
Programa
Desenvolvimento de aplicativos de IA
21 h
LLMs são muito eficientes, mas muitas vezes podem ser um pouco lentos, o que não é ideal em cenários em que precisamos de velocidade. Decodificação especulativa é uma técnica projetada para acelerar os LLMs, gerando respostas mais rapidamente sem comprometer a qualidade.
Em essência, é uma maneira de "adivinhar" no processo de geração de texto, fazendo previsões sobre as palavras que podem vir a seguir, ao mesmo tempo em que permite a precisão e a profundidade que esperamos dos LLMs.
Neste blog, explicarei o que é a decodificação especulativa, como ela funciona e como implementá-la com os modelos Gemma 2.
A decodificação especulativa acelera os LLMs ao incorporar um modelo menor e mais rápido que gera previsões preliminares. Esse modelo menor, geralmente chamado de modelo de "rascunho", gera um lote de tokens que o LLM principal, mais avançado, pode confirmar ou refinar. O modelo de rascunho funciona como uma primeira passagem, produzindo vários tokens que aceleram o processo de geração.
Em vez de o LLM principal gerar tokens sequencialmente, o modelo de rascunho fornece um conjunto de candidatos prováveis, e o modelo principal os avalia em paralelo. Esse método reduz a carga computacional do LLM principal ao descarregar as previsões iniciais, permitindo que ele se concentre apenas em correções ou validações.
Pense nisso como um escritor com um editor. O principal LLM é o escritor, capaz de produzir textos de alta qualidade, mas em um ritmo mais lento. Um modelo de "rascunho" menor e mais rápido atua como editor, gerando rapidamente possíveis continuações do texto. Em seguida, o LLM principal avalia essas sugestões, incorporando as mais precisas e descartando as demais. Isso permite que o LLM processe vários tokens ao mesmo tempo, acelerando a geração de texto.
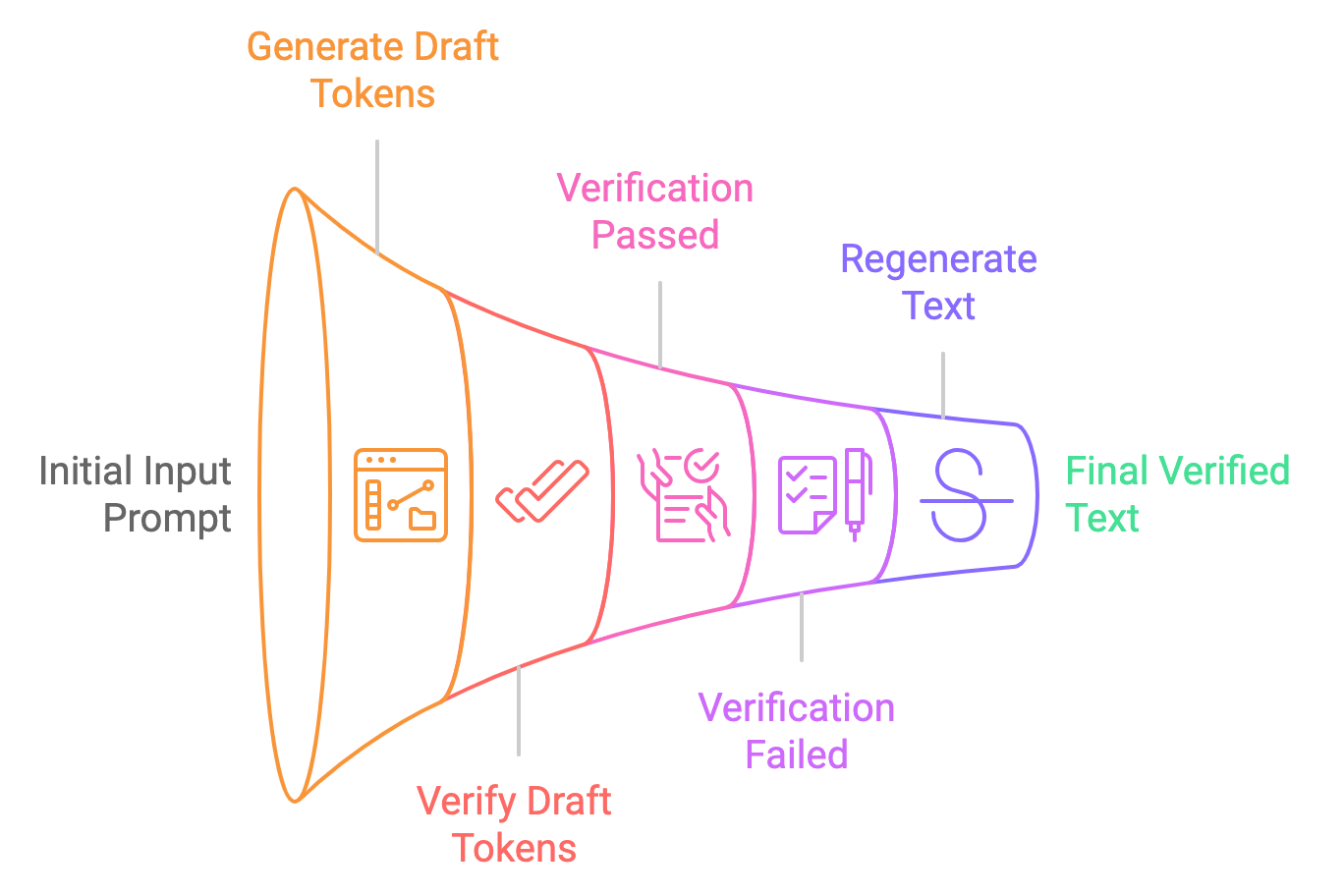
Vamos dividir o processo de decodificação especulativa em etapas simples:
A decodificação tradicional processa os tokens um por vez, o que leva a uma alta latência, mas a decodificação especulativa permite que um modelo menor gere tokens em massa, com o modelo maior verificando-os. Isso pode reduzir o tempo de resposta em 30 a 40%, diminuindo a latência de 25 a 30 segundos para apenas 15 a 18 segundos.
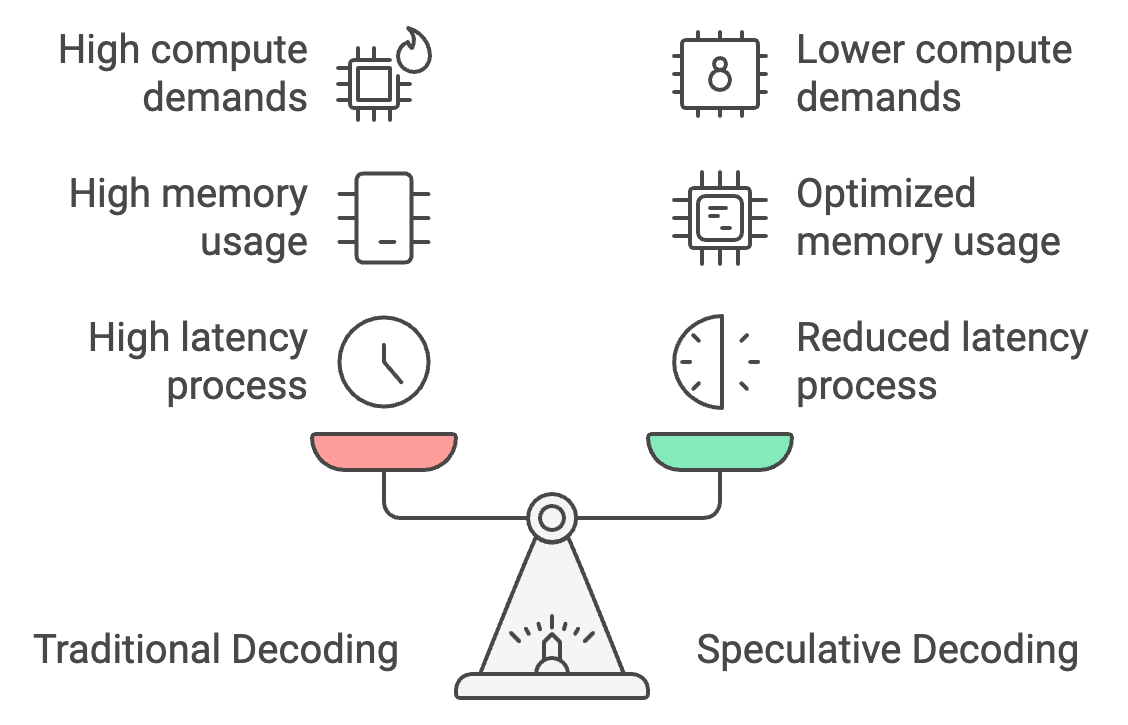
Além disso, a decodificação especulativa otimiza o uso da memória, transferindo a maior parte da geração de tokens para o modelo menor, reduzindo os requisitos de memória de 26 GB para cerca de 14 GB e fazendo com que o no dispositivo inferência no dispositivo mais acessível.
Por fim, ele reduz as demandas de computação em 50%, pois o modelo maior apenas verifica em vez de gerar tokens, permitindo um desempenho mais suave em dispositivos móveis com energia limitada e evitando o superaquecimento.
Para implementar um exemplo prático de decodificação especulativa usando os modelos Gemma2. Exploraremos como a decodificação especulativa se compara à inferência padrão em termos delatência e desempenho do .
Para começar, importe as dependências e defina a semente.
Em seguida, verifique se a GPU está disponível na máquina em que você está operando. Isso é necessário principalmente para modelos grandes, como Gemma 2-9B-it ou LLama2-13B.
Por fim, carregamos os modelos pequeno e grande junto com seus tokenizadores. Aqui, estamos usando o modelo Gemma2-2b-it (instruído) para o modelo preliminar e o modelo Gemma2-9b-it para verificação.
Há alguns outros modelos que também podem ser usados como alternativa. Por exemplo:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
# Set Seed
set_seed(42)
# Check if GPU is available
device = "cuda" if torch.cuda.is_available() else "cpu"
# Load the smaller Gemma2 model (draft generation)
small_tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b-it", device_map="auto")
small_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it", device_map="auto", torch_dtype=torch.bfloat16)
# Load the larger Gemma2 model (verification)
big_tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it", device_map="auto")
big_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it", device_map="auto", torch_dtype=torch.bfloat16)Primeiro, realizamos a inferência apenas no modelo grande (Gemma2-9b-it) e geramos resultados. Comece por tokenização o prompt de entrada e movendo os tokens para o dispositivo correto (GPU, se disponível). O método generate produz a saída do modelo, gerando até max_new_tokens. O resultado é então decodificado a partir de IDs de token para um texto legível por humanos.
def normal_inference(big_model, big_tokenizer, prompt, max_new_tokens=50):
inputs = big_tokenizer(prompt, return_tensors='pt').to(device)
outputs = big_model.generate(inputs['input_ids'], max_new_tokens=max_new_tokens)
return big_tokenizer.decode(outputs[0], skip_special_tokens=True)Em seguida, tentamos o método de decodificação especulativa, no qual seguimos as seguintes etapas:
def speculative_decoding(small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens=50):
# Step 1: Use the small model to generate the draft
inputs = small_tokenizer(prompt, return_tensors='pt').to(device)
small_outputs = small_model.generate(inputs['input_ids'], max_new_tokens=max_new_tokens)
draft = small_tokenizer.decode(small_outputs[0], skip_special_tokens=True)
# Step 2: Verify the draft with the big model
big_inputs = big_tokenizer(draft, return_tensors='pt').to(device)
# Step 3: Calculate log-likelihood of the draft tokens under the large model
with torch.no_grad():
outputs = big_model(big_inputs['input_ids'])
log_probs = torch.log_softmax(outputs.logits, dim=-1)
draft_token_ids = big_inputs['input_ids']
log_likelihood = 0
for i in range(draft_token_ids.size(1) - 1):
token_id = draft_token_ids[0, i + 1]
log_likelihood += log_probs[0, i, token_id].item()
avg_log_likelihood = log_likelihood / (draft_token_ids.size(1) - 1)
# Return the draft and its log-likelihood score
return draft, avg_log_likelihoodObservação: O log-likelihood é o logaritmo da probabilidade que um modelo atribui a uma sequência específica de tokens. Aqui, ele reflete a probabilidade ou a "confiança" do modelo de que a sequência de tokens (o texto gerado) é válida, considerando os tokens anteriores.
Depois de implementar as duas técnicas, podemos medir suas respectivas latências. Para a decodificação especulativa, avaliamos o desempenho examinando o valor de log-likelihood. Um valor de log-likelihood próximo de zero, especialmente na faixa negativa, indica que o texto gerado é preciso.
def measure_latency(small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens=50):
# Measure latency for normal inference (big model only)
start_time = time.time()
normal_output = normal_inference(big_model, big_tokenizer, prompt, max_new_tokens)
normal_inference_latency = time.time() - start_time
print(f"Normal Inference Output: {normal_output}")
print(f"Normal Inference Latency: {normal_inference_latency:.4f} seconds")
print("\n\n")
# Measure latency for speculative decoding
start_time = time.time()
speculative_output, log_likelihood = speculative_decoding(
small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens
)
speculative_decoding_latency = time.time() - start_time
print(f"Speculative Decoding Output: {speculative_output}")
print(f"Speculative Decoding Latency: {speculative_decoding_latency:.4f} seconds")
print(f"Log Likelihood (Verification Score): {log_likelihood:.4f}")
return normal_inference_latency, speculative_decoding_latencyIsso retorna:
A latência mais baixa se deve ao menor tempo gasto pelo modelo menor para a geração de texto e ao menor tempo gasto pelo modelo maior apenas para verificar o texto gerado.
Vamos comparar a decodificação especulativa com a inferência autorregressiva usando cinco prompts:
# List of 5 prompts
prompts = [
"The future of artificial intelligence is ",
"Machine learning is transforming the world by ",
"Natural language processing enables computers to understand ",
"Generative models like GPT-3 can create ",
"AI ethics and fairness are important considerations for "
]
# Inference settings
max_new_tokens = 200
# Initialize accumulators for latency, memory, and tokens per second
total_tokens_per_sec_normal = 0
total_tokens_per_sec_speculative = 0
total_normal_latency = 0
total_speculative_latency = 0
# Perform inference on each prompt and accumulate the results
for prompt in prompts:
normal_latency, speculative_latency, _, _, tokens_per_sec_normal, tokens_per_sec_speculative = measure_latency_and_memory(
small_model, big_model, small_tokenizer, big_tokenizer, prompt, max_new_tokens
)
total_tokens_per_sec_normal += tokens_per_sec_normal
total_tokens_per_sec_speculative += tokens_per_sec_speculative
total_normal_latency += normal_latency
total_speculative_latency += speculative_latency
# Calculate averages
average_tokens_per_sec_normal = total_tokens_per_sec_normal / len(prompts)
average_tokens_per_sec_speculative = total_tokens_per_sec_speculative / len(prompts)
average_normal_latency = total_normal_latency / len(prompts)
average_speculative_latency = total_speculative_latency / len(prompts)
# Output the averages
print(f"Average Normal Inference Latency: {average_normal_latency:.4f} seconds")
print(f"Average Speculative Decoding Latency: {average_speculative_latency:.4f} seconds")
print(f"Average Normal Inference Tokens per second: {average_tokens_per_sec_normal:.2f} tokens/second")
print(f"Average Speculative Decoding Tokens per second: {average_tokens_per_sec_speculative:.2f} tokens/second")Average Normal Inference Latency: 25.0876 seconds
Average Speculative Decoding Latency: 15.7802 seconds
Average Normal Inference Tokens per second: 7.97 tokens/second
Average Speculative Decoding Tokens per second: 12.68 tokens/secondIsso mostra que a decodificação especulativa é mais eficiente, gerando mais tokens por segundo do que a inferência normal. Essa melhoria se deve ao fato de o modelo menor lidar com a maior parte da geração de texto, enquanto a função do modelo maior se limita à verificação, reduzindo a carga computacional geral em termos de latência e memória.
Com esses requisitos de memória, podemos implantar facilmente técnicas de decodificação especulativa em dispositivos de borda e ganhar velocidade em nossos aplicativos no dispositivo, como chatbots, tradutores de idiomas, jogos e muito mais.
A abordagem acima é eficiente, mas há uma compensação entre a latência e a otimização da memória para a inferência no dispositivo. Para resolver isso, vamos aplicar a quantização a modelos pequenos e grandes. Você pode experimentar e tentar aplicar a quantização somente ao modelo grande, pois o modelo pequeno já ocupa o menor espaço.
A quantificação é aplicada a modelos menores e maiores usando a configuração BitsAndBytesConfig da biblioteca Hugging Face transformers. A quantização nos permite reduzir significativamente o uso da memória e, em muitos casos, melhorar a velocidade de inferência, convertendo os pesos do modelo em uma forma mais compacta.
Adicione o seguinte trecho de código ao código acima para que você veja os efeitos da quantização.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # Enables 4-bit quantization
bnb_4bit_quant_type="nf4", # Specifies the quantization type (nf4)
bnb_4bit_compute_dtype=torch.bfloat16, # Uses bfloat16 for computation
bnb_4bit_use_double_quant=False, # Disables double quantization to avoid additional overhead
)
# Load the smaller and larger Gemma2 models with quantization applied
small_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-it", device_map="auto", quantization_config=bnb_config)
big_model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it", device_map="auto", quantization_config=bnb_config)Aqui está uma rápida comparação das saídas para mostrar os efeitos da decodificação especulativa com e sem quantização:
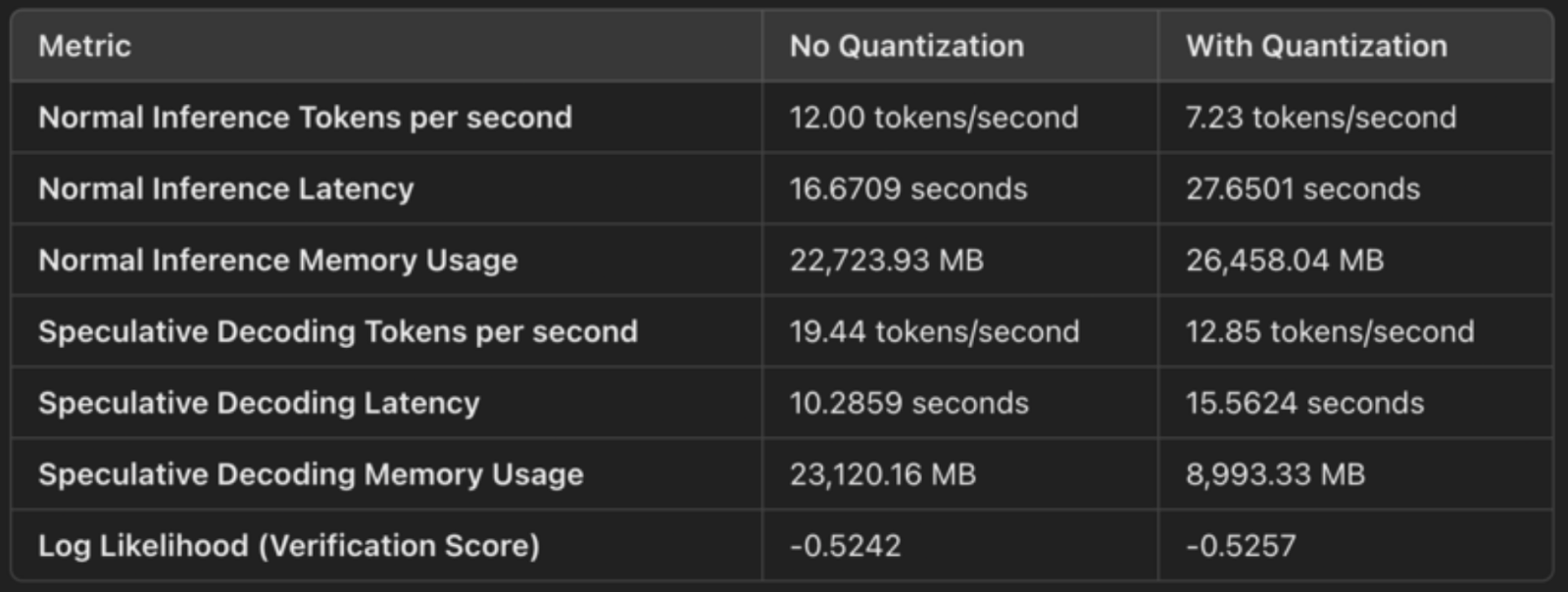
A configuração especifica load_in_4bit=True, o que significa que os pesos do modelo são quantizados de seu formato original de ponto flutuante de 32 ou 16 bits para inteiros de 4 bits. Isso reduz o espaço de memória do modelo. A quantização comprime os pesos do modelo, o que nos permite armazená-los e operá-los com mais eficiência. Essas são aseconomias concretasde memória do :
A configuração bnb_4bit_compute_dtype=torch.bfloat16 especifica que o cálculo é realizado em bfloat16 (BF16), um formato de ponto flutuante mais eficiente. O BF16 tem uma faixa dinâmica mais ampla do que o FP16, mas ocupa metade da memória em comparação com o FP32, o que o torna um bom equilíbrio entre precisão e desempenho.
O uso do BF16, especialmente em GPUs NVIDIA (como a A100), utiliza Tensor Cores, que são otimizados para operações do BF16. Isso resulta em multiplicações mais rápidas de matrizes e outros cálculos durante a inferência.
Para decodificação especulativa, observamos uma melhora na latência:
O menor espaço de memória significa acesso mais rápido à memória e uso mais eficiente dos recursos da GPU, levando a uma geração mais rápida.
A opção bnb_4bit_quant_type="nf4" especifica Norm-Four Quantization (NF4), que é otimizada para redes neurais. A quantização NF4 ajuda a manter a precisão de partes importantes do modelo, mesmo que os pesos sejam representados em 4 bits. Isso minimiza a degradação do desempenho do modelo em comparação com a quantização simples de 4 bits.
O NF4 ajuda a alcançar um equilíbrio entre a compactação da quantização de 4 bits e a precisão das previsões do modelo, garantindo que o desempenho permaneça próximo ao original e, ao mesmo tempo, reduzindo drasticamente o uso da memória.
A quantização dupla (bnb_4bit_use_double_quant=False) introduz uma camada adicional de quantização sobre os pesos de 4 bits, o que pode reduzir ainda mais o uso da memória, mas também aumenta a sobrecarga de computação. Nesse caso, a quantização dupla é desativada para evitar que você diminua a velocidade da inferência.
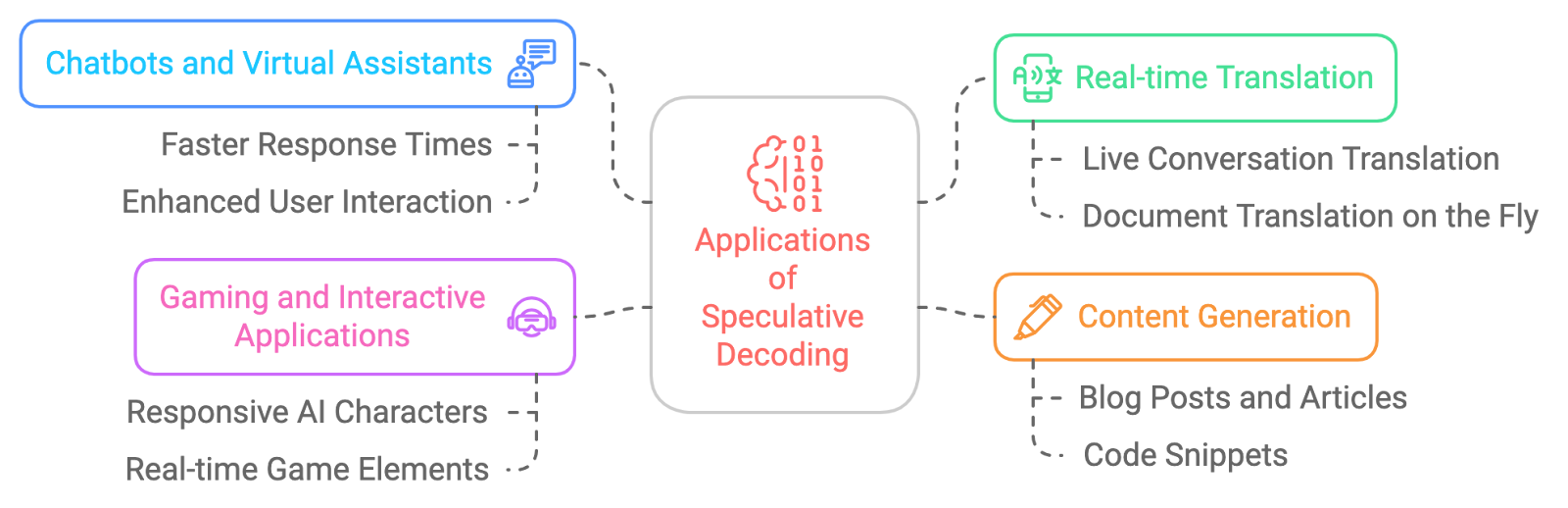
As possíveis aplicações da decodificação especulativa são vastas e empolgantes. Aqui estão alguns exemplos:
Embora a decodificação especulativa seja muito promissora, ela não está isenta de desafios:
A decodificação especulativa é uma técnica avançada que tem o potencial de revolucionar a maneira como interagimos com grandes modelos de linguagem. Ele pode acelerar significativamente a inferência LLM sem comprometer a qualidade do texto gerado. Embora existam desafios a serem superados, os benefícios da decodificação especulativa são inegáveis, e podemos esperar que sua adoção cresça nos próximos anos, possibilitando uma nova geração de aplicativos de IA mais rápidos, mais responsivos e mais eficientes.
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Elena Kosourova
15 min
blog
Natassha Selvaraj
15 min
blog
Abid Ali Awan
11 min
Tutorial
Dimitri Didmanidze
Tutorial
Kurtis Pykes
Tutorial
Arunn Thevapalan


