
Cours
Concepts des grands modèles de langage (LLM)
2 h
99.8K
Docker vous permet de créer des environnements cohérents, portables et isolés, ce qui le rend essentiel pour les LLMOps (Large Language Models Operations). En encapsulant diverses applications LLM et leurs dépendances dans des conteneurs, Docker simplifie le déploiement, assure la compatibilité entre les systèmes et rationalise les tests.
Dans ce tutoriel, vous apprendrez à construire une application de chatbot "questions-réponses sur les documents" et à la déployer sur le cloud à l'aide de Docker. Nous utiliserons Gradio pour l'interface utilisateur, LlamaIndex pour l'orchestration, LlamaParse pour l'analyse des documents, Mixedbread AI pour les embeddings, Groq pour l'accès aux grands modèles de langage, Docker pour le packaging de l'application et de ses dépendances, et Hugging Face Spaces pour le déploiement de l'application sur le cloud.
Ce tutoriel est conçu pour être simple et permettre à toute personne ayant une connaissance limitée du fonctionnement des applications d'IA de le construire gratuitement.
Il existe deux approches principales pour développer et déployer des applications d'IA :
Les deux approches présentent des avantages et des inconvénients. Dans notre cas, nous avons choisi la deuxième approche, en intégrant plusieurs services d'intelligence artificielle. Cela nous permet de créer une application d'IA rapide qui ne prend que quelques secondes à construire et à déployer. Notre objectif principal est de réduire la taille de l'image Docker, ce qui peut être réalisé efficacement en intégrant plusieurs services d'intelligence artificielle.
Consultez le tutoriel Local AI with Docker, n8n, Qdrant, and Ollama pour construire une application LLM à l'aide d'outils et de frameworks open-source pour une meilleure protection de la vie privée !
Nous allons créer un chatbot Q&A polyvalent qui permet aux utilisateurs de télécharger des documents et de discuter avec eux en temps réel. Il est assez similaire au NotebookLM de Google.
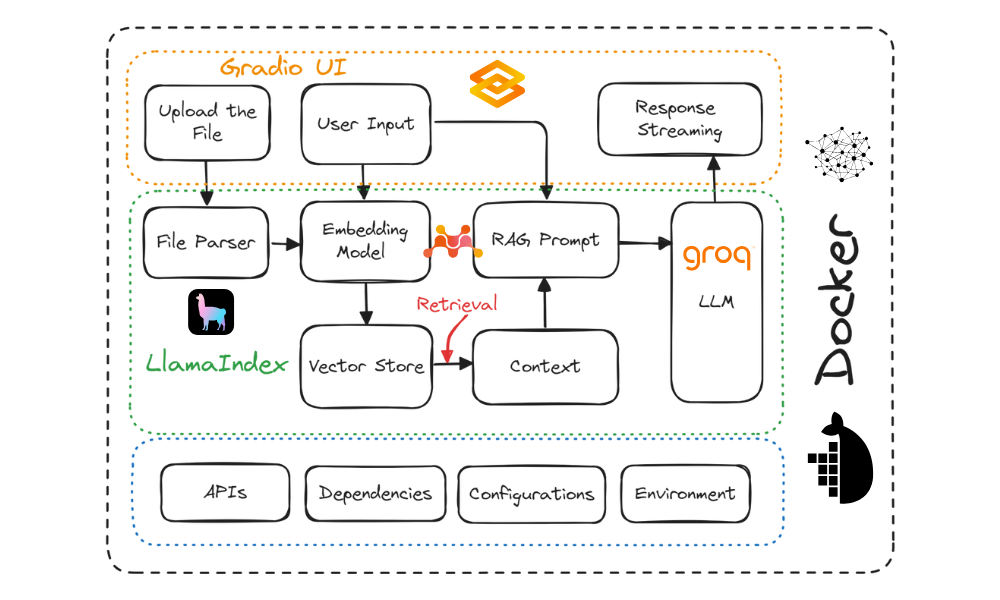
Schéma du projet. Image par l'auteur
Voici les outils que nous utiliserons dans ce projet :
Si vous êtes novice en matière de LLM, vous pouvez envisager de suivre le cours Master Large Language Models (LLMs) Concepts pour apprendre les terminologies de base, les méthodologies, les considérations éthiques et les recherches les plus récentes.
Apprenez à travailler avec des LLM en Python directement dans votre navigateur

Avant de construire l'application LLM, nous devons télécharger et installer Docker depuis le site officiel.
.env. Nous utiliserons ce fichier pour stocker les clés d'API pour LlamaCloud, MixedBread AI et Groq Cloud.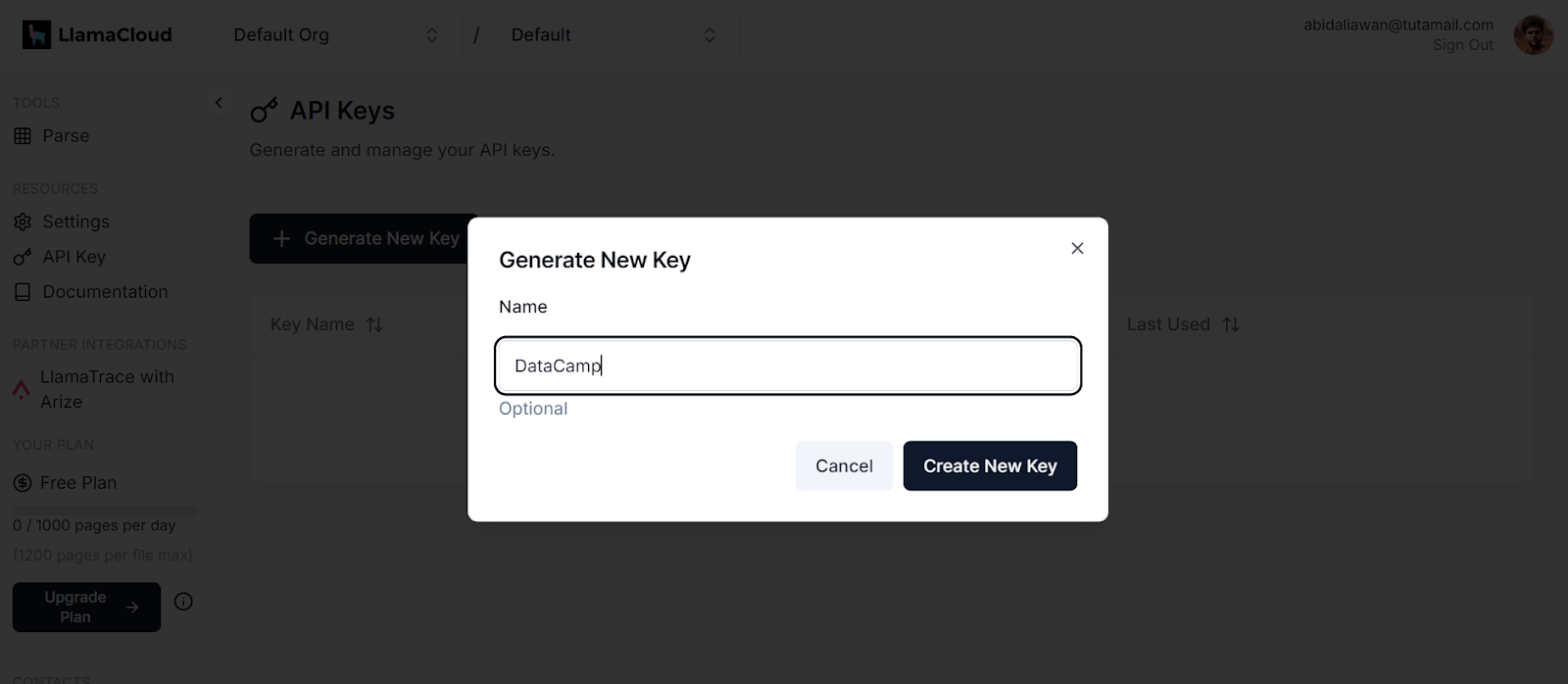
Générer une nouvelle clé dans LlamaCloud. Source de l'image : LlamaCloud
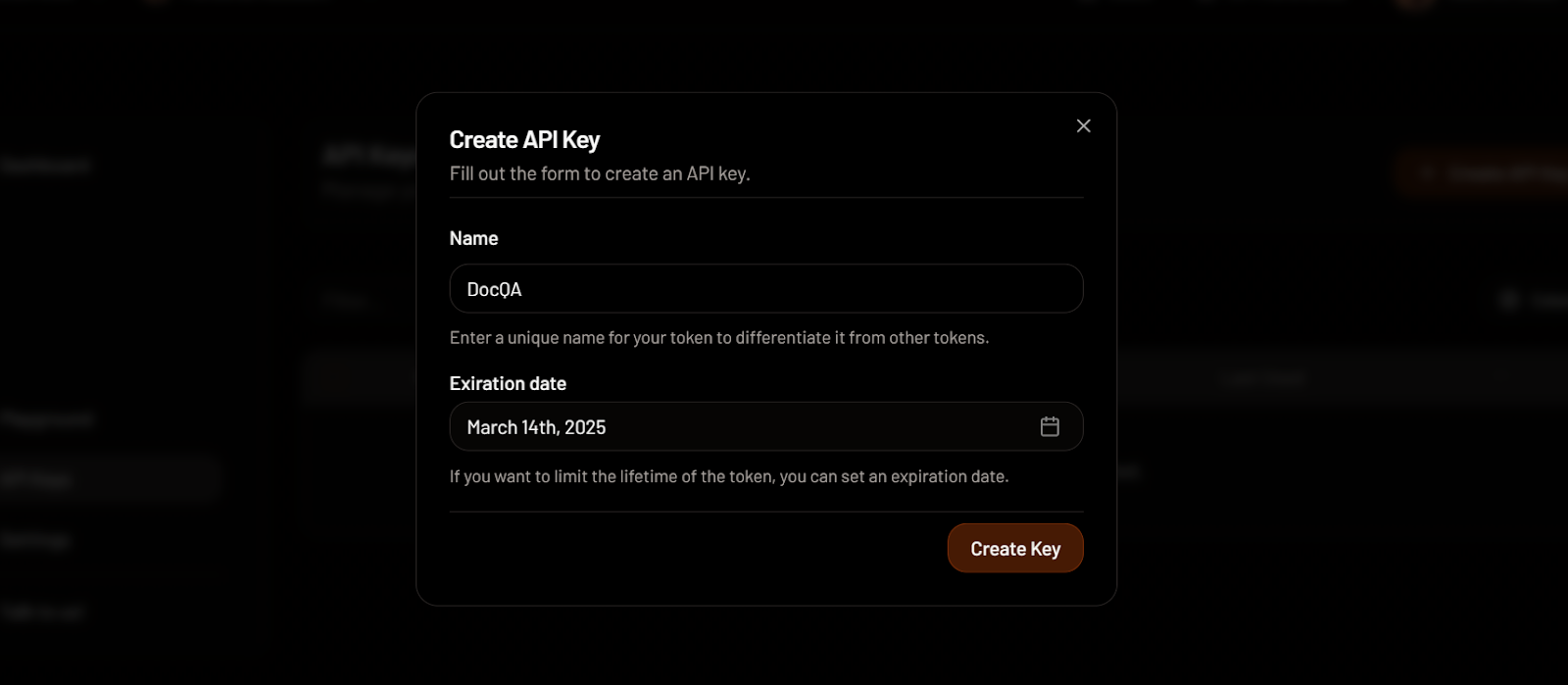
Création d'une clé API dans MixedBread. Source de l'image : MixedBread
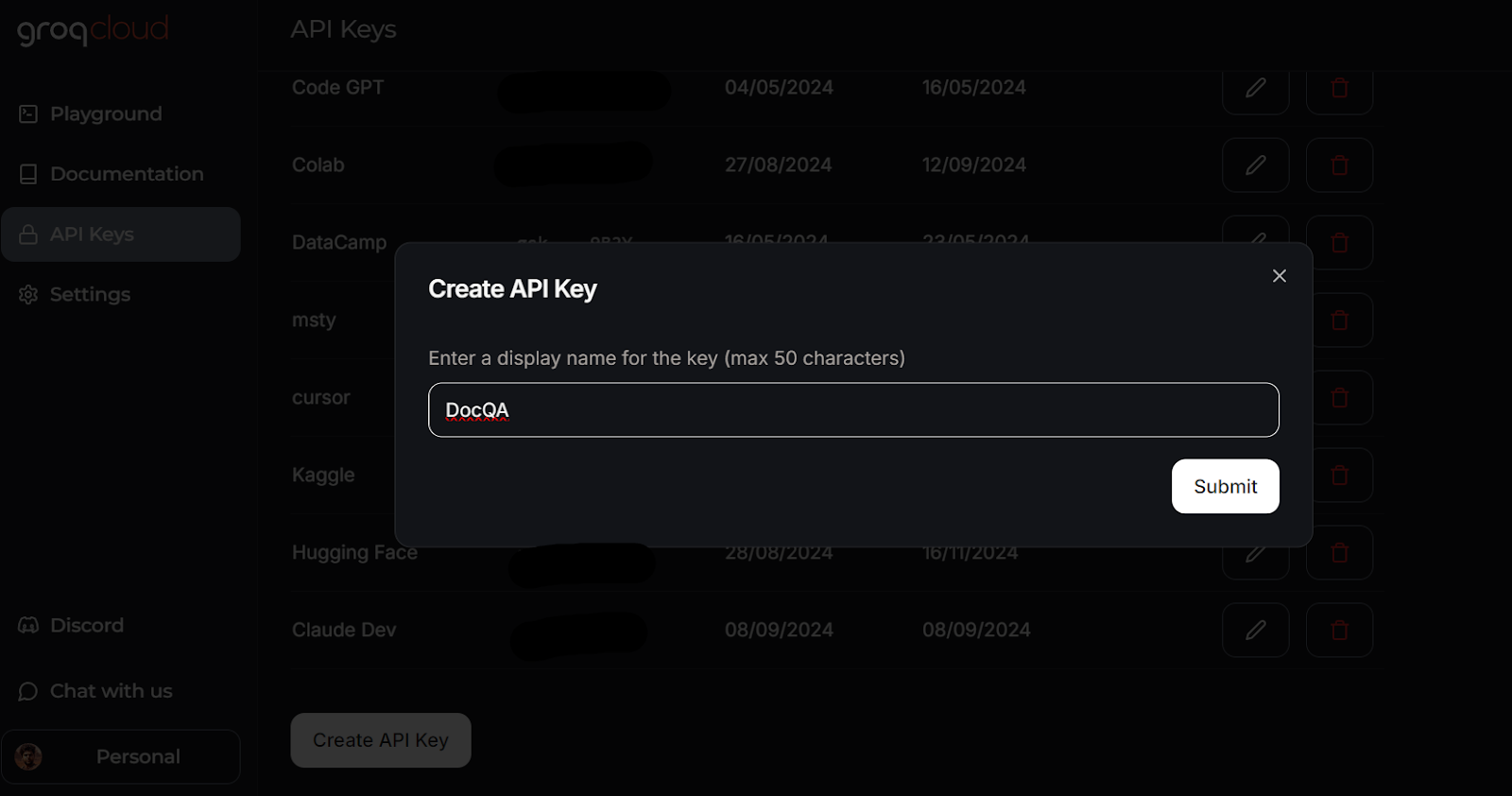
Création d'une clé API dans GroqCloud. Image source: GroqCloud
Apprenez tout sur GroqCloud en lisant l'article sur le moteur d'inférence Groq LPU. Vous découvrirez l'API Groq et ses fonctionnalités à l'aide d'exemples de code. En outre, vous apprendrez à créer des applications d'intelligence artificielle contextuelles à l'aide de l'API Groq et de LlamaIndex.
Voici à quoi devrait ressembler votre fichier .env:
LLAMA_CLOUD_API_KEY=llx-XXXXXX
GROQ_API_KEY=gsk_XXXXXXX
MXBAI_API_KEY=emb_XXXXXXN'oubliez pas d'ajouter le fichier .env à votre fichier .gitignore pour éviter d'exposer accidentellement vos clés d'API au public.
Nous allons maintenant créer un script Python appelé app.py et ajouter les composants de l'interface utilisateur tout en intégrant tous les services d'IA à l'aide de LlamaParser pour développer le pipeline Retrieval-Augmented Generation (RAG) avec LlamaIndex.
Le script app.py effectue les opérations suivantes :
.env.mixedbread-ai/mxbai-embed-large-v1.llama-3.1-70b-versatile.Ensuite, il mettra en œuvre les fonctions Python suivantes :
load_files(): Cette fonction chargera les fichiers, les analysera à l'aide de LlamaParser, les convertira en embeddings et les stockera dans le magasin de vecteurs. Une gestion des exceptions sera incluse pour gérer les cas où des fichiers qui ne sont pas des fichiers ou des formats de fichiers non pris en charge sont téléchargés.respond(): Cette fonction prend en compte les données de l'utilisateur, récupère le contenu du magasin de vecteurs et l'utilise pour générer une réponse à l'aide du modèle Groq. La réponse sera générée en flux continu et une gestion des exceptions sera incluse si aucun fichier n'a été téléchargé.Enfin, il construira les composants de l'interface utilisateur, y compris un chargeur de fichiers, des boutons, une boîte de dialogue et l'interface globale du dialogue.
Apprenez-en plus sur le framework LlamaIndex en suivant le tutoriel LlamaIndex.
Voici le script app.py:
import os
import gradio as gr
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.embeddings.mixedbreadai import MixedbreadAIEmbedding
from llama_index.llms.groq import Groq
from llama_parse import LlamaParse
# API keys
llama_cloud_key = os.environ.get("LLAMA_CLOUD_API_KEY")
groq_key = os.environ.get("GROQ_API_KEY")
mxbai_key = os.environ.get("MXBAI_API_KEY")
if not (llama_cloud_key and groq_key and mxbai_key):
raise ValueError(
"API Keys not found! Ensure they are passed to the Docker container."
)
# models name
llm_model_name = "llama-3.1-70b-versatile"
embed_model_name = "mixedbread-ai/mxbai-embed-large-v1"
# Initialize the parser
parser = LlamaParse(api_key=llama_cloud_key, result_type="markdown")
# Define file extractor with various common extensions
file_extractor = {
".pdf": parser,
".docx": parser,
".doc": parser,
".txt": parser,
".csv": parser,
".xlsx": parser,
".pptx": parser,
".html": parser,
".jpg": parser,
".jpeg": parser,
".png": parser,
".webp": parser,
".svg": parser,
}
# Initialize the embedding model
embed_model = MixedbreadAIEmbedding(api_key=mxbai_key, model_name=embed_model_name)
# Initialize the LLM
llm = Groq(model="llama-3.1-70b-versatile", api_key=groq_key)
# File processing function
def load_files(file_path: str):
global vector_index
if not file_path:
return "No file path provided. Please upload a file."
valid_extensions = ', '.join(file_extractor.keys())
if not any(file_path.endswith(ext) for ext in file_extractor):
return f"The parser can only parse the following file types: {valid_extensions}"
document = SimpleDirectoryReader(input_files=[file_path], file_extractor=file_extractor).load_data()
vector_index = VectorStoreIndex.from_documents(document, embed_model=embed_model)
print(f"Parsing completed for: {file_path}")
filename = os.path.basename(file_path)
return f"Ready to provide responses based on: {filename}"
# Respond function
def respond(message, history):
try:
# Use the preloaded LLM
query_engine = vector_index.as_query_engine(streaming=True, llm=llm)
streaming_response = query_engine.query(message)
partial_text = ""
for new_text in streaming_response.response_gen:
partial_text += new_text
# Yield an empty string to cleanup the message textbox and the updated conversation history
yield partial_text
except (AttributeError, NameError):
print("An error occurred while processing your request.")
yield "Please upload the file to begin chat."
# Clear function
def clear_state():
global vector_index
vector_index = None
return [None, None, None]
# UI Setup
with gr.Blocks(
theme=gr.themes.Default(
primary_hue="green",
secondary_hue="blue",
font=[gr.themes.GoogleFont("Poppins")],
),
css="footer {visibility: hidden}",
) as demo:
gr.Markdown("# DataCamp Doc Q&A 🤖📃")
with gr.Row():
with gr.Column(scale=1):
file_input = gr.File(
file_count="single", type="filepath", label="Upload Document"
)
with gr.Row():
btn = gr.Button("Submit", variant="primary")
clear = gr.Button("Clear")
output = gr.Textbox(label="Status")
with gr.Column(scale=3):
chatbot = gr.ChatInterface(
fn=respond,
chatbot=gr.Chatbot(height=300),
theme="soft",
show_progress="full",
textbox=gr.Textbox(
placeholder="Ask questions about the uploaded document!",
container=False,
),
)
# Set up Gradio interactions
btn.click(fn=load_files, inputs=file_input, outputs=output)
clear.click(
fn=clear_state, # Use the clear_state function
outputs=[file_input, output],
)
# Launch the demo
if __name__ == "__main__":
demo.launch()$ python app.py Sortie :

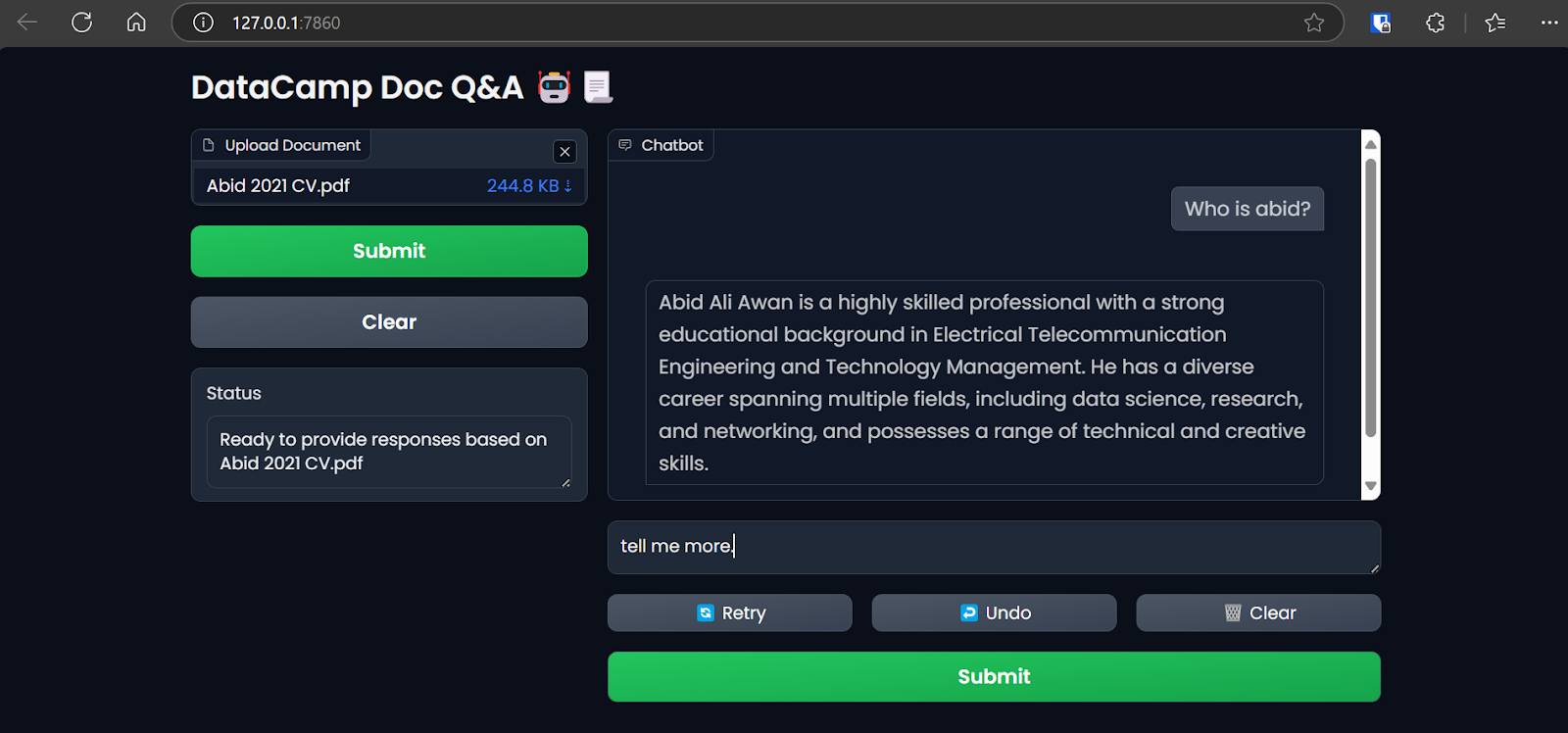
Accéder à l'application Gradio sur le navigateur. Image par l'auteur
Nous utilisons LlamaIndex pour déployer et construire notre application LLM pour ce tutoriel. Vous pouvez créer une application similaire avec LangChain en suivant la formation courte Développer des applications LLM avec LangChain.
Dockerfile pour empaqueter le script d'application, les dépendances Python et les configurations du serveur tout en initialisant le serveur Gradio. Le site Dockerfile effectuera les tâches suivantes :
requirements.txt dans le répertoire /app. Ce fichier contient les noms de tous les paquets Python requis.requirements.txt.app.py dans le répertoire /app.Voici à quoi devrait ressembler le site Dockerfile:
# Dockerfile
# Use the official Python image with the desired version
FROM python:3.9-slim
# Set the working directory inside the container
WORKDIR /app
# Copy the requirements file to the working directory
COPY requirements.txt /app
# Install the dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application code to the working directory
COPY app.py /app
# Expose the port that Gradio will run on (default is 7860)
EXPOSE 7860
ENV GRADIO_SERVER_NAME="0.0.0.0"
# Command to run your application
CMD ["python", "app.py"]requirements.txt. Ajoutez-le également à votre projet :gradio
llama-index-embeddings-mixedbreadai
llama-index-llms-groq
llama-indexdocqa. Il utilisera le site Dockerfile pour créer l'image Docker.$ docker build -t docqa . Nous pouvons voir les journaux des processus qui se déroulent pendant la construction de l'image Docker :
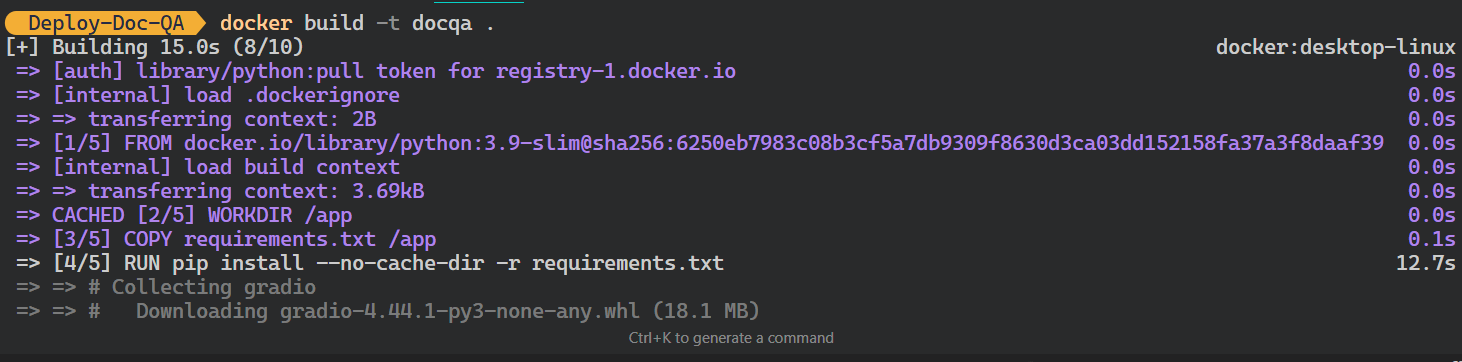
Construire l'image Docker LLM. Image par l'auteur
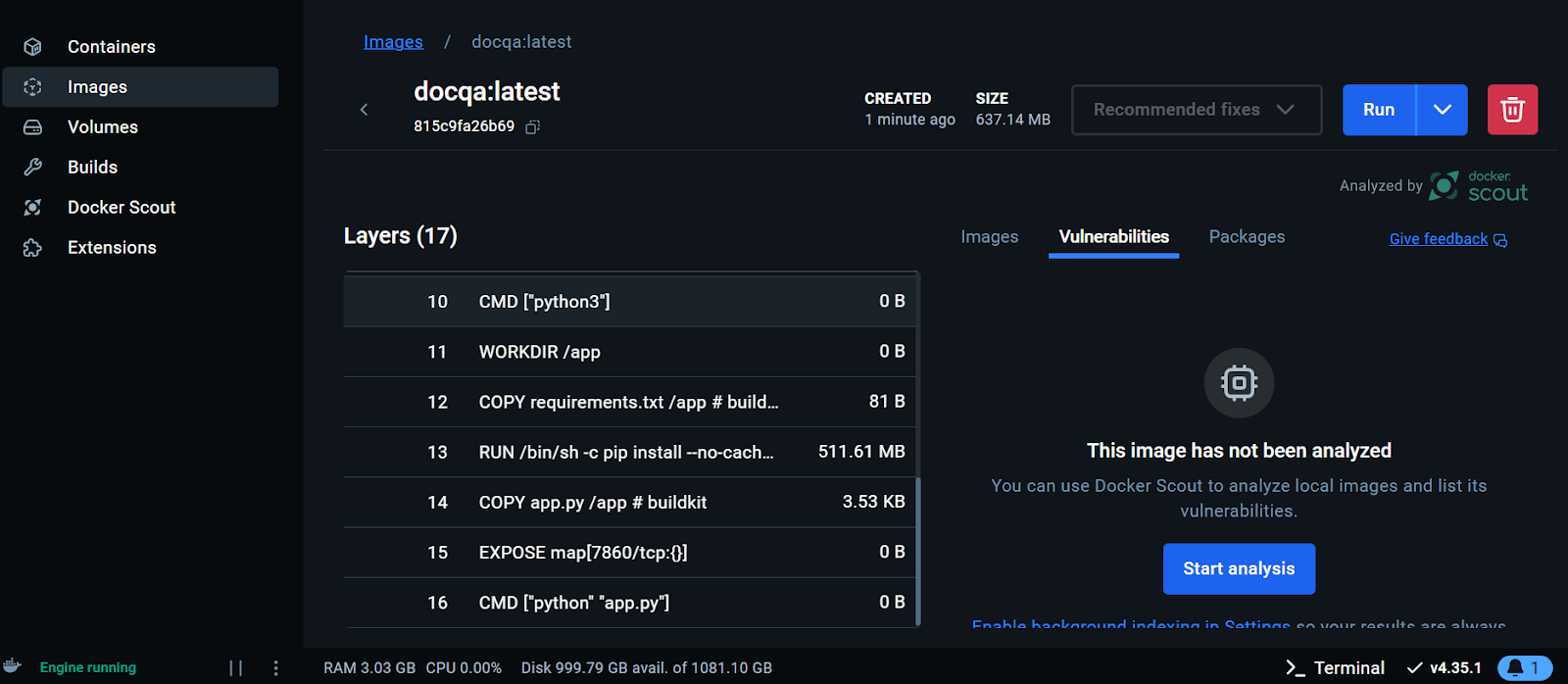
Visualisation de l'image Docker sur le Docker Desktop. Image par l'auteur
Nous allons maintenant exécuter le conteneur Docker localement en utilisant l'image. Nous lui fournirons le numéro de port, un fichier .env pour configurer les variables d'environnement, le nom du conteneur Docker et l'étiquette de l'image Docker.
$ docker run -p 7860:7860 --env-file .env --name docqa-container docqaUne fois le conteneur lancé, vous pouvez accéder à l'application Gradio en collant l'URL, dans ce cas, http://0.0.0.1:7860/ dans le navigateur.
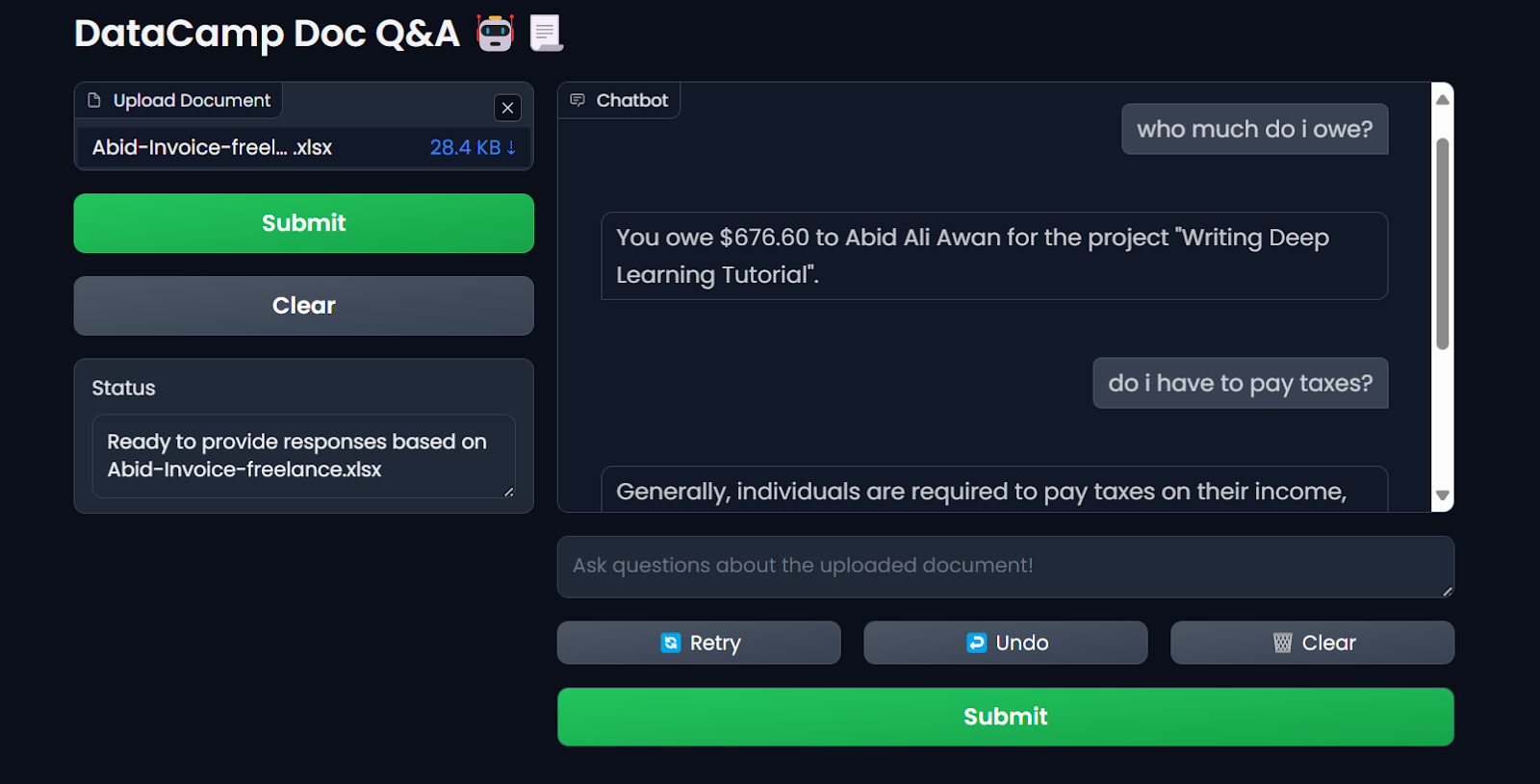
Test de l'application LLM du conteneur Docker. Image par l'auteur
$ docker psSortie :
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ff2a11da13d7 docqa "python app.py" 17 seconds ago Up 16 seconds 0.0.0.0:7860->7860/tcp docqa-containerstop:$ docker stop docqa-container rm:$ docker rm docqa-container Une fois que nous avons une image Docker, nous pouvons déployer notre application LLM n'importe où : GCP, AWS, Azure ou tout autre serveur cloud prenant en charge le déploiement Docker.
Pour simplifier les choses pour les débutants, nous allons déployer l'app à l'aide de Docker sur le cloud Hugging Face (Spaces).
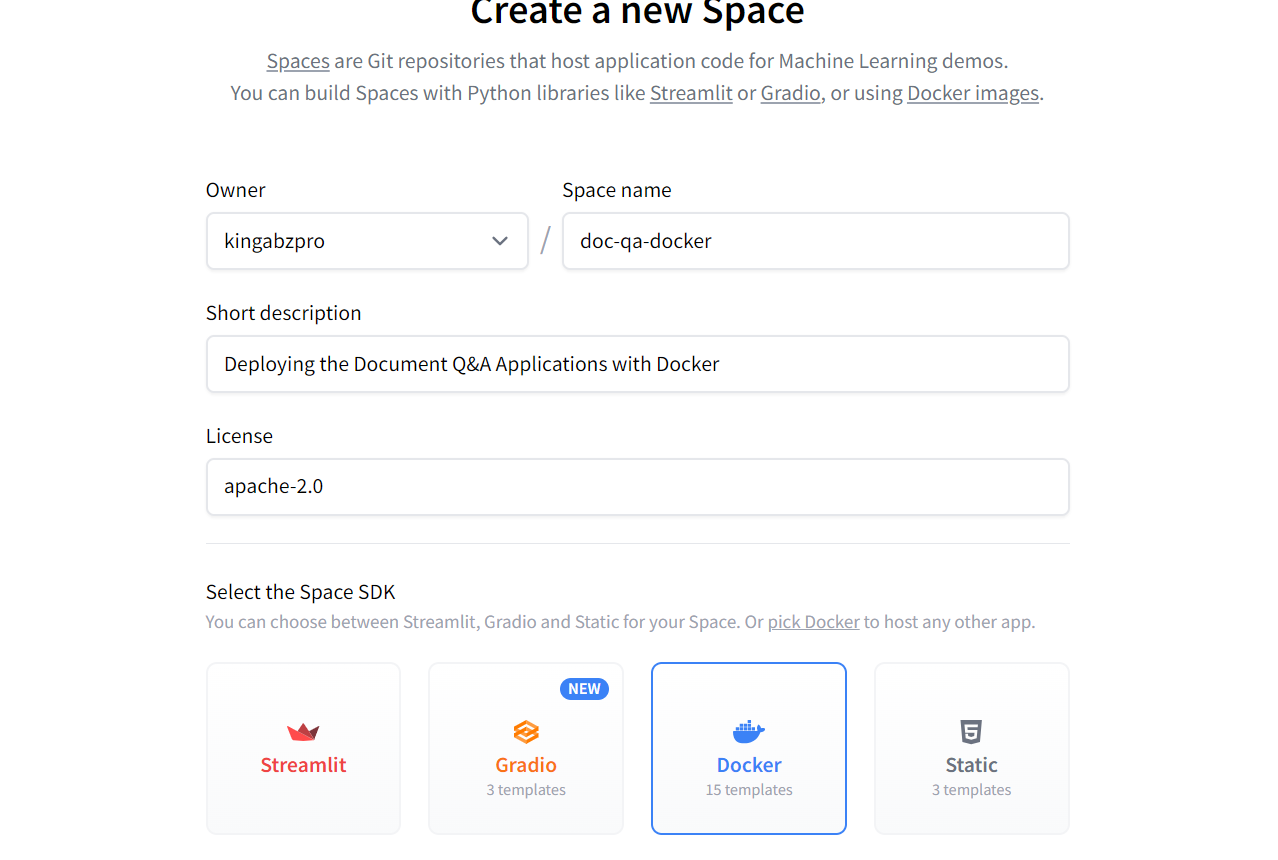
Création du nouvel espace Hugging Face à l'aide de Docker. Image source : Hugging Face
Une fois le dépôt Space créé, vous recevrez des instructions sur la manière de le cloner et d'y ajouter les fichiers nécessaires.
$ git clone https://huggingface.co/spaces/kingabzpro/doc-qa-dockerVoici à quoi devrait ressembler le répertoire de votre projet avec tous les fichiers. Veillez toujours à ne pas repousser le fichier .env, ajoutez-le donc au fichier .gitignore.
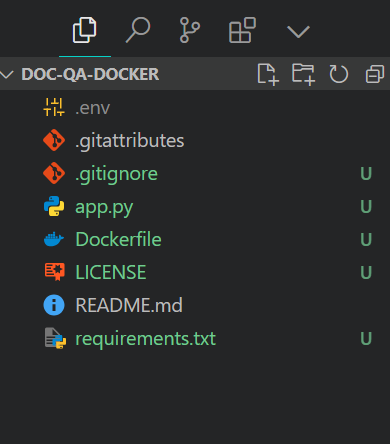
Structure du fichier du projet. Image par l'auteur
$ git add .
$ git commit -m "Deploying the App"
$ git pushSortie :
Enumerating objects: 8, done.
Counting objects: 100% (8/8), done.
Delta compression using up to 16 threads
Compressing objects: 100% (7/7), done.
Writing objects: 100% (7/7), 7.60 KiB | 7.60 MiB/s, done.
Total 7 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
To https://huggingface.co/spaces/kingabzpro/doc-qa-docker
afb20ad..5ca6388 main -> main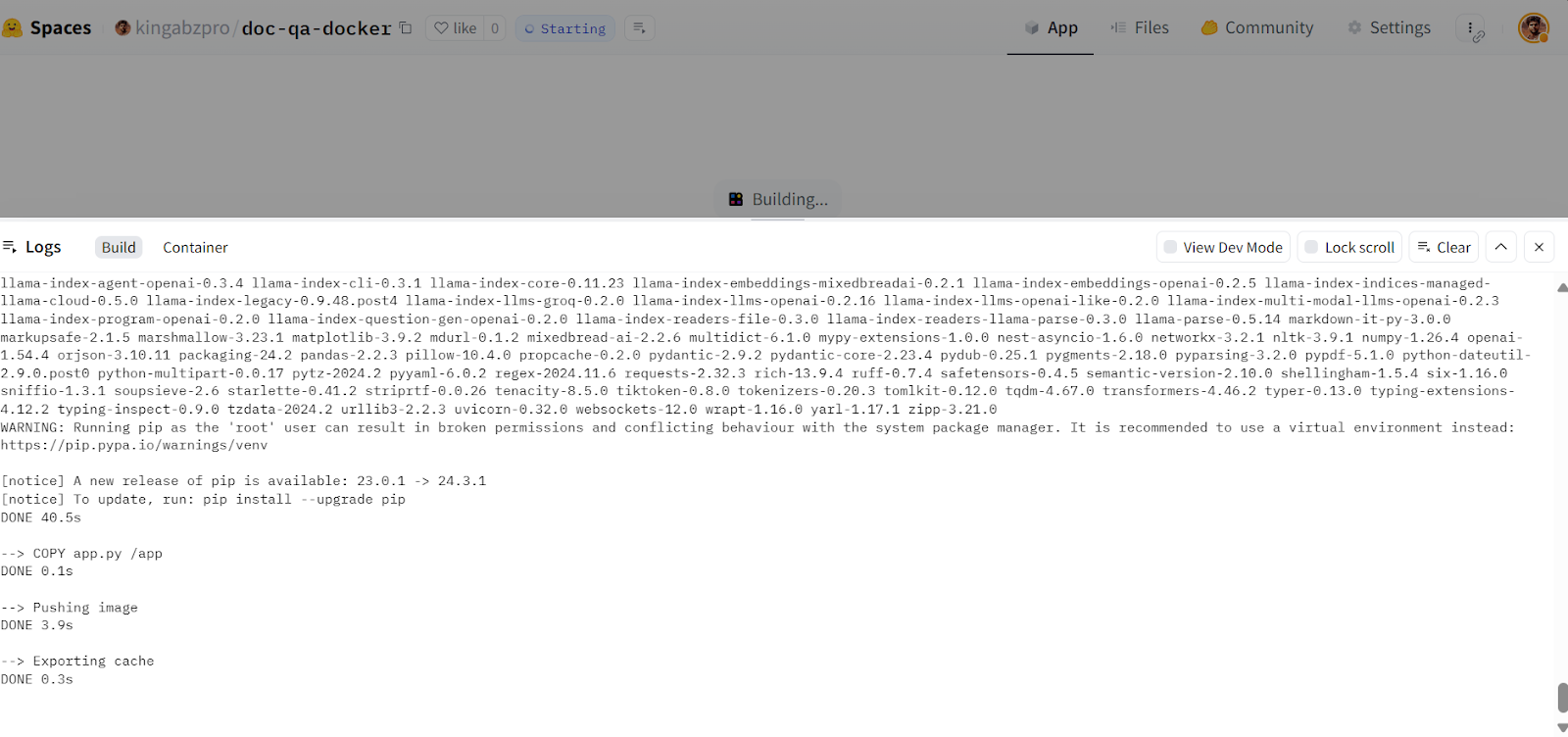
Construction de l'image Docker dans le cloud Hugging Face. Source de l'image : Doc Qa Docker
Si vous voyez une erreur comme celle ci-dessous, ne vous inquiétez pas. Cela est dû à des variables d'environnement manquantes. Il suffit de définir ces variables dans l'espace Hugging Face.

Erreur d'exécution sur l'application déployée. Source de l'image : Doc Qa Docker
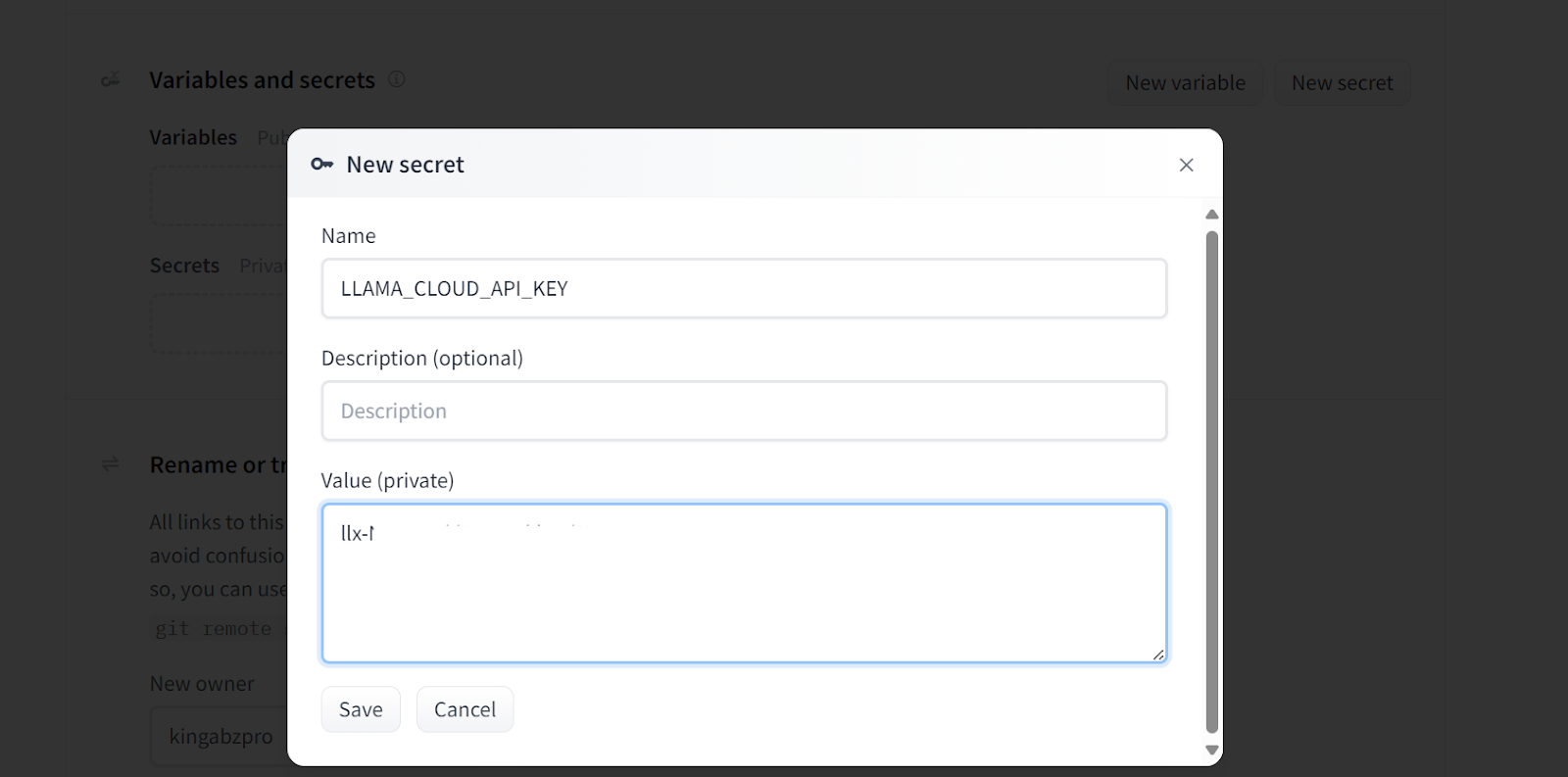
Ajout de secrets à l'application déployée. Source de l'image : Doc Qa Paramètres Docker.
Voici à quoi devraient ressembler vos secrets après avoir ajouté toutes les clés API nécessaires en tant que variables d'environnement :
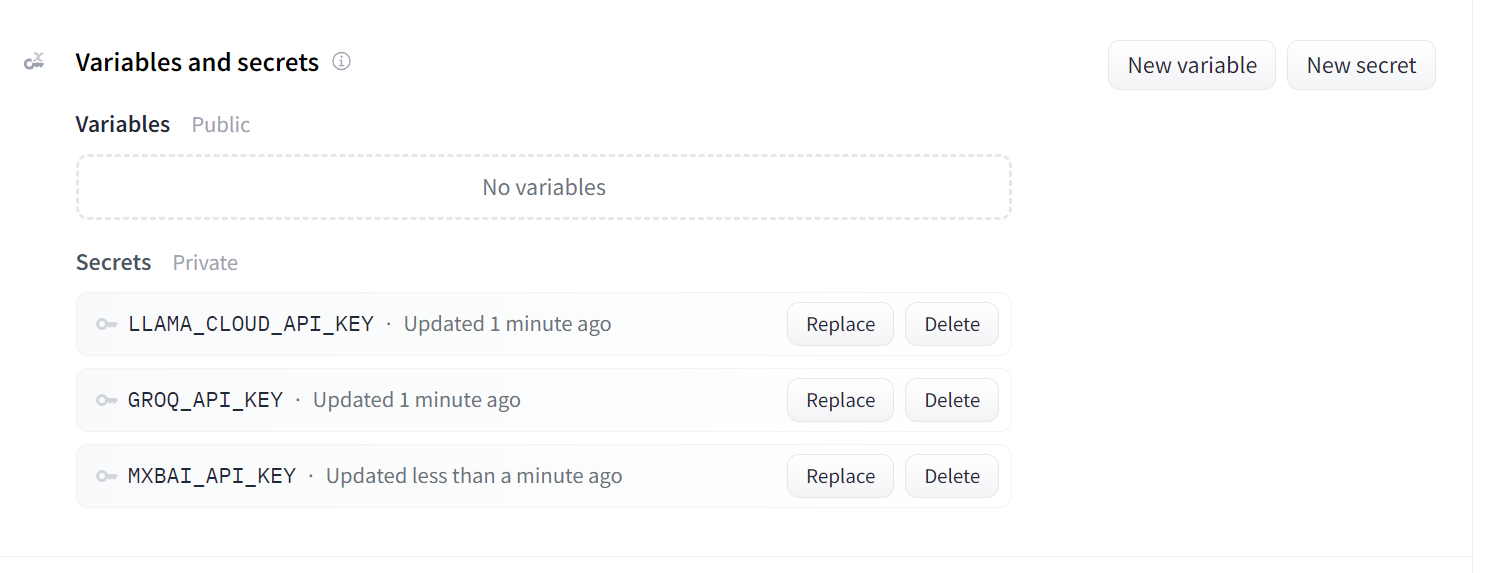
Secrets pour l'application déployée. Source de l'image : Doc Qa Paramètres Docker.
Une fois que vous avez configuré les secrets, l'application redémarre automatiquement et vous devriez voir l'application fonctionner. Utilisez-le et profitez de votre application de questions-réponses sur le cloud !
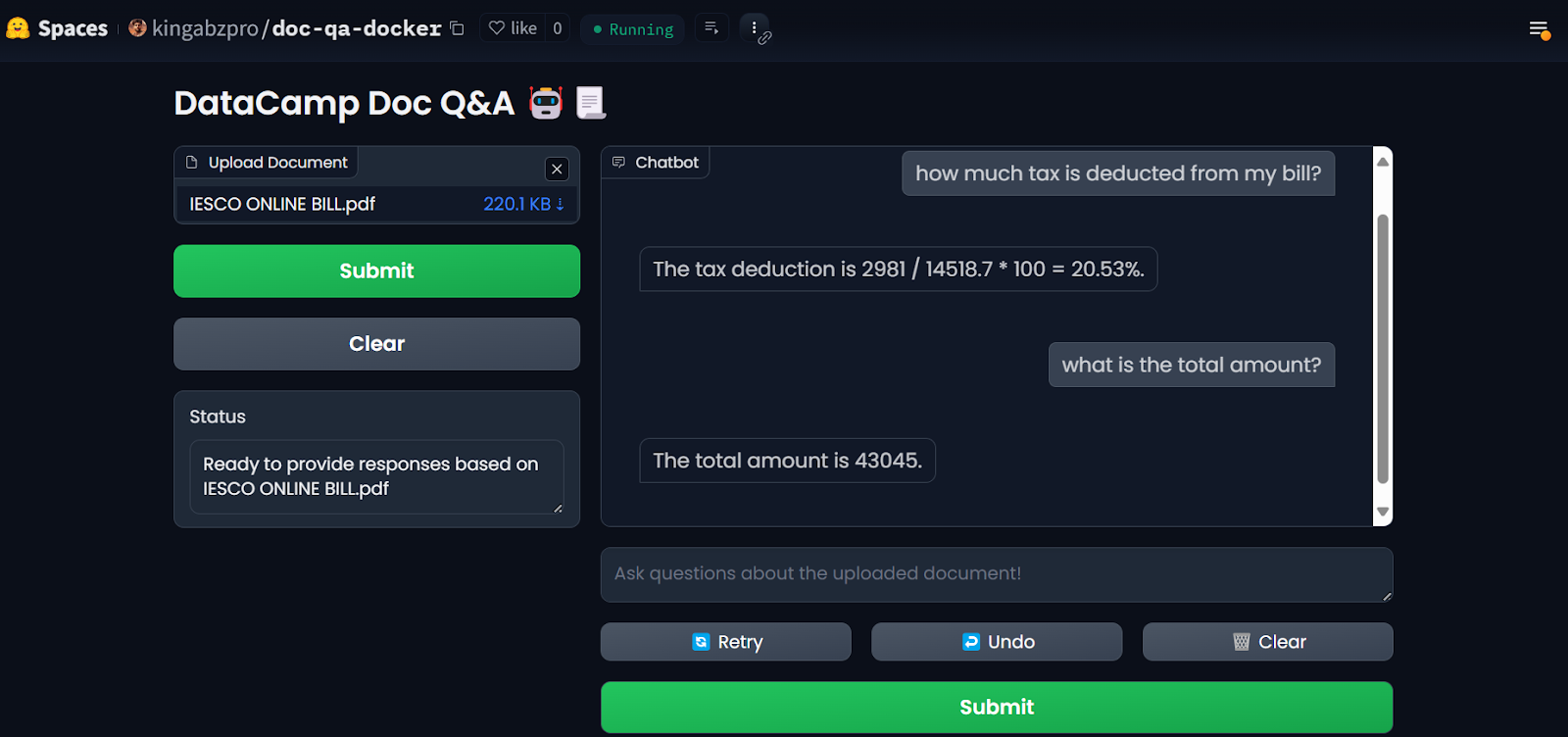
L'application LLM sur les espaces Hugging Face. Source de l'imagee : Doc Qa Docker
Pour reproduire les résultats, tous les fichiers et configurations se trouvent dans le repo GitHubsitory : kingabzpro/Deploy-Doc-QA.
L'utilisation des services d'intelligence artificielle présente des avantages : Vous n'avez pas besoin de déployer ou de gérer des services, vous bénéficiez d'un débit élevé et vous disposez d'un tableau de bord avec les journaux.
Votre tableau de bord LlamaCloud enregistre tous les documents qui ont été analysés. Vous pouvez consulter l'historique ou demander et comparer l'utilisation.
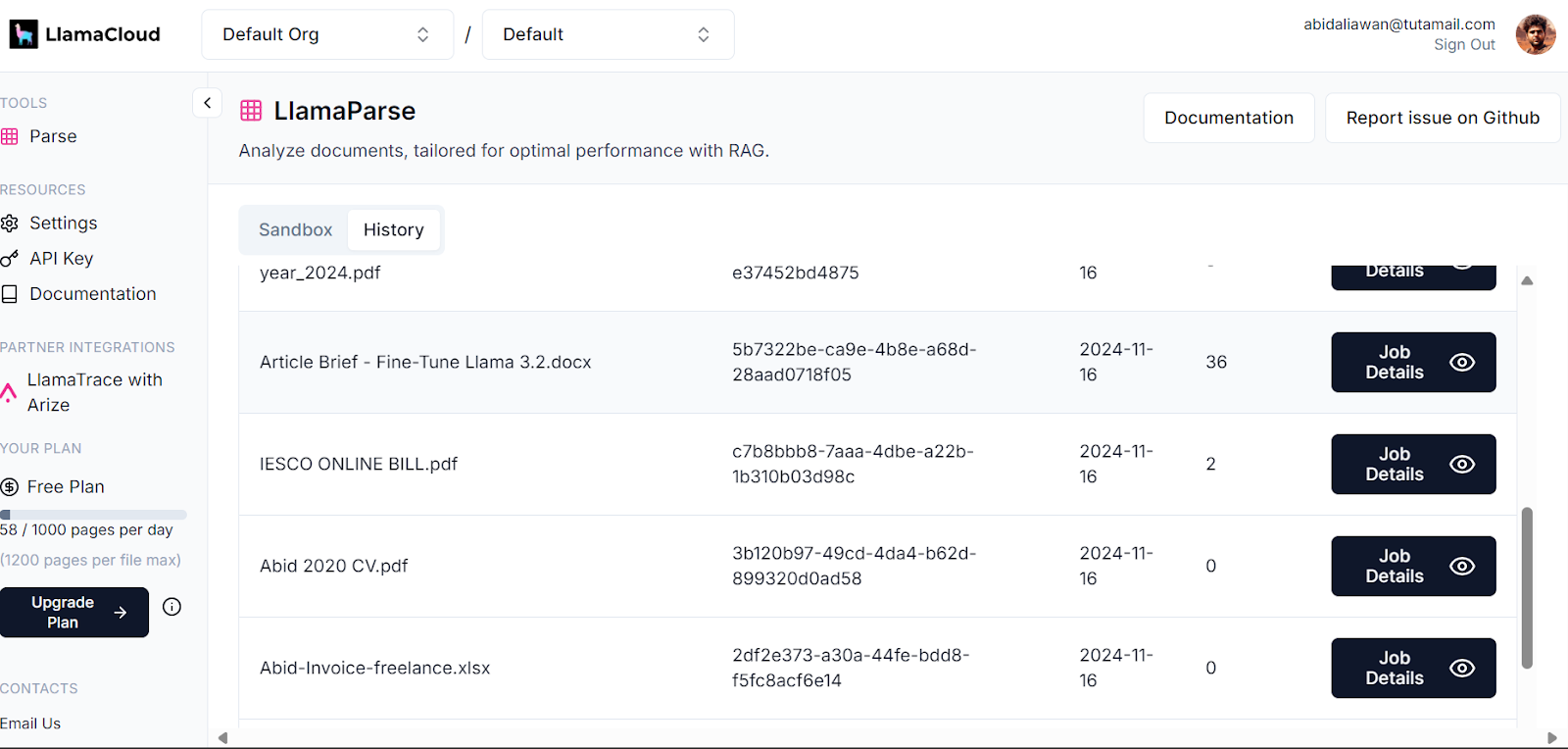
Tableau de bord du nuage de lamas. Image source : LlamaCloud
De même, vous pouvez vérifier le nombre de jetons utilisés pour le modèle d'intégration et le nombre de demandes générées.
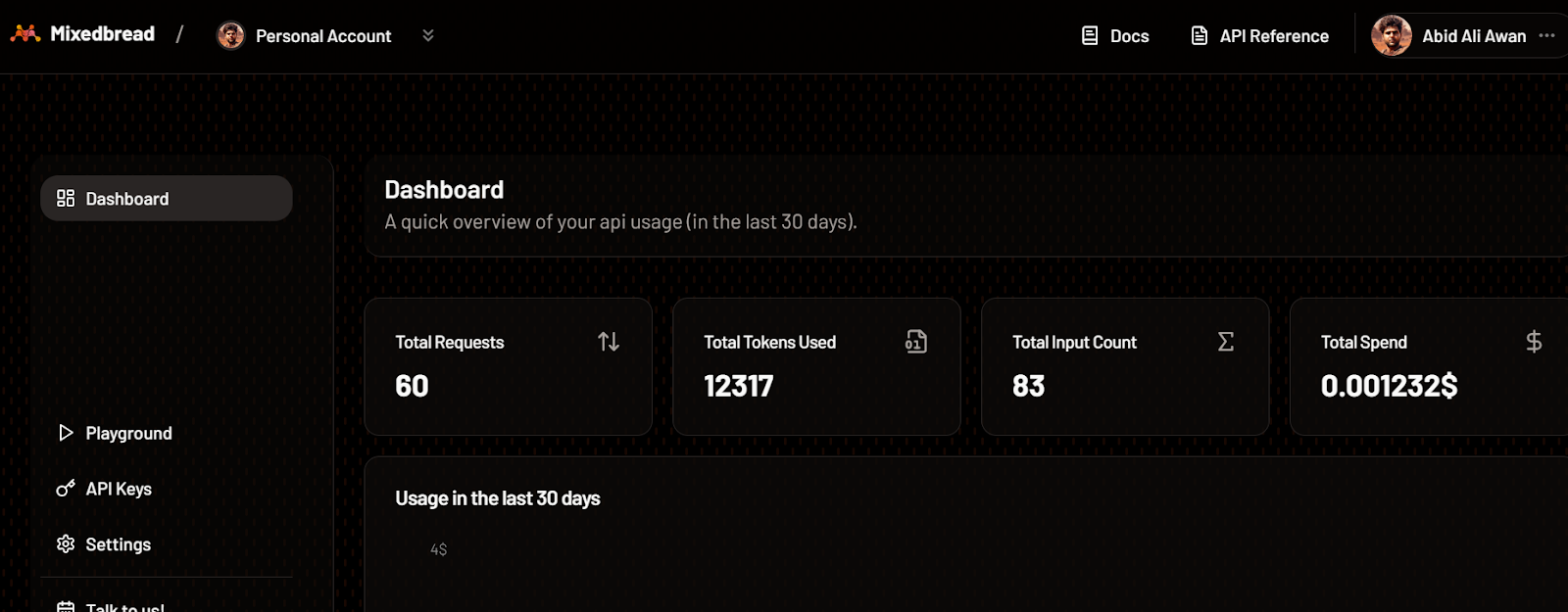
Tableau de bord mixte. Source de l'imagee : Mixedbread
Les journaux les plus détaillés de chaque API sont disponibles sur GroqCloud, avec des informations sur la latence, le nombre de jetons, la clé AI et l'identifiant de la demande pour vous permettre de déboguer le système.
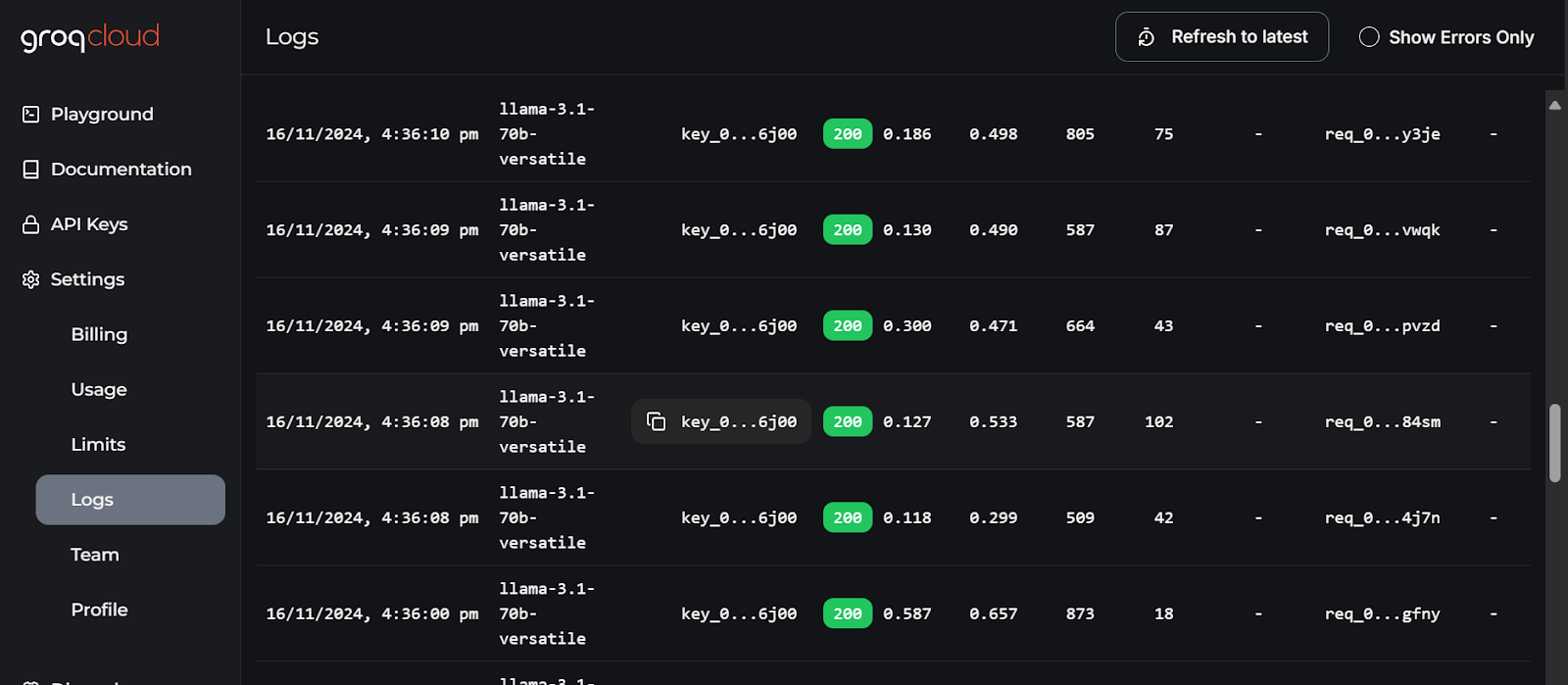
Journaux GroqCloud. Image source : GroqCloud
Ce guide nous a appris à combiner plusieurs services pour construire une application efficace de Q&A de documents avec une utilisation minimale des ressources et une surcharge de calcul. Tous les services et outils que nous avons utilisés sont disponibles gratuitement pour que vous puissiez tester et créer votre propre application.
Nous avons réduit la taille de notre image Docker de 600 Mo en utilisant plusieurs services d'IA prêts à l'emploi. Si nous avions tout déployé par nos propres moyens, la taille de l'image aurait été d'environ 20 Go ou plus.
Je vous recommande de suivre le cours LLMOps Concepts : De l'idéation au déploiement est la prochaine étape de votre parcours d'apprentissage. Ce cours vous permettra de mieux comprendre le cycle de développement du LLM et les défis liés au déploiement des applications. Il vous apprendra également à appliquer ces concepts de manière efficace.
Apprenez-en plus sur les LLM grâce à ces cours !
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min