



Course
Introduction to Python
4 hr
6.9M
Writing memory-efficient classes in Python is necessary for developing robust applications that perform well under various system constraints. Efficient memory usage speeds up application runtime and enhances scalability by consuming fewer resources, which is especially important in environments with limited memory availability.
In this article, I’ll introduce you to the fundamentals of memory management in Python and present different practical techniques for writing memory-efficient classes. Whether you’re building complex systems or simple scripts, these insights will help you write cleaner, more efficient Python code.
Python’s memory management system is sophisticated and designed to simplify development by handling the complexity of memory operations. This system is required to ensure that Python applications run efficiently.
The private heap is at the core of Python’s memory management. It is where all Python objects and data structures are stored. Programmers cannot access this private heap directly; instead, they interact with objects through Python’s memory management system.
The memory management system uses:
Python employs a dual approach for garbage collection:
Understanding and optimizing memory usage are vital for maintaining application performance.
Python offers several tools for memory profiling, which provide insights beyond standard debugging, helping developers identify and resolve memory inefficiencies:
We’ll be using the pympler library in this tutorial, and you can install it using the pip package manager on your terminal:
pip install pymplerYou can read more about memory profiling from our tutorial — Introduction to Memory Profiling in Python.
Now that we’ve understood the basics of memory management in Python let’s examine some advanced techniques for writing memory-efficient classes.
__slots__In Python, each class instance has a dictionary called __dict__ to store instance variables. While this allows for dynamic assignment of new variables, it can lead to significant memory overhead, especially when creating many class instances. By defining __slots__, you tell Python to allocate space for a fixed set of attributes, eliminating the need for the dynamic dictionary.
Using __slots__ has two primary benefits:
__slots__ is faster than accessing them through a dictionary due to the direct attribute lookup, which skips the hash table operations involved in dictionary access.Let’s consider a simple class representing a point in a two-dimensional space:
class PointWithoutSlots:
def __init__(self, x, y):
self.x = x
self.y = y
class PointWithSlots:
__slots__ = ('x', 'y')
def __init__(self, x, y):
self.x = x
self.y = yIn the PointWithoutSlots class, each instance has a __dict__ to store x and y attributes, whereas the PointWithSlots class does not, leading to less memory used per instance.
To illustrate the difference in memory usage, let’s create a thousand points and measure the total memory used using the pympler package:
from pympler import asizeof
points_without_slots = [PointWithoutSlots(i, i) for i in range(1000)]
points_with_slots = [PointWithSlots(i, i) for i in range(1000)]
print("Total memory (without __slots__):", asizeof.asizeof(points_without_slots))
print("Total memory (with __slots__):", asizeof.asizeof(points_with_slots))The output we see is:
Memory comparison with and without slots
The output typically shows that the instance of PointWithSlots consumes less memory than PointWithoutSlots, demonstrating the effectiveness of __slots__ in reducing per-instance memory overhead.
__slots__While __slots__ are beneficial for memory optimization, they come with certain limitations:
__slots__ is defined, you cannot dynamically add new attributes to instances.__slots__ is inherited, the subclass must also define __slots__ to continue benefiting from memory optimization, which can complicate the class design. Despite these limitations, using __slots__ is a powerful tool for developers aiming to optimize memory usage in Python applications, particularly in environments with stringent memory constraints or where the number of instances is very high.
Memory-efficient design patterns are architectural solutions that help optimize memory use and management in Python applications.
Two particularly effective patterns for memory efficiency in class design are the Flyweight and Singleton patterns. When correctly implemented in scenarios involving numerous instances of classes or shared data, these patterns can drastically reduce memory consumption.
The Flyweight design pattern works by sharing common parts of the state among multiple objects instead of keeping all data in each object, significantly reducing the overall memory footprint.
Consider a class representing graphical circles in a drawing application where each circle has a color, radius, and coordinates. Using the Flyweight pattern, color and radius, which are likely shared by many circles, can be stored in shared objects:
class Circle:
# Flyweight object
def __init__(self, color):
self.color = color
def draw(self, radius, x, y):
print(f"Drawing a {self.color} circle with radius {radius} at ({x},{y})")
class CircleFactory:
# Factory to manage Flyweight objects
_circles = {}
@classmethod
def get_circle(cls, color):
if not cls._circles.get(color):
cls._circles[color] = Circle(color)
return cls._circles[color]In this example, multiple circle instances share the Circle object from the CircleFactory based on color, ensuring that memory is used more efficiently by storing color data once.
Let’s use this class to create instances and understand how the memory is saved.
import sys
factory = CircleFactory()
circle1 = factory.get_circle("Red")
circle2 = factory.get_circle("Red")
circle3 = factory.get_circle("Blue")
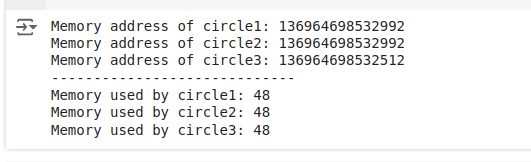
print("Memory address of circle1:", id(circle1))
print("Memory address of circle2:", id(circle2))
print("Memory address of circle3:", id(circle3))
print ("-----------------------------")
print("Memory used by circle1:", sys.getsizeof(circle1))
print("Memory used by circle2:", sys.getsizeof(circle2))
print("Memory used by circle3:", sys.getsizeof(circle3))The output we see is:
Memory usage for flyweight design pattern
We can see that circle1 and circle2 have the same memory address, which means they are indeed the same object (sharing the same instance for the color “Red”). circle3 has a different memory address because it represents a circle with a different color (“Blue”).
circle1 and circle2 being the same instance demonstrates that the CircleFactory successfully shared the Circle instance between these two. This is where memory efficiency comes in: if you had a thousand red circles in your application using the Flyweight pattern, they would all share a single Circle instance for the color, rather than each having its own separate Circle instance, thus saving a significant amount of memory.
The Singleton pattern ensures that a class has only one instance and provides a global point of access to it. This pattern is handy for managing configurations or shared resources across an application, reducing the memory overhead by not replicating shared resources or configuration data in multiple places.
Consider this Database class:
class Database:
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super(Database, cls).__new__(cls)
# Initialize any attributes of the instance here
return cls._instance
def connect(self):
# method to simulate database connection
return "Connection established"In this implementation, the Database ensures that no matter how many times it’s instantiated, only one shared instance is used, conserving memory by avoiding multiple identical objects.
We can check this by the following code:
db1 = Database()
print(db1.connect())
db2 = Database()
print(db1 is db2) The output is as follows:
Instance creation for singleton design pattern
The “True” output indicates that db1 and db2 variables refer to the same instance.
These patterns demonstrate how thoughtful design can significantly improve memory efficiency. By choosing and implementing appropriate design patterns, developers can optimize their Python applications to be leaner and more performant.
Selecting the appropriate built-in data type in Python can significantly impact memory efficiency. Built-in types are optimized for performance and memory usage due to their internal implementations in the Python interpreter.
For instance, due to their unique properties, tuples and sets can be more memory-efficient choices for specific use cases than lists and dictionaries.
Tuples generally use less memory than lists because they have a fixed size and cannot be altered once created, allowing Python’s internal mechanisms to optimize their storage in memory. For classes designed to handle data that does not need modification post-creation, tuples are an excellent choice.
Consider two simple Polygon classes that use tuples and lists each to store values:
class PolygonWithTuple:
def __init__(self, points):
self.points = tuple(points) # Storing points as a tuple
def display_points(self):
return self.points
class PolygonWithList:
def __init__(self, points):
self.points = list(points) # Storing points as a list
def display_points(self):
return self.pointsWe can create instances of both classes to compare the memory usage:
from pympler import asizeof
points = [(1, 2), (3, 4), (5, 6), (7, 8)]
# Creating instances of each class
polygon_tuple = PolygonWithTuple(points)
polygon_list = PolygonWithList(points)
# Memory usage comparison using pympler
print("Total memory used by Polygon with Tuple:", asizeof.asizeof(polygon_tuple))
print("Total memory used by Polygon with List:", asizeof.asizeof(polygon_list))The output we get is:
Memory comparison for tuples and lists
This output demonstrates that the tuple typically uses less memory than the list, making the PolygonWithTuple class more memory-efficient for storing fixed, unchangeable data like geometric coordinates.
In Python, generators are a powerful tool for managing memory efficiently, especially when working with large datasets.
Generators allow data to be processed one item at a time, only loading what is necessary at any given moment into memory. This method of lazy evaluation is beneficial in applications where large volumes of data are handled, but only a small amount at a time needs to be processed, thus reducing the overall memory footprint.
Consider an application that needs to process a large dataset of user records, such as calculating the average age of users. Instead of loading all records into a list (which could consume a significant amount of memory), a generator can process one record at a time.
def process_records(file_name):
"""Generator that yields user ages from a file one at a time."""
with open(file_name, 'r') as file:
for line in file:
user_data = line.strip().split(',')
yield int(user_data[1])
def average_age(file_name):
"""Calculate the average age from user records."""
total_age = 0
count = 0
for age in process_records(file_name):
total_age += age
count += 1
return total_age / count if count else 0
print("Average Age:", average_age('user_data.csv'))In this example, the process_records() generator function reads from a file one line at a time, converts the relevant data into an integer, and yields it. This means only one line’s worth of data is held in memory at any time, minimizing memory use. The average_age() function consumes the generator, accumulating total age and count without ever needing the entire dataset in memory at once.
Thus, using the lazy evaluation approach, we can conserve memory and enhance the responsiveness and scalability of their applications.
Circular references occur when two or more objects reference each other. This can happen subtly with structures like lists, dictionaries, or even more complex class definitions where instances hold references to each other, creating a loop.
As we saw in the fundamentals of memory management, Python has an additional garbage collector to detect and clean up circular references. However, relying on this mechanism can lead to increased memory usage and inefficiencies:
Consider a typical use case in a tree-like data structure where each node might keep a reference to its children and optionally to its parent. This parent-child linkage can easily create circular references.
class TreeNode:
def __init__(self, value, parent=None):
self.value = value
self.parent = parent
self.children = []
def add_child(self, child):
child.parent = self # Set parent reference
self.children.append(child)
root = TreeNode("root")
child = TreeNode("child1", root)
root.add_child(child)In this example, the root references the child through its children list, and the child references the root through its parent attribute. This setup can create a circular reference without any further intervention.
Weak references are one effective way to break or prevent circular references without redesigning the entire data structure.
Python’s weakref module allows a reference to an object that does not increase its reference count. This weak reference does not prevent the referenced object from being garbage collected, preventing memory leaks associated with circular references.
Here’s how we can modify the earlier class to use weak references:
import weakref
class TreeNode:
def __init__(self, value, parent=None):
self.value = value
self.parent = weakref.ref(parent) if parent else None
self.children = []
def add_child(self, child):
child.parent = weakref.ref(self)
self.children.append(child)
root = TreeNode("root")
child = TreeNode("child1", root)
root.add_child(child)In this class, the parent attribute is now a weak reference to the parent node. This means the parent node can be garbage collected even if the child node still exists, as long as there are no other strong references to the parent.
This approach efficiently prevents the memory leak issues typically associated with circular references in such structures.
This article introduced the fundamentals of memory management in Python and presented five advanced techniques for writing memory-efficient classes, along with practical examples and memory comparisons. We hope you adopt these techniques and best practices in your projects to build scalable and efficient applications.
We encourage you to check out our Python Programming track, which covers software engineering principles and object-oriented programming, including writing efficient Python code.
Learn more about Python with these courses!
Course
Course
Course
blog
Kurtis Pykes
12 min
blog
Javier Canales Luna
13 min
Tutorial
Oluseye Jeremiah
Tutorial
Théo Vanderheyden
Tutorial
Bex Tuychiev
Tutorial
François Aubry


