
programa
Desarrollo de aplicaciones de IA
21 h
Los LLM son tan potentes, pero a menudo pueden ser un poco lentos, y esto no es lo ideal en situaciones en las que necesitamos velocidad. Descodificación especulativa es una técnica diseñada para acelerar los LLM generando respuestas más rápidamente sin comprometer la calidad.
En esencia, es una forma de "adivinar por adelantado" en el proceso de generación de texto, haciendo predicciones sobre las palabras que podrían venir a continuación sin dejar de permitir la precisión y profundidad que esperamos de los LLM.
En este blog, te explicaré qué es la descodificación especulativa, cómo funciona y cómo aplicarla con los modelos Gemma 2.
La descodificación especulativa acelera los LLM incorporando un modelo más pequeño y rápido que genera predicciones preliminares. Este modelo más pequeño, a menudo llamado modelo "borrador", genera un lote de fichas que el LLM principal, más potente, puede confirmar o refinar. El modelo borrador actúa como una primera pasada, produciendo múltiples fichas que aceleran el proceso de generación.
En lugar de que el LLM principal genere tokens secuencialmente, el modelo borrador proporciona un conjunto de candidatos probables, y el modelo principal los evalúa en paralelo. Este método reduce la carga computacional del LLM principal al descargar las predicciones iniciales, permitiéndole centrarse sólo en las correcciones o validaciones.
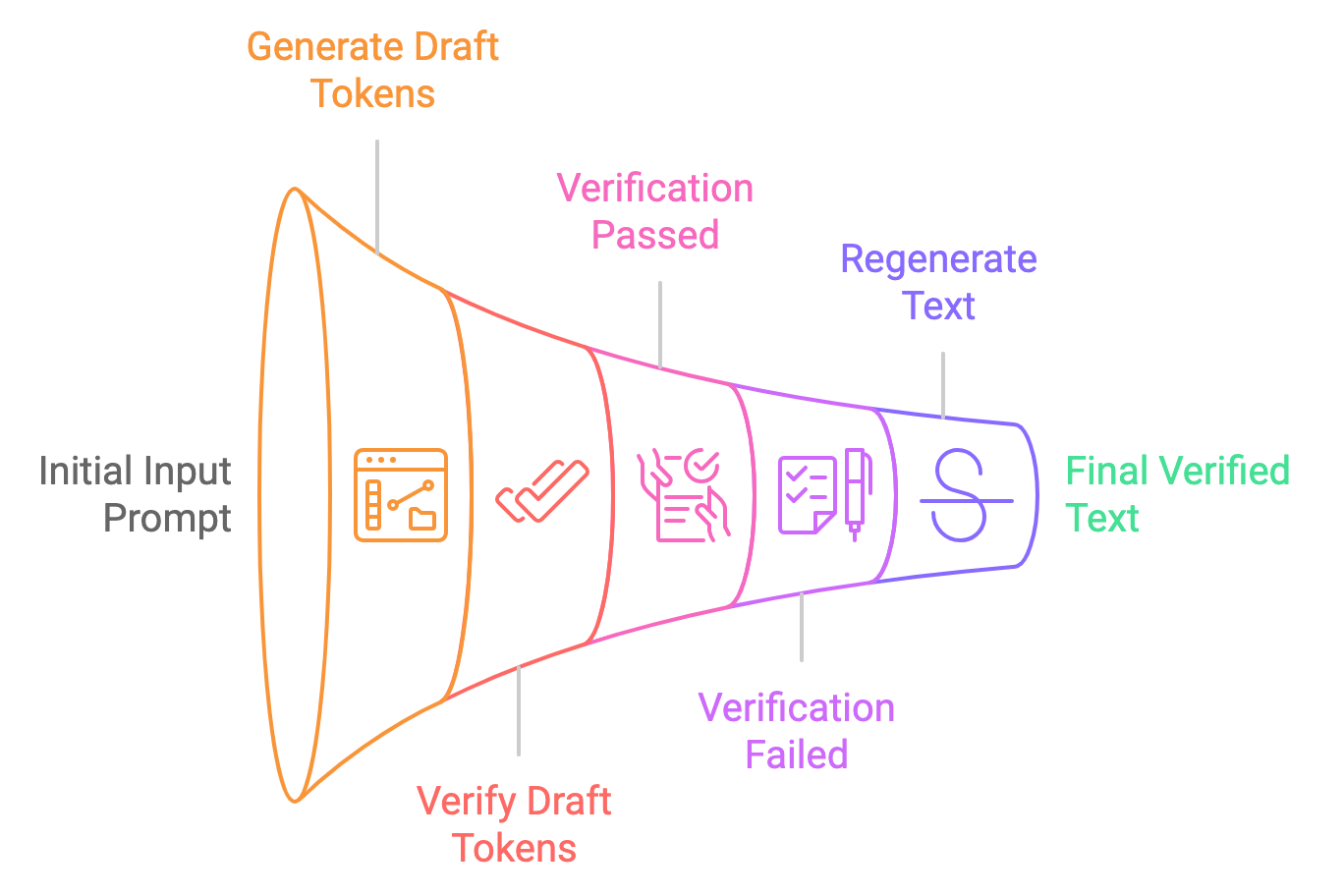
Piensa en ello como un escritor con un editor. El LLM principal es el escritor, capaz de producir textos de alta calidad pero a un ritmo más lento. Un modelo de "borrador" más pequeño y rápido actúa como editor, generando rápidamente posibles continuaciones del texto. A continuación, el LLM principal evalúa estas sugerencias, incorporando las acertadas y descartando el resto. Esto permite al LLM procesar varios tokens simultáneamente, acelerando la generación de texto.
Desglosemos el proceso de descodificación especulativa en sencillos pasos:
La descodificación tradicional procesa los tokens de uno en uno, lo que provoca una gran latencia, pero la descodificación especulativa permite que un modelo más pequeño genere tokens en masa, y que el modelo más grande los verifique. Esto puede reducir el tiempo de respuesta en un 30-40%, recortando la latencia de 25-30 segundos a tan sólo 15-18 segundos.
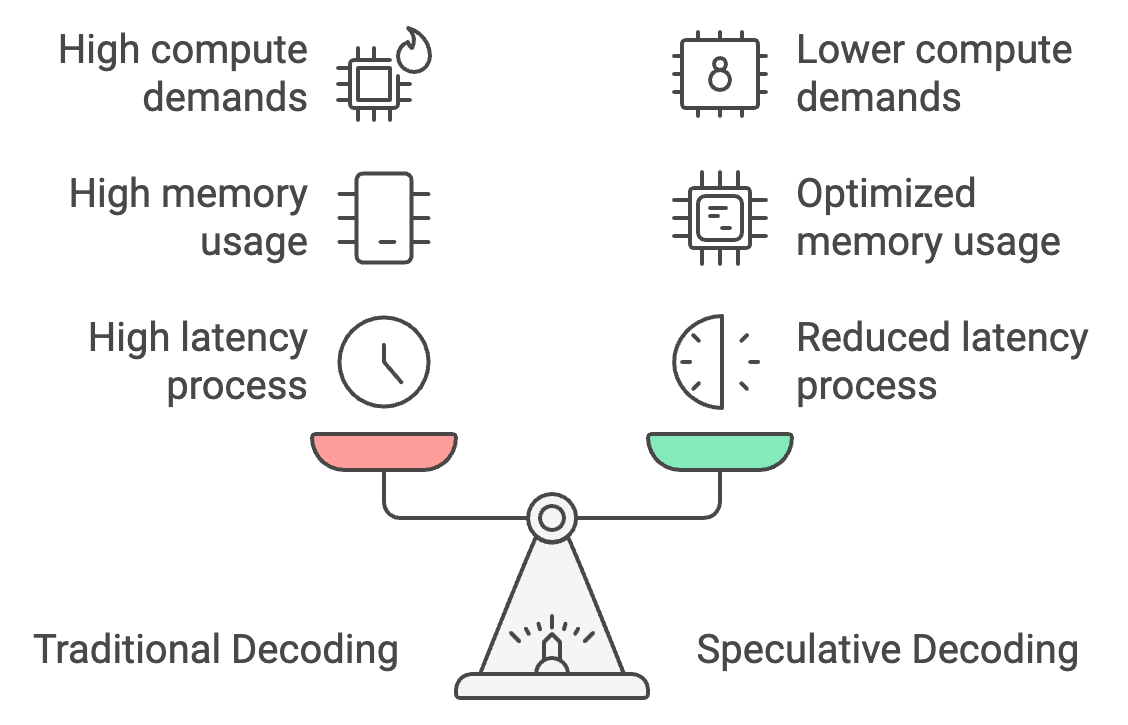
Además, la descodificación especulativa optimiza el uso de memoria desplazando la mayor parte de la generación de tokens al modelo más pequeño, reduciendo los requisitos de memoria de 26 GB a unos 14 GB y haciendo que en el dispositivo en el dispositivo.
Por último, reduce las demandas de cálculo en un 50%, ya que el modelo más grande sólo verifica en lugar de generar fichas, lo que permite un rendimiento más suave en dispositivos móviles con potencia limitada y evita el sobrecalentamiento.
Poner en práctica un ejemplo práctico de descodificación especulativa utilizando los modelos Gemma2. Exploraremos cómo se compara la descodificación especulativa con la inferencia estándar, tanto en términos delatencia como de rendimiento.
Para empezar, importa las dependencias y establece la semilla.
A continuación, comprueba si la GPU está disponible en la máquina en la que estás operando. Esto es necesario principalmente para modelos grandes como Gemma 2-9B-it o LLama2-13B.
Por último, cargamos el modelo pequeño y el grande junto con sus tokenizadores. Aquí utilizamos el modelo Gemma2-2b-it (instruir) para el proyecto de modelo y el modelo Gemma2-9b-it para la verificación.
También hay otros modelos que pueden utilizarse alternativamente. Por ejemplo:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
# Set Seed
set_seed(42)
# Check if GPU is available
device = "cuda" if torch.cuda.is_available() else "cpu"
# Load the smaller Gemma2 model (draft generation)
small_tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b-it", device_map="auto")
small_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it", device_map="auto", torch_dtype=torch.bfloat16)
# Load the larger Gemma2 model (verification)
big_tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it", device_map="auto")
big_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it", device_map="auto", torch_dtype=torch.bfloat16)En primer lugar, realizamos la inferencia sólo en el modelo grande (Gemma2-9b-it) y generamos el resultado. Empieza por tokenizando el prompt de entrada y moviendo los tokens al dispositivo correcto (GPU si está disponible). El método generate produce la salida del modelo, generando hasta max_new_tokens. A continuación, el resultado se descodifica a partir de los identificadores de los tokens para volver a convertirlos en texto legible por humanos.
def normal_inference(big_model, big_tokenizer, prompt, max_new_tokens=50):
inputs = big_tokenizer(prompt, return_tensors='pt').to(device)
outputs = big_model.generate(inputs['input_ids'], max_new_tokens=max_new_tokens)
return big_tokenizer.decode(outputs[0], skip_special_tokens=True)A continuación, probamos el método de descodificación especulativa, en el que seguimos los siguientes pasos:
def speculative_decoding(small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens=50):
# Step 1: Use the small model to generate the draft
inputs = small_tokenizer(prompt, return_tensors='pt').to(device)
small_outputs = small_model.generate(inputs['input_ids'], max_new_tokens=max_new_tokens)
draft = small_tokenizer.decode(small_outputs[0], skip_special_tokens=True)
# Step 2: Verify the draft with the big model
big_inputs = big_tokenizer(draft, return_tensors='pt').to(device)
# Step 3: Calculate log-likelihood of the draft tokens under the large model
with torch.no_grad():
outputs = big_model(big_inputs['input_ids'])
log_probs = torch.log_softmax(outputs.logits, dim=-1)
draft_token_ids = big_inputs['input_ids']
log_likelihood = 0
for i in range(draft_token_ids.size(1) - 1):
token_id = draft_token_ids[0, i + 1]
log_likelihood += log_probs[0, i, token_id].item()
avg_log_likelihood = log_likelihood / (draft_token_ids.size(1) - 1)
# Return the draft and its log-likelihood score
return draft, avg_log_likelihoodNota: La log-verosimilitud es el logaritmo de la probabilidad que un modelo asigna a una secuencia concreta de fichas. Aquí, refleja la probabilidad o "confianza" que tiene el modelo en que la secuencia de tokens (el texto generado) es válida dados los tokens anteriores.
Tras aplicar ambas técnicas, podemos medir sus respectivas latencias. Para la descodificación especulativa, evaluamos el rendimiento examinando el valor de log-verosimilitud. Un valor de log-verosimilitud próximo a cero, sobre todo en el rango negativo, indica que el texto generado es exacto.
def measure_latency(small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens=50):
# Measure latency for normal inference (big model only)
start_time = time.time()
normal_output = normal_inference(big_model, big_tokenizer, prompt, max_new_tokens)
normal_inference_latency = time.time() - start_time
print(f"Normal Inference Output: {normal_output}")
print(f"Normal Inference Latency: {normal_inference_latency:.4f} seconds")
print("\n\n")
# Measure latency for speculative decoding
start_time = time.time()
speculative_output, log_likelihood = speculative_decoding(
small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens
)
speculative_decoding_latency = time.time() - start_time
print(f"Speculative Decoding Output: {speculative_output}")
print(f"Speculative Decoding Latency: {speculative_decoding_latency:.4f} seconds")
print(f"Log Likelihood (Verification Score): {log_likelihood:.4f}")
return normal_inference_latency, speculative_decoding_latencyEsto vuelve:
La menor latencia se debe a que el modelo más pequeño tarda menos en generar el texto y el modelo más grande tarda menos sólo en verificar el texto generado.
Comparemos la descodificación especulativa con la inferencia autorregresiva utilizando cinco indicaciones:
# List of 5 prompts
prompts = [
"The future of artificial intelligence is ",
"Machine learning is transforming the world by ",
"Natural language processing enables computers to understand ",
"Generative models like GPT-3 can create ",
"AI ethics and fairness are important considerations for "
]
# Inference settings
max_new_tokens = 200
# Initialize accumulators for latency, memory, and tokens per second
total_tokens_per_sec_normal = 0
total_tokens_per_sec_speculative = 0
total_normal_latency = 0
total_speculative_latency = 0
# Perform inference on each prompt and accumulate the results
for prompt in prompts:
normal_latency, speculative_latency, _, _, tokens_per_sec_normal, tokens_per_sec_speculative = measure_latency_and_memory(
small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens
)
total_tokens_per_sec_normal += tokens_per_sec_normal
total_tokens_per_sec_speculative += tokens_per_sec_speculative
total_normal_latency += normal_latency
total_speculative_latency += speculative_latency
# Calculate averages
average_tokens_per_sec_normal = total_tokens_per_sec_normal / len(prompts)
average_tokens_per_sec_speculative = total_tokens_per_sec_speculative / len(prompts)
average_normal_latency = total_normal_latency / len(prompts)
average_speculative_latency = total_speculative_latency / len(prompts)
# Output the averages
print(f"Average Normal Inference Latency: {average_normal_latency:.4f} seconds")
print(f"Average Speculative Decoding Latency: {average_speculative_latency:.4f} seconds")
print(f"Average Normal Inference Tokens per second: {average_tokens_per_sec_normal:.2f} tokens/second")
print(f"Average Speculative Decoding Tokens per second: {average_tokens_per_sec_speculative:.2f} tokens/second")Average Normal Inference Latency: 25.0876 seconds
Average Speculative Decoding Latency: 15.7802 seconds
Average Normal Inference Tokens per second: 7.97 tokens/second
Average Speculative Decoding Tokens per second: 12.68 tokens/secondEsto demuestra que la descodificación especulativa es más eficaz, ya que genera más fichas por segundo que la inferencia normal. Esta mejora se debe a que el modelo más pequeño se encarga de la mayor parte de la generación del texto, mientras que el papel del modelo más grande se limita a la verificación, lo que reduce la carga computacional total en términos de latencia y memoria.
Con estos requisitos de memoria, podemos implantar fácilmente técnicas de descodificación especulativa en los dispositivos periféricos y aumentar la velocidad de nuestras aplicaciones en los dispositivos, como chatbots, traductores de idiomas, juegos, etc.
El planteamiento anterior es eficiente, pero hay un compromiso entre la latencia y la optimización de la memoria para la inferencia en el dispositivo. Para solucionarlo, apliquemos la cuantización tanto a los modelos pequeños como a los grandes. Puedes experimentar y probar a aplicar la cuantización sólo al modelo grande, puesto que el modelo pequeño ya ocupa el menor espacio.
La cuantificación se aplica a modelos más pequeños y más grandes utilizando la configuración BitsAndBytesConfig de la biblioteca Cara abrazada transformers. La cuantización nos permite reducir significativamente el uso de memoria y, en muchos casos, mejorar la velocidad de inferencia convirtiendo los pesos del modelo a una forma más compacta.
Añade el siguiente fragmento de código al código anterior para comprobar los efectos de la cuantización.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # Enables 4-bit quantization
bnb_4bit_quant_type="nf4", # Specifies the quantization type (nf4)
bnb_4bit_compute_dtype=torch.bfloat16, # Uses bfloat16 for computation
bnb_4bit_use_double_quant=False, # Disables double quantization to avoid additional overhead
)
# Load the smaller and larger Gemma2 models with quantization applied
small_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it", device_map="auto", quantization_config=bnb_config)
big_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it", device_map="auto", quantization_config=bnb_config)He aquí una rápida comparación de los resultados para mostrar los efectos de la descodificación especulativa con y sin cuantización:
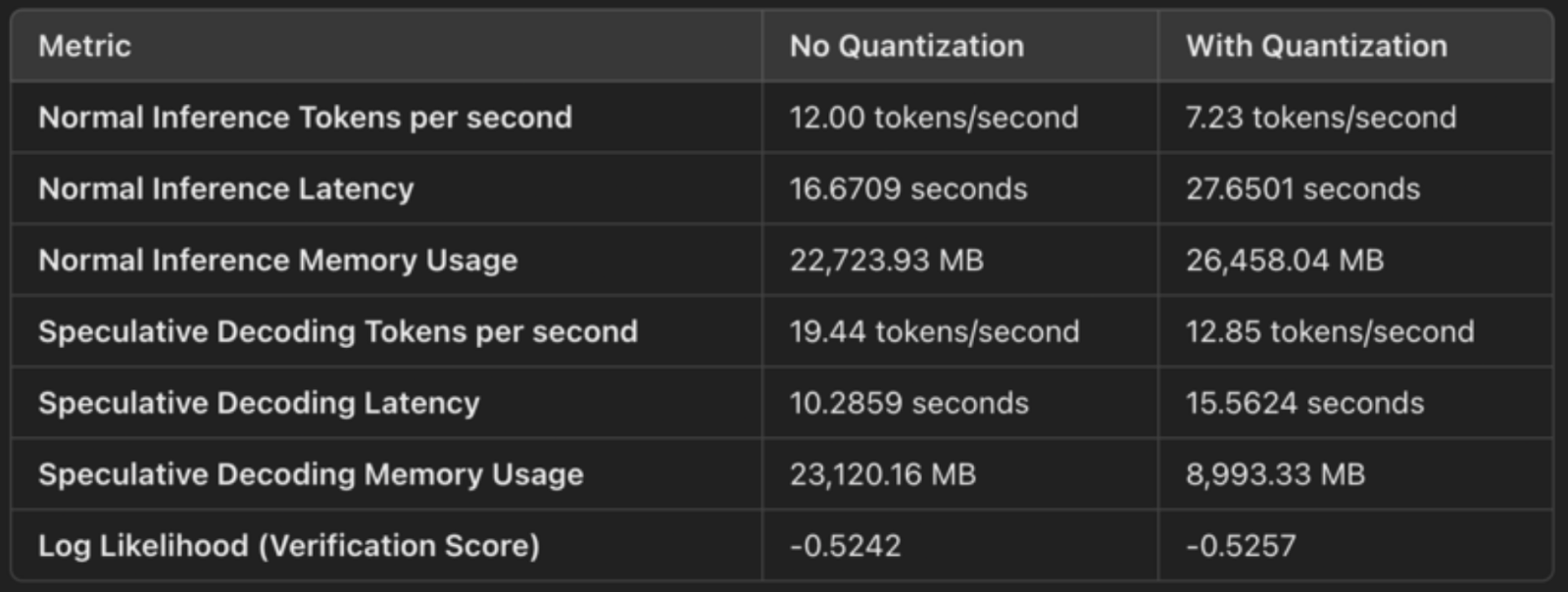
La configuración especifica load_in_4bit=True, lo que significa que los pesos del modelo se cuantifican desde su formato original de coma flotante de 32 o 16 bits a enteros de 4 bits. Esto reduce la huella de memoria del modelo. La cuantización comprime los pesos del modelo, lo que nos permite almacenarlos y operar con ellos de forma más eficaz. Estos son losahorros concretosde memoria :
La configuración bnb_4bit_compute_dtype=torch.bfloat16 especifica que el cálculo se realice en bfloat16 (BF16), un formato de coma flotante más eficiente. El BF16 tiene un rango dinámico más amplio que el FP16, pero ocupa la mitad de memoria que el FP32, lo que lo convierte en un buen equilibrio entre precisión y rendimiento.
El uso de BF16, especialmente en GPUs NVIDIA (como la A100), utiliza Tensor Cores, que están optimizados para las operaciones de BF16. Así se consiguen multiplicaciones de matrices y otros cálculos más rápidos durante la inferencia.
Para la descodificación especulativa, observamos una mejora de la latencia:
La menor huella de memoria implica un acceso más rápido a la memoria y un uso más eficiente de los recursos de la GPU, lo que se traduce en una generación más rápida.
La opción bnb_4bit_quant_type="nf4" especifica Cuantización Norma-Cuatro (NF4), que está optimizada para redes neuronales. La cuantización NF4 ayuda a conservar la precisión de partes importantes del modelo, aunque los pesos se representen en 4 bits. Esto minimiza la degradación del rendimiento del modelo en comparación con la simple cuantización de 4 bits.
NF4 ayuda a conseguir un equilibrio entre la compacidad de la cuantización de 4 bits y la precisión de las predicciones del modelo, garantizando que el rendimiento se mantenga próximo al original, al tiempo que se reduce drásticamente el uso de memoria.
La doble cuantización (bnb_4bit_use_double_quant=False) introduce una capa adicional de cuantización sobre los pesos de 4 bits, lo que puede reducir aún más el uso de memoria, pero también añade sobrecarga de cálculo. En este caso, se desactiva la doble cuantización para evitar ralentizar la inferencia.
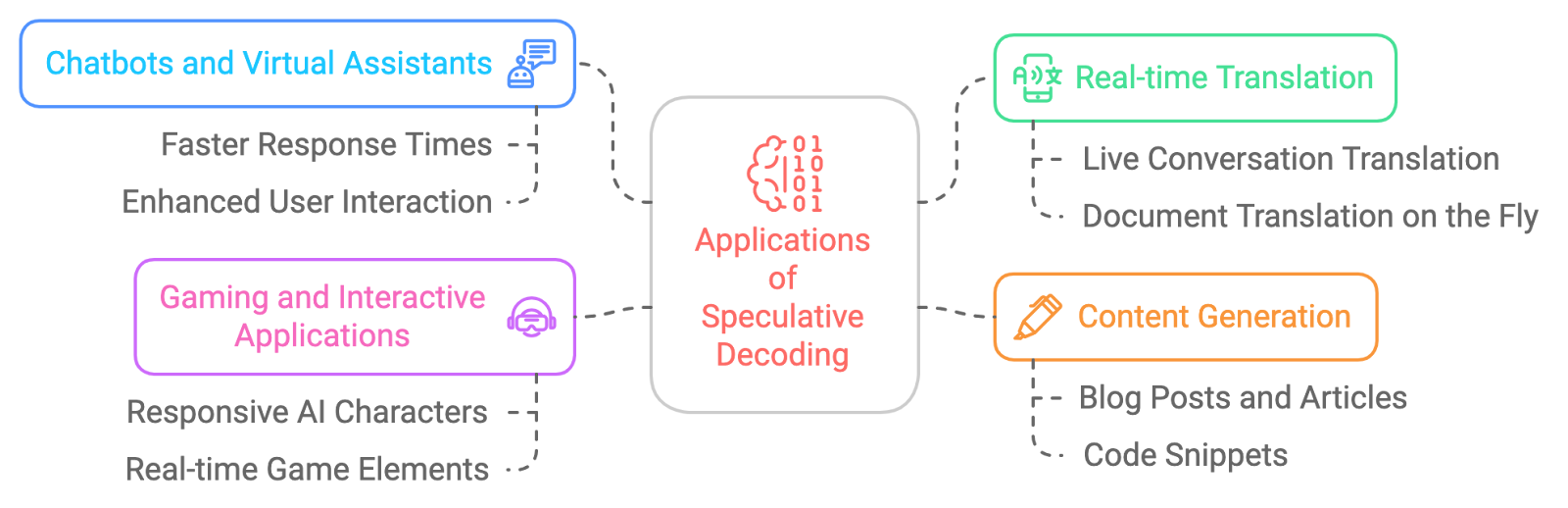
Las aplicaciones potenciales de la descodificación especulativa son amplias y apasionantes. He aquí algunos ejemplos:
Aunque la descodificación especulativa es muy prometedora, no está exenta de dificultades:
La descodificación especulativa es una potente técnica que puede revolucionar la forma en que interactuamos con grandes modelos lingüísticos. Puede acelerar significativamente la inferencia LLM sin comprometer la calidad del texto generado. Aunque hay retos que superar, las ventajas de la descodificación especulativa son innegables, y podemos esperar que su adopción crezca en los próximos años, permitiendo una nueva generación de aplicaciones de IA más rápidas, con mayor capacidad de respuesta y más eficientes.
Aprende IA con estos cursos
programa
Curso
Curso
blog
Zoumana Keita
14 min
blog
Natassha Selvaraj
15 min
blog
Abid Ali Awan
11 min
blog
Abid Ali Awan
10 min
Tutorial
Kurtis Pykes
Tutorial
Dimitri Didmanidze

