
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
LLMs sind so leistungsfähig, aber sie sind oft etwas langsam, was in Szenarien, in denen wir Geschwindigkeit brauchen, nicht ideal ist. Spekulative Dekodierung ist eine Technik, die LLMs beschleunigt, indem sie Antworten schneller erzeugt, ohne die Qualität zu beeinträchtigen.
Im Wesentlichen ist es eine Möglichkeit, bei der Texterstellung "vorauszuahnen" und Vorhersagen über die nächsten Wörter zu treffen, ohne dabei die Genauigkeit und Tiefe zu vernachlässigen, die wir von LLMs erwarten.
In diesem Blog erkläre ich, was spekulative Dekodierung ist, wie sie funktioniert und wie man sie mit Gemma 2-Modellen implementiert.
Die spekulative Dekodierung beschleunigt LLMs, indem sie ein kleineres, schnelleres Modell verwendet, das vorläufige Vorhersagen erstellt. Dieses kleinere Modell, das oft als "Draft"-Modell bezeichnet wird, generiert eine Reihe von Token, die das mächtigere LLM entweder bestätigen oder verfeinern kann. Das Entwurfsmodell fungiert als erster Durchgang und erzeugt mehrere Token, die den Generierungsprozess beschleunigen.
Anstatt dass das Haupt-LLM nacheinander Token generiert, liefert das Entwurfsmodell eine Reihe von wahrscheinlichen Kandidaten, die das Hauptmodell parallel auswertet. Diese Methode reduziert die Rechenlast des LLM, indem sie die anfänglichen Vorhersagen auslagert, so dass er sich nur auf Korrekturen oder Validierungen konzentrieren kann.
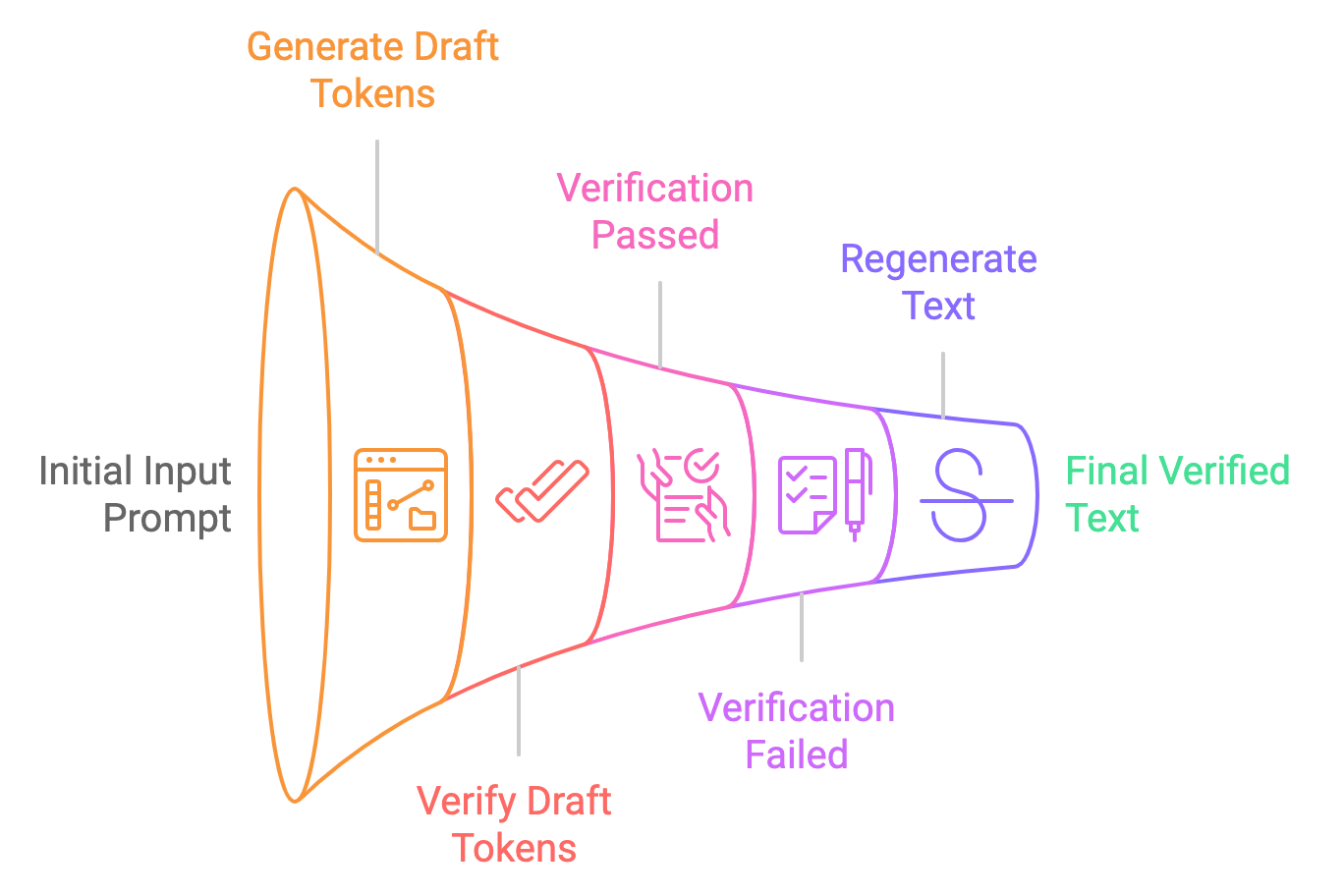
Stell dir das vor wie ein Schriftsteller mit einem Redakteur. Der Haupt-LLM ist der Schreiber, der in der Lage ist, qualitativ hochwertige Texte zu produzieren, allerdings in einem langsameren Tempo. Ein kleineres, schnelleres "Entwurfsmodell" fungiert als Editor, der schnell mögliche Fortsetzungen des Textes erstellt. Das Haupt-LLM wertet diese Vorschläge aus, übernimmt die richtigen und verwirft die anderen. So kann der LLM mehrere Token gleichzeitig verarbeiten und die Texterstellung beschleunigen.
Lass uns den Prozess der spekulativen Dekodierung in einfache Schritte aufteilen:
Bei der traditionellen Dekodierung werden die Token einzeln verarbeitet, was zu einer hohen Latenz führt. Bei der spekulativen Dekodierung hingegen kann ein kleineres Modell Token in großen Mengen erzeugen, die dann von dem größeren Modell überprüft werden. Das kann die Reaktionszeit um 30-40% reduzieren und die Latenzzeit von 25-30 Sekunden auf nur 15-18 Sekunden senken.
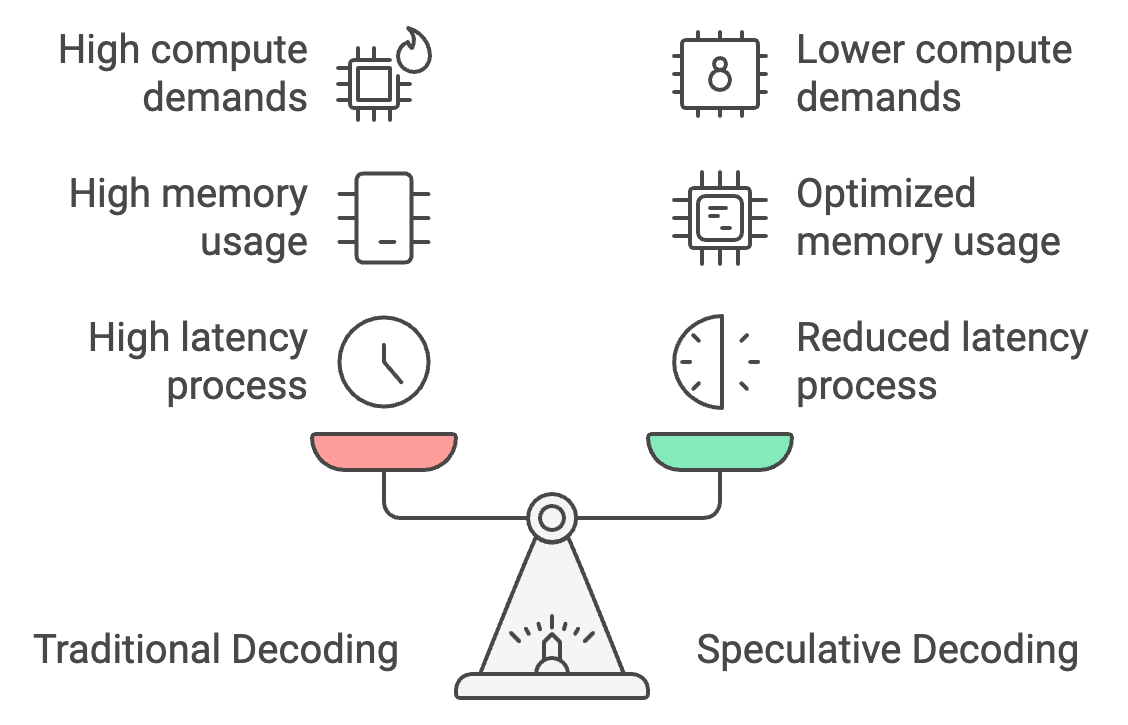
Darüber hinaus optimiert die spekulative Dekodierung die Speichernutzung, indem sie den Großteil der Token-Generierung auf das kleinere Modell verlagert, wodurch der Speicherbedarf von 26 GB auf etwa 14 GB sinkt und die auf dem Gerät Inferenz leichter zugänglich.
Schließlich senkt es den Rechenaufwand um 50 %, da das größere Modell nur verifiziert statt Token zu erzeugen, was eine reibungslosere Leistung auf mobilen Geräten mit begrenzter Leistung ermöglicht und eine Überhitzung verhindert.
Ein praktisches Beispiel für spekulative Dekodierung mit den Gemma2-Modellen zu implementieren. Wir werden untersuchen, wie die spekulative Dekodierung im Vergleich zur Standardinferenz sowohl in Bezug auf die Latenzzeit als auch auf die Leistung abschneidet.
Um loszulegen, importiere die Abhängigkeiten und setze den Seed.
Prüfe als Nächstes, ob die GPU auf dem Rechner, auf dem du arbeitest, verfügbar ist. Dies ist vor allem für große Modelle wie Gemma 2-9B-it oder LLama2-13B erforderlich.
Schließlich laden wir sowohl das kleine als auch das große Modell zusammen mit ihren Tokenizern. Hier verwenden wir das Modell Gemma2-2b-it (instruct) für den Modellentwurf und das Modell Gemma2-9b-it für die Überprüfung.
Es gibt auch einige andere Modelle, die alternativ verwendet werden können. Zum Beispiel:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
# Set Seed
set_seed(42)
# Check if GPU is available
device = "cuda" if torch.cuda.is_available() else "cpu"
# Load the smaller Gemma2 model (draft generation)
small_tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b-it", device_map="auto")
small_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it", device_map="auto", torch_dtype=torch.bfloat16)
# Load the larger Gemma2 model (verification)
big_tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it", device_map="auto")
big_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it", device_map="auto", torch_dtype=torch.bfloat16)Zunächst führen wir die Inferenz nur für das große Modell (Gemma2-9b-it) durch und erzeugen die Ergebnisse. Beginnen Sie mit Tokenisierung der Eingabeaufforderung und verschiebe die Token auf das richtige Gerät (GPU, falls vorhanden). Die Methode generate erzeugt den Output des Modells und generiert bis zu max_new_tokens. Das Ergebnis wird dann aus den Token-IDs wieder in menschenlesbaren Text umgewandelt.
def normal_inference(big_model, big_tokenizer, prompt, max_new_tokens=50):
inputs = big_tokenizer(prompt, return_tensors='pt').to(device)
outputs = big_model.generate(inputs['input_ids'], max_new_tokens=max_new_tokens)
return big_tokenizer.decode(outputs[0], skip_special_tokens=True)Als Nächstes versuchen wir die spekulative Dekodierungsmethode, bei der wir die folgenden Schritte durchführen:
def speculative_decoding(small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens=50):
# Step 1: Use the small model to generate the draft
inputs = small_tokenizer(prompt, return_tensors='pt').to(device)
small_outputs = small_model.generate(inputs['input_ids'], max_new_tokens=max_new_tokens)
draft = small_tokenizer.decode(small_outputs[0], skip_special_tokens=True)
# Step 2: Verify the draft with the big model
big_inputs = big_tokenizer(draft, return_tensors='pt').to(device)
# Step 3: Calculate log-likelihood of the draft tokens under the large model
with torch.no_grad():
outputs = big_model(big_inputs['input_ids'])
log_probs = torch.log_softmax(outputs.logits, dim=-1)
draft_token_ids = big_inputs['input_ids']
log_likelihood = 0
for i in range(draft_token_ids.size(1) - 1):
token_id = draft_token_ids[0, i + 1]
log_likelihood += log_probs[0, i, token_id].item()
avg_log_likelihood = log_likelihood / (draft_token_ids.size(1) - 1)
# Return the draft and its log-likelihood score
return draft, avg_log_likelihoodHinweis: Die Log-Likelihood ist der Logarithmus der Wahrscheinlichkeit, die ein Modell einer bestimmten Abfolge von Token zuordnet. Hier spiegelt sie wider, wie wahrscheinlich oder "zuversichtlich" das Modell ist, dass die Tokenfolge (der generierte Text) angesichts der vorherigen Token gültig ist.
Nachdem wir beide Techniken implementiert haben, können wir ihre jeweiligen Latenzen messen. Bei der spekulativen Dekodierung bewerten wir die Leistung, indem wir den Log-Likelihood-Wert untersuchen. Ein Log-Likelihood-Wert, der gegen Null geht, insbesondere im negativen Bereich, zeigt an, dass der generierte Text korrekt ist.
def measure_latency(small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens=50):
# Measure latency for normal inference (big model only)
start_time = time.time()
normal_output = normal_inference(big_model, big_tokenizer, prompt, max_new_tokens)
normal_inference_latency = time.time() - start_time
print(f"Normal Inference Output: {normal_output}")
print(f"Normal Inference Latency: {normal_inference_latency:.4f} seconds")
print("\n\n")
# Measure latency for speculative decoding
start_time = time.time()
speculative_output, log_likelihood = speculative_decoding(
small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens
)
speculative_decoding_latency = time.time() - start_time
print(f"Speculative Decoding Output: {speculative_output}")
print(f"Speculative Decoding Latency: {speculative_decoding_latency:.4f} seconds")
print(f"Log Likelihood (Verification Score): {log_likelihood:.4f}")
return normal_inference_latency, speculative_decoding_latencyDas gibt zurück:
Die geringere Latenzzeit ist darauf zurückzuführen, dass das kleinere Modell weniger Zeit für die Texterstellung und das größere Modell weniger Zeit für die Überprüfung des generierten Textes benötigt.
Vergleichen wir die spekulative Dekodierung mit der autoregressiven Inferenz anhand von fünf Aufforderungen:
# List of 5 prompts
prompts = [
"The future of artificial intelligence is ",
"Machine learning is transforming the world by ",
"Natural language processing enables computers to understand ",
"Generative models like GPT-3 can create ",
"AI ethics and fairness are important considerations for "
]
# Inference settings
max_new_tokens = 200
# Initialize accumulators for latency, memory, and tokens per second
total_tokens_per_sec_normal = 0
total_tokens_per_sec_speculative = 0
total_normal_latency = 0
total_speculative_latency = 0
# Perform inference on each prompt and accumulate the results
for prompt in prompts:
normal_latency, speculative_latency, _, _, tokens_per_sec_normal, tokens_per_sec_speculative = measure_latency_and_memory(
small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens
)
total_tokens_per_sec_normal += tokens_per_sec_normal
total_tokens_per_sec_speculative += tokens_per_sec_speculative
total_normal_latency += normal_latency
total_speculative_latency += speculative_latency
# Calculate averages
average_tokens_per_sec_normal = total_tokens_per_sec_normal / len(prompts)
average_tokens_per_sec_speculative = total_tokens_per_sec_speculative / len(prompts)
average_normal_latency = total_normal_latency / len(prompts)
average_speculative_latency = total_speculative_latency / len(prompts)
# Output the averages
print(f"Average Normal Inference Latency: {average_normal_latency:.4f} seconds")
print(f"Average Speculative Decoding Latency: {average_speculative_latency:.4f} seconds")
print(f"Average Normal Inference Tokens per second: {average_tokens_per_sec_normal:.2f} tokens/second")
print(f"Average Speculative Decoding Tokens per second: {average_tokens_per_sec_speculative:.2f} tokens/second")Average Normal Inference Latency: 25.0876 seconds
Average Speculative Decoding Latency: 15.7802 seconds
Average Normal Inference Tokens per second: 7.97 tokens/second
Average Speculative Decoding Tokens per second: 12.68 tokens/secondDas zeigt, dass die spekulative Dekodierung effizienter ist und mehr Token pro Sekunde erzeugt als die normale Inferenz. Diese Verbesserung ist darauf zurückzuführen, dass das kleinere Modell den Großteil der Texterstellung übernimmt, während sich die Rolle des größeren Modells auf die Überprüfung beschränkt, wodurch die gesamte Rechenlast in Bezug auf Latenzzeit und Speicherplatz reduziert wird.
Mit diesen Speicheranforderungen können wir spekulative Dekodierungstechniken auf Edge-Geräten leicht einsetzen und unsere On-Device-Anwendungen wie Chatbots, Sprachübersetzer, Spiele und mehr beschleunigen.
Der obige Ansatz ist effizient, aber es gibt einen Kompromiss zwischen Latenzzeit und Speicheroptimierung für die Inferenz auf dem Gerät. Um dieses Problem zu lösen, wenden wir die Quantisierung sowohl auf kleine als auch auf große Modelle an. Du kannst experimentieren und versuchen, die Quantisierung nur auf das große Modell anzuwenden, da das kleine Modell bereits den wenigsten Platz einnimmt.
Die Quantifizierung wird auf kleinere und größere Modelle mit der Konfiguration BitsAndBytesConfig aus der Bibliothek Hugging Face transformers angewendet. Die Quantisierung ermöglicht es uns, den Speicherbedarf erheblich zu reduzieren und in vielen Fällen die Inferenzgeschwindigkeit zu erhöhen, indem wir die Gewichte des Modells in eine kompaktere Form umwandeln.
Füge den folgenden Codeschnipsel zu dem obigen Code hinzu, um die Auswirkungen der Quantisierung zu sehen.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # Enables 4-bit quantization
bnb_4bit_quant_type="nf4", # Specifies the quantization type (nf4)
bnb_4bit_compute_dtype=torch.bfloat16, # Uses bfloat16 for computation
bnb_4bit_use_double_quant=False, # Disables double quantization to avoid additional overhead
)
# Load the smaller and larger Gemma2 models with quantization applied
small_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it", device_map="auto", quantization_config=bnb_config)
big_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it", device_map="auto", quantization_config=bnb_config)Hier ist ein kurzer Vergleich der Ausgaben, um die Auswirkungen der spekulativen Dekodierung mit und ohne Quantisierung zu zeigen:
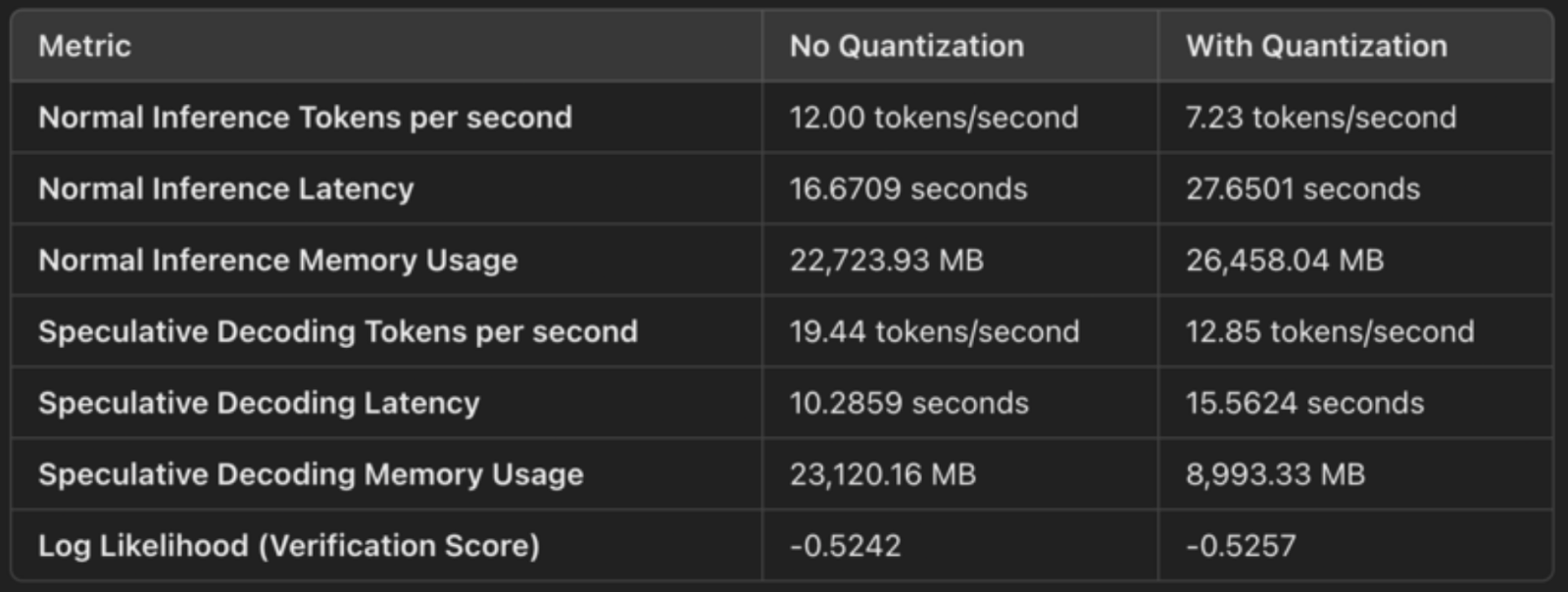
Die Konfiguration gibt load_in_4bit=True an, was bedeutet, dass die Gewichte des Modells von ihrem ursprünglichen 32-Bit- oder 16-Bit-Gleitkommaformat in 4-Bit-Ganzzahlen quantisiert werden. Dadurch wird der Speicherbedarf des Modells reduziert. Die Quantisierung komprimiert die Gewichte des Modells, sodass wir sie effizienter speichern und verarbeiten können. Dies sind die konkreten Speichereinsparungen:
Die Konfiguration bnb_4bit_compute_dtype=torch.bfloat16 legt fest, dass die Berechnung in bfloat16 (BF16), einem effizienteren Gleitkommaformat, durchgeführt wird. BF16 hat einen größeren Dynamikbereich als FP16, benötigt aber nur halb so viel Speicherplatz wie FP32 und bietet damit ein gutes Gleichgewicht zwischen Präzision und Leistung.
Die Verwendung von BF16, insbesondere auf NVIDIA GPUs (wie A100), verwendet Tensor Cores, die für BF16-Operationen optimiert sind. Dies führt zu schnelleren Matrixmultiplikationen und anderen Berechnungen während der Inferenz.
Für spekulative Dekodierung, sehen wir eine verbesserte Latenzzeit:
Der kleinere Speicherbedarf bedeutet einen schnelleren Speicherzugriff und eine effizientere Nutzung der GPU-Ressourcen, was zu einer schnelleren Generierung führt.
Die Option bnb_4bit_quant_type="nf4" legt die Norm-Vier-Quantisierung (NF4)fest , die für neuronale Netze optimiert ist. Die NF4-Quantisierung hilft dabei, die Genauigkeit wichtiger Teile des Modells beizubehalten, auch wenn die Gewichte in 4 Bits dargestellt werden. Dadurch wird die Verschlechterung der Modellleistung im Vergleich zur einfachen 4-Bit-Quantisierung minimiert.
NF4 hilft dabei, ein Gleichgewicht zwischen der Kompaktheit der 4-Bit-Quantisierung und der Genauigkeit der Vorhersagen des Modells zu erreichen, sodass die Leistung nahe am Original bleibt und gleichzeitig der Speicherverbrauch drastisch reduziert wird.
Die doppelte Quantisierung (bnb_4bit_use_double_quant=False) führt eine zusätzliche Quantisierungsebene über den 4-Bit-Gewichten ein, die den Speicherverbrauch weiter reduzieren kann, aber auch einen zusätzlichen Rechenaufwand bedeutet. In diesem Fall ist die doppelte Quantisierung deaktiviert, um die Schlussfolgerung nicht zu verlangsamen.
Die Anwendungsmöglichkeiten der spekulativen Dekodierung sind groß und spannend. Hier sind ein paar Beispiele:
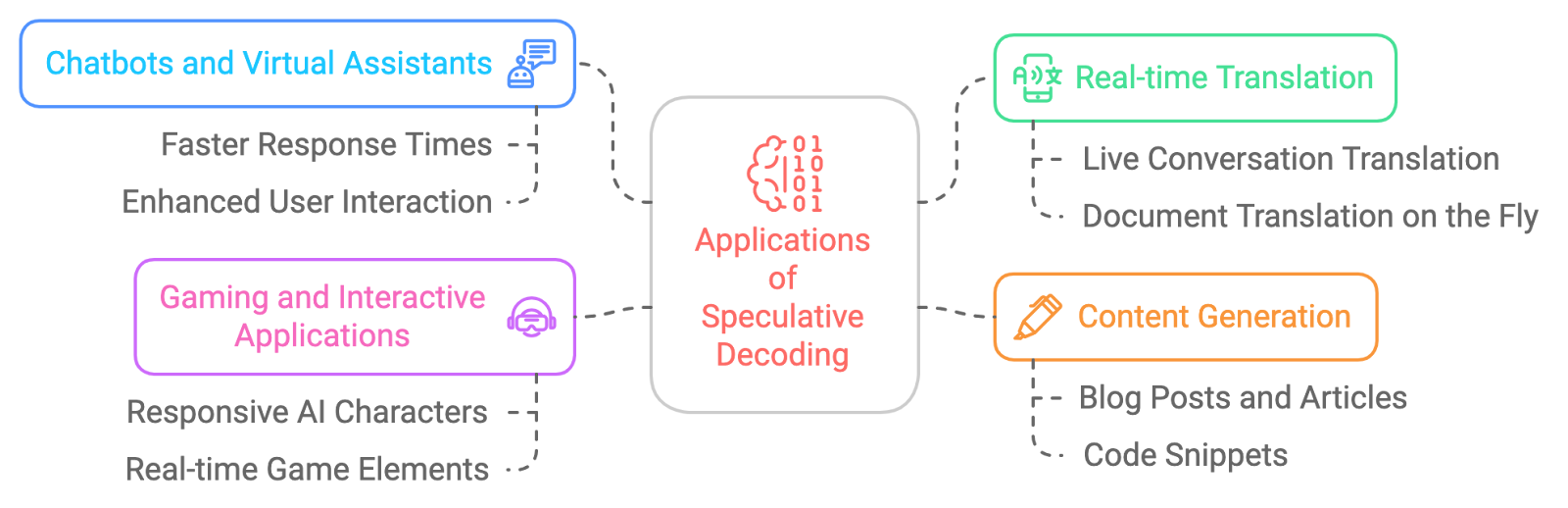
Die spekulative Dekodierung ist zwar sehr vielversprechend, aber nicht ohne Herausforderungen:
Die spekulative Dekodierung ist eine leistungsstarke Technik, die das Potenzial hat, die Art und Weise, wie wir mit großen Sprachmodellen arbeiten, zu revolutionieren. Sie kann die LLM-Inferenz erheblich beschleunigen, ohne die Qualität des generierten Textes zu beeinträchtigen. Auch wenn es noch einige Herausforderungen zu bewältigen gibt, sind die Vorteile der spekulativen Dekodierung unbestreitbar, und wir können davon ausgehen, dass sie in den kommenden Jahren immer häufiger eingesetzt wird und eine neue Generation schnellerer, reaktionsschnellerer und effizienterer KI-Anwendungen ermöglicht.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
