
Cours
Introduction aux LLM en Python
3 h
33.6K
Avez-vous déjà rencontré des problèmes de mémoire lors de la mise au point des modèles ou trouvé que le processus prenait un temps insupportable ? Si vous cherchez une solution plus efficace et plus rapide que l'utilisation de la bibliothèque Transformers pour affiner les grands modèles de langage (LLM), vous êtes au bon endroit !
Dans ce tutoriel, nous verrons comment affiner le modèle Llama 3.1 3B en utilisant seulement 9 Go de VRAM, ce qui permet d'atteindre des vitesses deux fois supérieures aux méthodes traditionnelles de Transformers. Nous verrons également comment effectuer une inférence rapide, convertir le modèle dans des formats de fichiers compatibles avec vLLM et GGUF, et pousser de manière transparente le modèle sauvegardé vers le Hugging Face Hub avec seulement quelques lignes de code.
Si ces concepts vous sont inconnus, n'oubliez pas de suivre la formation suivante Maîtriser les concepts des grands modèles de langue (LLM) afin d'acquérir une base solide avant de vous lancer dans l'affinage.

Image par l'auteur
Unsloth AI est un framework Python conçu pour affiner et accéder rapidement à de grands modèles de langage. Il offre une API simple et des performances deux fois plus rapides que celles de Transformers.
L'accès au modèle Llama-3.1 à l'aide d'Unsloth est assez simple. Nous ne chargerons pas le modèle 16 bits. Au lieu de cela, nous chargerons la version 4 bits disponible sur la Hugging Face afin d'économiser la mémoire du GPU et d'accélérer l'inférence.
%%capture
%pip install unslothFastLanguageModel. from transformers import TextStreamer
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-bnb-4bit"
)
FastLanguageModel.for_inference(model)prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
inputs = tokenizer(
[
prompt_style.format(
"You are a professional machine learning engineer",
"How would you deal with NaN validation loss?",
"",
)
],
return_tensors="pt",
).to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=128)
Nous avons reçu une réponse positive concernant la manière de gérer la perte de validation NaN.

Si vous avez des difficultés à exécuter le code ci-dessus dans Kaggle, voici un exemple de carnet de notes : Accès aux LLM à l'aide d'Unsloth.
En prenant le Introduction aux LLM en Python vous apprendrez les bases de l'architecture Transformer, y compris comment la construire, la peaufiner et l'évaluer. C'est votre porte d'entrée dans le monde de la mise au point du LLM à l'aide de Python.
Dans ce guide, nous allons apprendre à peaufiner Llama 3.1 sur le serveur lighteval/MATH en utilisant Unsloth. L'ensemble de données consiste en des problèmes d'algèbre avec des solutions au format markdown. L'ensemble des données est divisé en cinq niveaux de difficulté.
Pour mieux comprendre ce guide, je vous recommande d'apprendre la théorie qui sous-tend chaque étape de l'affinage des MLD en lisant les documents suivants Guide d'introduction au réglage fin des LLM. Prenez quelques minutes pour lire le guide, il vous aidera à comprendre ce processus.
Nous utilisons un notebook Kaggle comme IDE cloud, et nous devons configurer le notebook avant de travailler avec le modèle ou les données.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama-3.1-8B-bnb-4bit on Math Dataset',
job_type="training",
anonymous="allow"
)Tout comme dans la section d'inférence du modèle, nous chargerons la version quantifiée de 4 bits du modèle Llama 3.1 en utilisant la longueur de séquence maximale de 2048 et le type de données None.
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype
)Ensuite, nous chargerons le jeu de données et le traiterons. Pour cela, nous devons d'abord créer un style d'invite qui nous aidera à obtenir les résultats souhaités.
Le style d'invite comprend une invite système, une instruction et un espace réservé pour la saisie et la réponse.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
You are a math genius who can solve any level of algebraic problems. Please answer the following math question.
### Input:
{}
### Response:
{}"""Ensuite, créez la fonction qui utilisera le style d'invite pour saisir les problèmes mathématiques et les solutions, en les convertissant en texte approprié. Veillez à ajouter EOS_TOKEN pour éviter toute réputation.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["problem"]
outputs = examples["solution"]
texts = []
for input, output in zip(inputs, outputs):
text = prompt_style.format(input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }Chargez les 500 échantillons de l'ensemble de données, appliquez la fonction formatting_prompts_func à l'ensemble de données et affichez le premier échantillon de la colonne de texte.
from datasets import load_dataset
dataset = load_dataset("lighteval/MATH", split="train[0:500]", trust_remote_code=True)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][0]Le texte comporte une invite, une instruction, un problème d'algèbre et une solution à ce problème.

Nous ajoutons le LoRA (Low-Rank Adapter) au modèle en utilisant les modules linéaires du modèle de base.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=False,
loftq_config=None,
)Configurez l'entraîneur avec le modèle, le tokenizer, la longueur maximale de la séquence et les arguments d'entraînement. Ceci est assez similaire à la mise en place d'un simulateur utilisant la bibliothèque Transformers et TRL.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)La formation du modèle a duré près de 19 minutes, ce qui est impressionnant. La perte de formation a été réduite de manière significative à chaque étape.
trainer_stats = trainer.train()
Vous pouvez consulter les performances détaillées du modèle et les mesures matérielles en vous rendant sur le tableau de bord Pondérations et biais.
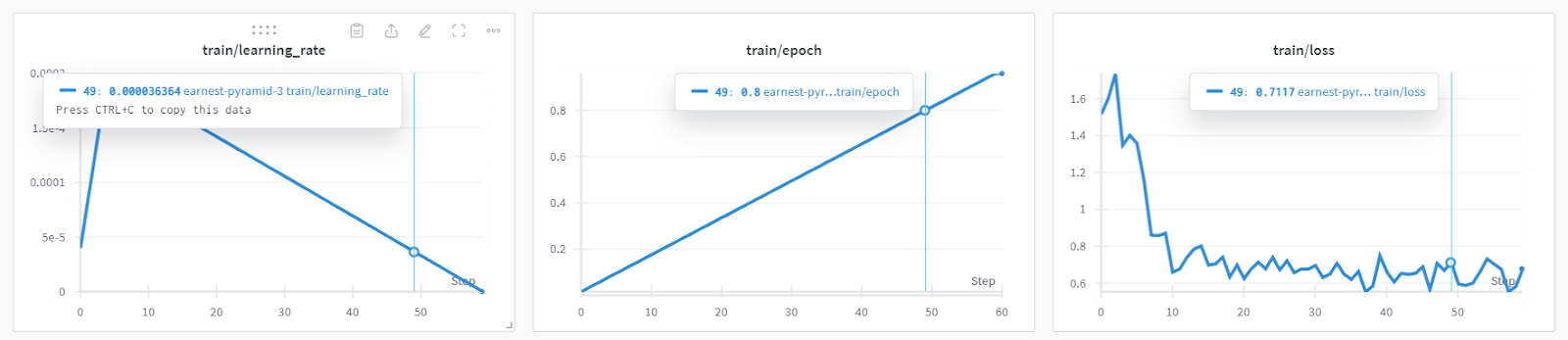
Vous pouvez également utiliser torch et trainer_stats pour générer votre propre rapport.
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory /max_memory*100, 3)
lora_percentage = round(used_memory_for_lora/max_memory*100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")Le modèle a été entraîné en 20 minutes, et la mémoire réservée maximale pour l'entraînement était d'environ 3,7 Go. C'est relativement peu par rapport à la méthode traditionnelle, qui consiste à charger le modèle complet, à le quantifier et enfin à l'affiner. Dans ce cas, il faudra au moins 15 Go de mémoire GPU.
1207.5478 seconds used for training.
20.13 minutes used for training.
Peak reserved memory = 9.73 GB.
Peak reserved memory for training = 3.746 GB.
Peak reserved memory % of max memory = 61.241 %.
Peak reserved memory for training % of max memory = 23.578 %.Pour tester le modèle après l'avoir affiné, nous devons activer l'inférence rapide. Ensuite, nous introduirons un exemple de question d'algèbre provenant de l'ensemble de données dans le style d'invite et nous le convertirons en jetons. Ensuite, nous utiliserons le modèle pour générer la réponse et décoder la sortie pour afficher le texte.
Le texte généré était au format Markdown, mais nous l'avons converti pour afficher le texte avec les équations mathématiques appropriées.
from IPython.display import display, Markdown
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
prompt_style.format(
"If the system of equations \begin{align*} 3x+y&=a,\\ 2x+5y&=2a, \end{align*} has a solution $(x,y)$ when $x=2$, compute $a$.",
"",
)
],
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=250,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
Markdown(response[0].split("\n\n### Response:")[1])Comme nous pouvons le constater, la réponse générée s'aligne sur l'ensemble des données et nous fournit les solutions aux problèmes algébriques.

Sauvegardons notre modèle peaufiné et poussons-le vers le Hub Hugging Face pour que vous puissiez facilement le partager ou le déployer.
new_model_online = "kingabzpro/Llama-3.1-8B-MATH"
new_model_local = "Llama-3.1-8B-MATH"
model.save_pretrained(new_model_local) # Local saving
tokenizer.save_pretrained(new_model_local) # Local savingLe code suivant créera un nouveau dépôt dans le Hugging Face et poussera ensuite le LoRA et le tokenizer avec les métadonnées.
model.push_to_hub(new_model_online) # Online saving
tokenizer.push_to_hub(new_model_online) # Online saving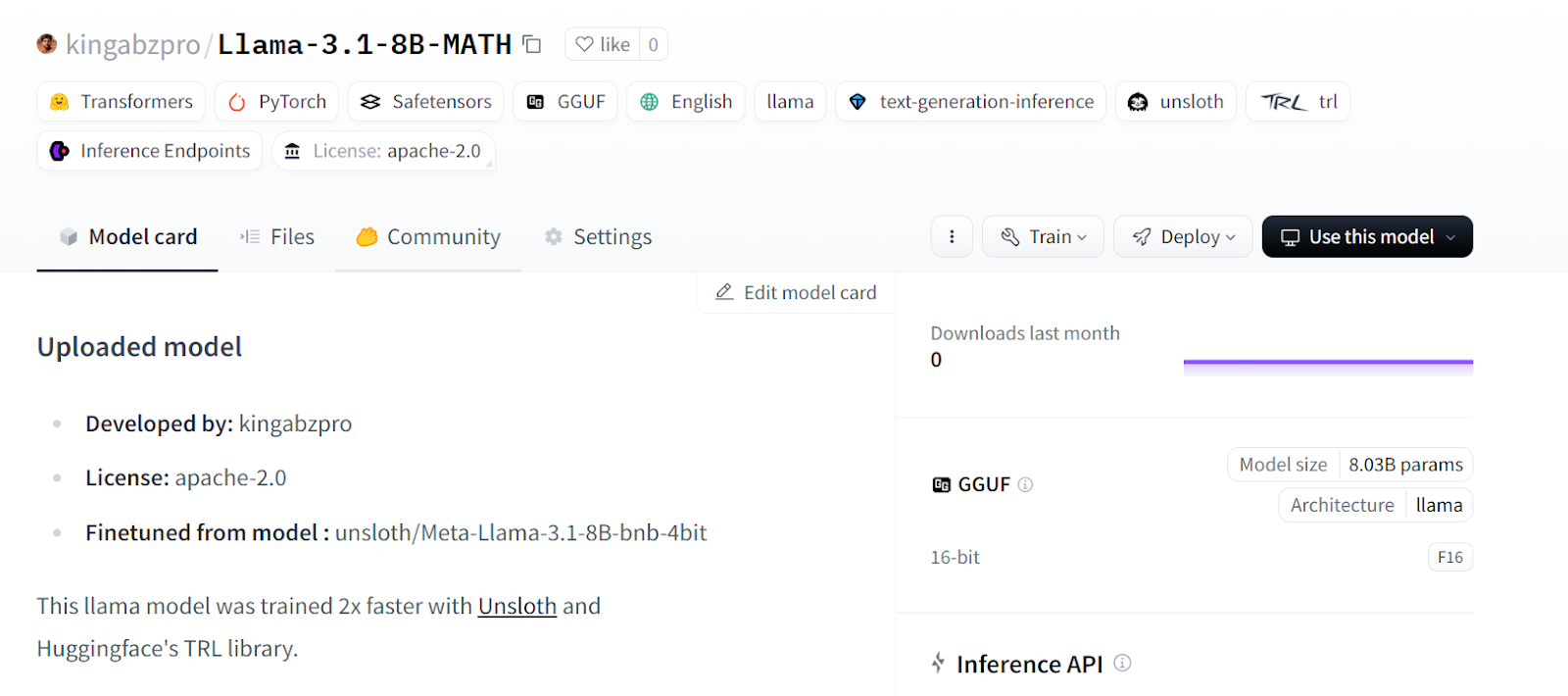
Source : kingabzpro/Llama-3.1-8B-MATH
Si vous rencontrez des problèmes lors de la mise au point du LLM à l'aide d'Unsloth, veuillez vous référer au document suivant Ajustement des LLM à l'aide d'Unsloth Carnet de notes Kaggle. Il contient un code stable que vous pouvez exécuter vous-même pour reproduire les résultats.
La prochaine étape de votre parcours en matière d'IA consiste à utiliser les LLM pour développer des applications d'IA efficaces. Vous pouvez trouver plus d'informations en suivant le lien suivant Comment construire des applications LLM avec LangChain.
La fusion de LoRa avec le modèle de base nécessite de la VRAM et du stockage local supplémentaires. Pour éviter de dépasser les limites, nous allons créer un nouveau notebook Kaggle avec le GPU P100 comme accélérateur. Nous allons également activer l'API Hugging Face pour accéder à la clé API.
%%capture
%pip install unslothfrom huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)from unsloth import FastLanguageModel
new_model_name = "kingabzpro/Llama-3.1-8B-MATH"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = new_model_name, # YOUR MODEL YOU USED FOR TRAINING
max_seq_length = 2048,
dtype = None,
load_in_4bit = True,
)
FastLanguageModel.for_inference(model); 
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
You are a math genius who can solve any level of algebraic problem. Please answer the following math question.
### Input:
{}
### Response:
{}"""from IPython.display import display, Markdown
inputs = tokenizer(
[
prompt_style.format(
"Solve the equation $|y-6| + 2y = 9$ for $y$.", # input
"", # output - leave this blank for generation!
)
],
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=250,
pad_token_id=tokenizer.eos_token_id,
)
response = tokenizer.batch_decode(outputs)
Markdown(response[0].split("\n\n### Response:")[1])
Le modèle fonctionne parfaitement et est prêt à être fusionné avec le modèle de base.
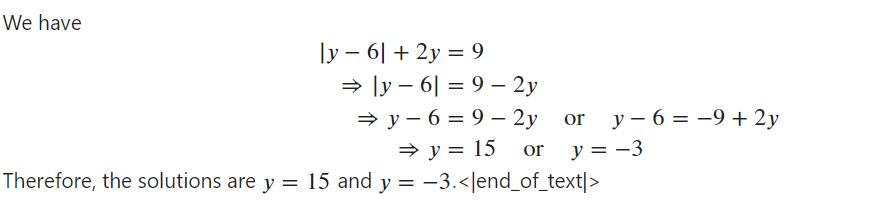
working ne nous fournit que 20 Go, ce qui n'est pas suffisant pour fusionner et pousser le modèle complet. La création d'un autre dossier dans le répertoire racine nous permettra d'accéder aux 60 Go de stockage temporaire.%mkdir ../temp
%cd /kaggle/tempmodel.push_to_hub_merged(new_model_name, tokenizer, save_method = "merged_16bit")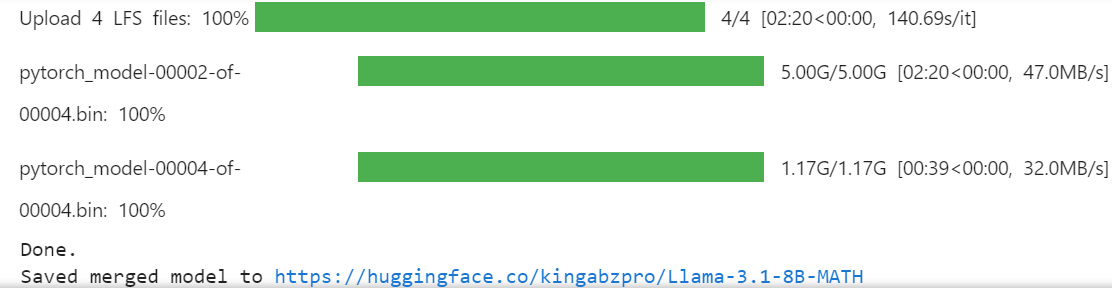
model.push_to_hub_gguf(new_model_name, tokenizer, quantization_method = "q4_k_m")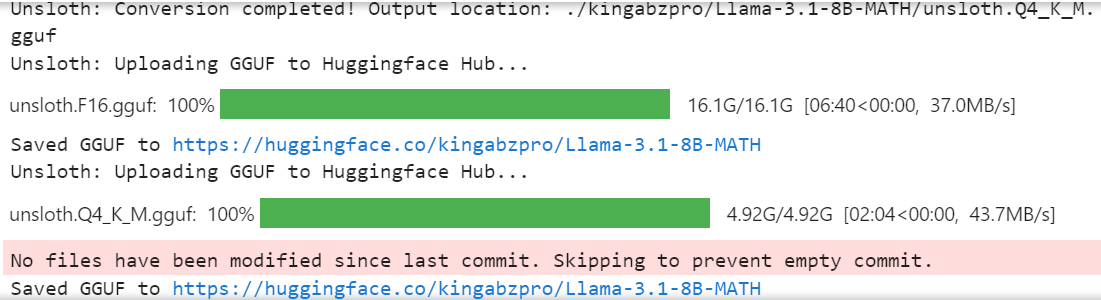
Le modèle complet 16 bits, l'adaptateur et les fichiers GGUF quantifiés sont disponibles dans votre référentiel de modèles. Pour utiliser localement le modèle affiné, il suffit de télécharger le fichier GGUF quantifié et de l'utiliser avec Jan, Misty, GPT4ALL ou Ollama.
Suivez le sitepour peaufiner Llama 3.2 et l'utiliser localement : A Step-by-Step Guide tutoriel pour apprendre à affiner le modèle Llama 3.2 sur un ensemble de données de support client, fusionner et exporter le modèle vers le Hugging Face Hub, et convertir le modèle affiné au format GGUF afin qu'il puisse être utilisé localement avec l'application Jan.
Source : kingabzpro/Llama-3.1-8B-MATH
Si vous rencontrez des problèmes lors du chargement et de la fusion de la LoRA avec le modèle de base, veuillez consulter le document suivant Fusionner LoRA Adopter avec Unsloth pour obtenir de l'aide.
Je vous recommande également de lire le blog 12 projets LLM pour tous les niveaux. Il comprend une liste de projets LLM pour les débutants, les étudiants intermédiaires, les étudiants en dernière année et les experts.
Dans ce tutoriel, nous avons appris comment affiner efficacement le modèle Llama 3.1 3B en utilisant de faibles ressources informatiques et en atteignant des vitesses deux fois plus rapides que les méthodes traditionnelles.
Nous avons également appris à effectuer une inférence rapide du modèle, à fusionner la LoRA avec le modèle de base et à l'envoyer au hub de Hugging Face.
En outre, nous avons converti le modèle au format llama.cpp et l'avons quantifié afin que le modèle affiné puisse être facilement utilisé localement sur l'ordinateur portable à l'aide des applications Jan ou GPT4ALL.
Pour améliorer les performances du modèle, nous vous recommandons vivement d'affiner le modèle sur l'ensemble des données, d'optimiser les hyperparamètres et de travailler sur le style de l'invite. Même après un réglage fin, vous pouvez améliorer les performances des applications d'IA de nombreuses façons en utilisant l'appel de fonction et les pipelines RAG.
Pour savoir quelle solution est la plus adaptée à votre cas particulier, consultez le siteRAG vs Fine-Tuning : Un tutoriel complet avec des exemples pratiques guide. Il comprend un exemple de code que vous pouvez essayer sur votre ensemble de données et comparer les résultats.
Principaux cours de LLM
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach