
Kurs
Einführung in LLMs mit Python
3 Std.
33.6K
Bist du bei der Feinabstimmung von Modellen schon einmal auf Speicherprobleme gestoßen oder hast festgestellt, dass der Prozess unerträglich lange dauert, bis er abgeschlossen ist? Wenn du auf der Suche nach einer effizienteren und schnelleren Lösung als die Transformers-Bibliothek für die Feinabstimmung großer Sprachmodelle (LLMs) bist, bist du hier genau richtig!
In diesem Tutorial zeigen wir dir, wie du das Llama 3.1 3B Modell mit nur 9 GB VRAM feinabstimmst und damit eine doppelt so hohe Geschwindigkeit erreichst wie mit herkömmlichen Transformers-Methoden. Außerdem werden wir uns damit beschäftigen, wie man schnelle Inferenzen durchführt, das Modell in vLLM-kompatible und GGUF-Dateiformate umwandelt und das gespeicherte Modell mit nur wenigen Zeilen Code nahtlos in den Hugging Face Hub überträgt.
Wenn du mit diesen Konzepten noch nicht vertraut bist, solltest du unbedingt den Master Large Language Models (LLMs) Konzepte um eine solide Grundlage zu schaffen, bevor du dich an die Feinabstimmung machst.

Bild vom Autor
Unsloth AI ist ein Python-Framework, das für die schnelle Feinabstimmung und den Zugriff auf große Sprachmodelle entwickelt wurde. Es bietet eine einfache API und eine Leistung, die im Vergleich zu Transformers 2x schneller ist.
Der Zugriff auf das Llama-3.1-Modell mit Unsloth ist ziemlich einfach. Wir werden das 16-Bit-Modell nicht laden. Stattdessen laden wir die 4-Bit-Version, die auf dem Hugging Face verfügbar ist, um den GPU-Speicher zu schonen und die Inferenz zu beschleunigen.
%%capture
%pip install unslothFastLanguageModel. from transformers import TextStreamer
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-bnb-4bit"
)
FastLanguageModel.for_inference(model)prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
inputs = tokenizer(
[
prompt_style.format(
"You are a professional machine learning engineer",
"How would you deal with NaN validation loss?",
"",
)
],
return_tensors="pt",
).to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=128)
Wir haben eine positive Antwort auf die Frage erhalten, wie wir mit NaN-Validierungsverlusten umgehen sollen.

Wenn du Probleme hast, den obigen Code in Kaggle auszuführen, findest du hier das Beispiel-Notizbuch: Zugriff auf LLMs mit Unsloth.
Durch die Teilnahme an der Einführung in LLMs in Python lernst du die Grundlagen der Transformer-Architektur kennen und erfährst, wie du sie aufbaust, abstimmst und auswertest. Es ist dein Einstieg in die Welt der LLM-Feinabstimmung mit Python.
In dieser Anleitung lernen wir, wie wir Llama 3.1 auf der lighteval/MATH Datensatz mit Unsloth verfeinert. Der Datensatz besteht aus Algebra-Aufgaben mit Lösungen im Markdown-Format. Der gesamte Datensatz ist in fünf Schwierigkeitsstufen unterteilt.
Um diesen Leitfaden besser zu verstehen, empfehle ich dir, die Theorie hinter den einzelnen Schritten der Feinabstimmung von LLMs zu lesen Einleitender Leitfaden zur Feinabstimmung von LLMs. Nimm dir ein paar Minuten Zeit, um den Leitfaden durchzulesen, denn er wird dir helfen, diesen Prozess zu verstehen.
Wir verwenden ein Kaggle-Notizbuch als Cloud-IDE und müssen das Notizbuch einrichten, bevor wir mit dem Modell oder den Daten arbeiten.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama-3.1-8B-bnb-4bit on Math Dataset',
job_type="training",
anonymous="allow"
)Genau wie im Abschnitt zur Modellinferenz laden wir die 4-Bit-quantisierte Version des Llama 3.1-Modells mit der maximalen Sequenzlänge von 2048 und dem Datentyp None.
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype
)Dann laden wir den Datensatz und verarbeiten ihn. Dafür müssen wir zuerst einen Prompt-Stil erstellen, der uns hilft, die gewünschten Ergebnisse zu erzielen.
Der Prompt-Stil umfasst einen Systemprompt, eine Anweisung und einen Platzhalter für Eingabe und Antwort.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
You are a math genius who can solve any level of algebraic problems. Please answer the following math question.
### Input:
{}
### Response:
{}"""Danach erstellst du die Funktion, die den Prompt-Stil verwendet, um die mathematischen Probleme und Lösungen einzugeben und sie in den richtigen Text umzuwandeln. Achte darauf, dass du EOS_TOKEN hinzufügst, um einen Ruf zu vermeiden.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["problem"]
outputs = examples["solution"]
texts = []
for input, output in zip(inputs, outputs):
text = prompt_style.format(input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }Lade die 500 Stichproben aus dem Datensatz, wende die Funktion formatting_prompts_func auf den Datensatz an und zeige die erste Stichprobe in der Textspalte an.
from datasets import load_dataset
dataset = load_dataset("lighteval/MATH", split="train[0:500]", trust_remote_code=True)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][0]Der Text enthält eine Systemaufforderung, eine Anweisung, eine Algebra-Frage und die Lösung der Aufgabe.

Wir fügen den LoRA (Low-Rank Adapter) zum Modell hinzu, indem wir die linearen Module des Basismodells verwenden.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=False,
loftq_config=None,
)Richte den Trainer mit dem Modell, dem Tokenizer, der maximalen Sequenzlänge und den Trainingsargumenten ein. Das ist ganz ähnlich wie das Einrichten eines Trainers mit der Transformers- und TRL-Bibliothek.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)Das Modelltraining dauerte fast 19 Minuten, was beeindruckend ist. Der Ausbildungsverlust hat sich mit jedem Schritt deutlich verringert.
trainer_stats = trainer.train()
Detaillierte Informationen zur Modellleistung und zu den Hardware-Kennzahlen findest du im Dashboard "Gewichte und Verzerrungen".
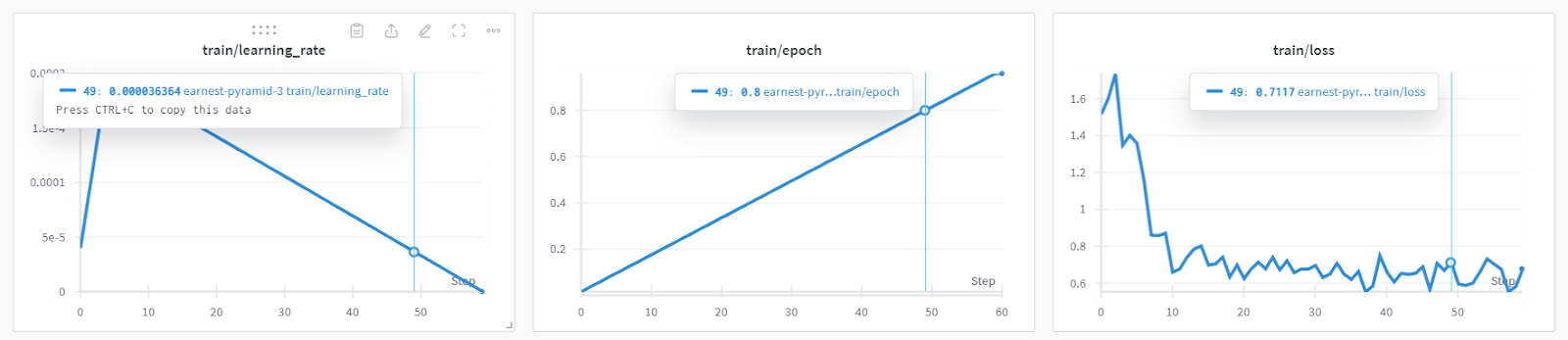
Du kannst auch torch und trainer_stats verwenden, um deinen eigenen Bericht zu erstellen.
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory /max_memory*100, 3)
lora_percentage = round(used_memory_for_lora/max_memory*100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")Das Modell wurde in 20 Minuten trainiert, und der für das Training reservierte Spitzenspeicher betrug etwa 3,7 GB. Das ist relativ wenig im Vergleich zur traditionellen Methode, bei der das gesamte Modell geladen, quantisiert und schließlich feinabgestimmt werden muss. In diesem Fall werden mindestens 15 GB GPU-Speicher benötigt.
1207.5478 seconds used for training.
20.13 minutes used for training.
Peak reserved memory = 9.73 GB.
Peak reserved memory for training = 3.746 GB.
Peak reserved memory % of max memory = 61.241 %.
Peak reserved memory for training % of max memory = 23.578 %.Um das Modell nach der Feinabstimmung zu testen, müssen wir die schnelle Inferenz aktivieren. Als Nächstes geben wir eine Beispiel-Algebra-Frage aus dem Datensatz in den Prompt-Stil ein und wandeln sie in Tokens um. Dann verwenden wir das Modell, um die Antwort zu erzeugen und die Ausgabe zu dekodieren, um den Text anzuzeigen.
Der generierte Text war im Markdown-Format, aber wir haben ihn konvertiert, um den Text mit richtigen mathematischen Gleichungen anzuzeigen.
from IPython.display import display, Markdown
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
prompt_style.format(
"If the system of equations \begin{align*} 3x+y&=a,\\ 2x+5y&=2a, \end{align*} has a solution $(x,y)$ when $x=2$, compute $a$.",
"",
)
],
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=250,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
Markdown(response[0].split("\n\n### Response:")[1])Wie wir sehen können, stimmt die generierte Antwort mit dem Datensatz überein und liefert uns die Lösungen für die algebraischen Probleme.

Speichern wir unser abgestimmtes Modell und übertragen es in den Hugging Face Hub, damit du es einfach teilen oder einsetzen kannst.
new_model_online = "kingabzpro/Llama-3.1-8B-MATH"
new_model_local = "Llama-3.1-8B-MATH"
model.save_pretrained(new_model_local) # Local saving
tokenizer.save_pretrained(new_model_local) # Local savingDer folgende Code erstellt ein neues Repository im Hugging Face und pusht dann die LoRA und den Tokenizer mit den Metadaten.
model.push_to_hub(new_model_online) # Online saving
tokenizer.push_to_hub(new_model_online) # Online saving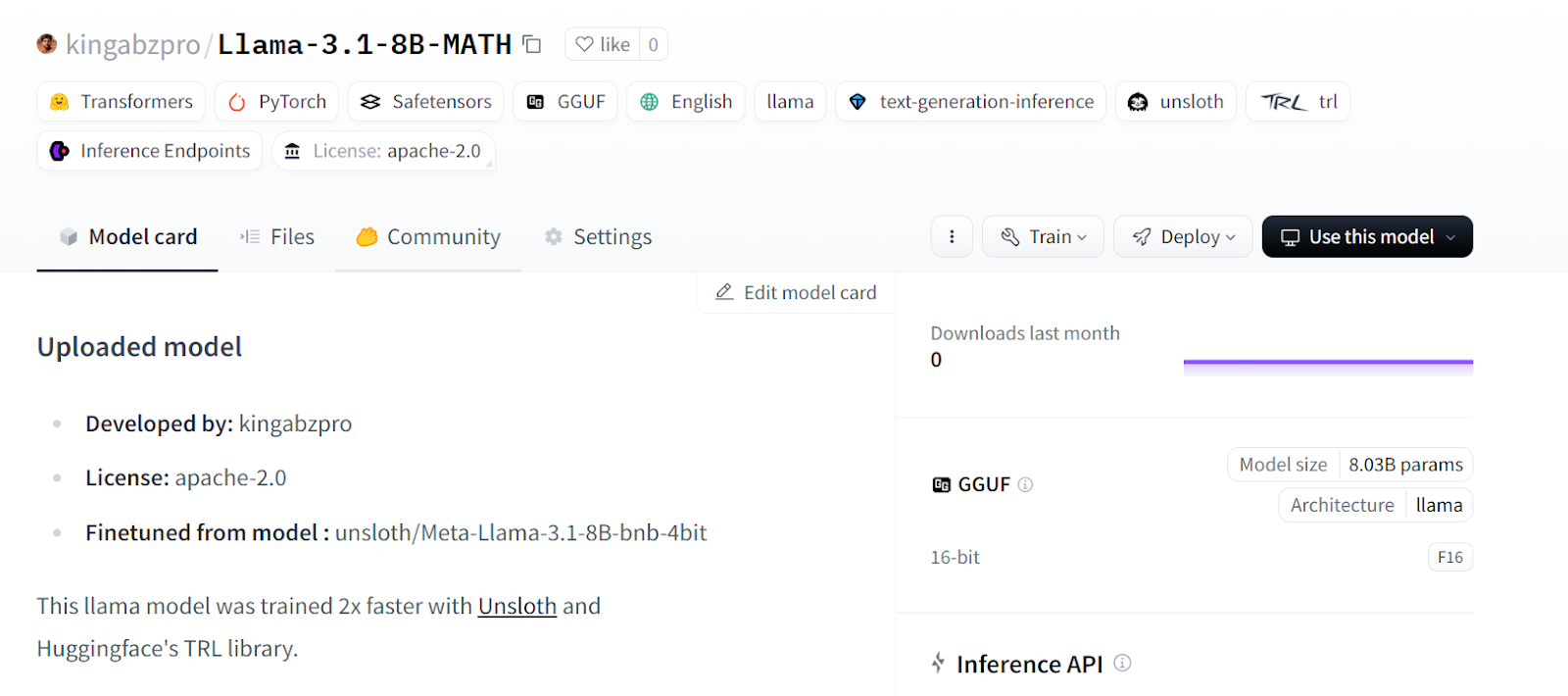
Source: kingabzpro/Llama-3.1-8B-MATH
Wenn du bei der Feinabstimmung der LLM mit Unsloth auf Probleme stößt, lies bitte den Abschnitt Feinabstimmung von LLMs mit Unsloth Kaggle Notebook. Sie enthält stabilen Code, den du selbst ausführen kannst, um die Ergebnisse zu reproduzieren.
Der nächste Schritt auf deiner KI-Reise besteht darin, LLMs zu nutzen, um effektive KI-Anwendungen zu entwickeln. Weitere Informationen findest du auf der Seite Wie man LLM-Anwendungen mit LangChain erstellt Tutorial.
Das Zusammenführen von LoRa mit dem Basismodell erfordert zusätzlichen VRAM und lokalen Speicher. Um keine Grenzen zu überschreiten, erstellen wir ein neues Kaggle-Notebook mit dem P100 Grafikprozessor als Beschleuniger. Wir werden auch die Hugging Face API aktivieren, um auf den API-Schlüssel zuzugreifen.
%%capture
%pip install unslothfrom huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)from unsloth import FastLanguageModel
new_model_name = "kingabzpro/Llama-3.1-8B-MATH"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = new_model_name, # YOUR MODEL YOU USED FOR TRAINING
max_seq_length = 2048,
dtype = None,
load_in_4bit = True,
)
FastLanguageModel.for_inference(model); 
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
You are a math genius who can solve any level of algebraic problem. Please answer the following math question.
### Input:
{}
### Response:
{}"""from IPython.display import display, Markdown
inputs = tokenizer(
[
prompt_style.format(
"Solve the equation $|y-6| + 2y = 9$ for $y$.", # input
"", # output - leave this blank for generation!
)
],
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=250,
pad_token_id=tokenizer.eos_token_id,
)
response = tokenizer.batch_decode(outputs)
Markdown(response[0].split("\n\n### Response:")[1])
Das Modell funktioniert einwandfrei und ist bereit, mit dem Basismodell zusammengeführt zu werden.
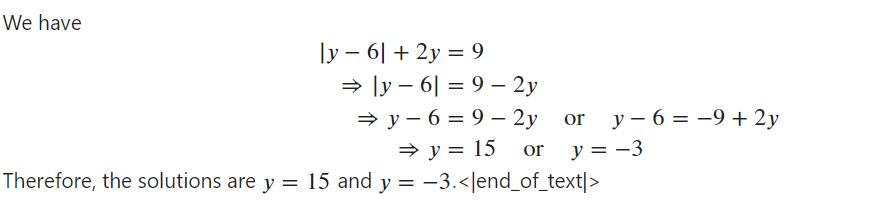
working stellt uns nur 20 GB zur Verfügung, was nicht genug ist, um das gesamte Modell zusammenzuführen und zu pushen. Wenn wir einen weiteren Ordner im Stammverzeichnis anlegen, können wir auf die 60 GB temporären Speicherplatz zugreifen.%mkdir ../temp
%cd /kaggle/tempmodel.push_to_hub_merged(new_model_name, tokenizer, save_method = "merged_16bit")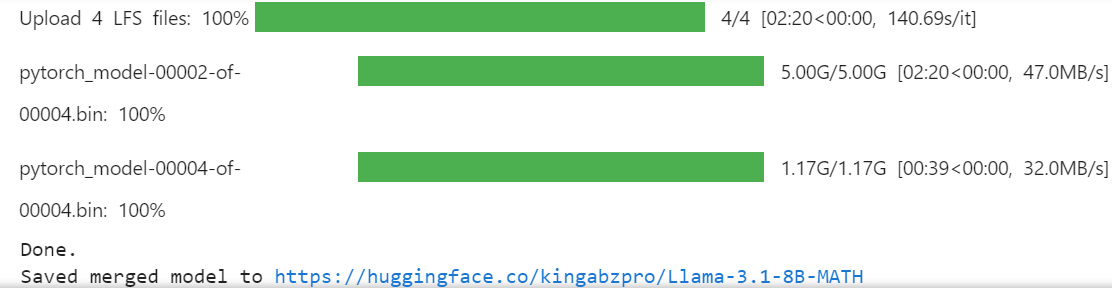
model.push_to_hub_gguf(new_model_name, tokenizer, quantization_method = "q4_k_m")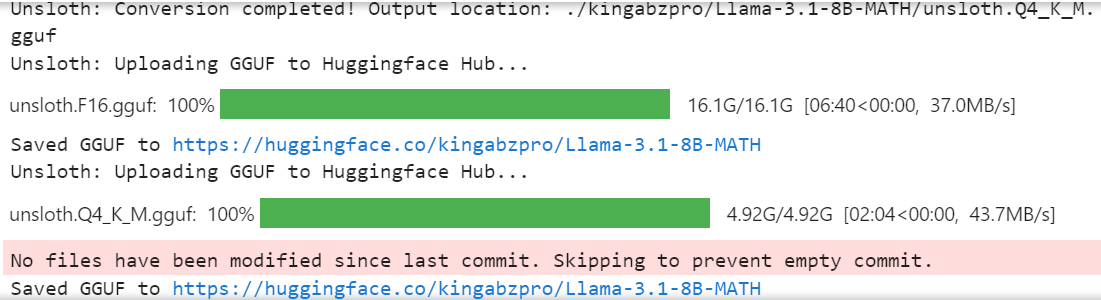
Das vollständige 16-Bit-Modell, der Adapter und die quantisierten GGUF-Dateien sind in deinem Modell-Repository verfügbar. Um das fein abgestimmte Modell lokal zu verwenden, lade einfach die quantisierte GGUF-Datei herunter und verwende sie mit Jan, Misty, GPT4ALL oder Ollama.
Folge der Feinabstimmung von Llama 3.2 und dessen lokaler Nutzung: Eine Schritt-für-Schritt-Anleitung Tutorial, in dem du lernst, wie du das Llama 3.2-Modell an einem Kundensupport-Datensatz fein abstimmst, das Modell zusammenführst und in den Hugging Face Hub exportierst und das fein abgestimmte Modell in das GGUF-Format konvertierst, damit es lokal mit der Jan-Anwendung verwendet werden kann.
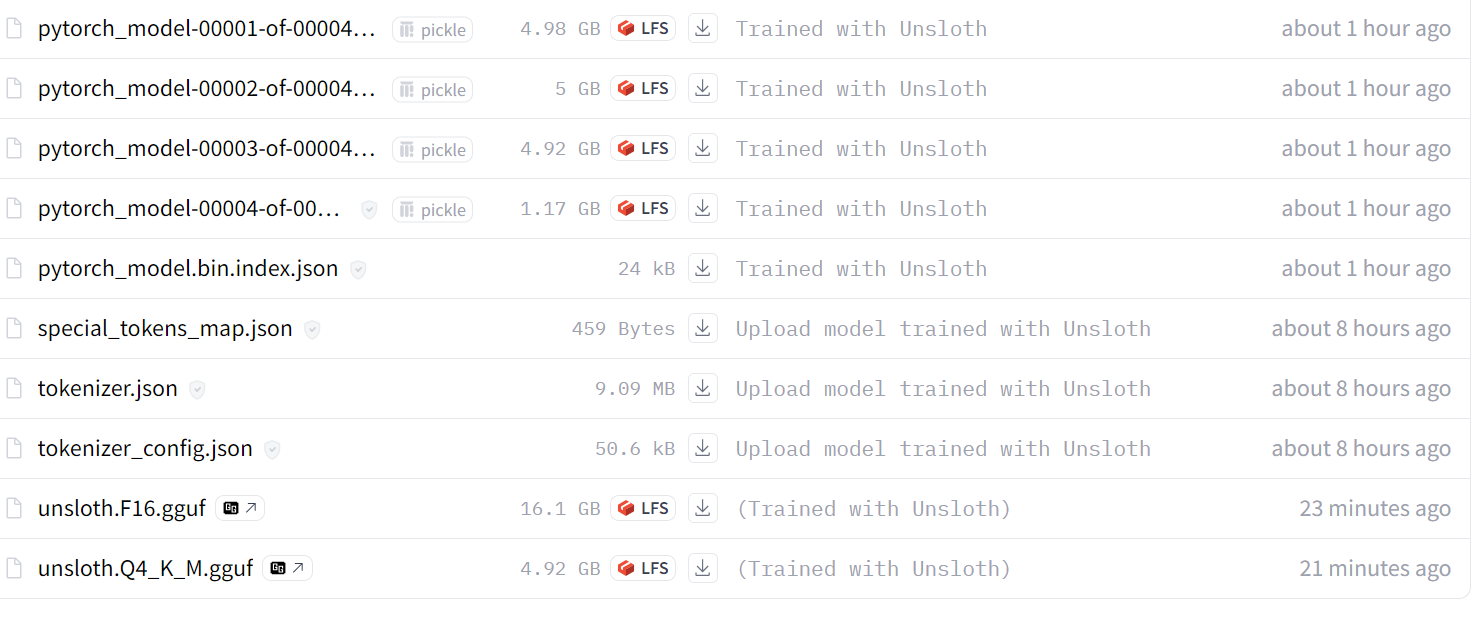
Source: kingabzpro/Llama-3.1-8B-MATH
Wenn du Probleme beim Laden und Zusammenführen der LoRA mit dem Basismodell hast, sieh dir bitte den Zusammenführung von LoRA Adopter mit Unsloth Kaggle-Notizbuch für weitere Hilfe.
Ich empfehle dir auch, den Blog zu lesen 12 LLM-Projekte für alle Niveaus. Sie enthält eine Liste von LLM-Projekten für Anfänger, Mittelstufenschüler, Abschlussschüler und Experten.
In diesem Tutorium haben wir gelernt, wie man das Llama 3.1 3B-Modell mit geringen Rechenressourcen effektiv feinabstimmen kann und dabei eine doppelt so hohe Geschwindigkeit erreicht wie mit herkömmlichen Methoden.
Wir haben auch gelernt, wie man eine schnelle Modellinferenz durchführt, das LoRA-Modell mit dem Basismodell zusammenführt und es an den Hugging Face Hub sendet.
Außerdem haben wir das Modell in das llama.cpp-Format konvertiert und quantisiert, so dass das fein abgestimmte Modell mit den Anwendungen Jan oder GPT4ALL einfach lokal auf dem Laptop verwendet werden kann.
Um die Leistung des Modells zu verbessern, empfehlen wir dringend, das Modell mit dem gesamten Datensatz zu optimieren, die Hyperparameter zu optimieren und am Prompt-Stil zu arbeiten. Auch nach dem Feintuning kannst du die Leistung von KI-Anwendungen durch Funktionsaufrufe und RAG-Pipelines in vielerlei Hinsicht verbessern.
Welche Lösung für deinen speziellen Fall besser ist, erfährst du auf RAG vs. Fine-Tuning: Ein umfassendes Tutorial mit praktischen Beispielen guide. Er enthält einen Beispielcode, den du mit deinem Datensatz ausprobieren und die Ergebnisse vergleichen kannst.
Top LLM-Kurse
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
