
Lernpfad
Associate Data Engineer in SQL
30 Std.
Als ich zum ersten Mal mit großen Datensätzen gearbeitet habe, bin ich schnell auf ein bekanntes Problem gestoßen: Daten waren überall verstreut. Es war echt nicht einfach, alles zusammen zu analysieren. Ich musste Trends über Zeiträume, Regionen und Produkte hinweg vergleichen, aber mit herkömmlichen Datenbanken ging das nicht. Da hab ich von Datenwürfeln gehört und angefangen, mich damit zu beschäftigen.
In diesem Leitfaden erkläre ich dir die Grundlagen, den Aufbau und die Bedeutung von Datenwürfeln. Als zusätzliches Material empfehle ich dir unsere Kurse „Datengesteuerte Entscheidungsfindung in SQL “ und „Datenbankdesign “.
Ich werde die Idee erklären und in den historischen Kontext setzen:
Datenwürfel sind Tools zum Verwalten von multidimensionalen Daten in der Datenanalyse, zum Beispiel in der Business Intelligence. Anders als bei den üblichen flachen Datenstrukturen, wie Tabellenkalkulationen oder relationalen Datenbanken, kann man mit Datenwürfeln komplexe Datensätze in drei oder mehr Dimensionen besser durchsuchen.
All das ist für den Analysten oft nicht so klar, also lass mich das Konzept eines Datenwürfels anhand eines Beispiels erklären. Ich sag's mal aus der Sicht eines BI-Analysten:
Angenommen, du möchtest die Verkäufe in einem Einzelhandelsgeschäft verfolgen. Die verfügbaren Daten können zum Beispiel Umsatz und Verkaufszahlen sein, sortiert nach Zeit, Produkttyp und Ladenstandort. Ein Datenwürfel, der eigentlich eher ein logisches oder konzeptionelles Modell ist, sortiert deine Daten so, dass jedes BI-Tool, das du benutzt, schnell Visualisierungen von beliebigen Kombinationen der von mir genannten Dimensionen erstellen kann. Du kannst damit zum Beispiel die Gesamtverkäufe pro Produkt in allen Läden in einem bestimmten Jahr anschauen.
Stell dir vor, du hast eine Tabelle mit den Spalten „Zeit (Monate)“, „Produkttyp“, „Filialstandort“ und „Umsatz“. Diese Tabelle ist kein Datenwürfel, aber man kann sie zum Erstellen von „ “ oder zum Füllen eines Datenwürfels verwenden. Dabei wird jede Zeile zu einer Zelle, die aus der einzigartigen Kombination von Zeit, Produkttyp und Filialstandort gebildet wird, wobei der Umsatz der Wert in dieser Zelle ist.
|
Monat |
Produkttyp |
Ladenstandort |
Einnahmen |
|
Januar |
Elektronik |
Chicago |
10.000 |
|
Januar |
Kleidung |
Chicago |
5.000 |
|
Januar |
Möbel |
New York |
12.000 |
|
Februar |
Elektronik |
Los Angeles |
8.000 |
|
Februar |
Kleidung |
Chicago |
6.000 |
|
März |
Elektronik |
New York |
9.000 |
|
März |
Möbel |
Los Angeles |
11.000 |
In einem Würfel werden das die Dimensionen. Das heißt, jede einzigartige Kombination aus Zeit × Produkt × Standort zeigt auf eineZelle „ “, die den Umsatz oder die Menge enthält, und das wird ein Aggregat, das vorab gespeichert und schnell abgerufen werden kann (mehr dazu später).
Datenwürfel wurden in den 1990er Jahren populär, als Data Warehousing und OLAP (Online Analytical Processing) aufkamen . Damals brauchten Firmen schnellere und interaktivere Wege, um immer mehr Daten zu analysieren. Datenwürfel haben das Problem gelöst, indem sie Infos in flexible, mehrdimensionale Ansichten sortiert haben, die das Erkennen von Trends und Mustern echt vereinfacht haben.
Mit der Technologie haben sich auch die Datenwürfel weiterentwickelt. Dank besserer Rechenleistung, Speicherplatz und Parallelverarbeitung können sie jetzt mit größeren und komplexeren Datensätzen umgehen. Heutzutage sind Datenwürfel nicht mehr nur auf die alten lokalen Systeme beschränkt. Sie sind jetzt weit in Cloud-basierte Analyseplattformen integriert. Das macht Echtzeitverarbeitung und skalierbare, bedarfsgerechte Einblicke für moderne Business-Intelligence-Anforderungen möglich.
Es ist wichtig, die Kernkomponenten von Datenwürfeln zu zerlegen, um ihre Funktionsweise vollständig zu verstehen. Hier sind ein paar Beispiele für die einzelnen Teile.
Dimensionen sind die kategorialen Attribute, die die Struktur eines Datenwürfels festlegen. Du kannst die Dimensionen nutzen, um deine Daten nach verschiedenen Segmenten zu sortieren und zu filtern.
Hier sind ein paar typische Beispiele für Dimensionen, die in Datenwürfeln verwendet werden:
Maßnahmen sind die quantitativen Datenpunkte, die im Cube gespeichert sind, um Einblicke zu geben. Du kannst diese Zahlenwerte mit mathematischen Operationen wie Summe, Durchschnitt, Anzahl oder Maximum zusammenfassen.
Hier sind ein paar Beispiele für Maßnahmen, die dir begegnen könnten
Hierarchien ordnen Dimensionen in Ebenen, die durch Funktionen wie Drilldown und Rollup eine erweiterte Analyse ermöglichen. Durch die hierarchische Strukturierung von Dimensionen kannst du von einfachen Zusammenfassungen zu detaillierteren Datenansichten navigieren. Hier sind ein paar Beispiele für Hierarchien:
Schauen wir mal, wie ein Datenwürfel aufgebaut ist und warum seine Struktur die Analyse so viel einfacher macht.
Stell dir einen Datenwürfel wie eine 3D-Tabelle vor, wo jede Achse eine andere Art darstellt, deine Daten zu betrachten, wie zum Beispiel Zeit, Ort oder Produkttyp. Mit dieser Konfiguration kannst du komplexe Datensätze aus mehreren Blickwinkeln gleichzeitig erkunden.
Stell dir zum Beispiel vor, du analysierst Einzelhandelsumsätze. Dein Würfel könnte Folgendes enthalten:
Die Vorteile der multidimensionalen Modellierung sind unter anderem:
Ich werde den Datenwürfel visualisieren, damit du seine Struktur und die Interpretation der darin enthaltenen Daten besser verstehst. Hier ist eine einfache Darstellung eines 3D-Datenwürfels:
In der folgenden Abbildung:
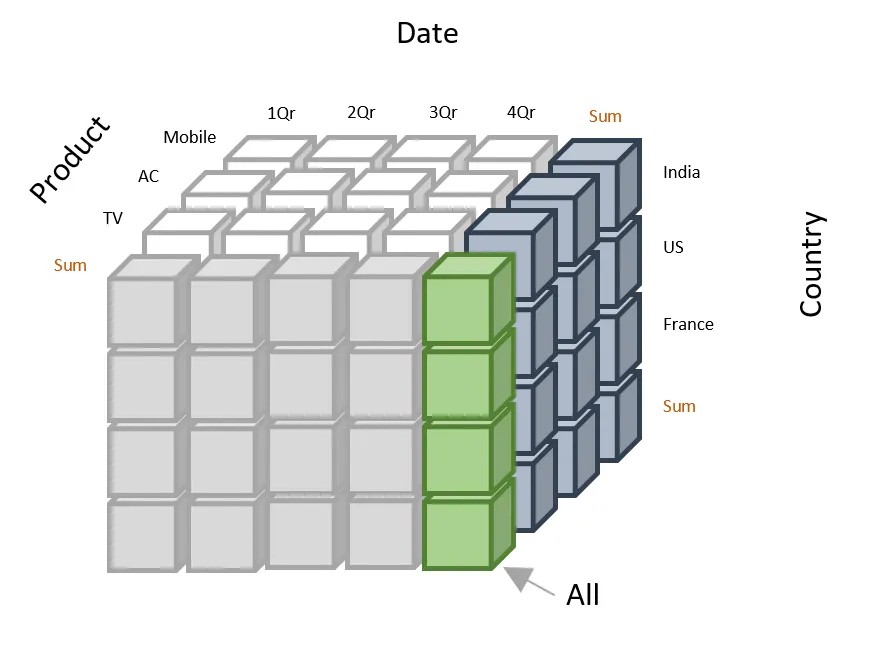
Beispiel für die Darstellung eines Datenwürfels. Quelle: Revenue Operations meistern
Du kannst den obigen Datenwürfel so verstehen:
Hier sind ein paar Gründe, warum Datenwürfel verwendet werden:
Wie ich schon erwähnt habe, helfen Datenwürfel dabei, komplexe Infos zu verstehen, indem sie diese in übersichtliche Ebenen sortieren. Das macht es einfacher, auf Daten aus Datenbanken zuzugreifen und sie zu analysieren.
Datenwürfel sind so gemacht, dass sie Fragen schnell beantworten können, weil sie schon berechnete Zusammenfassungen speichern und eine coole Indexierung nutzen. Mit dieser Struktur kannst du schnell durch Dimensionen und Kennzahlen navigieren. Zum Beispiel wird eine Abfrage, um die Quartalsumsätze aller Filialen zu finden, fast sofort erledigt, weil der Datenwürfel diese vorab berechneten Aggregate schon hat. Ich hab das schon mal angesprochen, und meiner Meinung nach ist das echt einer der wichtigsten Punkte.
Datenwürfel machen auch interaktive Datenexploration durch Funktionen wie Slicing und Dicing möglich. Mit dem Slicing kannst du dich auf eine bestimmte Dimension konzentrieren, z. B. die Umsätze eines einzelnen Monats. Mit dem Dicing kannst du dagegen Daten aus mehreren Dimensionen gleichzeitig anschauen, zum Beispiel die Verkäufe nach Produktkategorie in New York im Januar.
Du kannst zum Beispiel eine Analyse mit den Jahresumsätzen starten, dann auf die Quartalsergebnisse schauen und dann nach Regionen für eine bestimmte Produktkategorie filtern.
Datenwürfel sind so gemacht, dass sie mit deinen Bedürfnissen mitwachsen. Sie können große Datensätze gut verarbeiten, vor allem zusammen mit modernen Tools wie Cloud-Speicher oder Big-Data-Plattformen. Du kannst ganz einfach neue Daten einbinden, benutzerdefinierte Dimensionen hinzufügen und Kennzahlen einrichten, die genau den Anforderungen deines Unternehmens entsprechen.
Stell dir vor, du hast einen schnell wachsenden Online-Shop. Wenn du dein Sortiment erweiterst, neue Regionen erschließt oder aktuellere Daten hinzufügst, kann dein Datenwürfel mitwachsen, ohne dass die Berichte und Erkenntnisse, auf die du dich bereits verlässt, durcheinander geraten.
Datenwürfel sind zwar super zum Analysieren deiner Datensätze, bringen aber auch ein paar Herausforderungen mit sich. Hier sind ein paar bekannte Probleme.
Einen Datenwürfel aufzubauen ist nicht nur eine technische Aufgabe, sondern erfordert auch ein gutes Verständnis deines Unternehmens. Die damit verbundenen Komplexitäten können Folgendes umfassen:
Die Arbeit mit Datenwürfeln bringt einige Herausforderungen mit sich, vor allem, wenn deine Datenmenge wächst. Dazu gehören:
Wenn du Datenwürfel in bestehende Systeme einbindest, kannst du auf folgende Probleme stoßen:
Datenwürfel sind super, um komplexe Daten aus verschiedenen Blickwinkeln zu organisieren und zu verstehen. Sie helfen dir, Muster schneller zu erkennen, Abfragen effizienter auszuführen und Informationen zu erkunden, indem du sie nach Belieben aufteilst.
Wenn du deine Fähigkeiten ausbauen möchtest, empfehle ich dir unseren Kurs „Data Warehousing Concepts“, in dem du mehr über die Eigenschaften von Data Warehouses und die Integration von Datenwürfeln in bestehende Systeme lernst, falls dies für deine Tätigkeit erforderlich ist. Unser Kurs „Data Engineering verstehen“ hilft dir auch dabei, deine Fähigkeiten in der Pflege und Verarbeitung von Daten zu verbessern.
Lerne mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
