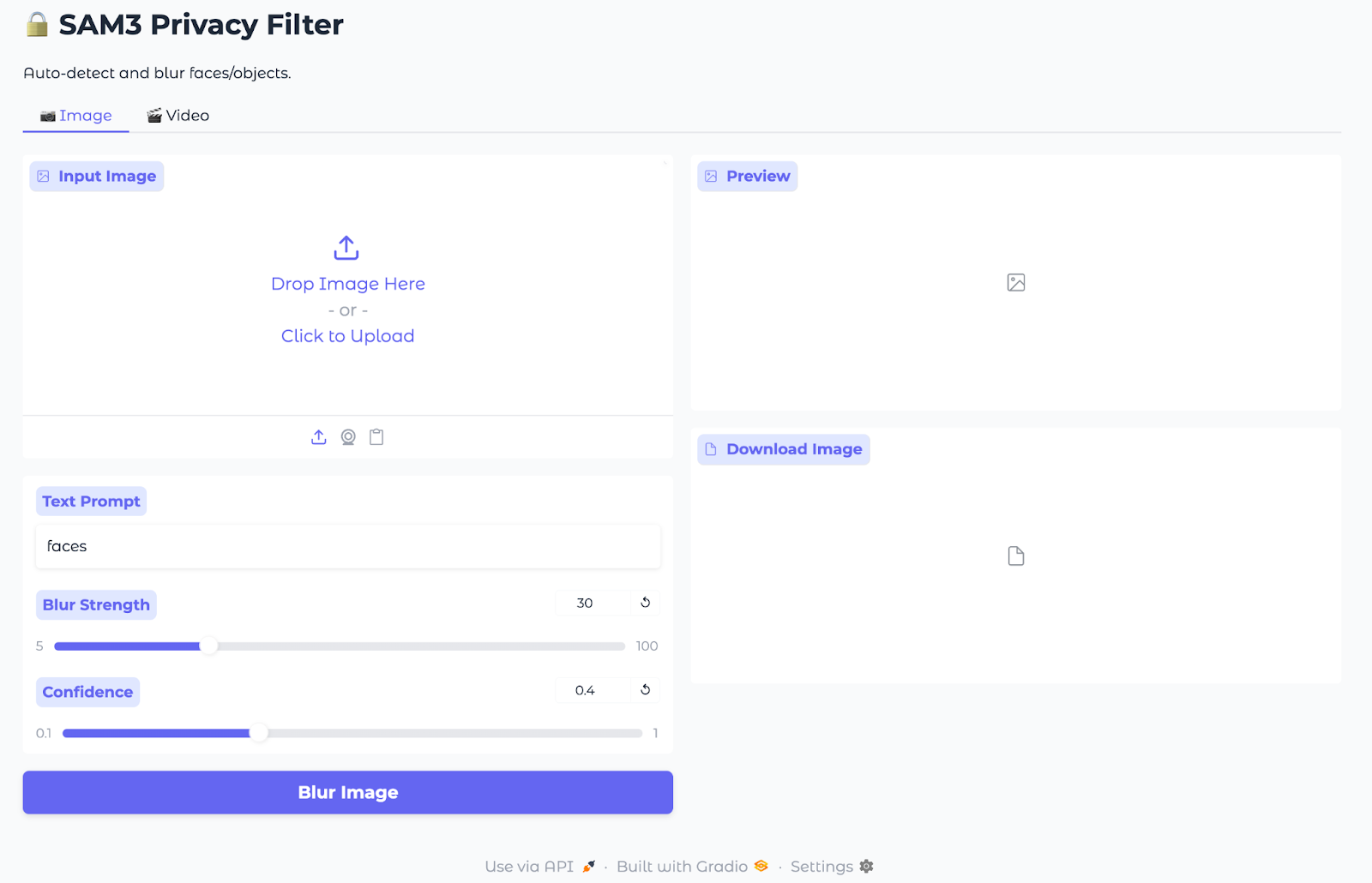
Vamos ver a implementação completa em pequenas etapas.
Antes de rodar essa demonstração, vamos ver se temos tudo o que precisa. Para rodar o Filtro de Privacidade SAM3 no Colab, você precisa do mais recente Transformers, junto com algumas bibliotecas de tempo de execução para UI, operações tensoriais, imagens e E/S de vídeo. O trecho abaixo instala tudo de uma vez só.
import subprocess
import sys
import os
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", "-q", package])
print(" Installing latest Transformers")
install("git+https://github.com/huggingface/transformers.git")
pkgs = [
"accelerate",
"gradio",
"numpy",
"pillow",
"torch",
"torchvision",
"imageio[ffmpeg]"
]
for p in pkgs:
install(p)Aqui está o que cada pré-requisito faz:
git+https://github.com/huggingface/transformers.git: Isso pega a biblioteca mais recente Transformers da fonte, então as classes Sam3Processor e Sam3Model ficam disponíveis.torch e torchvision: Esses são os utilitários de computação tensorial e imagem que executam a passagem direta do SAM3.accelerate: Esse é o auxiliar de inferência usado pelo Transformers.gradio: Uma interface de usuário leve para fazer upload de mídia e ver resultados borrados.numpy, pillow: Isso inclui matrizes de imagens e operações de imagem PIL para composição de máscara/desfoque.imageio[ffmpeg]: Ele lê/grava vídeos e codifica MP4 (FFmpeg) para a guia de vídeo.Depois que o ambiente estiver configurado e o facebook/sam3 carregado, a demonstração permite segmentar com prompts de texto curtos e desfocar as máscaras resultantes em imagens ou vídeos por meio de um aplicativo Gradio simples.
Observação: Se você planeja usar uma GPU no Colab, defina o tempo de execução para GPU (T4/A100) antes da instalação. Usei uma GPU A100 no Colab pra ter uma experiência mais rápida.
Depois de configurar o ambiente, importe as bibliotecas que alimentam a interface do usuário, a inferência do modelo, o manuseio de imagens/vídeos e o tempo. Esses são os únicos módulos que você precisa para o filtro de privacidade SAM3.
import gradio as gr
import torch
import numpy as np
import imageio
from PIL import Image, ImageFilter
from transformers import Sam3Processor, Sam3Model
import timeAgora, Gradio fornece a interface web, a biblioteca transformers executa o SAM3 e PyTorch executa a inferência na GPU ou CPU. Enquanto PIL carrega e edita imagens (incluindo desfoque gaussiano), NumPy gerencia as matrizes de máscara e imageio lê e grava arquivos de vídeo.
Depois, vamos carregar o modelo e criar um pequeno mecanismo que transforma comandos de texto em máscaras que você pode desfocar.
Agora que o ambiente está pronto, vamos colocar o SAM3 em um pequeno mecanismo que carrega o modelo uma vez, executa a segmentação de instância solicitada por texto sob demanda e retorna máscaras binárias que são usadas para desfocar.
class Sam3PrivacyEngine:
def __init__(self):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model = None
self.processor = None
print(f"Initializing SAM3 on {self.device}")
try:
self.model = Sam3Model.from_pretrained("facebook/sam3").to(self.device)
self.processor = Sam3Processor.from_pretrained("facebook/sam3")
print("SAM3 Loaded Successfully!")
except Exception as e:
print(f"Error loading SAM3: {e}")
def predict_masks(self, image_pil, text_prompt, threshold=0.4):
if self.model is None: return []
inputs = self.processor(
images=image_pil,
text=text_prompt,
return_tensors="pt"
).to(self.device)
with torch.no_grad():
outputs = self.model(**inputs)
results = self.processor.post_process_instance_segmentation(
outputs,
threshold=threshold,
mask_threshold=0.5,
target_sizes=inputs["original_sizes"].tolist()
)[0]
masks = []
if "masks" in results:
for i, mask_tensor in enumerate(results["masks"]):
mask_np = (mask_tensor.cpu().numpy() * 255).astype(np.uint8)
mask_pil = Image.fromarray(mask_np)
masks.append(mask_pil)
return masks
engine = Sam3PrivacyEngine()Vamos entender como esse mecanismo se encaixa no pipeline:
Sam3PrivacyEngine.init(): Esse inicializador escolhe o melhor dispositivo (CUDA, se disponível, caso contrário, CPU), carrega os pesos facebook/sam3 e o par Sam3Processor e move o modelo para o dispositivo escolhido para que a inferência possa ser executada de forma eficiente.Sam3PrivacyEngine.predict_masks(): Esse método cria entradas de modelo a partir de uma imagem PIL e um prompt de texto, faz a inferência direta com um torch.no_grad() e para evitar sobrecarga de gradiente e pós-processa as saídas com um post_process_instance_segmentation e usando os limites de detecção e máscara fornecidos, além dos tamanhos originais dos alvos para o dimensionamento correto. Ele retorna máscaras de segmentação por instância convertidas de tensores para matrizes NumPy e, em seguida, para máscaras PIL “L” (imagens em escala de cinza de 8 bits (modo “L”), em que cada pixel é um valor de 0 a 255) para composição.engine = Sam3PrivacyEngine(): Essa linha cria uma única instância reutilizável do mecanismo, de modo que o modelo SAM3 é carregado uma vez e pode ser chamado repetidamente para imagens ou quadros de vídeo sem reinicialização.Com esse mecanismo independente inicializado, você pode transformar qualquer imagem e texto em máscaras de instância. Depois, vamos aplicar o desfoque de forma seletiva usando essas máscaras e incorporar tudo na interface do Gradio.
Nesta seção, pegamos as máscaras do SAM3 e aplicamos privacidade. Ele desfoca só as áreas mascaradas, deixando o resto como está. Começamos com uma função de desfoque gaussiano reutilizável e, em seguida, conectamo-la a dois pipelines, um para imagens e outro para vídeos.
Esse auxiliar pega uma imagem e uma ou mais máscaras PIL “L”, mistura tudo numa única máscara composta e cola uma cópia desfocada da imagem só onde a máscara é branca (255).
def apply_blur_pure(image_pil, masks, blur_strength):
if not masks:
return image_pil
radius = blur_strength
blurred_image = image_pil.filter(ImageFilter.GaussianBlur(radius=radius))
composite_mask = Image.new("L", image_pil.size, 0)
for mask in masks:
composite_mask.paste(255, (0, 0), mask=mask)
final_image = image_pil.copy()
final_image.paste(blurred_image, (0, 0), mask=composite_mask)
return final_imageVeja como essa função funciona:
GaussianBlur() primeiro cria uma versão totalmente desfocada da imagem. Enquanto composite_mask é uma máscara “L” (escala de cinza) inicializada em preto (0 = manter o original). composite_mask, para que apenas as regiões brancas fiquem desfocadas.final_image.paste() ” só troca os pixels mascarados, deixando o resto como está para garantir a melhor qualidade visual possível.Com uma única chamada, você pode desfocar qualquer conjunto de regiões, como rostos, telas, placas, mantendo os fundos como estão.
Essa etapa cobre todo o fluxo da imagem, desde a normalização da entrada até a obtenção de máscaras do SAM3, passando pelo desfoque dos pixels mascarados e, por fim, o retorno do resultado.
def process_image(input_img, text_prompt, blur_strength, confidence):
if input_img is None: return None, None
if isinstance(input_img, np.ndarray):
image_pil = Image.fromarray(input_img).convert("RGB")
else:
image_pil = input_img.convert("RGB")
masks = engine.predict_masks(image_pil, text_prompt, confidence)
result_pil = apply_blur_pure(image_pil, masks, blur_strength)
output_path = "privacy_image.png"
result_pil.save(output_path)
return np.array(result_pil), output_pathA gente lida com imagens usando o seguinte pipeline passo a passo:
engine.predict_masks() para pegar as máscaras de instância SAM3 para o text_prompt fornecido.apply_blur_pure() com o blur_strength que escolhemos, pra que só as áreas mascaradas fiquem desfocadas.png e devolve tanto uma matriz NumPy quanto um arquivo para baixar.Com o fluxo de imagens concluído, agora podemos seguir para o pipeline de vídeo.
O fluxo de vídeo reflete o caminho da imagem, mas transmite quadro a quadro com imageio. Para cada quadro, a gente segmenta, desfoca as regiões mascaradas e grava em um arquivo MP4 codificado em H.264.
def process_video(video_path, text_prompt, blur_strength, confidence, max_frames):
if not video_path: return None, None
try:
reader = imageio.get_reader(video_path)
meta = reader.get_meta_data()
fps = meta.get('fps', 24)
output_path = "privacy_video.mp4"
writer = imageio.get_writer(
output_path,
fps=fps,
codec='libx264',
pixelformat='yuv420p',
macro_block_size=1
)
print("Starting video processing...")
for i, frame in enumerate(reader):
if i >= max_frames:
break
frame_pil = Image.fromarray(frame).convert("RGB")
masks = engine.predict_masks(frame_pil, text_prompt, confidence)
processed_pil = apply_blur_pure(frame_pil, masks, blur_strength)
writer.append_data(np.array(processed_pil))
if i % 10 == 0:
print(f"Processed frame {i}...")
writer.close()
reader.close()
print("Video processing complete.")
return output_path, output_path
except Exception as e:
print(f"Error: {e}")
return None, NoneAqui está como lidamos com vídeos com o seguinte pipeline:
imageio.get_reader(), depois iteramos os quadros e lemos o FPS dos metadados (padrão 24, se estiver faltando).engine.predict_masks() e desfoca as regiões mascaradas com a função apply_blur_pure().pixelformat='yuv420p' para ampla compatibilidade e macro_block_size=1 para evitar artefatos de alinhamento.Com esse fluxo de vídeo, você pode ocultar áreas confidenciais em gravações de reuniões, vídeos de câmeras de bordo ou capturas de tela usando um simples comando de texto.
Agora que o mascaramento e o desfoque estão prontos, vamos colocar tudo em uma interface Gradio leve para que qualquer pessoa possa enviar uma imagem ou vídeo, digitar um prompt de texto e baixar o resultado.
with gr.Blocks(title="SAM3 Privacy Filter", theme=gr.themes.Soft()) as demo:
gr.Markdown("# SAM3 Privacy Filter")
gr.Markdown("Auto-detect and blur faces/objects.")
with gr.Tabs():
with gr.Tab("Image"):
with gr.Row():
with gr.Column():
im_input = gr.Image(label="Input Image", type="numpy")
im_prompt = gr.Textbox(label="Text Prompt", value="faces")
im_blur = gr.Slider(5, 100, value=30, label="Blur Strength")
im_conf = gr.Slider(0.1, 1.0, value=0.4, label="Confidence")
im_btn = gr.Button("Blur Image", variant="primary")
with gr.Column():
im_output = gr.Image(label="Preview")
im_dl = gr.File(label="Download Image")
im_btn.click(process_image, [im_input, im_prompt, im_blur, im_conf], [im_output, im_dl])
with gr.Tab("Video"):
with gr.Row():
with gr.Column():
vid_input = gr.Video(label="Input Video")
vid_prompt = gr.Textbox(label="Text Prompt", value="faces")
vid_blur = gr.Slider(5, 100, value=30, label="Blur Strength")
vid_conf = gr.Slider(0.1, 1.0, value=0.4, label="Confidence")
vid_limit = gr.Slider(10, 300, value=60, step=10, label="Max Frames")
vid_btn = gr.Button("Blur Video", variant="primary")
with gr.Column():
vid_output = gr.Video(label="Preview")
vid_dl = gr.File(label="Download Video")
vid_btn.click(process_video, [vid_input, vid_prompt, vid_blur, vid_conf, vid_limit], [vid_output, vid_dl])
demo.launch(share=True, debug=True)O aplicativo Gradio incorpora o pipeline de mascaramento e desfoque SAM3 a uma interface de usuário web simples usando:
gr.Blocks): Esse bloco cria um aplicativo Gradio de página única com um título e duas guias, uma para imagens e outra para vídeos, para que os usuários possam alternar entre os modos sem sair da página.process_image ” (Desfoque a imagem), que chama o SAM3 pra máscaras e aplica o desfoque gaussiano só nos pixels mascarados.process_video ” (Desfoque vídeo ), repetindo quadros para prever máscaras, desfocar regiões mascaradas e codificar um vídeo “ H.264 ”.demo.launch() ` inicia o aplicativo, gera um link compartilhável e exibe rastreamentos detalhados da pilha quando a depuração está ativada.Agora, nosso Filtro de Privacidade SAM3 está pronto para carregar mídia (imagem/vídeo), definir avisos e limites e exportar os resultados desfocados.
Observação: Todas as imagens e vídeos nesta demonstração são provenientes de Pexels.com e são de uso gratuito.
Cursos mais populares do DataCamp
Programa
Curso
Curso
blog
blog
Richie Cotton
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan



