
Cours
Entraîner efficacement des modèles d’IA avec PyTorch
4 h
1.5K
Vous connaissez peut-être déjà la segmentation d'images et de vidéos, mais la segmentation audio est un concept beaucoup moins exploré. Il s'agit de la capacité à séparer et à isoler des sons dans un flux audio, par exemple en extrayant une voix parlée de la musique de fond ou en isolant la voix d'une seule personne dans une réunion de groupe. Jusqu'à récemment, ces tâches nécessitaient des outils spécialisés et spécifiques, ainsi qu'un effort manuel considérable.
Dans ce tutoriel, nous examinerons SAM Audio, l'extension audio du modèle Segment Anything. Nous allons configurer un environnement local, installer les dépendances requises, charger le modèle et exécuter l'inférence sur un GPU RTX 3090.
Au cours de cette présentation, nous démontrerons comment SAM Audio peut segmenter avec précision des parties spécifiques d'un signal audio d'une manière beaucoup plus intuitive et cliniquement précise que les approches traditionnelles de traitement audio.
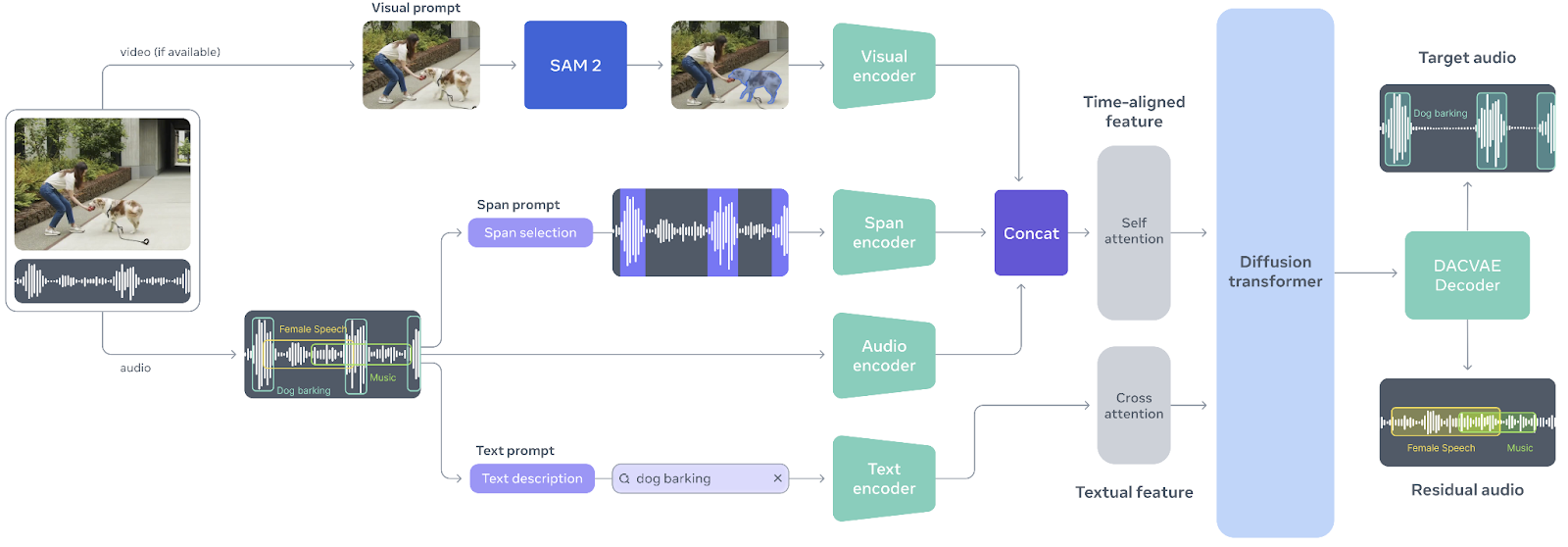
SAM Audio est un modèle multimodal unifié unique en son genre, conçu pour rendre la séparation audio aussi intuitive que l'interaction avec le son lui-même. Inspiré par le succès du modèle modèle Segment Anything en matière de vision, SAM Audio permet aux utilisateurs d'isoler n'importe quel son à partir de mélanges audio complexes à l'aide d'indications naturelles, que ce soit par le biais de texte, d'indications visuelles dans une vidéo ou en marquant des intervalles de temps. Cette approche unifiée remplace les outils audio fragmentés et à usage unique par un système unique qui fonctionne de manière fiable pour la parole, la musique et les sons généraux, même dans des scénarios réels et complexes.
Source : facebookresearch/sam-audio
Au cœur de SAM Audio se trouve Perception Encoder Audiovisual (PE-AV), un moteur puissant qui synchronise ce qui est vu avec ce qui est entendu en encodant conjointement les signaux audio et visuels dans le temps.
Basé sur le Perception Encoder open source de Meta, PE-AV fournit des représentations riches et précises dans le temps qui permettent d'obtenir des performances de pointe en matière de séparation audio multimodale.
Ensemble, SAM Audio et PE-AV ouvrent de nouvelles perspectives pour les médias créatifs, l'accessibilité et la compréhension audio, rendant la segmentation audio de qualité professionnelle plus rapide, plus accessible et plus facile à contrôler que jamais.
Je vais maintenant vous expliquer comment démarrer et utiliser SAM Audio localement.
SAM Audio est un modèle à accès restreint, ce qui signifie que vous devez demander l'autorisation avant de pouvoir le télécharger et l'utiliser localement. Veuillez commencer par consulter la page du modèle Hugging Face à l'adresse suivante : facebook/sam-audio-large et remplissez le formulaire de demande d'accès. L'approbation prend généralement environ 10 minutes, mais dans certains cas, l'accès peut être refusé en fonction de votre emplacement ou d'autres politiques appliquées par Meta.
Source : facebook/sam-audio-large · Hugging Face
Une fois l'accès accordé, veuillez lancer un notebook Jupyter local et installer la bibliothèque SAM Audio directement à partir du référentiel officiel :
!pip install -q git+https://github.com/facebookresearch/sam-audio.gitUn problème courant lors de l'utilisation de SAM Audio est le plantage ou le redémarrage inattendu du noyau Jupyter. Ceci est généralement dû à une version incompatible d'torchcodec. Pour résoudre ce problème, veuillez désinstaller la version existante et installer explicitement la version recommandée :
!pip uninstall -y torchcodec
!pip install --no-cache-dir "torchcodec==0.7.0" -f https://download.pytorch.org/whl/torchcodec/Pour accélérer le téléchargement des modèles et des dépendances, nous utiliserons hf_transfer:
!pip install hf_transferEnfin, veuillez vous connecter au Hugging Face Hub à l'aide d'un jeton d'accès. Veuillez vous assurer d'avoir généré un jeton API à partir de votre compte Hugging Face et de l'avoir enregistré en tant que variable d'environnement (HF_TOKEN) :
import os
from huggingface_hub import login
login(token=os.environ["HF_TOKEN"])Dans cette étape, nous allons télécharger et charger le modèle de base SAM Audio. Bien que SAM Audio propose également une variante plus importante, le modèle de base offre une qualité de séparation presque identique tout en étant nettement plus léger en termes de mémoire GPU.
Cela le rend beaucoup plus adapté à l'expérimentation locale, en particulier sur les GPU grand public comme le RTX 3090.
Afin d'éviter les erreurs de mémoire insuffisante (OOM), il est important de charger le modèle en FP16 (demi-précision) plutôt qu'en FP32.
La RTX 3090 offre une excellente prise en charge FP16, et le passage à la demi-précision réduit de près de moitié l'utilisation de la VRAM sans affecter de manière notable la qualité de l'inférence.
import torch
import torchaudio
from pathlib import Path
from sam_audio import SAMAudio, SAMAudioProcessor
MODEL_ID = "facebook/sam-audio-base" # base model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SAMAudio.from_pretrained(MODEL_ID).eval()
# Use fp16 on GPU to cut VRAM roughly in half (3090 supports fp16 well)
model = model.to(device=device, dtype=torch.float16).eval()
processor = SAMAudioProcessor.from_pretrained(MODEL_ID)
print("Device:", device)
print("Sampling rate:", processor.audio_sampling_rate)La première fois que vous exécutez cette opération, le téléchargement peut prendre un certain temps. SAM Audio rassemble plusieurs composants et points de contrôle qui, ensemble, forment le pipeline complet de segmentation audio, y compris l'encodeur de perception et les modules de séparation générative. Ce comportement est normal et ne se produit qu'une seule fois, car les fichiers sont mis en cache localement pour les exécutions futures.
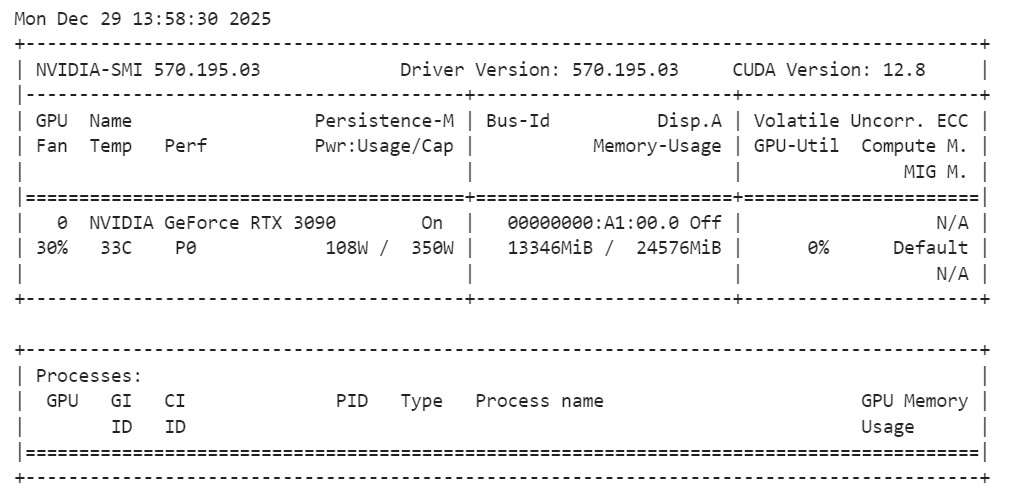
Une fois le modèle chargé, il est recommandé de vérifier l'utilisation de la mémoire GPU afin de s'assurer que tout fonctionne dans les limites :
!nvidia-smiVeuillez noter que le modèle de base SAM Audio utilise environ 14 Go de VRAM, ce qui convient parfaitement à une RTX 3090. Cela laisse suffisamment de marge pour l'inférence et l'expérimentation sans provoquer de problèmes de mémoire, ce qui rend la configuration stable et fiable pour les tâches de segmentation audio locale.
Pour évaluer SAM Audio, nous avons besoin d'un échantillon audio réaliste contenant plusieurs sources sonores qui se chevauchent. Pour ce tutoriel, nous utiliserons un exemple tiré de AudioCaps, un ensemble de données de référence largement utilisé pour la compréhension et le sous-titrage audio.
AudioCaps contient des extraits audio courts et variés, enregistrés dans des environnements réels, ce qui le rend idéal pour évaluer les modèles de séparation audio.
Nous chargeons l'ensemble de données directement depuis Hugging Face à l'aide de la bibliothèque datasets. L'échantillon audio est stocké au format Parquet et comprend à la fois des données de forme d'onde et des métadonnées telles que la fréquence d'échantillonnage.
from datasets import load_dataset
from IPython.display import Audio
# Get an example audio from AudioCaps
dset = load_dataset(
"parquet",
data_files="hf://datasets/OpenSound/AudioCaps/data/test-00000-of-00041.parquet",
)
samples = dset["train"][8]["audio"].get_all_samples()
Audio(samples.data, rate=samples.sample_rate)Ce code télécharge un seul fragment de l'ensemble de tests AudioCaps et extrait un clip audio à des fins de démonstration. Le widget Audio vous permet d'écouter le mélange brut directement dans le notebook, ce qui est utile pour comprendre la complexité de l'audio d'origine avant la segmentation. Voici comment cela se présente :
L'écoute est le moyen le plus rapide de comprendre un mixage audio, mais visualiser la forme d'onde vous aide à visualiser où les choses se produisent.
Un graphique représentant la forme d'onde permet de repérer plus facilement les moments où l'énergie est forte (comme un klaxon, un applaudissement ou un cri), les zones plus calmes (pauses ou bruit de fond) et les pics soudains qui correspondent souvent à des événements sonores brefs.
Cela s'avère particulièrement utile lorsque nous commençons à séparer les sons, car vous pouvez comparer le mélange original et la sortie segmentée et de valider rapidement si SAM Audio a effectivement extrait la bonne région.
Vous trouverez ci-dessous une fonction d'aide simple qui crée un graphique de la forme d'onde pendant une durée fixe (afin que le graphique reste lisible). Il prend en charge l'audio mono et stéréo, et transfère automatiquement les tenseurs vers le processeur afin de fonctionner de manière fluide sur un ordinateur portable.
import matplotlib.pyplot as plt
import torch
def plot_waveform(wav, sr, title="Waveform", max_seconds=15):
"""
wav: Tensor [C, T] or [T]
sr: sample rate (int)
"""
if isinstance(wav, torch.Tensor):
w = wav.detach().cpu()
else:
w = torch.tensor(wav)
if w.ndim == 1:
w = w.unsqueeze(0)
# limit duration for readability
max_samples = int(sr * max_seconds)
w = w[:, :max_samples]
t = torch.arange(w.shape[1]) / sr
plt.figure(figsize=(14, 3))
for c in range(w.shape[0]):
plt.plot(t, w[c].numpy(), label=f"ch{c}")
plt.title(title)
plt.xlabel("Time (s)")
plt.ylabel("Amplitude")
if w.shape[0] > 1:
plt.legend()
plt.tight_layout()
plt.show()
plot_waveform(samples.data, samples.sample_rate, title="Traffic noise + Horn")Dans cet exemple, vous remarquerez généralement une forme d'onde dense et chargée représentant un bruit de fond continu (trafic) et des des pics plus marqués qui correspondent souvent à des événements courts et plus forts (comme un klaxon).
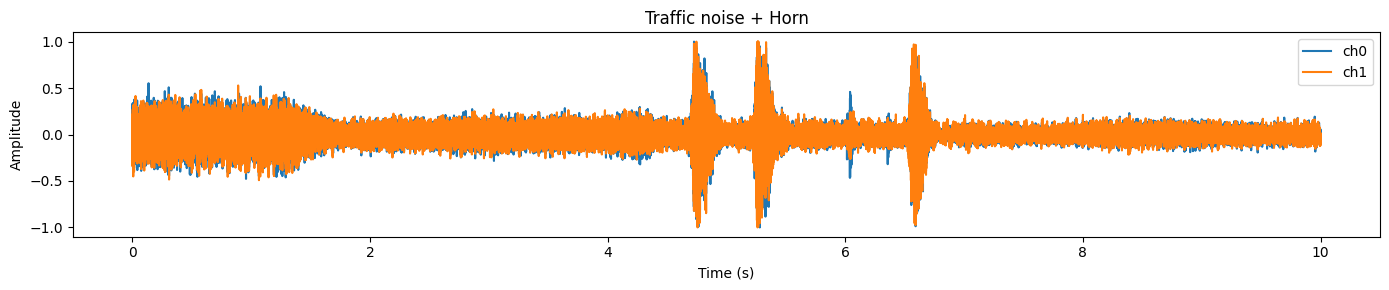
Avant de pouvoir exécuter SAM Audio, il est nécessaire de s'assurer que la forme d'onde d'entrée correspond à ce que le modèle attend. Dans la pratique, les données audio brutes issues des ensembles de données peuvent varier en termesd' , deforme, detype de données, denombre de canaux et defréquence d'échantillonnage. Si nous omettons cette étape, vous rencontrerez fréquemment des erreurs (dimensions incorrectes), obtiendrez des résultats médiocres (fréquence d'échantillonnage incorrecte) ou gaspillerez de la mémoire GPU (type de données incorrect).
Voici ce que nous allons standardiser :
C, T] (canaux en premier).float32 ) pour un traitement sécurisé, puis faire correspondre le type de données du modèle (FP16 sur CUDA).wav = torch.tensor(samples.data)
# Ensure [C, T]
if wav.ndim == 1:
wav = wav.unsqueeze(0) # [1, T]
elif wav.ndim == 2 and wav.shape[0] > wav.shape[1]:
wav = wav.transpose(0, 1) # [T, C] -> [C, T]
wav = wav.float()
orig_sr = int(samples.sample_rate)
target_sr = int(processor.audio_sampling_rate)
if orig_sr != target_sr:
wav = torchaudio.functional.resample(wav, orig_sr, target_sr)
# Mono
wav = wav.mean(0, keepdim=True) # [1, T]
# Move to device + match model dtype (FP16 on CUDA)
wav = wav.to(device=device, dtype=next(model.parameters()).dtype)
duration_s = wav.shape[-1] / target_sr
print(f"Resampled duration: {duration_s:.2f}s @ {target_sr} Hz")Si tout est correctement configuré, vous devriez obtenir un résultat similaire à celui-ci :
Resampled duration: 10.00s @ 48000 HzCela confirme (1) que la durée audio correspond à nos attentes et (2) que la forme d'onde utilise désormais la fréquence d'échantillonnage préférée du modèle.
Maintenant, voici la partie intéressante : nous allons séparer une source sonore cible du mélange audio original. SAM Audio vous permet d'effectuer cette opération à l'aide d'invites naturelles. Dans cet exemple, nous allons extraire « un klaxon » d'un clip contenant des bruits de circulation et des klaxons.
Nous utiliserons deux types de conseils simultanément :
description) : indique au modèle ce que nous souhaitons (« Un klaxon qui retentit »).anchors) : indique au modèle à quel moment la cible apparaît (en secondes).Cela rend la séparation beaucoup plus fiable, en particulier lorsque le mélange audio est complexe ou lorsque le son cible est bref.
Dans le format des ancres :
6.3, 7.0] représente la fenêtre temporelle (début, fin) en secondes.description = "A horn honking"
anchors = [[["+", 6.3, 7.0]]] # batch -> one sample -> one anchor
# (Optional) sanity-check anchors
assert 0 <= anchors[0][0][1] < anchors[0][0][2] <= duration_s + 1e-6, "Anchor out of range!"
inputs = processor(
audios=[wav],
descriptions=[description],
anchors=anchors,
).to(device)
with torch.inference_mode():
result = model.separate(inputs)
target_np = result.target[0].detach().float().cpu().numpy()
resid_np = result.residual[0].detach().float().cpu().numpy()
Audio(target_np, rate=processor.audio_sampling_rate)Lorsque cela fonctionne correctement, le résultat est véritablement impressionnant : le son cible devrait ressembler à une piste de cuivres claire, dont la plupart des bruits de fond ont été supprimés. C'est l'idée principale derrière SAM Audio : vous n'avez pas besoin de stems parfaits ni d'édition manuelle, vous guidez le modèle à l'aide d'instructions intuitives, et il isole le son pour vous. Voici comment cela se présente :
L'écoute constitue la meilleure preuve, mais la forme d'onde permet de visualiser facilement ce qui s'est produit.
plot_waveform(target_np, processor.audio_sampling_rate, title="Cleand Audio with only Horn")Dans la sortie séparée, vous remarquerez généralement des pics distincts là où se produit le klaxon, tandis que le reste de la forme d'onde reste relativement calme.
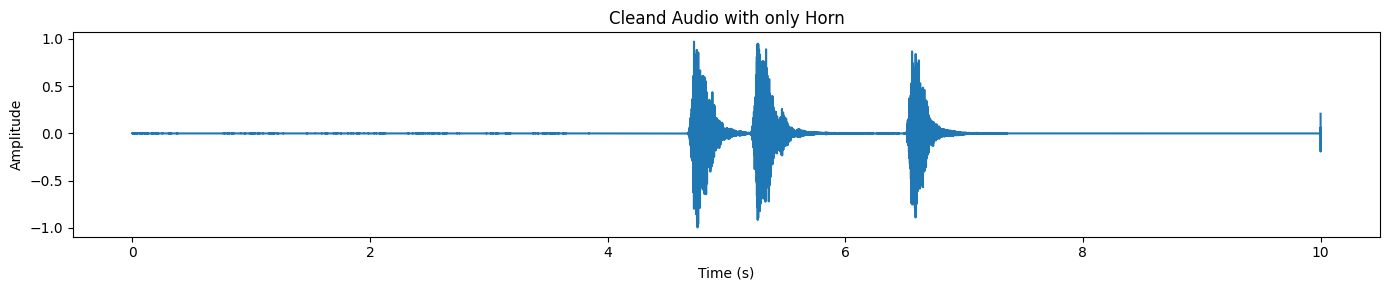
SAM Audio renvoie également une piste résiduelle, qui correspond essentiellement au « reste de l'audio » après suppression de la cible.
plot_waveform(resid_np, processor.audio_sampling_rate, title="Residual Audio with no Horn")Nous n'entendons ici que le bruit de la circulation et les bruits de fond, sans aucun klaxon.
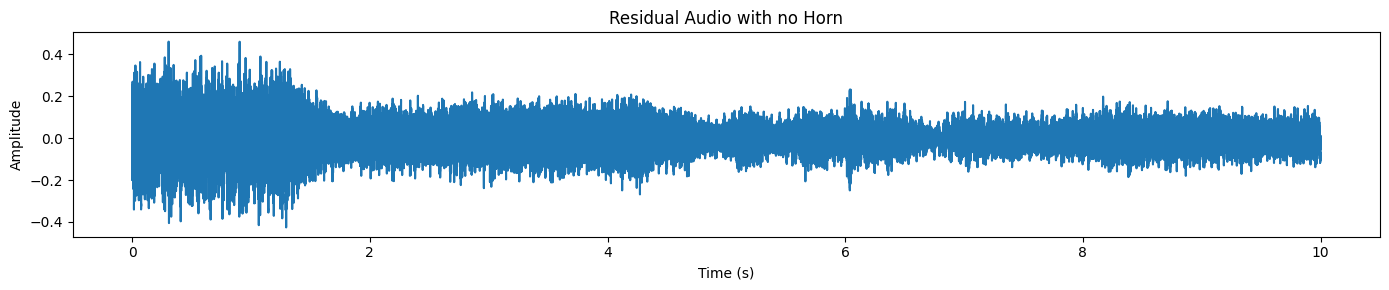
Examinons un exemple plus complexe et plus réaliste. Cette fois-ci, nous sélectionnerons un extrait dans lequel une personne non anglophone est en conversation téléphonique alors qu'il y a beaucoup de bruit de fond (bruit de la rue, ambiance, sons superposés).
C'est précisément dans ce type de situation que la séparation audio s'avère véritablement utile : la parole est présente, mais elle est difficile à comprendre en raison du mélange confus.
Tout d'abord, veuillez charger un nouvel échantillon et écouter le mélange audio brut :
samples_2 = dset["train"][45]["audio"].get_all_samples()
Audio(samples_2.data, rate=samples_2.sample_rate)Veuillez maintenant visualiser la forme d'onde.
plot_waveform(samples_2.data, samples_2.sample_rate, title="Background Noise and a Man Talking")Vous observerez un signal dense et très intense sur la majeure partie du clip, ce qui indique généralement un bruit de fond important et un chevauchement audio :
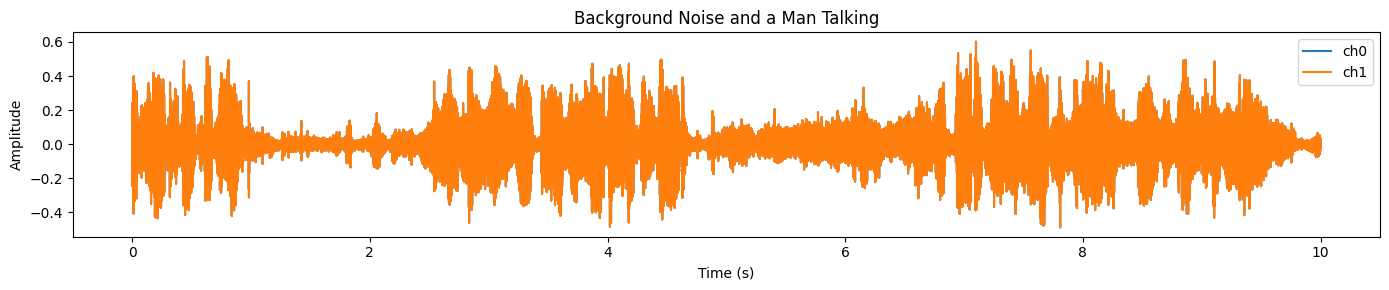
Nous exécuterons les mêmes étapes de prétraitement que précédemment : vérifier la forme [C, T], rééchantillonner à la fréquence d'échantillonnage cible du processeur, convertir en mono et transférer vers le GPU en FP16.
# Convert numpy → torch
wav = torch.tensor(samples_2.data)
# Ensure [C, T]
if wav.ndim == 1:
wav = wav.unsqueeze(0)
elif wav.ndim == 2 and wav.shape[0] > wav.shape[1]:
wav = wav.transpose(0, 1)
wav = wav.float()
orig_sr = int(samples.sample_rate)
target_sr = int(processor.audio_sampling_rate)
# Resample if needed
if orig_sr != target_sr:
wav = torchaudio.functional.resample(wav, orig_sr, target_sr)
# Mono
wav = wav.mean(0, keepdim=True)
# Move to GPU + FP16
wav = wav.to(device=device, dtype=next(model.parameters()).dtype)
duration_s = wav.shape[-1] / target_sr
print(f"Duration: {duration_s:.2f}s @ {target_sr} Hz")
Vous devriez voir quelque chose comme :
Duration: 10.00s @ 48000 HzDans l'exemple précédent, nous avons assisté le modèle à l'aide d'un ancrage temporel et d'une invite textuelle. Ici, nous allons utiliser des invites textuelles, ce qui constitue un excellent moyen de tester la capacité du modèle à généraliser sans instructions supplémentaires.
description = "A man speaking"
inputs = processor(
audios=[wav],
descriptions=[description],
).to(device)
with torch.inference_mode():
result = model.separate(inputs)
target_np = result.target[0].detach().float().cpu().numpy()
plot_waveform(target_np, processor.audio_sampling_rate, title="Clean Audio with a Man Talking")Enfin, créez un graphique de la forme d'onde de la parole séparée. Par rapport au mélange original, la forme d'onde devrait apparaître plus nette et moins « chargée », en particulier dans les zones où le bruit de fond prédominait auparavant :
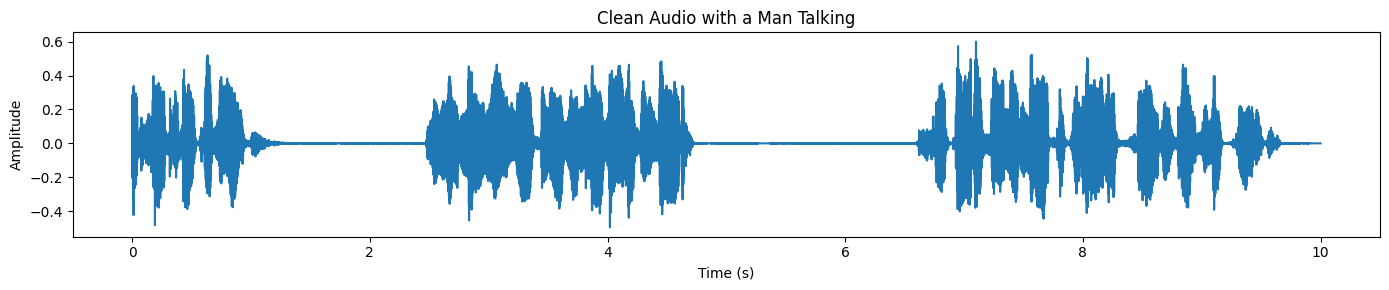
Si vous rencontrez des difficultés lors de l'exécution du code ci-dessus, veuillez consulter le cahier DataLab dont le lien figure ci-dessous pour obtenir une référence complète et fonctionnelle ainsi que des conseils supplémentaires : Utilisation locale de SAM-Audio — DataLab.
SAM Audio est conçu pour la compréhension et l'édition audio dans le monde réel. Au lieu de s'appuyer sur des outils spécifiques à certaines tâches, il utilise des invites naturelles pour séparer et isoler les sons dans les environnements vocaux, musicaux et quotidiens.
Ces fonctionnalités le rendent utile dans les flux de travail créatifs, professionnels et de recherche où un son clair et contrôlable est essentiel.
Pour être honnête, il n'existe pas beaucoup d'informations sur la manière de faire fonctionner SAM Audio localement. J'ai tenté de l'exécuter sur Kaggle avec des GPU T4, mais cela n'a pas fonctionné. J'ai également tenté d'utiliser UV et de configurer un environnement Python virtuel, mais cela n'a pas fonctionné non plus.
Le principal problème que j'ai rencontré à plusieurs reprises était lié aux conflits de dépendances. L'installation de SAM Audio directement à partir du référentiel GitHub remplace souvent les bibliothèques audio et PyTorch existantes, ce qui entraîne le plantage du noyau Jupyter.
C'est pourquoi je recommande vivement de commencer par une configuration propre à l'aide de Conda ou d'un nouvel environnement virtuel Python, en installant d'abord PyTorch et CUDA, puis en ajoutant les bibliothèques requises. Dans ce tutoriel, la configuration est devenue stable une fois que j'ai corrigé le problème en réinstallant la version appropriée d' torchcodec.
Dans ce tutoriel, nous avons exécuté avec succès le modèle de base SAM Audio sur une RTX 3090 en utilisant environ 14 Go de VRAM, ce qui est tout à fait raisonnable pour l'inférence locale. La vitesse d'inférence est rapide et la qualité de la séparation audio est véritablement remarquable. Vous pouvez également étendre cette configuration à l'invite vidéo, où SAM Audio fonctionne avec SAM 3 pour isoler l'audio en fonction d'indices visuels.
Pour en savoir plus sur SAM 3, je vous recommande de consulter notre tutoriel SAM 3.
Meilleurs cours DataCamp
Cours
Cours
Cours