
Cursus
Ingénieur de données associé en SQL
30 h
Lorsque j'ai commencé à travailler avec des ensembles de données volumineux, j'ai rapidement rencontré un problème familier : des données fragmentées dispersées dans différents systèmes. Il n'existait aucun moyen simple d'analyser l'ensemble de ces données. J'avais besoin de comparer les tendances au fil du temps, entre les régions et par produit, mais les bases de données traditionnelles ne permettaient pas d'effectuer ce type d'analyse. C'est à ce moment-là que j'ai entendu parler des cubes de données et que j'ai commencé à étudier le concept.
Dans ce guide, je vais vous expliquer les principes fondamentaux, la structure et l'importance des cubes de données. Pour obtenir des informations complémentaires, je vous recommande de suivre nos cours « Prise de décision basée sur les données dans SQL » et « Conception de bases de données ».
Je vais définir l'idée et la replacer dans son contexte historique :
Les cubes de données sont des outils permettant de gérer des données multidimensionnelles dans le cadre de l'analyse de données, par exemple dans le domaine de l'intelligence économique. Contrairement aux structures de données plates traditionnelles, telles que les feuilles de calcul ou les bases de données relationnelles, les cubes de données permettent une exploration plus efficace d'ensembles de données complexes en trois dimensions ou plus.
Tout cela n'est souvent pas particulièrement évident pour l'analyste, je vais donc illustrer la notion de cube de données à l'aide d'un exemple. Je vais m'exprimer en tant qu'analyste BI :
Supposons que vous souhaitiez suivre les ventes d'un magasin de détail. Les données disponibles peuvent inclure le chiffre d'affaires et les quantités vendues, classées par critères tels que la période, le type de produit et l'emplacement du magasin. Un cube de données, qui est en réalité davantage un modèle logique ou conceptuel, organise vos données de manière à ce que l'outil BI que vous utilisez puisse rapidement générer des visualisations de n'importe quelle combinaison des dimensions que j'ai mentionnées. Par exemple, il peut être utilisé pour afficher le total des ventes par produit dans tous les magasins au cours d'une année spécifique.
Maintenant, imaginez que vous regardez un tableur avec les colonnes « Temps (mois) », « Type de produit », « Emplacement du magasin » et « Chiffre d'affaires ». Cette feuille de calcul ne représente pas un cube de données dans sa structure, mais elle pourrait être utilisée pour aider à créer des cubes de données ou à remplir un cube de données, où chaque ligne devient une cellule formée par la combinaison unique de l'heure, du type de produit et de l'emplacement du magasin, avec le chiffre d'affaires comme valeur à l'intérieur de cette cellule.
|
Mois |
Type de produit |
Emplacement du magasin |
Chiffre d'affaires |
|
janvier |
Électronique |
Chicago |
10 000 |
|
janvier |
Vêtements |
Chicago |
5 000 |
|
janvier |
Furniture |
New York |
12 000 |
|
février |
Électronique |
Los Angeles |
8 000 |
|
février |
Vêtements |
Chicago |
6 000 |
|
Mars |
Électronique |
New York |
9 000 |
|
Mars |
Furniture |
Los Angeles |
11 000 |
Dans un cube, ces éléments deviennent des dimensions:. En d'autres termes, chaque combinaison unique de temps × produit × emplacement renvoie à unecellule d' contenant le chiffre d'affaires ou la quantité, qui constituera un agrégat préenregistré et rapidement récupérable (nous y reviendrons plus tard).
Les cubes de données ont commencé à se populariser dans les années 1990, lors de l'essor du stockage de données et de l'OLAP (traitement analytique en ligne). À l'époque, les entreprises avaient besoin de moyens plus rapides et plus interactifs pour analyser des volumes de données toujours plus importants. Les cubes de données ont répondu à ce besoin en organisant les informations dans des vues flexibles et multidimensionnelles qui ont considérablement facilité l'identification des tendances et des modèles.
À mesure que la technologie a évolué, les cubes de données ont également évolué. Ils se sont adaptés pour traiter des ensembles de données plus volumineux et plus complexes grâce à l'amélioration de la puissance de calcul, du stockage et du traitement parallèle. Aujourd'hui, les cubes de données ne sont plus limités aux systèmes traditionnels sur site. Ils sont désormais largement intégrés dans les plateformes d'analyse basées sur le cloud. Cela permet un traitement en temps réel et des informations évolutives à la demande pour répondre aux besoins actuels en matière de veille stratégique.
Il est essentiel de décomposer les composants principaux des cubes de données afin de bien comprendre leur fonctionnement. Vous trouverez ci-dessous des exemples de chaque composant.
Les dimensions sont les attributs catégoriels qui définissent la structure d'un cube de données. Vous pouvez utiliser les dimensions pour classer et filtrer vos données en fonction de différents segments.
Voici quelques exemples courants de dimensions utilisées dans les cubes de données :
Les mesures sont les points de données quantitatives stockés dans le cube afin de fournir des informations. Vous pouvez agréger ces valeurs numériques à l'aide d'opérations mathématiques telles que la somme, la moyenne, le nombre ou le maximum.
Voici quelques exemples de mesures que vous pourriez rencontrer :
Les hiérarchies organisent les dimensions en niveaux qui facilitent l'analyse avancée grâce à des opérations telles que l'exploration et la synthèse. En structurant les dimensions de manière hiérarchique, vous pouvez naviguer depuis des résumés simples vers des vues plus détaillées des données. Voici quelques exemples de hiérarchies :
Examinons comment un cube de données est construit et pourquoi sa structure facilite considérablement l'analyse.
Imaginez un cube de données comme une feuille de calcul en 3D où chaque axe représente une manière différente d'examiner vos données, telle que l'heure, le lieu ou le type de produit. Cette configuration vous permet d'explorer des ensembles de données complexes sous plusieurs angles à la fois.
Par exemple, imaginez que vous analysez les ventes au détail. Votre cube peut contenir :
Les avantages de la modélisation multidimensionnelle sont les suivants.
Je vais visualiser le cube de données afin de vous aider à comprendre sa structure et à interpréter les données qu'il contient. Vous trouverez ci-dessous une représentation simplifiée d'un cube de données 3D :
Dans le schéma ci-dessous :
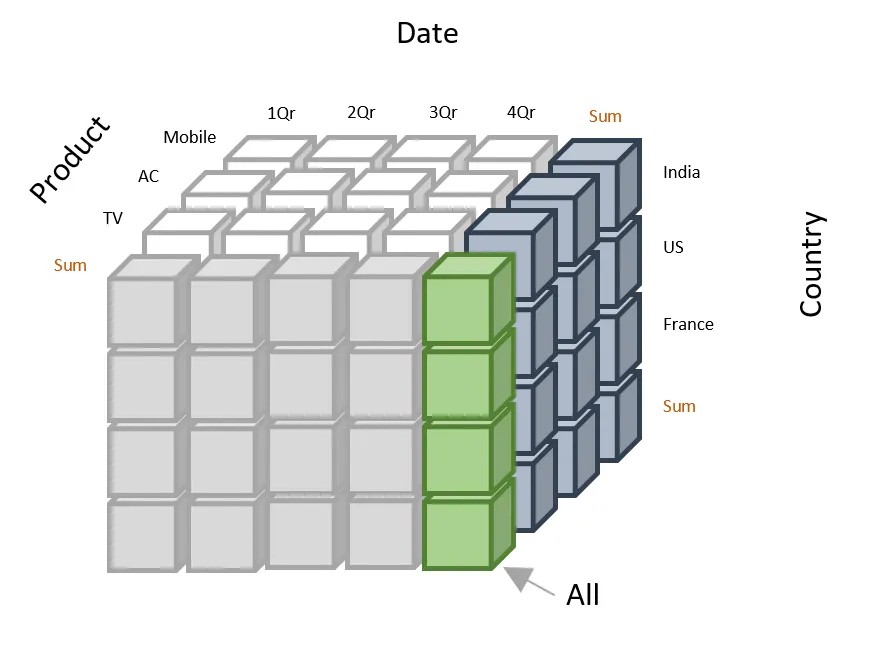
Exemple de représentation d'un cube de données. Source : Maîtriser les opérations de revenus
Vous pouvez interpréter le cube de données ci-dessus comme suit :
Voici les raisons pour lesquelles les cubes de données sont utilisés :
Comme je l'ai mentionné précédemment, les cubes de données permettent de donner un sens à des informations complexes en les classant en couches claires. Cela facilite l'accès aux données et leur analyse à partir des bases de données.
Les cubes de données sont conçus pour répondre rapidement aux questions, car ils stockent des résumés précalculés et utilisent un indexage avancé. Cette structure permet une navigation rapide à travers les dimensions et les mesures. Par exemple, une requête visant à trouver les ventes trimestrielles de tous les magasins est exécutée presque instantanément, car le cube de données contient déjà ces agrégats précalculés. J'ai commencé à en parler tout à l'heure, et c'est vraiment l'un des points essentiels, à mon avis.
Les cubes de données permettent également l'exploration interactive des données grâce à des opérations telles que le découpage et le segmentage. Le découpage vous permet de vous concentrer sur une dimension spécifique, comme l'examen des ventes d'un seul mois. En revanche, le découpage en cubes vous permet de visualiser simultanément des données sous plusieurs dimensions, telles que les ventes par catégorie de produits à New York au mois de janvier.
Par exemple, vous pouvez commencer une analyse avec les ventes annuelles, approfondir votre analyse en examinant les performances trimestrielles, puis segmenter par région pour une catégorie de produits spécifique.
Les cubes de données sont conçus pour évoluer en fonction de vos besoins. Ils gèrent efficacement les grands ensembles de données, en particulier lorsqu'ils sont associés à des outils modernes tels que le stockage dans le cloud ou les plateformes de mégadonnées. Vous pouvez facilement importer de nouvelles données, ajouter des dimensions personnalisées et configurer des mesures qui correspondent exactement aux besoins de votre entreprise en matière de suivi.
Imaginez que vous dirigez une boutique en ligne en pleine expansion. À mesure que vous élargissez votre gamme de produits, que vous vous implantez dans de nouvelles régions ou que vous ajoutez des données plus récentes, votre cube de données peut évoluer avec vous, sans perturber les rapports et les informations sur lesquels vous vous appuyez déjà.
Bien que les cubes de données soient utiles pour analyser vos ensembles de données, ils présentent différents défis. Vous trouverez ci-dessous quelques-uns des problèmes connus.
La création d'un cube de données n'est pas seulement une tâche technique, elle nécessite également une bonne compréhension de votre activité. Les complexités peuvent inclure les éléments suivants :
Le travail avec des cubes de données présente certains défis, en particulier lorsque vos données augmentent. Il s'agit notamment des éléments suivants :
Lorsque vous intégrez des cubes de données à des systèmes existants, vous pouvez rencontrer les difficultés suivantes :
Les cubes de données constituent un excellent moyen d'organiser et de comprendre des données complexes sous différents angles. Ils vous aident à repérer plus rapidement les tendances, à exécuter des requêtes plus efficacement et à explorer les informations en les découpant selon vos besoins.
Si vous souhaitez approfondir vos compétences, je vous recommande de suivre notre cours Concepts de l'entrepôt de données afin d'apprendre les propriétés des entrepôts de données et comment intégrer des cubes de données à des systèmes existants, si votre rôle l'exige. Notre cours « Comprendre l'ingénierie des données » vous aidera également à acquérir des compétences en matière de maintenance et de traitement des données.
Apprenez avec DataCamp
Cursus
Cours
Cours