Cours
Déployer l’IA en production avec FastAPI
4 h
4.5K
GPT-OSS ( ) est la première série de modèles à poids ouverts d'OpenAI, et vous pouvez l'exécuter directement sur votre propre ordinateur. Conçu pour un raisonnement puissant, des tâches agentées et des cas d'utilisation flexibles par les développeurs, GPT-OSS se distingue par son effort de raisonnement configurable et ses capacités transparentes de chaîne de pensée.
Dans ce tutoriel, je vais vous guider dans la configuration locale des modèles GPT-OSS d'OpenAI à l'aide d'Ollama et vous montrer comment créer une démo interactive qui met en valeur les capacités de raisonnement uniques du modèle. Nous explorerons les fonctionnalités configurables de la chaîne de pensée du modèle et créerons une application Streamlit qui visualise le processus de réflexion du modèle.
Nous tenons nos lecteurs informés des dernières actualités en matière d'IA en leur envoyant The Median, notre newsletter gratuite du vendredi qui résume les articles clés de la semaine. Abonnez-vous et restez informé en quelques minutes par semaine :
La série GPT-OSS d'OpenAI marque leur première publication en libre accès depuis GPT-2, permettant l'accès à des modèles de raisonnement haute performance sous licence Apache 2.0. Ces modèles linguistiques de pointe offrent des performances élevées à faible coût et surpassent les modèles ouverts de taille similaire dans les tâches de raisonnement.
Il existe deux variantes : gpt-oss-120b et gpt-oss-20b.

Source : OpenAI
Le gpt-oss-120b est le modèle ouvert phare d'OpenAI, dont les performances rivalisent avec celles de systèmes propriétaires tels que le o4‑mini sur des tests de raisonnement complexes. Malgré ses 117 milliards de paramètres, il est optimisé pour fonctionner sur un seul GPU de 80 Go. Cela en fait une option réaliste pour les laboratoires de recherche et les équipes d'entreprise qui cherchent à héberger localement des modèles linguistiques puissants.
Le modèle est conçu pour prendre en charge des flux de travail complexes tels que l'utilisation d'outils, le raisonnement en plusieurs étapes et le contrôle précis de l'effort « intellectuel » consacré à chaque tâche. Sa nature ouverte et sa licence Apache 2.0 en font un choix flexible pour les équipes qui souhaitent inspecter en profondeur, personnaliser ou affiner le modèle.
Le gpt-oss-20b offre une puissance de raisonnement surprenante dans un format adapté aux ordinateurs portables grand public. Avec seulement 21 milliards de paramètres au total, il surpasse encore le modèle o3-mini d'OpenAI, qui en compte 100 milliards. o3-mini sur certains benchmarks et fonctionne efficacement sur des appareils dotés de 16 Go de mémoire. Il s'agit de quantifié et préparé pour un déploiement local rapide, et compatible avec des outils tels que Ollama, vLLMet même la plateforme Metal d'Apple.
Ce modèle est idéal pour les développeurs qui souhaitent créer des applications d'IA réactives et privées sans dépendre d'une infrastructure cloud. À l'instar de son homologue plus complet, il prend en charge une profondeur de raisonnement ajustable et des étapes intermédiaires claires, ce qui le rend idéal pour les expériences, les assistants légers et les applications de périphériques.
L'exécution locale de GPT-OSS offre plusieurs avantages convaincants par rapport aux alternatives basées sur le cloud :
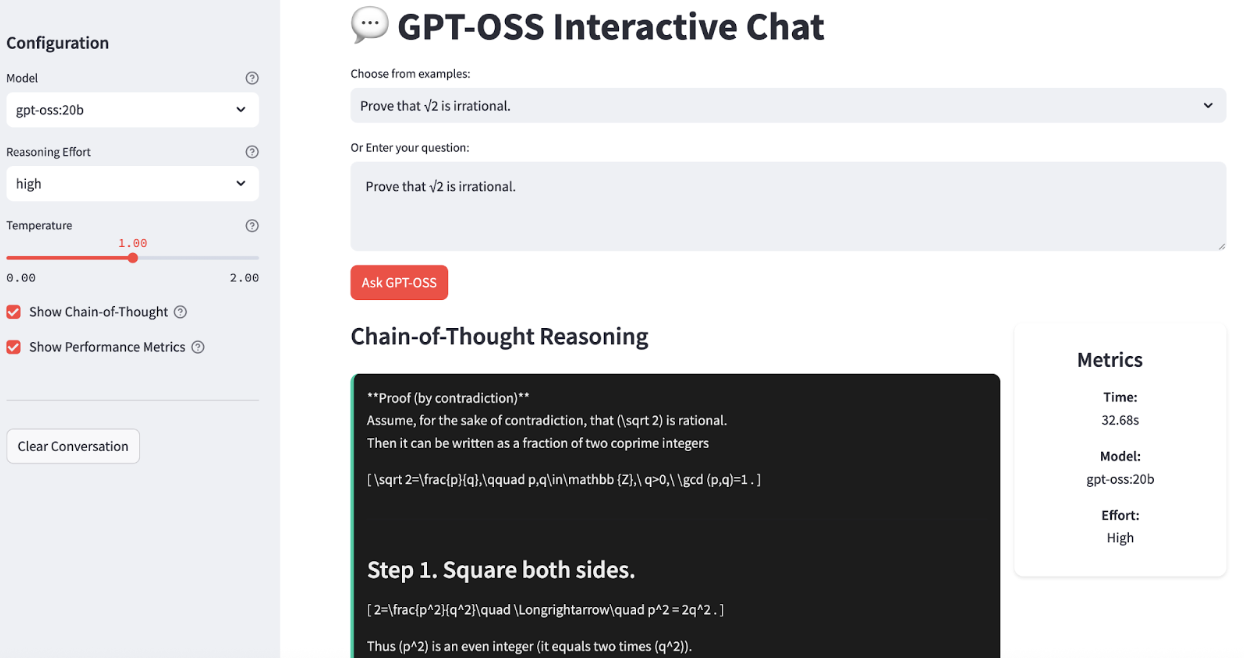
Ollama simplifie considérablement l'exécution locale de modèles linguistiques volumineux en gérant les téléchargements, la quantification et l'exécution. Je vais vous guider pas à pas pour configurer GPT-OSS sur votre système. À la fin, notre application ressemblera à ceci :
Tout d'abord, veuillez télécharger et installer Ollama depuis le site officiel.
Une fois installé, vous pouvez vérifier l'installation en ouvrant un terminal et en saisissant :
ollama --versionCela affichera la dernière version d'Ollama installée sur votre système.
OpenAI propose deux variantes GPT-OSS optimisées pour différents cas d'utilisation, mais pour les besoins de cette démonstration, nous n'utiliserons que la variante gpt-oss-20b :
# For production and high reasoning tasks
ollama pull gpt-oss:120b
# For lower latency and local deployment
ollama pull gpt-oss:20bLe modèle 20B est idéal pour le développement local et peut fonctionner sur des systèmes dotés d'une mémoire de 16 Go ou plus, tandis que le modèle 120B offre davantage de fonctionnalités, mais nécessite une mémoire de 80 Go ou plus.
Vérifions que tout fonctionne correctement :
ollama run gpt-oss:20bVous devriez voir une invite vous permettant d'interagir directement avec le modèle. Essayez de demander : « Démontrez que √2 est irrationnel."
Maintenant, créons rapidement une application simple qui présente les capacités de raisonnement de GPT-OSS. Notre application proposera les fonctionnalités suivantes :
Veuillez exécuter les commandes suivantes pour installer les dépendances nécessaires :
pip install streamlit ollamaL'extrait de code ci-dessus installe Streamlit pour créer l'interface Web et le client Python Ollama pour l'interaction locale avec le modèle GPT-OSS.
Avant de nous plonger dans la logique fondamentale du chat, nous devons rassembler tous les outils et configurer notre interface utilisateur.
import streamlit as st
import json
import ollama
import time
from typing import Dict, Any, List
import re
from datetime import datetime
# Configure page
st.set_page_config(
page_title="GPT-OSS Chat Demo",
layout="wide",
page_icon="💬"
)
# Custom CSS for UI
st.markdown("""
<style>
.reasoning-box {
background-
border-radius: 10px;
border-left: 4px solid #00d4aa;
}
.answer-box {
background-
border-radius: 10px;
border-left: 4px solid #007bff;
}
.metric-card {
background-
border-radius: 10px;
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
text-align: center;
}
.chat-message {
border-radius: 10px;
}
.user-message {
background-
border-left: 4px solid #2196f3;
}
.assistant-message {
background-
border-left: 4px solid #9c27b0;
}
</style>
""", unsafe_allow_html=True)Nous importons quelques paquets essentiels tels que Streamlit pour notre interface web, Ollama pour appeler le modèle GPT-OSS local, ainsi que des modules utilitaires tels que json, time, typing et re. Nous utilisons ensuite st.set_page_config() pour attribuer un titre à la page, lui donner une mise en page large et lui ajouter une icône, puis nous injectons un CSS léger afin que les étapes du raisonnement et les réponses apparaissent dans des panneaux distincts.
Une fois notre structure d'interface utilisateur en place, nous pouvons créer notre fonction d'call_model() ation du modèle principal :
def call_model(messages: List[Dict], model_name: str = "gpt-oss:20b", temperature: float = 1.0) -> Dict[str, Any]:
try:
start_time = time.time()
# Prepare options for Ollama
options = {
'temperature': temperature,
'top_p': 1.0,
}
response = ollama.chat(
model=model_name,
messages=messages,
options=options
)
end_time = time.time()
if isinstance(response, dict) and 'message' in response:
content = response['message'].get('content', '')
elif hasattr(response, 'message'):
content = getattr(response.message, 'content', '')
else:
content = str(response)
return {
'content': content,
'response_time': end_time - start_time,
'success': True
}
except Exception as e:
return {
'content': f"Error: {e}",
'response_time': 0,
'success': False
}Le code ci-dessus :
start_time et end_time autour de l'appel ollama.chat() afin de communiquer les temps de réponse à l'utilisateur.call_model() » encapsule l'appel entier dans un bloc « e try/except » afin de détecter les erreurs.Afin de garantir la transparence totale de notre démonstration, il est nécessaire de séparer le « monologue intérieur » du modèle de son verdict final. La fonction parse_reasoning_response() effectue exactement cette opération :
def parse_reasoning_response(content: str) -> Dict[str, str]:
patterns = [
r"<thinking>(.*?)</thinking>",
r"Let me think.*?:(.*?)(?=\n\n|\nFinal|Answer:)",
r"Reasoning:(.*?)(?=\n\n|\nAnswer:|\nConclusion:)",
]
reasoning = ""
answer = content
for pat in patterns:
m = re.search(pat, content, re.DOTALL | re.IGNORECASE)
if m:
reasoning = m.group(1).strip()
answer = content.replace(m.group(0), "").strip()
break
if not reasoning and len(content.split('\n')) > 3:
lines = content.split('\n')
for i, l in enumerate(lines):
if any(k in l.lower() for k in ['therefore', 'in conclusion', 'final answer', 'answer:']):
reasoning = '\n'.join(lines[:i]).strip()
answer = '\n'.join(lines[i:]).strip()
break
return {
'reasoning': reasoning or "No explicit reasoning detected.",
'answer': answer or content
}Nous séparons le « raisonnement » caché du modèle de son verdict final afin que les utilisateurs puissent, s'ils le souhaitent, inspecter chaque étape du raisonnement. Voici comment la réponse est analysée :
… ou des expressions telles que « Raisonnement : » et « Laissez-moi réfléchir » à l'aide d'expressions régulières.parse_reasoning_response() » renvoie toujours une réponse.Maintenant que nous avons construit chaque élément constitutif, nous allons les assembler pour créer une application de chat interactive.
# Initialize history
if 'history' not in st.session_state:
st.session_state.history = []
# Sidebar for settings
with st.sidebar:
st.header("Configuration")
model_choice = st.selectbox(
"Model",
["gpt-oss:20b", "gpt-oss:120b"],
help="Choose between 20B (faster) or 120B (more capable)"
)
effort = st.selectbox(
"Reasoning Effort",
["low", "medium", "high"],
index=1,
help="Controls depth of reasoning shown"
)
temperature = st.slider(
"Temperature",
0.0, 2.0, 1.0, 0.1,
help="Controls response randomness"
)
show_reasoning = st.checkbox(
"Show Chain-of-Thought",
True,
help="Display model's thinking process"
)
show_metrics = st.checkbox(
"Show Performance Metrics",
True,
help="Display response time and model info"
)
st.markdown("---")
if st.button("Clear Conversation"):
st.session_state.history = []
st.rerun()
# Main Chat Interface
st.title("💬 GPT-OSS Interactive Chat")
examples = [
"",
"If a train travels 120km in 1.5 hours, then 80km in 45 minutes, what's its average speed?",
"Prove that √2 is irrational.",
"Write a function to find the longest palindromic substring.",
"Explain quantum entanglement in simple terms.",
"How would you design a recommendation system?",
]
selected_from_dropdown = st.selectbox("Choose from examples:", examples)
# Get the question text
question_value = ""
if hasattr(st.session_state, 'selected_example'):
question_value = st.session_state.selected_example
del st.session_state.selected_example
elif selected_from_dropdown:
question_value = selected_from_dropdown
question = st.text_area(
"Or Enter your question:",
value=question_value,
height=100,
placeholder="Ask anything! Try different reasoning effort levels to see how the model's thinking changes..."
)
# Submit button
col1, col2 = st.columns([1, 4])
with col1:
submit_button = st.button("Ask GPT-OSS", type="primary")
if submit_button and question.strip():
# System prompts
system_prompts = {
'low': 'You are a helpful assistant. Provide concise, direct answers.',
'medium': f'You are a helpful assistant. Show brief reasoning before your answer. Reasoning effort: {effort}',
'high': f'You are a helpful assistant. Show complete chain-of-thought reasoning step by step. Think through the problem carefully before providing your final answer. Reasoning effort: {effort}'
}
# Message history
msgs = [{'role': 'system', 'content': system_prompts[effort]}]
msgs.extend(st.session_state.history[-6:])
msgs.append({'role': 'user', 'content': question})
with st.spinner(f"GPT-OSS thinking ({effort} effort)..."):
res = call_model(msgs, model_choice, temperature)
if res['success']:
parsed = parse_reasoning_response(res['content'])
st.session_state.history.append({'role': 'user', 'content': question})
st.session_state.history.append({'role': 'assistant', 'content': res['content']})
col1, col2 = st.columns([3, 1] if show_metrics else [1])
with col1:
if show_reasoning and parsed['reasoning'] != 'No explicit reasoning detected.':
st.markdown("### Chain-of-Thought Reasoning")
st.markdown(f"<div class='reasoning-box'>{parsed['reasoning']}</div>", unsafe_allow_html=True)
st.markdown("### Answer")
st.markdown(f"<div class='answer-box'>{parsed['answer']}</div>", unsafe_allow_html=True)
if show_metrics:
with col2:
st.markdown(f"""
<div class="metric-card">
<h4> Metrics</h4>
<p><strong>Time:</strong><br>{res['response_time']:.2f}s</p>
<p><strong>Model:</strong><br>{model_choice}</p>
<p><strong>Effort:</strong><br>{effort.title()}</p>
</div>
""", unsafe_allow_html=True)
else:
st.error(f"{res['content']}")
if st.session_state.history:
st.markdown("---")
st.subheader("Conversation History")
recent_history = st.session_state.history[-8:] # Last 8 messages (4 exchanges)
for i, msg in enumerate(recent_history):
if msg['role'] == 'user':
st.markdown(f"""
<div class="chat-message user-message">
<strong>You:</strong> {msg['content']}
</div>
""", unsafe_allow_html=True)
else:
parsed_hist = parse_reasoning_response(msg['content'])
with st.expander(f"GPT-OSS Response", expanded=False):
if parsed_hist['reasoning'] != 'No explicit reasoning detected.':
st.markdown("**Reasoning Process:**")
st.code(parsed_hist['reasoning'], language='text')
st.markdown("**Final Answer:**")
st.markdown(parsed_hist['answer'])
# Footer
st.markdown("---")
st.markdown("""
<div style='text-align: center;'>
<p><strong>Powered by GPT-OSS-20B via Ollama</strong></p>
</div>
""", unsafe_allow_html=True)Dans cette dernière étape, nous rassemblons tous les éléments de notre application, y compris l'état de la session, les commandes de la barre latérale, les exemples d'invites, l'assemblage des messages, l'invocation du modèle, l'analyse et l'affichage, dans une seule boucle :
st.session_state.history pour mémoriser chaque échange entre l'utilisateur et l'assistant lors des rediffusions.call_model(), qui :parse_reasoning_response() », nous avons divisé la sortie du modèle en une réponse sous forme de chaîne de pensées appelée « raisonnement » et une réponse épurée appelée « réponse ».st.session_state.history, afin que la prochaine exécution puisse les inclure pour le contexte.Pour l'essayer vous-même, enregistrez le code sous le nom gpt_oss_demo.py et lancez :
streamlit run gpt_oss_demo.pyApprenez l'IA grâce à ces cours !
Cours
Cours
Cours