
Curso
Introdução a LLMs em Python
3 h
33.6K
Você já se deparou com problemas de memória ao fazer o ajuste fino de modelos ou descobriu que o processo leva um tempo insuportavelmente longo para ser concluído? Se você está procurando uma solução mais eficiente e mais rápida do que usar a biblioteca Transformers para fazer o ajuste fino de modelos de linguagem grandes (LLMs), veio ao lugar certo!
Neste tutorial, exploraremos como fazer o ajuste fino do modelo Llama 3.1 3B usando apenas 9 GB de VRAM, atingindo velocidades duas vezes mais rápidas do que os métodos tradicionais do Transformers. Também abordaremos como realizar inferência rápida, converter o modelo em formatos de arquivo compatíveis com vLLM e GGUF e enviar o modelo salvo para o Hugging Face Hub com apenas algumas linhas de código.
Se você ainda não conhece esses conceitos, não deixe de fazer o curso Conceitos de modelos de linguagem grandes (LLMs) para que você possa construir uma base sólida antes de mergulhar no ajuste fino.

Imagem do autor
Unsloth AI é uma estrutura Python projetada para ajuste fino rápido e acesso a grandes modelos de linguagem. Ele oferece uma API simples e um desempenho duas vezes mais rápido em comparação com o Transformers.
Acessar o modelo Llama-3.1 usando o Unsloth é bastante simples. Não carregaremos o modelo de 16 bits. Em vez disso, carregaremos a versão de 4 bits disponível no Hugging Face para economizar a memória da GPU e para obter uma inferência mais rápida.
%%capture
%pip install unslothFastLanguageModel. from transformers import TextStreamer
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-bnb-4bit"
)
FastLanguageModel.for_inference(model)prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
inputs = tokenizer(
[
prompt_style.format(
"You are a professional machine learning engineer",
"How would you deal with NaN validation loss?",
"",
)
],
return_tensors="pt",
).to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=128)
Recebemos uma resposta positiva sobre como lidar com a perda de validação NaN.

Se você estiver tendo problemas para executar o código acima no Kaggle, aqui está o Notebook de amostra: Acesso a LLMs usando o Unsloth.
Ao fazer o Introdução aos LLMs em Python você aprenderá os conceitos básicos da arquitetura do Transformer, inclusive como criá-lo, ajustá-lo e avaliá-lo. É a porta de entrada para você entrar no mundo do ajuste fino do LLM usando Python.
Neste guia, você aprenderá a ajustar o Llama 3.1 no servidor lighteval/MATH usando o Unsloth. O conjunto de dados consiste em problemas de álgebra com soluções em formato markdown. O conjunto completo de dados é dividido em cinco níveis de dificuldade.
Para entender melhor este guia, recomendo que você aprenda a teoria por trás de cada etapa envolvida no ajuste fino dos LLMs lendo Guia introdutório para ajuste fino de LLMs. Reserve alguns minutos para analisar o guia, pois ele ajudará você a entender esse processo.
Estamos usando um notebook do Kaggle como nosso IDE na nuvem e precisamos configurar o notebook antes de trabalhar com o modelo ou os dados.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama-3.1-8B-bnb-4bit on Math Dataset',
job_type="training",
anonymous="allow"
)Assim como na seção de inferência de modelo, carregaremos a versão quantizada de 4 bits do modelo Llama 3.1 usando o comprimento máximo de sequência de 2048 e o tipo de dados None.
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype
)Em seguida, carregaremos o conjunto de dados e o processaremos. Para isso, primeiro precisamos criar um estilo de prompt que nos ajudará a obter os resultados necessários.
O estilo do prompt inclui um prompt do sistema, uma instrução e um espaço reservado para entrada e resposta.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
You are a math genius who can solve any level of algebraic problems. Please answer the following math question.
### Input:
{}
### Response:
{}"""Depois disso, crie a função que usará o estilo prompt para inserir os problemas e as soluções matemáticas, convertendo-os no texto adequado. Certifique-se de adicionar EOS_TOKEN para evitar qualquer reputação.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["problem"]
outputs = examples["solution"]
texts = []
for input, output in zip(inputs, outputs):
text = prompt_style.format(input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }Carregue as 500 amostras do conjunto de dados, aplique a função formatting_prompts_func ao conjunto de dados e visualize a primeira amostra da coluna de texto.
from datasets import load_dataset
dataset = load_dataset("lighteval/MATH", split="train[0:500]", trust_remote_code=True)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][0]O texto tem um prompt do sistema, uma instrução, uma pergunta de problema de álgebra e uma solução para esse problema.

Adicionamos o LoRA (Low-Rank Adapter) ao modelo usando os módulos lineares do modelo básico.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=False,
loftq_config=None,
)Configure o treinador com o modelo, o tokenizador, o comprimento máximo da sequência e os argumentos de treinamento. Isso é bastante semelhante à configuração de um treinador usando a biblioteca Transformers e TRL.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)O treinamento do modelo levou quase 19 minutos, o que é impressionante. A perda de treinamento foi reduzida significativamente a cada etapa.
trainer_stats = trainer.train()
Você pode verificar o desempenho detalhado do modelo e as métricas de hardware acessando o painel Weights & Biases.
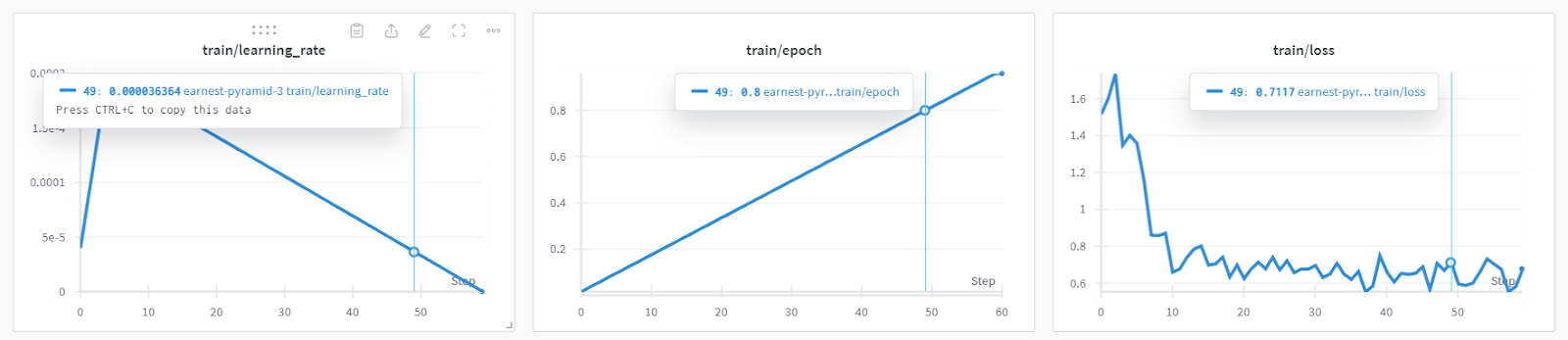
Você também pode usar os sites torch e trainer_stats para gerar seu próprio relatório.
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory /max_memory*100, 3)
lora_percentage = round(used_memory_for_lora/max_memory*100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")O modelo foi treinado em 20 minutos, e o pico de memória reservada para treinamento foi de aproximadamente 3,7 GB. Isso é relativamente baixo em comparação com o método tradicional, que envolve carregar o modelo completo, quantizá-lo e, por fim, fazer o ajuste fino. Nesse caso, você precisará de pelo menos 15 GB de memória da GPU.
1207.5478 seconds used for training.
20.13 minutes used for training.
Peak reserved memory = 9.73 GB.
Peak reserved memory for training = 3.746 GB.
Peak reserved memory % of max memory = 61.241 %.
Peak reserved memory for training % of max memory = 23.578 %.Para testar o modelo após o ajuste fino, precisamos ativar a inferência rápida. Em seguida, inseriremos uma amostra de pergunta de álgebra do conjunto de dados no estilo de prompt e a converteremos em tokens. Em seguida, usaremos o modelo para gerar a resposta e decodificar a saída para exibir o texto.
O texto gerado estava no formato Markdown, mas nós o convertemos para exibir o texto com as equações matemáticas adequadas.
from IPython.display import display, Markdown
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
prompt_style.format(
"If the system of equations \begin{align*} 3x+y&=a,\\ 2x+5y&=2a, \end{align*} has a solution $(x,y)$ when $x=2$, compute $a$.",
"",
)
],
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=250,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
Markdown(response[0].split("\n\n### Response:")[1])Como podemos ver, a resposta gerada se alinha com o conjunto de dados e nos fornece as soluções para os problemas algébricos.

Vamos salvar nosso modelo ajustado e enviá-lo para o Hugging Face Hub para que você possa compartilhá-lo ou implantá-lo facilmente.
new_model_online = "kingabzpro/Llama-3.1-8B-MATH"
new_model_local = "Llama-3.1-8B-MATH"
model.save_pretrained(new_model_local) # Local saving
tokenizer.save_pretrained(new_model_local) # Local savingO código a seguir criará um novo repositório no Hugging Face e, em seguida, enviará o LoRA e o tokenizador com os metadados.
model.push_to_hub(new_model_online) # Online saving
tokenizer.push_to_hub(new_model_online) # Online saving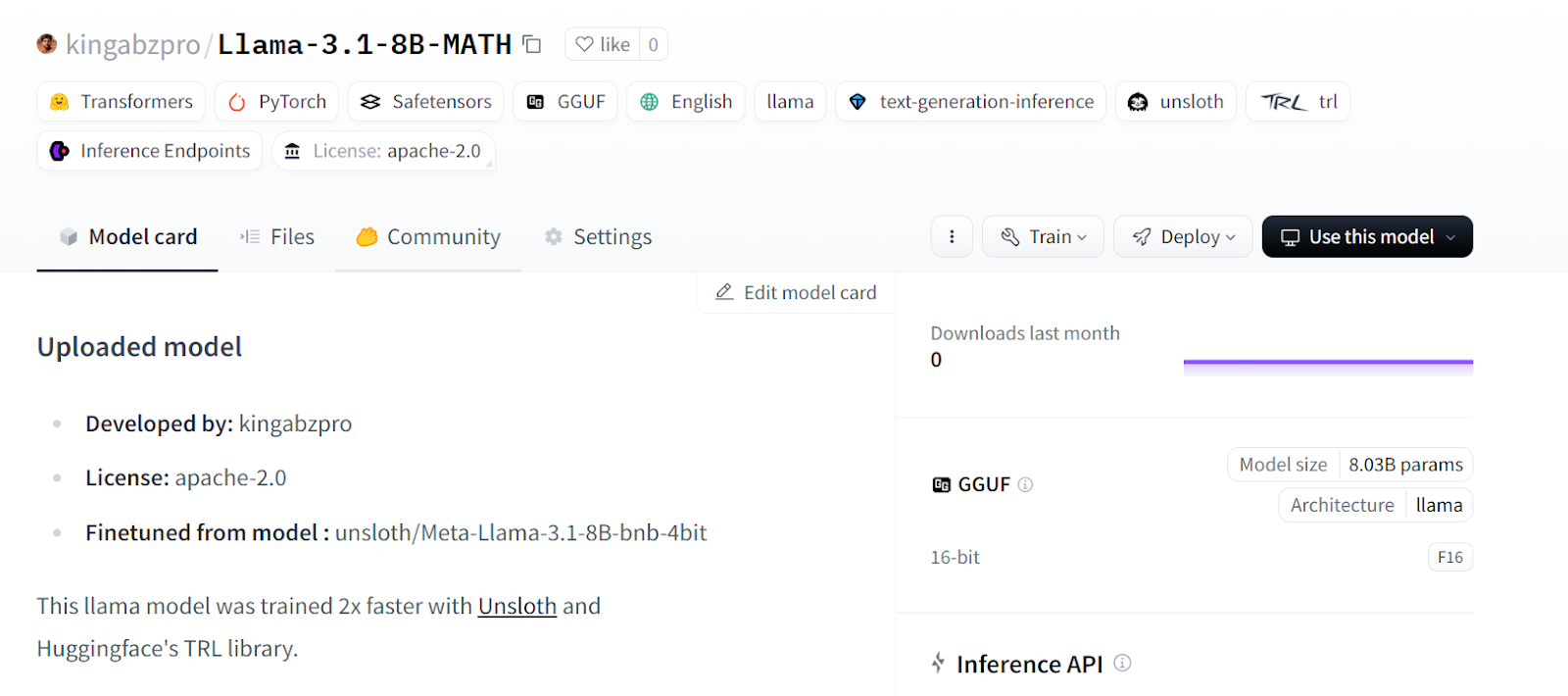
Fonte: kingabzpro/Llama-3.1-8B-MATH
Se você estiver enfrentando problemas ao fazer o ajuste fino do LLM usando o Unsloth, consulte a seção Ajuste fino de LLMs usando o Unsloth Caderno do Kaggle. Ele contém um código estável que você pode executar por conta própria para reproduzir os resultados.
A próxima etapa da sua jornada de IA é usar os LLMs para desenvolver aplicativos de IA eficazes. Você pode obter mais informações seguindo o guia Como criar aplicativos LLM com LangChain para você.
A fusão do LoRa com o modelo básico requer VRAM adicional e armazenamento local. Para evitar que você ultrapasse os limites, criaremos um novo notebook do Kaggle com a GPU P100 como acelerador. Você também ativará a API do Hugging Face para acessar a chave da API.
%%capture
%pip install unslothfrom huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)from unsloth import FastLanguageModel
new_model_name = "kingabzpro/Llama-3.1-8B-MATH"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = new_model_name, # YOUR MODEL YOU USED FOR TRAINING
max_seq_length = 2048,
dtype = None,
load_in_4bit = True,
)
FastLanguageModel.for_inference(model); 
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
You are a math genius who can solve any level of algebraic problem. Please answer the following math question.
### Input:
{}
### Response:
{}"""from IPython.display import display, Markdown
inputs = tokenizer(
[
prompt_style.format(
"Solve the equation $|y-6| + 2y = 9$ for $y$.", # input
"", # output - leave this blank for generation!
)
],
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=250,
pad_token_id=tokenizer.eos_token_id,
)
response = tokenizer.batch_decode(outputs)
Markdown(response[0].split("\n\n### Response:")[1])
O modelo está funcionando perfeitamente e está pronto para ser mesclado com o modelo básico.
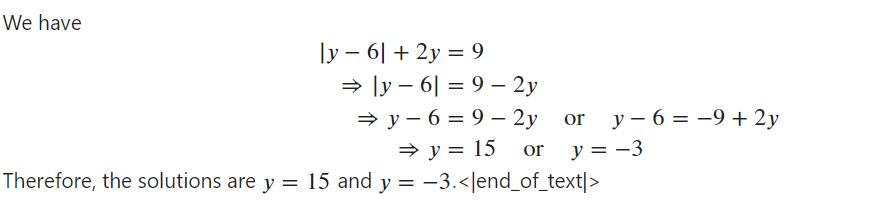
working nos fornece apenas 20 GB, o que não é suficiente para mesclar e enviar o modelo completo. A criação de outra pasta no diretório raiz nos permitirá acessar os 60 GB de armazenamento temporário.%mkdir ../temp
%cd /kaggle/tempmodel.push_to_hub_merged(new_model_name, tokenizer, save_method = "merged_16bit")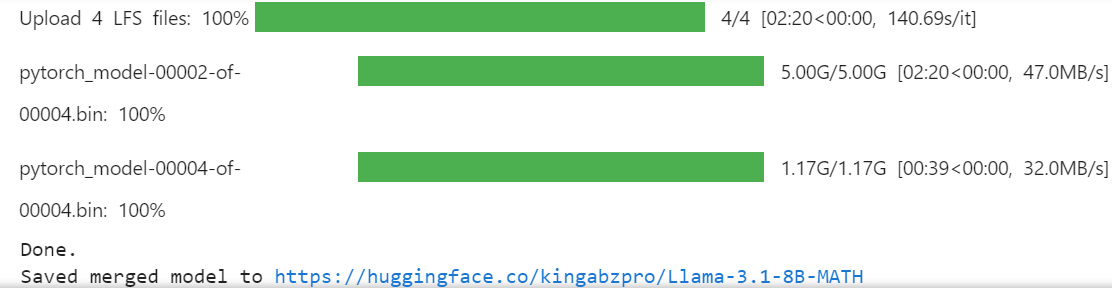
model.push_to_hub_gguf(new_model_name, tokenizer, quantization_method = "q4_k_m")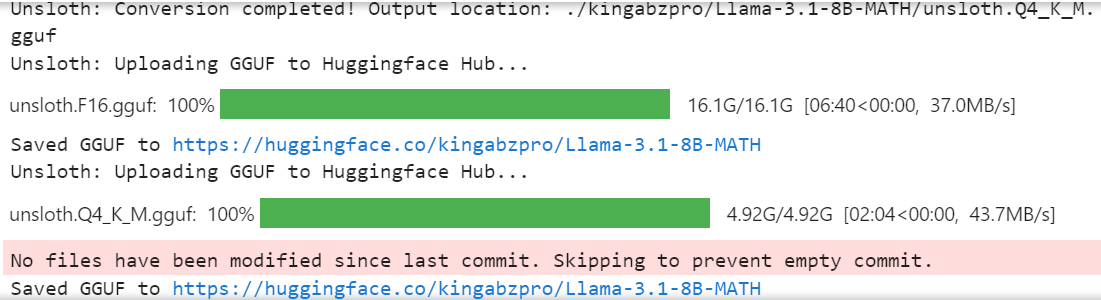
O modelo completo de 16 bits, o adaptador e os arquivos GGUF quantizados estão disponíveis em seu repositório de modelos. Para usar o modelo ajustado localmente, basta fazer o download do arquivo GGUF quantizado e começar a usá-lo com Jan, Misty, GPT4ALL ou Ollama.
Siga o site . Você pode ajustar o Llama 3.2 e usá-lo localmente: A Step-by-Step Guide tutorial para você aprender a ajustar o modelo Llama 3.2 em um conjunto de dados de suporte ao cliente, mesclar e exportar o modelo para o Hugging Face Hub e converter o modelo ajustado para o formato GGUF para que possa ser usado localmente com o aplicativo Jan.
Fonte: kingabzpro/Llama-3.1-8B-MATH
Se você estiver enfrentando problemas durante o carregamento e a mesclagem do LoRA com o modelo básico, consulte o artigo Mesclando o LoRA Adopter com o Unsloth do Kaggle para obter mais assistência.
Também recomendo que você leia o blog 12 projetos de LLM para todos os níveis. Inclui uma lista de projetos de LLM para iniciantes, alunos intermediários, alunos do último ano e especialistas.
Neste tutorial, aprendemos a fazer um ajuste fino eficaz do modelo Llama 3.1 3B usando poucos recursos de computação e atingindo velocidades duas vezes mais rápidas do que os métodos tradicionais.
Também aprendemos a executar a inferência rápida de modelos, mesclar o LoRA com o modelo básico e enviá-lo para o hub Hugging Face.
Além disso, convertemos o modelo no formato llama.cpp e o quantizamos para que o modelo ajustado possa ser facilmente usado localmente no laptop usando os aplicativos Jan ou GPT4ALL.
Para melhorar o desempenho do modelo, é altamente recomendável fazer o ajuste fino do modelo no conjunto de dados completo, otimizar os hiperparâmetros e trabalhar no estilo do prompt. Mesmo após o ajuste fino, você pode melhorar o desempenho dos aplicativos de IA de várias maneiras usando chamadas de função e pipelines RAG.
Saiba qual solução é melhor para seus casos específicos seguindo o site RAG vs. Fine-Tuning: Um tutorial abrangente com exemplos práticos guide. Ele inclui um código de amostra para você experimentar em seu conjunto de dados e comparar os resultados.
Principais cursos de LLM
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Zoumana Keita



