
Curso
Introducción a los LLMs en Python
3 h
33.6K
¿Te has encontrado alguna vez con problemas de memoria al afinar modelos o te has dado cuenta de que el proceso tarda un tiempo insoportablemente largo en completarse? Si buscas una solución más eficaz y rápida que utilizar la biblioteca Transformers para afinar grandes modelos lingüísticos (LLM), ¡has llegado al lugar adecuado!
En este tutorial, exploraremos cómo afinar el modelo Llama 3.1 3B utilizando sólo 9 GB de VRAM, consiguiendo velocidades 2 veces más rápidas que con los métodos tradicionales de Transformers. También veremos cómo realizar una inferencia rápida, convertir el modelo en formatos de archivo compatibles con vLLM y GGUF, y enviar sin problemas el modelo guardado al Hugging Face Hub con sólo unas líneas de código.
Si eres nuevo en estos conceptos, asegúrate de realizar el curso Dominar los Conceptos de los Grandes Modelos Lingüísticos (LLM) para construir una base sólida antes de sumergirte en el perfeccionamiento.

Imagen del autor
Unsloth AI es un marco de Python diseñado para ajustar y acceder rápidamente a grandes modelos lingüísticos. Ofrece una API sencilla y un rendimiento que es 2 veces más rápido en comparación con los Transformers.
Acceder al modelo Llama-3.1 utilizando Unsloth es bastante sencillo. No cargaremos el modelo de 16 bits. En su lugar, cargaremos la versión de 4 bits disponible en la Cara Abrazada para ahorrar memoria de la GPU y para una inferencia más rápida.
%%capture
%pip install unslothFastLanguageModel. from transformers import TextStreamer
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-bnb-4bit"
)
FastLanguageModel.for_inference(model)prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
inputs = tokenizer(
[
prompt_style.format(
"You are a professional machine learning engineer",
"How would you deal with NaN validation loss?",
"",
)
],
return_tensors="pt",
).to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=128)
Hemos recibido una respuesta positiva sobre cómo gestionar la pérdida de validación NaN.

Si tienes problemas para ejecutar el código anterior en Kaggle, aquí tienes el Cuaderno de muestra: Acceder a los LLM utilizando Unsloth.
Al cursar el Introducción al LLM en Python aprenderás los fundamentos de la arquitectura Transformer, incluyendo cómo construirla, afinarla y evaluarla. Es tu puerta de entrada al mundo de la puesta a punto del LLM utilizando Python.
En esta guía, aprenderemos a poner a punto Llama 3.1 en el programa lighteval/MATH utilizando Unsloth. El conjunto de datos consiste en problemas de álgebra con soluciones en formato markdown. El conjunto de datos se divide en cinco niveles de dificultad.
Para comprender mejor esta guía, te recomiendo que aprendas la teoría que hay detrás de cada paso del ajuste fino de los LLM leyendo Guía introductoria al ajuste fino de los LLM. Tómate unos minutos para revisar la guía, ya que te ayudará a entender este proceso.
Estamos utilizando un cuaderno Kaggle como nuestro IDE en la nube, y necesitamos configurar el cuaderno antes de trabajar con el modelo o los datos.
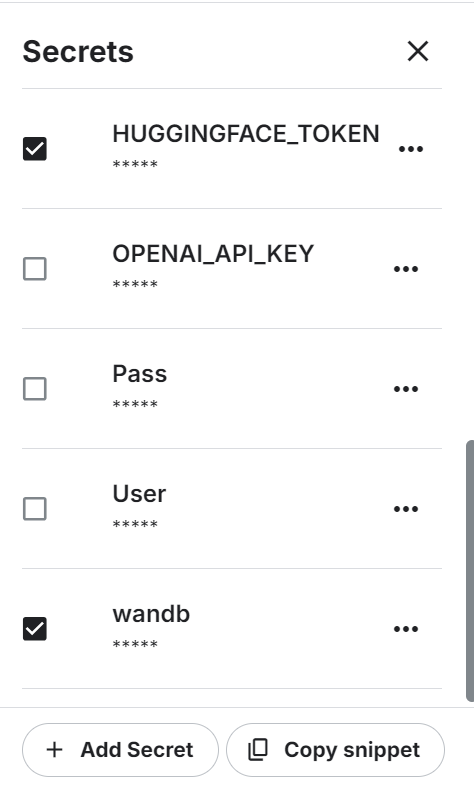
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama-3.1-8B-bnb-4bit on Math Dataset',
job_type="training",
anonymous="allow"
)Al igual que en la sección de inferencia del modelo, cargaremos la versión cuantificada de 4 bits del modelo Llama 3.1 utilizando la longitud máxima de secuencia de 2048 y el tipo de datos Ninguno.
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype
)A continuación, cargaremos el conjunto de datos y lo procesaremos. Para ello, primero tenemos que crear un estilo de aviso que nos ayude a obtener los resultados requeridos.
El estilo de aviso incluye un aviso del sistema, una instrucción y un marcador de posición para la entrada y la respuesta.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
You are a math genius who can solve any level of algebraic problems. Please answer the following math question.
### Input:
{}
### Response:
{}"""Después, crea la función que utilizará el estilo "prompt" para introducir los problemas matemáticos y las soluciones, convirtiéndolos en el texto adecuado. Asegúrate de añadir EOS_TOKEN para evitar cualquier reputación.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["problem"]
outputs = examples["solution"]
texts = []
for input, output in zip(inputs, outputs):
text = prompt_style.format(input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }Carga las 500 muestras del conjunto de datos, aplica la función formatting_prompts_func al conjunto de datos y visualiza la primera muestra de la columna de texto.
from datasets import load_dataset
dataset = load_dataset("lighteval/MATH", split="train[0:500]", trust_remote_code=True)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][0]El texto tiene una indicación del sistema, una instrucción, una pregunta de un problema de álgebra y la solución a ese problema.

Añadimos el LoRA (adaptador de bajo rango) al modelo utilizando los módulos lineales del modelo base.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=False,
loftq_config=None,
)Configura el entrenador con el modelo, el tokenizador, la longitud máxima de la secuencia y los argumentos de entrenamiento. Esto es bastante similar a configurar un entrenador utilizando la biblioteca Transformers y TRL.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)El entrenamiento del modelo duró casi 19 minutos, lo que es impresionante. La pérdida de entrenamiento se ha reducido significativamente con cada paso.
trainer_stats = trainer.train()
Puedes consultar el rendimiento detallado del modelo y las métricas de hardware accediendo al panel Pesos y sesgos.
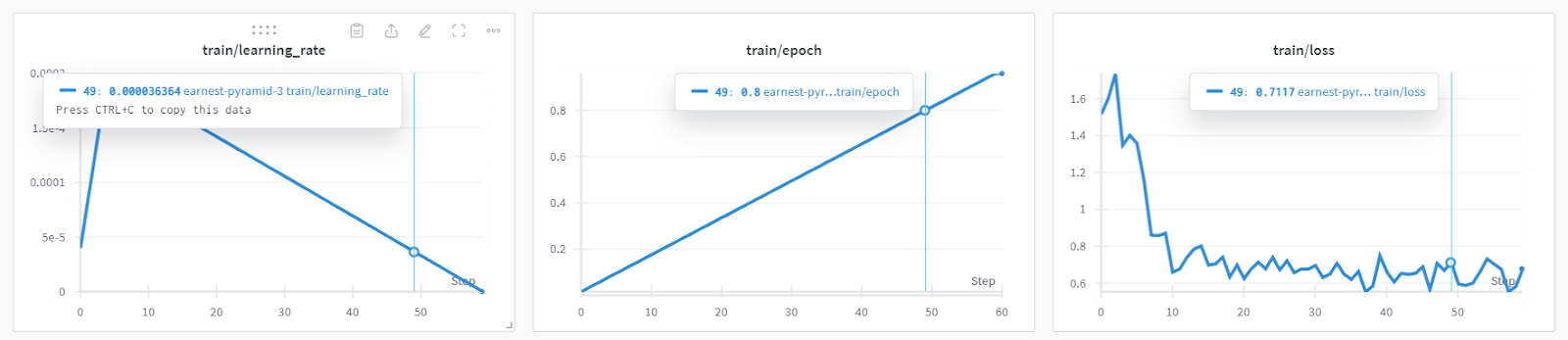
También puedes utilizar torch y trainer_stats para generar tu propio informe.
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory /max_memory*100, 3)
lora_percentage = round(used_memory_for_lora/max_memory*100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")El modelo se entrenó en 20 minutos, y el pico de memoria reservada para el entrenamiento fue de aproximadamente 3,7 GB. Esto es relativamente bajo en comparación con el método tradicional, que implica cargar el modelo completo, cuantizarlo y, por último, ajustarlo. En ese caso, necesitará al menos 15 GB de memoria GPU.
1207.5478 seconds used for training.
20.13 minutes used for training.
Peak reserved memory = 9.73 GB.
Peak reserved memory for training = 3.746 GB.
Peak reserved memory % of max memory = 61.241 %.
Peak reserved memory for training % of max memory = 23.578 %.Para probar el modelo tras el ajuste fino, necesitamos activar la inferencia rápida. A continuación, introduciremos una pregunta de álgebra de muestra del conjunto de datos en el estilo de pregunta y la convertiremos en tokens. A continuación, utilizaremos el modelo para generar la respuesta y descodificaremos la salida para mostrar el texto.
El texto generado estaba en formato Markdown, pero lo hemos convertido para mostrar el texto con las ecuaciones matemáticas adecuadas.
from IPython.display import display, Markdown
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
prompt_style.format(
"If the system of equations \begin{align*} 3x+y&=a,\\ 2x+5y&=2a, \end{align*} has a solution $(x,y)$ when $x=2$, compute $a$.",
"",
)
],
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=250,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
Markdown(response[0].split("\n\n### Response:")[1])Como vemos, la respuesta generada se ajusta al conjunto de datos y nos proporciona las soluciones de los problemas algebraicos.

Guardemos nuestro modelo afinado y enviémoslo al Hub Cara Abrazada para que puedas compartirlo o desplegarlo fácilmente.
new_model_online = "kingabzpro/Llama-3.1-8B-MATH"
new_model_local = "Llama-3.1-8B-MATH"
model.save_pretrained(new_model_local) # Local saving
tokenizer.save_pretrained(new_model_local) # Local savingEl siguiente código creará un nuevo repositorio en la Cara Abrazada y luego empujará el LoRA y el tokenizador con los metadatos.
model.push_to_hub(new_model_online) # Online saving
tokenizer.push_to_hub(new_model_online) # Online saving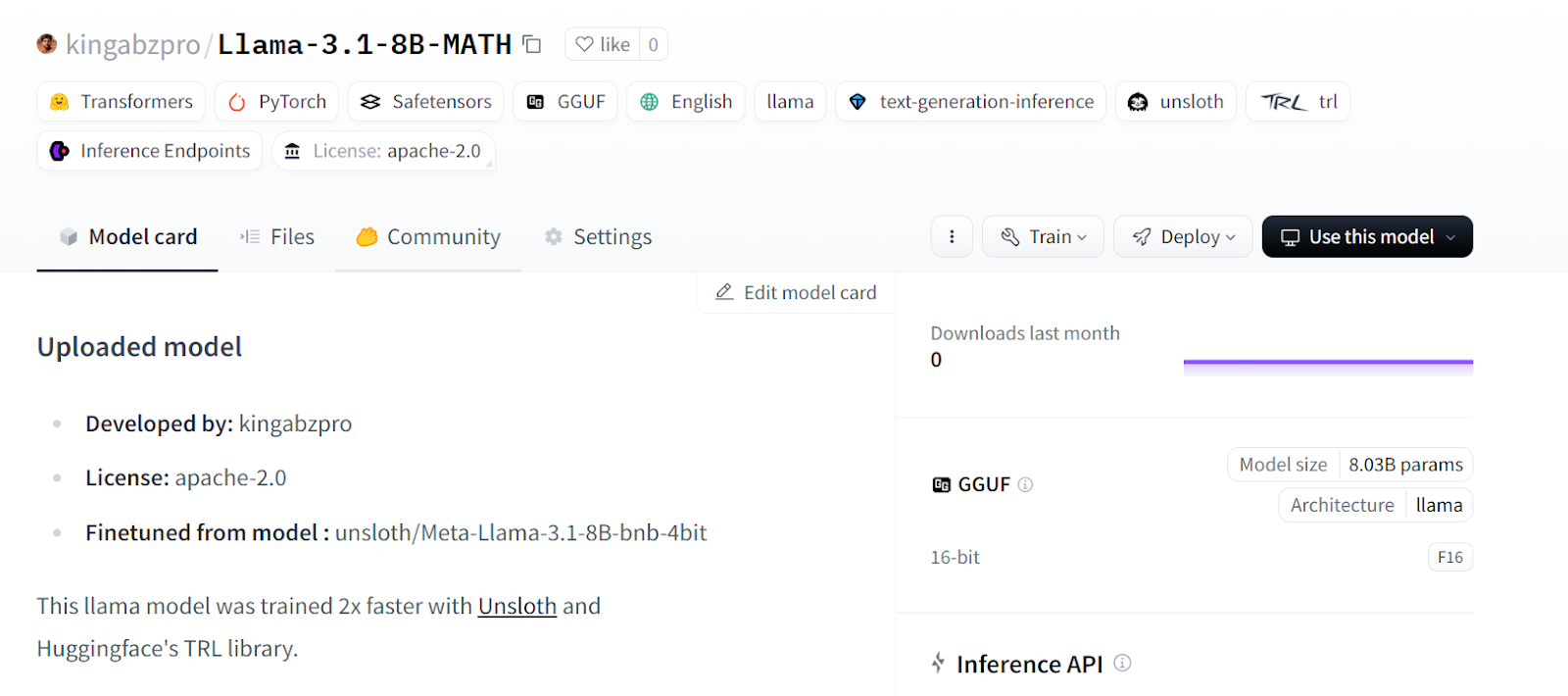
Fuente: kingabzpro/Llama-3.1-8B-MATH
Si tienes problemas al ajustar el LLM con Unsloth, consulta la sección Ajuste fino de los LLM con Unsloth Cuaderno Kaggle. Contiene código estable que puedes ejecutar por tu cuenta para reproducir los resultados.
El siguiente paso en tu viaje hacia la IA es utilizar los LLM para desarrollar aplicaciones de IA eficaces. Puedes encontrar más información siguiendo el enlace Cómo crear aplicaciones LLM con LangChain tutorial.
Fusionar el LoRa con el modelo base requiere VRAM adicional y almacenamiento local. Para no sobrepasar ningún límite, crearemos un nuevo cuaderno Kaggle con la GPU P100 como acelerador. También activaremos la API Cara Abrazada para acceder a la clave API.
%%capture
%pip install unslothfrom huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)from unsloth import FastLanguageModel
new_model_name = "kingabzpro/Llama-3.1-8B-MATH"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = new_model_name, # YOUR MODEL YOU USED FOR TRAINING
max_seq_length = 2048,
dtype = None,
load_in_4bit = True,
)
FastLanguageModel.for_inference(model); 
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
You are a math genius who can solve any level of algebraic problem. Please answer the following math question.
### Input:
{}
### Response:
{}"""from IPython.display import display, Markdown
inputs = tokenizer(
[
prompt_style.format(
"Solve the equation $|y-6| + 2y = 9$ for $y$.", # input
"", # output - leave this blank for generation!
)
],
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=250,
pad_token_id=tokenizer.eos_token_id,
)
response = tokenizer.batch_decode(outputs)
Markdown(response[0].split("\n\n### Response:")[1])
El modelo funciona perfectamente y está listo para fusionarse con el modelo base.
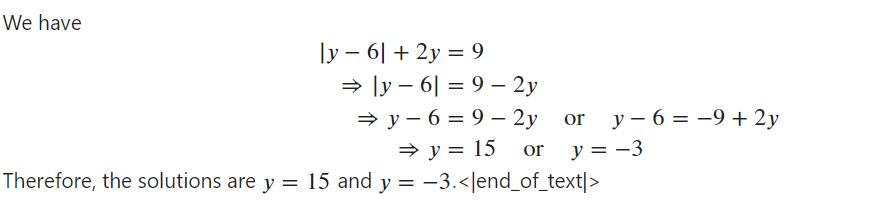
working sólo nos proporciona 20 GB, lo que no es suficiente para fusionar y enviar el modelo completo. Crear otra carpeta en el directorio raíz nos permitirá acceder a los 60 GB de almacenamiento temporal.%mkdir ../temp
%cd /kaggle/tempmodel.push_to_hub_merged(new_model_name, tokenizer, save_method = "merged_16bit")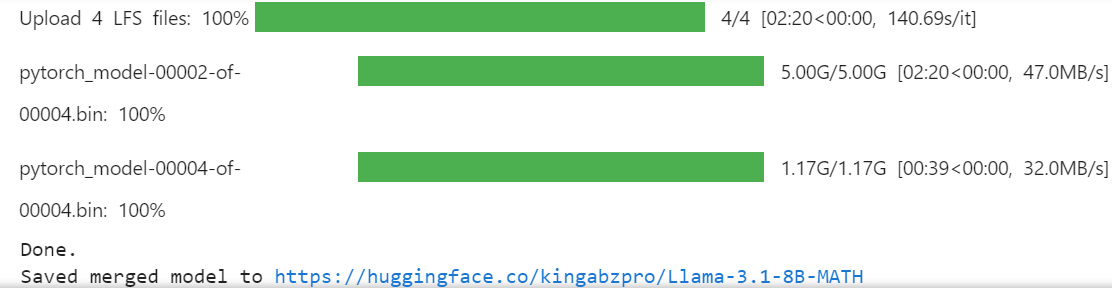
model.push_to_hub_gguf(new_model_name, tokenizer, quantization_method = "q4_k_m")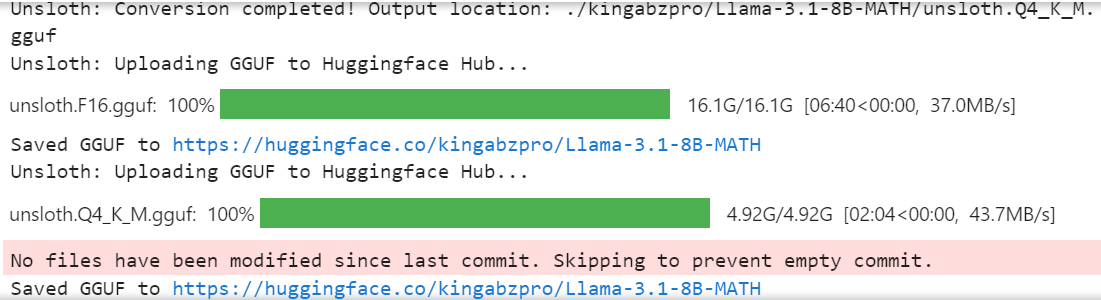
El modelo completo de 16 bits, el adaptador y los archivos GGUF cuantizados están disponibles en tu repositorio de modelos. Para utilizar localmente el modelo ajustado, sólo tienes que descargar el archivo GGUF cuantizado y empezar a utilizarlo con Jan, Misty, GPT4ALL u Ollama.
Sigue el enlacePuesta a punto de Llama 3.2 y uso local: Una guía paso a paso tutorial para aprender a afinar el modelo Llama 3.2 en un conjunto de datos de atención al cliente, fusionar y exportar el modelo al Hugging Face Hub, y convertir el modelo afinado al formato GGUF para poder utilizarlo localmente con la aplicación Jan.
Fuente: kingabzpro/Llama-3.1-8B-MATH
Si tienes problemas al cargar y fusionar el LoRA con el modelo base, consulta la sección Fusión del Adoptante LoRA con Unsloth para obtener más ayuda.
También te recomiendo que leas el blog 12 proyectos LLM para todos los niveles. Incluye una lista de proyectos LLM para principiantes, estudiantes de nivel intermedio, becarios de último curso y expertos.
En este tutorial, aprendimos a afinar eficazmente el modelo Llama 3.1 3B utilizando pocos recursos informáticos y consiguiendo velocidades que son el doble de rápidas que los métodos tradicionales.
También aprendimos a ejecutar la inferencia rápida del modelo, a fusionar el LoRA con el modelo base y a enviarlo al hub Cara Abrazada.
Además, convertimos el modelo al formato llama.cpp y lo cuantizamos para que el modelo ajustado pueda utilizarse fácilmente de forma local en el portátil mediante las aplicaciones Jan o GPT4ALL.
Para mejorar el rendimiento del modelo, recomendamos encarecidamente afinar el modelo en el conjunto de datos completo, optimizar los hiperparámetros y trabajar en el estilo de indicación. Incluso después de un ajuste fino, puedes mejorar el rendimiento de las aplicaciones de IA de muchas formas utilizando la llamada a funciones y los pipelines RAG.
Aprende qué solución es mejor para tus casos concretos siguiendo RAG vs Ajuste fino: Un tutorial completo con ejemplos prácticos Guía. Incluye un código de muestra para que lo pruebes con tu conjunto de datos y compares los resultados.
Los mejores cursos LLM
Curso
Curso
Curso