


Curso
Introdução ao Python
4 h
6.9M
Se você escrever classes eficientes em termos de memória em Python, será necessário desenvolver aplicativos robustos com bom desempenho sob várias restrições do sistema. O uso eficiente da memória acelera o tempo de execução do aplicativo e aumenta a escalabilidade ao consumir menos recursos, o que é especialmente importante em ambientes com disponibilidade limitada de memória.
Neste artigo, apresentarei a você os fundamentos do gerenciamento de memória em Python e apresentarei diferentes técnicas práticas para escrever classes eficientes em termos de memória. Quer você esteja criando sistemas complexos ou scripts simples, esses insights o ajudarão a escrever um código Python mais limpo e eficiente.
O sistema de gerenciamento de memória do Python é sofisticado e foi projetado para simplificar o desenvolvimento, lidando com a complexidade das operações de memória. Esse sistema é necessário para garantir que os aplicativos Python sejam executados com eficiência.
O heap privado é o núcleo do gerenciamento de memória do Python. É onde todos os objetos e estruturas de dados do Python são armazenados. Os programadores não podem acessar esse heap privado diretamente; em vez disso, eles interagem com os objetos por meio do sistema de gerenciamento de memória do Python.
O sistema de gerenciamento de memória usa:
O Python emprega uma abordagem dupla para a coleta de lixo:
Compreender e otimizar o uso da memória é fundamental para manter o desempenho dos aplicativos.
O Python oferece várias ferramentas para criação de perfil de memória, que fornecem insights além da depuração padrão, ajudando os desenvolvedores a identificar e resolver ineficiências de memória:
Usaremos a biblioteca pympler neste tutorial, e você pode instalá-la usando o gerenciador de pacotes pip em seu terminal:
pip install pymplerVocê pode ler mais sobre a criação de perfil de memória em nosso tutorial - Introdução à criação de perfil de memória em Python.Introdução à criação de perfis de memória em Python.
Agora que você entendeu os conceitos básicos do gerenciamento de memória em Python, vamos examinar algumas técnicas avançadas para escrever classes eficientes em termos de memória.
__slots__No Python, cada instância de classe tem um dicionário chamado __dict__ para armazenar variáveis de instância. Embora isso permita a atribuição dinâmica de novas variáveis, pode levar a uma sobrecarga significativa de memória, especialmente ao criar muitas instâncias de classe. Ao definir __slots__, você diz ao Python para alocar espaço para um conjunto fixo de atributos, eliminando a necessidade do dicionário dinâmico.
Usar __slots__ tem dois benefícios principais:
__slots__ é mais rápido do que por meio de um dicionário, devido à pesquisa direta de atributos, que ignora as operações de tabela de hash envolvidas no acesso ao dicionário.Vamos considerar uma classe simples que representa um ponto em um espaço bidimensional:
class PointWithoutSlots:
def __init__(self, x, y):
self.x = x
self.y = y
class PointWithSlots:
__slots__ = ('x', 'y')
def __init__(self, x, y):
self.x = x
self.y = yNa classe PointWithoutSlots cada instância tem um __dict__ para armazenar x e y enquanto a classe PointWithSlots não, o que resulta em menos memória usada por instância.
Para ilustrar a diferença no uso da memória, vamos criar mil pontos e medir a memória total usada usando o pacote pympler pacote:
from pympler import asizeof
points_without_slots = [PointWithoutSlots(i, i) for i in range(1000)]
points_with_slots = [PointWithSlots(i, i) for i in range(1000)]
print("Total memory (without __slots__):", asizeof.asizeof(points_without_slots))
print("Total memory (with __slots__):", asizeof.asizeof(points_with_slots))A saída que vemos é:
Comparação de memória com e sem slots
O resultado normalmente mostra que a instância de PointWithSlots consome menos memória do que PointWithoutSlotsdemonstrando a eficácia de __slots__ na redução do overhead de memória por instância.
__slots__Embora __slots__ sejam benéficos para a otimização da memória, eles têm certas limitações:
__slots__ for definido, você não poderá adicionar dinamicamente novos atributos às instâncias.__slots__ for herdadaa subclasse também deverá definir __slots__ para continuar se beneficiando da otimização da memória, o que pode complicar o design da classe . Apesar dessas limitações, o uso do __slots__ é uma ferramenta poderosa para desenvolvedores que desejam otimizar o uso da memória em aplicativos Python, especialmente em ambientes com restrições rigorosas de memória ou onde o número de instâncias é muito alto.
Os padrões de design com eficiência de memória são soluções arquitetônicas que ajudam a otimizar o uso e o gerenciamento da memória nos aplicativos Python.
Dois padrões particularmente eficazes para a eficiência de memória no design de classes são os padrões Flyweight e Singleton. Quando implementados corretamente em cenários que envolvem várias instâncias de classes ou dados compartilhados, esses padrões podem reduzir drasticamente o consumo de memória.
O padrão de design Flyweight funciona compartilhando partes comuns do estado entre vários objetos em vez de manter todos os dados em cada objeto, reduzindo significativamente o espaço total de memória.
Considere uma classe que representa círculos gráficos em um aplicativo de desenho em que cada círculo tem uma cor, um raio e coordenadas. Usando o padrão Flyweight, a cor e o raio, que provavelmente são compartilhados por muitos círculos, podem ser armazenados em objetos compartilhados:
class Circle:
# Flyweight object
def __init__(self, color):
self.color = color
def draw(self, radius, x, y):
print(f"Drawing a {self.color} circle with radius {radius} at ({x},{y})")
class CircleFactory:
# Factory to manage Flyweight objects
_circles = {}
@classmethod
def get_circle(cls, color):
if not cls._circles.get(color):
cls._circles[color] = Circle(color)
return cls._circles[color]Neste exemplo, várias instâncias de círculo compartilham o objeto Circle do objeto CircleFactory com base na cor, garantindo que a memória seja usada de forma mais eficiente ao armazenar os dados de cor uma vez.
Vamos usar essa classe para criar instâncias e entender como a memória é salva.
import sys
factory = CircleFactory()
circle1 = factory.get_circle("Red")
circle2 = factory.get_circle("Red")
circle3 = factory.get_circle("Blue")
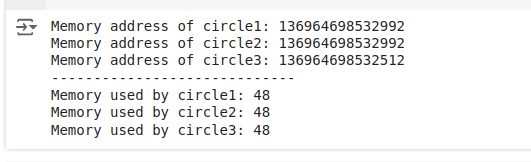
print("Memory address of circle1:", id(circle1))
print("Memory address of circle2:", id(circle2))
print("Memory address of circle3:", id(circle3))
print ("-----------------------------")
print("Memory used by circle1:", sys.getsizeof(circle1))
print("Memory used by circle2:", sys.getsizeof(circle2))
print("Memory used by circle3:", sys.getsizeof(circle3))A saída que vemos é:
Uso de memória para o padrão de design flyweight
Podemos ver que circle1 e circle2 têm o mesmo endereço de memória, o que significa que eles são de fato o mesmo objeto (compartilhando a mesma instância para a cor "Red"). circle3 tem um endereço de memória diferente porque representa um círculo com uma cor diferente ("Azul").
circle1 e circle2 sendo a mesma instância demonstra que o CircleFactory compartilhou com sucesso a instânciaCircle entre esses dois. É aqui que entra a eficiência da memória: se você tivesse mil círculos vermelhos em seu aplicativo usando o padrão Flyweight, todos eles compartilhariam uma única instância de Circle para a cor, em vez de cada um ter sua própria instância deCircle separada , economizando assim uma quantidade significativa de memória.
O padrão Singleton garante que uma classe tenha apenas uma instância e fornece um ponto de acesso global a ela. Esse padrão é útil para gerenciar configurações ou recursos compartilhados em um aplicativo, reduzindo a sobrecarga de memória ao não replicar recursos compartilhados ou dados de configuração em vários locais.
Considere o seguinte Database classe:
class Database:
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super(Database, cls).__new__(cls)
# Initialize any attributes of the instance here
return cls._instance
def connect(self):
# method to simulate database connection
return "Connection established"Nessa implementação, o Database garante que, não importa quantas vezes ele seja instanciado, apenas uma instância compartilhada será usada, conservando a memória ao evitar vários objetos idênticos.
Você pode verificar isso com o código a seguir:
db1 = Database()
print(db1.connect())
db2 = Database()
print(db1 is db2) O resultado é o seguinte:
Criação de instância para o padrão de design singleton
A saída "True" indica que db1 e db2 referem-se à mesma instância.
Esses padrões demonstram como um design cuidadoso pode melhorar significativamente a eficiência da memória. Ao escolher e implementar padrões de design apropriados, os desenvolvedores podem otimizar seus aplicativos Python para que sejam mais enxutos e tenham melhor desempenho.
Selecionando o tipo de dados tipo de dados interno apropriado em Python pode afetar significativamente a eficiência da memória. Os tipos incorporados são otimizados para desempenho e uso de memória devido às suas implementações internas no interpretador Python.
Por exemplo, devido às suas propriedades exclusivas, as tuplas e os conjuntos podem ser opções mais eficientes em termos de memória para casos de uso específicos do que as listas e os dicionários.
As tuplas geralmente usam menos memória do que as listas porque têm um tamanho fixo e não podem ser alteradas depois de criadas, permitindo que os mecanismos internos do Python otimizem seu armazenamento na memória. Para classes projetadas para lidar com dados que não precisam ser modificados após a criação, as tuplas são uma excelente opção.
Considere duas classes simples de polígono que usam tuplas e listas para armazenar valores:
class PolygonWithTuple:
def __init__(self, points):
self.points = tuple(points) # Storing points as a tuple
def display_points(self):
return self.points
class PolygonWithList:
def __init__(self, points):
self.points = list(points) # Storing points as a list
def display_points(self):
return self.pointsPodemos criar instâncias de ambas as classes para comparar o uso da memória:
from pympler import asizeof
points = [(1, 2), (3, 4), (5, 6), (7, 8)]
# Creating instances of each class
polygon_tuple = PolygonWithTuple(points)
polygon_list = PolygonWithList(points)
# Memory usage comparison using pympler
print("Total memory used by Polygon with Tuple:", asizeof.asizeof(polygon_tuple))
print("Total memory used by Polygon with List:", asizeof.asizeof(polygon_list))O resultado que você obtém é:
Comparação de memória para tuplas e listas
Esse resultado demonstra que a tupla normalmente usa menos memória do que a lista, o que torna a classe PolygonWithTuple mais eficiente em termos de memória para armazenar dados fixos e imutáveis, como coordenadas geométricas.
Em Python, geradores são uma ferramenta poderosa para gerenciar a memória de forma eficiente, especialmente quando você trabalha com grandes conjuntos de dados.
Os geradores permitem que os dados sejam processados um item de cada vez, carregando na memória apenas o que for necessário em um determinado momento. Esse método de avaliação preguiçosa é benéfico em aplicativos em que grandes volumes de dados são manipulados, mas apenas uma pequena quantidade de cada vez precisa ser processada, reduzindo assim o espaço total de memória.
Considere um aplicativo que precise processar um grande conjunto de dados de registros de usuários, como o cálculo da idade média dos usuários. Em vez de carregar todos os registros em uma lista (o que poderia consumir uma quantidade significativa de memória), um gerador pode processar um registro por vez.
def process_records(file_name):
"""Generator that yields user ages from a file one at a time."""
with open(file_name, 'r') as file:
for line in file:
user_data = line.strip().split(',')
yield int(user_data[1])
def average_age(file_name):
"""Calculate the average age from user records."""
total_age = 0
count = 0
for age in process_records(file_name):
total_age += age
count += 1
return total_age / count if count else 0
print("Average Age:", average_age('user_data.csv'))Neste exemplo, a função geradoraprocess_records() lê de um arquivo uma linha de cada vez, converte os dados relevantes em um número inteiro e os produz. Isso significa que apenas uma linha de dados é mantida na memória a qualquer momento, minimizando o uso da memória. A função average_age() consome o gerador, acumulando a idade total e a contagem sem nunca precisar de todo o conjunto de dados na memória de uma só vez.
Assim, usando a abordagem de avaliação preguiçosa, podemos conservar a memória e aumentar a capacidade de resposta e o dimensionamento dos aplicativos.
As referências circulares ocorrem quando dois ou mais objetos fazem referência uns aos outros. Isso pode acontecer sutilmente com estruturas como listas, dicionários ou até mesmo definições de classes mais complexas, em que as instâncias mantêm referências umas às outras, criando um loop.
Como vimos nos fundamentos do gerenciamento de memória, o Python tem um coletor de lixo adicional para detectar e limpar referências circulares. No entanto, confiar nesse mecanismo pode levar ao aumento do uso de memória e a ineficiências:
Considere um caso de uso típico em uma estrutura de dados em forma de árvore em que cada nó pode manter uma referência a seus filhos e, opcionalmente, a seu pai. Essa vinculação pai-filho pode facilmente criar referências circulares.
class TreeNode:
def __init__(self, value, parent=None):
self.value = value
self.parent = parent
self.children = []
def add_child(self, child):
child.parent = self # Set parent reference
self.children.append(child)
root = TreeNode("root")
child = TreeNode("child1", root)
root.add_child(child)Neste exemplo, o root faz referência aochild por meio de sua lista children, e o child faz referência ao root por meio de seu atributoparent. Essa configuração pode criar uma referência circular sem nenhuma intervenção adicional.
As referências fracas são uma maneira eficaz de interromper ou evitar referências circulares sem redesenhar toda a estrutura de dados.
O móduloweakref do Python permite que você faça uma referência a um objeto que não aumente sua contagem de referências. Essa referência fraca não impede que o objeto referenciado seja coletado pelo lixo, evitando vazamentos de memória associados a referências circulares.
Veja como podemos modificar a classe anterior para usar referências fracas:
import weakref
class TreeNode:
def __init__(self, value, parent=None):
self.value = value
self.parent = weakref.ref(parent) if parent else None
self.children = []
def add_child(self, child):
child.parent = weakref.ref(self)
self.children.append(child)
root = TreeNode("root")
child = TreeNode("child1", root)
root.add_child(child)Nessa classe, o atributo pai é agora uma referência fraca ao nó pai. Isso significa que o nó pai pode ser coletado do lixo mesmo que o nó filho ainda exista, desde que não haja outras referências fortes ao pai.
Essa abordagem evita com eficiência os problemas de vazamento de memória normalmente associados a referências circulares em tais estruturas.
Este artigo introduziu os fundamentos do gerenciamento de memória em Python e apresentou cinco técnicas avançadas para escrever classes eficientes em termos de memória, juntamente com exemplos práticos e comparações de memória. Esperamos que você adote essas técnicas e práticas recomendadas em seus projetos para criar aplicativos dimensionáveis e eficientes.
Recomendamos que você confira o nosso Programa Pythonque abrange princípios de engenharia de software e programação orientada a objetos, incluindo escrever código Python eficiente.
Aprenda mais sobre Python com estes cursos!
Curso
Curso
Curso