
Kurs
Effizientes KI-Modelltraining mit PyTorch
4 Std.
1.5K
Du kennst dich vielleicht schon mit der Segmentierung von Bildern und Videos aus, aber die Segmentierung von Audiodaten ist ein viel weniger erforschtes Gebiet. Das ist die Fähigkeit, Geräusche in einem Audiostream zu trennen und zu isolieren, wie zum Beispiel eine Stimme aus der Hintergrundmusik herauszuhören oder die Stimme einer einzelnen Person in einer Gruppensitzung zu isolieren. Bis vor kurzem brauchte man für diese Aufgaben spezielle Tools und musste ziemlich viel von Hand machen.
In diesem Tutorial schauen wir uns SAM Audio an, die Audio-Erweiterung des Segment Anything Model. Wir richten eine lokale Umgebung ein, installieren die erforderlichen Abhängigkeiten, laden das Modell und führen die Inferenz auf einer RTX 3090-GPU durch.
Dabei zeigen wir, wie SAM Audio bestimmte Teile eines Audiosignals auf eine Weise segmentieren kann, die viel intuitiver und präziser ist als herkömmliche Audioverarbeitungsmethoden.
SAM Audio ist das erste einheitliche multimodale Modell seiner Art, das entwickelt wurde, um die Audioseparation so intuitiv wie die Interaktion mit dem Klang selbst zu machen. Inspiriert vom Erfolg des Segment Anything Model im Bereich der Bildverarbeitung ermöglicht SAM Audio den Nutzern, beliebige Töne aus komplexen Audiomischungen mithilfe natürlicher Eingabeaufforderungen zu isolieren, sei es durch Text, visuelle Hinweise in Videos oder durch Markieren von Zeitabschnitten. Dieser einheitliche Ansatz ersetzt einzelne Audio-Tools, die nur für einen Zweck gedacht sind, durch ein einziges System, das zuverlässig für Sprache, Musik und allgemeine Geräusche funktioniert, sogar in echten, realen Situationen.
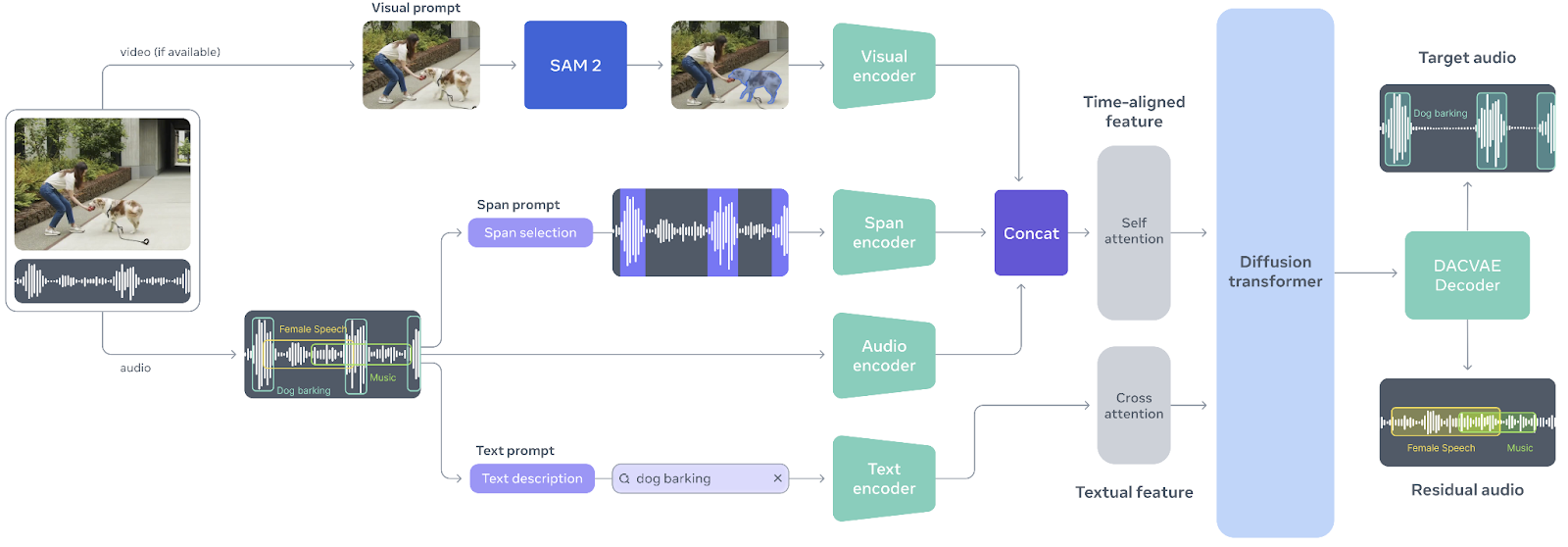
Quelle: facebookresearch/sam-audio
Das Herzstück von SAM Audio ist Perception Encoder Audiovisual (PE-AV), eine starke Engine, die das Gesehene mit dem Gehörten synchronisiert, indem sie Audio- und Videosignale im Zeitverlauf gemeinsam codiert.
PE-AV basiert auf dem Open-Source-Perception Encoder von Meta und bietet umfangreiche, zeitlich präzise Darstellungen, die eine hochmoderne Leistung bei der multimodalen Audio-Trennung ermöglichen.
Zusammen machen SAM Audio und PE-AV neue Möglichkeiten für kreative Medien, Barrierefreiheit und Audioverständnis möglich und sorgen dafür, dass professionelle Audiosegmentierung schneller, zugänglicher und einfacher zu steuern ist als je zuvor.
Ich zeig dir jetzt, wie du SAM Audio lokal einrichten und nutzen kannst.
SAM Audio ist ein geschützter Modell, was heißt, dass du erst Zugriff beantragen musst, bevor du es runterladen und lokal nutzen kannst. Schau dir erst mal die Hugging Face-Modellseite unter facebook/sam-audio-large und füll das Formular für die Zugangsanfrage aus. Die Genehmigung dauert normalerweise etwa 10 Minuten, aber manchmal kann der Zugang je nach deinem Standort oder anderen Richtlinien von Meta verweigert werden.
Quelle: facebook/sam-audio-large · Hugging Face
Sobald du Zugriff hast, starte ein lokales Jupyter Notebook und installiere die SAM Audio-Bibliothek direkt aus dem offiziellen Repository:
!pip install -q git+https://github.com/facebookresearch/sam-audio.gitEin häufiges Problem bei der Arbeit mit SAM Audio ist, dass der Jupyter-Kernel abstürzt oder plötzlich neu startet. Das liegt meistens daran, dass die Version von torchcodec nicht passt. Um das Problem zu beheben, deinstalliere die vorhandene Version und installiere explizit die empfohlene Version:
!pip uninstall -y torchcodec
!pip install --no-cache-dir "torchcodec==0.7.0" -f https://download.pytorch.org/whl/torchcodec/Für schnellere Downloads von Modellen und Abhängigkeiten nutzen wir hf_transfer:
!pip install hf_transferZum Schluss logg dich mit einem Zugriffstoken beim Hugging Face Hub ein. Stell sicher, dass du einen API-Token von deinem Hugging Face-Konto generiert und als Umgebungsvariable gespeichert hast (HF_TOKEN):
import os
from huggingface_hub import login
login(token=os.environ["HF_TOKEN"])In diesem Schritt laden wir das SAM Audio-Basismodellherunter und laden es: . SAM Audio hat zwar auch eine größere Version, aber das Basismodell macht fast die gleiche Trennungsqualität und braucht viel weniger GPU-Speicher.
Dadurch eignet es sich viel besser für lokale Experimente, vor allem auf Consumer-GPUs wie der RTX 3090.
Um Speicherplatzmangel-Fehler (OOM) zu vermeiden, ist es wichtig, das Modell in FP16 (halbe Genauigkeit) statt in FP32 zu laden.
Die RTX 3090 hat echt gute FP16-Unterstützung, und wenn man auf halbe Genauigkeit umschaltet, wird der VRAM-Verbrauch fast halbiert, ohne dass die Inferenzqualität merklich beeinträchtigt wird.
import torch
import torchaudio
from pathlib import Path
from sam_audio import SAMAudio, SAMAudioProcessor
MODEL_ID = "facebook/sam-audio-base" # base model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SAMAudio.from_pretrained(MODEL_ID).eval()
# Use fp16 on GPU to cut VRAM roughly in half (3090 supports fp16 well)
model = model.to(device=device, dtype=torch.float16).eval()
processor = SAMAudioProcessor.from_pretrained(MODEL_ID)
print("Device:", device)
print("Sampling rate:", processor.audio_sampling_rate)Wenn du das hier zum ersten Mal machst, kann der Download eine Weile dauern. SAM Audio nutzt mehrere Komponenten und Prüfpunkte, die zusammen die komplette Audio-Segmentierungspipeline bilden, einschließlich des Wahrnehmungscodierers und der generativen Trennungsmodule. Das ist normal und passiert nur einmal, weil die Dateien für spätere Durchläufe lokal zwischengespeichert werden.
Nachdem das Modell geladen ist, solltest du die GPU-Speichernutzung checken, um sicherzugehen, dass alles im Rahmen bleibt:
!nvidia-smiDu solltest beachten, dass das SAM Audio-Basismodell ungefähr 14 GB VRAM braucht, was auf einer RTX 3090 locker draufpasst. Das lässt genug Spielraum für Schlussfolgerungen und Experimente, ohne Speicherprobleme zu verursachen, und macht das Setup stabil und zuverlässig für lokale Audiosegmentierungsaufgaben.
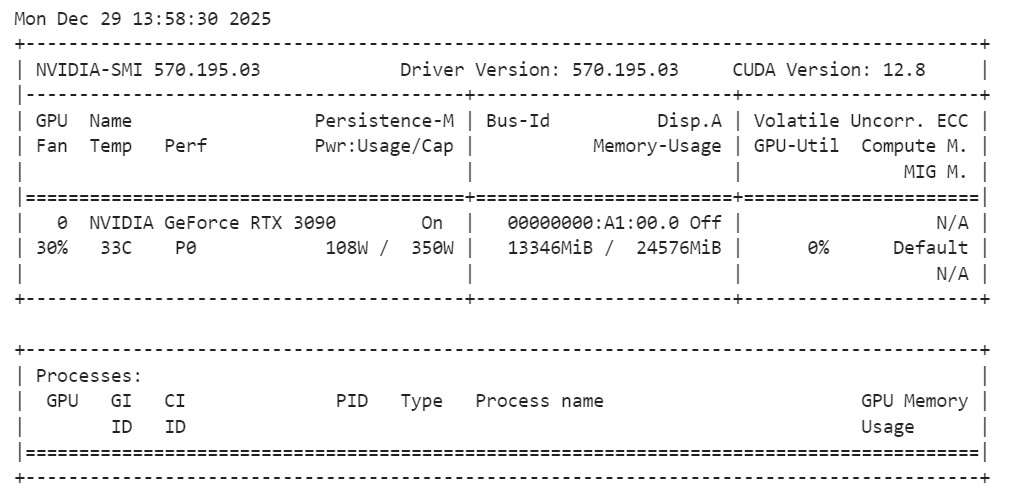
Um SAM Audio zu testen, brauchen wir ein realistisches Audio-Beispiel, das mehrere sich überlagernde Klangquellen hat. Für dieses Tutorial nehmen wir ein Beispiel von AudioCaps, einem weit verbreiteten Benchmark-Datensatz für das Verstehen und Untertiteln von Audio.
AudioCaps hat kurze, abwechslungsreiche Audio-Clips, die aus echten Umgebungen gesammelt wurden, und ist damit super, um Audio-Trennmodelle zu checken.
Wir laden den Datensatz direkt von Hugging Face mit der Bibliothek „ datasets “. Die Audio-Probe ist im Parquet-Format gespeichert und enthält sowohl Wellenformdaten als auch Metadaten wie die Abtastrate.
from datasets import load_dataset
from IPython.display import Audio
# Get an example audio from AudioCaps
dset = load_dataset(
"parquet",
data_files="hf://datasets/OpenSound/AudioCaps/data/test-00000-of-00041.parquet",
)
samples = dset["train"][8]["audio"].get_all_samples()
Audio(samples.data, rate=samples.sample_rate)Dieser Code lädt einen einzelnen Shard des AudioCaps-Testsatzes runter und extrahiert einen Audioclip zur Demo. Mit dem Widget „ Audio “ kannst du dir die Rohmischung direkt im Notebook anhören. Das ist super, um zu verstehen, wie komplex das Original-Audiomaterial vor der Segmentierung ist. So klingt es:
Zuhören ist der schnellste Weg, um eine Audiomischung zu verstehen, aber die Wellenform zu sehen hilft dir dabei, wo was passiert.
Ein Wellenformdiagramm macht es einfacher, Momente mit viel Energie (wie ein Horn, Klatschen oder Rufen), leisere Stellen (Pausen oder Hintergrundgeräusche) und plötzliche Spitzen, die oft mit kurzen Geräuschen zusammenhängen, zu erkennen.
Das ist besonders praktisch, wenn wir anfangen, Töne zu trennen, weil man dann die ursprüngliche Mischung mit der segmentierte Ausgabe und schnell überprüfen, ob SAM Audio wirklich den richtigen Bereich extrahiert hat.
Hier ist eine einfache Hilfsfunktion, die die Wellenform für eine bestimmte Zeitdauer anzeigt (damit das Diagramm übersichtlich bleibt). Es unterstützt sowohl Mono- als auch Stereo-Audio und verschiebt Tensoren automatisch auf die CPU, damit es auf einem Notebook reibungslos läuft.
import matplotlib.pyplot as plt
import torch
def plot_waveform(wav, sr, title="Waveform", max_seconds=15):
"""
wav: Tensor [C, T] or [T]
sr: sample rate (int)
"""
if isinstance(wav, torch.Tensor):
w = wav.detach().cpu()
else:
w = torch.tensor(wav)
if w.ndim == 1:
w = w.unsqueeze(0)
# limit duration for readability
max_samples = int(sr * max_seconds)
w = w[:, :max_samples]
t = torch.arange(w.shape[1]) / sr
plt.figure(figsize=(14, 3))
for c in range(w.shape[0]):
plt.plot(t, w[c].numpy(), label=f"ch{c}")
plt.title(title)
plt.xlabel("Time (s)")
plt.ylabel("Amplitude")
if w.shape[0] > 1:
plt.legend()
plt.tight_layout()
plt.show()
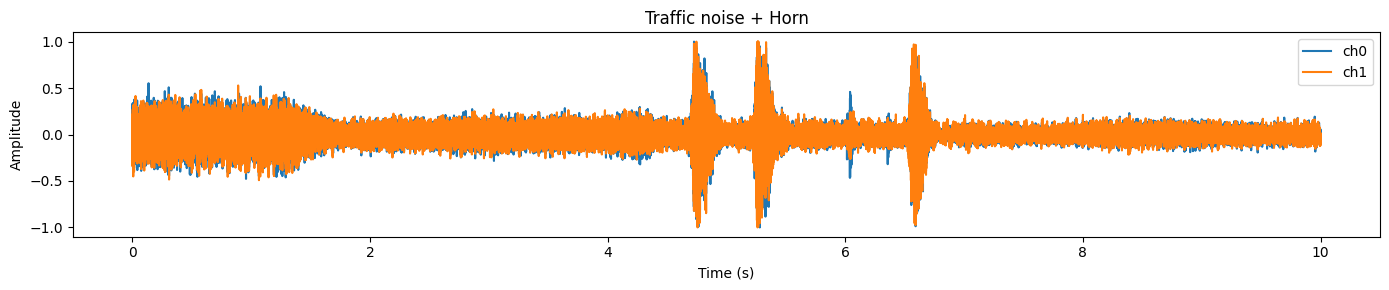
plot_waveform(samples.data, samples.sample_rate, title="Traffic noise + Horn")In diesem Beispiel siehst du normalerweise eine dichte Wellenform , die ein ständiges Hintergrundgeräusch (Verkehr) zeigt, und schärfere Spitzen , die oft mit kurzen, lauteren Ereignissen (wie einer Hupe) zusammenfallen.
Bevor wir SAM Audio starten können, müssen wir sicherstellen, dass die Eingangswellenform mit den Erwartungen des Modells übereinstimmt. In der Praxis kann das Roh-Audio aus Datensätzen in Bezug aufFormat, Typ, Anzahl der Kanäle und Abtastraten variieren . Wenn wir diesen Schritt überspringen, kommt es oft zu Fehlern (falsche Abmessungen), schlechten Ergebnissen (falsche Abtastrate) oder Verschwendung von GPU-Speicher (falscher Datentyp).
Hier ist, was wir standardisieren werden:
C, T] (Kanäle zuerst).float32 “ umwandeln, dann den Modell-Datentyp anpassen (FP16 auf CUDA).wav = torch.tensor(samples.data)
# Ensure [C, T]
if wav.ndim == 1:
wav = wav.unsqueeze(0) # [1, T]
elif wav.ndim == 2 and wav.shape[0] > wav.shape[1]:
wav = wav.transpose(0, 1) # [T, C] -> [C, T]
wav = wav.float()
orig_sr = int(samples.sample_rate)
target_sr = int(processor.audio_sampling_rate)
if orig_sr != target_sr:
wav = torchaudio.functional.resample(wav, orig_sr, target_sr)
# Mono
wav = wav.mean(0, keepdim=True) # [1, T]
# Move to device + match model dtype (FP16 on CUDA)
wav = wav.to(device=device, dtype=next(model.parameters()).dtype)
duration_s = wav.shape[-1] / target_sr
print(f"Resampled duration: {duration_s:.2f}s @ {target_sr} Hz")Wenn alles richtig eingerichtet ist, solltest du eine Ausgabe wie diese sehen:
Resampled duration: 10.00s @ 48000 HzDas zeigt, dass (1) die Audiolänge so ist, wie wir es erwarten, und (2) die Wellenform jetzt die vom Modell bevorzugte Abtastrate nutzt.
Jetzt kommt der spaßige Teil: Wir werden tatsächlich einen Ziel-Sound aus dem ursprünglichen Audiomixherausfiltern. Mit SAM Audio kannst du das mit natürlichen Sprachbefehlen machen. In diesem Beispiel extrahieren wir„ “ („ein Hupen“) aus einem Clip, der Verkehrsgeräusche und Hupen enthält.
Wir werden zwei Arten von Anleitungen gleichzeitig nutzen:
description): sagt dem Modell, was wir wollen („Ein hupendes Auto“).anchors): Sagt dem Modell , wann das Ziel passiert (in Sekunden).Das macht die Trennung viel zuverlässiger, vor allem wenn die Audiomischung voll ist oder der Zielklang kurz ist.
Im Ankerformat:
6.3, 7.0] ist das Zeitfenster (Start, Ende) in Sekunden.description = "A horn honking"
anchors = [[["+", 6.3, 7.0]]] # batch -> one sample -> one anchor
# (Optional) sanity-check anchors
assert 0 <= anchors[0][0][1] < anchors[0][0][2] <= duration_s + 1e-6, "Anchor out of range!"
inputs = processor(
audios=[wav],
descriptions=[description],
anchors=anchors,
).to(device)
with torch.inference_mode():
result = model.separate(inputs)
target_np = result.target[0].detach().float().cpu().numpy()
resid_np = result.residual[0].detach().float().cpu().numpy()
Audio(target_np, rate=processor.audio_sampling_rate)Wenn das richtig funktioniert, ist das Ergebnis echt beeindruckend: Der Ziel-Audio sollte wie eine klare Hornspur klingen, bei der der Großteil des Hintergrunds entfernt wurde. Das ist die Grundidee von SAM Audio: Du brauchst keine perfekten Stems oder manuelle Bearbeitung, sondern steuerst das Modell mit intuitiven Eingabeaufforderungen, und es isoliert den Sound für dich. So klingt es:
Hören ist der beste Beweis, aber die Wellenform macht es einfach zu sehen, was passiert ist.
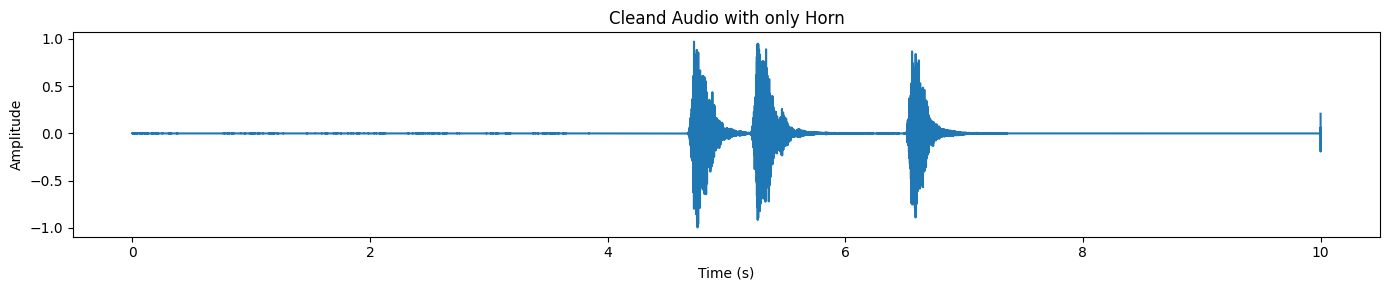
plot_waveform(target_np, processor.audio_sampling_rate, title="Cleand Audio with only Horn")In der getrennten Ausgabe siehst du normalerweise deutliche Spitzen, wo das Horn auftritt, während der Rest der Wellenform ziemlich ruhig bleibt.
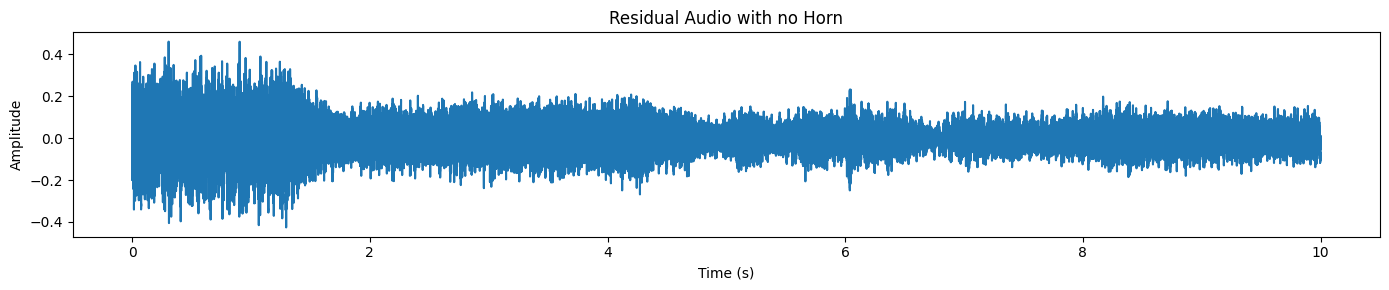
SAM Audio gibt auch einen Resttrack zurück, der im Grunde genommen „der Rest des Audios“ ist, nachdem das Ziel entfernt wurde.
plot_waveform(resid_np, processor.audio_sampling_rate, title="Residual Audio with no Horn")Wir hören hier nur Verkehrs-/Hintergrundgeräusche, aber keinen Hupenton.
Probieren wir mal ein schwierigeres, realistischeres Beispiel aus. Dieses Mal nehmen wir einen Clip, in dem jemand, der kein Englisch spricht, am Telefon quatscht, während es im Hintergrund ziemlich laut ist (Straßenlärm, Umgebungsgeräusche, überlappende Geräusche).
Genau in solchen Situationen ist die Audio-Trennung echt nützlich: Die Sprache ist zwar da, aber schwer zu verstehen, weil alles irgendwie durcheinander ist.
Lade erst mal ein neues Sample und hör dir die rohe Audiomischung an:
samples_2 = dset["train"][45]["audio"].get_all_samples()
Audio(samples_2.data, rate=samples_2.sample_rate)Jetzt stell dir die Wellenform vor.
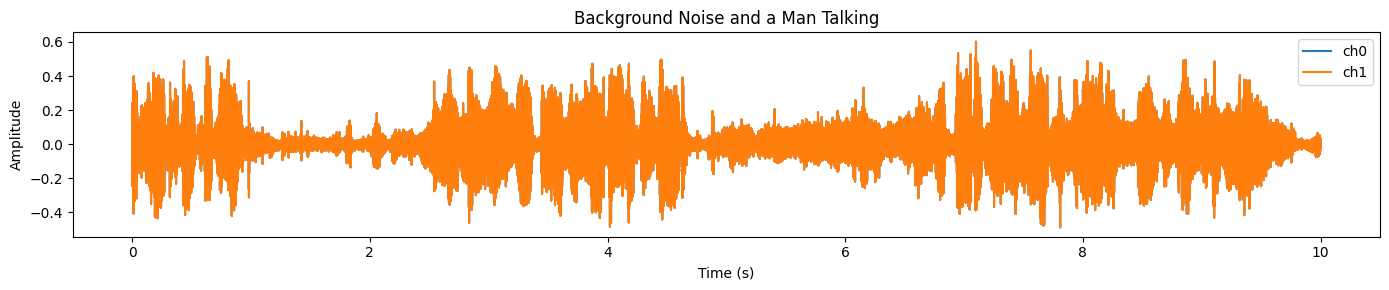
plot_waveform(samples_2.data, samples_2.sample_rate, title="Background Noise and a Man Talking")Du wirst in fast dem ganzen Clip ein dichtes, hochenergetisches Signal sehen, was meistens auf starke Hintergrundgeräusche und überlappende Audiosignale hindeutet:
Wir machen die gleichen Vorverarbeitungsschritte wie vorher: sicherstellen, dass die Form [C, T] stimmt, auf die Zielabtastrate des Prozessors umabtasten, in Mono umwandeln und in FP16 auf die GPU verschieben.
# Convert numpy → torch
wav = torch.tensor(samples_2.data)
# Ensure [C, T]
if wav.ndim == 1:
wav = wav.unsqueeze(0)
elif wav.ndim == 2 and wav.shape[0] > wav.shape[1]:
wav = wav.transpose(0, 1)
wav = wav.float()
orig_sr = int(samples.sample_rate)
target_sr = int(processor.audio_sampling_rate)
# Resample if needed
if orig_sr != target_sr:
wav = torchaudio.functional.resample(wav, orig_sr, target_sr)
# Mono
wav = wav.mean(0, keepdim=True)
# Move to GPU + FP16
wav = wav.to(device=device, dtype=next(model.parameters()).dtype)
duration_s = wav.shape[-1] / target_sr
print(f"Duration: {duration_s:.2f}s @ {target_sr} Hz")
Du solltest was in der Art sehen:
Duration: 10.00s @ 48000 HzIm vorherigen Beispiel haben wir dem Modell mit einem Zeitrahmen-Anker und einer Textvorlage geholfen. Hier machen wir nur Text-Prompts, was super ist, um zu checken, wie gut das Modell ohne extra Anleitung verallgemeinern kann.
description = "A man speaking"
inputs = processor(
audios=[wav],
descriptions=[description],
).to(device)
with torch.inference_mode():
result = model.separate(inputs)
target_np = result.target[0].detach().float().cpu().numpy()
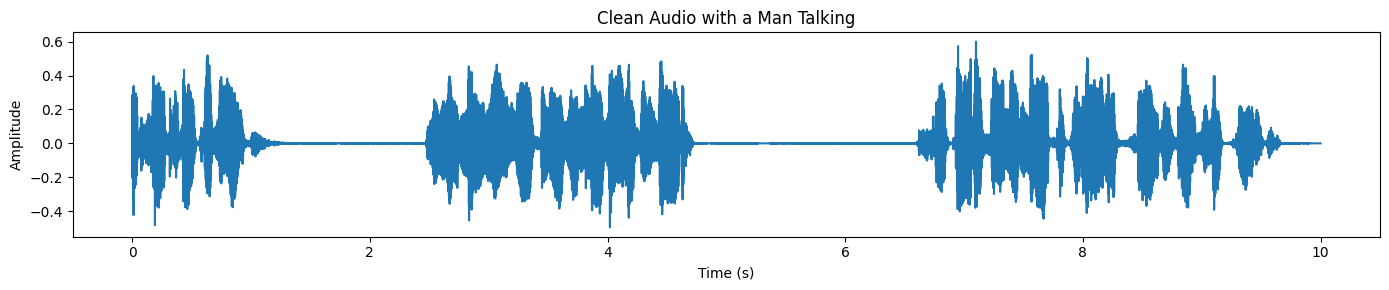
plot_waveform(target_np, processor.audio_sampling_rate, title="Clean Audio with a Man Talking")Zeichne zum Schluss die Wellenform der getrennten Sprache auf. Im Vergleich zur ursprünglichen Mischung sollte die Wellenform jetzt klarer und weniger „unruhig“ aussehen, vor allem in den Bereichen, wo vorher Hintergrundgeräusche dominierten:
Wenn du bei der Ausführung des obigen Codes Probleme hast, schau dir bitte das unten verlinkte DataLab-Notebook an, das eine vollständige, funktionierende Referenz und zusätzliche Anleitungen enthält: SAM-Audio lokal nutzen – DataLab.
SAM Audio ist für echtes Audioverständnis und -bearbeitung gemacht. Anstatt auf spezielle Tools zu setzen, nutzt es natürliche Eingabeaufforderungen, um Geräusche in Sprache, Musik und Alltagsumgebungen zu trennen und zu isolieren.
Diese Funktionen machen es super praktisch für kreative, professionelle und Forschungs-Workflows, wo klarer und kontrollierbarer Ton wichtig ist.
Um ehrlich zu sein, gibt's nicht viele Infos darüber, wie man SAM Audio lokal tatsächlich laufen lässt. Ich hab's auf Kaggle mit T4-GPUs ausprobiert, aber es hat nicht geklappt. Ich hab's auch mit UV versucht und eine virtuelle Python-Umgebung eingerichtet, aber das hat auch nicht geklappt.
Das Hauptproblem, auf das ich immer wieder gestoßen bin, waren Abhängigkeitskonflikte. Wenn du SAM Audio direkt aus dem GitHub-Repository installierst, werden oft die vorhandenen Audio- und PyTorch-Bibliotheken überschrieben, was zum Absturz des Jupyter-Kernels führt.
Deshalb empfehle ich dir, mit einer sauberen Installation mit Conda oder einer neuen virtuellen Python-Umgebung zu starten, zuerst PyTorch und CUDA zu installieren und dann die benötigten Bibliotheken hinzuzufügen. In diesem Tutorial wurde das Setup stabil, nachdem ich den Absturz durch die Neuinstallation der richtigen Version von „ torchcodec “ behoben hatte.
In diesem Tutorial haben wir das SAM Audio-Basismodell erfolgreich auf einer RTX 3090 mit etwa 14 GB VRAM laufen lassen, was für lokale Inferenz echt okay ist. Die Inferenzgeschwindigkeit ist echt schnell und die Qualität der Audio-Trennung ist echt beeindruckend. Du kannst diese Konfiguration auch auf videobasierte Eingabeaufforderungen ausweiten, bei denen SAM Audio zusammen mit SAM 3 arbeitet, um Audio anhand visueller Hinweise zu isolieren.
Um mehr über SAM 3 zu erfahren, schau dir am besten unser SAM 3-Tutorial.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Allan Ouko
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
