Cours
Introduction à PySpark
4 h
157.5K
PySpark est une interface pour Apache Spark en Python. Avec PySpark, vous pouvez écrire des commandes Python et SQL pour manipuler et analyser des données dans un environnement de traitement distribué. Pour apprendre les bases du langage, vous pouvez suivre le cours Introduction à PySpark de Datacamp. Il s'agit d'un programme pour débutants qui vous permettra de manipuler des données, de construire des pipelines d'apprentissage automatique et de mettre au point des modèles avec PySpark.
La plupart des scientifiques et analystes de données connaissent Python et l'utilisent pour mettre en œuvre des flux de travail d'apprentissage automatique. PySpark leur permet de travailler avec un langage familier sur des ensembles de données distribuées à grande échelle.
Apache Spark peut également être utilisé avec d'autres langages de programmation de la science des données comme R. Si cela vous intéresse, le cours Introduction à Spark avec sparklyr dans R est un excellent point de départ.
Les entreprises qui collectent des téraoctets de données disposeront d'un cadre de big data tel qu'Apache Spark. Pour travailler avec ces ensembles de données à grande échelle, la connaissance des cadres Python et R ne suffit pas.
Vous devez apprendre un cadre qui vous permet de manipuler des ensembles de données au-dessus d'un système de traitement distribué, car la plupart des organisations axées sur les données vous demanderont de le faire. PySpark est un excellent point de départ, car sa syntaxe est simple et peut être assimilée facilement si vous êtes déjà familiarisé avec Python.
La raison pour laquelle les entreprises choisissent d'utiliser un cadre comme PySpark est la rapidité avec laquelle il peut traiter les données volumineuses. Il est plus rapide que des bibliothèques comme Pandas et Dask, et peut traiter de plus grandes quantités de données que ces frameworks. Si vous aviez plus de pétaoctets de données à traiter, par exemple, Pandas et Dask échoueraient, mais PySpark serait en mesure de les traiter facilement.
Bien qu'il soit également possible d'écrire du code Python au-dessus d'un système distribué comme Hadoop, de nombreuses organisations choisissent d'utiliser Spark à la place et d'utiliser l'API PySpark car elle est plus rapide et peut traiter des données en temps réel. Avec PySpark, vous pouvez écrire du code pour collecter des données à partir d'une source continuellement mise à jour, alors que les données ne peuvent être traitées qu'en mode batch avec Hadoop.
Apache Flink est un système de traitement distribué qui dispose d'une API Python appelée PyFlink, et qui est en fait plus rapide que Spark en termes de performances. Cependant, Apache Spark existe depuis plus longtemps et bénéficie d'un meilleur soutien de la communauté, ce qui signifie qu'il est plus fiable.
En outre, PySpark offre une tolérance aux pannes, ce qui signifie qu'il a la capacité de récupérer les pertes après une panne. Le cadre dispose également d'un calcul en mémoire et est stocké dans une mémoire vive (RAM). Il peut fonctionner sur une machine qui n'a pas de disque dur ou de disque SSD installé.
Pré-requis :
Avant d'installer Apache Spark et PySpark, vous devez avoir installé les logiciels suivants sur votre appareil :
Si vous n'avez pas encore installé Python, suivez notre guide d'installation pour développeurs Python pour le configurer avant de passer à l'étape suivante.
Ensuite, suivez ce tutoriel pour installer Java sur votre ordinateur si vous utilisez Windows. Voici un guide d'installation pour MacOs, et en voici un pour Linux.
Un carnet Jupyter est une application web que vous pouvez utiliser pour écrire du code et afficher des équations, des visualisations et du texte. C'est l'un des éditeurs de programmation les plus utilisés par les data scientists. Nous utiliserons un Notebook Jupyter pour écrire tout le code PySpark dans ce tutoriel, assurez-vous donc de l'avoir installé.
Vous pouvez suivre notre tutoriel pour faire fonctionner Jupyter sur votre appareil local ou utiliser un IDE en ligne, basé sur le cloud, comme DataLab construit par DataCamp, qui est livré avec PySpark préinstallé.
Nous utiliserons l'ensemble de données de Datacamp sur le commerce électronique pour toutes les analyses de ce tutoriel, assurez-vous donc de l'avoir téléchargé. Nous avons renommé le fichier en "datacamp_ecommerce.csv" et l'avons enregistré dans le répertoire parent, et vous pouvez faire de même pour faciliter le codage.
Maintenant que tous les prérequis sont en place, vous pouvez procéder à l'installation d'Apache Spark et de PySpark. Vous pouvez sauter cette étape si vous utilisez DataLab.
Pour installer Apache Spark, rendez-vous sur lapage de téléchargement et téléchargez le fichier .tgz affiché sur la page :
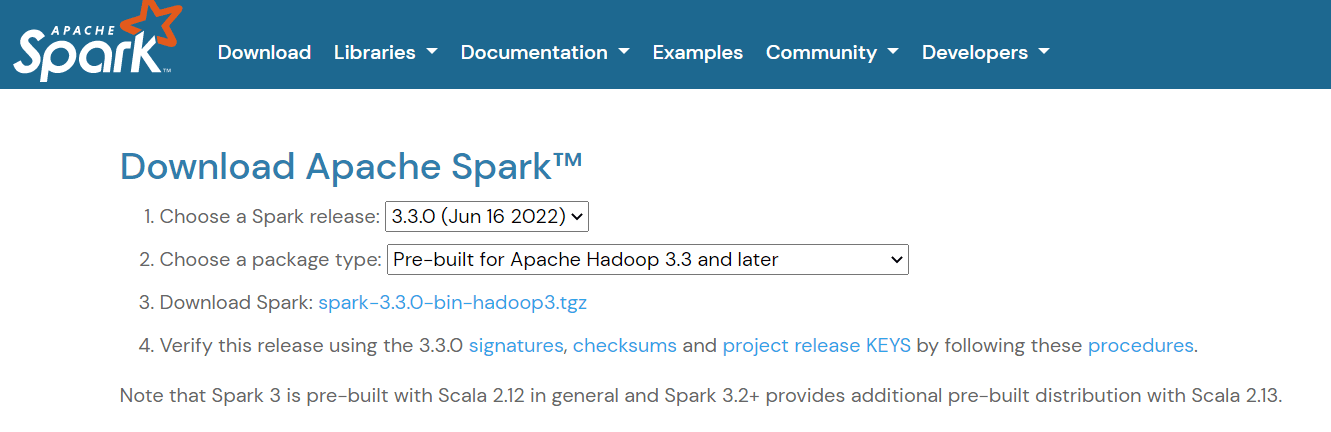
Ensuite, si vous utilisez Windows, créez un dossier dans votre répertoire C appelé "spark". Si vous utilisez Linux ou Mac, vous pouvez le coller dans un nouveau dossier de votre répertoire personnel.
Ensuite, extrayez le fichier que vous venez de télécharger et collez son contenu dans ce dossier "spark". Voici à quoi doit ressembler le chemin d'accès au dossier :

Vous devez maintenant définir vos variables d'environnement. Vous pouvez procéder de deux manières :
Méthode 1 : Modification des variables d'environnement à l'aide de Powershell
Si vous utilisez une machine Windows, la première façon de modifier vos variables d'environnement est d'utiliser Powershell :
Étape 1 : Cliquez sur Démarrer -> Windows Powershell -> Exécuter en tant qu'administrateur
Étape 2 : Saisissez la ligne suivante dans Windows Powershell pour définir SPARK_HOME :
setx SPARK_HOME "C:\spark\spark-3.3.0-bin-hadoop3" # change this to your pathÉtape 3 : Ensuite, définissez votre répertoire bin de Spark comme variable de chemin :
setx PATH "C:\spark\spark-3.3.0-bin-hadoop3\bin"Méthode 2 : Modification manuelle des variables d'environnement
Étape 1 : Accédez à Démarrer -> Système -> Paramètres -> Paramètres avancés
Étape 2 : Cliquez sur Variables d'environnement
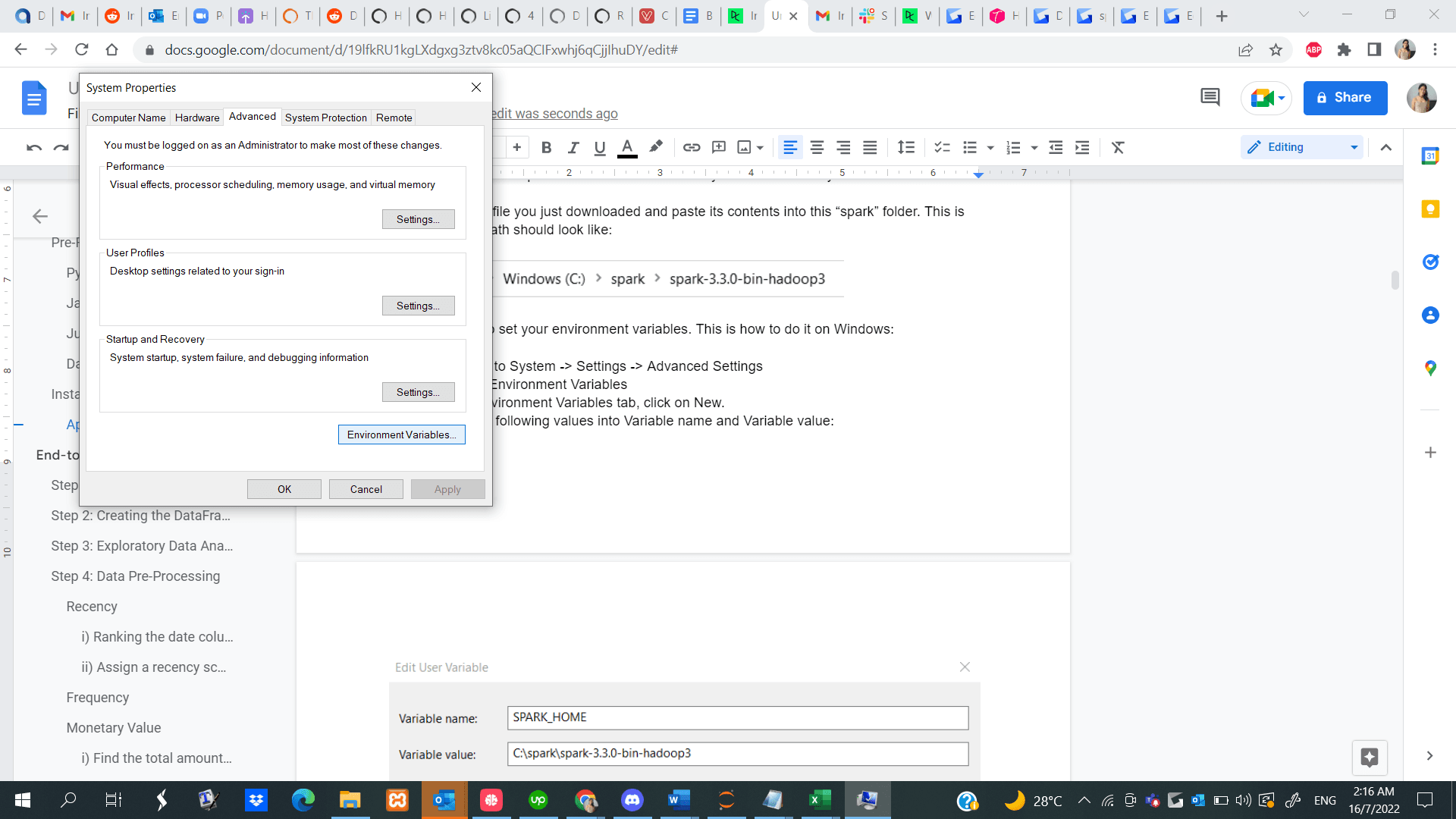
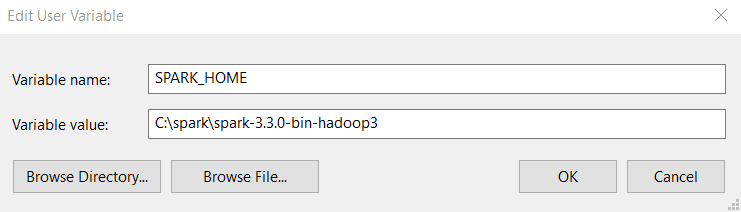
Étape 3 : Dans l'onglet Variables d'environnement, cliquez sur Nouveau.
Étape 4 : Saisissez les valeurs suivantes dans Nom de la variable et Valeur de la variable. Notez que la version que vous installez peut être différente de celle montrée ci-dessous, alors copiez et collez le chemin d'accès à votre répertoire Spark.
Étape 5 : Ensuite, dans l'onglet Variables d'environnement, cliquez sur Chemin et sélectionnez Modifier.
Étape 6 : Cliquez sur New et collez le chemin d'accès à votre répertoire bin de Spark. Voici un exemple de ce à quoi ressemble le répertoire bin :
C:\spark\spark-3.3.0-bin-hadoop3\binVous trouverez ici un guide sur la définition des variables d'environnement si vous utilisez un appareil Linux, et un autre pour MacOS.
Maintenant que vous avez installé Apache Spark et tous les autres prérequis nécessaires, ouvrez un fichier Python dans votre Notebook Jupyter et exécutez les lignes de code suivantes dans la première cellule :
!pip install pysparkVous pouvez également suivre ce guide d'installation de PySpark de bout en bout pour installer le logiciel sur votre appareil.
Maintenant que PySpark est opérationnel, nous allons vous montrer comment exécuter un projet de segmentation de la clientèle de bout en bout à l'aide de la bibliothèque.
La segmentation de la clientèle est une technique de marketing utilisée par les entreprises pour identifier et regrouper les utilisateurs qui présentent des caractéristiques similaires. Par exemple, si vous ne vous rendez chez Starbucks qu'en été pour acheter des boissons fraîches, vous pouvez être segmenté en tant qu'"acheteur saisonnier" et être attiré par des promotions spéciales conçues pour la saison estivale.
Les scientifiques des données élaborent généralement des algorithmes d'apprentissage automatique non supervisés, tels que le regroupement K-Means ou le regroupement hiérarchique, pour effectuer la segmentation des clients. Ces modèles sont excellents pour identifier des modèles similaires entre les groupes d'utilisateurs qui passent souvent inaperçus à l'œil nu.
Dans ce tutoriel, nous utiliserons le regroupement K-Means pour effectuer une segmentation de la clientèle sur l'ensemble de données de commerce électronique que nous avons téléchargé plus tôt.
À la fin de ce tutoriel, vous serez familiarisé avec les concepts suivants :
Exécutez et modifiez le code de ce tutoriel en ligne
Exécuter le codeUne SparkSession est un point d'entrée dans toutes les fonctionnalités de Spark, et est nécessaire si vous voulez construire un dataframe dans PySpark. Exécutez les lignes de code suivantes pour initialiser une SparkSession :
spark = SparkSession.builder.appName("Datacamp Pyspark Tutorial").config("spark.memory.offHeap.enabled","true").config("spark.memory.offHeap.size","10g").getOrCreate()À l'aide des codes ci-dessus, nous avons créé une session spark et défini un nom pour l'application. Ensuite, les données ont été mises en cache dans la mémoire hors tas pour éviter de les stocker directement sur le disque, et la quantité de mémoire a été spécifiée manuellement.
Nous pouvons maintenant lire le jeu de données que nous venons de télécharger :
df = spark.read.csv('datacamp_ecommerce.csv',header=True,escape="\"")Notez que nous avons défini un caractère d'échappement pour éviter les virgules dans le fichier .csv lors de l'analyse.
Jetons un coup d'œil à la tête du cadre de données à l'aide de la fonction show() :
df.show(5,0)La base de données se compose de 8 variables :
Maintenant que nous avons vu les variables présentes dans cet ensemble de données, effectuons une analyse exploratoire des données pour mieux comprendre ces points de données :
df.count() # Answer: 2,500df.select('CustomerID').distinct().count() # Answer: 95 pays proviennent la plupart des achats ?
pays proviennent la plupart des achats ?Pour trouver le pays dans lequel la plupart des achats sont effectués, nous devons utiliser la clause groupBy() de PySpark :
from pyspark.sql.functions import *
from pyspark.sql.types import *
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).show()Le tableau suivant sera affiché après l'exécution des codes ci-dessus :

La quasi-totalité des achats effectués sur la plateforme l'ont été à partir du Royaume-Uni, et une poignée seulement à partir de pays comme l'Allemagne, l'Australie et la France.
Remarquez que les données du tableau ci-dessus ne sont pas présentées dans l'ordre des achats. Pour trier ce tableau, nous pouvons inclure la clause orderBy() :
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()Les résultats affichés sont désormais triés par ordre décroissant :

Pour savoir quand le dernier achat a été effectué sur la plateforme, nous devons convertir la colonne "InvoiceDate" en un format d'horodatage et utiliser la fonction max() de Pyspark :
spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")
df = df.withColumn('date',to_timestamp("InvoiceDate", 'yy/MM/dd HH:mm'))
df.select(max("date")).show()Vous devriez voir apparaître le tableau suivant après avoir exécuté le code ci-dessus :
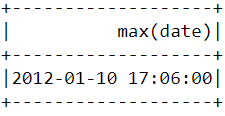
Comme nous l'avons fait ci-dessus, la fonction min() peut être utilisée pour trouver la date et l'heure d'achat les plus proches :
df.select(min("date")).show()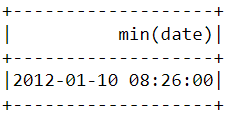
Remarquez que les achats les plus récents et les plus anciens ont été effectués le même jour, à quelques heures d'intervalle. Cela signifie que l'ensemble de données que nous avons téléchargé ne contient des informations que sur les achats effectués au cours d'une seule journée.
Maintenant que nous avons analysé l'ensemble des données et que nous avons une meilleure compréhension de chaque point de données, nous devons préparer les données pour alimenter l'algorithme d'apprentissage automatique.
Examinons à nouveau l'en-tête du cadre de données pour comprendre comment le prétraitement sera effectué :
df.show(5,0)
À partir de l'ensemble de données ci-dessus, nous devons créer plusieurs segments de clients en fonction du comportement d'achat de chaque utilisateur.
Les variables de cet ensemble de données sont dans un format qui ne peut pas être facilement intégré dans le modèle de segmentation de la clientèle. Prises individuellement, ces caractéristiques ne nous apprennent pas grand-chose sur le comportement d'achat des clients.
C'est pourquoi nous utiliserons les variables existantes pour obtenir trois nouvelles caractéristiques informatives : la récence, la fréquence et la valeur monétaire (RFM).
Le RFM est couramment utilisé dans le domaine du marketing pour évaluer la valeur d'un client sur la base de ses caractéristiques :
Nous allons maintenant prétraiter la base de données pour créer les variables ci-dessus.
Tout d'abord, calculons la valeur de la récence, c'est-à-dire la date et l'heure les plus récentes auxquelles un achat a été effectué sur la plateforme. Cela peut se faire en deux étapes :
Nous soustrayons chaque date de la base de données à la date la plus ancienne. Cela nous permettra de savoir depuis combien de temps un client a été vu dans le cadre de données. Une valeur de 0 indique la récence la plus faible, car elle sera attribuée à la personne qui a été vue en train d'effectuer un achat à la date la plus proche.
df = df.withColumn("from_date", lit("12/1/10 08:26"))
df = df.withColumn('from_date',to_timestamp("from_date", 'yy/MM/dd HH:mm'))
df2 = df.withColumn('from_date',to_timestamp(col('from_date'))).withColumn('recency',col("date").cast("long") - col('from_date').cast("long"))Un client peut effectuer plusieurs achats à des moments différents. Nous devons sélectionner uniquement la dernière fois qu'ils ont été vus en train d'acheter un produit, car cela indique le moment où l'achat le plus récent a été effectué :
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')Regardons l'en-tête du nouveau cadre de données. Une variable appelée "recency" lui est désormais associée :
df2.show(5,0)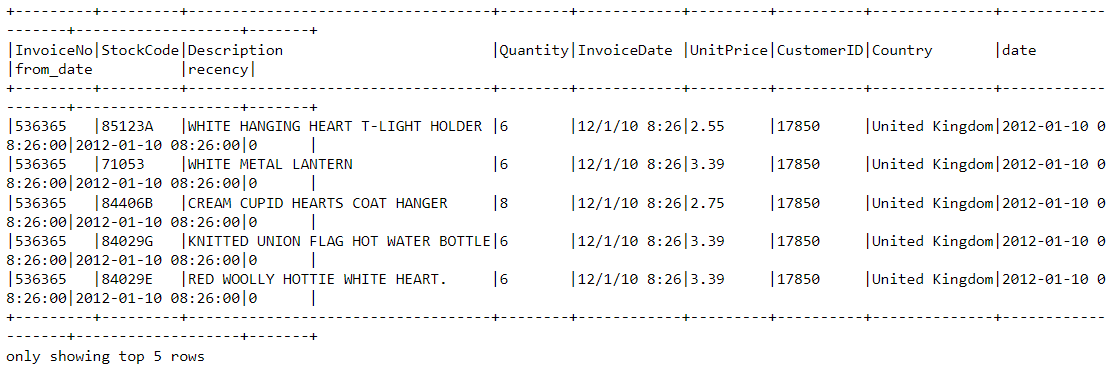
Un moyen plus simple de visualiser toutes les variables présentes dans un dataframe PySpark est d'utiliser la fonction printSchema(). C'est l'équivalent de la fonction info() dans Pandas :
df2.printSchema()Le résultat obtenu devrait ressembler à ceci :

Calculons maintenant la valeur de la fréquence - combien de fois un client a acheté quelque chose sur la plateforme. Pour ce faire, il suffit de regrouper chaque client par son numéro d'identification et de compter le nombre d'articles qu'il a achetés :
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))Regardez la tête de ce nouveau cadre de données que nous venons de créer :
df_freq.show(5,0)
Une valeur de fréquence est ajoutée à chaque client dans la base de données. Ce nouveau cadre de données ne comporte que deux colonnes et nous devons le joindre au précédent :
df3 = df2.join(df_freq,on='CustomerID',how='inner')Imprimons le schéma de ce cadre de données :
df3.printSchema()
Enfin, calculons la valeur monétaire, c'est-à-dire le montant total dépensé par chaque client dans le cadre de données. Il y a deux étapes pour y parvenir :
Chaque identifiant de client est accompagné de variables appelées "Quantité" et "Prix unitaire" pour un achat unique :

Pour obtenir le montant total dépensé par chaque client en un seul achat, nous devons multiplier la "Quantité" par le "Prix unitaire" :
m_val = df3.withColumn('TotalAmount',col("Quantity") * col("UnitPrice"))Pour connaître le montant total dépensé par chaque client, il suffit de regrouper les données en fonction de la colonne CustomerID et de faire la somme des montants totaux dépensés :
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))Fusionnez ce cadre de données avec toutes les autres variables :
finaldf = m_val.join(df3,on='CustomerID',how='inner')Maintenant que nous avons créé toutes les variables nécessaires à la construction du modèle, exécutez les lignes de code suivantes pour sélectionner uniquement les colonnes requises et supprimer les lignes dupliquées de la base de données :
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()Examinez l'en-tête du cadre de données final pour vous assurer que le prétraitement a été effectué avec précision :

Avant de construire le modèle de segmentation de la clientèle, normalisons le cadre de données afin de nous assurer que toutes les variables se situent à la même échelle :
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import StandardScaler
assemble=VectorAssembler(inputCols=[
'recency','frequency','monetary_value'
], outputCol='features')
assembled_data=assemble.transform(finaldf)
scale=StandardScaler(inputCol='features',outputCol='standardized')
data_scale=scale.fit(assembled_data)
data_scale_output=data_scale.transform(assembled_data)Exécutez les lignes de code suivantes pour voir à quoi ressemble le vecteur de caractéristiques normalisé :
data_scale_output.select('standardized').show(2,truncate=False)
Ce sont les caractéristiques mises à l'échelle qui seront introduites dans l'algorithme de regroupement.
Si vous souhaitez en savoir plus sur la préparation des données avec PySpark, suivez ce cours d'ingénierie des fonctionnalités sur Datacamp.
Maintenant que nous avons terminé l'analyse et la préparation des données, construisons le modèle de regroupement K-Means.
L'algorithme sera créé à l'aide de l'API d'apprentissage automatique de PySpark.
Lors de l'élaboration d'un modèle de regroupement K-Means, nous devons d'abord déterminer le nombre de grappes ou de groupes que l'algorithme doit renvoyer. Si nous optons pour trois groupes, par exemple, nous aurons trois segments de clientèle.
La technique la plus répandue pour déterminer le nombre de grappes à utiliser dans le cadre de la méthode K-Means est appelée "méthode du coude".
Pour ce faire, il suffit d'exécuter l'algorithme K-Means pour un large éventail de grappes et de visualiser les résultats du modèle pour chaque grappe. Le graphique aura un point d'inflexion qui ressemblera à un coude, et nous choisirons simplement le nombre de grappes à ce point.
Lisez ce tutoriel Datacamp sur le clustering K-Means pour en savoir plus sur le fonctionnement de l'algorithme.
Exécutons les lignes de code suivantes pour construire un algorithme de regroupement K-Means de 2 à 10 groupes :
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(predictionCol='prediction', featuresCol='standardized',metricName='silhouette', distanceMeasure='squaredEuclidean')
for i in range(2,10):
KMeans_algo=KMeans(featuresCol='standardized', k=i)
KMeans_fit=KMeans_algo.fit(data_scale_output)
output=KMeans_fit.transform(data_scale_output)
cost[i] = KMeans_fit.summary.trainingCostAvec les codes ci-dessus, nous avons construit et évalué avec succès un modèle de regroupement K-Means avec 2 à 10 groupes. Les résultats ont été placés dans un tableau et peuvent maintenant être visualisés dans un graphique linéaire :
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost[2:])
df_cost.columns = ["cost"]
new_col = range(2,10)
df_cost.insert(0, 'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()Les codes ci-dessus permettent d'obtenir le tableau suivant :
Le graphique ci-dessus montre qu'il existe un point d'inflexion qui ressemble à un coude à quatre. C'est pourquoi nous allons construire l'algorithme K-Means avec quatre grappes :
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)Utilisons le modèle que nous avons créé pour attribuer des grappes à chaque client de l'ensemble de données :
preds=KMeans_fit.transform(data_scale_output)
preds.show(5,0)Remarquez qu'il y a une colonne "prédiction" dans ce cadre de données qui nous indique à quel groupe appartient chaque identifiant de client :

La dernière étape de ce tutoriel consiste à analyser les segments de clientèle que nous venons de créer.
Exécutez les lignes de code suivantes pour visualiser la récence, la fréquence et la valeur monétaire de chaque identifiant de client dans le cadre de données :
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
list1 = ['recency','frequency','monetary_value']
for i in list1:
sns.barplot(x='prediction',y=str(i),data=avg_df)
plt.show()Les codes ci-dessus permettent d'obtenir les graphiques suivants :
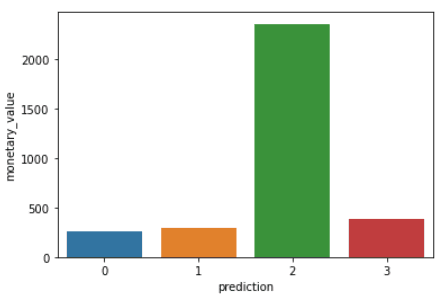
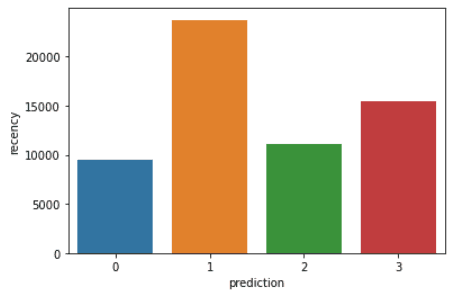
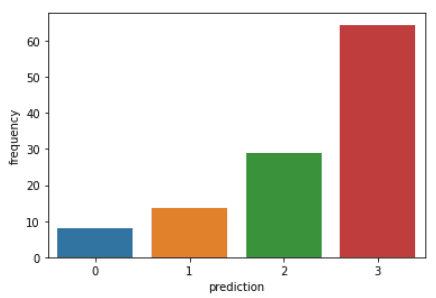
Voici un aperçu des caractéristiques affichées par les clients de chaque groupe :
Pour aller au-delà des concepts de modélisation prédictive couverts dans ce cours, vous pouvez suivre le cours Machine Learning with PySpark sur Datacamp.
Si vous avez réussi à suivre l'intégralité de ce tutoriel PySpark, félicitations ! Vous avez maintenant installé PySpark sur votre appareil local, analysé un ensemble de données sur le commerce électronique et construit un algorithme d'apprentissage automatique à l'aide du framework.
L'analyse ci-dessus comporte une mise en garde : elle a été réalisée à partir de 2 500 lignes de données sur le commerce électronique collectées en une seule journée. Le résultat de cette analyse pourrait être consolidé si nous disposions d'une plus grande quantité de données, car les techniques telles que la modélisation RFM sont généralement appliquées à des mois de données historiques.
Cependant, vous pouvez appliquer les principes appris dans cet article à une grande variété d'ensembles de données plus importants dans le domaine de l'apprentissage automatique non supervisé.
Consultez cet aide-mémoire de Datacamp pour en savoir plus sur la syntaxe de PySpark et ses modules.
Enfin, si vous souhaitez aller au-delà des concepts abordés dans ce tutoriel et apprendre les bases de la programmation avec PySpark, vous pouvez suivre le parcours d'apprentissage Big Data avec PySpark sur Datacamp. Ce parcours contient une série de cours qui vous apprendront à faire ce qui suit avec PySpark :
Comme vous l'avez vu tout au long de ce tutoriel, la maîtrise de PySpark et du traitement distribué des données est essentielle pour traiter les ensembles de données à grande échelle qui sont de plus en plus courants dans le monde moderne. Pour les entreprises qui gèrent des téraoctets, voire des pétaoctets de données, le fait de disposer d'une équipe maîtrisant PySpark peut considérablement améliorer votre capacité à obtenir des informations exploitables et à conserver un avantage concurrentiel.
Cependant, rester au fait des dernières technologies et des meilleures pratiques peut s'avérer difficile, en particulier pour les équipes qui travaillent dans des environnements en constante évolution. C'est là que DataCamp for Business peut faire la différence. DataCamp for Business fournit à votre équipe les outils et la formation dont elle a besoin pour rester à la pointe de la science et de l'ingénierie des données.
Grâce à des parcours d'apprentissage personnalisés comprenant des cours tels que Introduction à PySpark et Big Data avec PySpark, les membres de votre équipe peuvent passer du statut de débutant à celui d'expert, en apprenant à manipuler, traiter et analyser les big data avec PySpark. Les parcours d'apprentissage interactifs et les projets réels de la plateforme garantissent que votre équipe ne se contente pas d'apprendre la théorie, mais acquiert également une expérience pratique qu'elle peut appliquer immédiatement dans son travail.
Incorporer DataCamp dans la stratégie d'apprentissage de votre équipe signifie que votre organisation sera toujours équipée des dernières compétences nécessaires pour relever les défis complexes du big data. Qu'il s'agisse de créer des pipelines d'apprentissage automatique ou d'effectuer des analyses de données à grande échelle, votre équipe sera prête à tout gérer. Demandez une démonstration dès aujourd'hui pour en savoir plus.
Cours de visualisation de données
Cours
Cours
Cours
Tutoriel
DataCamp Team
Tutoriel
Aditya Sharma
Tutoriel
Matt Crabtree
Tutoriel
Sejal Jaiswal
Tutoriel
Moez Ali
Tutoriel
Abid Ali Awan