
Cursus
Développer des applications d'IA
21 h
Les LLM sont si puissants, mais ils sont souvent un peu lents, ce qui n'est pas idéal dans les scénarios où nous avons besoin de rapidité. Le décodage spéculatif est une technique conçue pour accélérer les LLM en générant des réponses plus rapidement sans compromettre la qualité.
Il s'agit essentiellement d'un moyen de "deviner à l'avance" dans le processus de génération de texte, en faisant des prédictions sur les mots qui pourraient suivre tout en permettant la précision et la profondeur que nous attendons des LLM.
Dans ce blog, j'expliquerai ce qu'est le décodage spéculatif, comment il fonctionne et comment le mettre en œuvre avec les modèles Gemma 2.
Le décodage spéculatif accélère les LLM en incorporant un modèle plus petit et plus rapide qui génère des prédictions préliminaires. Ce modèle plus petit, souvent appelé modèle "brouillon", génère un lot de jetons que le LLM principal, plus puissant, peut confirmer ou affiner. Le projet de modèle agit comme un premier passage, produisant plusieurs jetons qui accélèrent le processus de génération.
Au lieu que le LLM principal génère des jetons de manière séquentielle, le modèle provisoire fournit un ensemble de candidats probables, et le modèle principal les évalue en parallèle. Cette méthode réduit la charge de calcul du LLM principal en déchargeant les prédictions initiales, ce qui lui permet de se concentrer uniquement sur les corrections ou les validations.
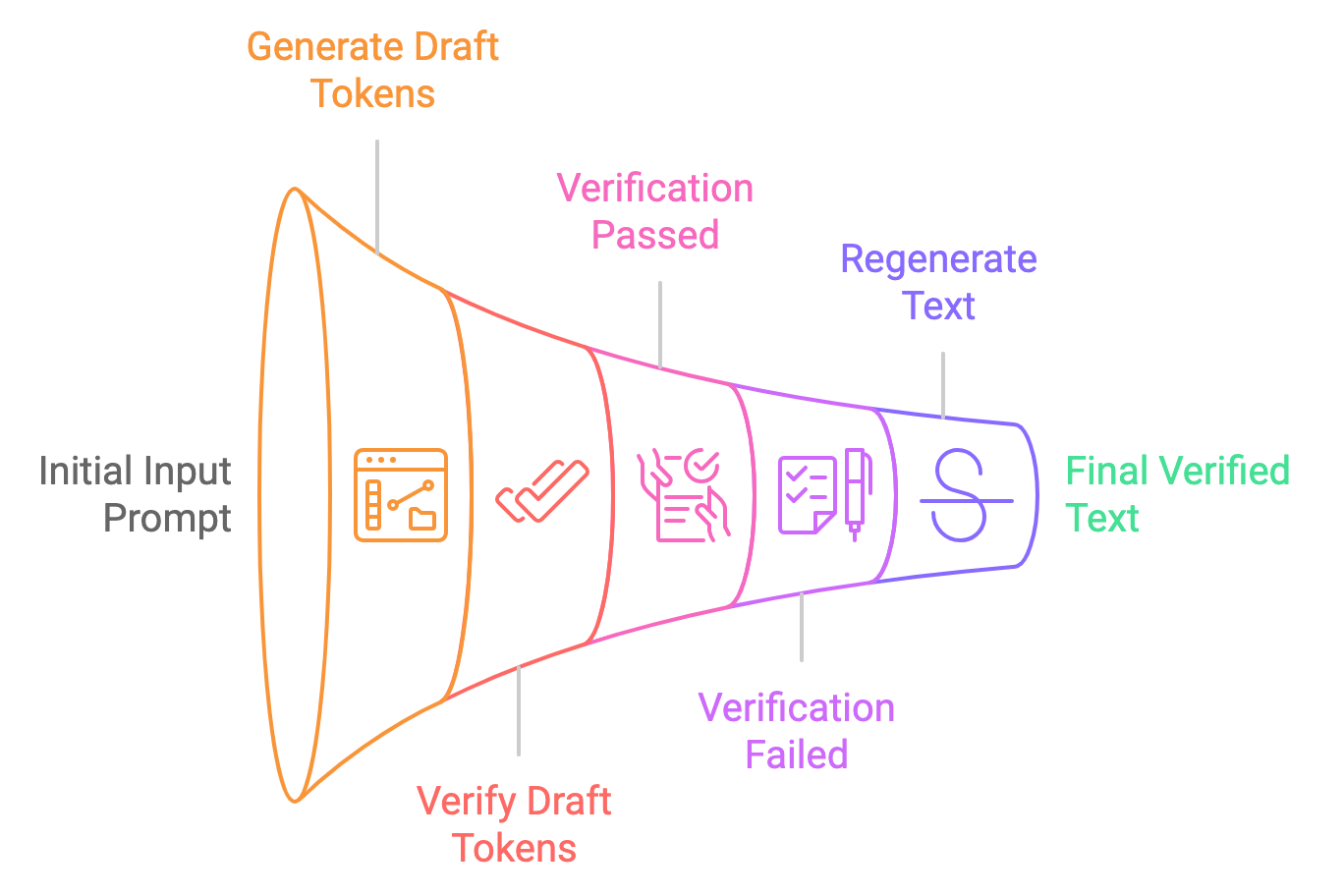
Pensez-y comme un écrivain avec un rédacteur en chef. Le principal LLM est le rédacteur, capable de produire des textes de qualité mais à un rythme plus lent. Un modèle "brouillon", plus petit et plus rapide, joue le rôle d'éditeur et génère rapidement des suites potentielles du texte. Le LLM principal évalue ensuite ces suggestions, en intégrant celles qui sont correctes et en rejetant les autres. Cela permet au LLM de traiter plusieurs tokens simultanément, ce qui accélère la génération de texte.
Décomposons le processus de décodage spéculatif en étapes simples :
Le décodage traditionnel traite les jetons un par un, ce qui entraîne une latence élevée, mais le décodage spéculatif permet à un modèle plus petit de générer des jetons en masse, le modèle plus grand les vérifiant. Le temps de réponse peut ainsi être réduit de 30 à 40 %, la latence passant de 25 à 30 secondes à 15 à 18 secondes seulement.
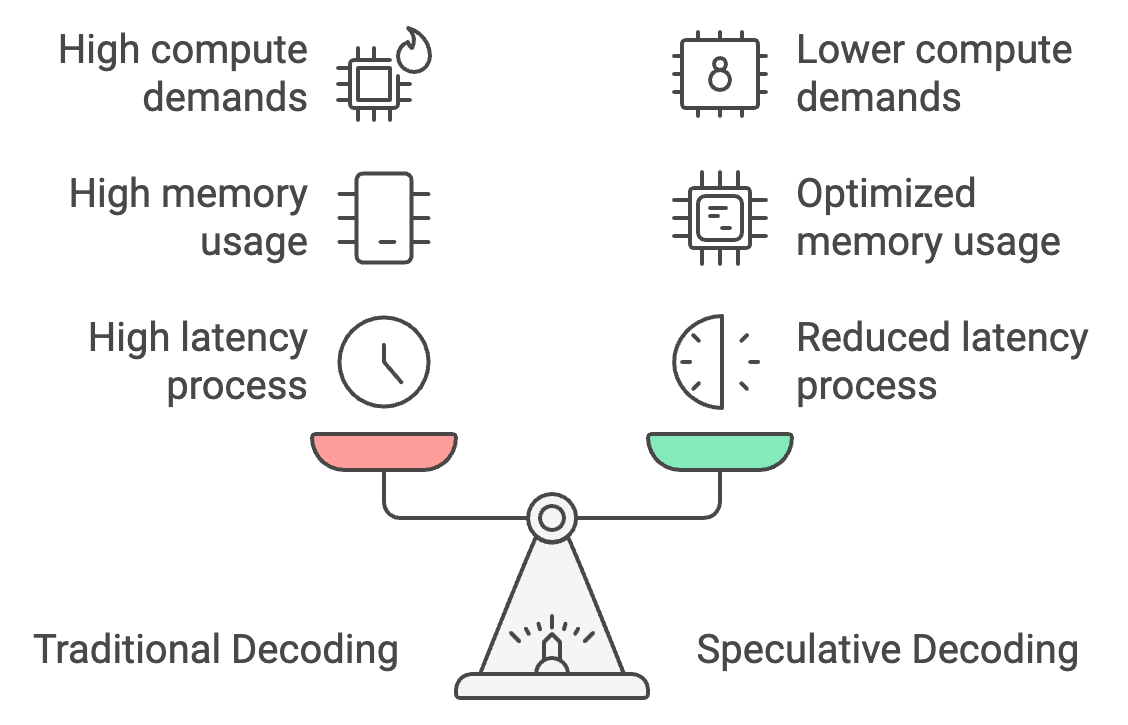
En outre, le décodage spéculatif optimise l'utilisation de la mémoire en transférant la majeure partie de la génération des jetons vers le modèle le plus petit, ce qui réduit les besoins en mémoire de 26 Go à environ 14 Go et rend le décodage spéculatif plus efficace. sur l'appareil l'inférence sur l'appareil.
Enfin, il réduit de 50 % les besoins en calcul, car le modèle plus grand ne vérifie que les jetons et n'en génère pas, ce qui permet des performances plus fluides sur les appareils mobiles à faible consommation d'énergie et évite la surchauffe.
Mettre en œuvre un exemple pratique de décodage spéculatif à l'aide des modèles Gemma2. Nous verrons comment le décodage spéculatif se compare à l'inférence standard en termes delatence et de performances( ).
Pour commencer, importez les dépendances et définissez la graine.
Ensuite, vérifiez si le GPU est disponible sur la machine sur laquelle vous travaillez. Ceci est principalement nécessaire pour les grands modèles tels que Gemma 2-9B-it ou LLama2-13B.
Enfin, nous chargeons le petit et le grand modèle avec leurs tokenizers. Nous utilisons ici le modèle Gemma2-2b-it (instruct) pour le projet de modèle et le modèle Gemma2-9b-it pour la vérification.
Il existe quelques autres modèles qui peuvent être utilisés alternativement. Par exemple :
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
# Set Seed
set_seed(42)
# Check if GPU is available
device = "cuda" if torch.cuda.is_available() else "cpu"
# Load the smaller Gemma2 model (draft generation)
small_tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b-it", device_map="auto")
small_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it", device_map="auto", torch_dtype=torch.bfloat16)
# Load the larger Gemma2 model (verification)
big_tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it", device_map="auto")
big_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it", device_map="auto", torch_dtype=torch.bfloat16)Tout d'abord, nous effectuons l'inférence sur le seul grand modèle (Gemma2-9b-it) et générons des résultats. Commencez par donner des jetons à l'invite l'invite d'entrée et en déplaçant les jetons vers le bon périphérique (GPU si disponible). La méthode generate produit la sortie du modèle, générant jusqu'à max_new_tokens. Le résultat est ensuite décodé en texte lisible par l'homme à partir des identifiants des jetons.
def normal_inference(big_model, big_tokenizer, prompt, max_new_tokens=50):
inputs = big_tokenizer(prompt, return_tensors='pt').to(device)
outputs = big_model.generate(inputs['input_ids'], max_new_tokens=max_new_tokens)
return big_tokenizer.decode(outputs[0], skip_special_tokens=True)Ensuite, nous essayons la méthode de décodage spéculatif, en procédant comme suit :
def speculative_decoding(small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens=50):
# Step 1: Use the small model to generate the draft
inputs = small_tokenizer(prompt, return_tensors='pt').to(device)
small_outputs = small_model.generate(inputs['input_ids'], max_new_tokens=max_new_tokens)
draft = small_tokenizer.decode(small_outputs[0], skip_special_tokens=True)
# Step 2: Verify the draft with the big model
big_inputs = big_tokenizer(draft, return_tensors='pt').to(device)
# Step 3: Calculate log-likelihood of the draft tokens under the large model
with torch.no_grad():
outputs = big_model(big_inputs['input_ids'])
log_probs = torch.log_softmax(outputs.logits, dim=-1)
draft_token_ids = big_inputs['input_ids']
log_likelihood = 0
for i in range(draft_token_ids.size(1) - 1):
token_id = draft_token_ids[0, i + 1]
log_likelihood += log_probs[0, i, token_id].item()
avg_log_likelihood = log_likelihood / (draft_token_ids.size(1) - 1)
# Return the draft and its log-likelihood score
return draft, avg_log_likelihoodNote : La log-vraisemblance est le logarithme de la probabilité qu'un modèle attribue à une séquence spécifique de jetons. Elle reflète la probabilité ou la "confiance" du modèle dans la validité de la séquence de jetons (le texte généré) compte tenu des jetons précédents.
Après avoir mis en œuvre les deux techniques, nous pouvons mesurer leurs temps de latence respectifs. Pour le décodage spéculatif, nous évaluons les performances en examinant la valeur de la log-vraisemblance. Une valeur de log-vraisemblance proche de zéro, en particulier dans la plage négative, indique que le texte généré est exact.
def measure_latency(small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens=50):
# Measure latency for normal inference (big model only)
start_time = time.time()
normal_output = normal_inference(big_model, big_tokenizer, prompt, max_new_tokens)
normal_inference_latency = time.time() - start_time
print(f"Normal Inference Output: {normal_output}")
print(f"Normal Inference Latency: {normal_inference_latency:.4f} seconds")
print("\n\n")
# Measure latency for speculative decoding
start_time = time.time()
speculative_output, log_likelihood = speculative_decoding(
small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens
)
speculative_decoding_latency = time.time() - start_time
print(f"Speculative Decoding Output: {speculative_output}")
print(f"Speculative Decoding Latency: {speculative_decoding_latency:.4f} seconds")
print(f"Log Likelihood (Verification Score): {log_likelihood:.4f}")
return normal_inference_latency, speculative_decoding_latencyCela renvoie :
La réduction du temps de latence est due au fait que le modèle le plus petit prend moins de temps pour générer le texte et que le modèle le plus grand prend moins de temps pour simplement vérifier le texte généré.
Comparons le décodage spéculatif avec l'inférence autorégressive en utilisant cinq invites :
# List of 5 prompts
prompts = [
"The future of artificial intelligence is ",
"Machine learning is transforming the world by ",
"Natural language processing enables computers to understand ",
"Generative models like GPT-3 can create ",
"AI ethics and fairness are important considerations for "
]
# Inference settings
max_new_tokens = 200
# Initialize accumulators for latency, memory, and tokens per second
total_tokens_per_sec_normal = 0
total_tokens_per_sec_speculative = 0
total_normal_latency = 0
total_speculative_latency = 0
# Perform inference on each prompt and accumulate the results
for prompt in prompts:
normal_latency, speculative_latency, _, _, tokens_per_sec_normal, tokens_per_sec_speculative = measure_latency_and_memory(
small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens
)
total_tokens_per_sec_normal += tokens_per_sec_normal
total_tokens_per_sec_speculative += tokens_per_sec_speculative
total_normal_latency += normal_latency
total_speculative_latency += speculative_latency
# Calculate averages
average_tokens_per_sec_normal = total_tokens_per_sec_normal / len(prompts)
average_tokens_per_sec_speculative = total_tokens_per_sec_speculative / len(prompts)
average_normal_latency = total_normal_latency / len(prompts)
average_speculative_latency = total_speculative_latency / len(prompts)
# Output the averages
print(f"Average Normal Inference Latency: {average_normal_latency:.4f} seconds")
print(f"Average Speculative Decoding Latency: {average_speculative_latency:.4f} seconds")
print(f"Average Normal Inference Tokens per second: {average_tokens_per_sec_normal:.2f} tokens/second")
print(f"Average Speculative Decoding Tokens per second: {average_tokens_per_sec_speculative:.2f} tokens/second")Average Normal Inference Latency: 25.0876 seconds
Average Speculative Decoding Latency: 15.7802 seconds
Average Normal Inference Tokens per second: 7.97 tokens/second
Average Speculative Decoding Tokens per second: 12.68 tokens/secondCela montre que le décodage spéculatif est plus efficace, générant plus de jetons par seconde que l'inférence normale. Cette amélioration est due au fait que le modèle le plus petit prend en charge la majeure partie de la génération du texte, tandis que le rôle du modèle le plus grand se limite à la vérification, ce qui réduit la charge de calcul globale en termes de latence et de mémoire.
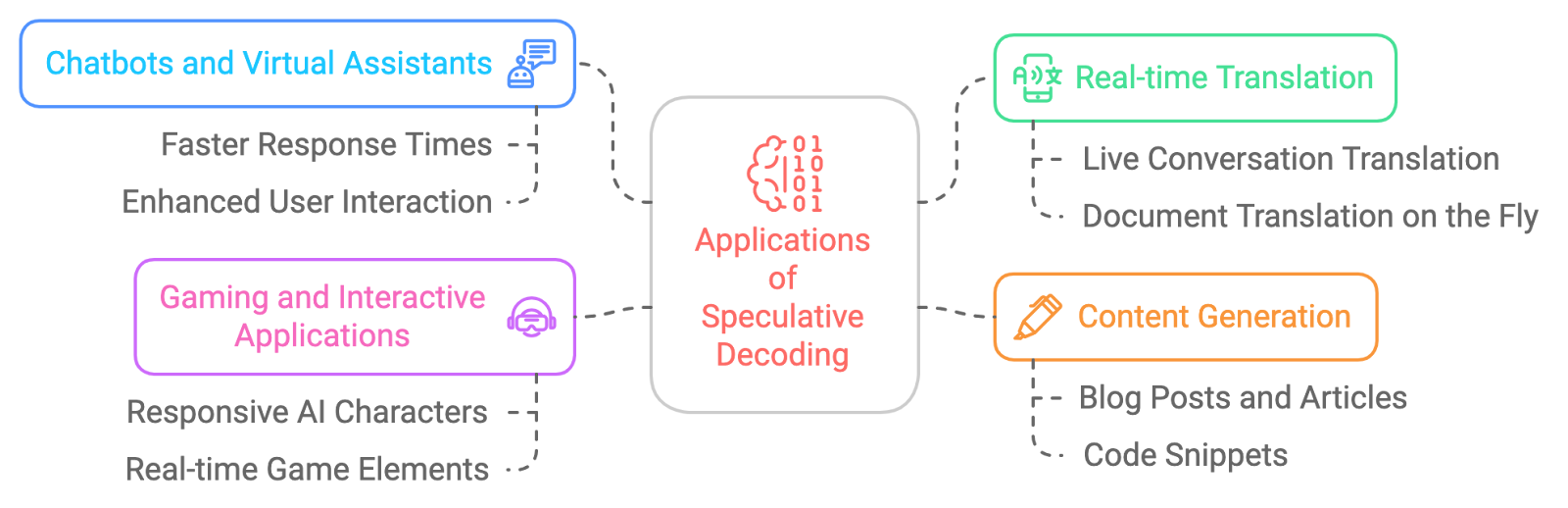
Grâce à ces exigences en matière de mémoire, nous pouvons facilement déployer des techniques de décodage spéculatif sur les appareils périphériques et accélérer nos applications sur appareil, telles que les chatbots, les traducteurs de langue, les jeux, etc.
L'approche ci-dessus est efficace, mais il faut trouver un compromis entre la latence et l'optimisation de la mémoire pour l'inférence sur l'appareil. Pour y remédier, appliquons la quantification aux petits et aux grands modèles. Vous pouvez expérimenter et essayer d'appliquer la quantification uniquement au grand modèle, puisque le petit modèle occupe déjà le moins d'espace.
La quantification est appliquée à des modèles plus petits et plus grands en utilisant la configuration BitsAndBytesConfig de la bibliothèque Hugging Face transformers. La quantification nous permet de réduire considérablement l'utilisation de la mémoire et, dans de nombreux cas, d'améliorer la vitesse d'inférence en convertissant les poids du modèle en une forme plus compacte.
Ajoutez l'extrait de code suivant au code ci-dessus pour constater les effets de la quantification.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # Enables 4-bit quantization
bnb_4bit_quant_type="nf4", # Specifies the quantization type (nf4)
bnb_4bit_compute_dtype=torch.bfloat16, # Uses bfloat16 for computation
bnb_4bit_use_double_quant=False, # Disables double quantization to avoid additional overhead
)
# Load the smaller and larger Gemma2 models with quantization applied
small_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it", device_map="auto", quantization_config=bnb_config)
big_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it", device_map="auto", quantization_config=bnb_config)Voici une comparaison rapide des résultats pour montrer les effets du décodage spéculatif avec et sans quantification :
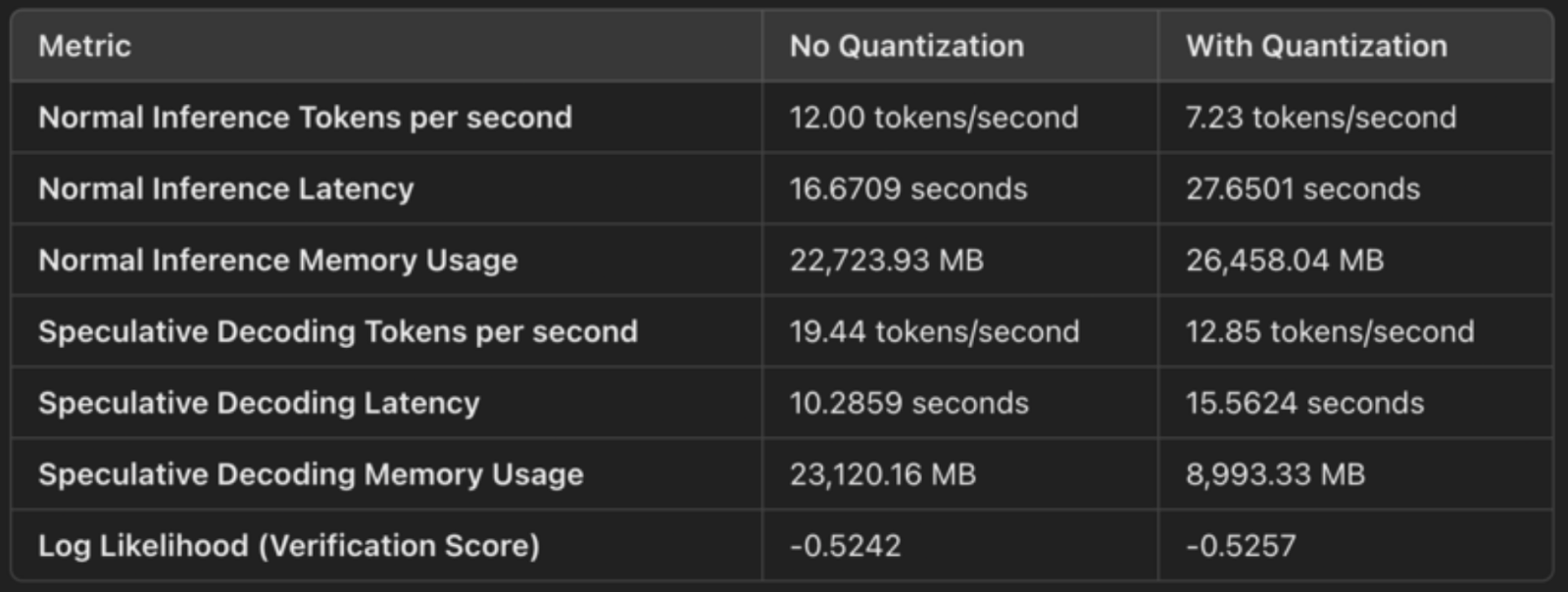
La configuration spécifie load_in_4bit=True, ce qui signifie que les poids du modèle sont quantifiés à partir de leur format original à virgule flottante de 32 ou 16 bits vers des entiers de 4 bits. Cela permet de réduire l'empreinte mémoire du modèle. La quantification comprime les poids du modèle, ce qui nous permet de les stocker et de les utiliser plus efficacement. Il s'agit deséconomies de mémoire concrètesde :
La configuration bnb_4bit_compute_dtype=torch.bfloat16 spécifie que le calcul est effectué en bfloat16 (BF16), un format de virgule flottante plus efficace. BF16 a une plage dynamique plus large que FP16 mais occupe la moitié de la mémoire par rapport à FP32, ce qui en fait un bon équilibre entre précision et performance.
L'utilisation de BF16, en particulier sur les GPU NVIDIA (comme l'A100), fait appel aux Tensor Cores, qui sont optimisés pour les opérations BF16. Cela permet d'accélérer les multiplications de matrices et d'autres calculs pendant l'inférence.
Pour le décodage spéculatif, nous constatons une amélioration de la latence :
L'empreinte mémoire réduite permet un accès plus rapide à la mémoire et une utilisation plus efficace des ressources du GPU, ce qui se traduit par une génération plus rapide.
L'option bnb_4bit_quant_type="nf4" spécifie la quantification Norm-Four (NF4), qui est optimisée pour les réseaux neuronaux. La quantification NF4 permet de conserver la précision des parties importantes du modèle, même si les poids sont représentés sur 4 bits. Cela minimise la dégradation des performances du modèle par rapport à une simple quantification sur 4 bits.
NF4 permet d'atteindre un équilibre entre la compacité de la quantification à 4 bits et la précision des prédictions du modèle, garantissant que les performances restent proches de l'original tout en réduisant considérablement l'utilisation de la mémoire.
La double quantification (bnb_4bit_use_double_quant=False) introduit une couche supplémentaire de quantification au-dessus des poids de 4 bits, ce qui permet de réduire encore l'utilisation de la mémoire, mais ajoute également une surcharge de calcul. Dans ce cas, la double quantification est désactivée pour éviter de ralentir l'inférence.
Les applications potentielles du décodage spéculatif sont vastes et passionnantes. Voici quelques exemples :
Si le décodage spéculatif est extrêmement prometteur, il n'est pas sans poser de problèmes :
Le décodage spéculatif est une technique puissante qui a le potentiel de révolutionner la façon dont nous interagissons avec les grands modèles de langage. Il permet d'accélérer considérablement l'inférence LLM sans compromettre la qualité du texte généré. Bien qu'il reste des défis à relever, les avantages du décodage spéculatif sont indéniables, et nous pouvons nous attendre à ce que son adoption augmente dans les années à venir, permettant une nouvelle génération d'applications d'IA plus rapides, plus réactives et plus efficaces.
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours