
Cours
Concepts MLOps
2 h
42.7K
Vous avez probablement entendu parler de DevOps (Developer Operations), qui automatise les processus de déploiement des applications. Si vous êtes un professionnel des données, vous connaissez probablement MLOps (Machine Learning Operations), qui rationalise le déploiement des modèles. Mais qu'en est-il de GitOps?
Dans ce blog, nous allons explorer GitOps, pourquoi il est important, les différents modèles de GitOps, et enfin, comment intégrer GitOps dans un grand projet de modèle de langage.

Image par l'auteur
Vous pouvez également apprendre la théorie derrière les concepts DevOps et MLOps en suivant deux de nos meilleures formations courtes, Concepts DevOps et Concepts MLOps.
GitOps est un cadre opérationnel qui étend les principes DevOps à l'automatisation de l'infrastructure. Il met l'accent sur les enseignements clés de DevOps, tels que le contrôle des versions, la collaboration et la conformité, CI/CDet l'observabilité, et les applique au provisionnement et à la gestion de l'infrastructure, en particulier dans les environnements cloud modernes.
À la base, GitOps automatise la gestion de l'infrastructure en traitant les configurations comme du code, souvent appelé Infrastructure as Code (IaC). Tout comme les équipes de développement utilisent le code source pour créer des binaires d'application de manière cohérente, les équipes d'exploitation utilisent des fichiers de configuration stockés dans des référentiels Git pour s'assurer que le même environnement d'infrastructure est déployé à chaque fois. Cette approche garantit la cohérence, la fiabilité et la reproductibilité.
Composants clés d'un flux de travail GitOps :
La gestion de l'infrastructure est traditionnellement manuelle, mais le cloud moderne exige l'automatisation pour gérer la vitesse et l'échelle des applications natives du cloud. Avec GitOps, l'infrastructure devient élastique et fiable, ce qui permet aux équipes de déployer les changements rapidement et de manière cohérente. Il élimine les erreurs manuelles, améliore l'efficacité et garantit que l'infrastructure et les applications sont toujours synchronisées, répondant ainsi aux besoins rapides des flux de développement modernes.
Principaux avantages de GitOps :
Dans l'approche GitOps, il existe deux modèles principaux pour le déploiement et la gestion des configurations d'infrastructure et d'application : le modèle "pull-based " et le modèle "push-based". Ces modèles diffèrent par la manière dont ils traitent les changements de configuration et les appliquent à l'environnement cible.
L'approche "pull-based" repose sur le stockage de l'état souhaité du système dans un dépôt Git. Un opérateur GitOps, tel que Flux ou Argo CD, surveille en permanence les modifications apportées au dépôt. Lorsque des mises à jour sont détectées, l'opérateur extrait automatiquement la configuration mise à jour et l'applique à l'environnement cible.
Le modèle basé sur l'extraction permet également de détecter les dérives et de s'auto-réparer, car le cluster "tire" continuellement l'état souhaité de Git. Ainsi, toute modification involontaire ou dérive de configuration dans l'environnement est automatiquement corrigée, ce qui permet de maintenir la cohérence et la stabilité.
L'approche basée sur le push s'appuie sur des outils tels que GitHub Actions ou d'autres services CI/CD pour pousser les mises à jour vers le cluster à chaque fois que des modifications sont apportées. Contrairement au modèle basé sur la traction, l'approche basée sur la poussée manque de réconciliation continue, ce qui signifie qu'il n'y a pas de détection de dérive intégrée ou de retour en arrière automatisé. Cela la rend moins résistante aux changements involontaires de l'environnement. Cependant, le modèle basé sur le "push" est souvent plus simple à mettre en œuvre et permet un contrôle granulaire des déploiements.
Nous nous concentrerons sur une approche GitOps basée sur le push en utilisant les GitHub Actionscar elle est plus simple à mettre en place et ne nécessite qu'un minimum de connaissances préalables. Bien qu'un système basé sur le push n'offre pas tous les avantages d'une approche basée sur le pull, il fournit néanmoins des fonctionnalités GitOps essentielles telles que des configurations contrôlées par version, des déploiements automatisés et des retours en arrière simplifiés.
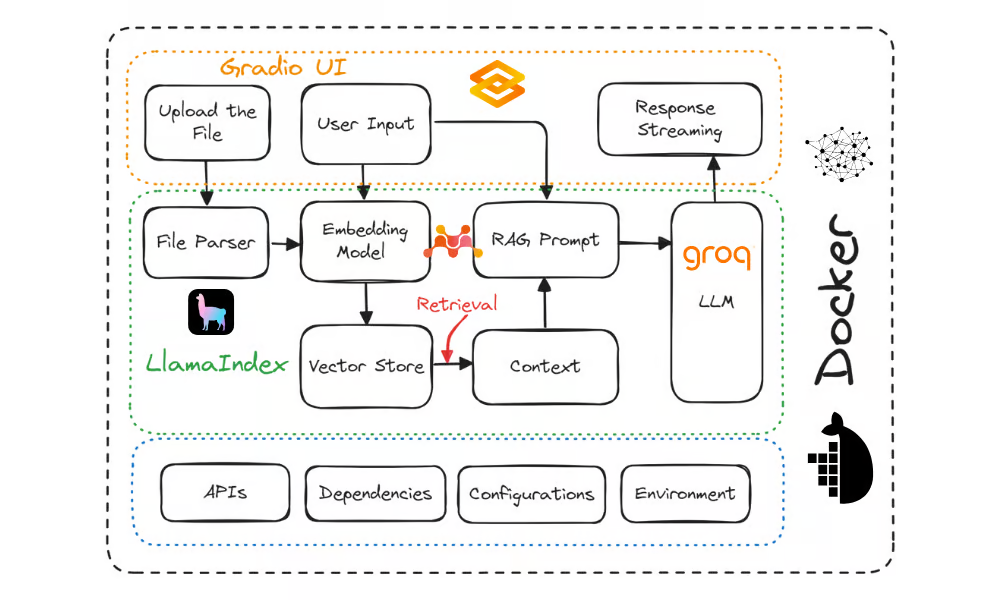
Dans cette section, nous appliquerons les principes GitOps au projet du tutoriel How to Deploy LLM Applications Using Docker : Un guide étape par étape. Ce projet comprend le code d'une application Gradio, un fichier Docker et requirements.txt. Elle montre comment déployer une application d'IA dans le cloud à l'aide de Docker.
Source : Comment déployer des applications LLM en utilisant Docker : Un guide pas à pas
Adoptez un état d'esprit MLOps pour former, documenter, maintenir et développer efficacement vos modèles d'apprentissage automatique en vous inscrivant à ce cours, Développer des modèles d'apprentissage automatique pour la production avec un état d'esprit MLOps.
Ce projet GitOps est conçu pour déployer des applications de grand modèle linguistique (LLM) à l'aide de Docker, Kubernetes et des actions GitHub. Le projet organise tous les fichiers du projet LLM dans le dossier app, crée un dossier infra pour les configurations Kubernetes, et utilise .github/workflows/ pour l'automatisation CI/CD avec GitHub Actions.
Suivez le cours Introduction à Kubernetes Apprenez les bases de Kubernetes et déployez et orchestrez des conteneurs à l'aide de Manifests et d'instructions kubectl.
Cette structure garantit des déploiements automatisés, évolutifs et spécifiques à l'environnement pour votre application LLM, en suivant les principes modernes de GitOps.
Deploying-LLM-Applications-with-Docker/
├── app/
│ ├── requirements.txt <-- Python dependencies for your LLM app
│ ├── main.py <-- Your LLM application code
│ └── Dockerfile <-- Docker instructions for building the app
├── infra/
│ ├── dev/ <-- Dev environment configs (YAML or Helm)
│ ├── staging/ <-- Staging environment configs
│ └── production/ <-- Production environment configs
└── .github/
└── workflows/
├── ci.yaml <-- GitHub Actions workflow for continuous integration
└── cd.yaml <-- GitHub Actions workflow for continuous deploymentVoici une ventilation simple :
Découvrez la différence entre Kubernetes et Docker en lisant l'article sur la différence entre Kubernetes et Docker. Kubernetes vs Docker .
C'est ce qui se passe dans le flux de travail des actions GitHub :
Developer commits code + config to GitHub
|
v
GitHub Actions CI (ci.yaml)
- Builds Docker image
- (Optional) pushes Docker image
|
v
GitHub Actions CD (cd.yaml)
- Deploys updated app/config
- kubectl apply or helm upgrade
|
v
Kubernetes Cluster Updatedkubectl apply ou helm upgrade pour mettre à jour les manifestes Kubernetes.Apprenez à automatiser l'entraînement, l'évaluation, la gestion des versions et le déploiement des modèles à l'aide des actions GitHub et créez un fichier en suivant les instructions ci-dessous. Guide de CI/CD pour l'apprentissage automatique à l'intention des débutants pour l'apprentissage automatique.
Si vous avez une expérience préalable des actions GitHub, la mise en place d'une méthodologie GitOps utilisant une approche basée sur le push peut être simple. Il vous suffit d'ajouter les fichiers de configuration de l'infrastructure, de configurer les pipelines CI/CD et vous êtes prêt à partir. Cependant, bien que cette approche soit simple, il y a plusieurs compromis importants à prendre en compte.
Avantages
Compromis
Lorsque votre projet prend de l'ampleur ou que vos besoins deviennent plus exigeants, la transition vers un modèle GitOps basé sur le tirage peut offrir des avantages significatifs. Si votre équipe a besoin de fonctionnalités telles que l'autoréparation, la réconciliation continue ou un tableau de bord visuel, l'adoption d'un outil basé sur les flux (pull-based) tel qu'Argo CD ou Flux pourrait être la prochaine étape logique.
Vous pouvez passer à un outil basé sur la traction comme Argo CD ou Flux. Ils surveilleront constamment votre dépôt et veilleront à ce que le cluster corresponde toujours à ce qui se trouve dans Git - aucune étape manuelle de "push" n'est nécessaire après le commit initial.
Pour mettre en œuvre efficacement GitOps, il est préférable de commencer à petite échelle et d'adopter progressivement ses technologies. Commencez par un simple fichier Docker pour conteneuriser votre application et la déployer dans le cloud. Ensuite, présentez Kubernetes pour permettre l'évolutivité et la fiabilité grâce à un déploiement et une gestion automatisés.
Une fois à l'aise, adoptez une approche GitOps basée sur le push en utilisant des outils comme GitHub Actions pour automatiser à la fois l'infrastructure du cloud et le déploiement des applications. Enfin, lorsque votre projet arrive à maturité et nécessite une stabilité au niveau de la production, passez à un modèle basé sur le tirage avec des outils tels qu'Argo CD ou Flux pour obtenir une réconciliation continue, une détection des dérives et des capacités d'autoréparation.
Cette progression pas à pas garantit une courbe d'apprentissage en douceur tout en exploitant le plein potentiel de GitOps pour les applications cloud-natives modernes.
Dans ce blog, nous avons exploré GitOps, son importance, les différents modèles GitOps et comment intégrer GitOps dans un projet d'IA. Si vous êtes novice en matière d'IA, nous vous recommandons vivement de suivre le cours Fondamentaux de l'IA qui couvre les fondamentaux de l'IA, approfondit les modèles tels que GPT-4o, et découvre les secrets de l'IA générative pour naviguer dans le paysage évolutif de l'IA.
Les meilleurs cours de DataCamp
Cours
Cours
Cours
blog
Fereshteh Forough
4 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach