
Curso
Treinamento Eficiente de Modelos de IA com PyTorch
4 h
1.5K
Você já deve estar familiarizado com a segmentação de imagens e vídeos, mas a segmentação de áudio é uma ideia muito menos explorada. É a capacidade de separar e isolar sons dentro de um fluxo de áudio, como extrair uma voz falada da música de fundo ou isolar a voz de uma única pessoa em uma reunião de grupo. Até recentemente, essas tarefas exigiam ferramentas especializadas e específicas para cada tarefa, além de um grande esforço manual.
Neste tutorial, vamos explorar o SAM Audio, a extensão de áudio do Modelo Segment Anything. Vamos configurar um ambiente local, instalar as dependências necessárias, carregar o modelo e executar a inferência em uma GPU RTX 3090.
Ao longo do caminho, vamos ver como o SAM Audio consegue segmentar com precisão partes específicas de um sinal de áudio de uma forma que parece muito mais intuitiva e clinicamente precisa do que as abordagens tradicionais de processamento de áudio.
O SAM Audio é um modelo multimodal unificado, o primeiro do tipo, feito pra tornar a separação de áudio tão intuitiva quanto interagir com o próprio som. Inspirado no sucesso do Modelo Segment Anything na visão, o SAM Audio permite que os usuários isolem qualquer som de misturas complexas de áudio usando comandos naturais, seja por meio de texto, dicas visuais em vídeo ou marcando intervalos de tempo. Essa abordagem unificada substitui as ferramentas de áudio fragmentadas e de finalidade única por um único sistema que funciona de maneira confiável com fala, música e sons em geral, mesmo em cenários reais e naturais.
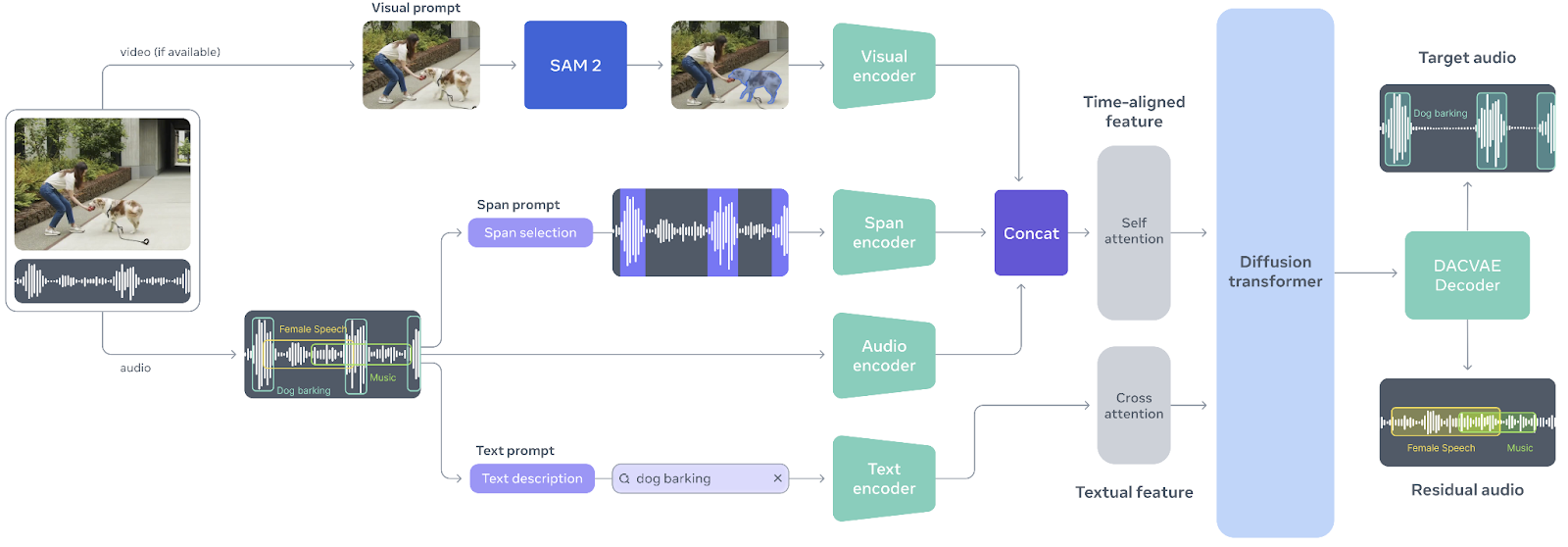
Fonte: facebookresearch/sam-audio
No centro do SAM Audio está o Perception Encoder Audiovisual (PE-AV), um motor poderoso que alinha o que é visto com o que é ouvido, codificando conjuntamente sinais de áudio e visuais ao longo do tempo.
Baseado no Perception Encoder de código aberto da Meta, o PE-AV oferece representações ricas e precisas no tempo, que permitem um desempenho de ponta na separação de áudio multimodal.
Juntas, a SAM Audio e a PE-AV abrem novas possibilidades para mídia criativa, acessibilidade e compreensão de áudio, tornando a segmentação de áudio de nível profissional mais rápida, acessível e fácil de controlar do que nunca.
Agora vou te mostrar como começar a usar o SAM Audio localmente.
O SAM Audio é um modelo fechado, o que significa que você precisa pedir acesso antes de poder baixar e usar localmente. Comece visitando a página do modelo Hugging Face em facebook/sam-audio-large e preencha o formulário de solicitação de acesso. A aprovação geralmente leva cerca de 10 minutos, mas, em alguns casos, o acesso pode ser negado dependendo da sua localização ou de outras políticas aplicadas pela Meta.
Fonte: facebook/sam-audio-large · Hugging Face
Depois de ter acesso, abra um Jupyter Notebook local e instale a biblioteca SAM Audio direto do repositório oficial:
!pip install -q git+https://github.com/facebookresearch/sam-audio.gitUm problema comum ao trabalhar com o SAM Audio é o kernel Jupyter travar ou reiniciar de repente. Isso geralmente é causado por uma versão incompatível do torchcodec. Para resolver isso, desinstale a versão atual e instale a recomendada explicitamente:
!pip uninstall -y torchcodec
!pip install --no-cache-dir "torchcodec==0.7.0" -f https://download.pytorch.org/whl/torchcodec/Para downloads mais rápidos de modelos e dependências, vamos usar hf_transfer:
!pip install hf_transferPor fim, entre no Hugging Face Hub usando um token de acesso. Certifique-se de ter gerado um token API da sua conta Hugging Face e guardado como uma variável de ambiente (HF_TOKEN):
import os
from huggingface_hub import login
login(token=os.environ["HF_TOKEN"])Nesta etapa, vamos baixar e carregar o modelo básico SAM Audio. Embora o SAM Audio também ofereça uma variante grande, o modelo básico tem quase a mesma qualidade de separação, mas usa bem menos memória da GPU.
Isso faz com que seja muito mais adequado para experimentação local, especialmente em GPUs de consumo, como a RTX 3090.
Para evitar erros de memória insuficiente (OOM), é importante carregar o modelo em FP16 (meia precisão) em vez de FP32.
A RTX 3090 tem um suporte FP16 excelente, e mudar para meia precisão quase reduz pela metade o uso de VRAM sem afetar muito a qualidade da inferência.
import torch
import torchaudio
from pathlib import Path
from sam_audio import SAMAudio, SAMAudioProcessor
MODEL_ID = "facebook/sam-audio-base" # base model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SAMAudio.from_pretrained(MODEL_ID).eval()
# Use fp16 on GPU to cut VRAM roughly in half (3090 supports fp16 well)
model = model.to(device=device, dtype=torch.float16).eval()
processor = SAMAudioProcessor.from_pretrained(MODEL_ID)
print("Device:", device)
print("Sampling rate:", processor.audio_sampling_rate)Na primeira vez que você executar isso, o download pode demorar um pouco. A SAM Audio usa vários componentes e pontos de verificação que, juntos, formam todo o pipeline de segmentação de áudio, incluindo o codificador de percepção e os módulos de separação generativa. Esse é o comportamento esperado e só rola uma vez, já que os arquivos ficam guardados no cache local pra futuras execuções.
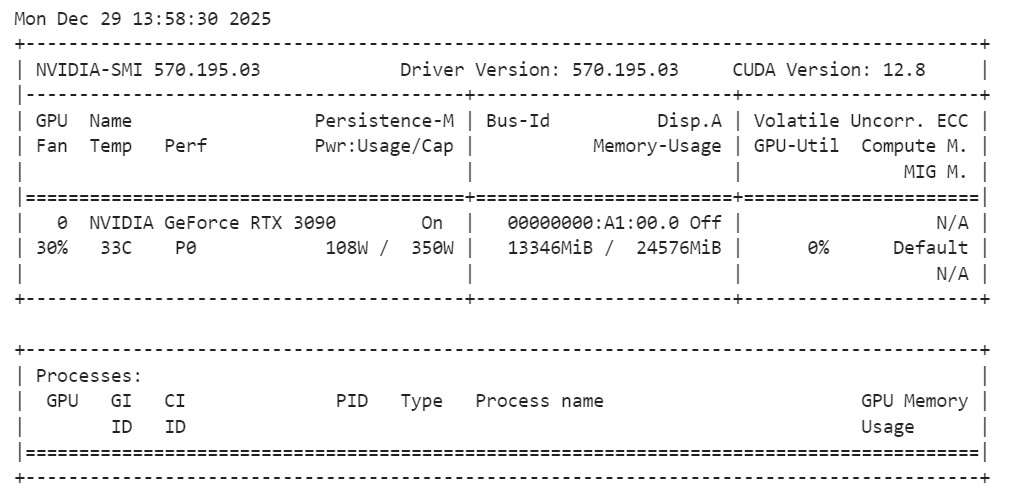
Depois que o modelo for carregado, é uma boa ideia conferir o uso da memória da GPU pra garantir que tudo esteja funcionando dentro dos limites:
!nvidia-smiVocê deve observar que o modelo básico do SAM Audio usa aproximadamente 14 GB de VRAM, o que se encaixa perfeitamente em uma RTX 3090. Isso deixa espaço suficiente para inferências e experimentos sem causar problemas de memória, tornando a configuração estável e confiável para tarefas de segmentação de áudio local.
Pra testar o SAM Audio, a gente precisa de uma amostra de áudio realista que tenha várias fontes de som sobrepostas. Para este tutorial, vamos usar um exemplo do AudioCaps, um conjunto de dados de referência muito usado para compreensão e legendagem de áudio.
O AudioCaps tem vários clipes de áudio curtos e variados, gravados em ambientes reais, o que o torna perfeito para avaliar modelos de separação de áudio.
Carregamos o conjunto de dados direto do Hugging Face usando a biblioteca datasets. A amostra de áudio está guardada no formato Parquet e inclui tanto dados de forma de onda quanto metadados, como a taxa de amostragem.
from datasets import load_dataset
from IPython.display import Audio
# Get an example audio from AudioCaps
dset = load_dataset(
"parquet",
data_files="hf://datasets/OpenSound/AudioCaps/data/test-00000-of-00041.parquet",
)
samples = dset["train"][8]["audio"].get_all_samples()
Audio(samples.data, rate=samples.sample_rate)Esse código baixa um único fragmento do conjunto de testes AudioCaps e extrai um clipe de áudio para demonstração. O widget Audio permite ouvir a mistura bruta diretamente dentro do notebook, o que é útil para entender a complexidade do áudio original antes da segmentação. É assim que soa:
Ouvir é a maneira mais rápida de entender uma mixagem de áudio, mas visualizar a forma de onda ajuda você a ver onde as coisas acontecem.
Um gráfico de forma de onda facilita a identificação de momentos com energia forte (como uma buzina, palmas ou gritos), regiões mais silenciosas (pausas ou ruído de fundo) e picos repentinos que geralmente correspondem a eventos sonoros curtos.
Isso fica bem útil quando a gente começa a separar os sons, porque dá pra comparar a mistura original com a saída segmentada e validar rapidamente se o SAM Audio realmente extraiu a região certa.
Abaixo está uma função auxiliar simples que plota a forma de onda por um tempo fixo (pra que o gráfico fique legível). Ele suporta áudio mono e estéreo e move automaticamente os tensores para a CPU, para que funcione perfeitamente em um notebook.
import matplotlib.pyplot as plt
import torch
def plot_waveform(wav, sr, title="Waveform", max_seconds=15):
"""
wav: Tensor [C, T] or [T]
sr: sample rate (int)
"""
if isinstance(wav, torch.Tensor):
w = wav.detach().cpu()
else:
w = torch.tensor(wav)
if w.ndim == 1:
w = w.unsqueeze(0)
# limit duration for readability
max_samples = int(sr * max_seconds)
w = w[:, :max_samples]
t = torch.arange(w.shape[1]) / sr
plt.figure(figsize=(14, 3))
for c in range(w.shape[0]):
plt.plot(t, w[c].numpy(), label=f"ch{c}")
plt.title(title)
plt.xlabel("Time (s)")
plt.ylabel("Amplitude")
if w.shape[0] > 1:
plt.legend()
plt.tight_layout()
plt.show()
plot_waveform(samples.data, samples.sample_rate, title="Traffic noise + Horn")Neste exemplo, você normalmente vai notar uma forma de onda intensa e densa representando ruído de fundo contínuo (tráfego) e picos mais acentuados que geralmente correspondem a eventos curtos e mais altos (como uma buzina).
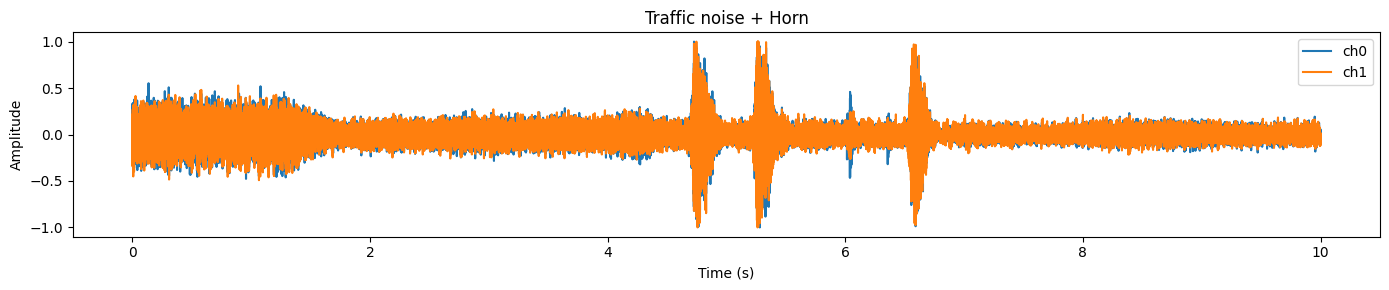
Antes de rodarmos o SAM Audio, precisamos ter certeza de que a forma de onda de entrada está de acordo com o que o modelo espera. Na prática, o áudio bruto dos conjuntos de dados pode variar emformato , tipo de dados, número de canais e taxa de amostragem. Se a gente pular essa etapa, você vai acabar encontrando erros (dimensões erradas), obtendo resultados ruins (taxa de amostragem errada) ou desperdiçando memória da GPU (tipo de dados errado).
Aqui está o que vamos padronizar:
C, T] (canais primeiro).float32 para um processamento seguro e, em seguida, combine o tipo de dados do modelo (FP16 no CUDA).wav = torch.tensor(samples.data)
# Ensure [C, T]
if wav.ndim == 1:
wav = wav.unsqueeze(0) # [1, T]
elif wav.ndim == 2 and wav.shape[0] > wav.shape[1]:
wav = wav.transpose(0, 1) # [T, C] -> [C, T]
wav = wav.float()
orig_sr = int(samples.sample_rate)
target_sr = int(processor.audio_sampling_rate)
if orig_sr != target_sr:
wav = torchaudio.functional.resample(wav, orig_sr, target_sr)
# Mono
wav = wav.mean(0, keepdim=True) # [1, T]
# Move to device + match model dtype (FP16 on CUDA)
wav = wav.to(device=device, dtype=next(model.parameters()).dtype)
duration_s = wav.shape[-1] / target_sr
print(f"Resampled duration: {duration_s:.2f}s @ {target_sr} Hz")Se tudo estiver configurado corretamente, você deverá ver uma saída como:
Resampled duration: 10.00s @ 48000 HzIsso confirma que (1) a duração do áudio é a que esperávamos e (2) a forma de onda agora está usando a taxa de amostragem preferida do modelo.
Agora vem a parte divertida: vamos separar um som alvo da mistura de áudio original. O SAM Audio permite que você faça isso usando comandos naturais e, neste exemplo, vamos extrair“ ” (uma buzina tocando) de um clipe que contém ruídos de trânsito e buzinas.
Vamos usar dois tipos de orientação ao mesmo tempo:
description): diz ao modelo o que a gente quer (“Uma buzina tocando”).anchors): diz ao modelo emque momento o alvo aparece (em segundos).Isso torna a separação muito mais confiável, principalmente quando a mistura de áudio está cheia ou quando o som alvo é curto.
No formato âncoras:
6.3, 7.0] é a janela de tempo (início, fim) em segundosdescription = "A horn honking"
anchors = [[["+", 6.3, 7.0]]] # batch -> one sample -> one anchor
# (Optional) sanity-check anchors
assert 0 <= anchors[0][0][1] < anchors[0][0][2] <= duration_s + 1e-6, "Anchor out of range!"
inputs = processor(
audios=[wav],
descriptions=[description],
anchors=anchors,
).to(device)
with torch.inference_mode():
result = model.separate(inputs)
target_np = result.target[0].detach().float().cpu().numpy()
resid_np = result.residual[0].detach().float().cpu().numpy()
Audio(target_np, rate=processor.audio_sampling_rate)Quando isso funciona direitinho, o resultado é realmente incrível: o áudio final deve soar como um programa de trompa limpo, com a maior parte do ruído de fundo removido. Essa é a ideia principal por trás do SAM Audio: você não precisa de faixas perfeitas ou edição manual, basta guiar o modelo com instruções intuitivas e ele isola o som para você. Abaixo está como soa:
Ouvir é a melhor prova, mas a forma de onda facilita ver o que aconteceu.
plot_waveform(target_np, processor.audio_sampling_rate, title="Cleand Audio with only Horn")Na saída separada, você normalmente vai notar picos distintos onde ocorre o som da buzina, enquanto o resto da forma de onda permanece relativamente silencioso.
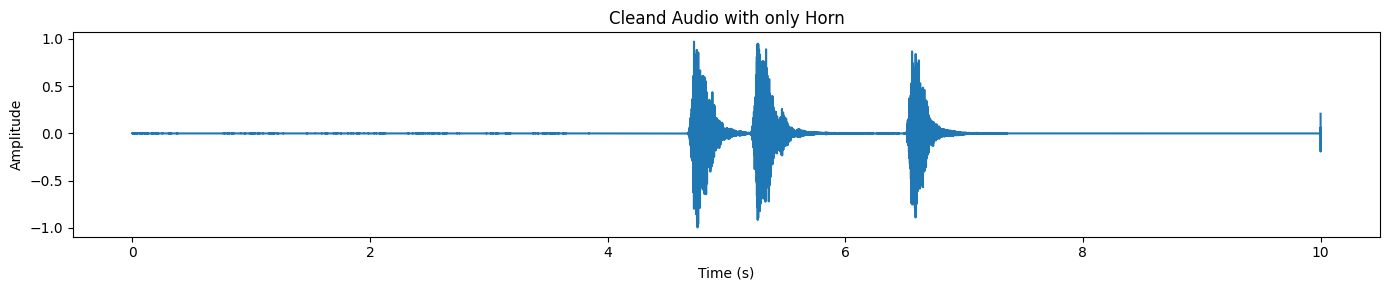
O SAM Audio também devolve um programa residual, que é basicamente “o resto do áudio” depois de tirar o alvo.
plot_waveform(resid_np, processor.audio_sampling_rate, title="Residual Audio with no Horn")Só vemos o barulho do trânsito/ruído de fundo aqui, e nenhum som de buzina.
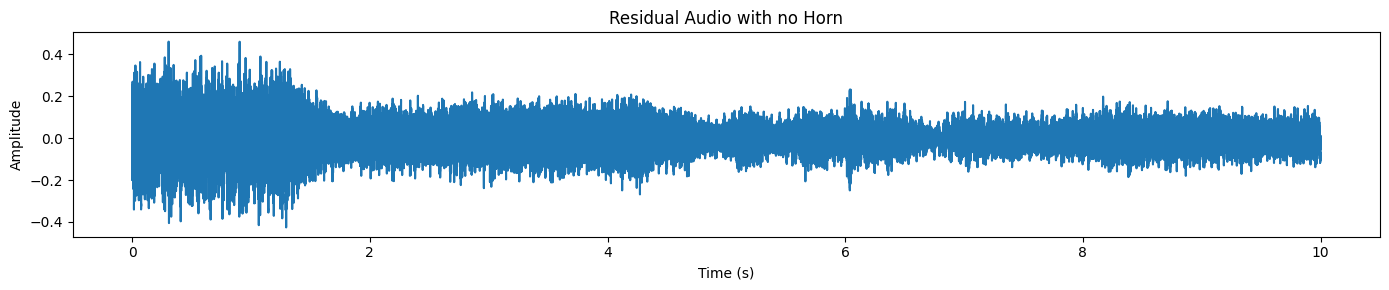
Vamos tentar um exemplo mais difícil e mais realista. Desta vez, vamos escolher um trecho em que uma pessoa que não fala inglês está falando ao telefone enquanto há muito barulho de fundo (barulho da rua, ambiente, sons sobrepostos).
É exatamente nesse tipo de situação que a separação de áudio se torna realmente útil: a fala está presente, mas é difícil de entender porque a mistura é confusa.
Primeiro, carregue uma nova amostra e ouça a mistura de áudio bruta:
samples_2 = dset["train"][45]["audio"].get_all_samples()
Audio(samples_2.data, rate=samples_2.sample_rate)Agora, imagina a forma de onda.
plot_waveform(samples_2.data, samples_2.sample_rate, title="Background Noise and a Man Talking")Você vai ver um sinal intenso e com muita energia na maior parte do clipe, o que geralmente indica um ruído de fundo forte e áudio sobreposto:
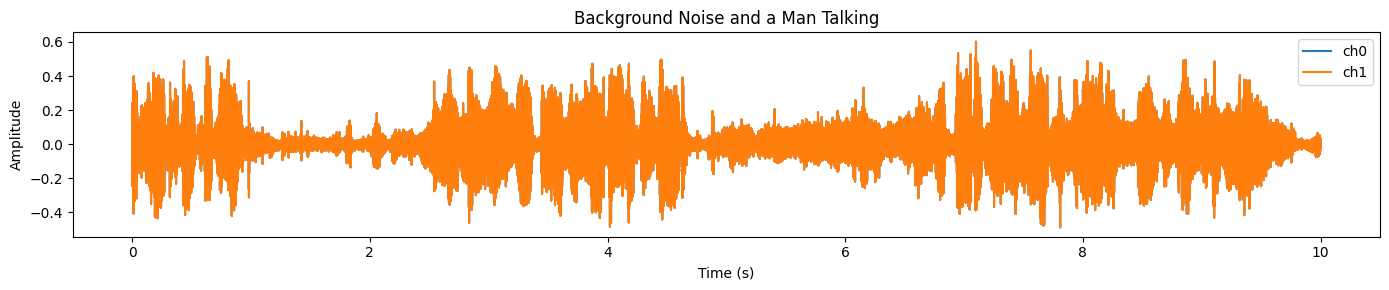
Vamos fazer as mesmas etapas de pré-processamento de antes: garantir a forma [C, T], reamostrar para a taxa de amostragem alvo do processador, converter para mono e mover para a GPU em FP16.
# Convert numpy → torch
wav = torch.tensor(samples_2.data)
# Ensure [C, T]
if wav.ndim == 1:
wav = wav.unsqueeze(0)
elif wav.ndim == 2 and wav.shape[0] > wav.shape[1]:
wav = wav.transpose(0, 1)
wav = wav.float()
orig_sr = int(samples.sample_rate)
target_sr = int(processor.audio_sampling_rate)
# Resample if needed
if orig_sr != target_sr:
wav = torchaudio.functional.resample(wav, orig_sr, target_sr)
# Mono
wav = wav.mean(0, keepdim=True)
# Move to GPU + FP16
wav = wav.to(device=device, dtype=next(model.parameters()).dtype)
duration_s = wav.shape[-1] / target_sr
print(f"Duration: {duration_s:.2f}s @ {target_sr} Hz")
Você deve ver algo assim:
Duration: 10.00s @ 48000 HzNo exemplo anterior, a gente ajudou o modelo com uma âncora de intervalo de tempo e um prompt de texto. Aqui, vamos usar apenas prompts de texto, o que é uma ótima maneira de testar o quão bem o modelo consegue generalizar sem orientações adicionais.
description = "A man speaking"
inputs = processor(
audios=[wav],
descriptions=[description],
).to(device)
with torch.inference_mode():
result = model.separate(inputs)
target_np = result.target[0].detach().float().cpu().numpy()
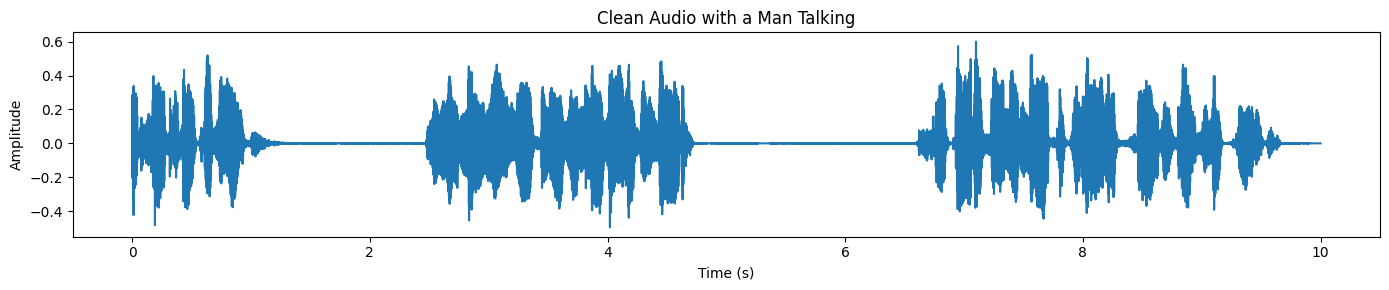
plot_waveform(target_np, processor.audio_sampling_rate, title="Clean Audio with a Man Talking")Por fim, trace a forma de onda da fala separada. Comparado com a mistura original, a forma de onda deve parecer mais limpa e menos “confusa”, especialmente nas áreas onde o ruído de fundo dominava antes:
Se você tiver algum problema ao executar o código acima, dê uma olhada no notebook do DataLab no link abaixo pra ver uma referência completa e funcional, além de orientações adicionais: Usando o SAM-Audio localmente — DataLab.
O SAM Audio foi feito pra entender e editar áudio do mundo real. Em vez de depender de ferramentas específicas para cada tarefa, ele usa comandos naturais para separar e isolar sons em conversas, músicas e ambientes do dia a dia.
Esses recursos tornam-no útil em fluxos de trabalho criativos, profissionais e de pesquisa, onde um áudio limpo e controlável é importante.
Pra ser sincero, não tem muita informação por aí sobre como realmente rodar o SAM Audio localmente. Tentei rodar no Kaggle com GPUs T4, mas não deu certo. Também tentei usar o UV e configurar um ambiente Python virtual, mas isso também não deu certo.
O principal problema que eu sempre encontrava eram conflitos de dependência. Instalar o SAM Audio direto do repositório GitHub muitas vezes substitui as bibliotecas de áudio e PyTorch que já existem, o que faz com que o kernel Jupyter trave.
É por isso que recomendo começar com uma configuração limpa usando o Conda ou um ambiente virtual Python novo, instalando primeiro o PyTorch e o CUDA e, em seguida, adicionando as bibliotecas necessárias. Neste tutorial, a configuração ficou estável depois que eu consertei a falha reinstalando a versão correta do torchcodec.
Neste tutorial, rodamos com sucesso o modelo base SAM Audio em uma RTX 3090 usando cerca de 14 GB de VRAM, o que é bem razoável para inferência local. A velocidade de inferência é rápida e a qualidade da separação de áudio é realmente impressionante. Você também pode estender essa configuração para prompts baseados em vídeo, onde o SAM Audio trabalha junto com o SAM 3 para isolar o áudio com base em pistas visuais.
Pra saber mais sobre o SAM 3, recomendo dar uma olhada no nosso Tutorial do SAM 3.
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
blog
Dr Ana Rojo-Echeburúa
9 min
Tutorial
Aashi Dutt
Tutorial
Moez Ali
Tutorial
Tutorial
Zoumana Keita


