


Curso
Introducción a Python
4 h
6.9M
Escribir clases eficientes en memoria en Python es necesario para desarrollar aplicaciones robustas que funcionen bien bajo diversas restricciones del sistema. El uso eficiente de la memoria acelera el tiempo de ejecución de la aplicación y mejora la escalabilidad al consumir menos recursos, lo que es especialmente importante en entornos con disponibilidad limitada de memoria.
En este artículo, te introduciré en los fundamentos de la gestión de memoria en Python y te presentaré diferentes técnicas prácticas para escribir clases eficientes en memoria. Tanto si estás construyendo sistemas complejos como simples scripts, estas ideas te ayudarán a escribir un código Python más limpio y eficiente.
El sistema de gestión de memoria de Python es sofisticado y está diseñado para simplificar el desarrollo manejando la complejidad de las operaciones de memoria. Este sistema es necesario para garantizar que las aplicaciones Python se ejecuten eficazmente.
El montón privado es el núcleo de la gestión de memoria de Python. Es donde se almacenan todos los objetos y estructuras de datos de Python. Los programadores no pueden acceder directamente a este montón privado, sino que interactúan con los objetos a través del sistema de gestión de memoria de Python.
El sistema de gestión de memoria utiliza:
Python emplea un enfoque dual para la recogida de basura:
Comprender y optimizar el uso de la memoria es vital para mantener el rendimiento de las aplicaciones.
Python ofrece varias herramientas para el perfilado de memoria, que proporcionan información más allá de la depuración estándar, ayudando a los desarrolladores a identificar y resolver ineficiencias de memoria:
En este tutorial utilizaremos la biblioteca pympler en este tutorial, y puedes instalarla utilizando el gestor de paquetes pip en tu terminal:
pip install pymplerPuedes leer más sobre el perfilado de memoria en nuestro tutorial -Introducción a los perfiles de memoria en Python.
Ahora que hemos comprendido los fundamentos de la gestión de memoria en Python, examinemos algunas técnicas avanzadas para escribir clases eficientes en memoria.
__slots__En Python, cada instancia de clase tiene un diccionario llamado __dict__ para almacenar las variables de instancia. Aunque esto permite la asignación dinámica de nuevas variables, puede suponer una importante sobrecarga de memoria, especialmente cuando se crean muchas instancias de clase. Al definir __slots__, le dices a Python que asigne espacio a un conjunto fijo de atributos, eliminando la necesidad del diccionario dinámico.
Utilizar __slots__ tiene dos ventajas principales:
__slots__ es más rápido que hacerlo a través de un diccionario, debido a la búsqueda directa de atributos, que omite las operaciones de tabla hash que implica el acceso al diccionario.Consideremos una clase simple que represente un punto en un espacio bidimensional:
class PointWithoutSlots:
def __init__(self, x, y):
self.x = x
self.y = y
class PointWithSlots:
__slots__ = ('x', 'y')
def __init__(self, x, y):
self.x = x
self.y = yEn la PointWithoutSlots cada instancia tiene un __dict__ para almacenar x y y mientras que la clase PointWithSlots no, por lo que se utiliza menos memoria por instancia.
Para ilustrar la diferencia en el uso de la memoria, vamos a crear mil puntos y medir la memoria total utilizada utilizando la función pympler paquete:
from pympler import asizeof
points_without_slots = [PointWithoutSlots(i, i) for i in range(1000)]
points_with_slots = [PointWithSlots(i, i) for i in range(1000)]
print("Total memory (without __slots__):", asizeof.asizeof(points_without_slots))
print("Total memory (with __slots__):", asizeof.asizeof(points_with_slots))La salida que vemos es:
Comparación de la memoria con y sin ranuras
La salida suele mostrar que la instancia de PointWithSlots consume menos memoria que PointWithoutSlotslo que demuestra la eficacia de __slots__ para reducir la sobrecarga de memoria por instancia.
__slots__Aunque __slots__ son beneficiosas para optimizar la memoria, tienen ciertas limitaciones:
__slots__, no puedes añadir dinámicamente nuevos atributos a las instancias.__slots__ es heredala subclase también debe definir __slots__ para seguir beneficiándose de la optimización de memoria, lo que puede complicar el diseño de la clase . A pesar de estas limitaciones, utilizar __slots__ es una poderosa herramienta para los desarrolladores que pretendan optimizar el uso de memoria en las aplicaciones Python, sobre todo en entornos con estrictas restricciones de memoria o en los que el número de instancias sea muy elevado.
Los patrones de diseño eficientes en memoria son soluciones arquitectónicas que ayudan a optimizar el uso y la gestión de la memoria en las aplicaciones Python.
Dos patrones especialmente eficaces para la eficiencia de memoria en el diseño de clases son los patrones Flyweight y Singleton. Cuando se implementan correctamente en escenarios que implican numerosas instancias de clases o datos compartidos, estos patrones pueden reducir drásticamente el consumo de memoria.
El patrón de diseño Flyweight funciona compartiendo partes comunes del estado entre varios objetos en lugar de mantener todos los datos en cada objeto, lo que reduce significativamente la huella de memoria total.
Considera una clase que represente círculos gráficos en una aplicación de dibujo en la que cada círculo tenga un color, un radio y unas coordenadas. Utilizando el patrón Peso Mosca, el color y el radio, que probablemente compartan muchos círculos, pueden almacenarse en objetos compartidos:
class Circle:
# Flyweight object
def __init__(self, color):
self.color = color
def draw(self, radius, x, y):
print(f"Drawing a {self.color} circle with radius {radius} at ({x},{y})")
class CircleFactory:
# Factory to manage Flyweight objects
_circles = {}
@classmethod
def get_circle(cls, color):
if not cls._circles.get(color):
cls._circles[color] = Circle(color)
return cls._circles[color]En este ejemplo, varias instancias del círculo comparten el Circle objeto del CircleFactory en función del color, lo que garantiza un uso más eficiente de la memoria al almacenar los datos de color una sola vez.
Utilicemos esta clase para crear instancias y comprender cómo se guarda la memoria.
import sys
factory = CircleFactory()
circle1 = factory.get_circle("Red")
circle2 = factory.get_circle("Red")
circle3 = factory.get_circle("Blue")
print("Memory address of circle1:", id(circle1))
print("Memory address of circle2:", id(circle2))
print("Memory address of circle3:", id(circle3))
print ("-----------------------------")
print("Memory used by circle1:", sys.getsizeof(circle1))
print("Memory used by circle2:", sys.getsizeof(circle2))
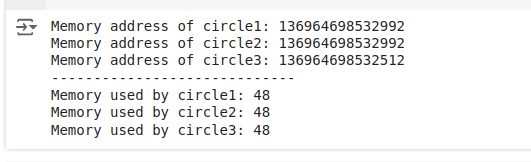
print("Memory used by circle3:", sys.getsizeof(circle3))La salida que vemos es:
Uso de memoria para el patrón de diseño flyweight
Podemos ver que circle1 y circle2 tienen la misma dirección de memoria, lo que significa que efectivamente son el mismo objeto (comparten la misma instancia para el color "Rojo"). circle3 tiene una dirección de memoria diferente porque representa un círculo con un color distinto ("Azul").
circle1 y circle2 sean la misma instancia demuestra que CircleFactory compartió con éxito la instanciaCircle entre estas dos. Aquí es donde entra en juego la eficiencia de la memoria: si tuvieras mil círculos rojos en tu aplicación utilizando el patrón Flyweight, todos compartirían una única instancia Circle para el color, en lugar de tener cada uno su propia instanciaCircle independiente , ahorrando así una cantidad significativa de memoria.
El patrón Singleton garantiza que una clase sólo tenga una instancia y proporciona un punto de acceso global a ella. Este patrón es útil para gestionar configuraciones o recursos compartidos en toda una aplicación, reduciendo la sobrecarga de memoria al no replicar los recursos compartidos o los datos de configuración en varios lugares.
Considera esto Database clase:
class Database:
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super(Database, cls).__new__(cls)
# Initialize any attributes of the instance here
return cls._instance
def connect(self):
# method to simulate database connection
return "Connection established"En esta implementación, el Database se asegura de que, independientemente de cuántas veces se instancie, sólo se utilice una instancia compartida, conservando memoria al evitar múltiples objetos idénticos.
Podemos comprobarlo con el siguiente código:
db1 = Database()
print(db1.connect())
db2 = Database()
print(db1 is db2) El resultado es el siguiente:
Creación de instancias para el patrón de diseño singleton
La salida "Verdadero" indica que db1 y db2 se refieren a la misma instancia.
Estos patrones demuestran cómo un diseño bien pensado puede mejorar significativamente la eficiencia de la memoria. Al elegir y aplicar los patrones de diseño adecuados, los desarrolladores pueden optimizar sus aplicaciones Python para que sean más ágiles y eficaces.
Seleccionar el tipo de datos tipo de datos incorporado en Python puede influir significativamente en la eficiencia de la memoria. Los tipos incorporados están optimizados para el rendimiento y el uso de memoria debido a sus implementaciones internas en el intérprete de Python.
Por ejemplo, debido a sus propiedades únicas, las tuplas y los conjuntos pueden ser opciones más eficientes en memoria para casos de uso específicos que las listas y los diccionarios.
Las tuplas suelen utilizar menos memoria que las listas porque tienen un tamaño fijo y no pueden alterarse una vez creadas, lo que permite a los mecanismos internos de Python optimizar su almacenamiento en memoria. Para las clases diseñadas para manejar datos que no necesitan modificación tras su creación, las tuplas son una opción excelente.
Considera dos clases simples de Polígonos que utilizan sendas tuplas y listas para almacenar valores:
class PolygonWithTuple:
def __init__(self, points):
self.points = tuple(points) # Storing points as a tuple
def display_points(self):
return self.points
class PolygonWithList:
def __init__(self, points):
self.points = list(points) # Storing points as a list
def display_points(self):
return self.pointsPodemos crear instancias de ambas clases para comparar el uso de memoria:
from pympler import asizeof
points = [(1, 2), (3, 4), (5, 6), (7, 8)]
# Creating instances of each class
polygon_tuple = PolygonWithTuple(points)
polygon_list = PolygonWithList(points)
# Memory usage comparison using pympler
print("Total memory used by Polygon with Tuple:", asizeof.asizeof(polygon_tuple))
print("Total memory used by Polygon with List:", asizeof.asizeof(polygon_list))El resultado que obtenemos es:
Comparación de memoria para tuplas y listas
Este resultado demuestra que la tupla suele utilizar menos memoria que la lista, lo que hace que la clase PolygonWithTuple más eficiente para almacenar datos fijos e inmutables, como las coordenadas geométricas.
En Python, generadores son una potente herramienta para gestionar la memoria de forma eficiente, especialmente cuando se trabaja con grandes conjuntos de datos.
Los generadores permiten procesar los datos de uno en uno, cargando en memoria sólo lo necesario en cada momento. Este método de evaluación perezosa es beneficioso en aplicaciones en las que se manejan grandes volúmenes de datos, pero sólo es necesario procesar una pequeña cantidad cada vez, reduciendo así la huella de memoria total.
Considera una aplicación que necesita procesar un gran conjunto de datos de registros de usuarios, como calcular la edad media de los usuarios. En lugar de cargar todos los registros en una lista (lo que podría consumir una cantidad importante de memoria), un generador puede procesar un registro cada vez.
def process_records(file_name):
"""Generator that yields user ages from a file one at a time."""
with open(file_name, 'r') as file:
for line in file:
user_data = line.strip().split(',')
yield int(user_data[1])
def average_age(file_name):
"""Calculate the average age from user records."""
total_age = 0
count = 0
for age in process_records(file_name):
total_age += age
count += 1
return total_age / count if count else 0
print("Average Age:", average_age('user_data.csv'))En este ejemplo, la función generadoraprocess_records() lee de un fichero una línea cada vez, convierte los datos relevantes en un número entero y lo devuelve. Esto significa que sólo se guarda en memoria una línea de datos en cada momento, minimizando el uso de memoria. La función average_age() consume el generador, acumulando la edad total y el recuento sin necesitar nunca todo el conjunto de datos en memoria a la vez.
Así, utilizando el enfoque de la evaluación perezosa, podemos conservar memoria y mejorar la capacidad de respuesta y la escalabilidad de sus aplicaciones.
Las referencias circulares se producen cuando dos o más objetos se referencian entre sí. Esto puede ocurrir sutilmente con estructuras como listas, diccionarios o incluso definiciones de clases más complejas en las que las instancias mantienen referencias entre sí, creando un bucle.
Como vimos en los fundamentos de la gestión de memoria, Python tiene un recolector de basura adicional para detectar y limpiar las referencias circulares. Sin embargo, confiar en este mecanismo puede llevar a un mayor uso de memoria y a ineficiencias:
Considera un caso de uso típico en una estructura de datos en forma de árbol, en la que cada nodo puede guardar una referencia a sus hijos y, opcionalmente, a su padre. Esta vinculación padre-hijo puede crear fácilmente referencias circulares.
class TreeNode:
def __init__(self, value, parent=None):
self.value = value
self.parent = parent
self.children = []
def add_child(self, child):
child.parent = self # Set parent reference
self.children.append(child)
root = TreeNode("root")
child = TreeNode("child1", root)
root.add_child(child)En este ejemplo, el root hace referencia al child a través de su listachildren, y el child hace referencia al root a través de su atributoparent. Esta configuración puede crear una referencia circular sin más intervención.
Las referencias débiles son una forma eficaz de romper o evitar las referencias circulares sin rediseñar toda la estructura de datos.
El móduloweakref de Python permite una referencia a un objeto que no aumenta su número de referencias. Esta referencia débil no impide que el objeto referenciado sea recogido de la basura, evitando las fugas de memoria asociadas a las referencias circulares.
He aquí cómo podemos modificar la clase anterior para utilizar referencias débiles:
import weakref
class TreeNode:
def __init__(self, value, parent=None):
self.value = value
self.parent = weakref.ref(parent) if parent else None
self.children = []
def add_child(self, child):
child.parent = weakref.ref(self)
self.children.append(child)
root = TreeNode("root")
child = TreeNode("child1", root)
root.add_child(child)En esta clase, el atributo padre es ahora una referencia débil al nodo padre. Esto significa que el nodo padre puede ser recogido de la basura aunque el nodo hijo siga existiendo, siempre que no haya otras referencias fuertes al padre.
Este enfoque evita eficazmente los problemas de fugas de memoria que suelen asociarse a las referencias circulares en dichas estructuras.
Este artículo introduce los fundamentos de la gestión de memoria en Python y presenta cinco técnicas avanzadas para escribir clases eficientes en memoria, junto con ejemplos prácticos y comparaciones de memoria. Esperamos que adoptes estas técnicas y buenas prácticas en tus proyectos para crear aplicaciones escalables y eficientes.
Te animamos a que consultes nuestro Curso de Programación en Pythonque abarca los principios de la ingeniería de software y programación orientada a objetos, incluyendo escribir código Python eficiente.
¡Aprende más sobre Python con estos cursos!
Curso
Curso
Curso
Tutorial
Théo Vanderheyden
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Moez Ali