
programa
Desarrollar grandes modelos lingüísticos
16 h
Últimamente, el campo de los grandes modelos lingüísticos (LLM) está cambiando rápidamente. Los LLM más recientes se están diseñando para ser más pequeños e inteligentes, lo que los hace menos caros y más fáciles de usar en comparación con los modelos más grandes.
Con el lanzamiento de Llama 3.2, ahora tenemos acceso a modelos más pequeños, como las variantes 1B y 3B. Aunque estos modelos más pequeños pueden no igualar la precisión de los modelos más grandes en tareas generales, pueden afinarse para que funcionen excepcionalmente bien en áreas específicas, como la clasificación de emociones en las interacciones de atención al cliente. Esta capacidad les permite sustituir potencialmente a los modelos tradicionales en estos ámbitos.
En este tutorial, exploraremos las capacidades de la visión y los modelos ligeros de Llama 3.2. Aprenderemos a acceder al modelo Llama 3.2 3B, a afinarlo en un conjunto de datos de asistencia al cliente y, posteriormente, a fusionarlo y exportarlo al hub Cara Abrazada.
Si eres nuevo en la IA, es muy recomendable que realices el curso Fundamentos de la IA y aprendas los fundamentos de ChatGPT, grandes modelos de lenguaje, IA generativa y mucho más.

Imagen del autor
La familia de modelos de código abierto Llama 3.2 tiene dos variantes: los modelosligeros y de visión . Los modelos de visión destacan en el razonamiento de imágenes y en la vinculación de la visión con el lenguaje, mientras que los modelos ligeros son buenos en la generación de textos multilingües y en la llamada a herramientas para dispositivos de borde.
El modelo ligero tiene dos variantes más pequeñas: 1B y 3B. Estos modelos son buenos en tareas de generación de textos multilingües y de llamada a herramientas. Son pequeños, lo que significa que pueden ejecutarse en un dispositivo para garantizar que los datos nunca salgan de él y proporcionan generación de texto a alta velocidad con un bajo coste informático.
Para crear estos modelos ligeros y eficientes, Llama 3.2 utiliza técnicas de poda y destilación de conocimientos. La poda reduce el tamaño del modelo conservando el rendimiento, y la destilación de conocimientos utiliza las redes más grandes para compartir conocimientos con las más pequeñas, mejorando su rendimiento.
El modelo 3B supera a otros modelos como Gemma 2 (2.6B) y Phi 3.5-mini en tareas como el seguimiento de instrucciones, el resumen, la reescritura de instrucciones y el uso de herramientas.
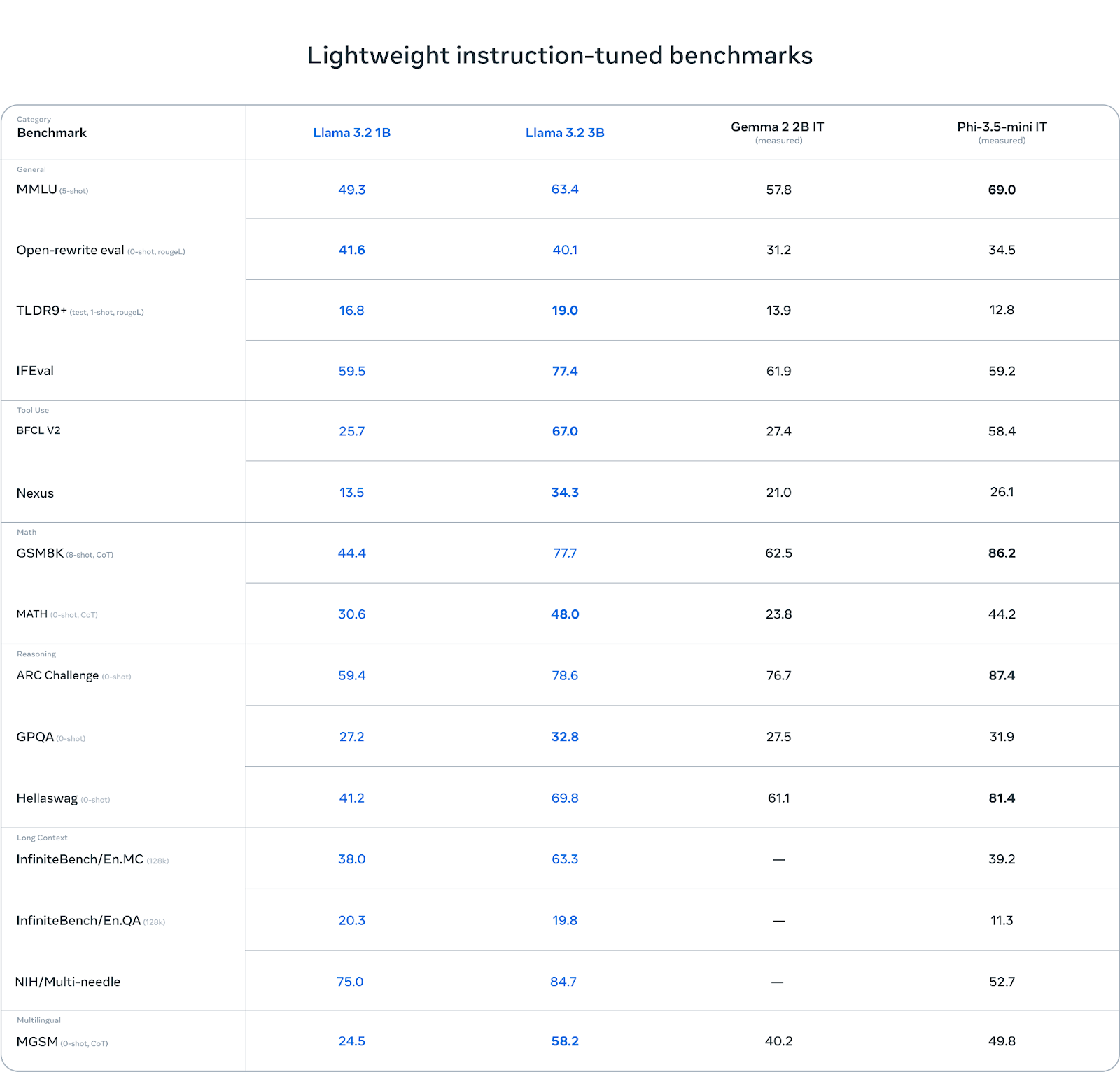
Fuente: Llama 3.2: Revolucionando la IA y la visión de vanguardia con modelos abiertos y personalizables
Los modelos de visión se presentan en dos variantes: 11B y 90B. Estos modelos están diseñados para apoyar el razonamiento de imágenes. El 11B y el 90B pueden comprender e interpretar documentos, tablas y gráficos y realizar tareas como subtitulación de imágenes y conexión visual a tierra. Estas capacidades avanzadas de visión fueron posibles integrando codificadores de imágenes preentrenados con modelos lingüísticos que utilizan pesos adaptadores formados por capas de atención cruzada.
En comparación con Claude 3 Haiku y GPT-4o minilos modelos de visión Llama 3.2 han destacado en el reconocimiento de imágenes y en diversas tareas de comprensión visual, lo que los convierte en herramientas robustas para aplicaciones de IA multimodal.
Fuente: Llama 3.2: Revolucionando la IA y la visión de vanguardia con modelos abiertos y personalizables
Puedes obtener más información sobre los casos de uso de Llama 3.2, los puntos de referencia, Llama Guard 3 y la arquitectura del modelo leyendo nuestro último blog, Guía de Llama 3.2: Cómo funciona, casos prácticos y más.
Aunque el modelo Llama 3.2 está disponible gratuitamente y es de código abierto, tienes que aceptar los términos y condiciones y rellenar el formulario del sitio web.
Para acceder al último modelo Llama 3.2 en la plataforma Kaggle:
Fuente: Descargar Llama
Fuente: Meta | Llama 3.2 | Kaggle
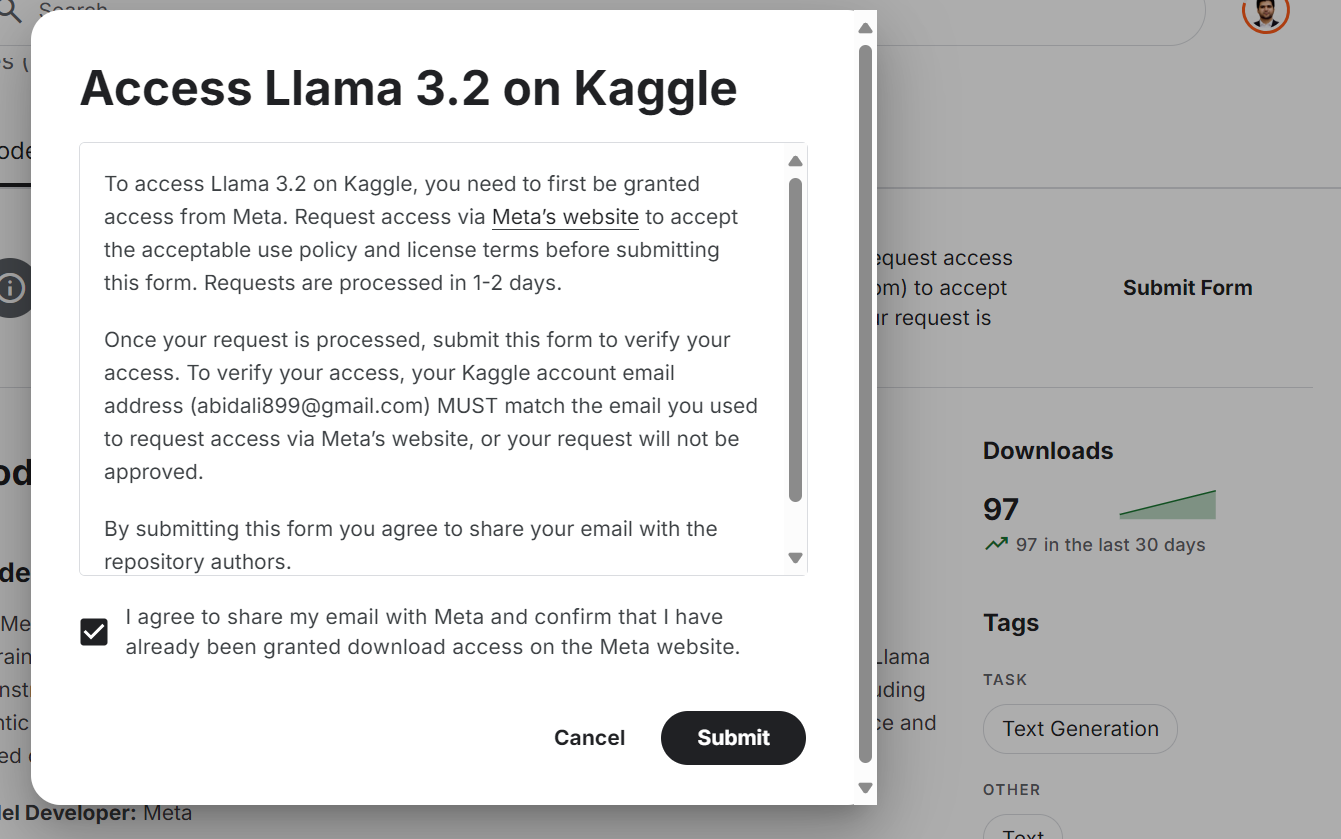
Fuente: Meta | Llama 3.2 | Kaggle
%%capture
%pip install -U transformers acceleratefrom transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, TextStreamer
import torch
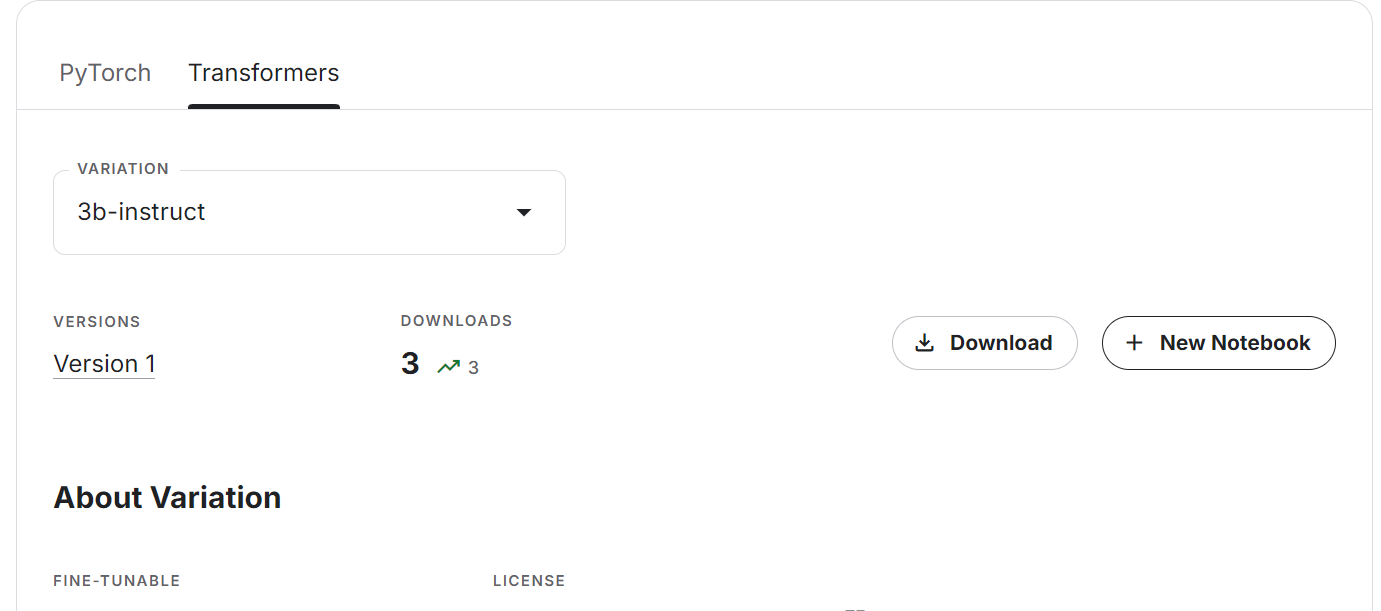
base_model = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)pad_token_id para evitar recibir mensajes de advertencia.if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
if model.config.pad_token_id is None:
model.config.pad_token_id = model.config.eos_token_idpipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)messages = [{"role": "user", "content": "Who is Vincent van Gogh?"}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])La respuesta es bastante precisa.

from IPython.display import Markdown, display
messages = [
{
"role": "system",
"content": "You are a skilled Python developer specializing in database management and optimization.",
},
{
"role": "user",
"content": "I'm experiencing a sorting issue in my database. Could you please provide Python code to help resolve this problem?",
},
]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
outputs = pipe(prompt, max_new_tokens=512, do_sample=True)
display(
Markdown(
outputs[0]["generated_text"].split(
"<|start_header_id|>assistant<|end_header_id|>"
)[1]
)
)El resultado es muy preciso. El modelo funciona bastante bien a pesar de tener sólo 3.000 millones de parámetros.
Si tienes dificultades para acceder a los modelos ligeros Llama 3.2, consulta el cuaderno, Acceso a los modelos ligeros Llama 3.2.
Acceder al modelo de Visión es sencillo, y no tienes que preocuparte por la memoria de la GPU, ya que en esta guía utilizaremos varias GPU.
Fuente: Meta | Llama 3.2 Visión | Kaggle
Fuente: Meta | Llama 3.2 Visión | Kaggle
%%capture
%pip install -U transformers accelerateimport torch
from transformers import MllamaForConditionalGeneration, AutoProcessor
base_model = "/kaggle/input/llama-3.2-vision/transformers/11b-vision-instruct/1"
processor = AutoProcessor.from_pretrained(base_model)
model = MllamaForConditionalGeneration.from_pretrained(
base_model,
low_cpu_mem_usage=True,
torch_dtype=torch.bfloat16,
device_map="auto",
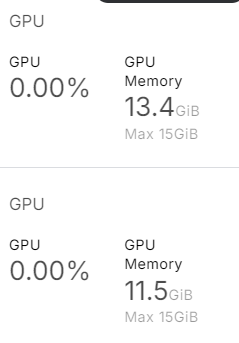
)Como podemos ver, utiliza casi 25 GB de memoria de la GPU. Esto será imposible de ejecutar en un ordenador portátil o en la versión gratuita de Google Colab.
import requests
from PIL import Image
url = "https://media.datacamp.com/cms/google/ad_4nxcz-j3ir2begccslzay07rqfj5ttakp2emttn0x6nkygls5ywl0unospj2s0-mrwpdtmqjl1fagh6pvkkjekqey_kwzl6qnodf143yt66znq0epflvx6clfoqw41oeoymhpz6qrlb5ajer4aeniogbmtwtd.png"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Describe the tutorial feature image."}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=120)
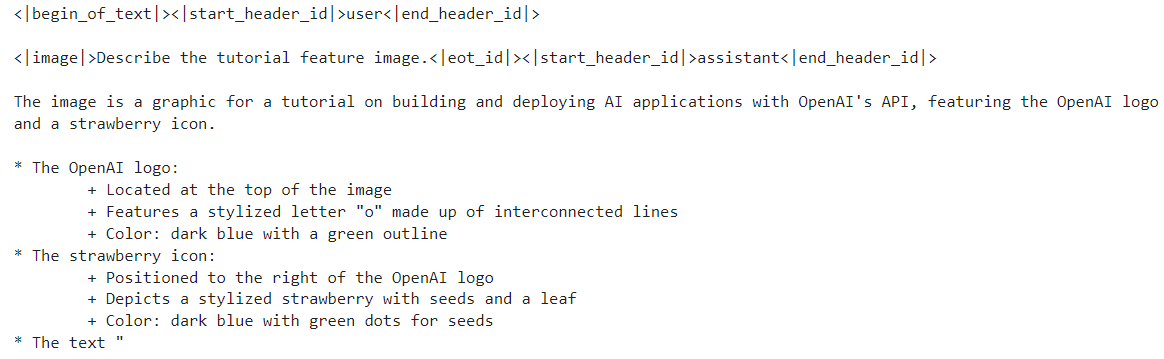
print(processor.decode(output[0]))Como resultado, obtenemos una descripción detallada de la imagen. Es bastante preciso.
Si tienes problemas al ejecutar el código anterior, consulta la página Acceso a los modelos de visión de Llama 3.2 Cuaderno Kaggle.
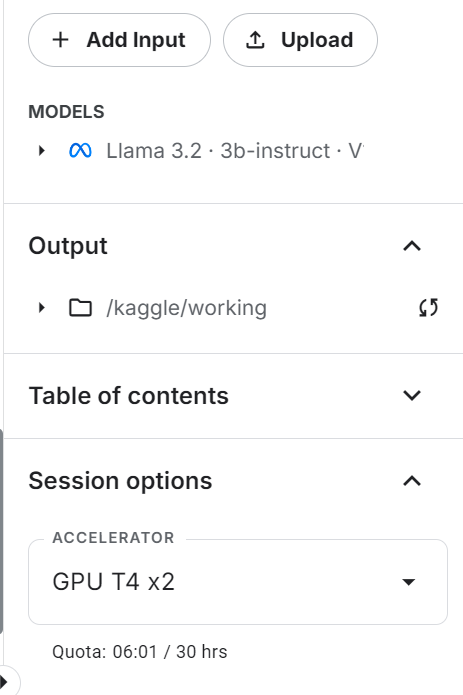
En esta sección, aprenderemos a afinar el modelo Llama 3.2 3B Instruct utilizando la biblioteca Transformers en el conjunto de datos de atención al cliente. Utilizaremos Kaggle para acceder a GPUs libres y obtener mayor RAM que Colab.
Inicia el nuevo cuaderno en Kaggle y establece las variables de entorno. Utilizaremos la API Cara Abrazada para guardar el modelo y Pesos y Sesgos para seguir su rendimiento.
Instala y actualiza todos los paquetes Python necesarios.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandbCarga los paquetes y funciones de Python que utilizaremos a lo largo del proceso de ajuste y evaluación.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_formatInicia sesión en Hugging Face CLI utilizando la clave API.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Conéctate a Pesos y Sesgos utilizando la clave API e instala el nuevo proyecto.
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama 3.2 on Customer Support Dataset',
job_type="training",
anonymous="allow"
)Establece las variables de modo base, conjunto de datos y nombre del nuevo modelo. Las utilizaremos en varios lugares de este proyecto, por lo que es mejor establecerlas al principio para evitar confusiones.
base_model = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
new_model = "llama-3.2-3b-it-Ecommerce-ChatBot"
dataset_name = "bitext/Bitext-customer-support-llm-chatbot-training-dataset"Establece el tipo de datos y la implementación de la atención.
# Set torch dtype and attention implementation
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
torch_dtype = torch.bfloat16
attn_implementation = "flash_attention_2"
else:
torch_dtype = torch.float16
attn_implementation = "eager"Carga el modelo y el tokenizador proporcionando el directorio local del modelo. Aunque nuestro modelo es pequeño, cargar el modelo completo y afinarlo llevará algún tiempo. En su lugar, cargaremos el modelo en cuantización de 4 bits.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)Cargaremos el Bitext-soporte-cliente-llm-chatbot del hub Cara Abrazada. Se trata de un conjunto de datos sintéticos híbridos que utilizaremos para crear nuestro propio chatbot personalizado de atención al cliente.
Cargaremos, barajaremos y seleccionaremos sólo 1000 muestras. Estamos afinando el modelo en un pequeño subconjunto para reducir el tiempo de entrenamiento, pero siempre puedes seleccionar el modelo completo.
A continuación, crearemos la columna "texto" utilizando las instrucciones del sistema, las consultas de los usuarios y las respuestas de los asistentes. A continuación, convertiremos la respuesta JSON al formato del chat.
#Importing the dataset
dataset = load_dataset(dataset_name, split="train")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
instruction = """You are a top-rated customer service agent named John.
Be polite to customers and answer all their questions.
"""
def format_chat_template(row):
row_json = [{"role": "system", "content": instruction },
{"role": "user", "content": row["instruction"]},
{"role": "assistant", "content": row["response"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= 4,
)
Como vemos, hemos combinado la consulta del cliente y la respuesta del asistente en un formato de chat.
dataset['text'][3]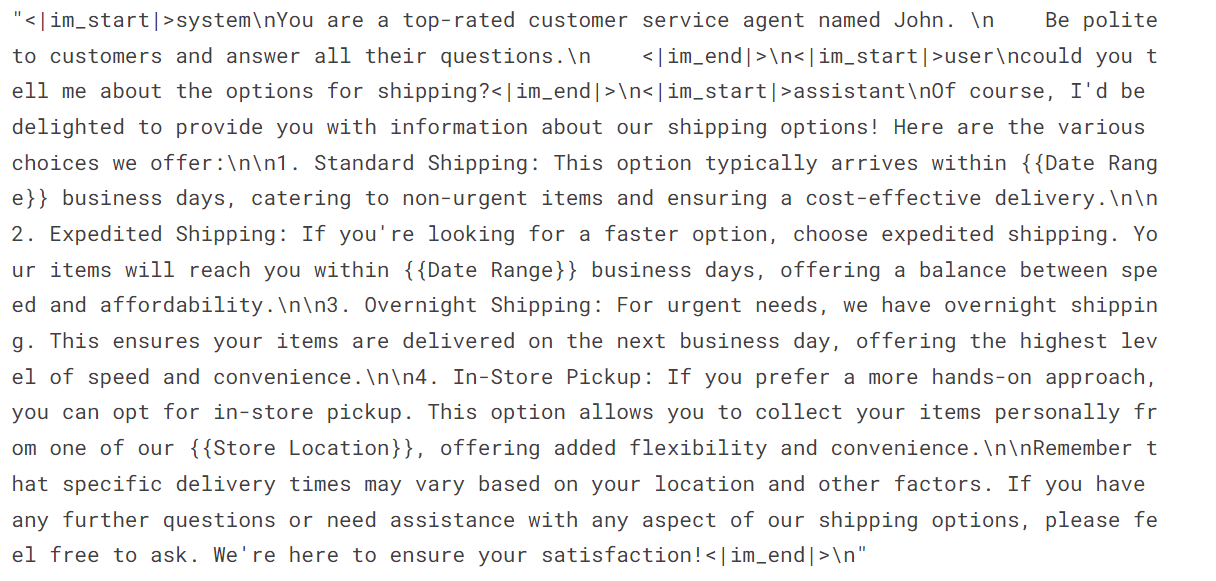
Extrae el nombre del modelo lineal del modelo.
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)Utiliza el nombre del módulo lineal para crear el adoptador LoRA. Sólo afinaremos el adoptador LoRA y dejaremos el resto del modelo para ahorrar memoria y acelerar el tiempo de entrenamiento.
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = get_peft_model(model, peft_config)Estamos configurando los hiperparámetros del modelo para ejecutarlo en el entorno Kaggle. Puedes entender cada hiperparámetro consultando el apartado Ajuste fino de Llama 2 y cambiándolo para optimizar el entrenamiento que se ejecuta en tu sistema.
#Hyperparamter
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
eval_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)A continuación, configuraremos un entrenador de ajuste fino supervisado (SFT) y proporcionaremos un conjunto de datos de entrenamiento y evaluación, la configuración de LoRA, el argumento de entrenamiento, el tokenizador y el modelo.
# Setting sft parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length= 512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Inicia el proceso de entrenamiento y controla las métricas de pérdida de entrenamiento y validación.
trainer.train()La pérdida de entrenamiento se redujo gradualmente. Lo cual es una buena señal.
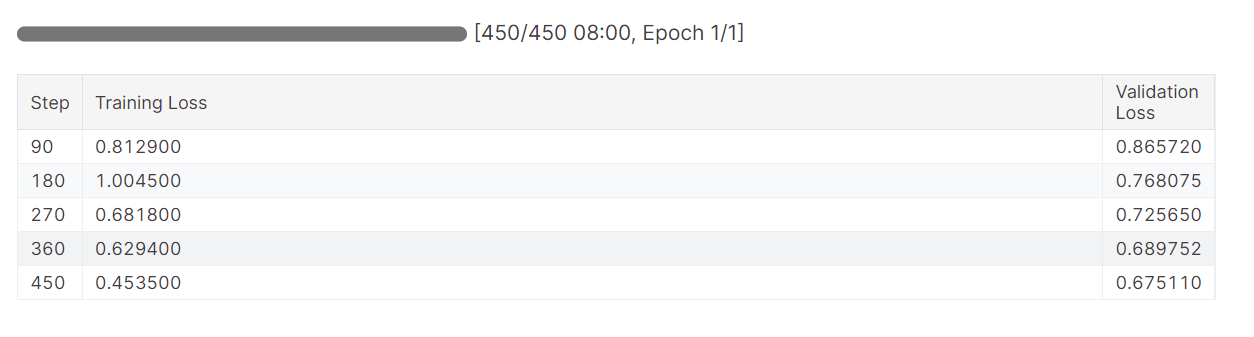
El historial detallado de la ejecución se genera cuando terminamos la ejecución de Pesos y Sesgos.
wandb.finish()
Siempre puedes visitar el panel de ponderaciones y sesgos para revisar a fondo las métricas del modelo.
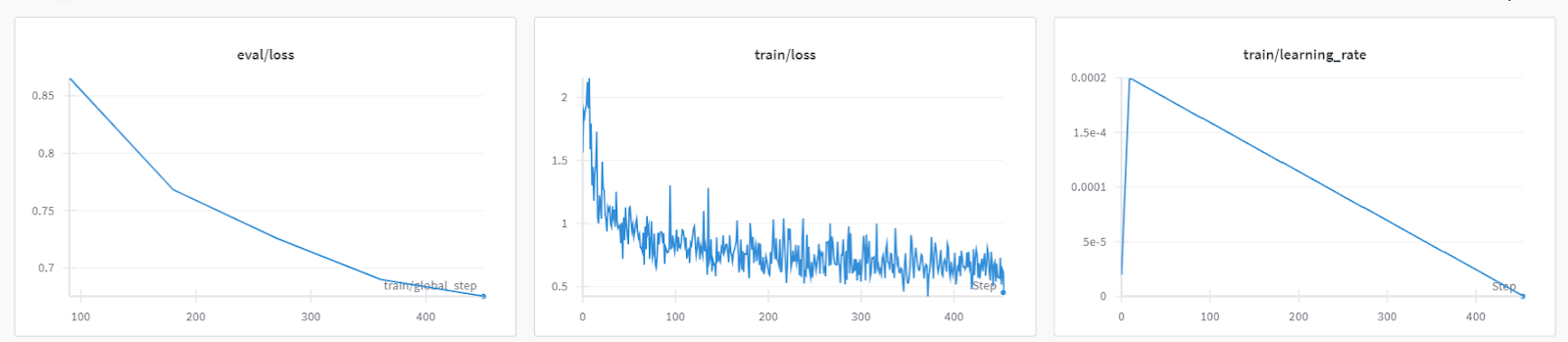
Para poner a prueba el modelo afinado, le proporcionaremos la muestra puntual del conjunto de datos.
messages = [{"role": "system", "content": instruction},
{"role": "user", "content": "I bought the same item twice, cancel order {{Order Number}}"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=150, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])El modelo afinado ha adoptado el estilo y ha proporcionado una respuesta precisa.

Guarda localmente el modelo ajustado y envíalo también al hub Cara Abrazada. La función push_to_hub creará un nuevo repositorio de modelos y enviará los archivos del modelo a tu repositorio de Cara Abrazada.
# Save the fine-tuned model
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)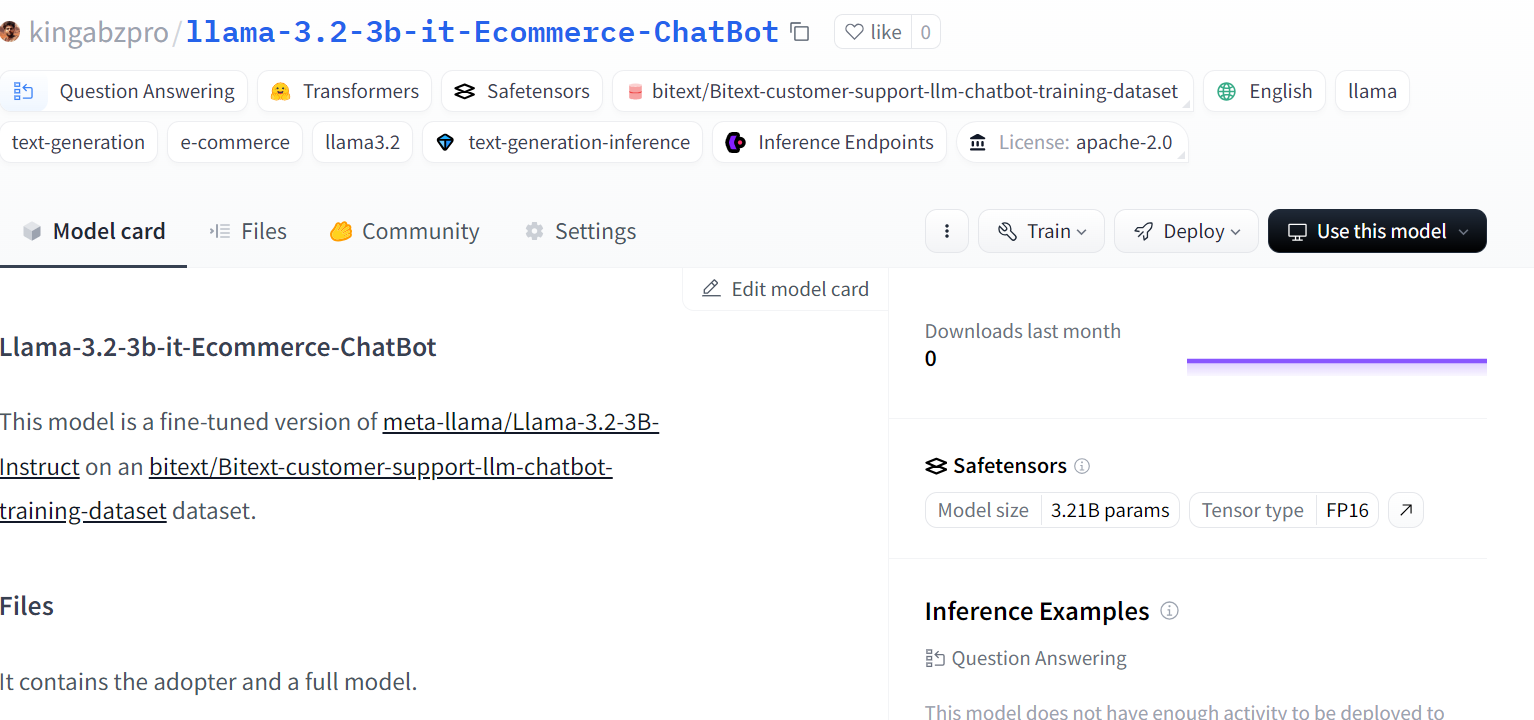
Fuente: kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot
Para afinar los modelos más grandes de Llama 3, deberías consultar Ajuste fino de Llama 3.1 para la clasificación de textos tutorial. Este tutorial es bastante popular y te ayudará a encontrar los LLM en la tarea completa.
Haz clic en el botón "Guardar versión" de la parte superior derecha, selecciona la opción de guardado rápido y cambia la opción de guardar salida para guardar el archivo del modelo y todo el código.
Echa un vistazo a Pon a punto Llama 3.2 en Atención al Cliente Cuaderno Kaggle para ver el código fuente, los resultados y la salida.
Esta es una guía muy basada en el código. Si buscas una guía sin código o con poco código para ajustar los LLM, consulta la Guía para principiantes de LlaMA-Factory WebUI de: Ajuste fino de los LLM.
Crearemos un cuaderno nuevo y añadiremos el cuaderno guardado anteriormente para acceder al adaptador LoRA ajustado para evitar cualquier problema de memoria.
Asegúrate de que también has añadido el modelo base "Llama 3.2 3B Instruct".
Instala y actualiza todos los paquetes Python necesarios.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlConéctate a la CLI de Cara Abrazada para enviar el modelo fusionado al hub de Cara Abrazada.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Proporciona la ubicación al modelo base y afina LoRA. Los utilizaremos para cargar el modelo base y fusionarlo con el adaptador.
# Model
base_model_url = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
new_model_url = "/kaggle/input/fine-tune-llama-3-2-on-customer-support/llama-3.2-3b-it-Ecommerce-ChatBot/"Carga el tokenizador y el modelo completo.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model_url)
base_model_reload= AutoModelForCausalLM.from_pretrained(
base_model_url,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="auto",
)Aplica el formato de chat al modelo y al tokenizador. A continuación, fusiona el modelo base con el adaptador LoRA.
# Merge adapter with base model
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
model = PeftModel.from_pretrained(base_model_reload, new_model_url)
model = model.merge_and_unload()Para comprobar si el modelo se ha fusionado correctamente, facilítale la consulta de muestras y genera el reposo.
instruction = """You are a top-rated customer service agent named John.
Be polite to customers and answer all their questions.
"""
messages = [{"role": "system", "content": instruction},
{"role": "user", "content": "I have to see what payment payment modalities are accepted"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=150, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])Como vemos, nuestro modelo afinado funciona perfectamente.

Guarda el tokenizador y el modelo localmente.
new_model = "llama-3.2-3b-it-Ecommerce-ChatBot"
model.save_pretrained(new_model)
tokenizer.save_pretrained(new_model)Empuja el tokenizador y el modelo fusionado al repositorio de modelos de Cara Abrazada.
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)Tras unos minutos, podrás ver todos los archivos de modelos con archivos de metadatos en tu repositorio de Cara Abrazada.
Fuente: kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot
También puedes revisar el código fuente en Fusión y exportación del modelo Llama 3.2 cuaderno Kaggle para saber más sobre cómo fusionar y subir tu modelo al hub Cara Abrazada.
El siguiente paso en este proyecto es convertir el modelo completo al formato GGUF y luego cuantizarlo. Después, puedes utilizarlo localmente utilizando tu aplicación de chat favorita, como Jan, Msty o GPT4ALL. Sigue el Ajuste fino de Llama 3 y uso local para aprender a convertir todo el LLM al formato GGUF y utilizarlo localmente en tu portátil.
Afinar los LLM más pequeños nos permite ahorrar costes y mejorar el tiempo de inferencia. Con datos suficientes, puedes mejorar el rendimiento del modelo en determinadas tareas cercanas a la GPT-4-mini. En resumen, el futuro de la IA pasa por utilizar múltiples LLM más pequeños en una red con una relación maestro-esclavo.
El modelo maestro recibirá la consulta inicial y decidirá qué modelo especializado utilizar para generar las respuestas. Esto reducirá el tiempo de cálculo, mejorará los resultados y reducirá los costes de funcionamiento.
En este tutorial, hemos aprendido sobre Llama 3.2 y cómo acceder a ella en Kaggle. También hemos aprendido a afinar el modelo ligero Llama 3.2 en el conjunto de datos de atención al cliente para que aprenda a responder con un estilo determinado y proporcione información precisa específica del dominio. Por último, fusionamos el adaptador LoRA con el modelo base y enviamos el modelo completo al Hugging Face Hub.
Toma nuestro Trabajar con Cara Abrazada para aprender a utilizar la herramienta y afinar los modelos.
Los mejores cursos LLM
programa
programa
Curso
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita



