
Kurs
MLOps-Konzepte
2 Std.
42.8K
Du hast wahrscheinlich schon von DevOps (Developer Operations) gehört , das die Prozesse zur Anwendungsbereitstellung automatisiert. Wenn du ein Datenexperte bist, kennst du wahrscheinlich MLOps (Machine Learning Operations), das den Einsatz von Modellen vereinfacht. Aber was ist mit GitOps?
In diesem Blog werden wir uns mit GitOps beschäftigen, warum es wichtig ist, welche verschiedenen GitOps-Modelle es gibt und schließlich, wie man GitOps in ein großes Sprachmodellprojekt integriert.

Bild vom Autor
Du kannst auch die Theorie hinter DevOps- und MLOps-Konzepten lernen, indem du zwei unserer besten Kurzkurse besuchst, DevOps-Konzepte und MLOps-Konzepte.
GitOps ist ein operatives Framework, das die DevOps-Prinzipien auf die Automatisierung der Infrastruktur ausweitet. Er betont die wichtigsten Erkenntnisse aus DevOps, wie Versionskontrolle, Zusammenarbeit und Compliance, CI/CDund Beobachtbarkeit, und wendet sie auf die Bereitstellung und Verwaltung von Infrastrukturen an, insbesondere in modernen Cloud-Umgebungen.
Im Kern automatisiert GitOps das Infrastrukturmanagement, indem es Konfigurationen als Code behandelt, oft auch als Infrastructure as Code (IaC) bezeichnet. Genauso wie die Entwicklungsteams den Quellcode verwenden, um konsistente Binärdateien zu erstellen, verwenden die Betriebsteams Konfigurationsdateien, die in Git-Repositories gespeichert sind, um sicherzustellen, dass jedes Mal die gleiche Infrastrukturumgebung bereitgestellt wird. Dieser Ansatz garantiert Konsistenz, Zuverlässigkeit und Wiederholbarkeit.
Die wichtigsten Komponenten eines GitOps Workflows:
Die Verwaltung der Infrastruktur erfolgte traditionell manuell, aber die moderne Cloud erfordert Automatisierung, um die Geschwindigkeit und den Umfang von Cloud-nativen Anwendungen zu bewältigen. Mit GitOps wird die Infrastruktur elastisch und zuverlässig, sodass die Teams Änderungen schnell und konsistent umsetzen können. Sie beseitigt manuelle Fehler, verbessert die Effizienz und stellt sicher, dass Infrastruktur und Anwendungen immer synchron sind und die schnellen Anforderungen moderner Entwicklungsabläufe erfüllen.
Die wichtigsten Vorteile von GitOps:
Beim GitOps-Ansatz gibt es zwei primäre Modelle für die Bereitstellung und Verwaltung von Infrastruktur- und Anwendungskonfigurationen: Pull-basiert und Push-basiert. Diese Modelle unterscheiden sich darin, wie sie mit Konfigurationsänderungen umgehen und sie auf die Zielumgebung anwenden.
Der Pull-basierte Ansatz beruht auf der Speicherung des gewünschten Zustands des Systems in einem Git-Repository. Ein GitOps-Operator wie Flux oder Argo CD überwacht das Repository kontinuierlich auf Änderungen. Wenn Updates entdeckt werden, zieht der Operator automatisch die aktualisierte Konfiguration und wendet sie auf die Zielumgebung an.
Das Pull-basierte Modell bietet außerdem eine Drifterkennung und Selbstheilung, da der Cluster kontinuierlich den gewünschten Zustand aus Git "zieht". So wird sichergestellt, dass unbeabsichtigte Änderungen oder Konfigurationsabweichungen in der Umgebung automatisch korrigiert werden, um Konsistenz und Stabilität zu gewährleisten.
Der Push-basierte Ansatz setzt auf Tools wie GitHub Actions oder andere CI/CD-Dienste, um Aktualisierungen in den Cluster zu pushen, sobald Änderungen übertragen werden. Im Gegensatz zum Pull-basierten Modell fehlt beim Push-basierten Ansatz der kontinuierliche Abgleich, d.h. es gibt keine eingebaute Drift-Erkennung oder ein automatisches Rollback. Das macht sie weniger widerstandsfähig gegenüber ungewollten Veränderungen in der Umwelt. Das Push-basierte Modell ist jedoch oft einfacher zu implementieren und bietet eine genauere Kontrolle über die Einsätze.
Wir werden uns auf einen Push-basierten GitOps-Ansatz konzentrieren, der GitHub-Aktionenkonzentrieren, da er einfacher einzurichten ist und nur minimale Vorkenntnisse erfordert. Auch wenn ein Push-basiertes System nicht alle Vorteile eines Pull-basierten Ansatzes bietet, so bietet es doch wichtige GitOps-Funktionen wie versionskontrollierte Konfigurationen, automatisierte Bereitstellungen und vereinfachte Rollbacks.
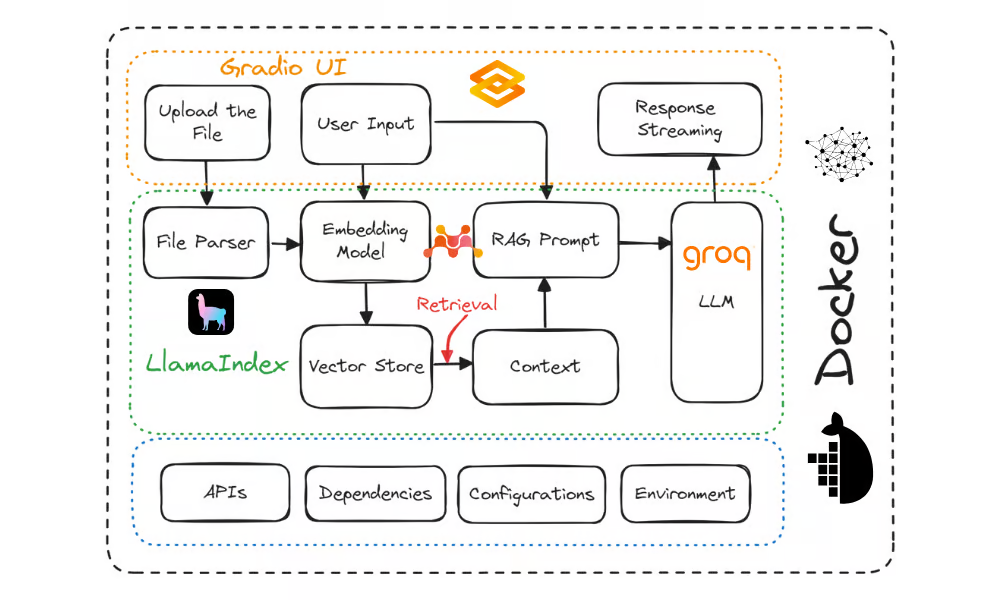
In diesem Abschnitt werden wir die GitOps-Prinzipien auf das Projekt aus dem Tutorial How to Deploy LLM Applications Using Docker anwenden : Eine Schritt-für-Schritt-Anleitung. Dieses Projekt enthält den Code für eine Gradio-Anwendung, Dockerfile und requirements.txt. Er zeigt, wie man eine KI-Anwendung mit Docker in der Cloud bereitstellt.
Quelle: Wie man LLM-Anwendungen mit Docker einsetzt: Eine Schritt-für-Schritt-Anleitung
Mach dir eine MLOps-Mentalität zu eigen, um deine Machine Learning-Modelle effektiv zu trainieren, zu dokumentieren, zu pflegen und zu skalieren, indem du dich für diesen Kurs anmeldest, Entwicklung von Machine Learning-Modellen für die Produktion mit einer MLOps-Mentalität.
Dieses GitOps-Projekt wurde entwickelt, um Large Language Model (LLM)-Anwendungen mit Docker, Kubernetes und GitHub Actions bereitzustellen. Das Projekt organisiert alle LLM-Projektdateien im Ordner app, erstellt einen Ordner infra für Kubernetes-Konfigurationen und nutzt .github/workflows/ für die CI/CD-Automatisierung mit GitHub Actions.
Nimm die Einführung in Kubernetes und lerne die Grundlagen von Kubernetes und die Bereitstellung und Orchestrierung von Containern mithilfe von Manifesten und kubectl-Anweisungen.
Diese Struktur gewährleistet automatisierte, skalierbare und umgebungsspezifische Implementierungen für deine LLM-Anwendung, die modernen GitOps-Prinzipien folgen.
Deploying-LLM-Applications-with-Docker/
├── app/
│ ├── requirements.txt <-- Python dependencies for your LLM app
│ ├── main.py <-- Your LLM application code
│ └── Dockerfile <-- Docker instructions for building the app
├── infra/
│ ├── dev/ <-- Dev environment configs (YAML or Helm)
│ ├── staging/ <-- Staging environment configs
│ └── production/ <-- Production environment configs
└── .github/
└── workflows/
├── ci.yaml <-- GitHub Actions workflow for continuous integration
└── cd.yaml <-- GitHub Actions workflow for continuous deploymentHier ist eine einfache Aufschlüsselung:
Lerne den Unterschied zwischen Kubernetes und Docker, indem du den Kubernetes vs. Docker Tutorial.
Genau das passiert im GitHub Actions Workflow:
Developer commits code + config to GitHub
|
v
GitHub Actions CI (ci.yaml)
- Builds Docker image
- (Optional) pushes Docker image
|
v
GitHub Actions CD (cd.yaml)
- Deploys updated app/config
- kubectl apply or helm upgrade
|
v
Kubernetes Cluster Updatedkubectl apply oder helm upgrade aus, um Kubernetes-Manifeste zu aktualisieren.Erfahre, wie du das Training, die Bewertung, die Versionierung und die Bereitstellung von Modellen mit GitHub Actions automatisieren kannst und erstelle eine Datei, indem du A Beginner's Guide to CI/CD for Machine Learning Tutorials.
Wenn du bereits Erfahrung mit GitHub Actions hast, kann die Einrichtung einer GitOps-Methode mit einem Push-basierten Ansatz ganz einfach sein. Du musst nur noch die Konfigurationsdateien für die Infrastruktur hinzufügen, CI/CD-Pipelines einrichten und schon bist du startklar. Dieser Ansatz ist zwar einfach, aber es gibt einige wichtige Kompromisse zu beachten.
Vorteile
Kompromisse
Wenn sich dein Projekt vergrößert oder deine Anforderungen anspruchsvoller werden, kann die Umstellung auf ein Pull-basiertes GitOps-Modell erhebliche Vorteile bieten. Wenn dein Team Funktionen wie Selbstheilung, kontinuierlichen Abgleich oder ein visuelles Dashboard benötigt, könnte die Einführung eines Pull-basierten Tools wie Argo CD oder Flux der nächste logische Schritt sein.
Du kannst zu einem Pull-basierten Tool wie Argo CD oder Flux wechseln. Sie überwachen dein Repository ständig und stellen sicher, dass der Cluster immer mit dem übereinstimmt, was in Git vorhanden ist - es sind keine manuellen "Push"-Schritte nach dem ersten Commit nötig.
Um GitOps effektiv umzusetzen, ist es am besten, klein anzufangen und die Technologien nach und nach zu übernehmen. Beginne mit einer einfachen Dockerdatei, um deine Anwendung zu containerisieren und in der Cloud bereitzustellen. Dann führst du Kubernetes ein, um Skalierbarkeit und Zuverlässigkeit durch automatisierte Bereitstellung und Verwaltung zu ermöglichen.
Sobald du dich daran gewöhnt hast, kannst du einen Push-basierten GitOps-Ansatz mit Tools wie GitHub Actions anwenden, um sowohl die Cloud-Infrastruktur als auch die Anwendungsbereitstellung zu automatisieren. Wenn dein Projekt reift und Stabilität auf Produktionsebene benötigt, kannst du mit Tools wie Argo CD oder Flux zu einem Pull-basierten Modell übergehen, um einen kontinuierlichen Abgleich, die Erkennung von Drifts und Selbstheilungsfunktionen zu erreichen.
Dieses schrittweise Vorgehen sorgt für eine reibungslose Lernkurve, während du das volle Potenzial von GitOps für moderne Cloud-native Anwendungen nutzt.
In diesem Blog haben wir uns mit GitOps, seiner Bedeutung, den verschiedenen GitOps-Modellen und der Integration von GitOps in ein KI-Projekt beschäftigt. Wenn du neu in der KI bist, empfehlen wir dir den Kurs KI-Grundlagen Lernpfad, der die Grundlagen der KI behandelt, Modelle wie GPT-4o vorstellt und die Geheimnisse der generativen KI lüftet, um sich in der sich entwickelnden KI-Landschaft zurechtzufinden.
Top DataCamp Kurse
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
