
Programa
Engenheiro de dados associado em SQL
30 h
Quando comecei a trabalhar com grandes conjuntos de dados, logo me deparei com um problema bem conhecido: dados fragmentados espalhados por vários sistemas. Não tinha jeito fácil de analisar tudo junto. Eu precisava comparar tendências ao longo do tempo, entre regiões e por produto, mas os bancos de dados tradicionais não conseguiam lidar com essa análise. Foi aí que eu ouvi falar sobre cubos de dados e comecei a estudar o conceito.
Neste guia, vou explicar os fundamentos, a estrutura e a importância dos cubos de dados. Se você quiser mais informações, recomendo os nossos cursos Tomada de Decisão Baseada em Dados em SQL e Design de Banco de Dados.
Vou explicar a ideia e colocar no contexto histórico:
Cubos de dados são ferramentas para gerenciar dados multidimensionais em análises de dados, como em inteligência de negócios. Diferente das estruturas de dados planas tradicionais, como planilhas ou bancos de dados relacionais, os cubos de dados permitem uma exploração mais eficiente de conjuntos de dados complexos em três ou mais dimensões.
Muitas vezes, tudo isso não é muito claro para o analista, então vou explicar melhor a ideia de um cubo de dados com um exemplo. Vou falar como analista de BI:
Digamos que você queira acompanhar as vendas de uma loja de varejo. Os dados disponíveis podem incluir receita e quantidade vendida, organizados por coisas como tempo, tipo de produto e localização da loja. Um cubo de dados, que é mais um modelo lógico ou conceitual, organiza seus dados para que qualquer ferramenta de BI que você esteja usando possa gerar rapidamente visualizações de qualquer combinação das dimensões que mencionei. Por exemplo, dá pra ver o total de vendas por produto em todas as lojas num ano específico.
Agora, imagina que você está olhando uma planilha com as colunas “Tempo (meses)”, “Tipo de produto”, “Localização da loja” e “Receita”. Essa planilha não tem a estrutura de um cubo de dados, mas pode ser usada pra ajudar a criar um cubo de dados ou preencher um cubo de dados, onde cada linha vira uma célula formada pela combinação única de Tempo, Tipo de Produto e Localização da Loja, com a Receita como o valor dentro dessa célula.
|
Mês |
Tipo de produto |
Localização da loja |
Receita |
|
Janeiro |
Eletrônica |
Chicago |
10.000 |
|
Janeiro |
Roupas |
Chicago |
5.000 |
|
Janeiro |
Móveis |
Nova York |
12.000 |
|
fevereiro |
Eletrônica |
Los Angeles |
8.000 |
|
fevereiro |
Roupas |
Chicago |
6.000 |
|
Março |
Eletrônica |
Nova York |
9.000 |
|
Março |
Móveis |
Los Angeles |
11.000 |
Num cubo, isso vira dimensões. Ou seja, cada combinação única de tempo × produto × localização aponta para umacélula e e que contém receita ou quantidade, e isso vai ser um agregado que é pré-armazenado e recuperado rapidamente (mais sobre isso depois).
Os cubos de dados ficaram famosos nos anos 90, quando o armazenamento de dados e o OLAP (Processamento Analítico Online) começaram a crescer . Naquela época, as empresas precisavam de maneiras mais rápidas e interativas de analisar quantidades crescentes de dados. Os cubos de dados atenderam a essa necessidade organizando as informações em visualizações flexíveis e multidimensionais que facilitaram muito a identificação de tendências e padrões.
Conforme a tecnologia foi evoluindo, os cubos de dados também mudaram. Eles se adaptaram para lidar com conjuntos de dados maiores e mais complexos graças a melhorias na capacidade de computação, armazenamento e processamento paralelo. Hoje em dia, os cubos de dados não estão mais limitados aos sistemas tradicionais locais. Agora, eles estão bem integrados em plataformas de análise baseadas em nuvem. Isso dá suporte ao processamento em tempo real e insights escaláveis e sob demanda para as necessidades modernas de inteligência de negócios.
É importante dividir os componentes principais dos cubos de dados para entender como eles funcionam de verdade. Abaixo estão alguns exemplos de cada componente.
As dimensões são os atributos categóricos que definem a estrutura de um cubo de dados. Você pode usar as dimensões para categorizar e filtrar seus dados com base em diferentes segmentos.
Aqui estão alguns exemplos comuns de dimensões usadas em cubos de dados:
As medidas são os dados quantitativos guardados no cubo para dar uma ideia do que está rolando. Você pode juntar esses valores numéricos usando operações matemáticas, como soma, média, contagem ou máximo.
Aqui estão alguns exemplos de medidas que você pode encontrar
As hierarquias organizam as dimensões em níveis que ajudam a fornecer análises avançadas por meio de operações como detalhamento e agregação. Ao organizar as dimensões de forma hierárquica, você pode ir de resumos simples para visualizações de dados mais detalhadas. Exemplos de hierarquias podem incluir o seguinte:
Vamos ver como um cubo de dados é feito e por que a estrutura dele facilita tanto a análise.
Pense num cubo de dados como uma planilha 3D, onde cada eixo representa uma maneira diferente de ver seus dados, como tempo, localização ou tipo de produto. Essa configuração permite que você explore conjuntos de dados complexos de vários ângulos ao mesmo tempo.
Por exemplo, imagina que você está analisando vendas no varejo. Seu cubo pode ter:
As vantagens da modelagem multidimensional são as seguintes.
Vou visualizar o cubo de dados para ajudar você a entender sua estrutura e como interpretar os dados que ele contém. Abaixo tá uma representação simples de um cubo de dados 3D:
No diagrama abaixo:
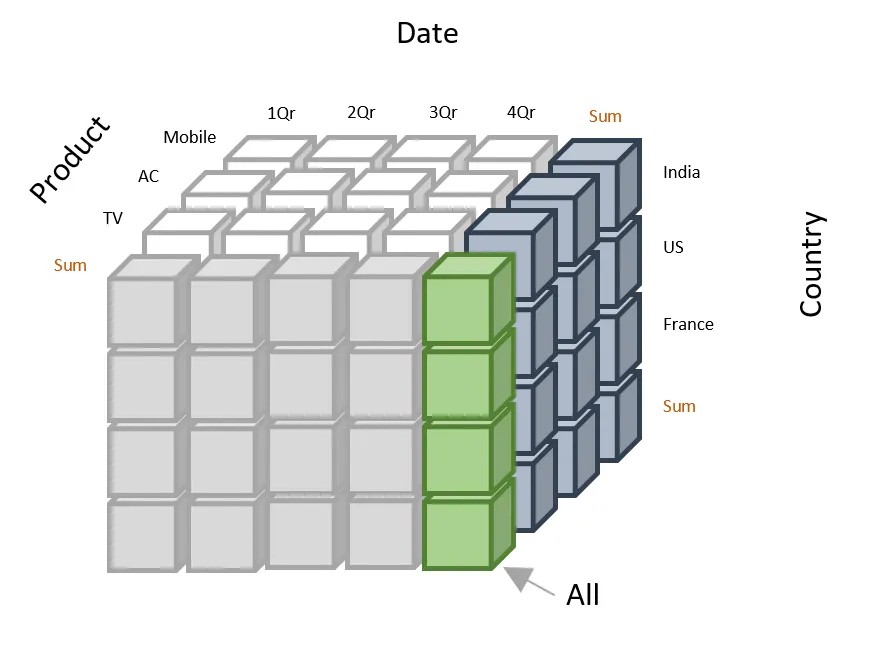
Exemplo de representação de cubo de dados. Fonte: Dominando as operações de receita
Você pode entender o cubo de dados acima assim:
Aqui estão alguns motivos pelos quais os cubos de dados são usados:
Como eu falei antes, os cubos de dados ajudam a entender informações complexas, organizando-as em camadas claras. Isso facilita o acesso e a análise dos dados dos bancos de dados.
Os cubos de dados são feitos pra responder perguntas rapidinho, porque eles guardam resumos já calculados e usam uma indexação avançada. Essa estrutura facilita a navegação rápida pelas dimensões e medidas. Por exemplo, uma consulta para encontrar as vendas trimestrais em todas as lojas é feita quase na hora, já que o cubo de dados já tem esses agregados pré-calculados. Eu já comecei a falar sobre isso antes, e, na minha opinião, é realmente um dos pontos principais.
Os cubos de dados também permitem a exploração interativa dos dados por meio de operações como divisão e segmentação. A divisão permite que você se concentre em uma dimensão específica, como analisar as vendas de apenas um mês. Já o dicing te deixa ver os dados em várias dimensões ao mesmo tempo, tipo vendas por categoria de produto em São Paulo durante janeiro.
Por exemplo, você pode começar uma análise com as vendas anuais, detalhar o desempenho trimestral e, em seguida, dividir por região para uma categoria específica de produto.
Os cubos de dados são feitos pra crescer junto com suas necessidades. Eles lidam bem com grandes conjuntos de dados, principalmente quando combinados com ferramentas modernas, como armazenamento em nuvem ou plataformas de big data. Você pode facilmente importar novos dados, adicionar dimensões personalizadas e configurar medidas que correspondam exatamente ao que sua empresa precisa acompanhar.
Imagina que você está administrando uma loja online que está crescendo rápido. À medida que você amplia sua linha de produtos, entra em novas regiões ou adiciona dados mais recentes, seu cubo de dados pode crescer junto com você, sem bagunçar os relatórios e insights nos quais você já confia.
Embora os cubos de dados sejam úteis para analisar seus conjuntos de dados, eles trazem alguns desafios. Abaixo estão alguns dos problemas conhecidos.
Criar um cubo de dados não é só uma tarefa técnica, mas também precisa de entender bem o seu negócio. As complexidades envolvidas podem incluir o seguinte:
Trabalhar com cubos de dados tem alguns desafios, principalmente quando os dados aumentam. Isso inclui:
Quando você junta cubos de dados com sistemas que já existem, pode ser que você tenha os seguintes desafios:
Cubos de dados são uma ótima maneira de organizar e entender dados complexos de diferentes ângulos. Eles ajudam você a identificar padrões mais rapidamente, executar consultas com mais eficiência e explorar informações dividindo-as da maneira que você precisar.
Se você quer melhorar suas habilidades, recomendo fazer nosso curso Conceitos de Data Warehousing para aprender sobre as propriedades do data warehouse e como integrar cubos de dados com os sistemas que já existem, se o seu trabalho precisar disso. Nosso curso Entendendo a Engenharia de Dados também vai te ajudar com habilidades em manter e processar dados.
Aprenda com o DataCamp
Programa
Curso
Curso
blog
Joleen Bothma
9 min
blog
Matt Crabtree
10 min
blog
Javier Canales Luna
14 min
blog
Kurtis Pykes
11 min
blog
Matt Crabtree
15 min

