
Course
Introduction to LLMs in Python
3 hr
33.6K
Have you ever encountered memory issues while fine-tuning models or found that the process takes an unbearably long time to complete? If you are searching for a more efficient and faster solution than using the Transformers library for fine-tuning large language models (LLMs), you have come to the right place!
In this tutorial, we will explore how to fine-tune the Llama 3.1 3B model using only 9GB of VRAM, achieving speeds 2x faster than traditional Transformers methods. We will also cover how to perform fast inference, convert the model into vLLM-compatible and GGUF file formats, and seamlessly push the saved model to the Hugging Face Hub with just a few lines of code.
If you’re new to these concepts, be sure to take the Master Large Language Models (LLMs) Concepts course to build a solid foundation before diving into fine-tuning.

Image by Author
Unsloth AI is a Python framework designed for fast fine-tuning and accessing large language models. It offers a simple API and performance that is 2x faster compared to Transformers.
Accessing the Llama-3.1 model using Unsloth is pretty simple. We won't be loading the 16-bit model. Instead, we will be loading the 4-bit version available on the Hugging Face to save the GPU memory and for faster inference.
%%capture
%pip install unslothFastLanguageModel function. from transformers import TextStreamer
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-bnb-4bit"
)
FastLanguageModel.for_inference(model)prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
inputs = tokenizer(
[
prompt_style.format(
"You are a professional machine learning engineer",
"How would you deal with NaN validation loss?",
"",
)
],
return_tensors="pt",
).to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=128)
We received a positive response regarding how to handle NaN validation loss.

If you are having trouble running the above code in Kaggle, here is the sample Notebook: Accessing LLMs using Unsloth.
By taking the Introduction to LLMs in Python course, you will learn the basics of Transformer architecture, including how to build it, fine-tune it, and evaluate it. It is your gateway into the world of LLM fine-tuning using Python.
In this guide, we will learn how to fine-tune Llama 3.1 on the lighteval/MATH dataset using Unsloth. The dataset consists of algebra problems with solutions in markdown format. The entire dataset is divided into five difficulty levels.
To better understand this guide, I recommend you learn the theory behind each step involved in fine-tuning LLMs by reading An Introductory Guide to Fine-Tuning LLMs. Take a few minutes to review the guide, as it will help you understand this process.
We are using a Kaggle notebook as our cloud IDE, and we need to set up the notebook before working with the model or data.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama-3.1-8B-bnb-4bit on Math Dataset',
job_type="training",
anonymous="allow"
)Just like the model inference section, we will load the 4-bit quantized version of the Llama 3.1 model using the 2048 max sequence length and None data type.
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype
)Then, we will load the dataset and process it. For that, we first have to create a prompt style that will help us get the required results.
The prompt style includes a system prompt, instruction, and a placeholder for input and response.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
You are a math genius who can solve any level of algebraic problems. Please answer the following math question.
### Input:
{}
### Response:
{}"""After that, create the function that will use the prompt style to input the math problems and solutions, converting them into the proper text. Make sure to add EOS_TOKEN to avoid any reputation.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["problem"]
outputs = examples["solution"]
texts = []
for input, output in zip(inputs, outputs):
text = prompt_style.format(input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }Load the 500 samples from the dataset, apply the formatting_prompts_func function to the dataset, and view the first sample from the text column.
from datasets import load_dataset
dataset = load_dataset("lighteval/MATH", split="train[0:500]", trust_remote_code=True)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][0]The text has a system prompt, instruction, algebra problem question, and solution to that problem.

We add the LoRA (Low-Rank Adapter) to the model using the linear modules from the base model.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=False,
loftq_config=None,
)Set up the trainer with the model, tokenizer, max sequence length, and training arguments. This is quite similar to setting up a trainer using the Transformers and TRL library.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)The model training took almost 19 minutes, which is impressive. The training loss has reduced significantly with each step.
trainer_stats = trainer.train()
You can check out detailed model performance and hardware metrics by going to the Weights & Biases dashboard.
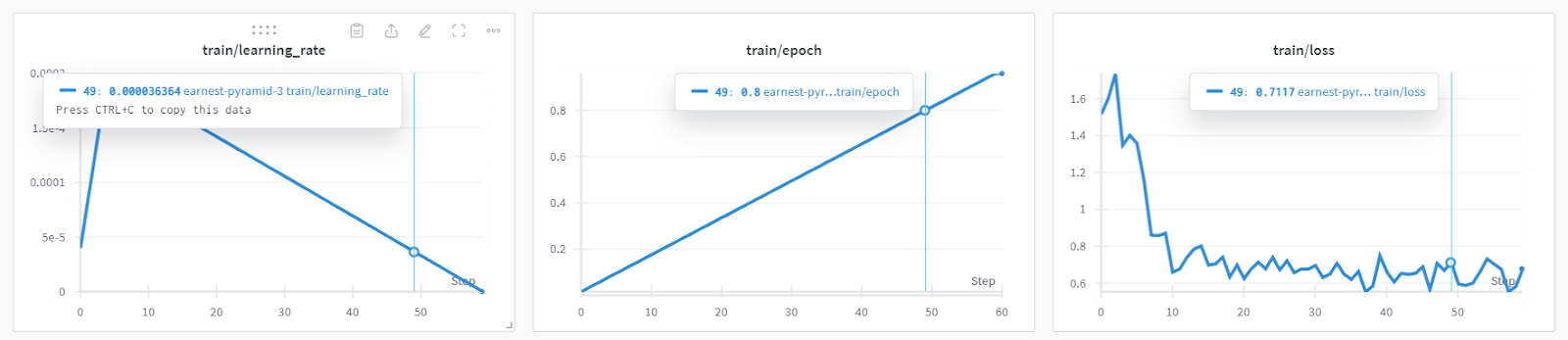
You can also use torch and trainer_stats to generate your own report.
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory /max_memory*100, 3)
lora_percentage = round(used_memory_for_lora/max_memory*100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")The model was trained in 20 minutes, and the peak reserved memory for training was approximately 3.7 GB. This is relatively low compared to the traditional method, which involves loading the full model, quantizing it, and finally fine-tuning it. In that case, it will require at least 15 GB of GPU memory.
1207.5478 seconds used for training.
20.13 minutes used for training.
Peak reserved memory = 9.73 GB.
Peak reserved memory for training = 3.746 GB.
Peak reserved memory % of max memory = 61.241 %.
Peak reserved memory for training % of max memory = 23.578 %.To test the model after fine-tuning, we need to activate fast inference. Next, we will input a sample algebra question from the dataset into the prompt style and convert it into tokens. Then, we will use the model to generate the response and decode the output to display the text.
The generated text was in Markdown format, but we have converted it to display the text with proper math equations.
from IPython.display import display, Markdown
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
prompt_style.format(
"If the system of equations \begin{align*} 3x+y&=a,\\ 2x+5y&=2a, \end{align*} has a solution $(x,y)$ when $x=2$, compute $a$.",
"",
)
],
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=250,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
Markdown(response[0].split("\n\n### Response:")[1])As we can see, the generated response aligns with the dataset and provides us with the solutions for the algebraic problems.

Let’s save our fine-tuned model and push it to the Hugging Face Hub so you can easily share or deploy it.
new_model_online = "kingabzpro/Llama-3.1-8B-MATH"
new_model_local = "Llama-3.1-8B-MATH"
model.save_pretrained(new_model_local) # Local saving
tokenizer.save_pretrained(new_model_local) # Local savingThe following code will create a new repository in the Hugging Face and then push the LoRA and the tokenizer with the metadata.
model.push_to_hub(new_model_online) # Online saving
tokenizer.push_to_hub(new_model_online) # Online saving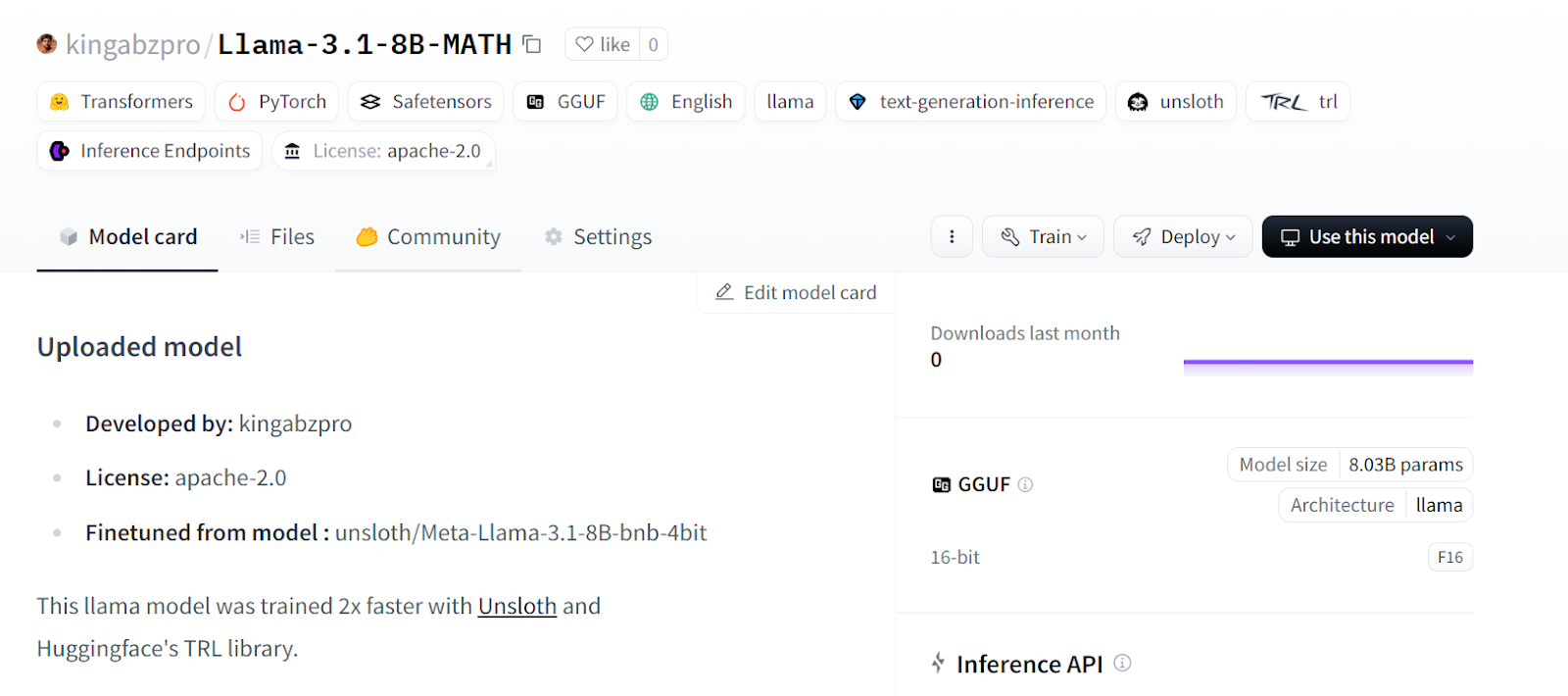
Source: kingabzpro/Llama-3.1-8B-MATH
If you are experiencing issues while fine-tuning the LLM using Unsloth, please refer to the Fine-tuning LLMs using Unsloth Kaggle Notebook. It contains stable code that you can run on your own to reproduce the results.
The next step in your AI journey is to use LLMs to develop effective AI applications. You can find more information by following the How to Build LLM Applications with LangChain tutorial.
Merging the LoRa with the base model requires additional VRAM and local storage. To avoid exceeding any limits, we will create a new Kaggle notebook with the P100 GPU as an accelerator. We will also activate the Hugging Face API to access the API key.
%%capture
%pip install unslothfrom huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)from unsloth import FastLanguageModel
new_model_name = "kingabzpro/Llama-3.1-8B-MATH"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = new_model_name, # YOUR MODEL YOU USED FOR TRAINING
max_seq_length = 2048,
dtype = None,
load_in_4bit = True,
)
FastLanguageModel.for_inference(model); 
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
You are a math genius who can solve any level of algebraic problem. Please answer the following math question.
### Input:
{}
### Response:
{}"""from IPython.display import display, Markdown
inputs = tokenizer(
[
prompt_style.format(
"Solve the equation $|y-6| + 2y = 9$ for $y$.", # input
"", # output - leave this blank for generation!
)
],
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=250,
pad_token_id=tokenizer.eos_token_id,
)
response = tokenizer.batch_decode(outputs)
Markdown(response[0].split("\n\n### Response:")[1])
The model is working perfectly and is ready to be merged with the base model.
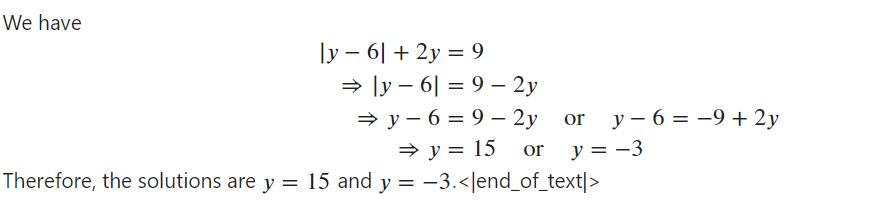
working directory only provides us with 20 GB, which is not enough for merging and pushing the full model. Creating another folder in the root directory will allow us to access the 60 GB of temporary storage.%mkdir ../temp
%cd /kaggle/tempmodel.push_to_hub_merged(new_model_name, tokenizer, save_method = "merged_16bit")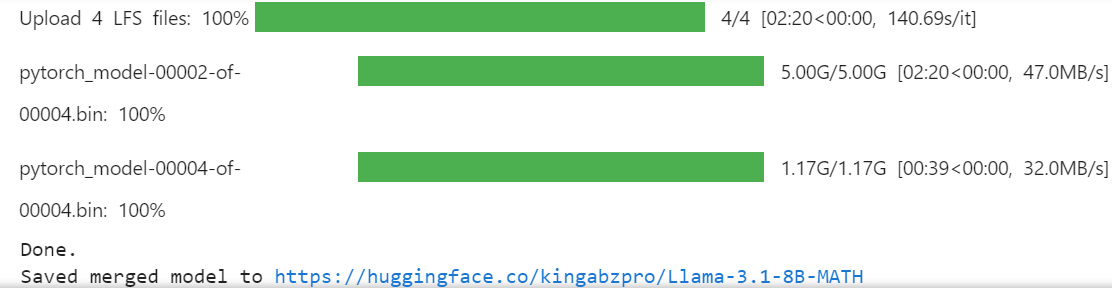
model.push_to_hub_gguf(new_model_name, tokenizer, quantization_method = "q4_k_m")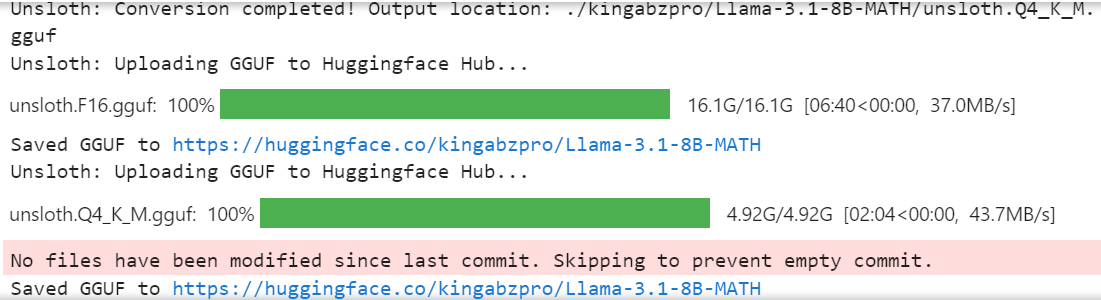
The full 16-bit model, adapter, and quantized GGUF files are available on your model repository. To use the fine-tuned model locally, simply download the quantized GGUF file and start using it with Jan, Misty, GPT4ALL, or Ollama.
Follow the Fine-tuning Llama 3.2 and Using It Locally: A Step-by-Step Guide tutorial to learn how to fine-tune the Llama 3.2 model on a customer support dataset, merge and export the model to the Hugging Face Hub, and convert the fine-tuned model to GGUF format so it can be used locally with the Jan application.
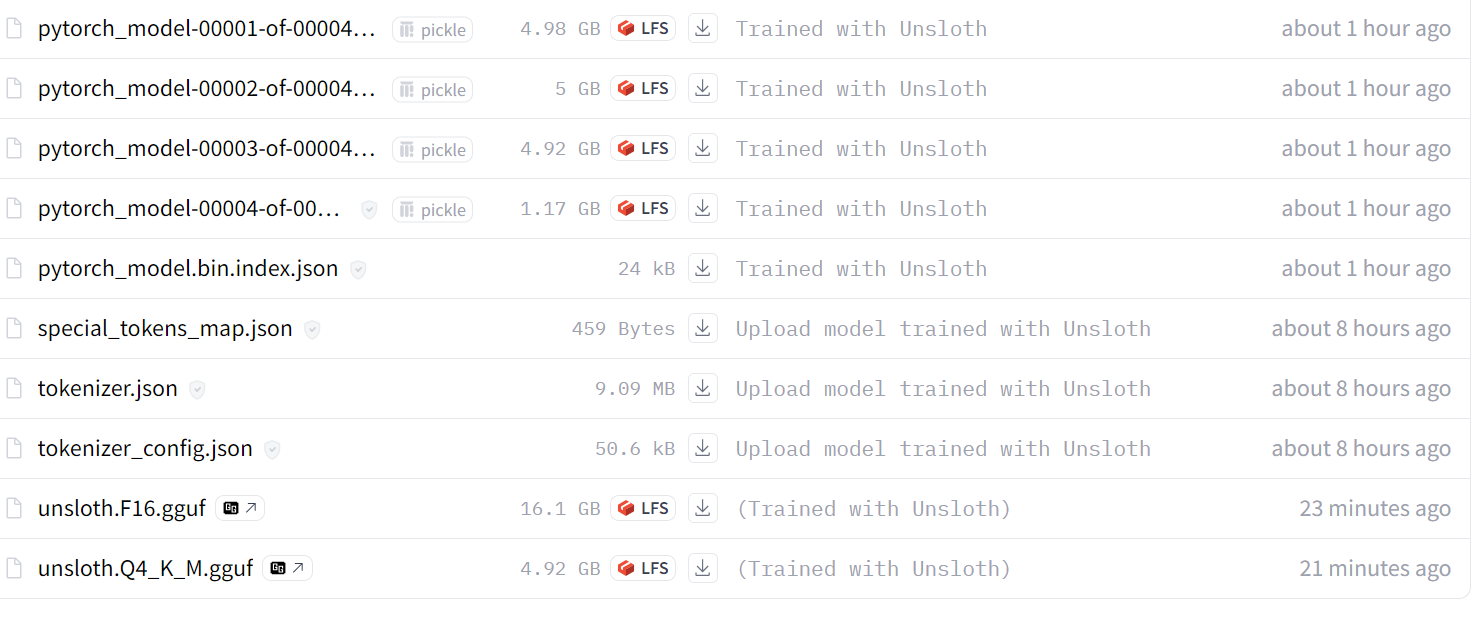
Source: kingabzpro/Llama-3.1-8B-MATH
If you are facing issues during loading and merging the LoRA with the base model, please check out the Merging LoRA Adopter with Unsloth Kaggle notebook for further assistance.
I also recommend you read the blog 12 LLM Projects For All Levels. It includes a list of LLM projects for beginners, intermediate students, final-year scholars, and experts.
In this tutorial, we learned how to effectively fine-tune the Llama 3.1 3B model using low computing resources and achieving speeds that are 2x faster than traditional methods.
We also learned how to run fast model inference, merge the LoRA with the base model, and push it to the Hugging Face hub.
Additionally, we converted the model into the llama.cpp format and quantized it so that the fine-tuned model can be easily used locally on the laptop using Jan or GPT4ALL applications.
To improve the model's performance, we highly recommend fine-tuning the model on the full dataset, optimizing the hyperparameters, and working on the prompt style. Even after fine-tuning, you can improve the performance of AI applications in many ways using function calling and RAG pipelines.
Learn which solution is better for your specific cases by following the RAG vs Fine-Tuning: A Comprehensive Tutorial with Practical Example guide. It includes a sample code for you to try on your dataset and compare the results.
Top LLM Courses
Course
Course
Course
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
code-along
Maxime Labonne

